Reinforcement Learning
|
|
|
- Kristian Ramsey
- 6 years ago
- Views:
Transcription

1

2 Reinforcement learning is learning what to do--how to map situations to actions--so as to maximize a numerical reward signal Sutton & Barto, Reinforcement learning, 1998.
3 Reinforcement learning is learning what to do--how to map situations to actions--so as to maximize a numerical reward signal Sutton & Barto, Reinforcement learning, The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them. Actions may affect not only the immediate reward but also the next situation and all subsequent rewards. These two characteristics--trial-and-error search and delayed reward--are the two most important distinguishing features of reinforcement learning.

4 We examine how an agent can learn from success and failure, from reward and punishment Russell & Norvig, Artificial Intelligence: a Modern Approach, 2011
5 We examine how an agent can learn from success and failure, from reward and punishment Russell & Norvig, Artificial Intelligence: a Modern Approach, 2011 RL is the problem faced by an agent that learns behavior through trial-and-error interactions with a dynamic environment, without specifying how the task is to be achieved.
6 RL vs traditional AI Techniques that require a predefined model of state transitions and assume determinism Search Planning generate a satisfactory generate a satisfactory trajectory trajectory through a graph of with more complexity than a graph, states states are represented by compositions (atomic symbols) of logical expressions
7 RL vs traditional AI Techniques that require a predefined model of state transitions and assume determinism RL assumes that the entire state space can be enumerated and stored in memory; no model necessary interact with the environment delayed reward exploration partially observable states life-long learning
8 RL vs traditional AI delayed reward The agent must learn from current state s the optimal action a to maximize target function a= (s). Training samples should be <s, (s)> but... information is not available this way! r s r a s a s a r s cumulative reward maximum reward??? a r s a r s cumulative reward
9 RL vs traditional AI exploration vs. exploitation The agent influences the distribution of training examples by the action sequences it chooses exploration of unknown states and actions (new information) exploitation of states and actions already learned (to maximize cumulative reward)
10 RL vs traditional AI partially observable states The agent sensors may provide only partial information. For example: camera in robot It may be necessary to consider previous observations + current sensor data in order to choose actions life-long learning Robot must learn several related tasks, within the same environment, with the same sensors and same possible actions use experience
11 Types of machine learning Supervised Learning set of (INPUT, OUTPUT) pairs (x1, y1), (x2, y2) (xn, yn) try to produce a function Y = f(x) to apply to future data
12 Types of machine learning Supervised Learning set of (INPUT, OUTPUT) pairs (x1, y1), (x2, y2) (xn, yn) try to produce a function Y = f(x) to apply to future data Unsupervised Learning only INPUT points X1, X2, X3 XN try to either find clusters of those data or generate a probability function over the random variable X P(X = x)
13 Types of machine learning Supervised Learning set of (INPUT, OUTPUT) pairs (x1, y1), (x2, y2) (xn, yn) try to produce a function Y = f(x) to apply to future data Unsupervised Learning only INPUT points X1, X2, X3 XN try to either find clusters of those data or generate a probability function over the random variable X P(X = x) a sequence of states and actions s,a,s,a,s where some of the states have associated rewards r try to learn an optimal policy (s), so that for every state s, choose the optimal action to do
14 RL key elements policy ( ): defines the learning agent's way of behaving at a given time. It is a mapping from perceived states of the environment to actions to be taken when in those states. reward function (r): defines the goal in a reinforcement learning problem. It maps each perceived state (or state-action pair) of the environment to a single number, a reward, indicating the intrinsic desirability of that state. The reward function defines what are the good and bad events for the agent. value function (V) : specifies what is good in the long run. The value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state. It indicates the long-term desirability of states after taking into account the states (and rewards) that are likely to follow. model of the environment: it is something that imitates the behavior of the environment.

