Exploration. CS : Deep Reinforcement Learning Sergey Levine
|
|
|
- Lisa Paul
- 6 years ago
- Views:
Transcription
1 Exploration CS : Deep Reinforcement Learning Sergey Levine
2 Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent
3 Today s Lecture 1. What is exploration? Why is it a problem? 2. Multi-armed bandits and theoretically grounded exploration 3. Optimism-based exploration 4. Posterior matching exploration 5. Information-theoretic exploration Goals: Understand what the exploration is Understand how theoretically grounded exploration methods can be derived Understand how we can do exploration in deep RL in practice
 this is")
4 What s the problem? this is easy (mostly) this is impossible Why?
5 Montezuma s revenge Getting key = reward Opening door = reward Getting killed by skull = nothing (is it good? bad?) Finishing the game only weakly correlates with rewarding events We know what to do because we understand what these sprites mean!

6 Put yourself in the algorithm s shoes the only rule you may be told is this one Incur a penalty when you break a rule Can only discover rules through trial and error Rules don t always make sense to you Mao Temporally extended tasks like Montezuma s revenge become increasingly difficult based on How extended the task is How little you know about the rules Imagine if your goal in life was to win 50 games of Mao (and you didn t know this in advance)

7 Another example
8 Exploration and exploitation Two potential definitions of exploration problem How can an agent discover high-reward strategies that require a temporally extended sequence of complex behaviors that, individually, are not rewarding? How can an agent decide whether to attempt new behaviors (to discover ones with higher reward) or continue to do the best thing it knows so far? Actually the same problem: Exploitation: doing what you know will yield highest reward Exploration: doing things you haven t done before, in the hopes of getting even higher reward
9 Exploration and exploitation examples Restaurant selection Exploitation: go to your favorite restaurant Exploration: try a new restaurant Online ad placement Exploitation: show the most successful advertisement Exploration: show a different random advertisement Oil drilling Exploitation: drill at the best known location Exploration: drill at a new location Examples from D. Silver lecture notes:
10 Exploration is hard Can we derive an optimal exploration strategy? what does optimal even mean? regret vs. Bayes-optimal strategy? more on this later multi-armed bandits (1-step stateless RL problems) contextual bandits (1-step RL problems) small, finite MDPs (e.g., tractable planning, model-based RL setting) large, infinite MDPs, continuous spaces theoretically tractable theoretically intractable
11 What makes an exploration problem tractable? multi-arm bandits contextual bandits small, finite MDPs large or infinite MDPs can formalize exploration as POMDP identification policy learning is trivial even with POMDP can frame as Bayesian model identification, reason explicitly about value of information optimal methods don t work but can take inspiration from optimal methods in smaller settings use hacks




12 Bandits What s a bandit anyway? the drosophila of exploration problems
13 Let s play! Drug prescription problem Bandit arm = drug (1 of 4) Reward 1 if patient lives 0 if patient dies (stakes are high) How well can you do?
14 How can we define the bandit? solving the POMDP yields the optimal exploration strategy but that s overkill: belief state is huge! we can do very well with much simpler strategies expected reward of best action (the best we can hope for in expectation) actual reward of action actually taken
 actual reward of action actually taken Variety of relatively simple strategies Often can provide theoretical guarantees on")
15 How can we beat the bandit? expected reward of best action (the best we can hope for in expectation) actual reward of action actually taken Variety of relatively simple strategies Often can provide theoretical guarantees on regret Variety of optimal algorithms (up to a constant factor) But empirical performance may vary Exploration strategies for more complex MDP domains will be inspired by these strategies
16 Optimistic exploration some sort of variance estimate intuition: try each arm until you are sure it s not great number of times we picked this action
17 Probability matching/posterior sampling this is a model of our bandit This is called posterior sampling or Thompson sampling Harder to analyze theoretically Can work very well empirically See: Chapelle & Li, An Empirical Evaluation of Thompson Sampling.
18 Information gain Bayesian experimental design:

19 Information gain example Example bandit algorithm: Russo & Van Roy Learning to Optimize via Information-Directed Sampling don t take actions that you re sure are suboptimal don t bother taking actions if you won t learn anything
20 General themes UCB: Thompson sampling: Info gain: Most exploration strategies require some kind of uncertainty estimation (even if it s naïve) Usually assumes some value to new information Assume unknown = good (optimism) Assume sample = truth Assume information gain = good
21 Why should we care? Bandits are easier to analyze and understand Can derive foundations for exploration methods Then apply these methods to more complex MDPs Not covered here: Contextual bandits (bandits with state, essentially 1-step MDPs) Optimal exploration in small MDPs Bayesian model-based reinforcement learning (similar to information gain) Probably approximately correct (PAC) exploration
22 Break
23 Classes of exploration methods in deep RL Optimistic exploration: new state = good state requires estimating state visitation frequencies or novelty typically realized by means of exploration bonuses Thompson sampling style algorithms: learn distribution over Q-functions or policies sample and act according to sample Information gain style algorithms reason about information gain from visiting new states
24 Optimistic exploration in RL UCB: exploration bonus can we use this idea with MDPs? + simple addition to any RL algorithm - need to tune bonus weight
25 The trouble with counts But wait what s a count? Uh oh we never see the same thing twice! But some states are more similar than others
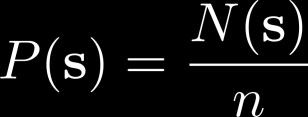
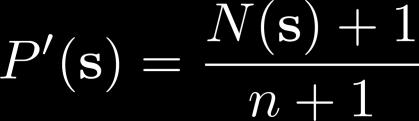
26 Fitting generative models

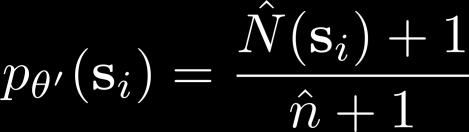
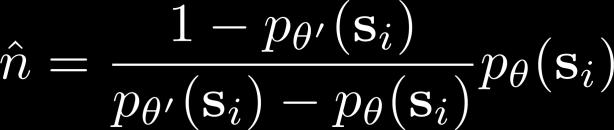
27 Exploring with pseudo-counts Bellemare et al. Unifying Count-Based Exploration


: this is the one used by")
28 What kind of bonus to use? Lots of functions in the literature, inspired by optimal methods for bandits or small MDPs UCB: MBIE-EB (Strehl & Littman, 2008): BEB (Kolter & Ng, 2009): this is the one used by Bellemare et al. 16

29 Does it work? Bellemare et al. Unifying Count-Based Exploration

 Bellemare et al.")
30 What kind of model to use? need to be able to output densities, but doesn t necessarily need to produce great samples opposite considerations from many popular generative models in the literature (e.g., GANs) Bellemare et al.: CTS model: condition each pixel on its top-left neighborhood Other models: stochastic neural networks, compression length, EX2

31 Counting with hashes What if we still count states, but in a different space? Tang et al. #Exploration: A Study of Count-Based Exploration
32 Implicit density modeling with exemplar models need to be able to output densities, but doesn t necessarily need to produce great samples Can we explicitly compare the new state to past states? Intuition: the state is novel if it is easy to distinguish from all previous seen states by a classifier Fu et al. EX2: Exploration with Exemplar Models




33 Implicit density modeling with exemplar models Fu et al. EX2: Exploration with Exemplar Models
34 Posterior sampling in deep RL Thompson sampling: What do we sample? How do we represent the distribution? since Q-learning is off-policy, we don t care which Q-function was used to collect data Osband et al. Deep Exploration via Bootstrapped DQN


