CS480 Introduction to Machine Learning Decision Trees. Edith Law
|
|
|
- Frank Anthony May
- 5 years ago
- Views:
Transcription
1 CS480 Introduction to Machine Learning Decision Trees Edith Law




2 Frameworks of machine learning Classification Supervised Learning Unsupervised Learning Reinforcement Learning 2
3 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 3
4 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 4
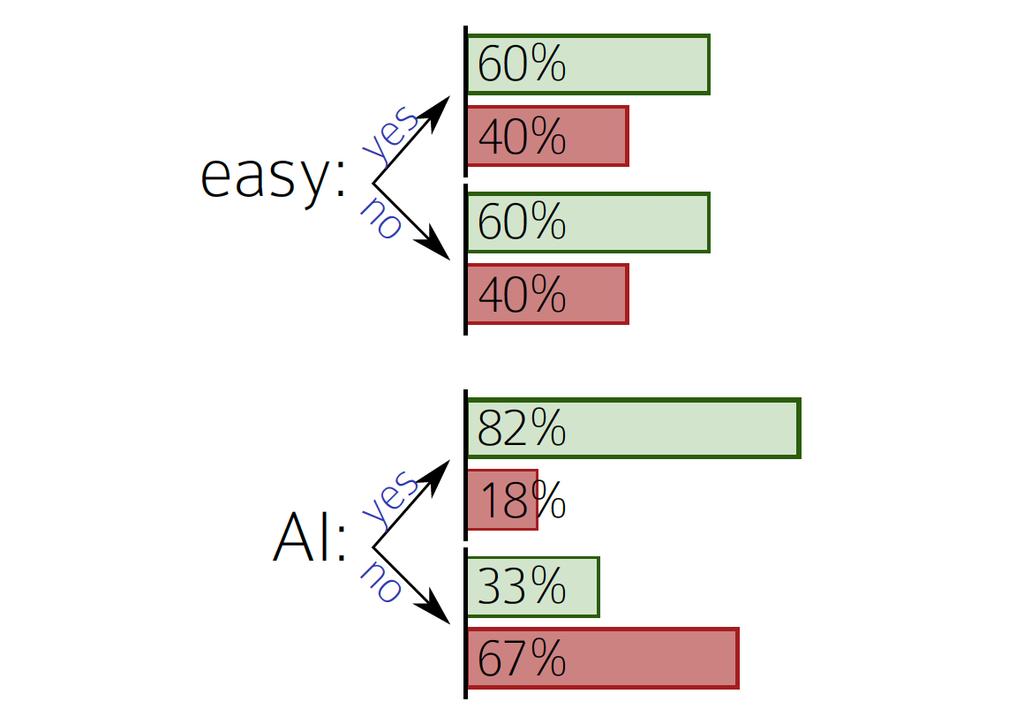
5 Prediction is about finding questions that matter Suppose we are given some data about students preferences for courses. course type course time difficulty grade rating s1 AI morning easy 90 like s1 ML afternoon easy 87 like s2 AI morning hard 72 nah s3 theory morning hard 79 nah s3 systems evening hard 85 nah s4 systems morning hard 66 like 5
6 Prediction is about finding questions that matter You: Is the course under consideration a ML course? Me: Yes You: Has this student taken any other AI courses? Me: Yes You: Has this student liked most AI courses? Me: No You: I predict this student will not like this course. 6
7 Prediction is about finding questions that matter isml? no yes You: Is the course under consideration a ML course? Me: Yes You: Has this student taken any other AI courses? Me: Yes You: Has this student liked most AI courses? Me: No You: I predict this student will not like this course. nah takenotherai? no yes morning? likedotherai? no yes no yes like nah nah like 7
8 Learning Decision Trees Given a set of training data in the form of examples (e.g., <user, course>, rating), construct questions that you can ask. In machine learning language, example = a set of features values < AI, morning, easy, 90, like > question = constructed based on features takenotherai? label / target class rating grade > 80%? class time? answer to the question = determined by the feature values yes/no categorical (e.g., morning, afternoon, evening ) 8
9 Learning Decision Trees Learning is about searching for the best tree to describe the data. - We could enumerate all possible trees, and evaluate each tree using the training set or test set - How many trees are there given 3 features? - There are too many possible trees! (NP Hard problem) It is computational infeasible to consider all the trees, so decision trees must be built greedily by asking - If I could ask one question, what question would I ask? - What is the question that would be most helpful in helping me guess whether the student will enjoy the course? Each node represents a question that split the data; so learning a decision tree amounts to choosing what the internal nodes should be. 9
10 Learning Decision Trees These questions can take many forms: radius > 17.5 radius in [12, 18] grade is {A, B, C, D, F} grade >= B color is RED 2*radius-3*texture > 16 10


11 Decision Tree 11




12 Decision Tree Uninformative Informative 12
13 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 13
![Supervised Learning Problem Setting: Set of possible instances Unknown target function Set of function hypotheses H = {h h : X Y} X f : X Y [D] Figure1.](/docs-images/88/115933499/images/14-0.jpg "1 The learning algorithm: input: training examples x i, y i output: hypothesis h H that best approximates the target function f The set of all hypotheses that can be outputted by a learning")
14 Supervised Learning Problem Setting: Set of possible instances Unknown target function Set of function hypotheses H = {h h : X Y} X f : X Y [D] Figure1.1 The learning algorithm: input: training examples x i, y i output: hypothesis h H that best approximates the target function f The set of all hypotheses that can be outputted by a learning algorithm is called the hypothesis space. 14
15 Decision Tree Learning The learning algorithm: input: training examples Problem Setting: Set of possible instances Unknown target function Set of function hypotheses x i, y i output: hypothesis h H that best approximates the target function f X Each instance is a feature vector H = {h h : X Y} f : X Y y = 1 if a student likes the course, y = 0 if not Each hypothesis h is a decision tree. 15
16 Interpreting Decision Trees (Outlook = Sunny Humidity = Normal) (Outlook = Overcast) (Outlook = Rain Wind = Weak) 16
17 Another Example: Cancer Recurrence Prediction Wisconsin Breast Cancer (Prognosis) Dataset consists of 30 features of the cancer cells nuclei. There are 10 features related to radius, texture, perimeter, smoothness, concavity, etc., of the nuclei. For each feature, there is the mean, standard error and max of the feature values. For each example, the outcomes are N=no recurrence or R=recurrence. radius texture perimeter outcome , N N R 17
18 Example: Cancer Recurrence Prediction What does a node present? a partitioning of the input space internal nodes: a test or question - discrete features: branch on all values - real features: branch on threshold value leaf nodes: include examples that satisfy the tests along the branch R = recurrence N = no recurrence Each example falls in precisely one leaf. Each leaf typically contains more than one example. 18
19 Interpreting Decision Trees can always convert a decision tree into an equivalent set of if-then rules. R = recurrence N = no recurrence 19
20 Interpreting Decision Trees can always convert a decision tree into an equivalent set of if-then rules, as well as calculate an estimated probability of recurrence. R = recurrence N = no recurrence 20
21 Interpreting Decision Trees x 1 > θ 1 x 2 E x 2 θ 2 x 2 > θ 3 θ 3 B x 1 θ 4 θ 2 C D A A B C D E θ 1 θ 4 x 1 21
22 Interpreting Decision Trees 22
23 Interpreting Decision Trees Ishwaran H. and Rao J.S. (2009) 23
24 Which kinds of functions can decision trees express? For decision tress, the hypothesis space is the set of all possible finite discrete functions (i.e., functions whose output is a finite set of categories) that can be learned based on the data. Every finite discrete function can be represented by some decision tree. 24
25 Which kinds of functions can decision trees express? boolean function can be fully expressed - each entry in the truth table can be one path (very inefficient!) - most boolean functions can be encoded more compactly. Some functions are harder to encode - parity functions: returns 1 iff an even number of inputs are 1 - an exponentially big decision tree O(2 M ) would be needed - majority function: returns 1 if more than half the inputs are 1 Many other functions can be approximated by a Boolean function With real-valued features, decision trees are good at problems in which the class label is constant in large connected axis-orthogonal regions of the input space. 25
26 Decision Boundaries for Real-Valued Features 26
27 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 27
28 Example: Cancer Outcome Prediction Suppose we get a new instance radius = 16, texture = 12 How do we classify it? Simple procedure: R = recurrence N = no recurrence at every node, test the correspond attribute follow the appropriate branch of the tree at a leaf, either predict the class of the majority of the examples for that test, or sample from the probabilities of the two classes. 28
29 Decision Tree Testing Algorithm DecisionTreeTest(tree, test point) If tree is of the form LEAF(guess) then return guess else if tree is of the form NODE(f, left, right) then if f = no in test point then return DecisionTreeTest(left, test point) else return DecisionTreeTest(right, test point) end if end if 29
30 Learning Decision Trees Most algorithms developed for learning decision trees are variations on core algorithm that employs a recursive, top-down procedure that grows a tree (possibly until it classifies all training data correctly). C4.5 (Quinlan, 1993) ID3 (Quinlan 1986) 30
31 Decision Tree Training Algorithm Given a set of labeled training instances: 1. if all the training instances have the same class, create a leaf with that class label and exit. Else 2. Pick the best test to split the data on. 3. Split the training set according to the value of the outcome of the test. 4. Recursively repeat step 1-3 on each subset of the training data. 31
32 Decision Tree Training Algorithm DecisionTreeTrain(data, remaining features) guess most frequent answer in data If the labels in data are ambiguous then return LEAF(guess) else if remaining features is empty then return LEAF(guess) else for all f remaining features do NO the subset of data on which f = no YES the subset of data on which f = yes score(f) # of majority vote answer in NO + # of majority vote answer in YES end for f the feature with maximal score (f) NO the subset of data on which f=no YES the subset of data on which f=yes left DecisionTreeTrain(NO, remaining features \ {f}) right DecisionTreeTrain(YES, remaining features \ {f}) return NODE(f, left, right) end if 32
33 What is a good test? The test should provide information about the class label. e.g., you are given 40 examples, 30 positives, 10 negative. Consider two tests that would split the examples as follows: Which is best? Intuitively, we prefer an attribute that separates the training instances as well as possible. How would we quantify this mathematically? 33



34 Notion of information Consider three cases: dice coin biased coin There is different amounts of uncertainty to the observed outcomes. 34
35 Information Content Let E be an event that occurs with probability P(E). If we are told that E has occurred with certainty, then we receive I(E) bits of information. I(E) = log 2 1 P(E) You can also think of information as the amount of surprise in the outcome. For example, if P(E) = 1, then I(E=0) fair coin flip provides log2 2 = 1 bit of information fair dice roll provides log2 6 = 2.58 bits of information 35
36 Information Content For example, below is a list of probabilities that a certain letter xi appears in the English alphabet. The lower the probability, the higher the information content / surprise. I(x i ) 36
37 Entropy Given an information source S which emits k symbols from an alphabet {s1,, sk} with probabilities {p1,, pk}, where each emission is independent of the others. What is the average amount of information we expect from the output of S? H(S) = k i p i I(s i ) = k i p i log 1 p i = k i p i log p i H(S) is the entropy of S. 37
38 Entropy H(S) = i p i log 1 p i Several ways to think about entropy: average amount of information per symbol average amount of surprise when observing the symbol uncertainty the observer has before seeing the symbol average number of bits needed to communicate the symbols. 38
39 Binary Classification We try to classify a sample of the data S using a decision tree. Suppose we have p positive samples and n negative samples What is the entropy of this dataset? H(S) = p log p p log p = p p + n log 2 p p + n n p + n log 2 n p + n 39
40 Binary Classification e.g., you are given 40 examples, 30 positives, 10 negative. H(S) = p log p p log p = p p + n log 2 p p + n n p + n log 2 n p + n = 3 4 log log =
41 Binary Classification H(S) = p log p p log p Entropy measures the impurity of S. Entropy is 0 if all members of S belong to the same class, Entropy is 1 if there is an equal number of pos and neg examples. 41
42 Conditional Entropy The conditional entropy, H(y x), is the average specific conditional entropy of y given the values of x: H(y x) = v P(x = v)h(y x = v) Interpretation: the expected number of bits needed to transmit y if both the emitter and receive know the possible values of x (but before they were told x s specific value). 42
43 What is a good test? A good test/question should provide information about the class label. e.g., you are given 40 examples, 30 positives, 10 negative. T1 T2 H(S) = i p i log 1 p i H(y x) = v P(x = v) H(y x = v) H(S) = 3 4 log 2 H(S T1) = [ log log = log ] + 10 [0] = H(S T2) = [ log log ] [ log log ] =
44 Information Gain Suppose there is a feature called x. The reduction in entropy that would be obtained by knowing the values of x: IG(S, x) = H(S) H(S x) Equivalently, suppose one has to transmit y: How many bits (on average) would it save if both the transmitter and emitter knew x? 44
45 Information Gain A good test/question should provide information about the class label. e.g., you are given 40 examples, 30 positives, 10 negative. T1 T2 Which test/question gives a higher information gain? 45
46 Information Gain Which attribute is the best classifier? S={9+,5-} H(S)=0.94 humidity S={9+,5-} H(S)=0.94 wind high normal weak strong S={3+,4-} S={6+,1-} S={6+,2-} S={3+,3-} H(S high)=0.985 H(S normal)=0.592 H(S weak)=0.811 H(S strong)=
47 Information Gain Which attribute is the best classifier? S={9+,5-} H(S)=0.94 S={9+,5-} H(S)=0.94 humidity wind high normal weak strong S={3+,4-} S={6+,1-} S={6+,2-} S={3+,3-} H(S high)=0.985 H(S normal)=0.592 H(S weak)=0.811 H(S strong)=1.00 Gain(S, Humidity)= = (7/14).985 (7/14).592 = Gain(S, Wind)= = (8/14).811 (6/14)1.0 =
48 Decision Tree Training Algorithm Given a set of labeled training instances: 1. if all the training instances have the same class, create a leaf with that class label and exit. Else 2. Pick the best test to split the data on. 3. Split the training set according to the value of the outcome of the test. 4. Recursively repeat step 1-3 on each subset of the training data. How do we pick the best test?.for classification, choose the test with the highest information gain. for regression: choose the test with the lowest mean-squared error. 48
49 Decision Tree Training as Search We can think of decision tree learning as searching in a space of hypotheses for one that fits the training examples. The hypothesis space searched by the algorithm is the set of possible trees. It begins with an empty tree, then considering progressively more elaborate hypotheses in search for a decision tree that correctly classifies the training data. 49
50 Example: ID3 ID3 is top-down greedy search algorithm for decision trees. It maintains only a single current hypothesis as it searches, and does not do any backtracking. has no ability to determine alternative decision trees that are consistent with the data, and so runs the risk of converging to a locally optimal solution. handle noisy data by accepting hypotheses that imperfectly fit the data. 50
51 Special Cases What if the outcome of the test is not binary? The number of possible values influences the information gain: the more possible values, the higher the gain nonetheless, the attributes could be irrelevant We could transform attribute into one (or many) binary attributes. C4.5 (the most popular decision tree construction algorithm) uses only binary tests, i.e., attribute = value (discrete) or attribute < value (continuous). 51
52 Special Cases Suppose feature j are real-values. How do we choose a finite set of thresholds of the form xj > c? choose midpoints of the observed data values x1,j,, xm,j choose midpoints of the observed data values with different y values It can be shown (Fayyad 1992) that the value of the threshold that maximizes information gain must lie at the boundary between adjacent examples (in sorted list) that differ in their target classification. 52
53 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 53
54 Longer Trees = Worse Performance Decision trees construction proceeds until all leaves are pure (i.e., all examples are from the same class. As the tree grows, the performance on the test set (generalization performance) can start to degrade. 54
55 Overfitting We say that a hypothesis overfits the training examples, if some other hypothesis that fits the training examples less well actually perform better over the entire distribution of instances (including instances beyond the training set). Definition: Given a hypothesis space H, a hypothesis h in H is said to overfit the training data if there exist some alternative hypothesis h in H, such that h has a smaller error than h over the training examples, but h has a smaller error than h over the entire distribution of instances. Why does this happen? How can it be possible for the tree h to fit the training examples better than h, but for it to perform more poorly over subsequent examples? 55
56 Overfitting This can happen when the training examples contain random errors or noise. when training data is noise free, but there is coincidental regularities in the dataset, e.g., some irrelevant attribute happens to partition the examples very well, despite being unrelated to the actual target function. In one study (Mingers, 1989b), overfitting was found to decrease the accuracy of the learned decision trees on 10-25% of the problems. 56
57 Overfitting: How to Avoid Remove some nodes to get better generalization! Early stopping: stop growing the tree when further splitting the data does not improve information gain of the validation set. Post pruning: Grow a full tree, then prune the tree by eliminating lower nodes that have low information gain on the validation set. In general, post pruning is better: it allows you to deal with cases where a single attribute is not informative, but a combination of attributes is informative. 57
58 Early Stopping: Criteria Maximum depth exceeded Maximum running time exceeded All children nodes are sufficiently homogeneous All children noes have too few training examples Cross-Validation Reduction in cost is small 58
59 Post Pruning (or Reduced Error Pruning) Split the data set into a training set and a validation set Grow a large tree (e.g. until each leaf is pure) For each node: - Evaluate the validation set accuracy of pruning the subtree rooted at the node - Greedily remove the node such that the removal most improves validation set accuracy, with its corresponding subtree - Replace the removed node by a leaf with the majority class of the corresponding examples (assigning it the most common classification of the training examples affiliated with that node). Stop when pruning starts hurting the accuracy on validation set. 59
60 Reduced Error Pruning Pruning: Effects Any leaf nodes added due to coincidental regularities is likely to be pruned because the same regularities are unlikely to be in the validation set. 60
61 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 61
62 Inductive Bias 62

63 Inductive Bias A B B A A B The type of solutions are we more likely to prefer In the absence of data that narrow down the relevant concept. 63
64 Inductive Bias There are many trees consistent with the examples. How does greedy decision tree algorithms (e.g., ID3) choose? - It goes from simple to complex. - select trees that place attributes with higher information gain closer to the root. - prefer to make decisions by only looking at as few features as possible. So, for decision trees, the inductive biases are - Occam s razor: prefer the simplest hypothesis that fits the data. Shorter trees are better than Longer trees. - Trees that place high information gain attributes closer to the root are preferred over those that do not. 64
65 Inductive Bias The set of assumptions that the learner makes about the target function (i.e., the function that maps input to output) that enables it to generalize to future instances. Restriction Bias: limit the hypothesis space (e.g., linear regression models) Preference Bias: impose ordering on the hypothesis space (e.g., decision tree) 65
66 Overview What is the idea behind decision trees? What kind of functions are we learning with the decision trees? What is the training and testing procedure for decision trees? What can we do to ensure that the learned decision tree generalizes to future examples? What is the inductive bias of decision trees? What are the pros and cons of decision trees? 66
67 Advantages of Decision Trees provide a general representation of classification rules the learned function is easy to interpret fast learning algorithms good accuracy in practice and many applications in industry 67
68 Limitations of Decision Trees Sensitivity: - exact tree output may be sensitive to small changes - with many features, tests may not be meaningful good for learning (non-linear) piecewise axis-orthogonal decision boundaries, but not for learning functions with smooth, curvilinear boundaries. 68
69 What you should know How to use a decision tree to classify a new example How to build a decision tree using an information-theoretic approach How to detect (and fix) overfitting in decision trees How to handle both discrete and continuous attributes and outputs What inductive bias means 69
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
The lab is designed to remind you how to work with scientific data (including dealing with uncertainty) and to review experimental design.
 and to review experimental design.") Name: Partner(s): Lab #1 The Scientific Method Due 6/25 Objective The lab is designed to remind you how to work with scientific data (including dealing with uncertainty) and to review experimental design.
Name: Partner(s): Lab #1 The Scientific Method Due 6/25 Objective The lab is designed to remind you how to work with scientific data (including dealing with uncertainty) and to review experimental design.
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
RANKING AND UNRANKING LEFT SZILARD LANGUAGES. Erkki Mäkinen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TAMPERE REPORT A ER E P S I M S
 N S ER E P S I M TA S UN A I S I T VER RANKING AND UNRANKING LEFT SZILARD LANGUAGES Erkki Mäkinen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TAMPERE REPORT A-1997-2 UNIVERSITY OF TAMPERE DEPARTMENT OF
N S ER E P S I M TA S UN A I S I T VER RANKING AND UNRANKING LEFT SZILARD LANGUAGES Erkki Mäkinen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TAMPERE REPORT A-1997-2 UNIVERSITY OF TAMPERE DEPARTMENT OF
Learning goal-oriented strategies in problem solving
 Learning goal-oriented strategies in problem solving Martin Možina, Timotej Lazar, Ivan Bratko Faculty of Computer and Information Science University of Ljubljana, Ljubljana, Slovenia Abstract The need
Learning goal-oriented strategies in problem solving Martin Možina, Timotej Lazar, Ivan Bratko Faculty of Computer and Information Science University of Ljubljana, Ljubljana, Slovenia Abstract The need
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Version Space. Term 2012/2013 LSI - FIB. Javier Béjar cbea (LSI - FIB) Version Space Term 2012/ / 18
 Version Space Term 2012/ / 18") Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Self Study Report Computer Science
 Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Data Stream Processing and Analytics
 Data Stream Processing and Analytics Vincent Lemaire Thank to Alexis Bondu, EDF Outline Introduction on data-streams Supervised Learning Conclusion 2 3 Big Data what does that mean? Big Data Analytics?
Data Stream Processing and Analytics Vincent Lemaire Thank to Alexis Bondu, EDF Outline Introduction on data-streams Supervised Learning Conclusion 2 3 Big Data what does that mean? Big Data Analytics?
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
On the Polynomial Degree of Minterm-Cyclic Functions
 On the Polynomial Degree of Minterm-Cyclic Functions Edward L. Talmage Advisor: Amit Chakrabarti May 31, 2012 ABSTRACT When evaluating Boolean functions, each bit of input that must be checked is costly,
On the Polynomial Degree of Minterm-Cyclic Functions Edward L. Talmage Advisor: Amit Chakrabarti May 31, 2012 ABSTRACT When evaluating Boolean functions, each bit of input that must be checked is costly,
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Constructive Induction-based Learning Agents: An Architecture and Preliminary Experiments
 Proceedings of the First International Workshop on Intelligent Adaptive Systems (IAS-95) Ibrahim F. Imam and Janusz Wnek (Eds.), pp. 38-51, Melbourne Beach, Florida, 1995. Constructive Induction-based
Proceedings of the First International Workshop on Intelligent Adaptive Systems (IAS-95) Ibrahim F. Imam and Janusz Wnek (Eds.), pp. 38-51, Melbourne Beach, Florida, 1995. Constructive Induction-based
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
CS 1103 Computer Science I Honors. Fall Instructor Muller. Syllabus
 CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Word learning as Bayesian inference
 Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Functional Skills Mathematics Level 2 assessment
 Functional Skills Mathematics Level 2 assessment www.cityandguilds.com September 2015 Version 1.0 Marking scheme ONLINE V2 Level 2 Sample Paper 4 Mark Represent Analyse Interpret Open Fixed S1Q1 3 3 0
Functional Skills Mathematics Level 2 assessment www.cityandguilds.com September 2015 Version 1.0 Marking scheme ONLINE V2 Level 2 Sample Paper 4 Mark Represent Analyse Interpret Open Fixed S1Q1 3 3 0
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Conference Presentation
 Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Mining Association Rules in Student s Assessment Data
 www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
South Carolina College- and Career-Ready Standards for Mathematics. Standards Unpacking Documents Grade 5
 South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents Grade 5 South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents
South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents Grade 5 South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents
Case study Norway case 1
 Case study Norway case 1 School : B (primary school) Theme: Science microorganisms Dates of lessons: March 26-27 th 2015 Age of students: 10-11 (grade 5) Data sources: Pre- and post-interview with 1 teacher
Case study Norway case 1 School : B (primary school) Theme: Science microorganisms Dates of lessons: March 26-27 th 2015 Age of students: 10-11 (grade 5) Data sources: Pre- and post-interview with 1 teacher
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
Informatics 2A: Language Complexity and the. Inf2A: Chomsky Hierarchy
 Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Mining Student Evolution Using Associative Classification and Clustering
 Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Objectives. Chapter 2: The Representation of Knowledge. Expert Systems: Principles and Programming, Fourth Edition
 Chapter 2: The Representation of Knowledge Expert Systems: Principles and Programming, Fourth Edition Objectives Introduce the study of logic Learn the difference between formal logic and informal logic
Chapter 2: The Representation of Knowledge Expert Systems: Principles and Programming, Fourth Edition Objectives Introduce the study of logic Learn the difference between formal logic and informal logic
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
A NEW ALGORITHM FOR GENERATION OF DECISION TREES
 TASK QUARTERLY 8 No 2(2004), 1001 1005 A NEW ALGORITHM FOR GENERATION OF DECISION TREES JERZYW.GRZYMAŁA-BUSSE 1,2,ZDZISŁAWS.HIPPE 2, MAKSYMILIANKNAP 2 ANDTERESAMROCZEK 2 1 DepartmentofElectricalEngineeringandComputerScience,
TASK QUARTERLY 8 No 2(2004), 1001 1005 A NEW ALGORITHM FOR GENERATION OF DECISION TREES JERZYW.GRZYMAŁA-BUSSE 1,2,ZDZISŁAWS.HIPPE 2, MAKSYMILIANKNAP 2 ANDTERESAMROCZEK 2 1 DepartmentofElectricalEngineeringandComputerScience,
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
A General Class of Noncontext Free Grammars Generating Context Free Languages
 INFORMATION AND CONTROL 43, 187-194 (1979) A General Class of Noncontext Free Grammars Generating Context Free Languages SARWAN K. AGGARWAL Boeing Wichita Company, Wichita, Kansas 67210 AND JAMES A. HEINEN
INFORMATION AND CONTROL 43, 187-194 (1979) A General Class of Noncontext Free Grammars Generating Context Free Languages SARWAN K. AGGARWAL Boeing Wichita Company, Wichita, Kansas 67210 AND JAMES A. HEINEN
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C
 Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
ABSTRACT. A major goal of human genetics is the discovery and validation of genetic polymorphisms
 ABSTRACT DEODHAR, SUSHAMNA DEODHAR. Using Grammatical Evolution Decision Trees for Detecting Gene-Gene Interactions in Genetic Epidemiology. (Under the direction of Dr. Alison Motsinger-Reif.) A major
ABSTRACT DEODHAR, SUSHAMNA DEODHAR. Using Grammatical Evolution Decision Trees for Detecting Gene-Gene Interactions in Genetic Epidemiology. (Under the direction of Dr. Alison Motsinger-Reif.) A major
arxiv: v1 [math.at] 10 Jan 2016
![arxiv: v1 [math.at] 10 Jan 2016](/thumbs/72/66271209.jpg "arxiv: v1 [math.at] 10 Jan 2016") THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Physics 270: Experimental Physics
 2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
LEGO MINDSTORMS Education EV3 Coding Activities
 LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
CHAPTER 4: REIMBURSEMENT STRATEGIES 24
 CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
Grammars & Parsing, Part 1:
 Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review