15 RL Agent Environment interaction RL deals with how an autonomous agent that senses and acts in its environment estimate Value function can learn to choose optimal actions to achieve its goal. a.k.a. learning with a critic
16 RL Agent Environment interaction Goals can be defined by a reward (r) function that assigns numerical values to action state pairs (a,s) This reward function is known by the critic who could be external o built-in The task of the agent is to perform sequences of actions, observe their consequences and learn a control policy ( ) :S A that chooses actions that maximize the accumulated reward

17 But first A little bit of history
18 A little bit of history Early AI psychology of animal learning Learning by trial and error Law of effects Search and memory
19 A little bit of history Early AI psychology of animal learning Optimal control Value functions and dynamic programming Learning by trial and error Bellman equations, 1950 Law of effects Search and memory Howard, Modern RL
20 A little bit of history Early AI psychology of animal learning Minsky PhD thesis: computational models of reinforcement learning SNARCs: Stochastic Neural-Analog Reinforcement Calculators
21 A little bit of history Early AI psychology of animal learning Minsky PhD thesis: computational models of reinforcement learning SNARCs: Stochastic Neural-Analog Reinforcement Calculators 1954 Clark and Farley paper: Trial-and-error learning generalization and pattern recognition Reinforcement learning supervised learning Confusion!!!
22 A little bit of history Early AI psychology of animal learning Minsky PhD thesis: computational models of reinforcement learning SNARCs: Stochastic Neural-Analog Reinforcement Calculators 1954 Clark and Farley paper: Trial-and-error learning generalization and pattern recognition Reinforcement learning supervised learning Confusion!!! 1961 Minsky paper: the terms "reinforcement" and "reinforcement learning" were used in the engineering literature for the first time
23 A little bit of history Widrow and Hoff Rosenblatt Motivated by reinforcement learning used rewards and punishments but they studied supervised learning systems Some NN books use the term "trial-and-error" to describe networks that learn from training examples, because they use error information to update weights CONFUSION!! It misses the essential selectional character of trial-and-error learning Michie and Chambers
24 A little bit of history 1964 Widrow and Smith: used supervised learning methods, assuming instruction from a teacher learning with a teacher 1973 Widrow, Gupta and Maitra: modified LMS to produce a RL rule that could learn from success and failure signals learning with a critic" 1975 John Holland: trial and error in evolutionary methods 1986 classifier RL systems including association and value functions, with a genetic algorithm
25 A little bit of history 1980s Much of the early work was directed towards showing that RL and supervised learning were different (Barto, Sutton, and Brouwer, 1981; Barto and Sutton, 1981; Barto and Anandan, 1985). Studies showed how RL could address important problems in NN learning how it could produce learning algorithms for multilayer networks (Barto, Anderson, and Sutton, 1982; Barto and Anderson, 1985; Barto and Anandan, 1985; Barto, 1985, 1986; Barto and Jordan, 1987) Chris Watkins: Q-learning algorithm
26 Typical RL example: TIC TAC TOE How to construct a player that will find imperfections in its opponent's play and learn to maximize its chances of winning?
27 Typical RL example: TIC TAC TOE How to construct a player that will find imperfections in its opponent's play and learn to maximize its chances of winning? simple problem however it cannot be solved in a satisfactory way through classical techniques Game theory - minimax Evolutionary approach Dynamic programming Search
28 Typical RL example: TIC TAC TOE How to construct a player that will find imperfections in its opponent's play and learn to maximize its chances of winning? simple problem however it cannot be solved in a satisfactory way through classical techniques Game theory - minimax Evolutionary approach it assumes a particular way of playing by the opponent Dynamic programming can compute an optimal solution for any opponent, but require as input a complete specification of that opponent, including the probabilities with which the opponent makes each move in each board state Search By directly searching the policy space entire policies are proposed and compared on the basis of scalar evaluations.
29 Typical RL example: TIC TAC TOE Value Function: table of numbers, one for each possible state of the game. Each number will be the estimate of the probability of our winning from that state For all states with 3 Xs in a row the probability of winning is 1, because we have already won. For all states with three O in a row, the correct probability is 0, as we cannot win from them. We set the initial values of all the other states to 0.5 (50% chance of winning) state value
30 Typical RL example: TIC TAC TOE Value Function: table of numbers, one for each possible state of the game. Each number will be the estimate of the probability of our winning from that state For all states with 3 Xs in a row the probability of winning is 1, because we have already won. For all states with three O in a row, the correct probability is 0, as we cannot win from them. We set the initial values of all the other states to 0.5 (50% chance of winning) Play many games against the opponent. To select our moves we examine the states that would result from each of our possible moves and look up their current values in the table. Most of the time we move greedily, selecting the move that leads to the state with greatest value highest estimated probability of winning. Occasionally, we select randomly from other moves exploratory moves.
31 Typical RL example: TIC TAC TOE mejor movida movida exploratoria
32 Typical RL example: TIC TAC TOE While playing, we change the values of the states in which we find ourselves during the game. We attempt to make them more accurate estimates of the probabilities of winning. The current value of the earlier state is adjusted to be closer to the value of the later state. This can be done by moving the earlier state's value a fraction alpha of the way towards the value of the later state: This update rule is an example of a temporal-difference learning method, so called because its changes are based on a difference between estimates at two different times.
33 RL model environment agent Standard reinforcement learning model
34 RL model environment fully/partially observable environment non deterministic/stationary environment agent Standard reinforcement learning model
35 RL model environment fully/partially observable environment non deterministic/stationary environment agent Standard reinforcement learning model
36 Agent Environment interaction examples environment agent
37 Agent Environment interaction environment The agent must find a policy, mapping states to actions, that maximizes some measure of agent reinforcement/reward
38 Agent Environment interaction Usual assumptions: Markov model, discrete states, finite actions, discrete time, stochastic transitions, perfect observations, rationality.
39 Markov decision processes Assume: finite set of states S set of actions A at each discrete time agent observes state st ϵ S and chooses at ϵ A then receives immediate reward rt and state changes to st+1 Markov assumption: st+1 = δ(st,at) and rt = r(st,at) - rt and st+1 depend only on current state and action - functions δ and r may be nondeterministic - functions δ and r not necessarily known to agent
40 Agent learning task Execute actions in environment, observe results and: learn action policy : S A that maximizes cumulative reward over time E [rt + γ rt+1 + γ2 rt+2 + ] γ=0, only inmediate reward is considered from any starting state in S 0 γ < 1 is the discount factor for future rewards γ=1, future reward are given greater emphasis than inmediate reward Note: Target function is : S A but we have no training examples of form (s,a)!!! Training examples are of form <(s,a),r>
41 Policy Search What is an optimal policy? How the agent should take the future into account in the decisions it makes finite-horizon model infinite-horizon discounted model average reward model
42 Policy Search What is an optimal policy? How the agent should take the future into account in the decisions it makes finite-horizon model at a given moment in time, the agent should optimize its expected reward for the next h steps
43 Policy Search What is an optimal policy? How the agent should take the future into account in the decisions it makes finite-horizon model infinite-horizon discounted model It takes the long-run reward of the agent into account, but future rewards are discounted according to a discount factor γ
44 Policy Search What is an optimal policy? How the agent should take the future into account in the decisions it makes finite-horizon model infinite-horizon discounted model average reward model The agent is supposed to take actions that optimize its long-run average reward
45 Value function In a deterministic world, for each possible policy, an evaluation function over states can be defined: V (st) rt + γ rt+1 + γ2 rt+2 + Σ γi rt+i where rt, rt+1, are generated by following policy π starting at state st So the agent task is to learn the optimal policy * * argmax V (s) V*(s)= Vπ* (s) Maximum reward to be obtained starting from s
46 Example States: each position in the grid possible action reward absorbing state (s,a) r(s,a) immediate reward values γ = 0.9 r ((1,1), right) 0 ((1,1), up) 0 ((1,2), right) 0 ((1,2), left) 0 ((1,2), up) 0 ((1,3), up) 100
47 Example Policy example: it specifies exactly one action that the agent will select in any given state. The optimal policy shortest path towards G
48 Example <(s,a),a,a)> Vπ(s) values V <(1,1), up,right,right)> 81 <(1,1), right,right,up)> 81 <(1,2), right,up)> 90 <(1,3), up)> 100
49 Example 90??? <(s,a),a,a)> Vπ(s) values V <(1,1), up,right,right)> 81 <(1,1), right,right,up)> 81 <(1,2), right,up)> 90 <(1,3), up)> 100
50 Example 90 = 0 + γ γ2 0 + γ3 0 + = 0.9*100 <(s,a),a,a)> Vπ(s) values V <(1,1), up,right,right)> 81 <(1,1), right,right,up)> 81 <(1,2), right,up)> 90 <(1,3), up)> 100
51 Example??? Vπ(s) values
52 Example 81 = 0 + γ 0 + γ = 0.92 * 100 <(s,a),a,a)> Vπ(s) values V <(1,1), up,right,right)> 81 <(1,1), right,right,up)> 81 <(1,2), right,up)> 90 <(1,3), up)> 100
53 Value function The task of the agent is to learn a policy : S A that selects next action at based on current observed state st, for example, (st)=at How? Policy that maximizes cumulative reward over time. That is, policy that maximizes : V (st) rt + γ rt+1 + γ2 rt+2 + Σ γi rt+i where the sequence of rewards was generated by a0 = (s0) a1 = (s1) a2 = (s2) s0 r0 s1 r1 s2 r2
54 What to learn? The agent tries to learn the evaluation function V * (or V*) The agent should prefer state s1 over s2 whenever V*(s1) > V*(s2), because the cumulative future reward will be greater from s1. a1 s1 a2 s2 s0
55 What to learn? The agent tries to learn the evaluation function Vπ* (or V*) The agent should prefer state s1 over s2 whenever V*(s1) > V*(s2), because the cumulative future reward will be greater from s1. a1 s1 a2 s2 s0 But we have a problem!!!???
56 What to learn? The agent tries to learn the evaluation function Vπ* (or V*) The agent should prefer state s1 over s2 whenever V*(s1) > V*(s2), because the cumulative future reward will be greater from s1. a1 s1 But we have a problem!!! a2 s2 The agent must choose among ACTIONS, not STATES s0 training examples are of form <(s,a),r>
57 What to learn? The optimal action in state s is the action that maximizes the sum of the immediate reward r(s,a) plus the value V* of the immediate successor state, discounted by γ: *(s) = argmax [ r(s,a) + γ V*(δ(s,a))] a δ(st,at) = st+1 immediate reward value of successor state
58 Value function How finding an optimal policy for an infinite-horizon discounted model? (Bellman, 1957)
59 Value function How finding an optimal policy for an infinite-horizon discounted model? (Bellman, 1957) The optimal value of a state: t V ( s ) max E rt t 0 * can be found as the solution of the Bellman equations: V * ( s) max r ( s, a) P( s, a, s' )V * ( s' ), s S a s ' S
60 Value function Optimal value function (Value iteration algorithm, Bellman, 1957): * V ( s ) max r ( s, a ) P( s, a, s ' )V ( s' ), s S a s ' S * Given the optimal value function, the optimal policy can be specified as: * ( s ) arg max r ( s, a ) P ( s, a, s ' )V ( s ' ) a s ' S *
61 What to learn? The optimal action in state s is the action that maximizes the sum of the immediate reward r(s,a) plus the value V* of the immediate successor state, discounted by γ: *(s) = argmax [ r(s,a) + γ V*(δ(s,a))] a δ(st,at) = st+1 Another problem!!! The value iteration algorithm works well if agent knows δ : S x A S, and r: S x A But when it doesn t, it can t choose actions this way!!!
