Reinforcement Learning
|
|
|
- Barnard Turner
- 6 years ago
- Views:
Transcription
1 Reinforcement Learning Policy Op4miza4on and Planning (Material not examinable) Subramanian Ramamoorthy School of Informa4cs 31 March, 2017
2 Plan for Lecture: Policies and Plans Policy Op5miza5on Policies can be op5mized directly, without learning value func5ons Policy-gradient methods Special case: how could we learn with real-valued (con5nuous) ac5ons Planning Uses of environment models Integra5on of planning, learning, and execu5on Model-based reinforcement learning 31/03/2017 2
3 Policy-gradient methods (Note: slightly different nota5on in this sec5on, following 2 nd ed. of S+B)
4 Approaches to control 1. Previous approach: Ac5on-value methods: learn the value of each (state-)ac5on; pick the max, usually 2. New approach: Policy-gradient methods: learn the parameters of a stochas5c policy update by gradient ascent in performance includes actor-cri5c methods, which learn both value and policy parameters 31/03/2017 4
5 Actor-cri5c architecture World 31/03/2017 5
6 Why Approximate Policies rather than Values? In many problems, the policy is simpler to approximate than the value func5on In many problems, the op5mal policy is stochas5c e.g., bluffing, POMDPs To enable smoother change in policies To avoid a search on every step (the max) To be^er relate to biology 31/03/2017 6
7 Policy Approxima5on Policy = a func5on from state to ac5on How does the agent select ac5ons? In such a way that it can be affected by learning? In such a way as to assure explora5on? Approxima5on: there are too many states and/or ac5ons to represent all policies To handle large/con5nuous ac5on spaces 31/03/2017 7
8 Gradient Bandit Algorithm 31/03/2017 8
9 Core Principle: Policy Gradient Methods Parameterized policy selects ac5ons without consul5ng a value func5on VF can s5ll be used to learn the policy weights But not needed for ac5on selec5on Gradient ascent on a performance measure η(θ) with respect to policy weights t+1 = t + \ r ( t ) Expectation approximates the gradient (hence policy gradient ) 31/03/2017 9
 to TD(λ)")
10 Linear-exponen5al policies (discrete ac5ons) Factor to modulate TD update, going beyond TD(0) to TD(λ) 31/03/




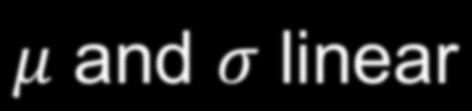

11 eg, linear-gaussian policies (con5nuous ac5ons) Action prob. density μ and σ linear in the state action 31/03/
12 eg, linear-gaussian policies (con5nuous ac5ons) 31/03/
13 Gaussian eligibility func5ons 31/03/
14 Policy Gradient Setup 31/03/
15 REINFORCE: Monte-Carlo Policy Gradient, from Policy Gradient Theorem 31/03/
16 The generality of the policy-gradient strategy Can be applied whenever we can compute the effect of parameter changes on the ac5on probabili5es, e.g., has been applied to spiking neuron models There are many possibili5es other than linear-exponen5al and linear-gaussian e.g., mixture of random, argmax, and fixed-width gaussian; learn the mixing weights, drij/diffusion models 31/03/
17 Planning

18 Paths to a Policy 31/03/
19 Schematic 31/03/
20 Models Model: anything the agent can use to predict how the environment will respond to its actions Distribution model: description of all possibilities and their probabilities e.g., a for all s, s ʹ, and a A(s) P ss ʹ and R a s ʹ Sample model: produces sample experiences e.g., a simulation model Both types of models can be used to produce simulated experience Often sample models are much easier to come by 31/03/
21 Planning Planning: any computational process that uses a model to create or improve a policy Planning in AI: state-space planning model planning plan-space planning (e.g., partial-order planner) We take the following (unusual) view: all state-space planning methods involve computing value functions, either explicitly or implicitly they all apply backups to simulated experience policy model simulated experience backups values policy 31/03/
22 Planning Cont. Classical DP methods are state-space planning methods Heuristic search methods are state-space planning methods A planning method based on Q-learning: Random-Sample One-Step Tabular Q-Planning 31/03/

23 Paths to a Policy: Dyna 31/03/
24 Learning, Planning, and Acting Two uses of real experience: model learning: to improve the model direct RL: to directly improve the value function and policy Improving value function and/or policy via a model is sometimes called indirect RL or model-based RL. Here, we call it planning. planning model value/policy direct RL model learning acting experience 24
25 Direct vs. Indirect RL Indirect methods: make fuller use of experience: get better policy with fewer environment interactions Direct methods simpler not affected by bad models But they are very closely related and can be usefully combined: planning, acting, model learning, and direct RL can occur simultaneously and in parallel 31/03/
26 The Dyna Architecture (Sutton 1990) Policy/value functions planning update direct RL update real experience model learning simulated experience search control Environment Model 31/03/
27 The Dyna-Q Algorithm direct RL model learning planning 31/03/
28 Dyna-Q on a Simple Maze rewards = 0 until goal, when =1 31/03/
 G WITH PLANNING (N=50) G S S")
29 Dyna-Q Snapshots: Midway in 2nd Episode WITHOUT PLANNING (N=0) G WITH PLANNING (N=50) G S S 31/03/
30 When the Model is Wrong: The changed envirnoment is harder Blocking Maze G G S S 150 Dyna-Q+ Dyna-Q Cumulative reward Dyna-AC 31/03/ Time steps 30
31 The changed environment is easier Shortcut Maze G G S S 400 Cumulative reward Dyna-Q+ Dyna-Q Dyna-AC 31/03/ Time steps 31
32 What is Dyna-Q +? Uses an exploration bonus : Keeps track of time since each state-action pair was tried for real An extra reward is added for transitions caused by state-action pairs related to how long ago they were tried: the longer unvisited, the more reward for visiting The agent actually plans how to visit long unvisited states 31/03/
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING. Calendar Description Units: 1.
 University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Edexcel GCSE. Statistics 1389 Paper 1H. June Mark Scheme. Statistics Edexcel GCSE
 Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Improving Fairness in Memory Scheduling
 Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Introduction to the Practice of Statistics
 Chapter 1: Looking at Data Distributions Introduction to the Practice of Statistics Sixth Edition David S. Moore George P. McCabe Bruce A. Craig Statistics is the science of collecting, organizing and
Chapter 1: Looking at Data Distributions Introduction to the Practice of Statistics Sixth Edition David S. Moore George P. McCabe Bruce A. Craig Statistics is the science of collecting, organizing and
Managerial Decision Making
 Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
SELF-STUDY QUESTIONNAIRE FOR REVIEW of the COMPUTER SCIENCE PROGRAM
 Disclaimer: This Self Study was developed to meet the goals of the CAC Session at the 2006 Summit. It should not be considered as a model or a template. ABET Computing Accreditation Commission SELF-STUDY
Disclaimer: This Self Study was developed to meet the goals of the CAC Session at the 2006 Summit. It should not be considered as a model or a template. ABET Computing Accreditation Commission SELF-STUDY
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Changing User Attitudes to Reduce Spreadsheet Risk
 Changing User Attitudes to Reduce Spreadsheet Risk Dermot Balson Perth, Australia Dermot.Balson@Gmail.com ABSTRACT A business case study on how three simple guidelines: 1. make it easy to check (and maintain)
Changing User Attitudes to Reduce Spreadsheet Risk Dermot Balson Perth, Australia Dermot.Balson@Gmail.com ABSTRACT A business case study on how three simple guidelines: 1. make it easy to check (and maintain)
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS
 COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Development of Multistage Tests based on Teacher Ratings
 Development of Multistage Tests based on Teacher Ratings Stéphanie Berger 12, Jeannette Oostlander 1, Angela Verschoor 3, Theo Eggen 23 & Urs Moser 1 1 Institute for Educational Evaluation, 2 Research
Development of Multistage Tests based on Teacher Ratings Stéphanie Berger 12, Jeannette Oostlander 1, Angela Verschoor 3, Theo Eggen 23 & Urs Moser 1 1 Institute for Educational Evaluation, 2 Research
BAYESIAN ANALYSIS OF INTERLEAVED LEARNING AND RESPONSE BIAS IN BEHAVIORAL EXPERIMENTS
 Page 1 of 42 Articles in PresS. J Neurophysiol (December 20, 2006). doi:10.1152/jn.00946.2006 BAYESIAN ANALYSIS OF INTERLEAVED LEARNING AND RESPONSE BIAS IN BEHAVIORAL EXPERIMENTS Anne C. Smith 1*, Sylvia
Page 1 of 42 Articles in PresS. J Neurophysiol (December 20, 2006). doi:10.1152/jn.00946.2006 BAYESIAN ANALYSIS OF INTERLEAVED LEARNING AND RESPONSE BIAS IN BEHAVIORAL EXPERIMENTS Anne C. Smith 1*, Sylvia
Shockwheat. Statistics 1, Activity 1
 Statistics 1, Activity 1 Shockwheat Students require real experiences with situations involving data and with situations involving chance. They will best learn about these concepts on an intuitive or informal
Statistics 1, Activity 1 Shockwheat Students require real experiences with situations involving data and with situations involving chance. They will best learn about these concepts on an intuitive or informal
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
CS224d Deep Learning for Natural Language Processing. Richard Socher, PhD
 CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I
 Session 1793 Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I John Greco, Ph.D. Department of Electrical and Computer Engineering Lafayette College Easton, PA 18042 Abstract
Session 1793 Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I John Greco, Ph.D. Department of Electrical and Computer Engineering Lafayette College Easton, PA 18042 Abstract
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Navigating the PhD Options in CMS
 Navigating the PhD Options in CMS This document gives an overview of the typical student path through the four Ph.D. programs in the CMS department ACM, CDS, CS, and CMS. Note that it is not a replacement
Navigating the PhD Options in CMS This document gives an overview of the typical student path through the four Ph.D. programs in the CMS department ACM, CDS, CS, and CMS. Note that it is not a replacement
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method
 Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Toward Probabilistic Natural Logic for Syllogistic Reasoning
 Toward Probabilistic Natural Logic for Syllogistic Reasoning Fangzhou Zhai, Jakub Szymanik and Ivan Titov Institute for Logic, Language and Computation, University of Amsterdam Abstract Natural language
Toward Probabilistic Natural Logic for Syllogistic Reasoning Fangzhou Zhai, Jakub Szymanik and Ivan Titov Institute for Logic, Language and Computation, University of Amsterdam Abstract Natural language
Create Quiz Questions
 You can create quiz questions within Moodle. Questions are created from the Question bank screen. You will also be able to categorize questions and add them to the quiz body. You can crate multiple-choice,
You can create quiz questions within Moodle. Questions are created from the Question bank screen. You will also be able to categorize questions and add them to the quiz body. You can crate multiple-choice,
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Surprise-Based Learning for Autonomous Systems
 Surprise-Based Learning for Autonomous Systems Nadeesha Ranasinghe and Wei-Min Shen ABSTRACT Dealing with unexpected situations is a key challenge faced by autonomous robots. This paper describes a promising
Surprise-Based Learning for Autonomous Systems Nadeesha Ranasinghe and Wei-Min Shen ABSTRACT Dealing with unexpected situations is a key challenge faced by autonomous robots. This paper describes a promising
Cal s Dinner Card Deals
 Cal s Dinner Card Deals Overview: In this lesson students compare three linear functions in the context of Dinner Card Deals. Students are required to interpret a graph for each Dinner Card Deal to help
Cal s Dinner Card Deals Overview: In this lesson students compare three linear functions in the context of Dinner Card Deals. Students are required to interpret a graph for each Dinner Card Deal to help
A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING
 A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING Yong Sun, a * Colin Fidge b and Lin Ma a a CRC for Integrated Engineering Asset Management, School of Engineering Systems, Queensland
A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING Yong Sun, a * Colin Fidge b and Lin Ma a a CRC for Integrated Engineering Asset Management, School of Engineering Systems, Queensland
Guide to the Uniform mark scale (UMS) Uniform marks in A-level and GCSE exams
 Uniform marks in A-level and GCSE exams") Guide to the Uniform mark scale (UMS) Uniform marks in A-level and GCSE exams This booklet explains why the Uniform mark scale (UMS) is necessary and how it works. It is intended for exams officers and
Guide to the Uniform mark scale (UMS) Uniform marks in A-level and GCSE exams This booklet explains why the Uniform mark scale (UMS) is necessary and how it works. It is intended for exams officers and
Introduction to Questionnaire Design
 Introduction to Questionnaire Design Why this seminar is necessary! Bad questions are everywhere! Don t let them happen to you! Fall 2012 Seminar Series University of Illinois www.srl.uic.edu The first
