Speaker Transformation Algorithm using Segmental Codebooks (STASC) Presented by A. Brian Davis
|
|
|
- Vincent Hicks
- 5 years ago
- Views:
Transcription
1 Speaker Transformation Algorithm using Segmental Codebooks (STASC) Presented by A. Brian Davis
2 Speaker Transformation Goal: map acoustic properties of one speaker onto another Uses: Personification of text-speech systems Multimedia Preprocessing step for speech recognition Reduce speaker variability Practical?
3 Steps Involved Training phase Given speech input from source and target, form spectral transformation Inputs / outputs to transformation: Segment speech small chunks (frames) Formants LPC cepstrum coefficients Others (excitation)? Can we generalize behavior of transform? Codebooks/codewords Vector quantization
4 Vector quantization Assign vectors to discrete set of values K-Means For STASC, also want average all vectors assigned to a class K-Means gives us this for free Shamelessly stolen from Dr. Gutierrez's pattern recognition slides
5 LSFs Line spectral frequencies Derived (losslessly) from LPC's Can convert to/from, thus can create speech from LSFs Relate to formant frequencies Used in STASC represent vocal tract of speakers Stable Why use instead of MFCCs?
6 STASC (first method) Assumes orthographic transcription What's said, in writing From transcription, phonemes retrieved Speech segments assigned phoneme based on transcription MFCCs, dmfccs for each segment (frame) passed into HMM, most likely path using Viterbi algorithm LSFs calculated per frame, labeled with phoneme from HMM Phoneme centroids calculated (average LSF values all vectors labeled particular phoneme One-one mapping
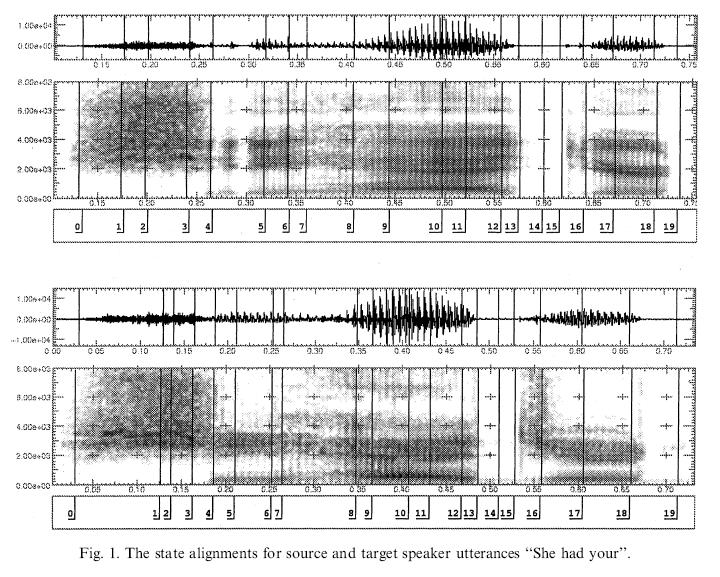
7
8 Second method (better) No orthographic transcription Intuitively, we know the HMM states in 1 st method didn't need correspond phonemes Require speakers speak same (hopefully phonetically balanced) sentence Sentences with phones approx. distributed as in normal speech Because fewer restrictions, need to do some extra processing of speaker's speech Normalize root-mean-squared energy Remove silence before/after speech
9 Second method transformation HMM trained on each sentence Data from source speaker's speech segments LSF vectors Number of states correspond sentence length Segmental k-means, separates speech segments into clusters Baum-Welch algorithm train HMM on cluster averages Covariance matrix uniform For source/target speech segments, Viterbi algorithm assigns segments to states. Transformation moves segments from state in source to state in target Centroids
10 Excitation characteristic From previous papers, know excitation greatly influences perception of speaker Not trivial to transfer Very different for voiced / unvoiced sounds Use current codebooks to transfer excitation Calculate short-time average magnitude spectrum of excitation signal each speech unit
11 Codebook weight estimation Assume we have vector w of LSFs labeled with HMM state Also centroids Si of each HMM state Algorithm: Calculate distances di from w to Si Perceptual distance closely spaced LSFs correspond to formant locations given higher weight From distances, calculate weights vi, represent w as linear combination Si's Minimize error?
12 Gradient Descent Find local optimum weights minimize error reconstructed LSFs vs actual LSFs Algorithm: Find gradient of difference reconstruction, predicted (weighted perceptually) Weight gradient by small value (speed to convergence) Add to old weights Until difference in weights between iterations is sufficiently small Found that only few weights given large value Only use 5 most likely weights 15% additional reduction in Itakura-Saito distance,.4 db error
13 Use of weights Given reconstruct LSF vector (segment of speech from speaker) from linear combination of sigmoids Use those weights and target's sigmoids, use resulting LSFs to reconstruct speech Other transformations? Excitation spectral characteristics Prosody Can estimate new weights for all, but why? Artist's impression
14 Excitation and Vocal Tract Use weights construct excitation filter linear combination of sigmoids' ( average target excitation magnitude spectra ) over (source EMS) Use weights construct vocal tract spectrum convert transformed LSF vectors to LPCs V t = 1 P 1 k=1 a k t e jk Expansion of bandwidths; gives unnatural speech
15 Bandwidth modification Assume average formant bandwidth values of target speaker similar most likely target codeword (LSF centroid) Since LSFs correspond to formant locations / bandwidths, change bandwidths by changing adjacent LSF distances Algorithm: Find LSF entries directly before/after each formant location in most likely Target codeword Calculate average formant bandwidth Same for corresponding speech segment LSF vectors form ratio of average codeword bandwidth over segment bandwidth Apply estimated bandwidth ratio to adjust LSFs of speech segment vectors Enforce reasonable bandwidths (average bandwidth of most likely centroid from target speech over 20
16 Bandwidth modification result
17 Prosodic Transformation Pitch, duration, energy modified to mimic target Dynamic segment lengths Constant for unvoiced, 2-3 pitch periods for voiced Pitch: No weights involved Modify f0 linearly, matching variance f0s, matching averages
18 Duration Uniform duration matching? Different people pronounce different phonemes differently Need finer control duration modification
19 Duration modification Duration phoneme dependent context (coarticulation) Triphones as speech units Find speech unit centroids (durations), weights per segment, form target duration as linear combination Uses? Human transcription
20 Energy scale modification Another characteristic of speaker Algorithm (finding energy scaling factor per time frame): Calculate RMS energy for each codeword Derive weights for representing scaling factor as linear combination (target's RMS energy) over (source's RMS energy) After applying other modifications, scale energy
21 Evaluations Want to test effectiveness of transformation Speaker recognition Speech recognition Objective and subjective Automatic speech recognizer Human subjects Test
22 Objective Idea: confuse a speaker recognition machine Stacking the deck Confidence measure The machine: st =log P X t P X s 256 mixture Gaussian mixture models 24 dimension feature vector (MFCCs, deltas) Binary split vector quantization One vector for all, split to two in arbitrary directions Train HMM 3 speakers, speaking 1 hour each; 45 minutes for training Different sentences (first method) 15 minutes set aside for testing
23 Testing Multiple speakers Each transformed to another Context dependent Target Source
24 Objective (2) Sentence HMM Source / target speak same sentences 15 minutes speech from 2 M, 1F Transform 1 M into M/F Phonetic codebooks also used; compare the two Measure fidelity to: Cepstrum Excitation spectrum RMS energy F0 Duration Results show sentence HMM better; increased training
25 Objective (2)
26 Subjective Listening experiments no cheating ABX test 20 stimuli presented A, B listened to; X presented; (2-3 word phrases) Is X perceptually closer to A or to B in terms of speaker identity HMM based transformation 100% M-F, 78% M-M But is it a garbled mess?
27 Intelligibility 150 short nonsense sentences (prevent inference) Shipping gray paint hands even Phone accuracy of natural, transformed speech compared. Phones retrieved from dictionary 93.8% accuracy transformed, 93.4% accuracy natural Target speaker more intelligible?
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Voice conversion through vector quantization
 J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
A comparison of spectral smoothing methods for segment concatenation based speech synthesis
 D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
Quarterly Progress and Status Report. VCV-sequencies in a preliminary text-to-speech system for female speech
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment
 Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions
 26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
International Journal of Advanced Networking Applications (IJANA) ISSN No. :
 ISSN No. :") International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Rachel E. Baker, Ann R. Bradlow. Northwestern University, Evanston, IL, USA
 LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing
 Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Expressive speech synthesis: a review
 Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Digital Signal Processing: Speaker Recognition Final Report (Complete Version)
") Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations
 A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Self-Supervised Acquisition of Vowels in American English
 Self-Supervised Acquisition of Vowels in American English Michael H. Coen MIT Computer Science and Artificial Intelligence Laboratory 32 Vassar Street Cambridge, MA 2139 mhcoen@csail.mit.edu Abstract This
Self-Supervised Acquisition of Vowels in American English Michael H. Coen MIT Computer Science and Artificial Intelligence Laboratory 32 Vassar Street Cambridge, MA 2139 mhcoen@csail.mit.edu Abstract This
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
Vimala.C Project Fellow, Department of Computer Science Avinashilingam Institute for Home Science and Higher Education and Women Coimbatore, India
 World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Self-Supervised Acquisition of Vowels in American English
 Self-Supervised cquisition of Vowels in merican English Michael H. Coen MIT Computer Science and rtificial Intelligence Laboratory 32 Vassar Street Cambridge, M 2139 mhcoen@csail.mit.edu bstract This paper
Self-Supervised cquisition of Vowels in merican English Michael H. Coen MIT Computer Science and rtificial Intelligence Laboratory 32 Vassar Street Cambridge, M 2139 mhcoen@csail.mit.edu bstract This paper
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Rhythm-typology revisited.
 DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
 " 'rear,.': T OOM 36-41L v CHU
" 'rear,.': T OOM 36-41L v CHU 1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
Affective Classification of Generic Audio Clips using Regression Models
 Affective Classification of Generic Audio Clips using Regression Models Nikolaos Malandrakis 1, Shiva Sundaram, Alexandros Potamianos 3 1 Signal Analysis and Interpretation Laboratory (SAIL), USC, Los
Affective Classification of Generic Audio Clips using Regression Models Nikolaos Malandrakis 1, Shiva Sundaram, Alexandros Potamianos 3 1 Signal Analysis and Interpretation Laboratory (SAIL), USC, Los
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
The IRISA Text-To-Speech System for the Blizzard Challenge 2017
 The IRISA Text-To-Speech System for the Blizzard Challenge 2017 Pierre Alain, Nelly Barbot, Jonathan Chevelu, Gwénolé Lecorvé, Damien Lolive, Claude Simon, Marie Tahon IRISA, University of Rennes 1 (ENSSAT),
The IRISA Text-To-Speech System for the Blizzard Challenge 2017 Pierre Alain, Nelly Barbot, Jonathan Chevelu, Gwénolé Lecorvé, Damien Lolive, Claude Simon, Marie Tahon IRISA, University of Rennes 1 (ENSSAT),
Automatic segmentation of continuous speech using minimum phase group delay functions
 Speech Communication 42 (24) 429 446 www.elsevier.com/locate/specom Automatic segmentation of continuous speech using minimum phase group delay functions V. Kamakshi Prasad, T. Nagarajan *, Hema A. Murthy
Speech Communication 42 (24) 429 446 www.elsevier.com/locate/specom Automatic segmentation of continuous speech using minimum phase group delay functions V. Kamakshi Prasad, T. Nagarajan *, Hema A. Murthy
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY
 TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
Automatic intonation assessment for computer aided language learning
 Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
On Developing Acoustic Models Using HTK. M.A. Spaans BSc.
 On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
Letter-based speech synthesis
 Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Arabic Orthography vs. Arabic OCR
 Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language
 Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation
 UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
Modern TTS systems. CS 294-5: Statistical Natural Language Processing. Types of Modern Synthesis. TTS Architecture. Text Normalization
 CS 294-5: Statistical Natural Language Processing Speech Synthesis Lecture 22: 12/4/05 Modern TTS systems 1960 s first full TTS Umeda et al (1968) 1970 s Joe Olive 1977 concatenation of linearprediction
CS 294-5: Statistical Natural Language Processing Speech Synthesis Lecture 22: 12/4/05 Modern TTS systems 1960 s first full TTS Umeda et al (1968) 1970 s Joe Olive 1977 concatenation of linearprediction