Reinforcement Learning II
|
|
|
- Tracey Johns
- 6 years ago
- Views:
Transcription
1 CSC411 Fall 2015 Machine Learning & Data Mining Reinforcement Learning II Slides from Rich Zemel
2 Formula(ng Reinforcement Learning World described by a discrete, 0inite set of states and actions At every time step t, we are in a state s t, and we: Take an action a t (possibly null action) Receive some reward r t+1 Move into a new state s t+1 Decisions can be described by a policy a selection of which action to take, based on the current state Aim is to maximize the total reward we receive over time Sometimes a future reward is discounted by γ k- 1, where k is the number of time- steps in the future when it is received
3 Basic Problems Markov Decision Problem (MDP): tuple <S,A,P,γ> where P is Standard MDP problems: 1. Planning: given complete Markov decision problem as input, compute policy with optimal expected return 2. Learning: Only have access to experience in the MDP, learn a near- optimal strategy
4 MDP formula(on Goal: 0ind policy π that maximizes expected accumulated future rewards V π (s t ), obtained by following π from state s t : Game show example: assume series of questions, increasingly dif0icult, but increasing payoff choice: accept accumulated earnings and quit; or continue and risk losing everything
5 What to Learn We might try to learn the function V (which we write as V*) V *(s) = max a [r(s, a)+γv *(δ(s, a))] We could then do a lookahead search to choose best action from any state s: π *(s) = argmax a [r(s,a)+γv *(δ(s,a))] where P(s t +1 = s',r t +1 = r' s t = s,a t = a) = P(s t +1 = s' s t = s,a t = a)p(r t +1 = r' s t = s,a t = a) = δ(s,a)r(s,a) But there s a problem: This works well if we know δ() and r() But when we don t, we cannot choose actions this way
6 Let us 0irst assume that δ() and r() are deterministic: Remember: What to Learn Reward function At every time step t, we are in a state s t, and we: Take an action a t (possibly null action) Receive some reward r t+1 r : (s,a) r Move into a new state s t+1 δ : (s,a) s How can we do learning? Transition function
7 Q Learning De0ine a new function very similar to V* Q(s, a) r(s, a)+γv *(δ(s, a)) If we learn Q, we can choose the optimal action even without knowing δ! π *(s) = argmax a [r(s, a)+γv *(δ(s, a))] Q is then the evaluation function we will learn
8
9 Q and V* are closely related: So we can write Q recursively: Training Rule to Learn Q Let Q^ denote the learner s current approximation to Q Consider training rule ˆQ(s, a) r(s, a)+γ max a' ˆQ(s', a') where s is state resulting from applying action a in state s
10 Q Learning for Determinis(c World For each s,a initialize table entry Q^(s,a) ß 0 Start in some initial state s Do forever: Select an action a and execute it Receive immediate reward r Observe the new state s Update the table entry for Q^(s,a) using Q learning rule: s ß s ˆQ(s, a) r(s, a)+γ max a' ˆQ(s', a') If get to absorbing state, restart to initial state, and run thru Do forever loop until reach absorbing state

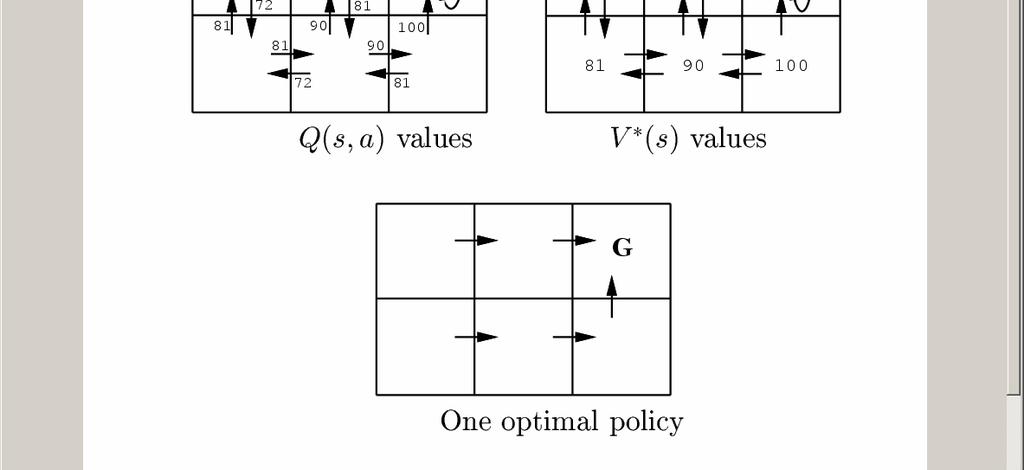
11 Upda(ng Es(mated Q Assume Robot is in state s 1 ; some of its current estimates of Q are as shown; executes rightward move Notice that if rewards are non- negative, then Q^ values only increase from 0, approach true Q
12 Q Learning: Summary training set consists of series of intervals (episodes): sequence of (state, action, reward) triples, end at absorbing state Each executed action a results in transition from state s i to s j ; algorithm updates Q^(s i,a) using the learning rule Intuition for simple grid world, reward only upon entering goal state à Q estimates improve from goal state back 1. All Q^(s,a) start at 0 2. First episode only update Q^(s,a) for transition leading to goal state 3. Next episode if go thru this next- to- last transition, will update Q^(s,a) another step back 4. Eventually propagate information from transitions with non- zero reward throughout state- action space
13 Q Learning: Convergence Proof Q^(s,a) converges to Q(s,a) Consider deterministic world, each (s,a) visited ly often. Proof: De0ine full interval as interval during which each (s,a) visited. During each full interval largest error in Q^ table reduced by factor of γ. Let Q^n be table after n updates, Δ n be max. error in Q^n
14 Q Learning: Convergence Proof Let Q^n be table after n updates, Δ n be max. error in Q^n For any entry updated on interval n+1, error in new estimate:
15 Q Learning: Convergence Proof (cont.) Largest error in initial table is bounded, since values of Q n^(s,a) and Q(s,a) are bounded for all s,a Largest error in table after one interval will be at most After k intervals, error will be at most Since, error à 0 as n à
16 Q Learning: Explora(on/Exploita(on Have not speci0ied how actions chosen (during learning) Can choose actions to maximize Q^(s,a) Good idea? Can instead employ stochastic action selection (policy): Can vary k during learning more exploration early on, shift towards exploitation
17 Nondeterminis(c Case What if reward and next state are non- deterministic? We rede0ine V,Q based on probabilistic estimates, expected values of them: Q(s, a) E[r(s, a)+γv *(δ(s, a))] s' = E[r(s, a)+γ P(s' s, a)max a' Q(s', a')]
18 Nondeterminis(c Case: Learning Q Training rule does not converge (can keep changing Q^ even if initialized to true Q values) So modify training rule to change more slowly where s is the state land in after s, and a indexes the actions that can be taken in state s where visits is the number of times action a is taken in state s
19 Summary What to study? Material covered in lectures and tutorial Use the books/readings as back- up, to help understand the methods and derivations Focus mainly on material since the mid- term The exam is closed book and notes Do not focus on memorizing formulas, but instead main ideas and methods
20 Topics to Study Unsupervised Learning what is the difference between hard/soft clustering? Gaussian mixture models / EM: what is a mixture? what does it mean that this is a generative model? what is E step? what is M step? EM vs. gradient descent? is convergence guaranteed? what are responsibilities? understand (but not memorize) eqns, objective PCA and autoencoders: what is PCA used for? what is the objective function(s)? what is a principal component? PCA vs. clustering? How does PCA compare to autoencoders
21 Support Vector Machines what is the kernel trick? Topics to Study (cont.) when can the kernel trick be applied? what is its purpose how is an SVM similar and different than a linear classihier? what is a support vector? What is the objective function? Primal vs. dual formulation Reinforcement Learning Compare to other forms of learning Q learning algorithm: updates, objective Exploration/exploitation
22 Topics to Study (cont.) Ensemble Methods Basic motivation, approach Bagging, boosting compare and contrast AdaBoost: steps of algorithm Mixture of experts: compare/contrast to others Bayesian Methods Motivation Posterior predictive distribution Learning & prediction
23 Future Looks Bright Data is everywhere! It s an exci=ng =me to know how to make the most of it. Internet Web traffic Store purchases Online ads Social connec=ons (Facebook, TwiRer, etc) Etc., etc., etc., etc., Robo=cs and Computer Vision Images, videos, range scans
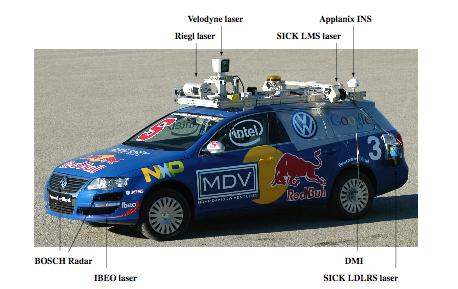
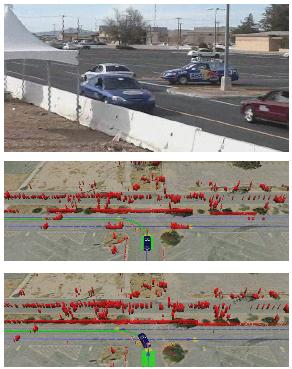
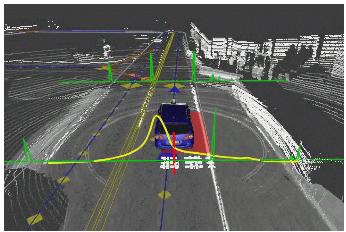
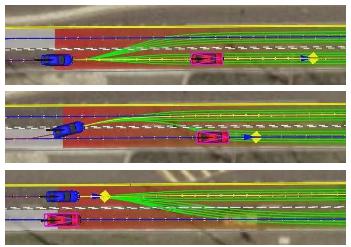
24 Autonomous Driving (2009)




25 Autonomous driving (2012) Videos: - Google car touring - Google car racing



26 Assis=ve Technology Hand Washing Fall Detec=on Intelligent Assis8ve Technology and Systems Lab University of Toronto

27 Navigation and Obstacle Avoidance Help (POMDP ) System prevented user from driving into detected obstacles, audio prompts for wayfinding assistance ( off-route turn left!, move forward, etc.) Tested with six cognitively-impaired older adults in Toronto: Single-Subject Research Design: A-B (B- A) trials with training session prior to each phase
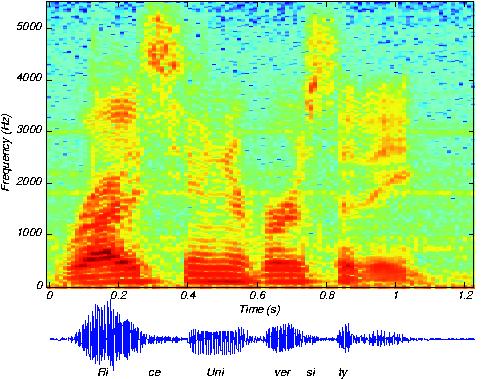
28 Speech Recognition (thanks to deep learning)

29 Protein folding Gene expression HIV/AID vaccines Machine Learning in Comp. Biology Workshops at NIPS Etc. Computa=onal Biology

30 Flight Delays
31 Poli=cal Campaigns...In our own campaign, polling was just one way we viewed how we were doing in a state in the general elec=on. We had a lot of voter iden=fica=on work. We had a lot of field data. So we'd put all that together and model out the elec=on in those states every week. So we'd say, okay, if the elec=on were held this week based on all our data, put it all in a blender, where are we?...it makes you enormously agile. - David Plouffe, Campaign Manager, Obama for America 2008 Video: How We Used Data to Win the Presiden=al Elec=on Dan Siroker, Director of Analy=cs for the 2008 Obama Presiden=al Campaign We could [predict] people who were going to give online. We could model people who were going to give through mail. We could model volunteers, said one of the senior advisers about the predictive profiles built by the data. In the end, modeling became something way bigger for us in 12 than in 08 because it made our time more efficient -Senior adviser to the Obama 2012 campaign
32 Paper recommendations Papers Good match Reviewers
33 Machine Learning for Sustainability Emerging topic (NIPS Mini Symposium) Machine learning for the NYC power grid: lessons learned and the future What it takes to win the carbon war. Why even AI is needed. Ecological Science and Policy: Challenges for Machine Learning Op8mizing Informa8on Gathering in Environmental Monitoring Approximate Dynamic Programming in Energy Resource Management
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Aviation English Solutions
 Aviation English Solutions DynEd's Aviation English solutions develop a level of oral English proficiency that can be relied on in times of stress and unpredictability so that concerns for accurate communication
Aviation English Solutions DynEd's Aviation English solutions develop a level of oral English proficiency that can be relied on in times of stress and unpredictability so that concerns for accurate communication
Master s Programme in Computer, Communication and Information Sciences, Study guide , ELEC Majors
 Master s Programme in Computer, Communication and Information Sciences, Study guide 2015-2016, ELEC Majors Sisällysluettelo PS=pääsivu, AS=alasivu PS: 1 Acoustics and Audio Technology... 4 Objectives...
Master s Programme in Computer, Communication and Information Sciences, Study guide 2015-2016, ELEC Majors Sisällysluettelo PS=pääsivu, AS=alasivu PS: 1 Acoustics and Audio Technology... 4 Objectives...
Managerial Decision Making
 Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
An Introduction to Simulation Optimization
 An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
IT Students Workshop within Strategic Partnership of Leibniz University and Peter the Great St. Petersburg Polytechnic University
 IT Students Workshop within Strategic Partnership of Leibniz University and Peter the Great St. Petersburg Polytechnic University 06.11.16 13.11.16 Hannover Our group from Peter the Great St. Petersburg
IT Students Workshop within Strategic Partnership of Leibniz University and Peter the Great St. Petersburg Polytechnic University 06.11.16 13.11.16 Hannover Our group from Peter the Great St. Petersburg
DOCTOR OF PHILOSOPHY HANDBOOK
 University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence
 Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
We are strong in research and particularly noted in software engineering, information security and privacy, and humane gaming.
 Computer Science 1 COMPUTER SCIENCE Office: Department of Computer Science, ECS, Suite 379 Mail Code: 2155 E Wesley Avenue, Denver, CO 80208 Phone: 303-871-2458 Email: info@cs.du.edu Web Site: Computer
Computer Science 1 COMPUTER SCIENCE Office: Department of Computer Science, ECS, Suite 379 Mail Code: 2155 E Wesley Avenue, Denver, CO 80208 Phone: 303-871-2458 Email: info@cs.du.edu Web Site: Computer
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
Guru: A Computer Tutor that Models Expert Human Tutors
 Guru: A Computer Tutor that Models Expert Human Tutors Andrew Olney 1, Sidney D'Mello 2, Natalie Person 3, Whitney Cade 1, Patrick Hays 1, Claire Williams 1, Blair Lehman 1, and Art Graesser 1 1 University
Guru: A Computer Tutor that Models Expert Human Tutors Andrew Olney 1, Sidney D'Mello 2, Natalie Person 3, Whitney Cade 1, Patrick Hays 1, Claire Williams 1, Blair Lehman 1, and Art Graesser 1 1 University
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Transfer Learning Action Models by Measuring the Similarity of Different Domains
 Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Academic Integrity RN to BSN Option Student Tutorial
 Academic Integrity RN to BSN Option Student Tutorial Slide 1 Title Slide Hello, Chamberlain RN to BSN option students. Welcome to our Brainshark Student Tutorial on Academic Integrity I am Amy Minnick,
Academic Integrity RN to BSN Option Student Tutorial Slide 1 Title Slide Hello, Chamberlain RN to BSN option students. Welcome to our Brainshark Student Tutorial on Academic Integrity I am Amy Minnick,
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment
 Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Performance Modeling and Design of Computer Systems
 Performance Modeling and Design of Computer Systems Computer systems design is full of conundrums: Given a choice between a single machine with speed s, orn machines each with speed s/n, which should we
Performance Modeling and Design of Computer Systems Computer systems design is full of conundrums: Given a choice between a single machine with speed s, orn machines each with speed s/n, which should we
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
COMPUTER SCIENCE GRADUATE STUDIES Course Descriptions by Methodology
 COMPUTER SCIENCE GRADUATE STUDIES Course Descriptions by Methodology MSc Students must complete 4 Graduate Level Courses and cover breadth in 3 Methodolgies. METHODOLOGY 1 Analysis and Computation in Discrete
COMPUTER SCIENCE GRADUATE STUDIES Course Descriptions by Methodology MSc Students must complete 4 Graduate Level Courses and cover breadth in 3 Methodolgies. METHODOLOGY 1 Analysis and Computation in Discrete
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION. by Yang Xu PhD of Information Sciences
 TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION by Yang Xu PhD of Information Sciences Submitted to the Graduate Faculty of in partial fulfillment of the requirements for the degree of Doctor of Philosophy
TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION by Yang Xu PhD of Information Sciences Submitted to the Graduate Faculty of in partial fulfillment of the requirements for the degree of Doctor of Philosophy
Case study Norway case 1
 Case study Norway case 1 School : B (primary school) Theme: Science microorganisms Dates of lessons: March 26-27 th 2015 Age of students: 10-11 (grade 5) Data sources: Pre- and post-interview with 1 teacher
Case study Norway case 1 School : B (primary school) Theme: Science microorganisms Dates of lessons: March 26-27 th 2015 Age of students: 10-11 (grade 5) Data sources: Pre- and post-interview with 1 teacher
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
White Paper. The Art of Learning
 The Art of Learning Based upon years of observation of adult learners in both our face-to-face classroom courses and using our Mentored Email 1 distance learning methodology, it is fascinating to see how
The Art of Learning Based upon years of observation of adult learners in both our face-to-face classroom courses and using our Mentored Email 1 distance learning methodology, it is fascinating to see how
COMPUTER SCIENCE GRADUATE STUDIES Course Descriptions by Research Area
 COMPUTER SCIENCE GRADUATE STUDIES Course Descriptions by Research Area PhD students must complete 4 graduate level courses and cover breadth in 4 research areas. PhD-U students must complete 4 research
COMPUTER SCIENCE GRADUATE STUDIES Course Descriptions by Research Area PhD students must complete 4 graduate level courses and cover breadth in 4 research areas. PhD-U students must complete 4 research
Learning Human Utility from Video Demonstrations for Deductive Planning in Robotics
 Learning Human Utility from Video Demonstrations for Deductive Planning in Robotics Nishant Shukla, Yunzhong He, Frank Chen, and Song-Chun Zhu Center for Vision, Cognition, Learning, and Autonomy University
Learning Human Utility from Video Demonstrations for Deductive Planning in Robotics Nishant Shukla, Yunzhong He, Frank Chen, and Song-Chun Zhu Center for Vision, Cognition, Learning, and Autonomy University
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Planning with External Events
 94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
CS224d Deep Learning for Natural Language Processing. Richard Socher, PhD
 CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test