62 Q function Define new function very similar to V* Q(s,a) r(s,a) + γ V*(δ(s,a)) If agent learns Q, it can choose optimal action even without knowing δ! *(s) = argmax [ r(s,a) + γ V*(δ(s,a))] a *(s) = argmax Q(s,a) a Q is the evaluation function the agent will learn
63 Q function Q is the evaluation function the agent will learn Important facts regarding Q-learning: One can choose globally an optimal sequence of actions by reacting to the local values of Q for the current state. the agent can choose an optimal action without a loookahead search to explicitly consider what state results from the action the value of Q for the current state and action summarizes in a single number all the information needed to determine the discounted cumulative reward
64 Q function (s,a) Q ((1,1), right,right,up) 81 Q(s,a) values ((1,1), up, ) 81 ((1,2), right, ) 90 ((1,2), left, ) 72 ((1,3), up) 100
65 Training rule to learn Q Note Q and V* are closely related: V*(s) = max Q(s,a ) a' which allows us to write Q recursively as: Q(st,at) = r(st,at) + γ V*(δ(st,at)) = r(st,at) + γ max Q(st+1,a ) a (Watkins, 1989)
66 Training rule to learn Q Note Q and V* are closely related: V*(s) = max Q(s,a ) a' which allows us to write Q recursively as: Q(st,at) = r(st,at) + γ V*(δ(st,at)) = r(st,at) + γ max Q(st+1,a ) a (Watkins, 1989) The training rule will be: ˆ ( s, a ) r max Q ˆ ( s', a' ) Q a' where s = δ(s,a) the state resulting from applying action a in state s
67 Q learning algorithm 2. For each s,a initialize table entry Qˆ ( s, a ) 0 Observe current state s 3. Do forever: 1. a) Select an action a and execute it b) Receive immediate reward r c) Observe new state s d) Update the table entry for Q estimate as follows: Qˆ ( s, a ) r max Qˆ ( s ', a ' ) e) a' s s
68 Q learning algorithm 2. For each s,a initialize table entry Qˆ ( s, a ) 0 Observe current state s 3. Do forever: 1. a) Select an action a and execute it b) Receive immediate reward r c) Observe new state s d) Update the table entry for Q estimate as follows: Qˆ ( s, a ) r max Qˆ ( s ', a ' ) e) a' s s This algorithm converges towards the true Q function, if the system can be assumed a deterministic Markov Decission Process and the immediate reward values are bounded (Machine Learning, T. Mitchell, chapter 13)
69 Q learning algorithm: example ˆ ( s 1,,a ˆ Q^(s ) r + γ max Q^(s,a ) Q 1 aright right ) r max Q ( s 2,2 a ' ) a' max{63,81,100} 90

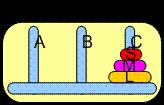
70 Another Q-learning example: Tower of Hanoi Initial state Final state Source:

71 Another Q-learning example: Tower of Hanoi Source:

72 Another Q-learning example: Tower of Hanoi Source:
73 Another Q-learning example: Tower of Hanoi Source:
74 Another Q-learning example: Tower of Hanoi Q(s,a) r + γ max Q(s,a ) Source:

75 Another Q-learning example: Tower of Hanoi Source:
76 Passive state-based representation the policy π is fixed: in state s, it always executes the action π(s) the goal is to learn how good the policy is to learn the value function Vπ(s) non deterministic rewards and actions the agent does not know the transition model P(s,a,s ), which specifies the probability of reaching state s from state s after doing action a the agent does not know the reward function r(s)
77 Passive The agents executes a series of trials in the environment using policy (s) (1,1)-.04 (1,2)-.04 (1,3)-.04 (1,2)-.04 (1,3)-.04 (2,3)-.04 (3,3)-.04 (4,3)+1
78 Passive The agents executes a series of trials in the environment using policy (s) (1,1)-.04 (1,2)-.04 (1,3)-.04 (1,2)-.04 (1,3)-.04 (2,3)-.04 (3,3)-.04 (4,3)+1 (1,1)-.04 (2,1)-.04 (3,1)-.04 (3,2)-.04 (4,2)-1
79 Passive The agents executes a series of trials in the environment using policy (s) Objective: to use the information about rewards to learn the expected utility Vπ(s) Vπ(s) = E [Σ γt r(st)] where r(s) is the reward for a state, st (a random variable) is the state reached at time t when executing policy π and s0 = s
 = -0.")
