Two Ideas For Structured Data: Reward augmented maximum likelihood Order matters. Samy Bengio, and the Brain team
|
|
|
- Priscilla Butler
- 6 years ago
- Views:
Transcription
1 Two Ideas For Structured Data: Reward augmented maximum likelihood Order matters Samy Bengio, and the Brain team
2 Reward augmented maximum likelihood for neural structured prediction Mohammad Norouzi, Samy Bengio, Zhifeng Chen, Navdeep Jaitly, Mike Schuster, Yonghui Wu, Dale Schuurmans [NIPS 2016]

3 Structured prediction Prediction of complex outputs: Image captioning A dog and a cat lying in bed next to each other.


4 Structured prediction Prediction of complex outputs: Image captioning Semantic segmentation
5 Structured prediction Prediction of complex outputs: Image captioning Semantic segmentation Speech recognition Machine translation As diets change, people get bigger but plane seating has not radically changed. multivariate, correlated, constrained, discrete Comme les habitudes alimentaires changent, les gens grossissent, mais les sièges dans les avions n'ont pas radicalement changé.


6 Reward function Reward is negative loss In classification, we use 0/1 reward, In segmentation, we use intersection over union, In speech recognition, we use edit distance or WER In machine translation, we use BLEU score

7 Structured prediction problem Given a dataset of input output pairs learn a conditional distribution, Approximate inference using beam search such that model s predictions, achieve a large empirical reward: Performance measure

8 Probabilistic structured prediction Chain rule to build a locally-normalized model: Globally normalized models...


![2014]](/docs-images/76/73114624/images/9-7.jpg "[Sutskever,")

9 </s> [Bahdanau, Cho, Bengio, 2014] [Sutskever, Vinyals, Le, 2014] Neural sequence models </s>
10 Empirical reward is discontinuous and piecewise constant

11 Maximum-likelihood objective Key problems: - There is no notion of reward - Does not capture the inherent ambiguity of the problem
12 Expected reward (RL) [Ranzato et al, 2015] + There is a notion of reward - Hard to train because most samples yield low rewards - Still, does not capture the inherent ambiguity of the problem
 Temperature")
13 Reward augmented maximum likelihood (RML) Temperature hyperparameter :
14 Reward augmented maximum likelihood (RML) + There is a notion of reward and ambiguity + Supervised labels are fully exploited + Simpler optimization requiring stationary samples from q
15 Reward augmented maximum likelihood (RML) SGD update for RML?
 but feasible. Sampling from BLEU: first sample from Hamming or edit distance, then apply an importance correction (i.e. importance sampling)")
16 Sampling from exponentiated payoff distribution Stratified sampling from Hamming reward: Sampling from Edit Distance is a bit more involving (variable size) but feasible. Sampling from BLEU: first sample from Hamming or edit distance, then apply an importance correction (i.e. importance sampling)
17 TIMIT experiments Standard benchmark for clean phone recognition 630 speakers, each speaking 10 phonetically-rich sentences Training from scratch either using ML or RML. Attention-based sequence to sequence model with 3 encoder layers and 1 decoder layer with 256 LSTM cells Edit distance sampling in the phone space - 60 phones Reporting average of 4 independent runs (train / dev/ test sets)

18 Timit results (phone error rates, lower is better)

19 Timit results Fraction of different number of edits applied to a sequence of length 20 for different τ
20 WMT 14 En-Fr experiments English to French translation. Training with 36M sentence pairs. Test with 3003 newstest-14 set. Training from scratch either using ML or RML. Attention-based sequence to sequence model using three-layer encoder and decoder networks with layers of 1024 LSTM cells. Vocabulary of 80k words in the target and 120k in the source Sampling based on Hamming reward Handle rare words by copying from source according to attention

21 WMT 14 En-Fr results (higher is better)
22 Order Matters: Sequence To Sequence For Sets Oriol Vinyals, Samy Bengio, Manjunath Kudlur [ICLR 2016]
23 Sequences in Machine Learning Sequences are common in many ML problems: Speech recognition Machine translation Question answering Image captioning Sentence parsing Time-series prediction Not always aligned : Sometimes, examples are of the form But sometimes there are of the form
24 The Sequence-to-Sequence Framework [Sutskever, et al, 2014]
25 Some Examples Applying Sequence-to-Sequence Machine Translation [Kalchbrenner et al, EMNLP 2013][Cho et al, EMLP 2014][Sutskever & Vinyals & Le, NIPS 2014][Luong et al, ACL 2015][Bahdanau et al, ICLR 2015] Image captions [Mao et al, ICLR 2015][Vinyals et al, CVPR 2015][Donahue et al, CVPR 2015][Xu et al, ICML 2015] Speech [Chorowsky et al, NIPS DL 2014][Chan et al, ICASSP 2016] Parsing [Vinyals & Kaiser et al, arxiv 2014] Dialogue [Shang et al, ACL 2015][Sordoni et al, NAACL 2015][Vinyals & Le, ICML DL 2015] Video Generation [Srivastava et al, ICML 2015] Geometry [Vinyals & Fortunato & Jaitly, NIPS 2015] etc...


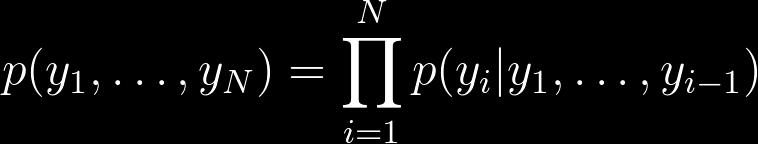
26 Main Ingredient: The Chain Rule


27 What About Sets? Unordered collection of objects Challenge: Bad: Less bad:



28 Examples Where Sets Appear Image -> Set of Objects Video -> Actors
29 More Examples of Sets Random Variables in a graphical model 3-SAT (a b c) ( a c d). ( b c d)
30 Sequences-as-Sets The man with a hat (a,4) (The,1) (hat,5) (man,2) (with,3)
31 Input Order Matters - Examples There is a lot of prior work showing that the order of input variables is important: Machine Translation [Sutskever et al, 2014], translating from English to French Reversing order of English words yielded improvement of up to 5 BLEU points Constituency Parsing [Vinyals et al, 2015], from English sentence to flattened parse tree Reversing order of English words yielded improvement of 0.5% F1 score Convex Hull [Vinyals et al, 2015], from collection of points to its convex hull Sorting points by their angle, yielded 10% improvement in most difficult cases
32 Read-Process-Write: Input Order Invariant Approach Reading block: Reads each input into memory, potentially in parallel Process block: LSTM with no input nor output Performs T steps of computation over the memory, using an attention mechanism [see next slide]. Writing block: LSTM (or Pointer Network) Alternate between an attention step over the memory and outputting the relevant data, such as a pointer to the input memory. Related and recent: Adaptive Computation Time [Graves, 2016] Encode, Review, Decode [Yang et al, 2016]

33 Attention Mechanism in the Process Block At each step of Process, we do: Get the next state of process Compute a function of the state and each input memory Softmax to get posteriors Compute a weighted average input Concatenate with the state of the process block and continue
 or not 10000 training iterations Results: out-of-sample accuracy (either the set is fully sorted or")
34 The Sorting Experiment Task: sort N unordered random floating point numbers (between 0 and 1) Compare Read-Process-Write with a vanilla Pointer Network Vary N the number of numbers to sort, and P, the number of process steps Also consider using a glimpse (attention step between each output step) or not training iterations Results: out-of-sample accuracy (either the set is fully sorted or not)
35 Output Order Matters - Examples Language Modeling Use an LSTM to maximize likelihood of sequence of words (PennTreeBank) Consider these orderings and obtained perplexity on dev set: Natural: This is a sentence. 86 Reverse:. sentence a is This 86 3-word reversal: a is This <pad>. sentence 96 Constituency Parsing Translate between an English sentence and its flattened parse tree Many ways to flatten a parse tree: for instance depth-first obtained 89.5% F1 Breadth-first obtained 81.5% F1
 ordering: Needs to pre-train the model with uniform exploration first After that, estimate the max")
36 Finding Good Output Orderings While Training Sometimes, the optimal order of the output variables per example is unknown While training, we can explore all (or several) potential orderings per example So instead of fixing the ordering and train with: We consider the best (or the best found) ordering: Needs to pre-train the model with uniform exploration first After that, estimate the max by sampling from the model This is very similar to REINFORCE where we learn a policy over orderings Use the same procedure at inference.
37 Example with 5-gram Modeling Simplified task: model 5-grams with no context 5-gram (sequence): y1=this, y2=is, y3=a, y4=five, y5=gram 5-gram (set): y1=(this,1), y2=(is,2), y3=(a,3), y4=(five,4), y5=(gram,5) (1,2,3,4,5): train on the natural ordering (5,1,3,4,2): train on another ordering Easy: train on examples from (1, 2, 3, 4, 5) and (5, 1, 3, 4, 2), uniformly sampled. Hard: train on examples from the 5! possible orderings, uniformly sampled.
38 Conclusion The sequence-to-sequence framework is very powerful for sequences But what about unordered sets? In many cases, order matters! either for inputs or outputs sets For input sets, we can read them irrespective of their order and use an attention mechanism to combine them as many times as needed. For output sets, we can explore the space of possible ordering and favor the best ones per example, both at training and inference time.
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
 Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Language Model and Grammar Extraction Variation in Machine Translation
 Language Model and Grammar Extraction Variation in Machine Translation Vladimir Eidelman, Chris Dyer, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department
Language Model and Grammar Extraction Variation in Machine Translation Vladimir Eidelman, Chris Dyer, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
arxiv: v2 [cs.lg] 8 Aug 2017
![arxiv: v2 [cs.lg] 8 Aug 2017](/thumbs/71/65790056.jpg "arxiv: v2 [cs.lg] 8 Aug 2017") Learn to Evaluate and Iteratively Refine Structured Outputs Michael Gygli 1 * Mohammad Norouzi 2 Anelia Angelova 2 arxiv:1703.04363v2 [cs.lg] 8 Aug 2017 Abstract We approach structured output prediction
Learn to Evaluate and Iteratively Refine Structured Outputs Michael Gygli 1 * Mohammad Norouzi 2 Anelia Angelova 2 arxiv:1703.04363v2 [cs.lg] 8 Aug 2017 Abstract We approach structured output prediction
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Noisy SMS Machine Translation in Low-Density Languages
 Noisy SMS Machine Translation in Low-Density Languages Vladimir Eidelman, Kristy Hollingshead, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department of
Noisy SMS Machine Translation in Low-Density Languages Vladimir Eidelman, Kristy Hollingshead, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department of
Deep Value Networks Learn to Evaluate and Iteratively Refine Structured Outputs
 Learn to Evaluate and Iteratively Refine Structured Outputs Michael Gygli 1 * Mohammad Norouzi 2 Anelia Angelova 2 Abstract We approach structured output prediction by optimizing a deep value network (DVN)
Learn to Evaluate and Iteratively Refine Structured Outputs Michael Gygli 1 * Mohammad Norouzi 2 Anelia Angelova 2 Abstract We approach structured output prediction by optimizing a deep value network (DVN)
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Stacks Teacher notes. Activity description. Suitability. Time. AMP resources. Equipment. Key mathematical language. Key processes
 Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
arxiv: v3 [cs.cl] 24 Apr 2017
![arxiv: v3 [cs.cl] 24 Apr 2017](/thumbs/71/65554092.jpg "arxiv: v3 [cs.cl] 24 Apr 2017") A Network-based End-to-End Trainable Task-oriented Dialogue System Tsung-Hsien Wen 1, David Vandyke 1, Nikola Mrkšić 1, Milica Gašić 1, Lina M. Rojas-Barahona 1, Pei-Hao Su 1, Stefan Ultes 1, and Steve
A Network-based End-to-End Trainable Task-oriented Dialogue System Tsung-Hsien Wen 1, David Vandyke 1, Nikola Mrkšić 1, Milica Gašić 1, Lina M. Rojas-Barahona 1, Pei-Hao Su 1, Stefan Ultes 1, and Steve
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
arxiv: v3 [cs.cl] 7 Feb 2017
![arxiv: v3 [cs.cl] 7 Feb 2017](/thumbs/71/66154314.jpg "arxiv: v3 [cs.cl] 7 Feb 2017") NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
Honors Mathematics. Introduction and Definition of Honors Mathematics
 Honors Mathematics Introduction and Definition of Honors Mathematics Honors Mathematics courses are intended to be more challenging than standard courses and provide multiple opportunities for students
Honors Mathematics Introduction and Definition of Honors Mathematics Honors Mathematics courses are intended to be more challenging than standard courses and provide multiple opportunities for students
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
arxiv: v4 [cs.cv] 13 Aug 2017
![arxiv: v4 [cs.cv] 13 Aug 2017](/thumbs/71/66201702.jpg "arxiv: v4 [cs.cv] 13 Aug 2017") Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
arxiv: v1 [cs.cl] 20 Jul 2015
![arxiv: v1 [cs.cl] 20 Jul 2015](/thumbs/71/66201242.jpg "arxiv: v1 [cs.cl] 20 Jul 2015") How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
arxiv: v2 [cs.cv] 4 Mar 2016
![arxiv: v2 [cs.cv] 4 Mar 2016](/thumbs/71/66025285.jpg "arxiv: v2 [cs.cv] 4 Mar 2016") MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS Fisher Yu Princeton University Vladlen Koltun Intel Labs arxiv:1511.07122v2 [cs.cv] 4 Mar 2016 ABSTRACT State-of-the-art models for semantic segmentation
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS Fisher Yu Princeton University Vladlen Koltun Intel Labs arxiv:1511.07122v2 [cs.cv] 4 Mar 2016 ABSTRACT State-of-the-art models for semantic segmentation
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Domain Adaptation in Statistical Machine Translation of User-Forum Data using Component-Level Mixture Modelling
 Domain Adaptation in Statistical Machine Translation of User-Forum Data using Component-Level Mixture Modelling Pratyush Banerjee, Sudip Kumar Naskar, Johann Roturier 1, Andy Way 2, Josef van Genabith
Domain Adaptation in Statistical Machine Translation of User-Forum Data using Component-Level Mixture Modelling Pratyush Banerjee, Sudip Kumar Naskar, Johann Roturier 1, Andy Way 2, Josef van Genabith
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Greedy Decoding for Statistical Machine Translation in Almost Linear Time
 in: Proceedings of HLT-NAACL 23. Edmonton, Canada, May 27 June 1, 23. This version was produced on April 2, 23. Greedy Decoding for Statistical Machine Translation in Almost Linear Time Ulrich Germann
in: Proceedings of HLT-NAACL 23. Edmonton, Canada, May 27 June 1, 23. This version was produced on April 2, 23. Greedy Decoding for Statistical Machine Translation in Almost Linear Time Ulrich Germann
The RWTH Aachen University English-German and German-English Machine Translation System for WMT 2017
 The RWTH Aachen University English-German and German-English Machine Translation System for WMT 2017 Jan-Thorsten Peter, Andreas Guta, Tamer Alkhouli, Parnia Bahar, Jan Rosendahl, Nick Rossenbach, Miguel
The RWTH Aachen University English-German and German-English Machine Translation System for WMT 2017 Jan-Thorsten Peter, Andreas Guta, Tamer Alkhouli, Parnia Bahar, Jan Rosendahl, Nick Rossenbach, Miguel
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
arxiv: v2 [cs.cl] 18 Nov 2015
![arxiv: v2 [cs.cl] 18 Nov 2015](/thumbs/71/65547585.jpg "arxiv: v2 [cs.cl] 18 Nov 2015") MULTILINGUAL IMAGE DESCRIPTION WITH NEURAL SEQUENCE MODELS Desmond Elliott ILLC, University of Amsterdam; Centrum Wiskunde & Informatica d.elliott@uva.nl arxiv:1510.04709v2 [cs.cl] 18 Nov 2015 Stella Frank
MULTILINGUAL IMAGE DESCRIPTION WITH NEURAL SEQUENCE MODELS Desmond Elliott ILLC, University of Amsterdam; Centrum Wiskunde & Informatica d.elliott@uva.nl arxiv:1510.04709v2 [cs.cl] 18 Nov 2015 Stella Frank
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Introducing the New Iowa Assessments Mathematics Levels 12 14
 Introducing the New Iowa Assessments Mathematics Levels 12 14 ITP Assessment Tools Math Interim Assessments: Grades 3 8 Administered online Constructed Response Supplements Reading, Language Arts, Mathematics
Introducing the New Iowa Assessments Mathematics Levels 12 14 ITP Assessment Tools Math Interim Assessments: Grades 3 8 Administered online Constructed Response Supplements Reading, Language Arts, Mathematics
Semantic and Context-aware Linguistic Model for Bias Detection
 Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
Human-like Natural Language Generation Using Monte Carlo Tree Search
 Human-like Natural Language Generation Using Monte Carlo Tree Search Kaori Kumagai Ichiro Kobayashi Daichi Mochihashi Ochanomizu University The Institute of Statistical Mathematics {kaori.kumagai,koba}@is.ocha.ac.jp
Human-like Natural Language Generation Using Monte Carlo Tree Search Kaori Kumagai Ichiro Kobayashi Daichi Mochihashi Ochanomizu University The Institute of Statistical Mathematics {kaori.kumagai,koba}@is.ocha.ac.jp
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
arxiv: v5 [cs.ai] 18 Aug 2015
![arxiv: v5 [cs.ai] 18 Aug 2015](/thumbs/71/66241401.jpg "arxiv: v5 [cs.ai] 18 Aug 2015") When Are Tree Structures Necessary for Deep Learning of Representations? Jiwei Li 1, Minh-Thang Luong 1, Dan Jurafsky 1 and Eduard Hovy 2 1 Computer Science Department, Stanford University, Stanford, CA
When Are Tree Structures Necessary for Deep Learning of Representations? Jiwei Li 1, Minh-Thang Luong 1, Dan Jurafsky 1 and Eduard Hovy 2 1 Computer Science Department, Stanford University, Stanford, CA
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX,
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY
 MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
arxiv: v2 [cs.cl] 26 Mar 2015
![arxiv: v2 [cs.cl] 26 Mar 2015](/thumbs/71/65580310.jpg "arxiv: v2 [cs.cl] 26 Mar 2015") Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
J j W w. Write. Name. Max Takes the Train. Handwriting Letters Jj, Ww: Words with j, w 321
 Write J j W w Jen Will Directions Have children write a row of each letter and then write the words. Home Activity Ask your child to write each letter and tell you how to make the letter. Handwriting Letters
Write J j W w Jen Will Directions Have children write a row of each letter and then write the words. Home Activity Ask your child to write each letter and tell you how to make the letter. Handwriting Letters
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each