Introduction to Questionnaire Design Why this seminar is necessary! Bad questions are everywhere! Don t let them happen to you! Fall 2012 Seminar Series University of Illinois www.srl.uic.edu The first
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Data Structures and Algorithms
 CS 3114 Data Structures and Algorithms 1 Trinity College Library Univ. of Dublin Instructor and Course Information 2 William D McQuain Email: Office: Office Hours: wmcquain@cs.vt.edu 634 McBryde Hall see
CS 3114 Data Structures and Algorithms 1 Trinity College Library Univ. of Dublin Instructor and Course Information 2 William D McQuain Email: Office: Office Hours: wmcquain@cs.vt.edu 634 McBryde Hall see
Process to Identify Minimum Passing Criteria and Objective Evidence in Support of ABET EC2000 Criteria Fulfillment
 Session 2532 Process to Identify Minimum Passing Criteria and Objective Evidence in Support of ABET EC2000 Criteria Fulfillment Dr. Fong Mak, Dr. Stephen Frezza Department of Electrical and Computer Engineering
Session 2532 Process to Identify Minimum Passing Criteria and Objective Evidence in Support of ABET EC2000 Criteria Fulfillment Dr. Fong Mak, Dr. Stephen Frezza Department of Electrical and Computer Engineering
Welcome to the session on ACCUPLACER Policy Development. This session will touch upon common policy decisions an institution may encounter during the
 Welcome to the session on ACCUPLACER Policy Development. This session will touch upon common policy decisions an institution may encounter during the development or reevaluation of a placement program.
Welcome to the session on ACCUPLACER Policy Development. This session will touch upon common policy decisions an institution may encounter during the development or reevaluation of a placement program.
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
GCSE English Language 2012 An investigation into the outcomes for candidates in Wales
 GCSE English Language 2012 An investigation into the outcomes for candidates in Wales Qualifications and Learning Division 10 September 2012 GCSE English Language 2012 An investigation into the outcomes
GCSE English Language 2012 An investigation into the outcomes for candidates in Wales Qualifications and Learning Division 10 September 2012 GCSE English Language 2012 An investigation into the outcomes
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
S T A T 251 C o u r s e S y l l a b u s I n t r o d u c t i o n t o p r o b a b i l i t y
 Department of Mathematics, Statistics and Science College of Arts and Sciences Qatar University S T A T 251 C o u r s e S y l l a b u s I n t r o d u c t i o n t o p r o b a b i l i t y A m e e n A l a
Department of Mathematics, Statistics and Science College of Arts and Sciences Qatar University S T A T 251 C o u r s e S y l l a b u s I n t r o d u c t i o n t o p r o b a b i l i t y A m e e n A l a
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Dream Team Resources. Monday June 26th 2:30-3:45 PM 4:00-5:15 PM
 Dream Team Resources Monday June 26th 2:30-3:45 PM 4:00-5:15 PM Allison Moschetti LearnZillion Coach The New Mexico Dream Team By the end of this session, you will: Understand the power of complex texts
Dream Team Resources Monday June 26th 2:30-3:45 PM 4:00-5:15 PM Allison Moschetti LearnZillion Coach The New Mexico Dream Team By the end of this session, you will: Understand the power of complex texts
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus
 Spring 2008 Syllabus") Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
INTERNATIONAL BACCALAUREATE AT IVANHOE GRAMMAR SCHOOL. An Introduction to the International Baccalaureate Diploma Programme For Students and Families
 INTERNATIONAL BACCALAUREATE AT IVANHOE GRAMMAR SCHOOL An Introduction to the International Baccalaureate Diploma Programme For Students and Families 2018-2019 The International Baccalaureate Organization
INTERNATIONAL BACCALAUREATE AT IVANHOE GRAMMAR SCHOOL An Introduction to the International Baccalaureate Diploma Programme For Students and Families 2018-2019 The International Baccalaureate Organization
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
School of Innovative Technologies and Engineering
 School of Innovative Technologies and Engineering Department of Applied Mathematical Sciences Proficiency Course in MATLAB COURSE DOCUMENT VERSION 1.0 PCMv1.0 July 2012 University of Technology, Mauritius
School of Innovative Technologies and Engineering Department of Applied Mathematical Sciences Proficiency Course in MATLAB COURSE DOCUMENT VERSION 1.0 PCMv1.0 July 2012 University of Technology, Mauritius