80 Passive HOMEWORK: FIND optimal policy for the 4x3 world, with reward r(s) = in all the nonterminal states
81 References & Further reading. Sutton and Barto. MIT Press Cambridge (1988) Artificial Intelligence. A Modern Approach. Russell and Norvig. Ed Prentice Hall (2011) (ch. 21) Machine Learning. Mitchell. Ed. McGraw Hil (1997) (ch. 13) : a survey. Kaelbling, Littman and Moore. Journal of Artificial Intelligence Research, vol. 4, (1996)

82 NATURE NEWS (2016): AI algorithm masters ancient game of Go "A computer has beaten a human professional for the first time at Go an ancient board game that has long been viewed as one of the greatest challenges for AI deep learning + reinforcement learning: "the AlphaGo program applied deep learning. It first studied 30 million positions from expert games, on the state of play from board data. Then it played against itself across 50 computers with reinforcement learning. "
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
How long did... Who did... Where was... When did... How did... Which did...
 (Past Tense) Who did... Where was... How long did... When did... How did... 1 2 How were... What did... Which did... What time did... Where did... What were... Where were... Why did... Who was... How many
(Past Tense) Who did... Where was... How long did... When did... How did... 1 2 How were... What did... Which did... What time did... Where did... What were... Where were... Why did... Who was... How many
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
The dilemma of Saussurean communication
 ELSEVIER BioSystems 37 (1996) 31-38 The dilemma of Saussurean communication Michael Oliphant Deparlment of Cognitive Science, University of California, San Diego, CA, USA Abstract A Saussurean communication
ELSEVIER BioSystems 37 (1996) 31-38 The dilemma of Saussurean communication Michael Oliphant Deparlment of Cognitive Science, University of California, San Diego, CA, USA Abstract A Saussurean communication
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games
 Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design
 Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I
 Session 1793 Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I John Greco, Ph.D. Department of Electrical and Computer Engineering Lafayette College Easton, PA 18042 Abstract
Session 1793 Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I John Greco, Ph.D. Department of Electrical and Computer Engineering Lafayette College Easton, PA 18042 Abstract
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
COMPUTER-AIDED DESIGN TOOLS THAT ADAPT
 COMPUTER-AIDED DESIGN TOOLS THAT ADAPT WEI PENG CSIRO ICT Centre, Australia and JOHN S GERO Krasnow Institute for Advanced Study, USA 1. Introduction Abstract. This paper describes an approach that enables
COMPUTER-AIDED DESIGN TOOLS THAT ADAPT WEI PENG CSIRO ICT Centre, Australia and JOHN S GERO Krasnow Institute for Advanced Study, USA 1. Introduction Abstract. This paper describes an approach that enables
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Applying Fuzzy Rule-Based System on FMEA to Assess the Risks on Project-Based Software Engineering Education
 Journal of Software Engineering and Applications, 2017, 10, 591-604 http://www.scirp.org/journal/jsea ISSN Online: 1945-3124 ISSN Print: 1945-3116 Applying Fuzzy Rule-Based System on FMEA to Assess the
Journal of Software Engineering and Applications, 2017, 10, 591-604 http://www.scirp.org/journal/jsea ISSN Online: 1945-3124 ISSN Print: 1945-3116 Applying Fuzzy Rule-Based System on FMEA to Assess the
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Action Models and their Induction
 Action Models and their Induction Michal Čertický, Comenius University, Bratislava certicky@fmph.uniba.sk March 5, 2013 Abstract By action model, we understand any logic-based representation of effects
Action Models and their Induction Michal Čertický, Comenius University, Bratislava certicky@fmph.uniba.sk March 5, 2013 Abstract By action model, we understand any logic-based representation of effects
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Arizona s College and Career Ready Standards Mathematics
 Arizona s College and Career Ready Mathematics Mathematical Practices Explanations and Examples First Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS State Board Approved June
Arizona s College and Career Ready Mathematics Mathematical Practices Explanations and Examples First Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS State Board Approved June
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD
 TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
a) analyse sentences, so you know what s going on and how to use that information to help you find the answer.
 analyse sentences, so you know what s going on and how to use that information to help you find the answer.") Tip Sheet I m going to show you how to deal with ten of the most typical aspects of English grammar that are tested on the CAE Use of English paper, part 4. Of course, there are many other grammar points
Tip Sheet I m going to show you how to deal with ten of the most typical aspects of English grammar that are tested on the CAE Use of English paper, part 4. Of course, there are many other grammar points
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
Given a directed graph G =(N A), where N is a set of m nodes and A. destination node, implying a direction for ow to follow. Arcs have limitations
, where N is a set of m nodes and A. destination node, implying a direction for ow to follow. Arcs have limitations") 4 Interior point algorithms for network ow problems Mauricio G.C. Resende AT&T Bell Laboratories, Murray Hill, NJ 07974-2070 USA Panos M. Pardalos The University of Florida, Gainesville, FL 32611-6595
4 Interior point algorithms for network ow problems Mauricio G.C. Resende AT&T Bell Laboratories, Murray Hill, NJ 07974-2070 USA Panos M. Pardalos The University of Florida, Gainesville, FL 32611-6595
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
While you are waiting... socrative.com, room number SIMLANG2016
 While you are waiting... socrative.com, room number SIMLANG2016 Simulating Language Lecture 4: When will optimal signalling evolve? Simon Kirby simon@ling.ed.ac.uk T H E U N I V E R S I T Y O H F R G E
While you are waiting... socrative.com, room number SIMLANG2016 Simulating Language Lecture 4: When will optimal signalling evolve? Simon Kirby simon@ling.ed.ac.uk T H E U N I V E R S I T Y O H F R G E
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
Foothill College Summer 2016
 Foothill College Summer 2016 Intermediate Algebra Math 105.04W CRN# 10135 5.0 units Instructor: Yvette Butterworth Text: None; Beoga.net material used Hours: Online Except Final Thurs, 8/4 3:30pm Phone:
Foothill College Summer 2016 Intermediate Algebra Math 105.04W CRN# 10135 5.0 units Instructor: Yvette Butterworth Text: None; Beoga.net material used Hours: Online Except Final Thurs, 8/4 3:30pm Phone:
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Extending Place Value with Whole Numbers to 1,000,000
 Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Characteristics of Functions
 Characteristics of Functions Unit: 01 Lesson: 01 Suggested Duration: 10 days Lesson Synopsis Students will collect and organize data using various representations. They will identify the characteristics
Characteristics of Functions Unit: 01 Lesson: 01 Suggested Duration: 10 days Lesson Synopsis Students will collect and organize data using various representations. They will identify the characteristics
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Transfer Learning Action Models by Measuring the Similarity of Different Domains
 Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Multiagent Simulation of Learning Environments
 Multiagent Simulation of Learning Environments Elizabeth Sklar and Mathew Davies Dept of Computer Science Columbia University New York, NY 10027 USA sklar,mdavies@cs.columbia.edu ABSTRACT One of the key
Multiagent Simulation of Learning Environments Elizabeth Sklar and Mathew Davies Dept of Computer Science Columbia University New York, NY 10027 USA sklar,mdavies@cs.columbia.edu ABSTRACT One of the key
Planning with External Events
 94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
Machine Learning and Development Policy
 Machine Learning and Development Policy Sendhil Mullainathan (joint papers with Jon Kleinberg, Himabindu Lakkaraju, Jure Leskovec, Jens Ludwig, Ziad Obermeyer) Magic? Hard not to be wowed But what makes
Machine Learning and Development Policy Sendhil Mullainathan (joint papers with Jon Kleinberg, Himabindu Lakkaraju, Jure Leskovec, Jens Ludwig, Ziad Obermeyer) Magic? Hard not to be wowed But what makes
DOCTOR OF PHILOSOPHY HANDBOOK
 University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus
 Spring 2008 Syllabus") Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples