arxiv: v1 [cs.cl] 22 Sep 2015
|
|
|
- Nicholas Johnson
- 5 years ago
- Views:
Transcription
1 Reasoning about Entailment with Neural Attention Tim Rocktäschel University College London Edward Grefenstette & Karl Moritz Hermann Google DeepMind arxiv: v1 [cs.cl] 22 Sep 2015 Tomáš Kočiský University of Oxford Phil Blunsom Google DeepMind & University of Oxford Abstract Automatically recognizing entailment relations between pairs of natural language sentences has so far been the dominion of classifiers employing hand engineered features derived from natural language processing pipelines. End-to-end differentiable neural architectures have failed to approach state-of-the-art performance until very recently. In this paper, we propose a neural model that reads two sentences to determine entailment using long short-term memory units. We extend this model with a word-by-word neural attention mechanism that encourages reasoning over entailments of pairs of words and phrases. Furthermore, we present a qualitative analysis of attention weights produced by this model, demonstrating such reasoning capabilities. On a large entailment dataset this model outperforms the previous best neural model and a classifier with engineered features by a substantial margin. It is the first generic end-to-end differentiable system that achieves state-of-the-art accuracy on a textual entailment dataset. 1 Introduction The ability to determine the semantic relationship between two sentences is an integral part of machines that understand and reason with natural language. Recognizing textual entailment (RTE) is the task of determining whether two natural language sentences are (i) contradicting each other, (ii) not related, or whether (iii) the first sentence (called premise) entails the second sentence (called hypothesis). This task is important since many natural language processing (NLP) problems, such as information extraction, relation extraction, text summarization or machine translation, rely on it explicitly or implicitly and could benefit from more accurate RTE systems [Dagan et al., 2006]. State-of-the-art systems for RTE so far relied heavily on engineered NLP pipelines, extensive manual creation of features, as well as various external resources and specialized subcomponents such as negation detection [see for example Lai and Hockenmaier, 2014, Jimenez et al., 2014, Zhao et al., 2014, Beltagy et al., 2015]. In contrast, end-to-end differentiable neural architectures failed to get close to acceptable performance due to the lack of large high-quality RTE datasets. An end-to-end differentiable solution to RTE is desirable, since it avoids specific assumptions about the underlying language. In particular, there is no need for language features like part-of-speech tags or dependency parses. Furthermore, a generic sequence-to-sequence solution allows to extend the concept of capturing entailment across any sequential data, not only natural language. Recently, Bowman et al. [2015] published the Stanford Natural Language Inference (SNLI) corpus accompanied by a neural network with long short-term memory units [LSTM, Hochreiter and Schmidhuber, 1997], which achieves an accuracy of 77.6% for RTE on this dataset. It is the first time a generic neural model without hand-crafted features got close to the accuracy of classifier with 1
2 engineered features for RTE. This can be explained by the high quality and size of SNLI compared to the two orders of magnitude smaller and partly synthetic datasets so far used to evaluate RTE systems. Bowman et al. s LSTM encodes the premise and hypothesis as dense fixed-length vectors whose concatenation is subsequently used in a multi-layer perceptron (MLP) for classification. In contrast, we are proposing an attentive neural network that is capable of reasoning over entailments of pairs of words and phrases by processing the hypothesis conditioned on the premise. Our contributions are threefold: (i) We present a neural model based on LSTMs that reads two sentences in one go to determine entailment, as opposed to mapping each sentence independently into a semantic space ( 2.2), (ii) We extend this model with a neural word-by-word attention mechanism to encourage reasoning over entailments of pairs of words and phrases ( 2.4), and (iii) We provide a detailed qualitative analysis of neural attention for RTE ( 4.1). Our benchmark LSTM achieves an accuracy of 80.9% on SNLI, outperforming a classifier with hand-crafted lexical features tailored to RTE by 2.7 percentage points. An extension with word-by-word neural attention surpasses this strong benchmark LSTM result by 2.6 percentage points, setting a new state-of-the-art accuracy of 83.5% for recognizing entailment on SNLI. 2 Methods In this section we discuss LSTMs ( 2.1) and describe how they can be applied to RTE ( 2.2). We introduce an extension of an LSTM for RTE with neural attention ( 2.3) and word-by-word attention ( 2.4). Finally, we show how such attentive models can easily be used for attending both ways: over the premise conditioned on the hypothesis and over the hypothesis conditioned on the premise ( 2.5). 2.1 LSTMs Recurrent neural networks (RNNs) with long short-term memory (LSTM) units [Hochreiter and Schmidhuber, 1997] have been successfully applied to a wide range of NLP tasks, such as machine translation [Sutskever et al., 2014, Bahdanau et al., 2014], constituency parsing [Vinyals et al., 2014], language modeling [Zaremba et al., 2014] and recently RTE [Bowman et al., 2015]. LSTMs encompass memory cells that can store information for a long period of time, as well as three types of gates that control the flow of information into and out of these cells: input gates (Eq. 2), forget gates (Eq. 3) and output gates (Eq. 4). Given an input vector x t at time step t, the previous output h t 1 and cell state c t 1, an LSTM with hidden size k computes the next output h t and cell state c t as [ ] xt H = (1) h t 1 o t = σ(w o H + b o ) (4) i t = σ(w i H + b i ) (2) f t = σ(w f H + b f ) (3) c t = f t c t 1 + i t tanh(w c H + b c ) (5) h t = o t tanh(c t ) (6) where W i, W f, W o, W c R 2k k are trained matrices and b i, b f, b o, b c R k trained biases that parameterize the gates and transformations of the input, σ denotes the element-wise application of the sigmoid function and the element-wise multiplication of two vectors. 2.2 Recognizing Textual Entailment with LSTMs LSTMs can readily be used for RTE by independently encoding the premise and hypothesis as dense vectors and taking their concatenation as input to an MLP classifier [Bowman et al., 2015]. This demonstrates that LSTMs can learn semantically rich sentence representations that are suitable for determining textual entailment. In contrast to learning sentence representations, we are interested in neural models that read both sentences to determine entailment, thereby reasoning over entailments of pairs of words and phrases. Figure 1 shows the high-level structure of this model. The premise (left) is read by an LSTM (A). A second LSTM with different parameters is reading a delimiter and the hypothesis (right), but its memory state is initialized with the last cell state of the previous LSTM (c 5 in the example). We use word2vec vectors [Mikolov et al., 2013] as word representations, which we do not optimize 2
3 (C) Word-by-word Attention (B) Attention h 1 h 2 h 3 h 4 h 5 h 6 h 7 h 8 h 9 (A) LSTMs c 1 c 2 c 3 c 4 c 5 c 6 c 7 c 8 c 9 x 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 A wedding party taking pictures :: Someone got married Premise Hypothesis Figure 1: Recognizing textual entailment using two LSTMs (A), one over the premise and one over the hypothesis, with attention only based on the last output vector (h 9, B) or word-by-word attention based on all output vectors of the hypothesis (h 7, h 8 and h 9, C). during training. Out-of-vocabulary words in the training set are randomly initialized by sampling values uniformly from ( 0.05, 0.05) and optimized during training. 1 Out-of-vocabulary words encountered at inference time on the validation and test corpus are set to fixed random vectors. By not tuning representations of words for which we have word2vec vectors, we ensure that at inference time their representation stays close to unseen similar words for which we have word2vec embeddings. We use a linear layer to project word vectors to the dimensionality of the hidden size of the LSTM, yielding input vectors x i. Finally, for classification we use a softmax layer over the output of a non-linear projection of the last output vector (h 9 in the example) into the target space of the three classes (ENTAILMENT, NEUTRAL or CONTRADICTION), and train using the cross-entropy loss. 2.3 Attention Attentive neural networks have recently demonstrated success in a wide range of tasks ranging from handwriting synthesis [Graves, 2013], machine translation [Bahdanau et al., 2014], digit classification [Mnih et al., 2014], image captioning [Xu et al., 2015], speech recognition [Chorowski et al., 2015] and sentence summarization [Rush et al., 2015], to geometric reasoning [Vinyals et al., 2015]. The idea is to allow the model to attend over past output vectors (see Figure 1 B), thereby mitigating the LSTM s cell state bottleneck. More precisely, an LSTM with attention for RTE does not need to capture the whole semantics of the premise in its cell state. Instead, it is sufficient to output vectors while reading the premise and accumulating a representation in the cell state that informs the second LSTM which of the output vectors of the premise it needs to attend over to determine the RTE class. Let Y R k L be a matrix consisting of output vectors [h 1 h L ] that the first LSTM produced when reading the L words of the premise, where k is a hyperparameter denoting the size of embeddings and hidden layers. Furthermore, let e L R L be a vector of 1s and h N be the last output vector after the premise and hypothesis was processed by the two LSTMs respectively. The attention mechanism will produce a vector α of attention weights and a weighted representation r of the premise via M = tanh(w y Y + W h h N e L ) M R k L (7) α = softmax(w T M) α R L (8) r = Yα T r R k (9) where W y, W h R k k are trained projection matrices, w R k is a trained parameter vector and w T its transpose. Note that the outer product W h h N e L is repeating the linearly transformed h N as many times as there are words in the premise. Hence, the intermediate attention representation m i 1 We found 12.1k words in SNLI for which we could not obtain word2vec embeddings, resulting in 3.65M tunable parameters. 3
4 (ith column vector in M) of the ith word in the premise is obtained from a non-linear combination of the premise s output vector h i (ith column vector in Y) and the transformed h N. The attention weight for the ith word in the premise is the result of a weighted combination (parameterized by w) of values in m i. We obtain the final sentence-pair representation used for classification from 2.4 Word-by-word Attention h = tanh(w p r + W x h N ) h R k (10) For determining whether one sentence entails another it can be a good strategy to check for entailment or contradiction of individual aligned word- and phrase-pairs. To encourage such behavior we employ neural word-by-word attention similar to Bahdanau et al. [2014], Hermann et al. [2015] and Rush et al. [2015]. The difference is that we do not use attention to generate words, but to obtain a sentence-pair encoding from fine-grained reasoning via soft-alignment of words and phrases in the premise and hypothesis. In our case, this amounts to attending over the first LSTM s output vectors of the premise while the second LSTM processes the hypothesis one word at a time, thus generating attention weights α t over all output vectors of the premise for every word x t in the hypothesis (Figure 1 C). This can be modeled as follows: M t = tanh(w y Y + (W h h t + W r r t 1 ) e L ) M t R L k (11) α t = softmax(w T M t ) α t R L (12) r t = Yα T t + tanh(w t r t 1 ) r t R k (13) The final sentence-pair representation is obtained from the last attention-weighted representation r L of the premise and the last output vector h N using 2.5 Two-way Attention h = tanh(w p r L + W x h N ) h R k (14) Inspired by bidirectional LSTMs that read a sequence and its reverse for improved encoding [Graves and Schmidhuber, 2005], we introduce two-way attention for RTE. The idea is simply to use the same model that attends over the premise conditioned on the hypothesis to also attend over the hypothesis conditioned on the premise by swapping the two sequences. This produces two sentencepair representations that we concatenate for classification. 3 Experiments We conduct experiments on the Stanford Natural Language Inference corpus [SNLI, Bowman et al., 2015]. This corpus is two orders of magnitude larger than other existing RTE corpora such as Sentences Involving Compositional Knowledge [SICK, Marelli et al., 2014]. Furthermore, a large part of training examples in SICK were generated heuristically from other examples. In contrast, all sentence-pairs in SNLI stem from human annotators. The size and quality of SNLI make it a suitable resource for training neural architectures such as the ones proposed in this paper. We use ADAM [Kingma and Ba, 2014] for optimization with a first momentum coefficient of 0.9 and a second momentum coefficient of For every model we perform a small grid search over combinations of the initial learning rate [1E-4, 3E-4, 1E-3], dropout 3 [0.0, 0.1, 0.2] and l 2 - regularization strength [0.0, 1E-4, 3E-4, 1E-3]. Subsequently, we take the best configuration based on performance on the validation set, and evaluate only that configuration on the test set. 4 Results and Discussion Results on the SNLI corpus are summarized in Table 1. The total number of model parameters, including tunable word representations, is denoted by θ W+M (without word representations θ M ). 2 Standard configuration recommended by Kingma and Ba. 3 As in Zaremba et al. [2014], we apply dropout only on the inputs and outputs of the network. 4
5 Table 1: Results on the SNLI corpus. Model k θ W+M θ M Train Dev Test LSTM [Bowman et al., 2015] M 221k Classifier [Bowman et al., 2015] LSTM shared M 111k LSTM shared M 252k LSTMs M 252k Attention M 242k Attention two-way M 242k Word-by-word attention M 252k Word-by-word attention two-way M 252k To ensure a comparable number of parameters to Bowman et al. s model that encodes the premise and hypothesis independently but with one LSTM, we also run experiments with a single LSTM ( shared with k = 100) as opposed to two different LSTMs that read the premise and hypothesis respectively. In addition, we compare our attentive models to two benchmark LSTMs whose hidden sizes were chosen so that they have at least as many parameters as the attentive models. Since we are not tuning word vectors for which we have word2vec embeddings, the total number of parameters θ W+M of our models is considerably smaller. We also compare our models against the benchmark classifier used by Bowman et al., which constructs features from the BLEU score between the premise and hypothesis, length difference, word overlap, uni- and bigrams, part-of-speech tags, as well as cross uni- and bigrams. LSTM We found that processing the hypothesis conditioned on the premise instead of encoding each sentence independently gives an improvement of 3.3 percentage points in accuracy over Bowman et al. s LSTM. We argue this is due to information being able to flow from one sentence representation to the other. Specifically, the model does not waste capacity on encoding the hypothesis (in fact it does not need to encode the hypothesis at all), but can read the hypothesis in a more focused way by checking words and phrases for contradictions and entailments based on the semantic representation of the premise. One interpretation is that the LSTM is approximating a finite-state automaton for RTE [c.f. Angeli and Manning, 2014]. Another difference to Bowman et al. s model is that we are using word2vec instead of GloVe and, more importantly, do not fine-tune these word embeddings. The drop in accuracy from train to test set is less severe for our models, which suggest that fine-tuning word embeddings could be a cause of overfitting. Our LSTM outperforms a feature-engineered classifier by 2.7 percentage points. To the best of our knowledge, this is the first instance of a neural end-to-end differentiable model to achieve state-ofthe-art performance on a textual entailment dataset. Attention With attention we found a 0.9 percentage point improvement over a single LSTM with a hidden size of 159, and a 1.4 percentage point increase over a benchmark model that uses two LSTMs (one for the premise and one for the hypothesis). The attention model produces output vectors summarizing contextual information of the premise that is useful to attend over later when reading the hypothesis. Therefore, when reading the premise, the model does not have to build up a semantic representation of the whole premise, but instead a representation that helps attending over the right output vectors when processing the hypothesis. In contrast, the output vectors of the premise are not used by the benchmark LSTMs. Thus, these models have to build up a representation of the premise and carry it over through the cell state to the part that processes the hypothesis a bottleneck that can be overcome to some degree by using attention. Word-by-word Attention Enabling the model to attend over output vectors of the premise for each word in the hypothesis yields another 1.2 percentage point improvement compared to attending conditioned only on the last output vector of the premise. We argue that this is due to the model being able to check for entailment or contradiction of individual words in the hypothesis, and demonstrate this effect in the qualitative analysis below. 5

6 (a) (b) (c) (d) Figure 2: Attention visualizations. Two-way Attention Allowing the model to also attend over the hypothesis based on the premise does not seem to improve performance on RTE. We suspect that this is due to entailment being an asymmetric relation. Hence, using the same LSTM to encode the hypothesis (in one direction) and the premise (in the other direction) might lead to noise in the training signal. This could be addressed by training different LSTMs at the cost of doubling the number of model parameters. 4.1 Qualitative Analysis It is instructive to analyze which output representations the model is attending over when deciding the class of an RTE example. Note that interpretations based on attention weights have to be taken with care since the model is not forced to solely rely on representations obtained from attention (see Eq. 10 and 14). In the following we visualize and discuss the attention patterns of the presented attentive models. For each attentive model we hand-picked examples from ten samples of the validation set. Attention Figure 2 shows to what extent the attentive model focuses on contextual representations of the premise after both LSTMs processed the premise and hypothesis respectively. Note how the model pays attention to output vectors of words that are semantically coherent with the premise ( riding and rides, animal and camel, 2a) or in contradiction, as caused by a single word ( blue vs. pink, 2b) or multiple words ( swim and lake vs. frolicking and grass, 2c). Interestingly, the model shows contextual understanding by not attending over yellow, the color of the toy, but pink, the color of the coat. However, for more involved examples with longer premises we found that attention is more uniformly distributed (2d). This suggests that conditioning attention only on the last output has limitations when multiple words need to be considered for deciding the RTE class. Word-by-word Attention Visualizations of word-by-word attention are depicted in Figure 3. We found that word-by-word attention can easily detect if the hypothesis is simply a reordering of words in the premise (3a). Furthermore, it is able to resolve synonyms ( airplane and aircraft, 3c) and capable of matching multi-word expressions to single words ( garbage can to trashcan, 3b). It is also noteworthy that irrelevant parts of the premise, such as words capturing little meaning or whole uninformative relative clauses, are correctly neglected for determining entailment ( which also has a rope leading out of it, 3b). Word-by-word attention seems to also work well when words in the premise and hypothesis are connected via deeper semantics or common-sense knowledge ( snow can be found outside and a 6
 (d)")
")
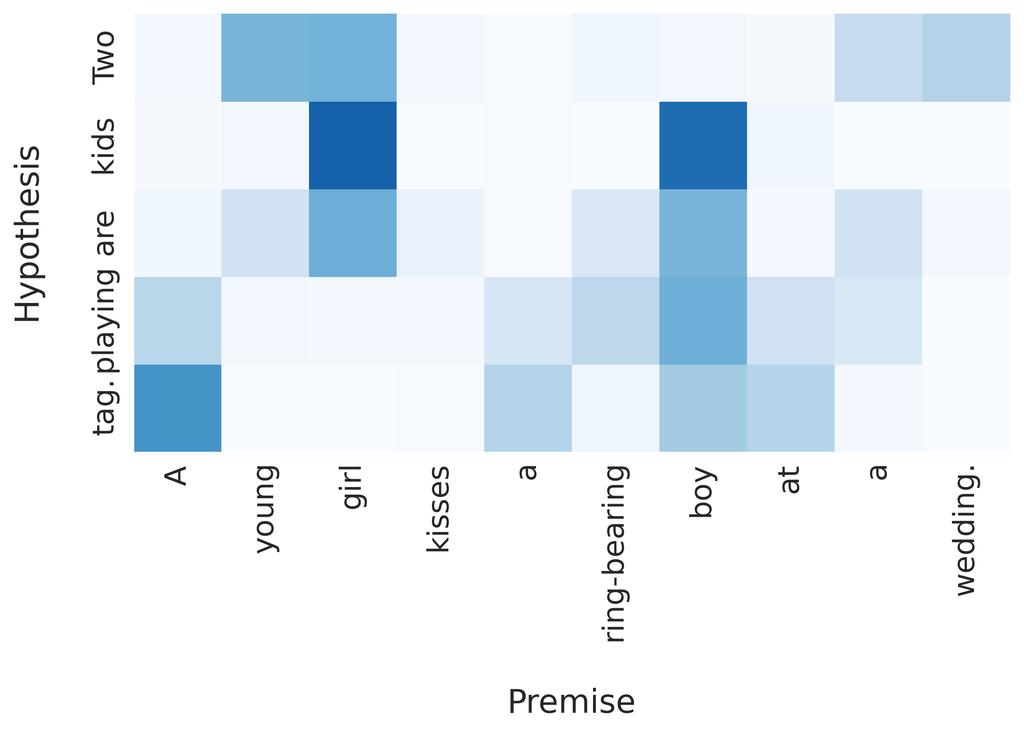
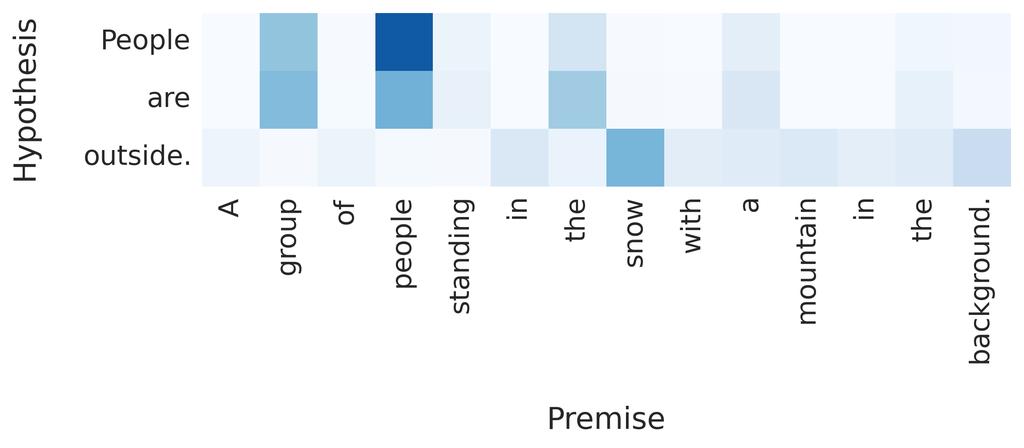
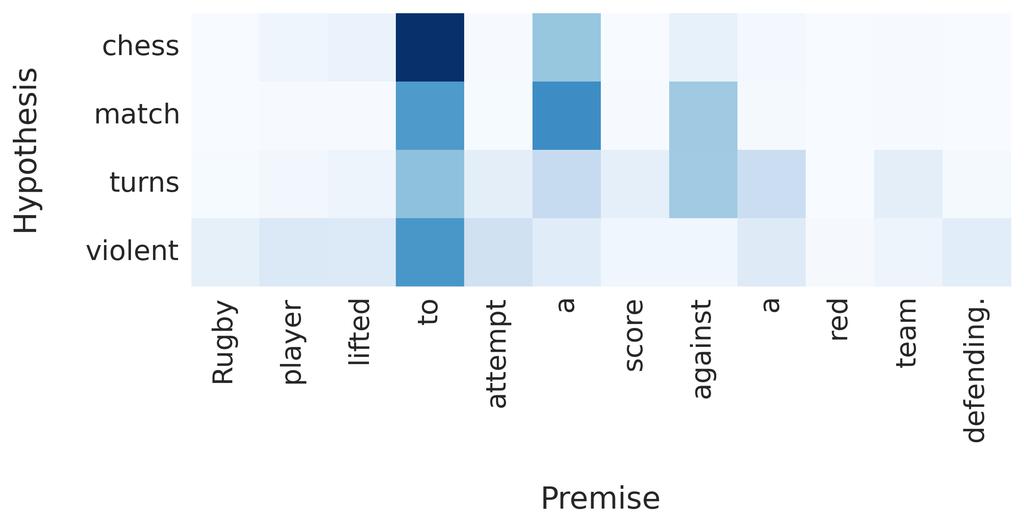
7 (a) (b) (c) (d) (e) (f) (g) Figure 3: Word-by-word attention visualizations. 7
8 mother is an adult, 3e and 3g). Furthermore, the model is able to resolve one-to-many relationships ( kids to boy and girl, 3d) Attention can fail, for example when the two sentences and their words are entirely unrelated (3f). In such cases, the model seems to back up to attending over function words, and the sentence-pair representation is likely dominated by the last output vector (see Eq. 14). 5 Conclusion In this paper, we show how the state-of-the-art in recognizing textual entailment on a large, humancurated and annotated corpus, can be improved with general end-to-end differentiable models. Our results demonstrate that LSTM recurrent neural networks that read pairs of sequences to produce a final representation from which a simple classifier predicts entailment, outperform both a neural baseline as well as a classifier with hand-engineered features. Furthermore, extending these models with attention over the premise provides further improvements to the predictive abilities of the system, resulting in a new state-of-the-art accuracy for recognizing entailment on the Stanford Natural Language Inference corpus. The models presented here are general sequence models, requiring no appeal to natural language specific processing beyond tokenization, and are therefore a suitable target for transfer learning through pre-training the recurrent systems on other corpora, and conversely, applying the models trained on this corpus to other entailment tasks. Future work will focus on such transfer learning tasks, as well as scaling the methods presented here to larger units of text (e.g. paragraphs and entire documents) using hierarchical attention mechanisms. Furthermore, we aim to investigate the application of these generic models to non-natural language sequential entailment problems. Acknowledgements We thank Nando de Freitas, Samuel Bowman and Jonathan Berant for their helpful comments on drafts of this paper. References Gabor Angeli and Christopher D Manning. Naturalli: Natural logic inference for common sense reasoning. In Conference on Empirical Methods in Natural Language Processing (EMNLP), Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations (ICLR), Islam Beltagy, Stephen Roller, Pengxiang Cheng, Katrin Erk, and Raymond J. Mooney. Representing meaning with a combination of logical form and vectors. arxiv preprint arxiv: , Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. In Conference on Empirical Methods in Natural Language Processing (EMNLP), Jan Chorowski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyunghyun Cho, and Yoshua Bengio. Attention-based models for speech recognition. In Advances in Neural Information Processing Systems (NIPS), Ido Dagan, Oren Glickman, and Bernardo Magnini. The pascal recognising textual entailment challenge. In Machine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising tectual entailment, pages Springer, Alex Graves. Generating sequences with recurrent neural networks. arxiv preprint arxiv: , Alex Graves and Jürgen Schmidhuber. Framewise phoneme classification with bidirectional lstm and other neural network architectures. Neural Networks, 18(5): ,
9 Karl Moritz Hermann, Tomáš Kočiský, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Blunsom. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems (NIPS), Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8): , Sergio Jimenez, George Duenas, Julia Baquero, Alexander Gelbukh, Av Juan Dios Bátiz, and Av Mendizábal. Unal-nlp: Combining soft cardinality features for semantic textual similarity, relatedness and entailment. In SemEval 2014, page 732, Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), Alice Lai and Julia Hockenmaier. Illinois-lh: A denotational and distributional approach to semantics. In SemEval 2014, page 329, Marco Marelli, Luisa Bentivogli, Marco Baroni, Raffaella Bernardi, Stefano Menini, and Roberto Zamparelli. Semeval-2014 task 1: Evaluation of compositional distributional semantic models on full sentences through semantic relatedness and textual entailment. In SemEval-2014, Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (NIPS), pages , Volodymyr Mnih, Nicolas Heess, Alex Graves, et al. Recurrent models of visual attention. In Advances in Neural Information Processing Systems (NIPS), pages , Alexander M Rush, Sumit Chopra, and Jason Weston. A neural attention model for abstractive sentence summarization. In Conference on Empirical Methods in Natural Language Processing (EMNLP), Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems (NIPS), pages , Oriol Vinyals, Lukasz Kaiser, Terry Koo, Slav Petrov, Ilya Sutskever, and Geoffrey Hinton. Grammar as a foreign language. In Advances in Neural Information Processing Systems (NIPS), Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In Advances in Neural Information Processing Systems (NIPS), Kelvin Xu, Jimmy Ba, Ryan Kiros, Aaron Courville, Ruslan Salakhutdinov, Richard Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In International Conference on Machine Learning (ICML), Wojciech Zaremba, Ilya Sutskever, and Oriol Vinyals. arxiv preprint arxiv: , Recurrent neural network regularization. Jiang Zhao, Tian Tian Zhu, and Man Lan. Ecnu: One stone two birds: Ensemble of heterogenous measures for semantic relatedness and textual entailment. In SemEval 2014, page 271,
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Probing for semantic evidence of composition by means of simple classification tasks
 Probing for semantic evidence of composition by means of simple classification tasks Allyson Ettinger 1, Ahmed Elgohary 2, Philip Resnik 1,3 1 Linguistics, 2 Computer Science, 3 Institute for Advanced
Probing for semantic evidence of composition by means of simple classification tasks Allyson Ettinger 1, Ahmed Elgohary 2, Philip Resnik 1,3 1 Linguistics, 2 Computer Science, 3 Institute for Advanced
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
 Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках
 Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
arxiv: v5 [cs.ai] 18 Aug 2015
![arxiv: v5 [cs.ai] 18 Aug 2015](/thumbs/71/66241401.jpg "arxiv: v5 [cs.ai] 18 Aug 2015") When Are Tree Structures Necessary for Deep Learning of Representations? Jiwei Li 1, Minh-Thang Luong 1, Dan Jurafsky 1 and Eduard Hovy 2 1 Computer Science Department, Stanford University, Stanford, CA
When Are Tree Structures Necessary for Deep Learning of Representations? Jiwei Li 1, Minh-Thang Luong 1, Dan Jurafsky 1 and Eduard Hovy 2 1 Computer Science Department, Stanford University, Stanford, CA
A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS
 A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka & Richard Socher The University of Tokyo {hassy, tsuruoka}@logos.t.u-tokyo.ac.jp
A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka & Richard Socher The University of Tokyo {hassy, tsuruoka}@logos.t.u-tokyo.ac.jp
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
ON THE USE OF WORD EMBEDDINGS ALONE TO
 ON THE USE OF WORD EMBEDDINGS ALONE TO REPRESENT NATURAL LANGUAGE SEQUENCES Anonymous authors Paper under double-blind review ABSTRACT To construct representations for natural language sequences, information
ON THE USE OF WORD EMBEDDINGS ALONE TO REPRESENT NATURAL LANGUAGE SEQUENCES Anonymous authors Paper under double-blind review ABSTRACT To construct representations for natural language sequences, information
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
FBK-HLT-NLP at SemEval-2016 Task 2: A Multitask, Deep Learning Approach for Interpretable Semantic Textual Similarity
 FBK-HLT-NLP at SemEval-2016 Task 2: A Multitask, Deep Learning Approach for Interpretable Semantic Textual Similarity Simone Magnolini Fondazione Bruno Kessler University of Brescia Brescia, Italy magnolini@fbkeu
FBK-HLT-NLP at SemEval-2016 Task 2: A Multitask, Deep Learning Approach for Interpretable Semantic Textual Similarity Simone Magnolini Fondazione Bruno Kessler University of Brescia Brescia, Italy magnolini@fbkeu
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
arxiv: v3 [cs.cl] 7 Feb 2017
![arxiv: v3 [cs.cl] 7 Feb 2017](/thumbs/71/66154314.jpg "arxiv: v3 [cs.cl] 7 Feb 2017") NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
arxiv: v1 [cs.cl] 20 Jul 2015
![arxiv: v1 [cs.cl] 20 Jul 2015](/thumbs/71/66201242.jpg "arxiv: v1 [cs.cl] 20 Jul 2015") How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM. Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim
 NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim School of Computing KAIST Daejeon, South Korea ABSTRACT
NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim School of Computing KAIST Daejeon, South Korea ABSTRACT
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
arxiv: v3 [cs.cl] 24 Apr 2017
![arxiv: v3 [cs.cl] 24 Apr 2017](/thumbs/71/65554092.jpg "arxiv: v3 [cs.cl] 24 Apr 2017") A Network-based End-to-End Trainable Task-oriented Dialogue System Tsung-Hsien Wen 1, David Vandyke 1, Nikola Mrkšić 1, Milica Gašić 1, Lina M. Rojas-Barahona 1, Pei-Hao Su 1, Stefan Ultes 1, and Steve
A Network-based End-to-End Trainable Task-oriented Dialogue System Tsung-Hsien Wen 1, David Vandyke 1, Nikola Mrkšić 1, Milica Gašić 1, Lina M. Rojas-Barahona 1, Pei-Hao Su 1, Stefan Ultes 1, and Steve
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Semantic and Context-aware Linguistic Model for Bias Detection
 Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Arizona s English Language Arts Standards th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS
 Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting
 LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
arxiv: v2 [cs.cl] 18 Nov 2015
![arxiv: v2 [cs.cl] 18 Nov 2015](/thumbs/71/65547585.jpg "arxiv: v2 [cs.cl] 18 Nov 2015") MULTILINGUAL IMAGE DESCRIPTION WITH NEURAL SEQUENCE MODELS Desmond Elliott ILLC, University of Amsterdam; Centrum Wiskunde & Informatica d.elliott@uva.nl arxiv:1510.04709v2 [cs.cl] 18 Nov 2015 Stella Frank
MULTILINGUAL IMAGE DESCRIPTION WITH NEURAL SEQUENCE MODELS Desmond Elliott ILLC, University of Amsterdam; Centrum Wiskunde & Informatica d.elliott@uva.nl arxiv:1510.04709v2 [cs.cl] 18 Nov 2015 Stella Frank
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
arxiv: v2 [cs.cl] 26 Mar 2015
![arxiv: v2 [cs.cl] 26 Mar 2015](/thumbs/71/65580310.jpg "arxiv: v2 [cs.cl] 26 Mar 2015") Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization
 LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
The RWTH Aachen University English-German and German-English Machine Translation System for WMT 2017
 The RWTH Aachen University English-German and German-English Machine Translation System for WMT 2017 Jan-Thorsten Peter, Andreas Guta, Tamer Alkhouli, Parnia Bahar, Jan Rosendahl, Nick Rossenbach, Miguel
The RWTH Aachen University English-German and German-English Machine Translation System for WMT 2017 Jan-Thorsten Peter, Andreas Guta, Tamer Alkhouli, Parnia Bahar, Jan Rosendahl, Nick Rossenbach, Miguel
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX,
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Language Model and Grammar Extraction Variation in Machine Translation
 Language Model and Grammar Extraction Variation in Machine Translation Vladimir Eidelman, Chris Dyer, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department
Language Model and Grammar Extraction Variation in Machine Translation Vladimir Eidelman, Chris Dyer, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter
 ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Facing our Fears: Reading and Writing about Characters in Literary Text
 Facing our Fears: Reading and Writing about Characters in Literary Text by Barbara Goggans Students in 6th grade have been reading and analyzing characters in short stories such as "The Ravine," by Graham
Facing our Fears: Reading and Writing about Characters in Literary Text by Barbara Goggans Students in 6th grade have been reading and analyzing characters in short stories such as "The Ravine," by Graham
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
A deep architecture for non-projective dependency parsing
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Noisy SMS Machine Translation in Low-Density Languages
 Noisy SMS Machine Translation in Low-Density Languages Vladimir Eidelman, Kristy Hollingshead, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department of
Noisy SMS Machine Translation in Low-Density Languages Vladimir Eidelman, Kristy Hollingshead, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department of
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks
 Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks Rajarshi Das Manzil Zaheer Siva Reddy and Andrew McCallum College of Information and Computer Sciences, University
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks Rajarshi Das Manzil Zaheer Siva Reddy and Andrew McCallum College of Information and Computer Sciences, University
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Stacks Teacher notes. Activity description. Suitability. Time. AMP resources. Equipment. Key mathematical language. Key processes
 Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Unsupervised Cross-Lingual Scaling of Political Texts
 Unsupervised Cross-Lingual Scaling of Political Texts Goran Glavaš and Federico Nanni and Simone Paolo Ponzetto Data and Web Science Group University of Mannheim B6, 26, DE-68159 Mannheim, Germany {goran,
Unsupervised Cross-Lingual Scaling of Political Texts Goran Glavaš and Federico Nanni and Simone Paolo Ponzetto Data and Web Science Group University of Mannheim B6, 26, DE-68159 Mannheim, Germany {goran,
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Highlighting and Annotation Tips Foundation Lesson
 English Highlighting and Annotation Tips Foundation Lesson About this Lesson Annotating a text can be a permanent record of the reader s intellectual conversation with a text. Annotation can help a reader
English Highlighting and Annotation Tips Foundation Lesson About this Lesson Annotating a text can be a permanent record of the reader s intellectual conversation with a text. Annotation can help a reader