35 Bootstrap Osband et al. Deep Exploration via Bootstrapped DQN



36 Why does this work? Exploring with random actions (e.g., epsilon-greedy): oscillate back and forth, might not go to a coherent or interesting place Exploring with random Q-functions: commit to a randomized but internally consistent strategy for an entire episode + no change to original reward function - very good bonuses often do better Osband et al. Deep Exploration via Bootstrapped DQN
37 Reasoning about information gain (approximately) Info gain: Generally intractable to use exactly, regardless of what is being estimated!
38 Reasoning about information gain (approximately) Generally intractable to use exactly, regardless of what is being estimated A few approximations: (Schmidhuber 91, Bellemare 16) intuition: if density changed a lot, the state was novel (Houthooft et al. VIME )
39 Reasoning about information gain (approximately) VIME implementation: Houthooft et al. VIME

40 Reasoning about information gain (approximately) VIME implementation: Approximate IG: + appealing mathematical formalism - models are more complex, generally harder to use effectively Houthooft et al. VIME
41 Exploration with model errors Stadie et al. 2015: encode image observations using auto-encoder build predictive model on auto-encoder latent states use model error as exploration bonus Schmidhuber et al. (see, e.g. Formal Theory of Creativity, Fun, and Intrinsic Motivation): exploration bonus for model error exploration bonus for model gradient many other variations
42 Suggested readings Schmidhuber. (1992). A Possibility for Implementing Curiosity and Boredom in Model-Building Neural Controllers. Stadie, Levine, Abbeel (2015). Incentivizing Exploration in Reinforcement Learning with Deep Predictive Models. Osband, Blundell, Pritzel, Van Roy. (2016). Deep Exploration via Bootstrapped DQN. Houthooft, Chen, Duan, Schulman, De Turck, Abbeel. (2016). VIME: Variational Information Maximizing Exploration. Bellemare, Srinivasan, Ostroviski, Schaul, Saxton, Munos. (2016). Unifying Count-Based Exploration and Intrinsic Motivation. Tang, Houthooft, Foote, Stooke, Chen, Duan, Schulman, De Turck, Abbeel. (2016). #Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning. Fu, Co-Reyes, Levine. (2017). EX2: Exploration with Exemplar Models for Deep Reinforcement Learning.
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Managerial Decision Making
 Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
How to make an A in Physics 101/102. Submitted by students who earned an A in PHYS 101 and PHYS 102.
 How to make an A in Physics 101/102. Submitted by students who earned an A in PHYS 101 and PHYS 102. PHYS 102 (Spring 2015) Don t just study the material the day before the test know the material well
How to make an A in Physics 101/102. Submitted by students who earned an A in PHYS 101 and PHYS 102. PHYS 102 (Spring 2015) Don t just study the material the day before the test know the material well
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
P-4: Differentiate your plans to fit your students
 Putting It All Together: Middle School Examples 7 th Grade Math 7 th Grade Science SAM REHEARD, DC 99 7th Grade Math DIFFERENTATION AROUND THE WORLD My first teaching experience was actually not as a Teach
Putting It All Together: Middle School Examples 7 th Grade Math 7 th Grade Science SAM REHEARD, DC 99 7th Grade Math DIFFERENTATION AROUND THE WORLD My first teaching experience was actually not as a Teach
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
MYCIN. The MYCIN Task
 MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
Algorithms and Data Structures (NWI-IBC027)
") Algorithms and Data Structures (NWI-IBC027) Frits Vaandrager F.Vaandrager@cs.ru.nl Institute for Computing and Information Sciences 7th September 2017 Frits Vaandrager 7th September 2017 Lecture 1 1 /
Algorithms and Data Structures (NWI-IBC027) Frits Vaandrager F.Vaandrager@cs.ru.nl Institute for Computing and Information Sciences 7th September 2017 Frits Vaandrager 7th September 2017 Lecture 1 1 /
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Formative Assessment in Mathematics. Part 3: The Learner s Role
 Formative Assessment in Mathematics Part 3: The Learner s Role Dylan Wiliam Equals: Mathematics and Special Educational Needs 6(1) 19-22; Spring 2000 Introduction This is the last of three articles reviewing
Formative Assessment in Mathematics Part 3: The Learner s Role Dylan Wiliam Equals: Mathematics and Special Educational Needs 6(1) 19-22; Spring 2000 Introduction This is the last of three articles reviewing
Grade 4. Common Core Adoption Process. (Unpacked Standards)
") Grade 4 Common Core Adoption Process (Unpacked Standards) Grade 4 Reading: Literature RL.4.1 Refer to details and examples in a text when explaining what the text says explicitly and when drawing inferences
Grade 4 Common Core Adoption Process (Unpacked Standards) Grade 4 Reading: Literature RL.4.1 Refer to details and examples in a text when explaining what the text says explicitly and when drawing inferences
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Data Structures and Algorithms
 CS 3114 Data Structures and Algorithms 1 Trinity College Library Univ. of Dublin Instructor and Course Information 2 William D McQuain Email: Office: Office Hours: wmcquain@cs.vt.edu 634 McBryde Hall see
CS 3114 Data Structures and Algorithms 1 Trinity College Library Univ. of Dublin Instructor and Course Information 2 William D McQuain Email: Office: Office Hours: wmcquain@cs.vt.edu 634 McBryde Hall see
Top Ten Persuasive Strategies Used on the Web - Cathy SooHoo, 5/17/01
 Top Ten Persuasive Strategies Used on the Web - Cathy SooHoo, 5/17/01 Introduction Although there is nothing new about the human use of persuasive strategies, web technologies usher forth a new level of
Top Ten Persuasive Strategies Used on the Web - Cathy SooHoo, 5/17/01 Introduction Although there is nothing new about the human use of persuasive strategies, web technologies usher forth a new level of
Hentai High School A Game Guide
 Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Chapter 4 - Fractions
 . Fractions Chapter - Fractions 0 Michelle Manes, University of Hawaii Department of Mathematics These materials are intended for use with the University of Hawaii Department of Mathematics Math course
. Fractions Chapter - Fractions 0 Michelle Manes, University of Hawaii Department of Mathematics These materials are intended for use with the University of Hawaii Department of Mathematics Math course
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task
 Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Improving Conceptual Understanding of Physics with Technology
 INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
Analysis of Enzyme Kinetic Data
 Analysis of Enzyme Kinetic Data To Marilú Analysis of Enzyme Kinetic Data ATHEL CORNISH-BOWDEN Directeur de Recherche Émérite, Centre National de la Recherche Scientifique, Marseilles OXFORD UNIVERSITY
Analysis of Enzyme Kinetic Data To Marilú Analysis of Enzyme Kinetic Data ATHEL CORNISH-BOWDEN Directeur de Recherche Émérite, Centre National de la Recherche Scientifique, Marseilles OXFORD UNIVERSITY
a) analyse sentences, so you know what s going on and how to use that information to help you find the answer.
 analyse sentences, so you know what s going on and how to use that information to help you find the answer.") Tip Sheet I m going to show you how to deal with ten of the most typical aspects of English grammar that are tested on the CAE Use of English paper, part 4. Of course, there are many other grammar points
Tip Sheet I m going to show you how to deal with ten of the most typical aspects of English grammar that are tested on the CAE Use of English paper, part 4. Of course, there are many other grammar points
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Experience Corps. Mentor Toolkit
 Experience Corps Mentor Toolkit 2 AARP Foundation Experience Corps Mentor Toolkit June 2015 Christian Rummell Ed. D., Senior Researcher, AIR 3 4 Contents Introduction and Overview...6 Tool 1: Definitions...8
Experience Corps Mentor Toolkit 2 AARP Foundation Experience Corps Mentor Toolkit June 2015 Christian Rummell Ed. D., Senior Researcher, AIR 3 4 Contents Introduction and Overview...6 Tool 1: Definitions...8
The Success Principles How to Get from Where You Are to Where You Want to Be
 The Success Principles How to Get from Where You Are to Where You Want to Be Life is like a combination lock. If you know the combination to the lock... it doesn t matter who you are, the lock has to open.
The Success Principles How to Get from Where You Are to Where You Want to Be Life is like a combination lock. If you know the combination to the lock... it doesn t matter who you are, the lock has to open.
Title:A Flexible Simulation Platform to Quantify and Manage Emergency Department Crowding
 Author's response to reviews Title:A Flexible Simulation Platform to Quantify and Manage Emergency Department Crowding Authors: Joshua E Hurwitz (jehurwitz@ufl.edu) Jo Ann Lee (joann5@ufl.edu) Kenneth
Author's response to reviews Title:A Flexible Simulation Platform to Quantify and Manage Emergency Department Crowding Authors: Joshua E Hurwitz (jehurwitz@ufl.edu) Jo Ann Lee (joann5@ufl.edu) Kenneth
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Cognitive Thinking Style Sample Report
 Cognitive Thinking Style Sample Report Goldisc Limited Authorised Agent for IML, PeopleKeys & StudentKeys DISC Profiles Online Reports Training Courses Consultations sales@goldisc.co.uk Telephone: +44
Cognitive Thinking Style Sample Report Goldisc Limited Authorised Agent for IML, PeopleKeys & StudentKeys DISC Profiles Online Reports Training Courses Consultations sales@goldisc.co.uk Telephone: +44
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
District Advisory Committee. October 27, 2015
 District Advisory Committee October 27, 2015 Outcomes for Today Understanding and awareness of needs for the 21 st century workforce and how these skills are changing education Deeper understanding of
District Advisory Committee October 27, 2015 Outcomes for Today Understanding and awareness of needs for the 21 st century workforce and how these skills are changing education Deeper understanding of
Full text of O L O W Science As Inquiry conference. Science as Inquiry
 Page 1 of 5 Full text of O L O W Science As Inquiry conference Reception Meeting Room Resources Oceanside Unifying Concepts and Processes Science As Inquiry Physical Science Life Science Earth & Space
Page 1 of 5 Full text of O L O W Science As Inquiry conference Reception Meeting Room Resources Oceanside Unifying Concepts and Processes Science As Inquiry Physical Science Life Science Earth & Space
Using AMT & SNOMED CT-AU to support clinical research
 Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
ME 443/643 Design Techniques in Mechanical Engineering. Lecture 1: Introduction
 ME 443/643 Design Techniques in Mechanical Engineering Lecture 1: Introduction Instructor: Dr. Jagadeep Thota Instructor Introduction Born in Bangalore, India. B.S. in ME @ Bangalore University, India.
ME 443/643 Design Techniques in Mechanical Engineering Lecture 1: Introduction Instructor: Dr. Jagadeep Thota Instructor Introduction Born in Bangalore, India. B.S. in ME @ Bangalore University, India.
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Medical Complexity: A Pragmatic Theory
 http://eoimages.gsfc.nasa.gov/images/imagerecords/57000/57747/cloud_combined_2048.jpg Medical Complexity: A Pragmatic Theory Chris Feudtner, MD PhD MPH The Children s Hospital of Philadelphia Main Thesis
http://eoimages.gsfc.nasa.gov/images/imagerecords/57000/57747/cloud_combined_2048.jpg Medical Complexity: A Pragmatic Theory Chris Feudtner, MD PhD MPH The Children s Hospital of Philadelphia Main Thesis
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Executive Guide to Simulation for Health
 Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Introduction to Questionnaire Design
 Introduction to Questionnaire Design Why this seminar is necessary! Bad questions are everywhere! Don t let them happen to you! Fall 2012 Seminar Series University of Illinois www.srl.uic.edu The first
Introduction to Questionnaire Design Why this seminar is necessary! Bad questions are everywhere! Don t let them happen to you! Fall 2012 Seminar Series University of Illinois www.srl.uic.edu The first
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) Feb 2015
 Feb 2015") Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Course Content Concepts
 CS 1371 SYLLABUS, Fall, 2017 Revised 8/6/17 Computing for Engineers Course Content Concepts The students will be expected to be familiar with the following concepts, either by writing code to solve problems,
CS 1371 SYLLABUS, Fall, 2017 Revised 8/6/17 Computing for Engineers Course Content Concepts The students will be expected to be familiar with the following concepts, either by writing code to solve problems,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Individual Differences & Item Effects: How to test them, & how to test them well
 Individual Differences & Item Effects: How to test them, & how to test them well Individual Differences & Item Effects Properties of subjects Cognitive abilities (WM task scores, inhibition) Gender Age
Individual Differences & Item Effects: How to test them, & how to test them well Individual Differences & Item Effects Properties of subjects Cognitive abilities (WM task scores, inhibition) Gender Age
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
CS177 Python Programming
 CS177 Python Programming Recitation 1 Introduction Adapted from John Zelle s Book Slides 1 Course Instructors Dr. Elisha Sacks E-mail: eps@purdue.edu Ruby Tahboub (Course Coordinator) E-mail: rtahboub@purdue.edu
CS177 Python Programming Recitation 1 Introduction Adapted from John Zelle s Book Slides 1 Course Instructors Dr. Elisha Sacks E-mail: eps@purdue.edu Ruby Tahboub (Course Coordinator) E-mail: rtahboub@purdue.edu
Arizona s English Language Arts Standards th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS
 Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
An Introduction to Simulation Optimization
 An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Transfer Learning Action Models by Measuring the Similarity of Different Domains
 Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
PREP S SPEAKER LISTENER TECHNIQUE COACHING MANUAL
 1 PREP S SPEAKER LISTENER TECHNIQUE COACHING MANUAL IMPORTANCE OF THE SPEAKER LISTENER TECHNIQUE The Speaker Listener Technique (SLT) is a structured communication strategy that promotes clarity, understanding,
1 PREP S SPEAKER LISTENER TECHNIQUE COACHING MANUAL IMPORTANCE OF THE SPEAKER LISTENER TECHNIQUE The Speaker Listener Technique (SLT) is a structured communication strategy that promotes clarity, understanding,
SDTM Implementation within Data Management
 SDTM Implementation within Data Management CDISC Users Group Meeting Lauren Shinaberry MSc, CCDM Data Management and SDTM SDTM can be seen as the end point representation of all the work done within DM
SDTM Implementation within Data Management CDISC Users Group Meeting Lauren Shinaberry MSc, CCDM Data Management and SDTM SDTM can be seen as the end point representation of all the work done within DM
The Task. A Guide for Tutors in the Rutgers Writing Centers Written and edited by Michael Goeller and Karen Kalteissen
 The Task A Guide for Tutors in the Rutgers Writing Centers Written and edited by Michael Goeller and Karen Kalteissen Reading Tasks As many experienced tutors will tell you, reading the texts and understanding
The Task A Guide for Tutors in the Rutgers Writing Centers Written and edited by Michael Goeller and Karen Kalteissen Reading Tasks As many experienced tutors will tell you, reading the texts and understanding
Section 7, Unit 4: Sample Student Book Activities for Teaching Listening
 Section 7, Unit 4: Sample Student Book Activities for Teaching Listening I. ACTIVITIES TO PRACTICE THE SOUND SYSTEM 1. Listen and Repeat for elementary school students. It could be done as a pre-listening
Section 7, Unit 4: Sample Student Book Activities for Teaching Listening I. ACTIVITIES TO PRACTICE THE SOUND SYSTEM 1. Listen and Repeat for elementary school students. It could be done as a pre-listening
How To Take Control In Your Classroom And Put An End To Constant Fights And Arguments
 How To Take Control In Your Classroom And Put An End To Constant Fights And Arguments Free Report Marjan Glavac How To Take Control In Your Classroom And Put An End To Constant Fights And Arguments A Difficult
How To Take Control In Your Classroom And Put An End To Constant Fights And Arguments Free Report Marjan Glavac How To Take Control In Your Classroom And Put An End To Constant Fights And Arguments A Difficult
Inquiry Practice: Questions
 Inquiry Practice: Questions Questioning in science Common misunderstandings: You can do inquiry about anything. All questions are good science inquiry questions. When scientists talk about questions, they
Inquiry Practice: Questions Questioning in science Common misunderstandings: You can do inquiry about anything. All questions are good science inquiry questions. When scientists talk about questions, they
TEAM-BUILDING GAMES, ACTIVITIES AND IDEAS
 1. Drop the Ball Time: 10 12 minutes Purpose: Cooperation and healthy competition Participants: Small groups Materials needed: Golf balls, straws, tape Each small group receives 12 straws and 18 inches
1. Drop the Ball Time: 10 12 minutes Purpose: Cooperation and healthy competition Participants: Small groups Materials needed: Golf balls, straws, tape Each small group receives 12 straws and 18 inches
Genevieve L. Hartman, Ph.D.
 Curriculum Development and the Teaching-Learning Process: The Development of Mathematical Thinking for all children Genevieve L. Hartman, Ph.D. Topics for today Part 1: Background and rationale Current
Curriculum Development and the Teaching-Learning Process: The Development of Mathematical Thinking for all children Genevieve L. Hartman, Ph.D. Topics for today Part 1: Background and rationale Current
University of Waterloo School of Accountancy. AFM 102: Introductory Management Accounting. Fall Term 2004: Section 4
 University of Waterloo School of Accountancy AFM 102: Introductory Management Accounting Fall Term 2004: Section 4 Instructor: Alan Webb Office: HH 289A / BFG 2120 B (after October 1) Phone: 888-4567 ext.
University of Waterloo School of Accountancy AFM 102: Introductory Management Accounting Fall Term 2004: Section 4 Instructor: Alan Webb Office: HH 289A / BFG 2120 B (after October 1) Phone: 888-4567 ext.
On Human Computer Interaction, HCI. Dr. Saif al Zahir Electrical and Computer Engineering Department UBC
 On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
Professional Voices/Theoretical Framework. Planning the Year
 Professional Voices/Theoretical Framework UNITS OF STUDY IN THE WRITING WORKSHOP In writing workshops across the world, teachers are struggling with the repetitiveness of teaching the writing process.
Professional Voices/Theoretical Framework UNITS OF STUDY IN THE WRITING WORKSHOP In writing workshops across the world, teachers are struggling with the repetitiveness of teaching the writing process.
Backwards Numbers: A Study of Place Value. Catherine Perez
 Backwards Numbers: A Study of Place Value Catherine Perez Introduction I was reaching for my daily math sheet that my school has elected to use and in big bold letters in a box it said: TO ADD NUMBERS
Backwards Numbers: A Study of Place Value Catherine Perez Introduction I was reaching for my daily math sheet that my school has elected to use and in big bold letters in a box it said: TO ADD NUMBERS
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Practice Examination IREB
 IREB Examination Requirements Engineering Advanced Level Elicitation and Consolidation Practice Examination Questionnaire: Set_EN_2013_Public_1.2 Syllabus: Version 1.0 Passed Failed Total number of points
IREB Examination Requirements Engineering Advanced Level Elicitation and Consolidation Practice Examination Questionnaire: Set_EN_2013_Public_1.2 Syllabus: Version 1.0 Passed Failed Total number of points
Virtually Anywhere Episodes 1 and 2. Teacher s Notes
 Virtually Anywhere Episodes 1 and 2 Geeta and Paul are final year Archaeology students who don t get along very well. They are working together on their final piece of coursework, and while arguing over
Virtually Anywhere Episodes 1 and 2 Geeta and Paul are final year Archaeology students who don t get along very well. They are working together on their final piece of coursework, and while arguing over
Learning and Teaching
 Learning and Teaching Set Induction and Closure: Key Teaching Skills John Dallat March 2013 The best kind of teacher is one who helps you do what you couldn t do yourself, but doesn t do it for you (Child,
Learning and Teaching Set Induction and Closure: Key Teaching Skills John Dallat March 2013 The best kind of teacher is one who helps you do what you couldn t do yourself, but doesn t do it for you (Child,