Introduction to AI. Math in Machine Learning seminar (MiML) McGill Math and Stats (McMaS)
|
|
|
- Marvin Alexander
- 5 years ago
- Views:
Transcription
1 Introduction to AI Math in Machine Learning seminar (MiML) McGill Math and Stats (McMaS)
,")
2 Background AI Artificial Intelligence is loosely defined as intelligence exhibited by machines Operationally: R&D in CS academic sub-disciplines: Computer Vision, Natural Language Processing (NLP), Robotics, etc
 is a small research area within AI: build machines that can successfully perform any task that a human might do On account of this ambitious goal, AGI has high visibility,")
3 Artificial General Intelligence (AGI) AI : specific tasks, AGI : general cognitive abilities. (AGI) is a small research area within AI: build machines that can successfully perform any task that a human might do On account of this ambitious goal, AGI has high visibility, disproportionate to its size or present level of success, among futurists, science fiction writers, and the public.

4 Perspectives on Research in Artificial Intelligence and Artificial General Intelligence Relevant to DoD taken from a study by JASON for the Department of Defence (Dod)
5 Historical Context AI coined in Perceptrons 1960 implied machines could learn from data Decline in perceptron no universal function approximator - only linear discriminator, can t learn XOR 1980 resurgence in AI expert systems. Learning rules. Petered out 1990s academic AI in doldrums Improved computers led, in 1997 to IBM Deep Blue beats champion Gary Kasparov in chess. Chess, once believed to require human intelligence, fell to a special-purpose very fast search algorithm.
6 Don t confuse AI with AGI 1997 NYT in response to Deep Blue: to play a decent game of Go [requires human intelligence] when that happens, will be a sign that AI is as good as the real thing 2016 NYT wrong: Google s AlphaGO beats world Champion Lee Sedol. Did not involve breakthrough - also using hybrid of DNN with massively parallel tree-search and Reinforcement Learning DNN require massive amounts of data which can be found labelled on the internet, or in the databases of private companies, like Facebook or Google, generated from a fast computer playing a lifetime of games
s, became available, which allowed for much larger, and deeper networks.")
7 2010: Deep Learning Revolution Neural Networks have been around for half a century. Popular in the 1990 s for solving simple tasks. Starting around 2010, new hardware, Graphics Processor Units (GPU)s, became available, which allowed for much larger, and deeper networks. large labelled data sets become available, allowed for training.
 team: Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever.")
8 2010: Deep Learning Revolution The large data set ImageNet was available in In 2012 Alexnet, trained on GPUs, won the 2012 ImageNet competition, with an error of 15.3%, more that 10% better than the runner up. Canadian (U Toronto) team: Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever. Between 2011 and 2015, error rate for image captioning by computer fell from 25% to 3%, better than accepted human figure of 5% more than 95% prediction correct caption (green column)

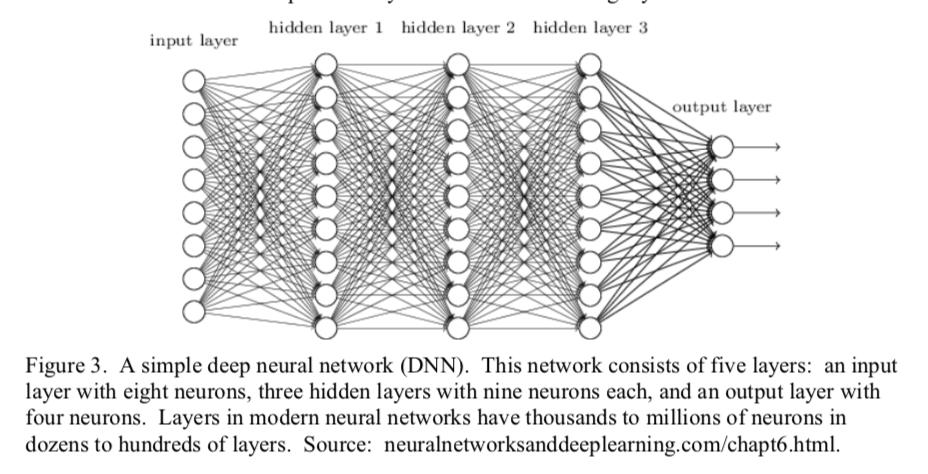
9 DNN and Images
 self-driving cars: now more limited by policy than tech.")
10 DNN exceed human performance in: some kinds of image recognition spoken word recognition the game of Go (long thought to require generalized human intelligence AGI) self-driving cars: now more limited by policy than tech.
 more likely DL will become")
11 rapidly advancing areas Reinforcement Learning graphical and Bayes models, esp. with probability programming models generative models (creating artificial images) more likely DL will become essential building block of a hybrid approach
 Robots learning how to walk Big in Montreal: Google DeepMind")
12 Reinforcement Learning Learn how to play Atari from raw image pixels. Learn how to beat Go champions (Huge branching factor) Robots learning how to walk Big in Montreal: Google DeepMind and Microsoft Research both work in this area


13 Generative Models A generative model takes a input random vectors and outputs realistic images (of a certain class)
14 Generative Models discriminator: has learned what a picture looks like. generator: tries to generate a believable picture.
 are computationally intensive.")

15 Hardware Both training (finding the best weights) and inference (evaluating the output of the network on a data point) are computationally intensive. Effort is measured in Joules. Hardware, software, and algorithms have evolved together. Currently, need to use Graphics Processing Units (GPU)s, rather than CPUs.
16 Hardware Want to do inference on mobile devices, need custom architectures, and custom hardware. Currently engineering practice to take trained networks and make them smaller. Also build custom chips with power source Research problem: design and train architectures with efficient inference in mind


17 Machine Learning vs DL Traditional Machine Learning (ML) can t compete with the raw performance of Deep Learning amazon.com However ML has performance guarantees which are important in the many applications where errors are costly.

18 Error Estimates Using probability (Central Limit Theorem) and linear or parametric models, can fit data, and also estimate the probability of an error Deep Learning models lack these estimates on errors!
19 <latexit sha1_base64="3mrmvwbthhzx8q0rthpq9fwqi7o=">aaab/3icbvbns8naej3ur1q/ooixl4tfeiss9kixoedfywx7aw0im+2mxbqbhn2ngmip/huvhpti1b/hzx/jthxr1gcdj/dmmjkxjjwp7tifvmfpewv1rbhe2tjc2t6xd/eakk4loq0s81i2a6wozxftaky5bsesyhfw2gqglxo/duulynf0o7oeegl3ixyygrwrfpsgqxeoq1kb7nyg7k2dosbnvl12ks4u6ie486rcq2nua4c6b390ezfjby004vipjltntjdjqrnhdftqpoommaxxn3ymjbcgysun94/qsvf6kiylquijqfp7isdcquweplngpvdz3kt8z+ukojz3chylqayrms0ku450jczhob6tlgiegykjzozwrazyyqjnzcutwslli6rzrbhoxb02avrhhiicwhgcgatnuimrqemdcdzae7zaq/vopvtj623wwrc+z/bhd6z3l3yxld8=</latexit> <latexit sha1_base64="kifqgqw5gdu6inuwanqn5k7mjb0=">aaab/3icbvdlssnafj3uv62vqodgzwarbkek3ehgkajisoj9qbvczdjph85mwsxedbelf8wnc6w49qvcu/nvnlyi2nrgwugce7n3nibhvgnh+bqkc4tlyyvf1dla+sbmlr2901rxkjfp4jjfsh0grrgvpkgpzqsdsij4wegrgjyp/dynkyrg4lpncfe46gkauyy0kxx7l4nnsktsdm99cu9mhcpap75ddirobpchulokximjepeejuq+/deny5xyijrmskmow020lyopkwzkwoqmiiqid1cpdawvibpl5zp7h/dqkcgmymlkadhrf0/kicuv8cb0cqt7atybi/95nvrhp15orzjqivb0uzqyqgm4dgogvbkswwyiwpkawyhui4mwnpgvtahzl8+tzrxiohx3yqrrbvmuwt44aefabsegbi5bhtqabvfgetydf+vberjg1uu0twb9z+ycp7devgd8xje+</latexit> <latexit sha1_base64="kifqgqw5gdu6inuwanqn5k7mjb0=">aaab/3icbvdlssnafj3uv62vqodgzwarbkek3ehgkajisoj9qbvczdjph85mwsxedbelf8wnc6w49qvcu/nvnlyi2nrgwugce7n3nibhvgnh+bqkc4tlyyvf1dla+sbmlr2901rxkjfp4jjfsh0grrgvpkgpzqsdsij4wegrgjyp/dynkyrg4lpncfe46gkauyy0kxx7l4nnsktsdm99cu9mhcpap75ddirobpchulokximjepeejuq+/deny5xyijrmskmow020lyopkwzkwoqmiiqid1cpdawvibpl5zp7h/dqkcgmymlkadhrf0/kicuv8cb0cqt7atybi/95nvrhp15orzjqivb0uzqyqgm4dgogvbkswwyiwpkawyhui4mwnpgvtahzl8+tzrxiohx3yqrrbvmuwt44aefabsegbi5bhtqabvfgetydf+vberjg1uu0twb9z+ycp7devgd8xje+</latexit> <latexit sha1_base64="tlykp0jeujhmlgyozak1q58na7m=">aaab/3icbvdlssnafl2pr1pfucgnm8eicejjutgnuhdjsoj9qbvczdpph84kywaihtifv+lghsju/q13/o3tb6ktby4czrmxe+8jes6udpwvq7c0vlk6vlwvbwxube/yu3tnfaes0aajeszbavaus4g2nnocthnjsqg4bqxdy7hfuqvssti60vlcpyh7eqszwdpivn2qoqvuvaladz5d96zoueaz3y47fwcc9epcevkggeq+/dntxsqvnnkey6u6bjxrxo6lzottuambkppgmsr92je0woiql5/cp0lhrumhmjamio0m6u+jhaulmhgytoh1qm17y/e/r5pq8nzlwzskmkzkuihmodixgoebekxsonlmccasmvsrgwcjitarluwicy8vkma14jov99op16qzoipwcedwai6cqq2uoa4nipaat/acr9aj9wy9we/t1oi1m9mhp7a+vggnzzrx</latexit> <latexit sha1_base64="cvgmpzvx4hqlf7sowtvlzxz8suo=">aaaccxicbva9swnbej2lxzfqjfralayhaql3abqrajywfomyd0hi2ntskiw7d8funngeaw38kzywsrd1h9jz+vpcjcka+gdg8d4mm/pcgdolbfvdsiwtr6yujddtg5tb6e3mzm5n+aektep87sugixxlzknvztsnjubslfxo6+7wbolxb6huzpeudbtqtsb9j/uywdpinqy6q6eopvhf4ov4kl5ur7kop5eevs1fr3a+k8nabxsk9eocezitpcevtwaodzlvra5pqke9tthwqukua92osdsmcdpktujfa0ygue+bhnpyunwop5+m0kfruqjns1oerlp190smhvkrce2nwhqg5r2j+j/xdhxvpb0zlwg19chsus/ksptoegvqmkmj5pehmehmbkvkgcum2osxmiesvlxiaswcyxecikmjcdmkyr8oiacohemjzqemvsbwd4/wdc/wg/vkja3xwwvc+p7zgz+w3r4aidoamg==</latexit> <latexit sha1_base64="midjfsw67e+258dkov97re2uxtu=">aaaccxicbvdpswjbfj61x2zlwx2dgjjaiwtxs10couuhdhqtcmoyo446olo7zmxg2+kxlv0rxtou0rx/oft/q/9esxpr2gcppr7vpd57nxswkpvlfriphcwl5zx0amztfso7aw5t16qfckwc7dnfnfwkcamecrrvjdqcqrb3gam7w9per18tianvxaooig2o+h7tuyyuljomviunscvpn6or+ikco6n8vegkjm7y0afv6jg5q2hnah+iputy5ey4+nm3n650zpdw18chj57cdenzteubasdikiozgwvaosqbwkpuj01npcsjbmett0bwqctd2poflk/bifp7ikzcyoi7upmjnzczxil+5zvd1ttux9qlqku8pf3ucxlupkxigv0qcfys0grhqfwtea+qqfjp8di6hlmx50mtvlstol3vaztafgmwc/zbhtjgcjtbgagab2bwdx7bm3gxhowny2y8tlttxvfmdvgd4+0l/mmbma==</latexit> <latexit sha1_base64="midjfsw67e+258dkov97re2uxtu=">aaaccxicbvdpswjbfj61x2zlwx2dgjjaiwtxs10couuhdhqtcmoyo446olo7zmxg2+kxlv0rxtou0rx/oft/q/9esxpr2gcppr7vpd57nxswkpvlfriphcwl5zx0amztfso7aw5t16qfckwc7dnfnfwkcamecrrvjdqcqrb3gam7w9per18tianvxaooig2o+h7tuyyuljomviunscvpn6or+ikco6n8vegkjm7y0afv6jg5q2hnah+iputy5ey4+nm3n650zpdw18chj57cdenzteubasdikiozgwvaosqbwkpuj01npcsjbmett0bwqctd2poflk/bifp7ikzcyoi7upmjnzczxil+5zvd1ttux9qlqku8pf3ucxlupkxigv0qcfys0grhqfwtea+qqfjp8di6hlmx50mtvlstol3vaztafgmwc/zbhtjgcjtbgagab2bwdx7bm3gxhowny2y8tlttxvfmdvgd4+0l/mmbma==</latexit> <latexit sha1_base64="v8zsjk0tq8ctlw6tmbrjzh6dnco=">aaaccxicbva9swnben3zm8avu0ubxsakioeujtzcwmbcioqxbjiy9jz7yzldvwn3tzyptdb+frslrwz9b3b+g/esijr4yodx3gwz8/yiuaud58tawfxaxlnnrexxnza3tu2d3boky4mjh0mwyqapfgfuee9tzugzkgrxn5ggpzzl/mytkyqg4loneelw1bc0obhpi3vtea9pyvvrpkc36rw58ebfpjrjhn0vkyon1lulttkza/4qd5yuwbs1rv3z7ou45krozjbslbcs6u6kpkaykvg+hsssitxefdiyvcbovccdfzkch0bpwscuposgy/x3riq4ugn3tsdheqbmvuz8z2vfojjppfressyctxyfmym6hfksseclwzolhiasqbkv4ggscgstxt6empfypklxyq5tdi+dqruyjsmh9sebkaixhimqoac14aemhsateagv1qp1bl1z75pwbws6swf+wpr4bimzl/s=</latexit> Neural Network Architecture y = X w i x i + b i z = ReLU (y) = max(y, 0)


20 Convolutional Neural Nets Deep NN: allows different weights everywhere. Convolutional NN: special case, for images, where weights are nonzero only for nearby neighbors (at the input level and later). In addition, for each layer, the pattern of the weights is the same at every location. Significantly reduces the total number of weights per layer, allowing for much deeper networks.
21 More architecture
22 <latexit sha1_base64="bhdihtjtp20hlfmpsytytweynsc=">aaacdhicbvhlbtnafb2bvzgvfbysyhehrprivwrnqyu2lbqabysikbzsbfnj8xuyynhs5he3svif/b07pomnayypiwi50khnzrmpmxpzrnbtouih59+5e+/+g4ohwapht54+6x0+v9c1vqwnrba1usqprseltgw3aq8ahbtkbv7mi7onfrlepxktv5hvg2lfz5kxnfhjqkz37qnfooscggrhdcbdyxa0r6ehxa3cfrgclqving2tfhdawfx71petn3nokc/mxqw2yzbmg6timuvanxwateni8kvls0hkrrneabisbaumo0gigd00d52oytdmgcrp1utho2gb8afen0gf7om8631piprzcqvhgmo9jcenstuqdgcc10fintaulegmpw5kwqfou61pazhytaflrdyrbrbs3xudrbrevbnlrkiz65vahvyfnrwmpek7lhtrulldonikmdvsngafv8imwdlamelurcdm1llk3j4cz8ktl98gf+nrhi3iz+p+6dnejgpyirwlaxktd+sufctnzeiy+em99mb74/3yx/t9/2ix6nv7mhfkn/bhvwevwlf3</latexit> <latexit sha1_base64="bhdihtjtp20hlfmpsytytweynsc=">aaacdhicbvhlbtnafb2bvzgvfbysyhehrprivwrnqyu2lbqabysikbzsbfnj8xuyynhs5he3svif/b07pomnayypiwi50khnzrmpmxpzrnbtouih59+5e+/+g4ohwapht54+6x0+v9c1vqwnrba1usqprseltgw3aq8ahbtkbv7mi7onfrlepxktv5hvg2lfz5kxnfhjqkz37qnfooscggrhdcbdyxa0r6ehxa3cfrgclqving2tfhdawfx71petn3nokc/mxqw2yzbmg6timuvanxwateni8kvls0hkrrneabisbaumo0gigd00d52oytdmgcrp1utho2gb8afen0gf7om8631piprzcqvhgmo9jcenstuqdgcc10fintaulegmpw5kwqfou61pazhytaflrdyrbrbs3xudrbrevbnlrkiz65vahvyfnrwmpek7lhtrulldonikmdvsngafv8imwdlamelurcdm1llk3j4cz8ktl98gf+nrhi3iz+p+6dnejgpyirwlaxktd+sufctnzeiy+em99mb74/3yx/t9/2ix6nv7mhfkn/bhvwevwlf3</latexit> <latexit sha1_base64="bhdihtjtp20hlfmpsytytweynsc=">aaacdhicbvhlbtnafb2bvzgvfbysyhehrprivwrnqyu2lbqabysikbzsbfnj8xuyynhs5he3svif/b07pomnayypiwi50khnzrmpmxpzrnbtouih59+5e+/+g4ohwapht54+6x0+v9c1vqwnrba1usqprseltgw3aq8ahbtkbv7mi7onfrlepxktv5hvg2lfz5kxnfhjqkz37qnfooscggrhdcbdyxa0r6ehxa3cfrgclqving2tfhdawfx71petn3nokc/mxqw2yzbmg6timuvanxwateni8kvls0hkrrneabisbaumo0gigd00d52oytdmgcrp1utho2gb8afen0gf7om8631piprzcqvhgmo9jcenstuqdgcc10fintaulegmpw5kwqfou61pazhytaflrdyrbrbs3xudrbrevbnlrkiz65vahvyfnrwmpek7lhtrulldonikmdvsngafv8imwdlamelurcdm1llk3j4cz8ktl98gf+nrhi3iz+p+6dnejgpyirwlaxktd+sufctnzeiy+em99mb74/3yx/t9/2ix6nv7mhfkn/bhvwevwlf3</latexit> <latexit sha1_base64="bhdihtjtp20hlfmpsytytweynsc=">aaacdhicbvhlbtnafb2bvzgvfbysyhehrprivwrnqyu2lbqabysikbzsbfnj8xuyynhs5he3svif/b07pomnayypiwi50khnzrmpmxpzrnbtouih59+5e+/+g4ohwapht54+6x0+v9c1vqwnrba1usqprseltgw3aq8ahbtkbv7mi7onfrlepxktv5hvg2lfz5kxnfhjqkz37qnfooscggrhdcbdyxa0r6ehxa3cfrgclqving2tfhdawfx71petn3nokc/mxqw2yzbmg6timuvanxwateni8kvls0hkrrneabisbaumo0gigd00d52oytdmgcrp1utho2gb8afen0gf7om8631piprzcqvhgmo9jcenstuqdgcc10fintaulegmpw5kwqfou61pazhytaflrdyrbrbs3xudrbrevbnlrkiz65vahvyfnrwmpek7lhtrulldonikmdvsngafv8imwdlamelurcdm1llk3j4cz8ktl98gf+nrhi3iz+p+6dnejgpyirwlaxktd+sufctnzeiy+em99mb74/3yx/t9/2ix6nv7mhfkn/bhvwevwlf3</latexit> <latexit sha1_base64="qq9/liwmtihlk7bmx0smtir6pdy=">aaacc3icbvc7sgnbfl3rm8zx1njmsbaigbcbqm2eqboliwjmaxmss5njmmr2dpmznyqlvy2f4c/ywchi6w/y+tdoehfnphdhcm693hupf3kmtg1/wkvlk6tr64mn5obw9s5uam+/qojielohaq9k3cokcizortpnat2ufpsepzvvujr4tvsqfqvetr6ftoxjnmbdrra2kptkd9uxydljdi6gbyfyqkndgzocexy7q3szhr67qyydt6dap8szj5kionm4aycym/podgis+vrowrfsdacq6lampwae03gygskayjlapdowvgcfqly8/wwmjozsqd1amhiatdxfezh2lrr5nun0se6rew8i/uc1it09a8vmhjgmgswwdsoodiamwaaok5ropjiee8nmryj0screm/isjosflxdjtzb37lxzzdiowqwjoiq0zmgbuyjcbzshagtu4bge4cw6t56sv+tt1rpkfc8cwb9y71/wujp9</latexit> <latexit sha1_base64="srpjo9nk3lz6/ikjm3yxgf88ae0=">aaacc3icbvc7sgnbfj2nrxhfuuubiugibmjucruramkslbiwd0g2y+zsjbkyo7vmzbrikt7gt/axbbqusfuh7pwzczkiaokbc4dz7uxee9yqualm88nilc2vrk4l11mbm1vbo+ndvbomiofjdqcsee0xsciojzvffspnubdku4w03ef54jeuija04jdqfblbrz1ouxqjpsunnrl2yp63xvamdjsc5qgnha7bhlkmoun4krseoemswtcngd/emifzejy+qz5+xlec9hvbc3dke64wq1k2rgko7bgjrtej41q7kireeib6pkuprz6rdjz9zqwptelbbib0cqwn6u+jgplsjnxxd/pi9ew8nxh/81qr6p7amevhpajhs0xdieevwekw0kocymvgmiasql4v4j4sccsdx0qhspdyiqkxc5zzsko6jtkyiqkoqabkgavoqamcgwqoaqxuwd14as/grffgvbivs9ae8t2zd/7aepscqb+cmg==</latexit> <latexit sha1_base64="srpjo9nk3lz6/ikjm3yxgf88ae0=">aaacc3icbvc7sgnbfj2nrxhfuuubiugibmjucruramkslbiwd0g2y+zsjbkyo7vmzbrikt7gt/axbbqusfuh7pwzczkiaokbc4dz7uxee9yqualm88nilc2vrk4l11mbm1vbo+ndvbomiofjdqcsee0xsciojzvffspnubdku4w03ef54jeuija04jdqfblbrz1ouxqjpsunnrl2yp63xvamdjsc5qgnha7bhlkmoun4krseoemswtcngd/emifzejy+qz5+xlec9hvbc3dke64wq1k2rgko7bgjrtej41q7kireeib6pkuprz6rdjz9zqwptelbbib0cqwn6u+jgplsjnxxd/pi9ew8nxh/81qr6p7amevhpajhs0xdieevwekw0kocymvgmiasql4v4j4sccsdx0qhspdyiqkxc5zzsko6jtkyiqkoqabkgavoqamcgwqoaqxuwd14as/grffgvbivs9ae8t2zd/7aepscqb+cmg==</latexit> <latexit sha1_base64="purzvfojsyoixn1fec1w6f1xk1w=">aaacc3icbvdlssnafj34rpuvdelmabeqhzj0oxuh0i0lfxxsa9o0tcatduhkemymhhk6d+ovuhghift/wj1/4/sbaoubc4dz7uxee7yyuaks68tyw9/y3nro7er39/ypds2j45ameofje0cseh0pscioj01ffsodwbaueoy0vvf96rfviza04ndqhbmnranoa4qr0pjrftj+xsv2bf7btm9hgfrk5bdhkceqm8kbunrumkwrys0af4i9tipggyzrfvb8ccch4qozjgxxrsbkyzbqfdmyyfcsswker2hauppyfblpzlnfjvbmkz4miqglkzhtf09kkjryhhq6m0rqkje9qfif101ucolklmejihzpfwujgyqc02cgtwxbio01qvhqfsveqyqqvjq+va5h5evv0qpwbkti31rfwn0rrw6cggioartcgbq4bg3qbbg8gcfwal6nr+pzedpe561rxmlmbpyb8fentqmy6g==</latexit> Training Given data x i, labels y(x i )andnetworku(x; w) withweightsw min w L(w) 1 n X sum is over a large number (millions) of data points. Instead approximate sum by a random subset (mini-batch) of hundreds of data points. minimize over weights by stochastic gradient descent (SGD): taking a small step in the gradient direction. Step size is called learning rate. SGD has a faster version: Nesterov s Momentum, which adds a momentum term to the update. The gradient is computed (automatically by software) using the chain rule w n+1 = w n + dt n r w L(w) i `(u(x i ; w),y(x i ))
23 <latexit sha1_base64="7xgexthan5otpeedgk0uhkj/lx0=">aaacb3icbvbns0jbfl3pvsy+rjzbdelgbplew1sbqhat0cigp0dn5o2jds6b95izl4i6a9op6a+0avfe2/5cu/5no0audubyd+fcy8w9xsiz0rb9acxm5hcwl+llizxvtfwn5ozwuqwrjlraah7isocv5uzqgmaa03iokfy9tktejzfys7dukhaik90lac3hlcgajgbtphpy9zzdpucn6gludlgvhorxqkbbd1b3r916mmvn7dhqd3gmssqljh5uacbft35ugwgjfco04vipiuogutbhujpc6tbrjrqnmengfq0ykrbpva0/vmoi9o3sqm1amhiajdxfg33sk9xzptppy91w095i/m+rrlp5uuszeuaacjj5qblxpam0cgu1mkre854hmehm/opig0tmtikuyukyoxmwfn2my2ecs5ngdiaiww7sqrocoiysneeeckdgdh7hgv6se+vjerxejqmx63tng/7aev8cn8oyfg==</latexit> <latexit sha1_base64="6ay+e2rpliaoi69aik1hsh9eqbe=">aaacb3icbvdlsgmxfm3uv62vuzecbitqecrmlnsnuohgxeul9gfthtjp2ozmmkossdrpd278ch/ajqulupux3pkzytqkapxa5r7ouzfkhi9kvcrlejcsc/mli0vj5dtk6tr6hrm5vzzbjdap4yafouohsrjlpksoyqqacoj8j5gk182p/co1ezig/fl1q9lwuzvtfsviack1d88zvqn4ci/g7rdwssgpczgc9aauc+w4ztrkwhpab2lpknqoht0xrx83bdd8qzcdhpmek8yqldxbcvujrkjrzmgwvy8kcrhuojapacqrt2qjntwxhptaacjwihrxbsfqz40y+vl2fu9p+kh15kw3fv/zapfqntriysniey6nd7uibluax6hajhuek9bxbgfb9v8h7icbsnlrpxqif07+s8po1raydlgnkqdtjmeo2amzyinjkannoabkainb8acewmi4mx6nz+nlopowvna2ws8yr58kypqb</latexit> <latexit sha1_base64="6ay+e2rpliaoi69aik1hsh9eqbe=">aaacb3icbvdlsgmxfm3uv62vuzecbitqecrmlnsnuohgxeul9gfthtjp2ozmmkossdrpd278ch/ajqulupux3pkzytqkapxa5r7ouzfkhi9kvcrlejcsc/mli0vj5dtk6tr6hrm5vzzbjdap4yafouohsrjlpksoyqqacoj8j5gk182p/co1ezig/fl1q9lwuzvtfsviack1d88zvqn4ci/g7rdwssgpczgc9aauc+w4ztrkwhpab2lpknqoht0xrx83bdd8qzcdhpmek8yqldxbcvujrkjrzmgwvy8kcrhuojapacqrt2qjntwxhptaacjwihrxbsfqz40y+vl2fu9p+kh15kw3fv/zapfqntriysniey6nd7uibluax6hajhuek9bxbgfb9v8h7icbsnlrpxqif07+s8po1raydlgnkqdtjmeo2amzyinjkannoabkainb8acewmi4mx6nz+nlopowvna2ws8yr58kypqb</latexit> <latexit sha1_base64="vkhpjlkeqzrmybifhjqbizone+0=">aaacb3icbvdlsgmxfm3uv62vuzecbitqecrmbhqjflorcvhbpqadh0yatqgzzjbklgxanrt/xy0lrdz6c+78gzntew09clmhc+4lucepgjxksr6mznlyyupadj23sbm1vwpu7tvkgatmqjhkowj4sbjgoakqqhhprikgwgek7vflqv+/j0lskn+qyutcahu57vcmljy88/cqmdibf/a6baewrsjjwcjhaddyndvhm/nw0zoa/hb7nutbdbxp/gy1qxwhhcvmkjrn24mumychkgzkngvfkkqi91gxndxlkcdstsz3jogxvtqwewpdxmgj+nsjqyguw8dxkwfsptnvpej/xjnwnxm3otykfef4+lanzlcfma0ftqkgwlghjgglqv8kcq8jhjwolqddwdh5kdscom0v7rsrxyrp4sica3aecsagz6aelkefvaegd+ajvibx49f4nt6m9+loxpjt7im/md6+are0lus=</latexit> <latexit sha1_base64="awvnnrfn/h+ajixbwucdpoxt5fs=">aaacbxicbvc7sgnbfl0bxzg+opzadayhiotdfgojbnkiweqwd0iwoduzjenmz5ezwupyplhxk+xtlbsx9r/s/bsniyhgd1zu4zx7mbnhczlt2ry/rmtc/mliuni5tbk6tr6r3tyqqccshjzjwanz87cinala1kxzwgslxb7hadxrfcd+9yzkxqjxpqchdx3ceazncnzgaqz3z7p9a3sklsbtedvoqbgpbbr2h02nmc7yoxsc9e2cwzipokp7awaondpvjvzaip8ktthwqu7kq+3gwgpgob2lgpgiisy93kf1qwx2qxljyrujtg+ufmoh0ptqakl+3iixr9ta98ykj3vxzxpj8t+vhun2irszeuaacjj9qb1xpam0jgs1mkre84ehmehm/opif0tmtakuzul4c/jfusnnhdvnxjo0ijbfenzgd7lgwdeu4axkuayct/aat/bs3vmp1ov1oh1nwf872/al1tsnabax2q==</latexit> <latexit sha1_base64="uxo1olhgseo3jgo0njbjeeyaw0y=">aaacbxicbvdlsgmxfm3uv62vqktdbitqecpmf+pgkhqj4qif+4b2gdjppg3nziyky6ntbtz4fe7dufckw//bnt8jpq2ith643mm595lc44amsmwah0ziyxfpesw5mlpb39jcsm/vvguqcuwqogcbqltieky5qsiqgkmhgidfzatmdotjv3zdhkqbv1b9kng+anpquyyulpz0/mw2dwtp4dw4hcmmcsvlayed3scxnhtgzjktwb9izzjmaz48leeftyun/d5sbtjycveyiskbvj5udoyeopiryaozsrii3evt0tcui59io55cmyshwmlblxc6uiit9fdgjhwp+76rj32konlwg4v/ey1iewd2thkykclx9cevylafcbwjbffbsgj9trawvp8v4g4sccsdxeqhmhfypknmc5azs8o6jskyign2wahiagucggk4acvqarjcgufwdf6me+pjgbmv09ge8b2zc/7aepsc0w6z9g==</latexit> <latexit sha1_base64="uxo1olhgseo3jgo0njbjeeyaw0y=">aaacbxicbvdlsgmxfm3uv62vqktdbitqecpmf+pgkhqj4qif+4b2gdjppg3nziyky6ntbtz4fe7dufckw//bnt8jpq2ith643mm595lc44amsmwah0ziyxfpesw5mlpb39jcsm/vvguqcuwqogcbqltieky5qsiqgkmhgidfzatmdotjv3zdhkqbv1b9kng+anpquyyulpz0/mw2dwtp4dw4hcmmcsvlayed3scxnhtgzjktwb9izzjmaz48leeftyun/d5sbtjycveyiskbvj5udoyeopiryaozsrii3evt0tcui59io55cmyshwmlblxc6uiit9fdgjhwp+76rj32konlwg4v/ey1iewd2thkykclx9cevylafcbwjbffbsgj9trawvp8v4g4sccsdxeqhmhfypknmc5azs8o6jskyign2wahiagucggk4acvqarjcgufwdf6me+pjgbmv09ge8b2zc/7aepsc0w6z9g==</latexit> <latexit sha1_base64="qureyautr9ztow0pxyawnj0me+u=">aaacbxicbvdlsgmxfm34rpu16lixwsjuhdltjw6eqjciliryb7tdkekzbwgmgzkmpbtdupfx3lhqxk3/4m6/mdmw0dydl3s4516se4kyuaud58tawl5zxvvpbgq3t7z3du29/zosicskigutshegrrjlpkqpzqqrs4kigjf60cunfv2eseufv9odmhgr6naauoy0kxz76drfp4wx8cztz7bfykwz4hduh/mub+ecgjmb/chupmmbgsq+/dlqc5xehgvmkfjntxhrb4ikppircbavkbij3emd0jsuo4gobzi5ygxpjnkgozcmuiyt9ffgeevkdalatezid9w8l4r/ec1ehxfekpi40ytj6unhwqawmi0etqkkwlobiqhlav4kcrdjhlujlmtcwdh5kdskbdcpuldorlsexzebh+ay5ielzkejxiekqaimhsateagv1qp1bl1z79prjwu2cwd+wpr4bt/4lky=</latexit> Technical Details Training CNNs is buggy. Gradients can be zero, causing training to stall, or can blow up. Lots of hacks or heuristics used to help. J(w) =L(w)+ w 2 2 J(w) =L(w)+ w 1 Regularization: the loss function is nonconvex. So add an extra term to make it convex, and keep the weights small. Called weight decay. Data augmentation: cutout: change the images at each stage, keeping same labels Dropout: randomly set half the weights to zero at each iteration. (Heuristic which helps) batch normalization: normalize the input data to each neuron, to be mean zero var = 1.
24 Challenges for rigorous deep learning it is not clear that the existing AI paradigm is immediately amenable to any sort of software engineering validation and verification. This is a serious issue, and is a potential roadblock to DoD s use of these modern AI systems, especially when considering the liability and accountability of using AI in lethal systems. JASON report (italics mine)
25 Evolution of engineering discipline

26 Importance of -ilities Reliability maintainability accountability verifiability evolvability attackability

27 Challenge: Adversarial Examples Goodfellow, Explaining and Harnessing Adversarial Examples, 2015
28 Hot current topic: next time we will talk about our progress on it.
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Artificial Neural Networks
 Artificial Neural Networks Andres Chavez Math 382/L T/Th 2:00-3:40 April 13, 2010 Chavez2 Abstract The main interest of this paper is Artificial Neural Networks (ANNs). A brief history of the development
Artificial Neural Networks Andres Chavez Math 382/L T/Th 2:00-3:40 April 13, 2010 Chavez2 Abstract The main interest of this paper is Artificial Neural Networks (ANNs). A brief history of the development
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
MASTER OF SCIENCE (M.S.) MAJOR IN COMPUTER SCIENCE
 MAJOR IN COMPUTER SCIENCE") Master of Science (M.S.) Major in Computer Science 1 MASTER OF SCIENCE (M.S.) MAJOR IN COMPUTER SCIENCE Major Program The programs in computer science are designed to prepare students for doctoral research,
Master of Science (M.S.) Major in Computer Science 1 MASTER OF SCIENCE (M.S.) MAJOR IN COMPUTER SCIENCE Major Program The programs in computer science are designed to prepare students for doctoral research,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Knowledge-Based - Systems
 Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Distributed Learning of Multilingual DNN Feature Extractors using GPUs
 Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Courses in English. Application Development Technology. Artificial Intelligence. 2017/18 Spring Semester. Database access
 The courses availability depends on the minimum number of registered students (5). If the course couldn t start, students can still complete it in the form of project work and regular consultations with
The courses availability depends on the minimum number of registered students (5). If the course couldn t start, students can still complete it in the form of project work and regular consultations with
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Mathematics process categories
 Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Top US Tech Talent for the Top China Tech Company
 THE FALL 2017 US RECRUITING TOUR Top US Tech Talent for the Top China Tech Company INTERVIEWS IN 7 CITIES Tour Schedule CITY Boston, MA New York, NY Pittsburgh, PA Urbana-Champaign, IL Ann Arbor, MI Los
THE FALL 2017 US RECRUITING TOUR Top US Tech Talent for the Top China Tech Company INTERVIEWS IN 7 CITIES Tour Schedule CITY Boston, MA New York, NY Pittsburgh, PA Urbana-Champaign, IL Ann Arbor, MI Los
Abstractions and the Brain
 Abstractions and the Brain Brian D. Josephson Department of Physics, University of Cambridge Cavendish Lab. Madingley Road Cambridge, UK. CB3 OHE bdj10@cam.ac.uk http://www.tcm.phy.cam.ac.uk/~bdj10 ABSTRACT
Abstractions and the Brain Brian D. Josephson Department of Physics, University of Cambridge Cavendish Lab. Madingley Road Cambridge, UK. CB3 OHE bdj10@cam.ac.uk http://www.tcm.phy.cam.ac.uk/~bdj10 ABSTRACT
CS224d Deep Learning for Natural Language Processing. Richard Socher, PhD
 CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the SAT
 The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
SORT: Second-Order Response Transform for Visual Recognition
 SORT: Second-Order Response Transform for Visual Recognition Yan Wang 1, Lingxi Xie 2( ), Chenxi Liu 2, Siyuan Qiao 2 Ya Zhang 1( ), Wenjun Zhang 1, Qi Tian 3, Alan Yuille 2 1 Cooperative Medianet Innovation
SORT: Second-Order Response Transform for Visual Recognition Yan Wang 1, Lingxi Xie 2( ), Chenxi Liu 2, Siyuan Qiao 2 Ya Zhang 1( ), Wenjun Zhang 1, Qi Tian 3, Alan Yuille 2 1 Cooperative Medianet Innovation
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
arxiv: v1 [cs.dc] 19 May 2017
![arxiv: v1 [cs.dc] 19 May 2017](/thumbs/71/66085786.jpg "arxiv: v1 [cs.dc] 19 May 2017") Atari games and Intel processors Robert Adamski, Tomasz Grel, Maciej Klimek and Henryk Michalewski arxiv:1705.06936v1 [cs.dc] 19 May 2017 Intel, deepsense.io, University of Warsaw Robert.Adamski@intel.com,
Atari games and Intel processors Robert Adamski, Tomasz Grel, Maciej Klimek and Henryk Michalewski arxiv:1705.06936v1 [cs.dc] 19 May 2017 Intel, deepsense.io, University of Warsaw Robert.Adamski@intel.com,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Objectives. Chapter 2: The Representation of Knowledge. Expert Systems: Principles and Programming, Fourth Edition
 Chapter 2: The Representation of Knowledge Expert Systems: Principles and Programming, Fourth Edition Objectives Introduce the study of logic Learn the difference between formal logic and informal logic
Chapter 2: The Representation of Knowledge Expert Systems: Principles and Programming, Fourth Edition Objectives Introduce the study of logic Learn the difference between formal logic and informal logic
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS
 COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Empowering Public Education Through Online Learning
 May 27, 2009 Empowering Public Education Through Online Learning Peter Stewart Curtis Johnson Agenda Introduction Curtis Johnson, Author Curtis has written a business style book about the education market
May 27, 2009 Empowering Public Education Through Online Learning Peter Stewart Curtis Johnson Agenda Introduction Curtis Johnson, Author Curtis has written a business style book about the education market
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
Knowledge based expert systems D H A N A N J A Y K A L B A N D E
 Knowledge based expert systems D H A N A N J A Y K A L B A N D E What is a knowledge based system? A Knowledge Based System or a KBS is a computer program that uses artificial intelligence to solve problems
Knowledge based expert systems D H A N A N J A Y K A L B A N D E What is a knowledge based system? A Knowledge Based System or a KBS is a computer program that uses artificial intelligence to solve problems
Grade Band: High School Unit 1 Unit Target: Government Unit Topic: The Constitution and Me. What Is the Constitution? The United States Government
 The Constitution and Me This unit is based on a Social Studies Government topic. Students are introduced to the basic components of the U.S. Constitution, including the way the U.S. government was started
The Constitution and Me This unit is based on a Social Studies Government topic. Students are introduced to the basic components of the U.S. Constitution, including the way the U.S. government was started
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE. Junior Year. Summer (Bridge Quarter) Fall Winter Spring GAME Credits.
 Fall Winter Spring GAME Credits.") DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Automating the E-learning Personalization
 Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Massachusetts Institute of Technology Tel: Massachusetts Avenue Room 32-D558 MA 02139
 Hariharan Narayanan Massachusetts Institute of Technology Tel: 773.428.3115 LIDS har@mit.edu 77 Massachusetts Avenue http://www.mit.edu/~har Room 32-D558 MA 02139 EMPLOYMENT Massachusetts Institute of
Hariharan Narayanan Massachusetts Institute of Technology Tel: 773.428.3115 LIDS har@mit.edu 77 Massachusetts Avenue http://www.mit.edu/~har Room 32-D558 MA 02139 EMPLOYMENT Massachusetts Institute of
GACE Computer Science Assessment Test at a Glance
 GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and