Transfer Learning with Applications
|
|
|
- Silvester Long
- 6 years ago
- Views:
Transcription
1 Transfer Learning with Applications Sinno Jialin Pan 1, Qiang Yang 2,3 and Wei Fan 3 1 Institute for Infocomm Research, Singapore 2 Hong Kong University of Science and Technology 3 Huawei Noah's Ark Research Lab, Hong Kong
2 Outline Part I: An overview of transfer learning (Sinno J. Pan) Part II: Transfer learning applications (Prof. Qiang Yang) Part III: Advanced research topics: heterogeneous transfer learning (Wei Fan) 2

 Lab Head, Text")

3 Transfer Learning Overview Sinno Jialin Pan (Ph.D.) Lab Head, Text Analytics, Data Analytics Department, Institute for Infocomm Research (I2R), Singapore
4 Transfer of Learning A psychological point of view The study of dependency of human conduct, learning or performance on prior experience. [Thorndike and Woodworth, 1901] explored how individuals would transfer in one context to another context that share similar characteristics. C++ Java Maths/Physics Computer Science/Economics 2
5 Transfer Learning In the machine learning community The ability of a system to recognize and apply knowledge and skills learned in previous domains/tasks to novel tasks/domains, which share some commonality. Given a target domain/task, how to identify the commonality between the domain/task and previous domains/tasks, and transfer knowledge from the previous domains/tasks to the target one? 3
6 Transfer Learning Traditional Machine Learning Transfer Learning training domains test domains training items test items domain A domain B domain C 4
7 Transfer Learning Different fields Transfer learning for reinforcement learning. Transfer learning for classification, and regression problems. Focus! [Taylor and Stone, Transfer Learning for Reinforcement Learning Domains: A Survey, JMLR 2009] [Pan and Yang, A Survey on Transfer Learning, IEEE TKDE 2010] 5

8 Motivating Example I: Indoor WiFi localization -30dBm -70dBm -40dBm 6
9 Indoor WiFi Localization (cont.) Training Test Average Error Distance S=(-37dbm,.., -77dbm), L=(1, 3) S=(-41dbm,.., -83dbm), L=(1, 4) S=(-49dbm,.., -34dbm), L=(9, 10) S=(-61dbm,.., -28dbm), L=(15,22) Localization model S=(-37dbm,.., -77dbm) S=(-41dbm,.., -83dbm) S=(-49dbm,.., -34dbm) S=(-61dbm,.., -28dbm) ~ 1.5 meters Device A Device A Drop! Training Test S=(-33dbm,.., -82dbm), L=(1, 3) S=(-57dbm,.., -63dbm), L=(10, 23) Localization model S=(-37dbm,.., -77dbm) S=(-41dbm,.., -83dbm) S=(-49dbm,.., -34dbm) S=(-61dbm,.., -28dbm) ~10 meters Device B Device A 7
10 Difference between Domains Time Period A Time Period B Device A Device B 8



11 Motivating Example II: Sentiment classification 9
12 Sentiment Classification (cont.) Training Sentiment Classifier Test Classification Accuracy ~ 84.6% Electronics Electronics Drop! Training Sentiment Classifier Test ~72.65% DVD Electronics 10
13 Difference between Domains Electronics (1) Compact; easy to operate; very good picture quality; looks sharp! (3) I purchased this unit from Circuit City and I was very excited about the quality of the picture. It is really nice and sharp. (5) It is also quite blurry in very dark settings. I will never buy HP again. Video Games (2) A very good game! It is action packed and full of excitement. I am very much hooked on this game. (4) Very realistic shooting action and good plots. We played this and were hooked. (6) The game is so boring. I am extremely unhappy and will probably never buy UbiSoft again. 11
14 A Major Assumption in Traditional Machine Learning Training and future (test) data come from the same domain, which implies Represented in the same feature spaces. Follow the same data distribution. 12
15 In Real-world Applications Training and testing data may come from different domains, which have: Different marginal distributions, or different feature spaces: Different predictive distributions, or different label spaces: 13
16 How to Build Systems on Each Domain of Interest Build every system from scratch? Time consuming and expensive! Reuse common knowledge extracted from existing systems? More practical! 14


17 The Goal of Transfer Learning Labeled Training Source Domain Data Transfer Learning Algorithms Predictive Models Electronics Time Period A Device A Target Domain Data Unlabeled data/a few labeled data for adaptation Target Domain Data Testing Time Period B Device B DVD 15
18 Transfer Learning Settings Heterogeneous Transfer Learning Transfer Learning Heterogeneous Feature Space Homogeneous Supervised Transfer Learning Semi-Supervised Transfer Learning Unsupervised Transfer Learning Homogeneous Transfer Learning 16
19 Transfer Learning Approaches Instance-based Approaches Feature-based Approaches Parameter-based Approaches Relational Approaches 17
20 Instance-based Transfer Learning Approaches General Assumption Source and target domains have a lot of overlapping features (domains share the same/similar support) 18
21 Instance-based Transfer Learning Approaches Case I Problem Setting Case II Problem Setting Assumption Assumption 19
22 Instance-based Approaches Case I Given a target task, 20
23 Instance-based Approaches Case I (cont.) 21
24 Instance-based Approaches Case I (cont.) Assumption: 22
 Correcting Sample Selection Bias /")

25 Instance-based Approaches Case I (cont.) Correcting Sample Selection Bias / Covariate Shift [Quionero-Candela, etal, Data Shift in Machine Learning, MIT Press 2009] 23
26 Instance-based Approaches Correcting sample selection bias Imagine a rejection sampling process, and view the source domain as samples from the target domain Assumption: sample selection bias is caused by the data generation process 24
27 Instance-based Approaches Correcting sample selection bias (cont.) The distribution of the selector variable maps the target onto the source distribution [Zadrozny, ICML-04] Label instances from the source domain with label 1 Label instances from the target domain with label 0 Train a binary classifier 25
28 Instance-based Approaches Kernel mean matching (KMM) Maximum Mean Discrepancy (MMD) [Alex Smola, Arthur Gretton and Kenji Kukumizu, ICML-08 tutorial] 26
29 Instance-based Approaches Kernel mean matching (KMM) (cont.) [Huang etal., NIPS-06] 27
30 Instance-based Approaches Direct density ratio estimation [Sugiyama etal., NIPS-07, Kanamori etal., JMLR-09] KL divergence loss Least squared loss [Sugiyama etal., NIPS-07] [Kanamori etal., JMLR-09] 28
31 Instance-based Approaches Case II Intuition: Part of the labeled data in the source domain can be reused in the target domain after re-weighting 29
32 Instance-based Approaches Case II (cont.) TrAdaBoost [Dai etal ICML-07] For each boosting iteration, Use the same strategy as AdaBoost to update the weights of target domain data. Use a new mechanism to decrease the weights of misclassified source domain data. 30
33 Feature-based Transfer Learning Approaches When source and target domains only have some overlapping features. (lots of features only have support in either the source or the target domain) 31
34 Feature-based Transfer Learning Approaches (cont.) How to learn? Solution 1: Encode application-specific knowledge to learn the transformation. Solution 2: General approaches to learning the transformation. 32
35 Feature-based Approaches Encode application-specific knowledge Electronics (1) Compact; easy to operate; very good picture quality; looks sharp! (3) I purchased this unit from Circuit City and I was very excited about the quality of the picture. It is really nice and sharp. (5) It is also quite blurry in very dark settings. I will never_buy HP again. Video Games (2) A very good game! It is action packed and full of excitement. I am very much hooked on this game. (4) Very realistic shooting action and good plots. We played this and were hooked. (6) The game is so boring. I am extremely unhappy and will probably never_buy UbiSoft again. 33
36 Feature-based Approaches Encode application-specific knowledge (cont.) Electronics compact sharp blurry hooked realistic boring Video Game Training T y = f( x) = sgn( w x ), w= [1,1, 1, 0, 0, 0] Prediction compact sharp blurry hooked realistic boring
37 Feature-based Approaches Encode application-specific knowledge (cont.) Electronics (1) Compact; easy to operate; very good picture quality; looks sharp! (3) I purchased this unit from Circuit City and I was very excited about the quality of the picture. It is really nice and sharp. (5) It is also quite blurry in very dark settings. I will never_buy HP again. Video Games (2) A very good game! It is action packed and full of excitement. I am very much hooked on this game. (4) Very realistic shooting action and good plots. We played this and were hooked. (6) The game is so boring. I am extremely unhappy and will probably never_buy UbiSoft again. 35
38 Feature-based Approaches Encode application-specific knowledge (cont.) Three different types of features Source domain (Electronics) specific features, e.g., compact, sharp, blurry Target domain (Video Game) specific features, e.g., hooked, realistic, boring Domain independent features (pivot features), e.g., good, excited, nice, never_buy 36
39 Feature-based Approaches Encode application-specific knowledge (cont.) How to identify pivot features? Term frequency on both domains Mutual information between features and labels (source domain) Mutual information on between features and domains How to utilize pivots to align features across domains? Structural Correspondence Learning (SCL) [Biltzer etal. EMNLP-06] Spectral Feature Alignment (SFA) [Pan etal. WWW-10] 37
40 Feature-based Approaches Structural Correspondence Learning (SCL) Intuition Use pivot features to construct pseudo tasks that related to target classification task Model correlations between pivot features and other features using multi-task learning techniques Discover new shared features by exploiting the feature correlations 38
41 Structural Correspondence Learning Algorithm Identify P pivot features Build P classifiers to predict the pivot features from remaining features Discover shared feature subspace Compute top K eigenvectors Project original features into eigenvectors to derive new shared features Train classifiers on the source using augmented features (original features + new features) 39
42 Feature-based Approaches Spectral Feature Alignment (SFA) Intuition Use a bipartite graph to model the correlations between pivot features and other features Discover new shared features by applying spectral clustering techniques on the graph 40
43 Spectral Feature Alignment (SFA) High level idea Domain-specific features Pivot features exciting 6 good never_buy realistic compact 8 hooked sharp blurry boring Electronics Video Game If two domain-specific words have connections to more common pivot words in the graph, they tend to be aligned or clustered together with a higher probability. If two pivot words have connections to more common domain-specific words in the graph, they tend to be aligned together with a higher probability. 41
44 Derive new features Domain-specific features Pivot features 7 exciting 6 good 2 never_buy Spectral Clustering realistic compact 8 hooked sharp blurry boring Electronics Video Game Video Game boring blurry compact realistic Electronics Electronics Electronics sharp hooked Video Game Video Game 42
45 Spectral Feature Alignment (SFA) Derive new features (cont.) Electronics sharp/hooked compact/realistic blurry/boring Video Game Training T y = f( x) = sgn( w x ), w= [1,1, 1] Prediction sharp/hooked compact/realistic blurry/boring
46 Spectral Feature Alignment (SFA) Algorithm Identify P pivot features Construct a bipartite graph between the pivot and remaining features. Apply spectral clustering on the graph to derive new features Train classifiers on the source using augmented features (original features + new features) 44
47 Feature-based Approaches Develop general approaches Time Period A Time Period B Device A Device B 45
48 Feature-based Approaches General approaches Learning features by minimizing distance between distributions Learning features inspired by multi-task learning Learning features inspired by self-taught learning 46
49 Feature-based Approaches Transfer Component Analysis [Pan etal., IJCAI-09, TNN-11] Motivation Source Target Latent factors Temperature Signal properties Power of APs Building structure 47
50 Transfer Component Analysis (cont.) Source Target Latent factors Temperature Signal properties Power of APs Building structure Cause the data distributions between domains different 48
51 Transfer Component Analysis (cont.) Source Target Noisy component Signal properties Building structure Principal components 49
 Learning by only minimizing distance between distributions may")
52 Transfer Component Analysis (cont.) Learning by only minimizing distance between distributions may map the data onto noisy factors. 50
53 Transfer Component Analysis (cont.) Main idea: the learned should map the source and target domain data to the latent space spanned by the factors which can reduce domain difference and preserve original data structure. High level optimization problem 51
54 Transfer Component Analysis (cont.) Recall: Maximum Mean Discrepancy (MMD) 52
55 Transfer Component Analysis (cont.) 53
56 Transfer Component Analysis (cont.) The kernel function can be a highly nonlinear function of A direct optimization of minimizing the quantity w.r.t. stuck in poor local minima can get 54
57 Transfer Component Analysis (cont.) [Pan etal., AAAI-08] To minimize the distance between domains To maximize the data variance To preserve the local geometric structure It is a SDP problem, expensive! It is transductive, cannot generalize on unseen instances! PCA is post-processed on the learned kernel matrix, which may potentially discard useful information. 55
58 Transfer Component Analysis (cont.) Parametric kernel Minimize distance between domains Regularization term Maximize data variance 56
 An illustrative example Latent features learned by PCA and TCA")
59 Transfer Component Analysis (cont.) An illustrative example Latent features learned by PCA and TCA Original feature space PCA TCA 57
60 Feature-based Approaches Multi-task Feature Learning General Multi-task Learning Setting Assumption: If tasks are related, they should share some good common features. Goal: Learn a low-dimensional representation shared across related tasks. 58
61 Feature-based Approaches Multi-task Feature Learning (cont.) [Argyriou etal., NIPS-07] [Ando and Zhang, JMLR-05] [Ji etal, KDD-08] 59
62 Feature-based Approaches Self-taught Feature Learning Intuition: There exist some higher-level features that can help the target learning task even only a few labeled data are given. Steps: 1) Learn higher-level features from a lot of unlabeled data. 2) Use the learned higher-level features to represent the data of the target task. 3) Training models from the new representations of the target task with corresponding labels. 60
63 Feature-based Approaches Self-taught Feature Learning How to learn higher-level features Sparse Coding [Raina etal., 2007] Deep learning [Glorot etal., 2011] 61
64 Parameter-based Transfer Learning Approaches Tasks are learned independently Motivation: A well-trained model has learned a lot of structure. If two tasks are related, this structure can be transferred to learn. 62
65 Parameter-based Approaches Multi-task Parameter Learning Assumption: If tasks are related, they may share similar parameter vectors. For example, [Evgeniou and Pontil, KDD-04] Common part Specific part for individual task 63
66 Parameter-based Approaches Multi-task Parameter Learning (cont.) A general framework: [Zhang and Yeung, UAI-10] [Agarwal etal, NIPS-10] 64
67 Relational Transfer Learning Approaches Motivation: If two relational domains (data is non-i.i.d) are related, they may share some similar relations among objects. These relations can be used for knowledge transfer across domains. 65
68 Relational Transfer Learning Approaches (cont.) [Mihalkova etal., AAAI-07, Davis and Domingos, ICML-09] Academic domain (source) Movie domain (target) Student (B) AdvisedBy Professor (A) Actor(A) WorkedFor Director(B) Publication Publication MovieMember MovieMember Paper (T) Movie (M) AdvisedBy (B, A) Publication (B, T) => Publication (A, T) WorkedFor (A, B) MovieMember (A, M) => MovieMember (B, M) P1(x, y) P2 (x, z) => P2 (y, z) 66
69 Relational Approaches Relational Adaptive bootstrapping [Li etal., ACL-12] Task: sentiment summarization What is the opinion expressed on? To construct lexicon of topic or target words How is the opinion expressed? To construct lexicon of sentiment words Sentiment lexicon (camera) great, amazing, light recommend, excellent, etc. artifacts, noise, never but, boring, etc. Topic lexicon (camera) camera, product, screen, photo, size, weight, quality, price, memory, etc. 67
70 Relational Approaches Relational Adaptive bootstrapping (RAP) (cont.) Reviews on cameras The camera is great. It is a very amazing product. I highly recommend this camera. Photos had some artifacts and noise. Reviews on movies This movie has good script, great casting, excellent acting. This movie is so boring. The Godfather was the most amazing movie. The movie is excellent. 68
 Bridge between cross-domain sentiment words Domain independent (general)")
71 Relational Approaches RAP (cont.) Bridge between cross-domain sentiment words Domain independent (general) sentiment words Bridge between cross-domain topic words 69
72 Relational Approaches RAP (cont.) Bridge between cross-domain topic words Syntactic structure between topic and sentiment words Sentiment words Topic word Topic word Common syntactic pattern: topic word nsubj sentiment word 70
73 Summary Transfer Learning Heterogeneous Transfer Learning Supervised Transfer Learning Semi-Supervised Transfer Learning Unsupervised Transfer Learning Homogeneous Transfer Learning In model level In data level Instance-based Approaches Feature-based Approaches Relational Approaches Parameter-based Approaches 71
74 Some Advanced Research Issues in Transfer Learning How to transfer knowledge across heterogeneous feature spaces Active learning meets transfer learning Transfer learning from multiple sources 72
75 Reference [Thorndike and Woodworth, The Influence of Improvement in one mental function upon the efficiency of the other functions, 1901] [Taylor and Stone, Transfer Learning for Reinforcement Learning Domains: A Survey, JMLR 2009] [Pan and Yang, A Survey on Transfer Learning, IEEE TKDE 2009] [Quionero-Candela, etal, Data Shift in Machine Learning, MIT Press 2009] [Biltzer etal.. Domain Adaptation with Structural Correspondence Learning, EMNLP 2006] [Pan etal., Cross-Domain Sentiment Classification via Spectral Feature Alignment, WWW 2010] [Pan etal., Transfer Learning via Dimensionality Reduction, AAAI 2008] 73
76 Reference (cont.) [Pan etal., Domain Adaptation via Transfer Component Analysis, IJCAI 2009] [Evgeniou and Pontil, Regularized Multi-Task Learning, KDD 2004] [Zhang and Yeung, A Convex Formulation for Learning Task Relationships in Multi-Task Learning, UAI 2010] [Agarwal etal, Learning Multiple Tasks using Manifold Regularization, NIPS 2010] [Argyriou etal., Multi-Task Feature Learning, NIPS 2007] [Ando and Zhang, A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data, JMLR 2005] [Ji etal, Extracting Shared Subspace for Multi-label Classification, KDD 2008] 74
77 Reference (cont.) [Raina etal., Self-taught Learning: Transfer Learning from Unlabeled Data, ICML 2007] [Dai etal., Boosting for Transfer Learning, ICML 2007] [Glorot etal., Domain Adaptation for Large-Scale Sentiment Classification: A Deep Learning Approach, ICML 2011] [Davis and Domingos, Deep Transfer vis Second-order Markov Logic, ICML 2009] [Mihalkova etal., Mapping and Revising Markov Logic Networks for Transfer Learning, AAAI 2007] [Li etal., Cross-Domain Co-Extraction of Sentiment and Topic Lexicons, ACL 2012] 75
78 Reference (cont.) [Sugiyama etal., Direct Importance Estimation with Model Selection and Its Application to Covariate Shift Adaptation, NIPS 2007] [Kanamori etal., A Least-squares Approach to Direct Importance Estimation, JMLR 2009] [Cristianini etal., On Kernel Target Alignment, NIPS 2002] [Huang etal., Correcting Sample Selection Bias by Unlabeled Data, NIPS 2006] [Zadrozny, Learning and Evaluating Classifiers under Sample Selection Bias, ICML 2004] 76
79 Thank You 77
80 Selected Applications of Transfer Learning Qiang Yang and Sinno J. Pan 2013 PAKDD Tutorial Brisbane, Australia
81 Part I. Cross Domain Transfer Learning for Activity Recognition Vincent W. Zheng, Derek H. Hu and Qiang Yang. Cross-Domain Activity Recognition. In Proceedings of the 11th International Conference on Ubiquitous Computing (Ubicomp-09), Orlando, Florida, USA, Sept.30- Oct.3, Derek Hao Hu, Qiang Yang. Transfer Learning for Activity Recognition via Sensor Mapping. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI-11), Barcelona, Spain, July 2011
82 Demo Annotation 3

83 ehealth Demo Sensor data 4 4

84 ehealth demo Activity annotation 5 5
85 ehealth demo Auto logging / activity recognition (service in background) 6 6
86 Demo Recognition 7

87 ehealth demo Real-time activity recognition 8 8
88 Demo Profiling 9

89 ehealth demo Activity profiling 10 10

90 ehealth demo Activity profiling for health management 11 11
91 Key Problem: Recognizing Actions and Context (Locations) Inferred through AR AR: Activity Recognition via Sensors Walking? Buying Ticket? Open Door? Sightseeing Watch show GPS and Other Sensors Sensors Sensors 12
")

92 1. Cross-Domain Activity Recognition [Zheng, Hu, Yang: UbiComp-2009, PCM-2011] Challenge: Some activities without data (partially labeled) Cross-domain activity recognition Use other activities with available labeled data Happen in kitchen Use cup, pot Making coffee Making tea 13

93 Cleaning Indoor Laundry Dishwashing 14




 = 0.")





94 System Workflow <Sensor Reading, Activity Name> Example: <SS, Make Coffee > Example: sim( Make Coffee, Make Tea ) = 0.6 Similarity Measure Example: Pseudo Training Data: <SS, Make Tea, 0.6> Source Domain Labeled Data THE WEB Target Domain Pseudo Labeled Data Weighted SVM Classifier 15
 Example Mined similarity between the activity sweeping and")
95 Calculating Activity Similarities How similar are two activities? Use Web search results TFIDF: Traditional IR similarity metrics (cosine similarity) Example Mined similarity between the activity sweeping and vacuuming, making the bed, gardening Calculated Similarity with the activity "Sweeping" 16
 [Intille et al.")
96 Datasets: MIT PlaceLab MIT PlaceLab Dataset (PLIA2) [Intille et al. Pervasive 2005] Activities: Common household activities 17

![Philipose, ISWC2005] Activities](/docs-images/71/65619222/images/97-1.jpg "Performed: 11 activities Sensors RFID")

97 Datasets: Intel Research Lab Intel Research Lab [Patterson, Fox, Kautz, Philipose, ISWC2005] Activities Performed: 11 activities Sensors RFID Readers & Tags Length: 10 mornings Picture excerpted from [Patterson, Fox, Kautz, Philipose, ISWC2005]. 18
98 Cross-Domain AR: Performance Intel Research Lab Dataset Accuracy with Cross Domain Transfer # Activities (Source Domain) # Activities (Target Domain) Baseline (Random Guess) Supervised (Upper bound) 63.2% % 78.3% Amsterdam Dataset 65.8% % 72.3% MIT Dataset (Cleaning to Laundry) MIT Dataset (Cleaning to Dishwashing) 58.9% % % % - Activities in the source domain and the target domain are generated from ten random trials, mean accuracies are reported. 19
99 Derek Hao Hu and Qiang Yang, IJCAI 2011 Transferring Across Feature Space Transfer from Source Domain to Target Domain py ( t xt) = pc ( xt) py ( t c) c ( i ) L s Transferring Across Label Space

100 Final goal: Estimate t We have Proposed Approach p( y x t ) Estimating the above equation at its mode: Feature Transfer Label Transfer

![Ubicomp 2008] MIT Placelab (PLIA1)](/docs-images/71/65619222/images/101-1.jpg "dataset [Intille et al.")
![Ubicomp 2006] Intel Research Lab](/docs-images/71/65619222/images/101-3.jpg "dataset [Patterson et al.")
![ISWC 2005] Baseline Unsupervised](/docs-images/71/65619222/images/101-4.jpg "Activity Recognition Algorithm")


101 Datasets Experiments UvA dataset [van Kasteren et al. Ubicomp 2008] MIT Placelab (PLIA1) dataset [Intille et al. Ubicomp 2006] Intel Research Lab dataset [Patterson et al. ISWC 2005] Baseline Unsupervised Activity Recognition Algorithm [Wyatt et al. 2005] Different sensors for different datasets State-based sensors for UvA dataset A series of different wired sensors for MIT dataset RFID sensor for Intel Research Lab Dataset
102 Experiments: Different Feature & Label Spaces Source: MIT PLIA1 dataset Target: UvA (Intel) datasets
103 Part II Source Free Transfer Learning Evan Wei Xiang, Sinno Jialin Pan, Weike Pan, Jian Su and Qiang Yang. Source-Selection-Free Transfer Learning. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence (IJCAI-11), Barcelona, Spain, July 2011.



104 Source-Selection-Free Transfer Learning Evan Xiang, Sinno Pan, Weike Pan, Jian Su, Qiang Yang HKUST - IJCAI
105 Transfer Learning Lack of labeled training data always happens Supervised Learning When we have some related source domains Transfer Learning HKUST - IJCAI

106 Where are the right source data? We may have an extremely large number of choices of potential sources to use. HKUST - IJCAI
107 Outline of Source-Selection-Free Transfer Learning (SSFTL) Stage 1: Building base models Stage 2: Label Bridging via Laplacian Graph Embedding Stage 3: Mapping the target instance using the base classifiers & the projection matrix Stage 4: Learning a matrix W to directly project the target instance to the latent space Stage 5: Making predictions for the incoming test data using W HKUST - IJCAI

108 SSFTL Building base models vs. vs. vs. vs. vs. vs. vs. vs. vs. vs. vs. From the taxonomy of the online information source, we can Compile a lot of base classification models HKUST - IJCAI

![mismatch Neighborhood matrix for label graph M q q Projection matrix V m Bob Tom John Gary Steve q History Travel Finance Tech Sports Laplacian Eigenmap [Belkin & Niyogi,2003] m-dimensional latent](/docs-images/71/65619222/images/109-5.jpg "space Since the label names are usually short and sparse,, in order to uncover the intrinsic relationships between the target and source labels, we turn to some social media such as Delicious, which")
109 vs. vs. vs. SSFTL Label Bridging via Laplacian Graph Embedding Problem However, the label spaces of the based classification models and the target task can be different vs. mismatch vs. vs. Neighborhood matrix for label graph M q q Projection matrix V m Bob Tom John Gary Steve q History Travel Finance Tech Sports Laplacian Eigenmap [Belkin & Niyogi,2003] m-dimensional latent space Since the label names are usually short and sparse,, in order to uncover the intrinsic relationships between the target and source labels, we turn to some social media such as Delicious, which can help to bridge different label sets together. The relationships between labels, e.g., similar or dissimilar, can be represented by the distance between their corresponding prototypes in the latent space, e.g., close to or far away from each other. HKUST - IJCAI
110 SSFTL Mapping the target instance using the base classifiers & the projection matrix V vs. vs. vs. 0.1: : :0.8 vs. vs. 0.6: :0.3 Target Instance Ipad2 is released in March, For each target instance, we can obtain a combined result on the label space via aggregating the predictions from all the base classifiers Then we can use the projection matrix V to transform such combined results from the label space to a latent space Probability Tech Finance Travel History Sports q Projection matrix V m-dimensional latent space = <Z 1, Z 2, Z 3,, Z m > q Label space m However, do we need to recall the base classifiers during the prediction phase? The answer is No! HKUST - IJCAI
111 SSFTL Learning a matrix W to directly project the target instance to the latent space Target Domain Labeled & Unlabeled Data vs. vs. vs. vs. vs. q Projection matrix V m For each target instance, we first aggregate its prediction on the base label space, and then project it onto the latent space Loss on unlabeled data Loss on labeled data Learned Projection matrix Our regression model d W HKUST - IJCAI m

112 SSFTL Making predictions for the incoming test data Target Domain Incoming Test Data Learned Projection matrix d W The learned projection matrix W can be used to transform any target instance directly from the feature space to the latent space m vs. vs. vs. vs. vs. q Projection matrix V m Therefore, we can make prediction directly for any incoming test data based on the distance to the label prototypes, without calling the base classification models HKUST - IJCAI

 Google Snippets (28 tasks) AOL Web queries (126 tasks) AG Reuters corpus (10 tasks) HKUST -")
113 Experiments - Datasets Building Source Classifiers with Wikipedia 3M articles, 500K categories (mirror of Aug 2009) 50, 000 pairs of categories are sampled for source models Building Label Graph with Delicious 800-day historical tagging log (Jan 2005 ~ March 2007) 50M tagging logs of 200K tags on 5M Web pages Benchmark Target Tasks 20 Newsgroups (190 tasks) Google Snippets (28 tasks) AOL Web queries (126 tasks) AG Reuters corpus (10 tasks) HKUST - IJCAI

114 SSFTL - Building base classifiers Parallelly using MapReduce Input Map Reduce vs. vs vs. vs. If we need to build 50,000 base classifiers, it would take about two days if we run the training process on a single server. Therefore, we distributed the training process to a cluster with 30 cores using MapReduce, and finished the training within two hours. The training data are replicated and assigned to different bins 3 In each bin, the training data are paired for building binary base classifiers These pre-trained source base classifiers are stored and reused for different incoming target tasks. HKUST - IJCAI

115 Experiments - Results Unsupervised SSFTL Semi-supervised SSFTL Our regression model -Parameter setttings- Source models: 5,000 Unlabeled target data: 100% lambda_2: 0.01 HKUST - IJCAI

116 Experiments - Results For each target instance, we first aggregate its prediction on the base label space, and then project it onto the latent space Loss on unlabeled data Our regression model -Parameter setttings- Mode: Semi-supervised Labeled target data: 20 Unlabeled target data: 100% lambda_2: 0.01 HKUST - IJCAI

117 Experiments - Results Our regression model -Parameter setttings- Mode: Semi-supervised Labeled target data: 20 Source models: 5,000 lambda_2: 0.01 HKUST - IJCAI

118 Experiments - Results Supervised SSFTL Semi-supervised SSFTL Our regression model -Parameter setttings- Labeled target data: 20 Unlabeled target data: 100% Source models: 5,000 HKUST - IJCAI

119 Experiments - Results For each target instance, we first aggregate its prediction on the base label space, and then project it onto the latent space Loss on unlabeled data Our regression model -Parameter setttings- Mode: Semi-supervised Labeled target data: 20 Source models: 5,000 Unlabeled target data: 100% lambda_2: 0.01 HKUST - IJCAI


120 Related Works HKUST - IJCAI
121 Conclusion Source-Selection-Free Transfer Learning When the potential auxiliary data is embedded in very large online information sources No need for task-specific source-domain data We compile the label sets into a graph Laplacian for automatic label bridging SSFTL is highly scalable Processing of the online information source can be done offline and reused for different tasks. HKUST - IJCAI

122 Q & A HKUST - IJCAI
123 Advance Research Topics in Transfer Learning Wei Fan Huawei Noah's Ark Research Lab, Hong Kong
124 Predictive Modeling with Heterogeneous Sources Xiaoxiao Shi Qi Liu Wei Fan Qiang Yang Philip S. Yu
125 Why learning with heterogeneous sources? Standard Supervised Learning Training (labeled) Test (unlabeled) Classifier 85.5% New York Times New York Times 1/18
126 Why heterogeneous sources? In Reality How to improve the performance? Training (labeled) Test (unlabeled) Labeled data are New insufficient! York Times New York Times 47.3% 2/18
127 Why heterogeneous sources? Labeled data from other sources Target domain test (unlabeled) 82.6% 47.3% Reuters New York Times 1. Different distributions 2. Different outputs 3. Different feature spaces 3/18
128 Real world examples Social Network: Can various bookmarking systems help predict social tags for a new system given that their outputs (social tags) and data (documents) are different? Wikipedia ODP Backflip Blink? 4/18


129 Real world examples Applied Sociology: Can the suburban housing price census data help predict the downtown housing prices?? #rooms #bathrooms #windows price XXX XXX #rooms #bathrooms #windows price XXXXX XXXXX 5/18
130 Other examples Bioinformatics Previous years flu data new swine flu Drug efficacy data against breast cancer drug data against lung cancer Intrusion detection Existing types of intrusions unknown types of intrusions Sentiment analysis Review from SDM Review from KDD 6/18
131 Learning with Heterogeneous Sources The paper mainly attacks two subproblems: Heterogeneous data distributions Clustering based KL divergence and a corresponding sampling technique Heterogeneous outputs (to regression problem) Unifying outputs via preserving similarity. 7/18
132 Learning with Heterogeneous Sources General Framework Source data Unifying data distributions Unifying outputs Target data Source data Target data 8/18
133 Unifying Data Distributions Basic idea: Combine the source and target data and perform clustering. Select the clusters in which the target and source data are similarly distributed, evaluated by KL divergence. 9/18

134 An Example D T Adaptive Clustering Combined Data 10/18
135 Unifying Outputs Basic idea: Generate initial outputs according to the regression model For the instances similar in the original output space, make their new outputs closer. 11/18
136 Initial Outputs Initial Outputs /18
137 Experiment Bioinformatics data set: 13/18
138 Experiment 14/18
139 Experiment Applied sociology data set: 15/18
140 Experiment 16/18
141 Conclusions Problem: Learning with Heterogeneous Sources: Heterogeneous data distributions Heterogeneous outputs Solution: Clustering based KL divergence help perform sampling Similarity preserving output generation help unify outputs 17/18
142 Transfer Learning on Heterogeneous Feature Spaces via Spectral Transformatio Xiaoxiao Shi, Qi Liu, Wei Fan, Philip S. Yu, and Ruixin Zhu
 Classifier Test documents (unlabeled) 85.5% 1/18")
143 Motivation Standard Supervised Learning Training documents (labeled) Classifier Test documents (unlabeled) 85.5% 1/18
 Huge set of unlabeled documents Labeled data are")
144 Motivation In Reality How to improve the performance? Training (labeled) Huge set of unlabeled documents Labeled data are insufficient! 47.3%
145 Learning Formulations
146 Learning from heterogeneous sources Labeled data from other sources Target domain test (unlabeled)??? Heterogeneous datasets: 1.Different data distributions: P(x train ) and P(x test ) are different 2.Different outputs: y train and y test are different 3.Different feature spaces: x train and x test are different 3/18
147 Some Applications of Transfer Learning WiFi-based localization tracking [Pan et al'08] Collaborative Filtering [Pan et al'10] Activity Recognition [Zheng et al'09] Text Classification [Dai et al'07] Sentiment Classification [Blitzer et al 07] Image Categorization [Shi et al 10]

148 Issues Different data distributions: P(x train ) and P(x test ) are different focuses more on Chicago local news focuses more on global news focuses more on scientific/objective documents



149 Issues Different outputs: y train and y test are different Wikipedia ODP Yahoo!
 Drug efficacy tests: Physical")

150 Issues Different feature spaces (the focus on the paper) Drug efficacy tests: Physical properties Topological properties Image Classification Wavelet features Color histogram
151 Unify different feature spaces Different number of features; different meanings of the features, no common feature, no overlap. Projection-based approach HeMap Find a projected space where (1) the source and target data are similar in distribution; (2) the original structure (separation) of each of the dataset is preserved.
152 Unify different feature spaces via HeMap Optimization objective of HeMap: The linear projection The linear projection The difference between error error the projected data
153 Unify different feature spaces via HeMap With some derivations, the objective can be reformulated as (more details can be found in the paper):
154 Algorithm flow of HeMap
155 Generalized HeMap to handle heterogeneous data (different distributions, outputs and feature spaces)
156 Unify different distributions and outputs Unify different distributions Clustering based sample selection [Shi etc al,09] Unify different outputs Bayesian like schema
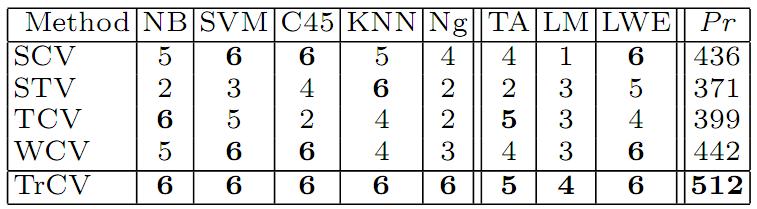
157 Generalization bound and are domain-specific parameters; is model complexity Principle I: minimize the difference between target and source datasets Principle II: minimize the combined expected error by maintaining the original structure (minimize projection error)
158 Experiments Drug efficacy prediction The dataset is collected by the College of Life Science and Biotechnology of Tongji University, China. It is to predict the efficacy of drug compounds against certain cell lines. The data are generated in two different feature spaces general descriptors: refer to physical properties of compounds drug-like index: refer to simple topological indices of compounds.
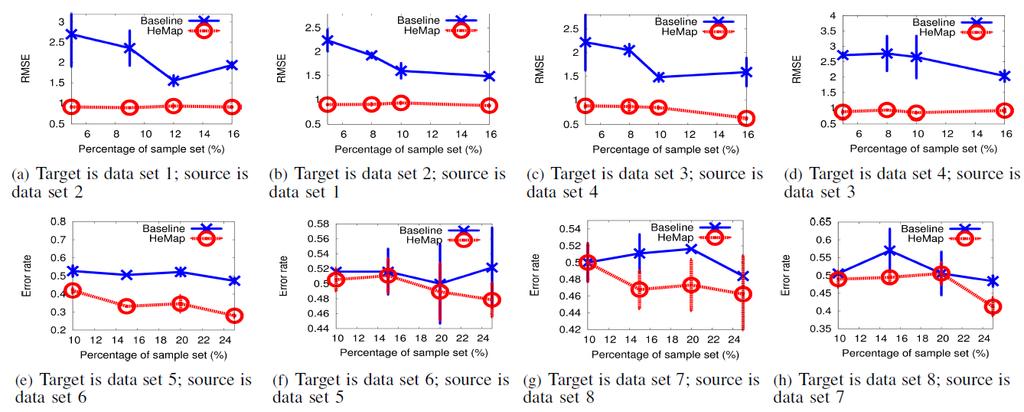
159 Experiments
160 Experiments Image classification Homer Simpson & Cactus Cartman & Bonsai Superman & CD Homer Simpson & Coin
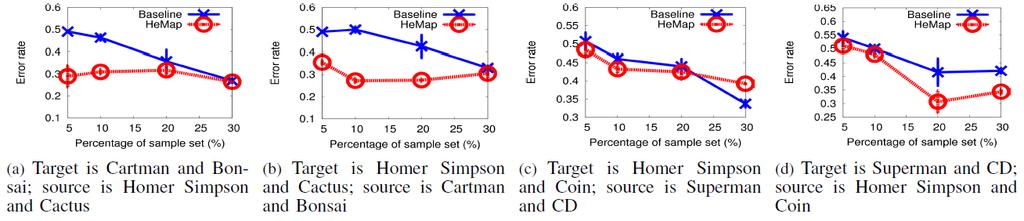
161 Experiments
162 Conclusions Extends the applicability of supervised learning, semi-supervised learning and transfer learning by using heterogeneous data: Different data distributions Different outputs Different feature spaces Unify different feature spaces via linear projection with two principles Maintain the original structure of the data Maximize the similarity of the two data in the projected space
163 Cross Validation Framework to Choose Amongst Models and Datasets for Transfer Learning Erheng Zhong, Wei Fan, Qiang Yang, Olivier Verscheure, Jiangtao Ren
164 Transfer Learning: What is it Definition source-domains to improve target-domain : short of labeled information. supervised unsupervised semi-supervised transfer learning Applications 1. WiFi-based localization tracking [Pan et al'08] 2. Collaborative Filtering [Pan et al'10] 3. Activity Recognition [Zheng et al'09] 4. Text Classification [Dai et al'07] 5. Sentiment Classification [Blitzer et al 07] 6. Image Categorization [Shi et al 10]...

165 Application Indoor WiFi localization tracking Transfer AP is the access point of device. (Lx, Ly) is the coordinate of location.
166 Application Collaborative Filtering



167 Transfer Learning: How it works Data Selection Model Selection
168 Re-cast: Model and Data Selection (1) How to select the right transfer learning algorithms? (2) How to tune the optimal parameters? (3) How to choose the most helpful source-domain from a large pool of datasets?
169 Model & Data Selection Traditional Methods 1. Analytical techniques: AIC, BIC, SRM, etc. 2. k-fold cross validation
170 Model & Data Selection Issuses P ( x) P ( x) s t The estimation is not consistent. Ideal Hypothesis P ( y x) P ( y x) s t A model approximating P s ( y x) is not necessarily close to P t ( y x) The number of labeled data in target domain is limited and thus the directly estimation of ( y x) is not reliable. P t


171 Model & Data Selection Model Selection Example Target Source If we choose the wrong model...
172 Model & Data Selection Data Selection Example Target If we choose the wrong source-domain...
173 Transfer Cross-Validation (TrCV) New criterion for transfer learning Hard to calculate in practice 1. The density ration between two domains Reverse Validation How to calculate this difference with limited labeled data? 2. The difference between the conditional distribution estimated by model and the true conditional distribution. Practical method: Transfer Cross-Validation (TrCV) Density Ratio Weighting
174 Density Ratio Weighting The selected model is an unbiased estimator to the ideal model is the expected loss to approximate is the model complexity Important property to choose the right model even when P(x) and P(y x) are different We adopt an existing method KMM (Huang et al 07) for density ratio weighting Reverse Validation to estimate P t (y x) P(y x,f) (next slide)

175 Reverse Validation The source-domain data in i-th fold The remaining data The predicted label of The predicted label of in i-th fold in i-th fold The true label of in i-th fold The unlabeled and labeled target-domain data
176 Properties The selected model is an unbiased estimator to the ideal one. [Lemma 1] The model selected by the proposed method has a generalization bound over target-domain data. [Theorem 1] The value of reverse validation is related to the difference between true conditional probability and model approximation. The confidence of TrCV has a bound. the accuracy estimated by TrCV the true accuracy of quantile point of the standard normal distribution

177 Experiment Data Set Wine Quality: two subsets related to red and white variants of the Portuguese Vinho Verde wine. For algorithm and parameters selection

178 Experiment Data Set Reuters-21578:the primary benchmark of text categorization formed by different news with a hierarchial structure. For algorithm and parameters selection

179 Experiment Data Set SyskillWebert: the standard dataset used to test web page ratings, generated by the HTML source of web pages plus the user rating. we randomly reserve Bands-recording artists as source-domain and the three others as target-domain data. For algorithm and parameters selection

180 Experiment Data Set 20-Newsgroup: primary benchmark of text categorization similar to Reuters For source-domain selection
181 Experiment Baseline methods SCV: standard k-fold CV on source-domain TCV: standard k-fold CV on labeled data from targetdomain STV: building a model on the source-domain data and validating it on labeled target-domain data WCV: using density ratio weighting to reduce the difference of marginal distribution between two domains, but ignoring the difference in conditional probability.
182 Experiment Other settings Algorithms: Naive Bayes(NB), SVM, C4.5, K-NN and NNge(Ng) TrAdaBoost(TA): instances weighting [Dai et al.'07] LatentMap(LM): feature transform [Xie et al.'09] LWE : model weighting ensemble [Gao et al.'08] Evaluation: if one criterion can select the better model in the comparison, it gains a higher measure value. The accuracy and value of criteria (e.g TrCV, SCV, etc) The number of comparisions between models


183 Results Algorithm Selection 6 win and 2 lose!


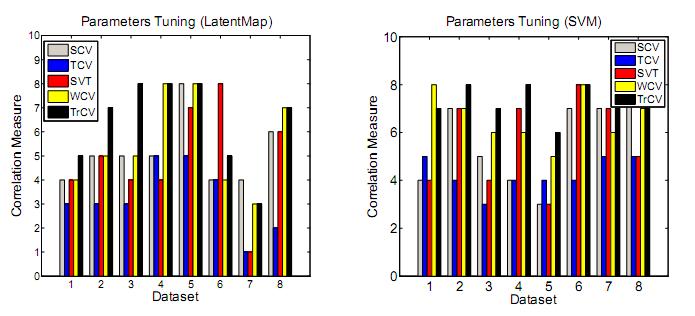
184 Results Parameter Tuning 13 win and 3 lose!
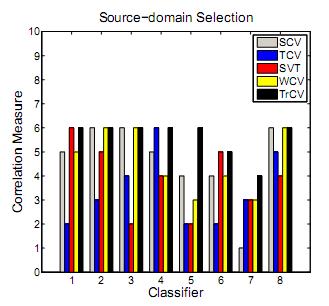
185 Results Source-domain Selection No lose!
186 Results Parameter Analysis TrCV achieves the highest correlation value under different number of folds from 5 to 30 with step size 5.
187 Results Parameter Analysis When only a few labeled data(< 0.4 T ) can be obtained in the target-domain, the performance of TrCV is much better than both SVT and TCV.
188 Conclusion Model and data selection when margin and conditional distributions are different between two domains. Key points Point-1 Density weighting to reduce the difference between marginal distributions of two domains; Point-2 Reverse validation to measure how well a model approximates the true conditional distribution of target-domain. Code and data available from the authors

189
190 Thanks! 18/18
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Transfer Learning Action Models by Measuring the Similarity of Different Domains
 Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY
 TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Massachusetts Institute of Technology Tel: Massachusetts Avenue Room 32-D558 MA 02139
 Hariharan Narayanan Massachusetts Institute of Technology Tel: 773.428.3115 LIDS har@mit.edu 77 Massachusetts Avenue http://www.mit.edu/~har Room 32-D558 MA 02139 EMPLOYMENT Massachusetts Institute of
Hariharan Narayanan Massachusetts Institute of Technology Tel: 773.428.3115 LIDS har@mit.edu 77 Massachusetts Avenue http://www.mit.edu/~har Room 32-D558 MA 02139 EMPLOYMENT Massachusetts Institute of
Welcome to. ECML/PKDD 2004 Community meeting
 Welcome to ECML/PKDD 2004 Community meeting A brief report from the program chairs Jean-Francois Boulicaut, INSA-Lyon, France Floriana Esposito, University of Bari, Italy Fosca Giannotti, ISTI-CNR, Pisa,
Welcome to ECML/PKDD 2004 Community meeting A brief report from the program chairs Jean-Francois Boulicaut, INSA-Lyon, France Floriana Esposito, University of Bari, Italy Fosca Giannotti, ISTI-CNR, Pisa,
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach
 Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Instructor: Mario D. Garrett, Ph.D. Phone: Office: Hepner Hall (HH) 100
 100") San Diego State University School of Social Work 610 COMPUTER APPLICATIONS FOR SOCIAL WORK PRACTICE Statistical Package for the Social Sciences Office: Hepner Hall (HH) 100 Instructor: Mario D. Garrett,
San Diego State University School of Social Work 610 COMPUTER APPLICATIONS FOR SOCIAL WORK PRACTICE Statistical Package for the Social Sciences Office: Hepner Hall (HH) 100 Instructor: Mario D. Garrett,
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
An Effective Framework for Fast Expert Mining in Collaboration Networks: A Group-Oriented and Cost-Based Method
 Farhadi F, Sorkhi M, Hashemi S et al. An effective framework for fast expert mining in collaboration networks: A grouporiented and cost-based method. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(3): 577
Farhadi F, Sorkhi M, Hashemi S et al. An effective framework for fast expert mining in collaboration networks: A grouporiented and cost-based method. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(3): 577
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Algebra 2- Semester 2 Review
 Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur)
 (Some slides, pony-based examples from Blase Ur)") Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation
 Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models
 What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Combining Proactive and Reactive Predictions for Data Streams
 Combining Proactive and Reactive Predictions for Data Streams Ying Yang School of Computer Science and Software Engineering, Monash University Melbourne, VIC 38, Australia yyang@csse.monash.edu.au Xindong
Combining Proactive and Reactive Predictions for Data Streams Ying Yang School of Computer Science and Software Engineering, Monash University Melbourne, VIC 38, Australia yyang@csse.monash.edu.au Xindong
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain