Professor E. Ambikairajah. UNSW, Australia. Section 1. Introduction to Speech Processing
|
|
|
- Dustin Jeffry Cox
- 5 years ago
- Views:
Transcription
1 Section Introduction to Speech Processing Acknowledgement: This lecture is mainly derived from Rabiner, L., and Juang, B.-H., Fundamentals of Speech Recognition, Prentice-Hall, New Jersey, 993
2 Introduction to Speech Processing Speech processing is the application of digital signal processing DSP techniques to the processing and\or analysis of speech signals Applications of speech processing include Speech Coding Speech Recognition Speaker Verification\Identification Speech Enhancement Speech Synthesis Text to Speech Conversion 2
3 Process of Speech Production Figure shows a schematic diagram of the speech production/speech perception process in human beings The speech production process begins when the talker formulates a message in his/her mind to transmit to the listener via speech The next step in the process is the conversion of the message into a language code. This corresponds to converting the message into a set of phoneme sequences corresponding to the sounds that make up the words, along with prosody syntax markers denoting duration of sounds, loudness of sounds, and pitch associated with the sounds. 3
4 Process of Speech Production Once the language code is chosen the talker must execute a series of neuromuscular commands to cause the vocal cords to vibrate when appropriate and to shape the vocal tract such that the proper sequence of speech sounds is created and spoken by the talker, thereby producing an acoustic signal as the final output. The neuromuscular commands must simultaneously control all aspects of articulatory motion including control of the lips, jaw, tongue and velum. 4
5 Process of Speech Perception Once the speech signal is generated and propagated to the listener, the speech perception process begins. A neural transduction process converts the spectral signal at the output of the basilar membrane into activity signals on the auditory nerve, corresponding roughly to a feature extraction process. The neural activity along the auditory nerve is converted into a language code at higher centres of processing within the brain, and finally message comprehension understanding of meaning is achieved. 5
6 Information Rate of the Speech Signal The discrete symbol information rate in the raw message text is rather low about 50 bits per second corresponding to about 8 sounds per second, where each sound is one of the about 50 distinct symbols After the language code conversion, with the inclusion of prosody information, the information rate rises to about 200 bps 6
7 text message formulation semantics message understanding discrete input information rate phonemes, prosody language code phonemes, words, sentences discrete output language translation SPEECH GENERATION articulatory motions neuro-muscular controls feature extraction, coding neural transduction continuous input vocal tract system 50 bit/s 200 bit/s 2000 bit/s kbit/s SPEECH RECOGNITION Figure. continuous output spectrum analysis basilar membrane motion acoustic waveform acoustic waveform 7
8 Information Rate of the Speech Signal In the next stage the representation of the information in the signal becomes continuous with an equivalent rate of about 2000 bps at the neuromuscular control level and about 30,000-50,000 bps at the acoustic signal level. The continuous information rate at the basilar membrane is in the range of 30,000-50,000 bps, while at the neural transduction stage it is about 2000 bps. The higher level processing within the brain converts the neural signals to a discrete representation, which ultimately is decoded into a low bit rate message. 8
9 The mechanism of Speech Production In order to apply DSP techniques to speech processing problems it is important to understand the fundamentals of the speech production process. Speech signals are composed of a sequence of sounds and the sequence of sounds are produced as a result of acoustical excitation of the vocal tract when air is expelled from the lungs See figure.2 9
10 Speech Production Mechanism Vocal tract begins at the opening between the vocal cords and ends at the lips In the average male, the total length of the vocal tract is about 7 cm. The cross-ectional area of the vocal, determined by the positions of the tongue, lips, jaw and velum varies from ero complete closure to about 20 cm 2. Lips Vocal folds 0

11 Speech Production Mechanism The nasal tract begins at the velum and ends at the nostrilss When the velum is lowered, the nasal tract is acoustically coupled to the vocal tract to produce the nasal sounds of speech. Lips Vocal folds
12 Classification of Speech Sounds In speech processing, speech sounds are divided into TWO broad classes which depend on the role of the vocal chords on the speech production mechanism VOICED speech is produced when the vocal chords play an active role i.e. vibrate in the production of a sound: Examples: Voiced sounds /a/, /e/, /i/ UNVOICED speech is produced when vocal chords are inactive Examples: unvoiced sounds /s/, /f/ 2
13 Voiced Speech Voiced speech occurs when air flows through the vocal chords into the vocal tract in discrete puffs rather than as a continuous flow Glottal volume velocity The vocal chords vibrate at a particular frequency, which is called the fundamental frequency of the sound 50 : 200 H for male speakers 50:300 H for female speakers 200:400 H child speakers Time 3
14 Unvoiced Speech For unvoiced speech, the vocal chords are held open and air flows continuously through them The vocal tract, however, is narrowed resulting in a turbulent flow of air along the tract Examples include the unvoiced fricatives /f/ & /s/ Characterised by high frequency components 4
15 Other Sound Classes Nasal Sounds Vocal tract coupled acoustically with nasal cavity through velar opening Sound radiated from nostrils as well as lips Examples include m, n, ing Plosive Sounds Characterised by complete closure/constriction towards front of the vocal tract Build up of pressure behind closure, sudden release Examples include p, t, k 5
16 Resonant Frequencies of Vocal Tract Vocal Tract is a non-uniform acoustic tube that is terminated at one end by the vocal chords and at the other end by the lips The Cross-sectional area of the vocal tract determined by the positions of the tongue, lips, jaw and velum.depends on lips, tongue, jaw and velum The spectrum of vocal tract response consists of a number of resonant frequencies of the vocal tract. These frequencies are called Formants Three to four formants present below 4kH of speech 6
17 Formant Frequencies Speech normally exhibits one formant frequency in every kh For VOICED speech, the magnitude of the lower formant frequencies is successively larger than the magnitude of the higher formant frequencies see Fig.3_ For UNVOICED speech, the magnitude of the higher formant frequencies is successively larger than the magnitude of the lower formant frequencies see Fig.3 7
18 .3: 8
19 Basic Assumptions of Speech Processing The basic assumption of almost all speech processing systems is that the source of excitation and the vocal tract system are independent. Therefore, it is a reasonable approximation to model the source of excitation and the vocal tract system separately as shown Figure.3 The vocal tract changes shape rather slowly in continuous speech and it is reasonable to assume that the vocal tract has a fixed characteristics over a time interval of the order of 0 ms. Thus once every 0 ms, on average, the vocal tract configuration is varied producing new vocal tract parameters resonant frequencies 9
20 Speech Sounds Phonemes: smallest segments of speech sounds /d/ and /b/ are distinct phonemes e.g. dark and bark It is important to realise, that phonemes are abstract linguistic units and may not be directly observed in the speech signal Different speakers producing the same string of phonemes convey the same information yet sound different as a result of differences in dialect and vocal tract length and shape. There are about 40 phonemes in English See Table A for IPA International Phonetic Alphabet symbol for each phoneme together with sample words in which they occur. 20

21 Acoustic Waveforms 2

22 Frame of waveform 22
23 The speech signal is a slowly time varying signal in the sense that when examined over sufficiently short period of time, its characteristics are fairly stationary. 23
24 Speech Production Model 24
25 Model for Speech Production To develop an accurate model for how speech is produced, it is necessary to develop a digital filter based model of the human speech production mechanism Model must accurately represent Figure.4: The excitation mechanism of speech production system The operation of the vocal tract The lip\nasal radiation process Both voiced & unvoiced speech for 0-20 ms 25
26 Figure.4: Discrete Time Model for Speech Production 26
27 Excitation Process The excitation process must take into account:- The voiced\unvoiced nature of speech The operation of the glottis The energy of the speech signal in a given 0-30 ms frame of speech The nature of the excitation function of the model will be different dependent on the nature of the speech sounds being produced For voiced speech, the excitation will be a train of unit impulses spaced at intervals of the pitch period e[n]=δ[n-pk] k=0,,2 For unvoiced speech, the excitation will be a random noise-like signal e[n]=random[n] 27
28 28 Excitation Source Voiced Speech Impulse train: en=δn-pk k=0,,2 en t P P { } P P P n n n n n n E E n e n e n e Z E =+ = =+ = = = = =
29 Excitation Process The next stage in the excitation process will be a model of the pulse shaping operation of the glottis This is only used for VOICED speech Typically used transfer function for the glottal model are: G = ct e But ct <<, e G ct 2 2 where c : speed of sound for voiced speech, G = for unvoiced speech 29
30 Glottal Pulse and Spectrum 30
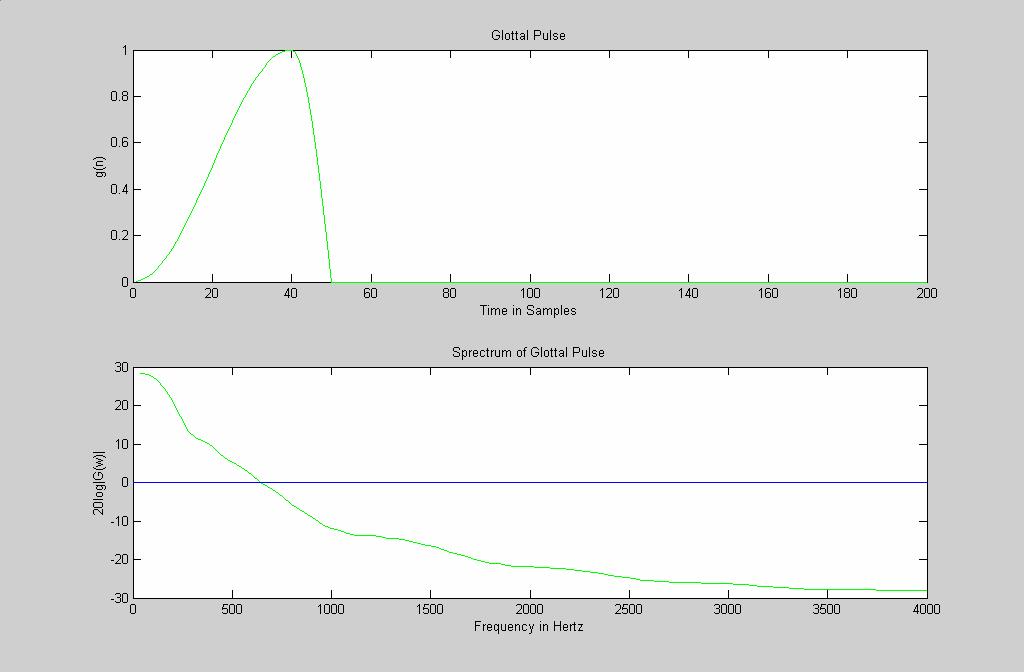
31 3
32 g Exercise: Glottal Pulse & Spectrum Plot n The following expression can be used to model the glottal pulse. Write a matlab script to plot the pulse and its spectrum. N =40 and N 2 = 0 [ cos πn / N] 2 = cos π n N /2N 0 0 n N N n N otherwise 32 + N 2 2
33 Excitation Process Finally, the energy of the sound is modelled by a gain factor Typically the gain factor for voiced speech A v will be in the region of 0 times that of unvoiced speech A uv Thus the signal coming out of the complete excitation process will be: x[n]=ae[n]*g[n], or X=AEG 33
34 Discrete Time Model of Excitation Process Impulse Generator Random Noise Generator e[n] e[n] P 2P 3P Voiced Unvoiced 4P e[n] time Glottal Pulse Shaping Model G time u g [n] A v \A uv 34 x[n]


35 Vocal Tract Model The vocal tract can be modelled acoustically as a series of short cylindrical tubes Model consists of N lossless tubes each of length l and cross sectional area A Total length = NL Waves propagated down tube are partially reflected and partially junctions 35
36 Lossless Tubes Model τ is time taken for wave to propagate through single section τ = l/c.c is speed of sound in air It has been shown that to represent the vocal tract by a discrete time system it should be sampled every 2τ seconds fs Fs = /2 τ τ = c/2l = Nc/2L Thus fs is proportional to number of lossless tubes Recall length of vocal tract is about 7cm 36
37 Vocal Tract Model This acoustic model can be converted into a time varying digital filter model For either voiced or unvoiced speech, the underlying spectrum of the vocal tract will exhibit distinct frequency peaks These are known as the FORMANT frequencies of the vocal tract Ideally, the vocal tract model should implement at least three or four of the formants 37
38 Formant Frequencies Speech normally exhibits one formant frequency in every kh For VOICED speech, the magnitude of the lower formant frequencies is successively larger than the magnitude of the higher formant frequencies For UNVOICED speech, the magnitude of the higher formant frequencies is successively larger than the magnitude of the lower formant frequencies 38
39 Voiced Speech 39
40 Unvoiced Speech 40
41 Vocal Tract Model Voiced Speech For voiced speech, the vocal tract model can be adequately represented by an all pole model Typically, two poles are required for each resonance, or formant frequency The all-pole model can be viewed as a casacade of 2 nd order resonators 2 poles each Thus, the transfer function for the vocal tract will be V U l = = = K p U g 2 + b + + k ck k = k = a k k 4
42 42 Discrete Time Model for Voiced Speech Production en T T t Impulse Train Generator Global Pulse Model gn t A v sn Vocal Tract Model vn en Radiation Model rn u g n u g n u l n [ ] * * * * * * R V G A E S n r n v n g n e A n s n r n u n s n v n u n u n g n e A n u V V l g l V g = = = = =
43 Vocal Tract Model Unvoiced Speech Because of the nature of the turbulent air flow which creates unvoiced speech, the vocal tract model requires both poles and eroes for unvoiced speech A single ero in a transfer function can be approximated by TWO poles Thus the transfer function for the vocal tract L will be: k + b k k = V = P P+ 2L k + a + k k = k = a k k 43
44 Exercise: 2 nd Order Pole Approximation Show that of a < a to eros = n= n= 0 a n And thus a ero can be approximated as closely as desired by two poles n 44
45 Lip Radiation Model The volume velocity at the lips is transformed into an acoustic pressure waveform some distance away from the lips. The typical lip radiation model used is that of a simple high pass filter, with the transfer function: R=- - 45
46 Exercise: Lip Radiation Model The following is an approximation to the lip radiation model. R= Use Matlab to plot the frequency response, Rθ of the model 46
47 Frequency Response of Lip Radiation Model 47
48 Overall Speech Production Model Excitation Model E Transfer Function: Vocal Tract Model V S=EGAVR S E = AG V R Lip Radiation Model R Speech Signal s[n] 48
49 49 Overall Transfer Function For Voiced Speech: + = = = + = + = + = = 2 ' P k k k v P k k k v P k k k v v a A a A E S a A E S R V A G E S
50 50 Overall Transfer Function For unvoiced speech: + + = + = + = + = + = + = = ' L P k k k uv L P k k k uv L P k k k uv uv a A a A E S a A E S R V G A E S
51 Overall Transfer Function Clearly, for EITHER form of speech sound, the model exhibits a transfer function of the form S E = q + k = a' k It is simply a matter of selecting the order of the model q such that it is sufficiently complex to represent both voiced and unvoiced speech frames Typical values of q used are 0, 2 or 4 G k 5
52 Use of the Vocal Tract Model The model of the vocal tract which has been outlined can be made to be a very accurate model of speech production for short 0-30 ms frames of speech samples It is widely used in modern low bit rate speech coding algorithms, as well as speech synthesis and speech recognition\speaker identification systems It is necessary to develop a technique which allows the coefficients of the model to be determined for a given frame of speech The most commonly used technique is called Linear Predictive Coding LPC 52
53 en Model for Speech Analysis Impulse Train Generator en t Global Pulse Model Random Noise Generator gn A v A uv T T t Vocal Tract Model It is possible to combine the components into one all pole model as shown previously en p k = a k k sn 53
54 Impulse Train Generator Random Noise Generator Refinement of this Model T T t un Vocal Tract Model p k = a k Parameters of this model: a k, G, T, v/uv classification G k 54 sn
55 55 Vocal Tract Model We have already deduced the transfer function relating the vocal tract excitation function to the speech signal ] [ ] [ ] [ n Gu k n s a n s a G U S q k k q k k k + = + = = =
56 Exercise: The waveform plot given below is for the word cattle. Note that each line of the plot corresponds to 0 ms of the signal. a Indicate the boundaries between the phonemes; i.e give the times corresponding to the boundaries /c/a/tt/le/. b Indicate the point where the voice pitch frequency is i the highest; and ii the lowest. Where are the approximate pitch frequencies at these points? c Is the speaker most probably a male, or a child? How do you know. 56
57 Speech waveform of the word Cattle 57
58 The lowest pitch has a period of about 2.5 ms corresponding to the frequency 46 H. This low pitch indicates the speaker is probably 58male
59 Exercise: The transfer function of the glottal model is given by G = e ct 2 e ct 2 where c is a constant and T is the sampling period 25 μs. Obtain the frequency response, Gθ, where θ is the digital frequency. Obtain expressions for the magnitude i Gθ at DC; ii Gθ at half the sampling frequency. Calculate the magnitude ratio of i/ii above in db. If the magnitude ratio is chosen to be 40 db, then calculate the value of the constant c. 59
60 60
61 6
62 62
63 63
64 64
65 65
66 66
67 67
68 68
69 69
70 70
Consonants: articulation and transcription
 Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Quarterly Progress and Status Report. VCV-sequencies in a preliminary text-to-speech system for female speech
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
 " 'rear,.': T OOM 36-41L v CHU
" 'rear,.': T OOM 36-41L v CHU Phonetics. The Sound of Language
 Phonetics. The Sound of Language 1 The Description of Sounds Fromkin & Rodman: An Introduction to Language. Fort Worth etc., Harcourt Brace Jovanovich Read: Chapter 5, (p. 176ff.) (or the corresponding
Phonetics. The Sound of Language 1 The Description of Sounds Fromkin & Rodman: An Introduction to Language. Fort Worth etc., Harcourt Brace Jovanovich Read: Chapter 5, (p. 176ff.) (or the corresponding
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
On Developing Acoustic Models Using HTK. M.A. Spaans BSc.
 On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
age, Speech and Hearii
 age, Speech and Hearii 1 Speech Commun cation tion 2 Sensory Comm, ection i 298 RLE Progress Report Number 132 Section 1 Speech Communication Chapter 1 Speech Communication 299 300 RLE Progress Report
age, Speech and Hearii 1 Speech Commun cation tion 2 Sensory Comm, ection i 298 RLE Progress Report Number 132 Section 1 Speech Communication Chapter 1 Speech Communication 299 300 RLE Progress Report
Voice conversion through vector quantization
 J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
A comparison of spectral smoothing methods for segment concatenation based speech synthesis
 D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Perceptual scaling of voice identity: common dimensions for different vowels and speakers
 DOI 10.1007/s00426-008-0185-z ORIGINAL ARTICLE Perceptual scaling of voice identity: common dimensions for different vowels and speakers Oliver Baumann Æ Pascal Belin Received: 15 February 2008 / Accepted:
DOI 10.1007/s00426-008-0185-z ORIGINAL ARTICLE Perceptual scaling of voice identity: common dimensions for different vowels and speakers Oliver Baumann Æ Pascal Belin Received: 15 February 2008 / Accepted:
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Quarterly Progress and Status Report. Voiced-voiceless distinction in alaryngeal speech - acoustic and articula
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
An Acoustic Phonetic Account of the Production of Word-Final /z/s in Central Minnesota English
 Linguistic Portfolios Volume 6 Article 10 2017 An Acoustic Phonetic Account of the Production of Word-Final /z/s in Central Minnesota English Cassy Lundy St. Cloud State University, casey.lundy@gmail.com
Linguistic Portfolios Volume 6 Article 10 2017 An Acoustic Phonetic Account of the Production of Word-Final /z/s in Central Minnesota English Cassy Lundy St. Cloud State University, casey.lundy@gmail.com
Automatic segmentation of continuous speech using minimum phase group delay functions
 Speech Communication 42 (24) 429 446 www.elsevier.com/locate/specom Automatic segmentation of continuous speech using minimum phase group delay functions V. Kamakshi Prasad, T. Nagarajan *, Hema A. Murthy
Speech Communication 42 (24) 429 446 www.elsevier.com/locate/specom Automatic segmentation of continuous speech using minimum phase group delay functions V. Kamakshi Prasad, T. Nagarajan *, Hema A. Murthy
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
Audible and visible speech
 Building sensori-motor prototypes from audiovisual exemplars Gérard BAILLY Institut de la Communication Parlée INPG & Université Stendhal 46, avenue Félix Viallet, 383 Grenoble Cedex, France web: http://www.icp.grenet.fr/bailly
Building sensori-motor prototypes from audiovisual exemplars Gérard BAILLY Institut de la Communication Parlée INPG & Université Stendhal 46, avenue Félix Viallet, 383 Grenoble Cedex, France web: http://www.icp.grenet.fr/bailly
COMMUNICATION DISORDERS. Speech Production Process
 Communication Disorders 165 implementing the methods selected; monitoring and evaluating the learning process to make sure progress is being made toward the goal; modifying or replacing strategies if they
Communication Disorders 165 implementing the methods selected; monitoring and evaluating the learning process to make sure progress is being made toward the goal; modifying or replacing strategies if they
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
COMPUTER INTERFACES FOR TEACHING THE NINTENDO GENERATION
 Session 3532 COMPUTER INTERFACES FOR TEACHING THE NINTENDO GENERATION Thad B. Welch, Brian Jenkins Department of Electrical Engineering U.S. Naval Academy, MD Cameron H. G. Wright Department of Electrical
Session 3532 COMPUTER INTERFACES FOR TEACHING THE NINTENDO GENERATION Thad B. Welch, Brian Jenkins Department of Electrical Engineering U.S. Naval Academy, MD Cameron H. G. Wright Department of Electrical
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Voiceless Stop Consonant Modelling and Synthesis Framework Based on MISO Dynamic System
 ARCHIVES OF ACOUSTICS Vol. 42, No. 3, pp. 375 383 (2017) Copyright c 2017 by PAN IPPT DOI: 10.1515/aoa-2017-0039 Voiceless Stop Consonant Modelling and Synthesis Framework Based on MISO Dynamic System
ARCHIVES OF ACOUSTICS Vol. 42, No. 3, pp. 375 383 (2017) Copyright c 2017 by PAN IPPT DOI: 10.1515/aoa-2017-0039 Voiceless Stop Consonant Modelling and Synthesis Framework Based on MISO Dynamic System
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION. Adam B. Buchwald
 SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION by Adam B. Buchwald A dissertation submitted to The Johns Hopkins University in conformity with the requirements
SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION by Adam B. Buchwald A dissertation submitted to The Johns Hopkins University in conformity with the requirements
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
School of Innovative Technologies and Engineering
 School of Innovative Technologies and Engineering Department of Applied Mathematical Sciences Proficiency Course in MATLAB COURSE DOCUMENT VERSION 1.0 PCMv1.0 July 2012 University of Technology, Mauritius
School of Innovative Technologies and Engineering Department of Applied Mathematical Sciences Proficiency Course in MATLAB COURSE DOCUMENT VERSION 1.0 PCMv1.0 July 2012 University of Technology, Mauritius
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
Problems of the Arabic OCR: New Attitudes
 Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Word Stress and Intonation: Introduction
 Word Stress and Intonation: Introduction WORD STRESS One or more syllables of a polysyllabic word have greater prominence than the others. Such syllables are said to be accented or stressed. Word stress
Word Stress and Intonation: Introduction WORD STRESS One or more syllables of a polysyllabic word have greater prominence than the others. Such syllables are said to be accented or stressed. Word stress
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
A student diagnosing and evaluation system for laboratory-based academic exercises
 A student diagnosing and evaluation system for laboratory-based academic exercises Maria Samarakou, Emmanouil Fylladitakis and Pantelis Prentakis Technological Educational Institute (T.E.I.) of Athens
A student diagnosing and evaluation system for laboratory-based academic exercises Maria Samarakou, Emmanouil Fylladitakis and Pantelis Prentakis Technological Educational Institute (T.E.I.) of Athens
Universal contrastive analysis as a learning principle in CAPT
 Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
International Journal of Advanced Networking Applications (IJANA) ISSN No. :
 ISSN No. :") International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Ansys Tutorial Random Vibration
 Ansys Tutorial Random Free PDF ebook Download: Ansys Tutorial Download or Read Online ebook ansys tutorial random vibration in PDF Format From The Best User Guide Database Random vibration analysis gives
Ansys Tutorial Random Free PDF ebook Download: Ansys Tutorial Download or Read Online ebook ansys tutorial random vibration in PDF Format From The Best User Guide Database Random vibration analysis gives
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Degree Qualification Profiles Intellectual Skills
 Degree Qualification Profiles Intellectual Skills Intellectual Skills: These are cross-cutting skills that should transcend disciplinary boundaries. Students need all of these Intellectual Skills to acquire
Degree Qualification Profiles Intellectual Skills Intellectual Skills: These are cross-cutting skills that should transcend disciplinary boundaries. Students need all of these Intellectual Skills to acquire
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
THE MULTIVOC TEXT-TO-SPEECH SYSTEM
 THE MULTVOC TEXT-TO-SPEECH SYSTEM Olivier M. Emorine and Pierre M. Martin Cap Sogeti nnovation Grenoble Research Center Avenue du Vieux Chene, ZRST 38240 Meylan, FRANCE ABSTRACT n this paper we introduce
THE MULTVOC TEXT-TO-SPEECH SYSTEM Olivier M. Emorine and Pierre M. Martin Cap Sogeti nnovation Grenoble Research Center Avenue du Vieux Chene, ZRST 38240 Meylan, FRANCE ABSTRACT n this paper we introduce
Klaus Zuberbühler c) School of Psychology, University of St. Andrews, St. Andrews, Fife KY16 9JU, Scotland, United Kingdom
 School of Psychology, University of St. Andrews, St. Andrews, Fife KY16 9JU, Scotland, United Kingdom") Published in The Journal of the Acoustical Society of America, Vol. 114, Issue 2, 2003, p. 1132-1142 which should be used for any reference to this work 1 The relationship between acoustic structure and
Published in The Journal of the Acoustical Society of America, Vol. 114, Issue 2, 2003, p. 1132-1142 which should be used for any reference to this work 1 The relationship between acoustic structure and
5.1 Sound & Light Unit Overview
 5.1 Sound & Light Unit Overview Enduring Understanding: Sound and light are forms of energy that travel and interact with objects in various ways. Essential Question: How is sound energy transmitted, absorbed,
5.1 Sound & Light Unit Overview Enduring Understanding: Sound and light are forms of energy that travel and interact with objects in various ways. Essential Question: How is sound energy transmitted, absorbed,
Automatic intonation assessment for computer aided language learning
 Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Course Law Enforcement II. Unit I Careers in Law Enforcement
 Course Law Enforcement II Unit I Careers in Law Enforcement Essential Question How does communication affect the role of the public safety professional? TEKS 130.294(c) (1)(A)(B)(C) Prior Student Learning
Course Law Enforcement II Unit I Careers in Law Enforcement Essential Question How does communication affect the role of the public safety professional? TEKS 130.294(c) (1)(A)(B)(C) Prior Student Learning
Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions
 26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
Expressive speech synthesis: a review
 Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
PELLISSIPPI STATE TECHNICAL COMMUNITY COLLEGE MASTER SYLLABUS APPLIED MECHANICS MET 2025
 PELLISSIPPI STATE TECHNICAL COMMUNITY COLLEGE MASTER SYLLABUS APPLIED MECHANICS MET 2025 Class Hours: 3.0 Credit Hours: 4.0 Laboratory Hours: 3.0 Revised: Fall 06 Catalog Course Description: A study of
PELLISSIPPI STATE TECHNICAL COMMUNITY COLLEGE MASTER SYLLABUS APPLIED MECHANICS MET 2025 Class Hours: 3.0 Credit Hours: 4.0 Laboratory Hours: 3.0 Revised: Fall 06 Catalog Course Description: A study of
Circuit Simulators: A Revolutionary E-Learning Platform
 Circuit Simulators: A Revolutionary E-Learning Platform Mahi Itagi Padre Conceicao College of Engineering, Verna, Goa, India. itagimahi@gmail.com Akhil Deshpande Gogte Institute of Technology, Udyambag,
Circuit Simulators: A Revolutionary E-Learning Platform Mahi Itagi Padre Conceicao College of Engineering, Verna, Goa, India. itagimahi@gmail.com Akhil Deshpande Gogte Institute of Technology, Udyambag,
The pronunciation of /7i/ by male and female speakers of avant-garde Dutch
 The pronunciation of /7i/ by male and female speakers of avant-garde Dutch Vincent J. van Heuven, Loulou Edelman and Renée van Bezooijen Leiden University/ ULCL (van Heuven) / University of Nijmegen/ CLS
The pronunciation of /7i/ by male and female speakers of avant-garde Dutch Vincent J. van Heuven, Loulou Edelman and Renée van Bezooijen Leiden University/ ULCL (van Heuven) / University of Nijmegen/ CLS
Quarterly Progress and Status Report. Sound symbolism in deictic words
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Sound symbolism in deictic words Traunmüller, H. journal: TMH-QPSR volume: 37 number: 2 year: 1996 pages: 147-150 http://www.speech.kth.se/qpsr
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Sound symbolism in deictic words Traunmüller, H. journal: TMH-QPSR volume: 37 number: 2 year: 1996 pages: 147-150 http://www.speech.kth.se/qpsr
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Dyslexia/dyslexic, 3, 9, 24, 97, 187, 189, 206, 217, , , 367, , , 397,
 Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Evaluation of Various Methods to Calculate the EGG Contact Quotient
 Diploma Thesis in Music Acoustics (Examensarbete 20 p) Evaluation of Various Methods to Calculate the EGG Contact Quotient Christian Herbst Mozarteum, Salzburg, Austria Work carried out under the ERASMUS
Diploma Thesis in Music Acoustics (Examensarbete 20 p) Evaluation of Various Methods to Calculate the EGG Contact Quotient Christian Herbst Mozarteum, Salzburg, Austria Work carried out under the ERASMUS
Beginning primarily with the investigations of Zimmermann (1980a),
,") Orofacial Movements Associated With Fluent Speech in Persons Who Stutter Michael D. McClean Walter Reed Army Medical Center, Washington, D.C. Stephen M. Tasko Western Michigan University, Kalamazoo, MI
Orofacial Movements Associated With Fluent Speech in Persons Who Stutter Michael D. McClean Walter Reed Army Medical Center, Washington, D.C. Stephen M. Tasko Western Michigan University, Kalamazoo, MI
Christine Mooshammer, IPDS Kiel, Philip Hoole, IPSK München, Anja Geumann, Dublin
 1 Title: Jaw and order Christine Mooshammer, IPDS Kiel, Philip Hoole, IPSK München, Anja Geumann, Dublin Short title: Production of coronal consonants Acknowledgements This work was partially supported
1 Title: Jaw and order Christine Mooshammer, IPDS Kiel, Philip Hoole, IPSK München, Anja Geumann, Dublin Short title: Production of coronal consonants Acknowledgements This work was partially supported
A Hybrid Text-To-Speech system for Afrikaans
 A Hybrid Text-To-Speech system for Afrikaans Francois Rousseau and Daniel Mashao Department of Electrical Engineering, University of Cape Town, Rondebosch, Cape Town, South Africa, frousseau@crg.ee.uct.ac.za,
A Hybrid Text-To-Speech system for Afrikaans Francois Rousseau and Daniel Mashao Department of Electrical Engineering, University of Cape Town, Rondebosch, Cape Town, South Africa, frousseau@crg.ee.uct.ac.za,
Listening and Speaking Skills of English Language of Adolescents of Government and Private Schools
 Listening and Speaking Skills of English Language of Adolescents of Government and Private Schools Dr. Amardeep Kaur Professor, Babe Ke College of Education, Mudki, Ferozepur, Punjab Abstract The present
Listening and Speaking Skills of English Language of Adolescents of Government and Private Schools Dr. Amardeep Kaur Professor, Babe Ke College of Education, Mudki, Ferozepur, Punjab Abstract The present
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations
 A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Online Publication Date: 01 May 1981 PLEASE SCROLL DOWN FOR ARTICLE
 This article was downloaded by:[university of Sussex] On: 15 July 2008 Access Details: [subscription number 776502344] Publisher: Psychology Press Informa Ltd Registered in England and Wales Registered
This article was downloaded by:[university of Sussex] On: 15 July 2008 Access Details: [subscription number 776502344] Publisher: Psychology Press Informa Ltd Registered in England and Wales Registered
A Study of the Effectiveness of Using PER-Based Reforms in a Summer Setting
 A Study of the Effectiveness of Using PER-Based Reforms in a Summer Setting Turhan Carroll University of Colorado-Boulder REU Program Summer 2006 Introduction/Background Physics Education Research (PER)
A Study of the Effectiveness of Using PER-Based Reforms in a Summer Setting Turhan Carroll University of Colorado-Boulder REU Program Summer 2006 Introduction/Background Physics Education Research (PER)
Lesson M4. page 1 of 2
 Lesson M4 page 1 of 2 Miniature Gulf Coast Project Math TEKS Objectives 111.22 6b.1 (A) apply mathematics to problems arising in everyday life, society, and the workplace; 6b.1 (C) select tools, including
Lesson M4 page 1 of 2 Miniature Gulf Coast Project Math TEKS Objectives 111.22 6b.1 (A) apply mathematics to problems arising in everyday life, society, and the workplace; 6b.1 (C) select tools, including
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,