Deep Reinforcement Learning and Control. Deep Q Learning CMU Katerina Fragkiadaki
|
|
|
- Peter Bridges
- 5 years ago
- Views:
Transcription
1 Carnegie Mellon School of Computer Science Deep Reinforcement Learning and Control Deep Q Learning CMU Katerina Fragkiadaki Parts of slides borrowed from Russ Salakhutdinov, Rich Sutton, David Silver
2 Components of an RL Agent An RL agent may include one or more of these components: - Policy: agent s behavior function - Value function: how good is each state and/or action - Model: agent s representation of the environment A policy is the agent s behavior t is a map from state to action: - Deterministic policy: a = π(s) - Stochastic policy: π(a s) = P[a s]
3 Review: Value Function A value function is a prediction of future reward - How much reward will get from action a in state s? Q-value function gives expected total reward - from state s and action a - under policy π - with discount factor γ Value functions decompose into a Bellman equation q (s, a) =r(s, a)+ X s 0 2S T (s 0 s, a) X a 0 2A (a 0 s 0 )q (s 0,a 0 )
4 Optimal Value Function An optimal value function is the maximum achievable value Once we have Q, the agent can act optimally Formally, optimal values decompose into a Bellman equation
5 Optimal Value Function An optimal value function is the maximum achievable value Formally, optimal values decompose into a Bellman equation nformally, optimal value maximizes over all decisions

6 Model Model is learned from experience Acts as proxy for environment Planner interacts with model, e.g. using look-ahead search
7 Approaches to RL Value-based RL (this is what we have looked at so far) - Estimate the optimal value function Q (s,a) - This is the maximum value achievable under any policy Policy-based RL (next week) - Search directly for the optimal policy π - This is the policy achieving maximum future reward Model-based RL (later) - Build a model of the environment - Plan (e.g. by look-ahead) using model
8 Deep Reinforcement Learning Use deep neural networks to represent - Value function - Policy - Model Optimize loss function by stochastic gradient descent (SGD)
9 Deep Q-Networks (DQNs) Represent action-state value function by Q-network with weights w When would this be preferred?
10 Q-Learning Optimal Q-values should obey Bellman equation Treat right-hand as a target Minimize MSE loss by stochastic gradient descent Remember VFA lecture: Minimize mean-squared error between the true action-value function q π (S,A) and the approximate Q function:
11 Q-Learning Minimize MSE loss by stochastic gradient descent Converges to Q using table lookup representation

12 Q-Learning: Off-Policy TD Control One-step Q-learning:
13 Q-Learning Minimize MSE loss by stochastic gradient descent Converges to Q using table lookup representation But diverges using neural networks due to: 1. Correlations between samples 2. Non-stationary targets
14 Q-Learning Minimize MSE loss by stochastic gradient descent Converges to Q using table lookup representation But diverges using neural networks due to: 1. Correlations between samples 2. Non-stationary targets Solution to both problems in DQN:
15 DQN To remove correlations, build data-set from agent s own experience Sample experiences from data-set and apply update To deal with non-stationarity, target parameters w are held fixed
16 Experience Replay Given experience consisting of state, value, or <state, action/value> pairs Repeat - Sample state, value from experience - Apply stochastic gradient descent update
17 DQNs: Experience Replay DQN uses experience replay and fixed Q-targets Store transition (s t,a t,r t+1,s t+1 ) in replay memory D Sample random mini-batch of transitions (s,a,r,s ) from D Compute Q-learning targets w.r.t. old, fixed parameters w Optimize MSE between Q-network and Q-learning targets Q-learning target Q-network Use stochastic gradient descent

18 DQNs in Atari
19 DQNs in Atari End-to-end learning of values Q(s,a) from pixels nput observation is stack of raw pixels from last 4 frames Output is Q(s,a) for 18 joystick/button positions Reward is change in score for that step Network architecture and hyperparameters fixed across all games Mnih et.al., Nature, 2014

20 DQNs in Atari End-to-end learning of values Q(s,a) from pixels s nput observation is stack of raw pixels from last 4 frames Output is Q(s,a) for 18 joystick/button positions Reward is change in score for that step DQN source code: sites.google.com/a/ deepmind.com/dqn/ Network architecture and hyperparameters fixed across all games Mnih et.al., Nature, 2014
21 Extensions Double Q-learning for fighting maximization bias Prioritized experience replay Dueling Q networks Multistep returns Value distribution Stochastic nets for explorations instead of \epsilon-greedy
22 Maximization Bias We often need to maximize over our value estimates. The estimated maxima suffer from maximization bias Consider a state for which all ground-truth q(s,a)=0. Our estimates Q(s,a) are uncertain, some are positive and some negative. Q(s,argmax_a(Q(s,a)) is positive while q(s,argmax_a(q(s,a))=0.
23 Double Q-Learning Train 2 action-value functions, Q 1 and Q 2 Do Q-learning on both, but - never on the same time steps (Q 1 and Q 2 are independent) - pick Q 1 or Q 2 at random to be updated on each step f updating Q 1, use Q 2 for the value of the next state: Action selections are ε-greedy with respect to the sum of Q 1 and Q 2
24 Double Q-Learning in Tabular Form nitialize Q 1 (s, a) and Q 2 (s, a), 8s 2 S,a2 A(s), arbitrarily nitialize Q 1 (terminal-state, ) =Q 2 (terminal-state, ) =0 Repeat (for each episode): nitialize S Repeat (for each step of episode): Choose A from S using policy derived from Q 1 and Q 2 (e.g., "-greedy in Q 1 + Q 2 ) Take action A, observe R, S 0 With 0.5 probabilility: Q 1 (S, A) Q 1 (S, A)+ R + Q 2 S 0, argmax a Q 1 (S 0,a) Q 1 (S, A) else: Q 2 (S, A) S S 0 ; until S is terminal Q 2 (S, A)+ R + Q 1 S 0, argmax a Q 2 (S 0,a) Q 2 (S, A) Hado van Hasselt 2010
25 Double DQN Current Q-network w is used to select actions Older Q-network w is used to evaluate actions Action evaluation: w Action selection: w van Hasselt, Guez, Silver, 2015
26 Prioritized Replay Weight experience according to ``surprise (or error) Store experience in priority queue according to DQN error Stochastic Prioritization p i is proportional to DQN error α determines how much prioritization is used, with α = 0 corresponding to the uniform case. Schaul, Quan, Antonoglou, Silver, CLR 2016
27 Dueling Networks Split Q-network into two channels Action-independent value function V(s; w) Action-dependent advantage function A(s, a; w) Q(s, a; w) = V(s; w) + A(s, a; w) Advantage function is defined as: Wang et.al., CML, 2016
28 Dueling Networks vs. DQNs DQN Dueling Networks Q(s, a; w) = V(s; w) + A(s, a; w) Unidentifiability : given Q, cannot recover V, A Wang et.al., CML, 2016
29 Dueling Networks vs. DQNs DQN Dueling Networks Q(s, a; w) = V(s; w) + ( A(s, a; w) 1 A a A(s, a ; w) ) Wang et.al., CML, 2016
30 Dueling Networks The value stream learns to pay attention to the road The advantage stream: pay attention only when there are cars immediately in front, so as to avoid collisions Wang et.al., CML, 2016
31 Visualizing neural saliency maps
32 Task: Generate an image that maximizes a classification score. Starting from a zero image, backpropagate to update the image pixel valiues, having fixed weights, maximizing the objective: Add the mean image to the final result.

33
34 Task: Generate a saliency map for a particular category S_c() is a non-linear function of. We can create a first order approximation: use the largest magnitude derivatives across R,G,B channels for each pixel to be its saliency value.

35

36 Dueling Networks The value stream learns to pay attention to the road The advantage stream: pay attention only when there are cars immediately in front, so as to avoid collisions Wang et.al., CML, 2016
37 Multistep Returns Truncated n-step return from a state s_t: R (n) t = n 1 γ (k) t k=0 R t+k+1 Multistep Q-learning update rule: R (n) t = (R (n) + γ (n) Q(s, a, w)) 2 t max a Q(S t+n, a, w) Singlestep Q-learning update rule:
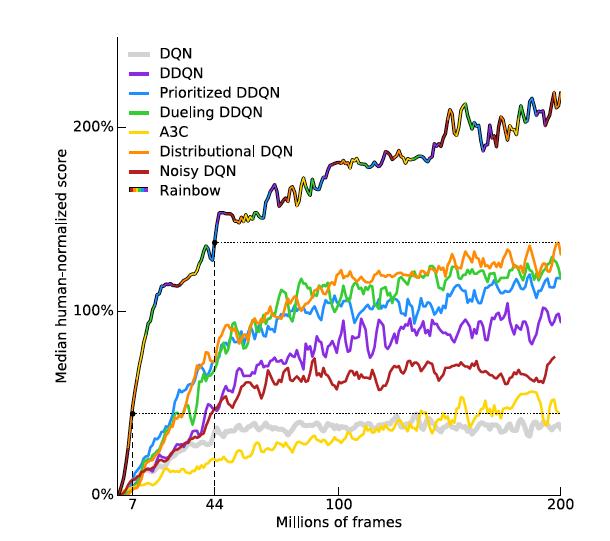
38
39
40
41 Question magine we have access to the internal state of the Atari simulator. Would online planning (e.g., using MCTS), outperform the trained DQN policy?
42 Question magine we have access to the internal state of the Atari simulator. Would online planning (e.g., using MCTS), outperform the trained DQN policy? With enough resources, yes. Resources = number of simulations (rollouts) and maximum allowed depth of those rollouts. There is always an amount of resources when a vanilla MCTS (not assisted by any deep nets) will outperform the learned with RL policy.
43 Question Then why we do not use MCTS with online planning to play Atari instead of learning a policy?
44 Question Then why we do not use MCTS with online planning to play Atari instead of learning a policy? Because using vanilla (not assisted by any deep nets) MCTS is very very slow, definitely very far away from real time game playing that humans are capable of.
45 Question f we used MCTS during training time to suggest actions using online planning, and we would try to mimic the output of the planner, would we do better than DQN that learns a policy without using any model while playing in real time?
46 Question f we used MCTS during training time to suggest actions using online planning, and we would try to mimic the output of the planner, would we do better than DQN that learns a policy without using any model while playing in real time? That would be a very sensible approach!

47
48 Offline MCTS to train online fast reactive policies AlphaGo: train policy and value networks at training time, combine them with MCTS at test time AlphaGoZero: train policy and value networks with MCTS in the training loop and at test time (same method used at train and test time) Offline MCTS: train policy and value networks with MCTS in the training loop, but at test time use the (reactive) policy network, without any lookahead planning. Where does the benefit come from?
49 Revision: Monte-Carlo Tree Search 1. Selection Used for nodes we have seen before Pick according to UCB 2. Expansion Used when we reach the frontier Add one node per playout 3. Simulation Used beyond the search frontier Don t bother with UCB, just play randomly 4. Backpropagation After reaching a terminal node Update value and visits for states expanded in selection and expansion Bandit based Monte-Carlo Planning, Kocsis and Szepesvari, 2006
50 Upper-Confidence Bound Sample actions according to the following score: score is decreasing in the number of visits (explore) score is increasing in a node s value (exploit) always tries every option once Finite-time Analysis of the Multiarmed Bandit Problem, Auer, Cesa-Bianchi, Fischer, 2002
51 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Explored Tree Search Tree
52 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
53 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
54 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
55 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
56 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
57 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
58 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
59 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree
60 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Explored Tree New Node
61 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Random Phase Explored Tree New Node
62 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Random Phase Explored Tree New Node
63 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Random Phase Explored Tree New Node
64 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Random Phase Explored Tree New Node
65 Monte-Carlo Tree Search Gradually grow the search tree: terate Tree-Walk Building Blocks Returned solution: Select next action Bandit phase Add a node Grow a leaf of the search tree Select next action bis Random phase, roll-out Compute instant reward Evaluate Update information in visited nodes Propagate Path visited most often Kocsis Szepesvári, 06 Bandit Based Phase Search Tree Random Phase Explored Tree New Node
66 Learning from MCTS The MCTS agent plays against himself and generates (s, Q(s,a)) pairs. Use this data to train: UCTtoRegression: A regression network, that given 4 frames regresses to Q(s,a) for all actions UCTtoClassification: A classification network, that given 4 frames predicts the best action through multiclass classification The state distribution visited using actions of the MCTS planner will not match the state distribution obtained from the learned policy. UCTtoClassification-nterleaved: nterleave UCTtoClassification with data collection: Start from 200 runs with MCTS as before, train UCTtoClassification, deploy it for 200 runs allowing 5% of the time a random action to be sampled, use MCTS to decide best action for those states, train UCTtoClassification and so on and so forth.
67 Results
68 Results Online planning (without aided by any neural net!) outperforms DQN policy. t takes though ``a few days on a recent multicore computer to play for each game.
69 Results Classification is doing much better than regression! indeed, we are training for exactly what we care about.
70 Results nterleaving is important to prevent mismatch between the training data and the data that the trained policy will see at test time.
71 Results Results improve further if you allow MCTS planner to have more simulations and build more reliable Q estimates.

72 Problem We do not learn to save the divers. Saving 6 divers brings very high reward, but exceeds the depth of our MCTS planner, thus it is ignored.
73 Question Why don t we always use MCTS (or some other planner) as supervision for reactive policy learning? Because in many domains we do not have access to the dynamics. n later lectures we will see how we will use online trajectory optimizers which learn (linear) dynamics on-the-fly as supervisors
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Human-like Natural Language Generation Using Monte Carlo Tree Search
 Human-like Natural Language Generation Using Monte Carlo Tree Search Kaori Kumagai Ichiro Kobayashi Daichi Mochihashi Ochanomizu University The Institute of Statistical Mathematics {kaori.kumagai,koba}@is.ocha.ac.jp
Human-like Natural Language Generation Using Monte Carlo Tree Search Kaori Kumagai Ichiro Kobayashi Daichi Mochihashi Ochanomizu University The Institute of Statistical Mathematics {kaori.kumagai,koba}@is.ocha.ac.jp
Guided Monte Carlo Tree Search for Planning in Learned Environments
 JMLR: Workshop and Conference Proceedings 29:33 47, 2013 ACML 2013 Guided Monte Carlo Tree Search for Planning in Learned Environments Jelle Van Eyck Department of Computer Science, KULeuven Leuven, Belgium
JMLR: Workshop and Conference Proceedings 29:33 47, 2013 ACML 2013 Guided Monte Carlo Tree Search for Planning in Learned Environments Jelle Van Eyck Department of Computer Science, KULeuven Leuven, Belgium
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design
 Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Improving Fairness in Memory Scheduling
 Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Planning with External Events
 94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
College Pricing. Ben Johnson. April 30, Abstract. Colleges in the United States price discriminate based on student characteristics
 College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
STT 231 Test 1. Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point.
 STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Emotional Variation in Speech-Based Natural Language Generation
 Emotional Variation in Speech-Based Natural Language Generation Michael Fleischman and Eduard Hovy USC Information Science Institute 4676 Admiralty Way Marina del Rey, CA 90292-6695 U.S.A.{fleisch, hovy}
Emotional Variation in Speech-Based Natural Language Generation Michael Fleischman and Eduard Hovy USC Information Science Institute 4676 Admiralty Way Marina del Rey, CA 90292-6695 U.S.A.{fleisch, hovy}
Chapters 1-5 Cumulative Assessment AP Statistics November 2008 Gillespie, Block 4
 Chapters 1-5 Cumulative Assessment AP Statistics Name: November 2008 Gillespie, Block 4 Part I: Multiple Choice This portion of the test will determine 60% of your overall test grade. Each question is
Chapters 1-5 Cumulative Assessment AP Statistics Name: November 2008 Gillespie, Block 4 Part I: Multiple Choice This portion of the test will determine 60% of your overall test grade. Each question is
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method
 Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
College Pricing and Income Inequality
 College Pricing and Income Inequality Zhifeng Cai U of Minnesota, Rutgers University, and FRB Minneapolis Jonathan Heathcote FRB Minneapolis NBER Income Distribution, July 20, 2017 The views expressed
College Pricing and Income Inequality Zhifeng Cai U of Minnesota, Rutgers University, and FRB Minneapolis Jonathan Heathcote FRB Minneapolis NBER Income Distribution, July 20, 2017 The views expressed
Functional Skills Mathematics Level 2 assessment
 Functional Skills Mathematics Level 2 assessment www.cityandguilds.com September 2015 Version 1.0 Marking scheme ONLINE V2 Level 2 Sample Paper 4 Mark Represent Analyse Interpret Open Fixed S1Q1 3 3 0
Functional Skills Mathematics Level 2 assessment www.cityandguilds.com September 2015 Version 1.0 Marking scheme ONLINE V2 Level 2 Sample Paper 4 Mark Represent Analyse Interpret Open Fixed S1Q1 3 3 0
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Ericsson Wallet Platform (EWP) 3.0 Training Programs. Catalog of Course Descriptions
 3.0 Training Programs. Catalog of Course Descriptions") Ericsson Wallet Platform (EWP) 3.0 Training Programs Catalog of Course Descriptions Catalog of Course Descriptions INTRODUCTION... 3 ERICSSON CONVERGED WALLET (ECW) 3.0 RATING MANAGEMENT... 4 ERICSSON
Ericsson Wallet Platform (EWP) 3.0 Training Programs Catalog of Course Descriptions Catalog of Course Descriptions INTRODUCTION... 3 ERICSSON CONVERGED WALLET (ECW) 3.0 RATING MANAGEMENT... 4 ERICSSON
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Detailed course syllabus
 Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Team Formation for Generalized Tasks in Expertise Social Networks
 IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust Team Formation for Generalized Tasks in Expertise Social Networks Cheng-Te Li Graduate
IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust Team Formation for Generalized Tasks in Expertise Social Networks Cheng-Te Li Graduate
Edexcel GCSE. Statistics 1389 Paper 1H. June Mark Scheme. Statistics Edexcel GCSE
 Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Results In. Planning Questions. Tony Frontier Five Levers to Improve Learning 1
 Key Tables and Concepts: Five Levers to Improve Learning by Frontier & Rickabaugh 2014 Anticipated Results of Three Magnitudes of Change Characteristics of Three Magnitudes of Change Examples Results In.
Key Tables and Concepts: Five Levers to Improve Learning by Frontier & Rickabaugh 2014 Anticipated Results of Three Magnitudes of Change Characteristics of Three Magnitudes of Change Examples Results In.
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization
 A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization Stefan Henß TU Darmstadt, Germany stefan.henss@gmail.com Margot Mieskes h da Darmstadt & AIPHES Germany margot.mieskes@h-da.de
A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization Stefan Henß TU Darmstadt, Germany stefan.henss@gmail.com Margot Mieskes h da Darmstadt & AIPHES Germany margot.mieskes@h-da.de