Munich AUtomatic Segmentation (MAUS)
|
|
|
- Claribel Parker
- 6 years ago
- Views:
Transcription
1
2 Munich AUtomatic Segmentation (MAUS) Phonemic Segmentation and Labeling using the MAUS Technique F. Schiel with contributions of A. Kipp, Th. Kisler Bavarian Archive for Speech Signals Institute of Phonetics and Speech Processing Ludwig-Maximilians-Universität München, Germany
3 Overview university-logo Super Pronunciation Model : Building the Automaton Pronunciation Model : From Automaton to Markov Model MAUS Web Application MAUS Web Services
4 Let Ψ be all possible Segmentation & Labeling (S&L) for a given utterance. Then the search for best S&L ˆK is: ˆK = argmax K Ψ P(K o) = argmax K Ψ P(K )p(o K ) p(o) with o the acoustic observation of the signal. Since p(o) = const for all K this simplifies to: ˆK = argmax K Ψ P(K )p(o K ) with: P(K ) = apriori probability for a label sequence, p(o K ) = the acoustical probability of o given K (often modeled by a concatenation of HMMs) university-logo
5 S&L approaches differ in creating Ψ and modeling P(K ) For example: forced alignment Ψ = 1 and P(K ) = 1 hence only p(o K ) is maximized. Other ways to model Ψ and P(K ): phonological rules resulting in M variants with P(K ) = 1 M phonotactic n-grams lexicon of pronunciation variants Markov process (MAUS) university-logo
6 university-logo
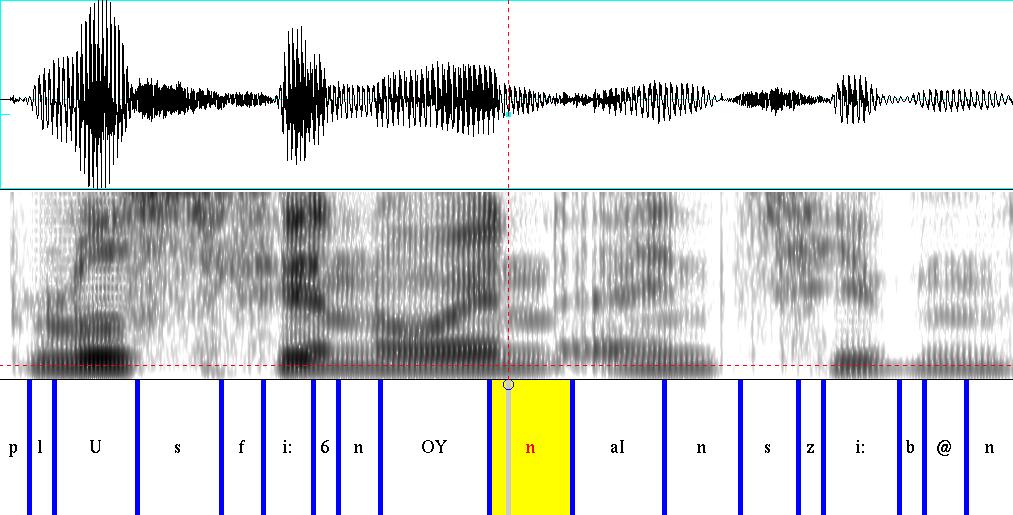
7 university-logo
8 Building the Automaton Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model Start with the orthographic transcript: heute Abend By applying lexicon-lookup and/or a test-to-phoneme algorithm produce a (more or less standardized) citation form in SAM-PA: hoyt@?a:b@nt Add word boundary symbols #, form a linear automaton G c :
9 Building the Automaton Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model Extend automaton G c by applying a set of substitution rules q k where each q k = (a, b, l, r) with a : pattern string b : replacement string l : left context string r : right context string For example the rules (/@n/,/m/,/b/,/t) and (/b@n/,/m/,/a:/,/t/) generate the reduced/assimilated pronunciation forms /?a:bmt/ and /?a:mt/ from the canonical pronunciation /?a:b@nt/ (evening) university-logo
10 Building the Automaton Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model Applying the two rules to G c results in the automaton:
11 From Automaton to Markov Process Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model Add transition probabilities to the arcs of G(N, A) Case 1 : all paths through G(N, A) are of equal probability Not trivial since paths can have different lengths! Transition probability from node d i to node d j : P(d j d i ) = P(d j)n(d i ) P(d i )N(d j ) N(d i ) : number of paths ending in node d i P(d i ) : probability that node d i is part of a path N(d i ) and P(d i ) can be calculated recursively through G(N, A) (see Kipp, 1998 for details). university-logo
12 From Automaton to Markov Process Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model Example: Markov process with 4 possible paths of different length Total probabilities: = = = = 1 4
13 From Automaton to Markov Process Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model Case 2 : all paths through G(N, A) have a probability according to the individual rule probabilities along the path through G(N, A) Again not trivial, since contexts of different rule applications may overlap! This may cause total branching probabilities > 1 Please refer to Kipp, 1998 for details to calculate correct transition probabilities.
14 Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model From Markov Process to Hidden Markov Model True HMM : add emission probabilities to nodes N of G c. -> Replace the phonemic symbols in N by mono-phone HMM. The search lattice for previous example:
15 Building the Automaton From Automaton to Markov Process From Markov Process to Hidden Markov Model From Markov Process to Hidden Markov Model Word boundary nodes # are replaced by a optional silence model: Possible silence intervals between words can be modeled.
16 Evaluation of Label Sequence Evaluation of Segmentation How to evaluate a S&L system? Required: reference corpus with hand-crafted S&L ( gold standard ). Usually two steps: 1 Evaluate the accuracy of the label sequence (transcript) 2 Evaluate the accuracy of segment boundaries
17 Evaluation of Label Sequence Evaluation of Label Sequence Evaluation of Segmentation Often used for label sequence evaluation: Cohen s κ κ = amount of overlap between two transcripts (system vs. gold standard); independent of the symbol set size (Cohen 1960). We consider κ not appropriate for S&L evaluation, since no gold standard exists in phonemic S&L different symbol set sizes do not matter in S&L the task difficulty is not considered (e.g. read vs. spontaneous speech)
18 Evaluation of Label Sequence Evaluation of Label Sequence Evaluation of Segmentation Proposal: Relative Symmetric Accuracy (RSA) = = the ratio from average symmetric system-to-labeler agreement ŜA hs to average inter-labeler agreement ŜA hh. RSA = ŜA hs ŜA hh 100%
19 Evaluation of Label Sequence Evaluation of Label Sequence Evaluation of Segmentation German MAUS: 3 human labelers spontaneous speech (Verbmobil) 9587 phonemic segments Average system - labeler agreement Average inter - labeler agreement Relative symmetric accurarcy ŜA hs = 81.85% ŜA hh = 84.01% RSA = 97.43%
20 Evaluation of Segmentation Evaluation of Label Sequence Evaluation of Segmentation No standardized methodology Problem: insertions and deletions Solution: compare only matching segments Often: count boundary deviations greater than threshold (e.g. 20msec) as errors Better: deviation histogram measured against all human segmenters

21 Evaluation of Segmentation Evaluation of Label Sequence Evaluation of Segmentation German MAUS: Note: center shift typical for HMM alignment
22 WebMAUS MAUS Web Services MAUS software package: ftp://ftp.bas.uni-muenchen.de/pub/bas/softw/maus MAUS package consists of basis script maus corpus processor maus.corpus adaptive maus maus.iter chunk segmentation processor maus.trn helper programs: visualization, graph generator etc. parameter sets for supported languages test benchmarks university-logo
23 Software Package MAUS WebMAUS MAUS Web Services MAUS installation requires: UNIX System V or cygwin Gnu C compiler HTK (University of Cambridge) awk,sox Current language support: deu, eng, ita, aus (with pronunciation modelling) hun, ekk, por, spa, nld, sampa (without modelling) maus BPF=file.par \ SIGNAL=file.wav LANGUAGE=eng \ OUT=file.TextGrid OUTFORMAT=TextGrid university-logo
24 WebMAUS MAUS Web Services How to adapt MAUS to a new language? Several possible ways (in ascending performance and effort): Use SAM-PA language (collective MAUS phoneme set). No pronunciation modelling possible. Effort: nil Performance: for some languages surprisingly good.
25 WebMAUS MAUS Web Services Hand craft pronunciation rules (depending on language not more than 10-20) and run MAUS in the manual rule set mode. Effort: small Performance: Very much dependent of the language, the type of speech, the speakers etc. Adapt HMM to a corpus of the new language using an iterative training schema (script maus.iter). Corpus does not need to be annotated. Effort: moderate (if corpus is available) Performance: For most languages very good, depending on the adaptation corpus (size, quality, match to target language etc.) university-logo
26 WebMAUS MAUS Web Services Retrieve statistically weighted pronunciation rules from a corpus. The corpus needs to be at least of 1 hour length and segmented/labeled manually. Effort: high. Performance: Unknown.
27 MAUS Web Interface WebMAUS MAUS Web Services WebMAUS: web interface to the latest version of MAUS Pros: no local installation necessary runs on all platforms (even SmartPhones) text-normalization and text-to-phoneme (partially) Cons: no adaptation to new languages no application of proprietary rule sets no iterative adaptation mode
28 WebMAUS Basic WebMAUS MAUS Web Services WebMAUS Basic : Signal + Text -> Segmentation simple, robust includes text-normalisation, tokenization and text-to-phoneme conversion no control of parameters or input (except language) supported languages: deu, hun, eng, nld, ita supported output: TextGrid (praat) SIGNAL TXT normalisation tokenization text to phoneme (Balloon) MAUS TextGrid
29 WebMAUS General WebMAUS MAUS Web Services WebMAUS General : Signal + Phonology -> Segmentation full control of all MAUS options phonologic input allows fine tuning requires input in BAS Partitur Format (BPF) supported output BPF, TextGrid, Emu supported languages: deu, eng, ita, aus, hun, ekk, por, spa, nld, sampa
30 WebMAUS Multiple WebMAUS MAUS Web Services WebMAUS Multiple : Signals + Texts -> Segmentations drag & drop of input files features like WebMAUS Basic batch processing of unlimited file pairs
31 MAUS Web Services WebMAUS MAUS Web Services web service = direct call to a server MAUS web services can be used within programming languages or scripts or from the command line, e.g.: curl -v -X POST -H content-type: multipart/form-data \ -F LANGUAGE=deu -F TEXT=@file.txt -F SIGNAL=@file.wav \ BASWebServices/services/runMAUSBasic To get started call: curl -X GET \ university-logo
32 MAUS Web Services WebMAUS MAUS Web Services script maus.web = CSH wrapper to web service calls The script maus.web (in MAUS package) can be used like the original maus script, but issues web service calls. maus.web BPF=file.par \ SIGNAL=file.wav LANGUAGE=eng \ OUT=file.TextGrid OUTFORMAT=TextGrid
33 References WebMAUS MAUS Web Services Kipp A (1998): Automatische Segmentierung und Etikettierung von Spontansprache. Doctoral Thesis, Technical University Munich. Wester M, Kessens J M, Strik H (1998): Improving the performance of a Dutch CSR by modeling pronunciation variation. Workshop on Modeling Pronunciation Variation, Rolduc, Netherlands, pp Kipp A, Wesenick M B, Schiel F (1996): Automatic Detection and Segmentation of Pronunciation Variants in German Speech Corpora. Proceedings of the ICSLP, Philadelphia, pp Schiel F (1999) Automatic Phonetic Transcription of Non-Prompted Speech. Proceedings of the ICPhS, San Francisco, August pp MAUS: ftp://ftp.bas.uni-muenchen.de/pub/bas/softw/maus Draxler Chr, Jänsch K (2008): WikiSpeech A Content Management System for Speech Databases. Proceedings of Interspeech Brisbane, Australia, pp CLARIN: Cohen J (1960): A coefficient of agreement for nominal scales. Educational and Psychological Measurement 20 (1): Fleiss J L (1971): Measuring nominal scale agreement among many raters. Psychological Bulletin, Vol. 76, No. 5 pp Kisler T, Schiel F, Sloetjes H (2012): Signal processing via web services: the use case WebMAUS. In: Proceedings Digital Humanities 2012, Hamburg, Germany, pp
34 Questions? WebMAUS MAUS Web Services
Multi-Tier Annotations in the Verbmobil Corpus
 Multi-Tier Annotations in the Verbmobil Corpus Karl Weilhammer, Uwe Reichel, Florian Schiel Institut für Phonetik und Sprachliche Kommunikation Ludwig-Maximilians-Universität München Schellingstr 3, 80799
Multi-Tier Annotations in the Verbmobil Corpus Karl Weilhammer, Uwe Reichel, Florian Schiel Institut für Phonetik und Sprachliche Kommunikation Ludwig-Maximilians-Universität München Schellingstr 3, 80799
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
PRAAT ON THE WEB AN UPGRADE OF PRAAT FOR SEMI-AUTOMATIC SPEECH ANNOTATION
 PRAAT ON THE WEB AN UPGRADE OF PRAAT FOR SEMI-AUTOMATIC SPEECH ANNOTATION SUMMARY 1. Motivation 2. Praat Software & Format 3. Extended Praat 4. Prosody Tagger 5. Demo 6. Conclusions What s the story behind?
PRAAT ON THE WEB AN UPGRADE OF PRAAT FOR SEMI-AUTOMATIC SPEECH ANNOTATION SUMMARY 1. Motivation 2. Praat Software & Format 3. Extended Praat 4. Prosody Tagger 5. Demo 6. Conclusions What s the story behind?
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Letter-based speech synthesis
 Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR
 COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR ROLAND HAUSSER Institut für Deutsche Philologie Ludwig-Maximilians Universität München München, West Germany 1. CHOICE OF A PRIMITIVE OPERATION The
COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR ROLAND HAUSSER Institut für Deutsche Philologie Ludwig-Maximilians Universität München München, West Germany 1. CHOICE OF A PRIMITIVE OPERATION The
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches
 NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
THE ROLE OF TOOL AND TEACHER MEDIATIONS IN THE CONSTRUCTION OF MEANINGS FOR REFLECTION
 THE ROLE OF TOOL AND TEACHER MEDIATIONS IN THE CONSTRUCTION OF MEANINGS FOR REFLECTION Lulu Healy Programa de Estudos Pós-Graduados em Educação Matemática, PUC, São Paulo ABSTRACT This article reports
THE ROLE OF TOOL AND TEACHER MEDIATIONS IN THE CONSTRUCTION OF MEANINGS FOR REFLECTION Lulu Healy Programa de Estudos Pós-Graduados em Educação Matemática, PUC, São Paulo ABSTRACT This article reports
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
The IFA Corpus: a Phonemically Segmented Dutch "Open Source" Speech Database
 The IFA Corpus: a Phonemically Segmented Dutch "Open Source" Speech Database R.J.J.H. van Son 1, Diana Binnenpoorte 2, Henk van den Heuvel 2, and Louis C.W. Pols 1 1 Institute of Phonetic Sciences (IFA)
The IFA Corpus: a Phonemically Segmented Dutch "Open Source" Speech Database R.J.J.H. van Son 1, Diana Binnenpoorte 2, Henk van den Heuvel 2, and Louis C.W. Pols 1 1 Institute of Phonetic Sciences (IFA)
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE. Pierre Foy
 TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Bi-Annual Status Report For. Improved Monosyllabic Word Modeling on SWITCHBOARD
 INSTITUTE FOR SIGNAL AND INFORMATION PROCESSING Bi-Annual Status Report For Improved Monosyllabic Word Modeling on SWITCHBOARD submitted by: J. Hamaker, N. Deshmukh, A. Ganapathiraju, and J. Picone Institute
INSTITUTE FOR SIGNAL AND INFORMATION PROCESSING Bi-Annual Status Report For Improved Monosyllabic Word Modeling on SWITCHBOARD submitted by: J. Hamaker, N. Deshmukh, A. Ganapathiraju, and J. Picone Institute
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES MODELING IMPROVED AMHARIC SYLLBIFICATION ALGORITHM
 ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES MODELING IMPROVED AMHARIC SYLLBIFICATION ALGORITHM BY NIRAYO HAILU GEBREEGZIABHER A THESIS SUBMITED TO THE SCHOOL OF GRADUATE STUDIES OF ADDIS ABABA UNIVERSITY
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES MODELING IMPROVED AMHARIC SYLLBIFICATION ALGORITHM BY NIRAYO HAILU GEBREEGZIABHER A THESIS SUBMITED TO THE SCHOOL OF GRADUATE STUDIES OF ADDIS ABABA UNIVERSITY
Journal of Phonetics
 Journal of Phonetics 40 (2012) 595 607 Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics How linguistic and probabilistic properties
Journal of Phonetics 40 (2012) 595 607 Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics How linguistic and probabilistic properties
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Achim Stein: Diachronic Corpora Aston Corpus Summer School 2011
 Achim Stein: Diachronic Corpora Aston Corpus Summer School 2011 Achim Stein achim.stein@ling.uni-stuttgart.de Institut für Linguistik/Romanistik Universität Stuttgart 2nd of August, 2011 1 Installation
Achim Stein: Diachronic Corpora Aston Corpus Summer School 2011 Achim Stein achim.stein@ling.uni-stuttgart.de Institut für Linguistik/Romanistik Universität Stuttgart 2nd of August, 2011 1 Installation
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
REVIEW OF CONNECTED SPEECH
 Language Learning & Technology http://llt.msu.edu/vol8num1/review2/ January 2004, Volume 8, Number 1 pp. 24-28 REVIEW OF CONNECTED SPEECH Title Connected Speech (North American English), 2000 Platform
Language Learning & Technology http://llt.msu.edu/vol8num1/review2/ January 2004, Volume 8, Number 1 pp. 24-28 REVIEW OF CONNECTED SPEECH Title Connected Speech (North American English), 2000 Platform
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Generating Test Cases From Use Cases
 1 of 13 1/10/2007 10:41 AM Generating Test Cases From Use Cases by Jim Heumann Requirements Management Evangelist Rational Software pdf (155 K) In many organizations, software testing accounts for 30 to
1 of 13 1/10/2007 10:41 AM Generating Test Cases From Use Cases by Jim Heumann Requirements Management Evangelist Rational Software pdf (155 K) In many organizations, software testing accounts for 30 to
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence
 A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
Using AMT & SNOMED CT-AU to support clinical research
 Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Evaluation of a Simultaneous Interpretation System and Analysis of Speech Log for User Experience Assessment
 Evaluation of a Simultaneous Interpretation System and Analysis of Speech Log for User Experience Assessment Akiko Sakamoto, Kazuhiko Abe, Kazuo Sumita and Satoshi Kamatani Knowledge Media Laboratory,
Evaluation of a Simultaneous Interpretation System and Analysis of Speech Log for User Experience Assessment Akiko Sakamoto, Kazuhiko Abe, Kazuo Sumita and Satoshi Kamatani Knowledge Media Laboratory,
Universal contrastive analysis as a learning principle in CAPT
 Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
GACE Computer Science Assessment Test at a Glance
 GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Writing a Basic Assessment Report. CUNY Office of Undergraduate Studies
 Writing a Basic Assessment Report What is a Basic Assessment Report? A basic assessment report is useful when assessing selected Common Core SLOs across a set of single courses A basic assessment report
Writing a Basic Assessment Report What is a Basic Assessment Report? A basic assessment report is useful when assessing selected Common Core SLOs across a set of single courses A basic assessment report
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question.
 Ch 2 Test Remediation Work Name MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. Provide an appropriate response. 1) High temperatures in a certain
Ch 2 Test Remediation Work Name MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. Provide an appropriate response. 1) High temperatures in a certain
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES. Judith Gaspers and Philipp Cimiano
 LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES Judith Gaspers and Philipp Cimiano Semantic Computing Group, CITEC, Bielefeld University {jgaspers cimiano}@cit-ec.uni-bielefeld.de ABSTRACT Semantic parsers
LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES Judith Gaspers and Philipp Cimiano Semantic Computing Group, CITEC, Bielefeld University {jgaspers cimiano}@cit-ec.uni-bielefeld.de ABSTRACT Semantic parsers
On-the-Fly Customization of Automated Essay Scoring
 Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
A Coding System for Dynamic Topic Analysis: A Computer-Mediated Discourse Analysis Technique
 A Coding System for Dynamic Topic Analysis: A Computer-Mediated Discourse Analysis Technique Hiromi Ishizaki 1, Susan C. Herring 2, Yasuhiro Takishima 1 1 KDDI R&D Laboratories, Inc. 2 Indiana University
A Coding System for Dynamic Topic Analysis: A Computer-Mediated Discourse Analysis Technique Hiromi Ishizaki 1, Susan C. Herring 2, Yasuhiro Takishima 1 1 KDDI R&D Laboratories, Inc. 2 Indiana University
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Eyebrows in French talk-in-interaction
 Eyebrows in French talk-in-interaction Aurélie Goujon 1, Roxane Bertrand 1, Marion Tellier 1 1 Aix Marseille Université, CNRS, LPL UMR 7309, 13100, Aix-en-Provence, France Goujon.aurelie@gmail.com Roxane.bertrand@lpl-aix.fr
Eyebrows in French talk-in-interaction Aurélie Goujon 1, Roxane Bertrand 1, Marion Tellier 1 1 Aix Marseille Université, CNRS, LPL UMR 7309, 13100, Aix-en-Provence, France Goujon.aurelie@gmail.com Roxane.bertrand@lpl-aix.fr
Spoken Language Parsing Using Phrase-Level Grammars and Trainable Classifiers
 Spoken Language Parsing Using Phrase-Level Grammars and Trainable Classifiers Chad Langley, Alon Lavie, Lori Levin, Dorcas Wallace, Donna Gates, and Kay Peterson Language Technologies Institute Carnegie
Spoken Language Parsing Using Phrase-Level Grammars and Trainable Classifiers Chad Langley, Alon Lavie, Lori Levin, Dorcas Wallace, Donna Gates, and Kay Peterson Language Technologies Institute Carnegie
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company
 Houghton Mifflin Harcourt Publishing Company") WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Florida Reading Endorsement Alignment Matrix Competency 1
 Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending