Effects of Using Simple Semantic Similarity on Textual Entailment Recognition
|
|
|
- Horace Gaines
- 5 years ago
- Views:
Transcription
1 Effects of Using Simple Semantic Similarity on Textual Entailment Recognition TEAM ID:u_tokyo Ken-ichi Yokote, Shohei Tanaka and Mitsuru Ishizuka Department of Information and Communication Eng. School of Information Science and Technology The University of Tokyo {yokote, tanaka, Abstract We applied various WordNet based similarity measures to the RTE (Recognizing Textual Entailment) task in order to compare the effects of them on Textual Entailment Recognition. Although the improvements over a baseline system are not big, many of them show positive effects. 1. Introduction In RTE (Recognizing Textual Entailment) tasks, it becomes effective to consider semantic similarities between given sentences -- T(precedent text) and H(hypothesis)--, while word-level matching is mainly employed in many present systems. However, the definition of semantic similarity is ambiguous and it is unclear what is the best way to measure the similarity for textual entailment. Thus, in our research, we tried to apply various WordNet based similarity measures to the RTE task in order to compare the effects of them on Textual Entailment Recognition. We used WordNet::Similarity [WordNet similarity] which is a freely available software package that makes it possible to measure the semantic similarity and relatedness between a pair of concepts (or synsets). 2. Our RTE System The following figure shows the overview of our RTE system. This is roughly divided into three stages.
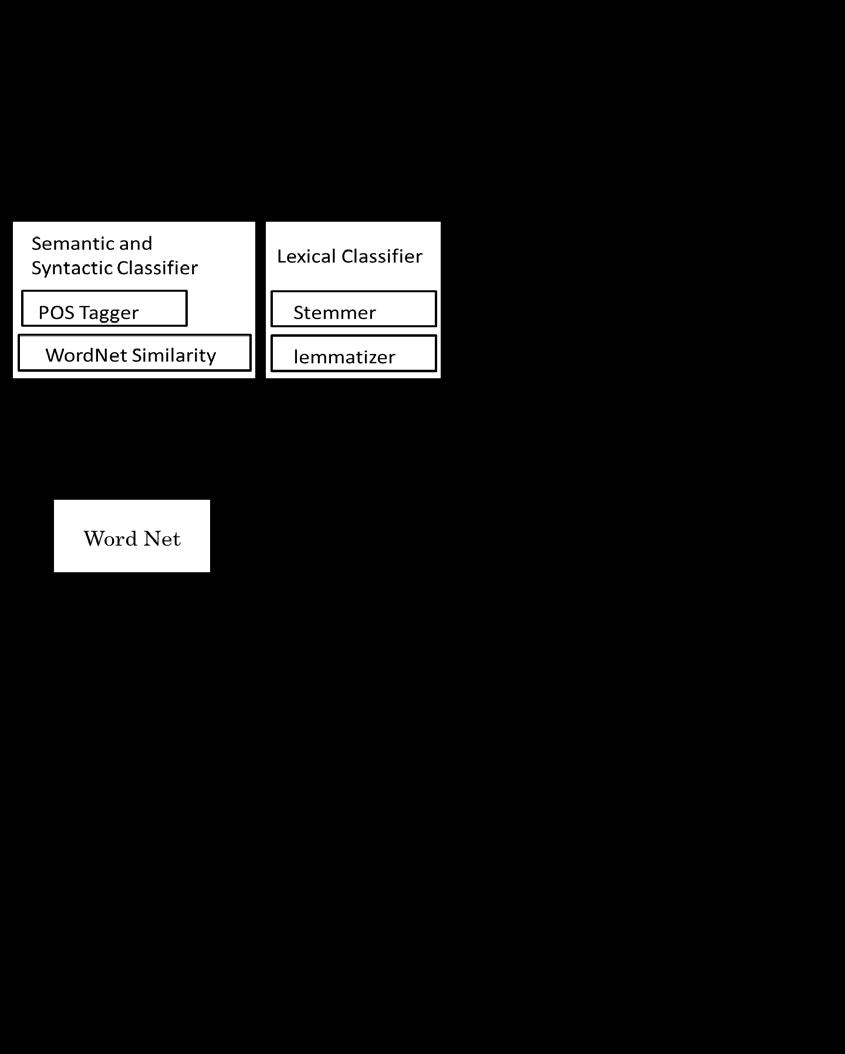
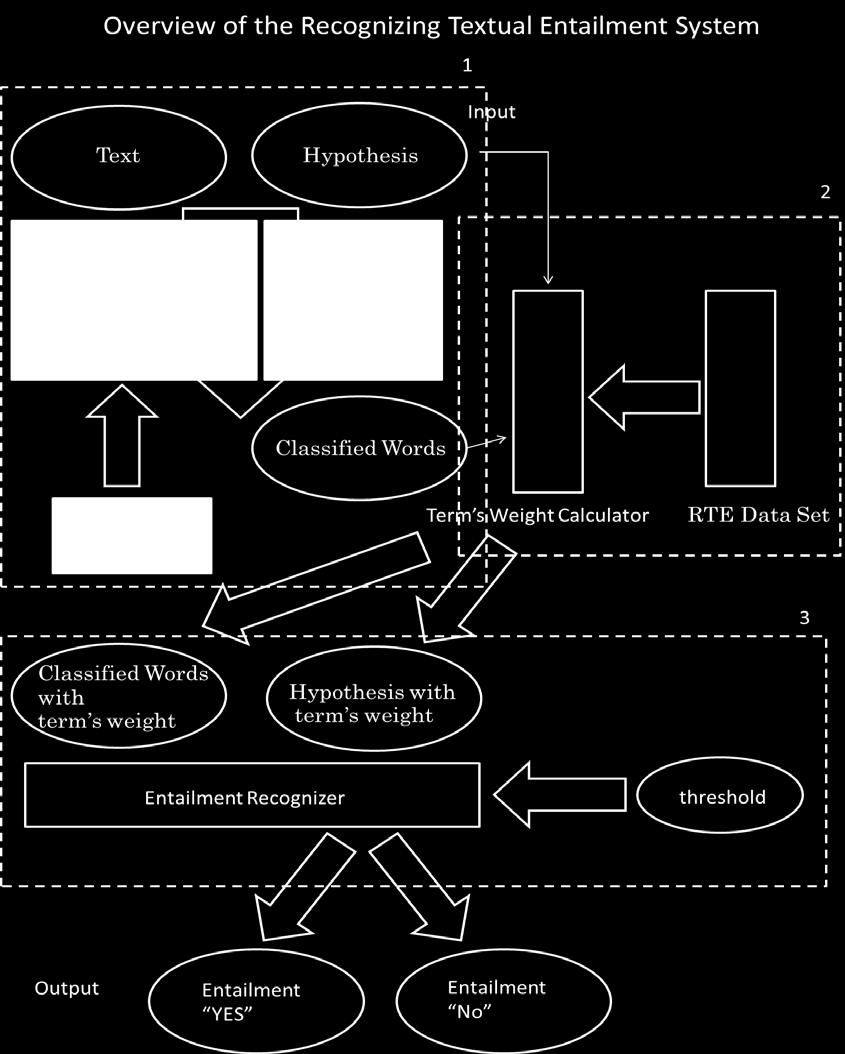
2
3 2.1 Stage 1 -- Classifying terms in H The system classifies terms in H into two groups, ones which are closely related to T, and the other. (The former are called classified words in the figure.) We employed two criteria in this classification. One is Lexical Classifier, which is based on lexical coincidence. Another one is Semantic and Syntactic Classifier, which is based on POS (part-of-speech) coincidence and Semantic Score. Here, the Semantic Score of h (h H) is defined as: score( h ) = Max { WordNet - Similarity ( h, t) s.t. t T } 2.2 Stage 2 -- Calculating the term s weights After the term classification in Stage 1, the system calculates the term s weight for all terms in H (including the classified words) as follows: T ( t ) = log ( T is amount of sentences in the Topic) textfreq( t) + 1 w 2 This is almost equivalent to IDF (Inverse Document Frequency). 2.3 Stage 3 -- Judging textual entailment First in this stage, the system constructs feature vectors of H and the set of the classified words, where each feature component corresponds to each word. Then, Entailment Recognizer judges whether entailment is YES or NO by comparing a threshold with the cosine similarity between H and the classified words. (The result of this similarity can be approximated by the degree of the overlaps of H and the classified words.) 3. Experimental Results 3.1 Baseline system As a baseline system, we used only lexical classifier in the stage1. For the development data set, it brought the best result shown below when the threshold was 0.7 in the experiments. DEVELOPMENT-SET Recall Precision 61.92
4 F-measure (macro) 50.6 (threshold = 0.7) Using this threshold value, experimental results for the test data set were as follows:. TEST-SET Recall Precision F-measure (macro) (threshold = 0.7) 3.2 Applying WordNet Similarity Functions We applied various WordNet similarity functions [WordNet similarity] to the classifier, and obtained their performance for the development data set as:. DEVELOPMENT-SET F-measure (macro) Path Similarity 51.0 Res (Resnik) Similarity 50.1 Wup (Wu-Palmer) Similarity 50.8 Lin Similarity 51.2 Lch (Leacock-Chodorow) Similarity 51.2 Jcn (Jiang-Conrath) Similarity 51.7 where the threshold in each case was chosen to attain the best result. Applying the same threshold in each case, we obtained the experimental results for the test data set. Below shows only top two cases. TEST-SET F-measure (macro) using Jcn (Jiang-Conrath) Similarity using Lch (Leacock-Chodorow) Similarity If we multiply these two similarity measures to generate a new measure, a bit better result has been obtained as: using Jcn and Lch Similarities where the threshold was also determined by multiplying two thresholds of Jcn and Lcn cases.
5 4. Discussion and Conclusion The experimental results to date show that Jcn (Jiang-Conrath) Similarity in the WordNet similarity functions is the most effective to RTE-7 task. There are rooms for further improvements by applying several WordNet similarity functions simultaneously. Also, we are interested in applying more comprehensive measures as the semantic similarity. Acknowledgments We are grateful to Kai Ishikawa, Masaaki Tsuchida and Toshi-ichi Fukushima (NEC Corp.) for their advice and help. References [WordNet similarity]
Vocabulary Usage and Intelligibility in Learner Language
 Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Robust Sense-Based Sentiment Classification
 Robust Sense-Based Sentiment Classification Balamurali A R 1 Aditya Joshi 2 Pushpak Bhattacharyya 2 1 IITB-Monash Research Academy, IIT Bombay 2 Dept. of Computer Science and Engineering, IIT Bombay Mumbai,
Robust Sense-Based Sentiment Classification Balamurali A R 1 Aditya Joshi 2 Pushpak Bhattacharyya 2 1 IITB-Monash Research Academy, IIT Bombay 2 Dept. of Computer Science and Engineering, IIT Bombay Mumbai,
A Semantic Similarity Measure Based on Lexico-Syntactic Patterns
 A Semantic Similarity Measure Based on Lexico-Syntactic Patterns Alexander Panchenko, Olga Morozova and Hubert Naets Center for Natural Language Processing (CENTAL) Université catholique de Louvain Belgium
A Semantic Similarity Measure Based on Lexico-Syntactic Patterns Alexander Panchenko, Olga Morozova and Hubert Naets Center for Natural Language Processing (CENTAL) Université catholique de Louvain Belgium
A Comparative Evaluation of Word Sense Disambiguation Algorithms for German
 A Comparative Evaluation of Word Sense Disambiguation Algorithms for German Verena Henrich, Erhard Hinrichs University of Tübingen, Department of Linguistics Wilhelmstr. 19, 72074 Tübingen, Germany {verena.henrich,erhard.hinrichs}@uni-tuebingen.de
A Comparative Evaluation of Word Sense Disambiguation Algorithms for German Verena Henrich, Erhard Hinrichs University of Tübingen, Department of Linguistics Wilhelmstr. 19, 72074 Tübingen, Germany {verena.henrich,erhard.hinrichs}@uni-tuebingen.de
Word Sense Disambiguation
 Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization
 LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Semantic Evidence for Automatic Identification of Cognates
 Semantic Evidence for Automatic Identification of Cognates Andrea Mulloni CLG, University of Wolverhampton Stafford Street Wolverhampton WV SB, United Kingdom andrea@wlv.ac.uk Viktor Pekar CLG, University
Semantic Evidence for Automatic Identification of Cognates Andrea Mulloni CLG, University of Wolverhampton Stafford Street Wolverhampton WV SB, United Kingdom andrea@wlv.ac.uk Viktor Pekar CLG, University
Lexical Similarity based on Quantity of Information Exchanged - Synonym Extraction
 Intl. Conf. RIVF 04 February 2-5, Hanoi, Vietnam Lexical Similarity based on Quantity of Information Exchanged - Synonym Extraction Ngoc-Diep Ho, Fairon Cédrick Abstract There are a lot of approaches for
Intl. Conf. RIVF 04 February 2-5, Hanoi, Vietnam Lexical Similarity based on Quantity of Information Exchanged - Synonym Extraction Ngoc-Diep Ho, Fairon Cédrick Abstract There are a lot of approaches for
A Domain Ontology Development Environment Using a MRD and Text Corpus
 A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
Combining a Chinese Thesaurus with a Chinese Dictionary
 Combining a Chinese Thesaurus with a Chinese Dictionary Ji Donghong Kent Ridge Digital Labs 21 Heng Mui Keng Terrace Singapore, 119613 dhji @krdl.org.sg Gong Junping Department of Computer Science Ohio
Combining a Chinese Thesaurus with a Chinese Dictionary Ji Donghong Kent Ridge Digital Labs 21 Heng Mui Keng Terrace Singapore, 119613 dhji @krdl.org.sg Gong Junping Department of Computer Science Ohio
The Role of String Similarity Metrics in Ontology Alignment
 The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
A Graph Based Authorship Identification Approach
 A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Matching Similarity for Keyword-Based Clustering
 Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Automatic Extraction of Semantic Relations by Using Web Statistical Information
 Automatic Extraction of Semantic Relations by Using Web Statistical Information Valeria Borzì, Simone Faro,, Arianna Pavone Dipartimento di Matematica e Informatica, Università di Catania Viale Andrea
Automatic Extraction of Semantic Relations by Using Web Statistical Information Valeria Borzì, Simone Faro,, Arianna Pavone Dipartimento di Matematica e Informatica, Università di Catania Viale Andrea
Assessing Entailer with a Corpus of Natural Language From an Intelligent Tutoring System
 Assessing Entailer with a Corpus of Natural Language From an Intelligent Tutoring System Philip M. McCarthy, Vasile Rus, Scott A. Crossley, Sarah C. Bigham, Arthur C. Graesser, & Danielle S. McNamara Institute
Assessing Entailer with a Corpus of Natural Language From an Intelligent Tutoring System Philip M. McCarthy, Vasile Rus, Scott A. Crossley, Sarah C. Bigham, Arthur C. Graesser, & Danielle S. McNamara Institute
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Information-theoretic evaluation of predicted ontological annotations
 BIOINFORMATICS Vol. 29 ISMB/ECCB 2013, pages i53 i61 doi:10.1093/bioinformatics/btt228 Information-theoretic evaluation of predicted ontological annotations Wyatt T. Clark and Predrag Radivojac* Department
BIOINFORMATICS Vol. 29 ISMB/ECCB 2013, pages i53 i61 doi:10.1093/bioinformatics/btt228 Information-theoretic evaluation of predicted ontological annotations Wyatt T. Clark and Predrag Radivojac* Department
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Let s think about how to multiply and divide fractions by fractions!
 Let s think about how to multiply and divide fractions by fractions! June 25, 2007 (Monday) Takehaya Attached Elementary School, Tokyo Gakugei University Grade 6, Class # 1 (21 boys, 20 girls) Instructor:
Let s think about how to multiply and divide fractions by fractions! June 25, 2007 (Monday) Takehaya Attached Elementary School, Tokyo Gakugei University Grade 6, Class # 1 (21 boys, 20 girls) Instructor:
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition
 Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition Roy Bar-Haim,Ido Dagan, Iddo Greental, Idan Szpektor and Moshe Friedman Computer Science Department, Bar-Ilan University,
Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition Roy Bar-Haim,Ido Dagan, Iddo Greental, Idan Szpektor and Moshe Friedman Computer Science Department, Bar-Ilan University,
Integrating Semantic Knowledge into Text Similarity and Information Retrieval
 Integrating Semantic Knowledge into Text Similarity and Information Retrieval Christof Müller, Iryna Gurevych Max Mühlhäuser Ubiquitous Knowledge Processing Lab Telecooperation Darmstadt University of
Integrating Semantic Knowledge into Text Similarity and Information Retrieval Christof Müller, Iryna Gurevych Max Mühlhäuser Ubiquitous Knowledge Processing Lab Telecooperation Darmstadt University of
A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF GRAPH DATA
 International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Handling Sparsity for Verb Noun MWE Token Classification
 Handling Sparsity for Verb Noun MWE Token Classification Mona T. Diab Center for Computational Learning Systems Columbia University mdiab@ccls.columbia.edu Madhav Krishna Computer Science Department Columbia
Handling Sparsity for Verb Noun MWE Token Classification Mona T. Diab Center for Computational Learning Systems Columbia University mdiab@ccls.columbia.edu Madhav Krishna Computer Science Department Columbia
Learning Semantically Coherent Rules
 Learning Semantically Coherent Rules Alexander Gabriel 1, Heiko Paulheim 2, and Frederik Janssen 3 1 agabriel@mayanna.org Technische Universität Darmstadt, Germany 2 heiko@informatik.uni-mannheim.de Research
Learning Semantically Coherent Rules Alexander Gabriel 1, Heiko Paulheim 2, and Frederik Janssen 3 1 agabriel@mayanna.org Technische Universität Darmstadt, Germany 2 heiko@informatik.uni-mannheim.de Research
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
The Ups and Downs of Preposition Error Detection in ESL Writing
 The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Distributed Divergent Creativity: Computational Creative Agents at Web Scale
 Distributed Divergent Creativity: Computational Creative Agents at Web Scale Tony Veale, Guofu Li School of Computer Science and Informatics, University College Dublin Contact author: Tony.Veale@UCD.ie
Distributed Divergent Creativity: Computational Creative Agents at Web Scale Tony Veale, Guofu Li School of Computer Science and Informatics, University College Dublin Contact author: Tony.Veale@UCD.ie
HLTCOE at TREC 2013: Temporal Summarization
 HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
Linking the Ohio State Assessments to NWEA MAP Growth Tests *
 Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
The MEANING Multilingual Central Repository
 The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing
 Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing Jan C. Scholtes Tim H.W. van Cann University of Maastricht, Department of Knowledge Engineering.
Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing Jan C. Scholtes Tim H.W. van Cann University of Maastricht, Department of Knowledge Engineering.
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2
 Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Graph Alignment for Semi-Supervised Semantic Role Labeling
 Graph Alignment for Semi-Supervised Semantic Role Labeling Hagen Fürstenau Dept. of Computational Linguistics Saarland University Saarbrücken, Germany hagenf@coli.uni-saarland.de Mirella Lapata School
Graph Alignment for Semi-Supervised Semantic Role Labeling Hagen Fürstenau Dept. of Computational Linguistics Saarland University Saarbrücken, Germany hagenf@coli.uni-saarland.de Mirella Lapata School
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Mining meaning from Wikipedia
 Mining meaning from Wikipedia OLENA MEDELYAN, DAVID MILNE, CATHERINE LEGG and IAN H. WITTEN University of Waikato, New Zealand Wikipedia is a goldmine of information; not just for its many readers, but
Mining meaning from Wikipedia OLENA MEDELYAN, DAVID MILNE, CATHERINE LEGG and IAN H. WITTEN University of Waikato, New Zealand Wikipedia is a goldmine of information; not just for its many readers, but
Analysis: Evaluation: Knowledge: Comprehension: Synthesis: Application:
 In 1956, Benjamin Bloom headed a group of educational psychologists who developed a classification of levels of intellectual behavior important in learning. Bloom found that over 95 % of the test questions
In 1956, Benjamin Bloom headed a group of educational psychologists who developed a classification of levels of intellectual behavior important in learning. Bloom found that over 95 % of the test questions
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Part III: Semantics. Notes on Natural Language Processing. Chia-Ping Chen
 Part III: Semantics Notes on Natural Language Processing Chia-Ping Chen Department of Computer Science and Engineering National Sun Yat-Sen University Kaohsiung, Taiwan ROC Part III: Semantics p. 1 Introduction
Part III: Semantics Notes on Natural Language Processing Chia-Ping Chen Department of Computer Science and Engineering National Sun Yat-Sen University Kaohsiung, Taiwan ROC Part III: Semantics p. 1 Introduction
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Semantic Inference at the Lexical-Syntactic Level
 Semantic Inference at the Lexical-Syntactic Level Roy Bar-Haim Department of Computer Science Ph.D. Thesis Submitted to the Senate of Bar Ilan University Ramat Gan, Israel January 2010 This work was carried
Semantic Inference at the Lexical-Syntactic Level Roy Bar-Haim Department of Computer Science Ph.D. Thesis Submitted to the Senate of Bar Ilan University Ramat Gan, Israel January 2010 This work was carried
Extended Similarity Test for the Evaluation of Semantic Similarity Functions
 Extended Similarity Test for the Evaluation of Semantic Similarity Functions Maciej Piasecki 1, Stanisław Szpakowicz 2,3, Bartosz Broda 1 1 Institute of Applied Informatics, Wrocław University of Technology,
Extended Similarity Test for the Evaluation of Semantic Similarity Functions Maciej Piasecki 1, Stanisław Szpakowicz 2,3, Bartosz Broda 1 1 Institute of Applied Informatics, Wrocław University of Technology,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features
 collocations by integrating features") Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features Sriram Venkatapathy Language Technologies Research Centre, International Institute of Information Technology
Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features Sriram Venkatapathy Language Technologies Research Centre, International Institute of Information Technology
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
2 Mitsuru Ishizuka x1 Keywords Automatic Indexing, PAI, Asserted Keyword, Spreading Activation, Priming Eect Introduction With the increasing number o
 PAI: Automatic Indexing for Extracting Asserted Keywords from a Document 1 PAI: Automatic Indexing for Extracting Asserted Keywords from a Document Naohiro Matsumura PRESTO, Japan Science and Technology
PAI: Automatic Indexing for Extracting Asserted Keywords from a Document 1 PAI: Automatic Indexing for Extracting Asserted Keywords from a Document Naohiro Matsumura PRESTO, Japan Science and Technology
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES SCHOOL OF INFORMATION SCIENCES
 ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES SCHOOL OF INFORMATION SCIENCES Afan Oromo news text summarizer BY GIRMA DEBELE DINEGDE A THESIS SUBMITED TO THE SCHOOL OF GRADUTE STUDIES OF ADDIS ABABA
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES SCHOOL OF INFORMATION SCIENCES Afan Oromo news text summarizer BY GIRMA DEBELE DINEGDE A THESIS SUBMITED TO THE SCHOOL OF GRADUTE STUDIES OF ADDIS ABABA
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Extracting Lexical Reference Rules from Wikipedia
 Extracting Lexical Reference Rules from Wikipedia Eyal Shnarch Computer Science Department Bar-Ilan University Ramat-Gan 52900, Israel shey@cs.biu.ac.il Libby Barak Dept. of Computer Science University
Extracting Lexical Reference Rules from Wikipedia Eyal Shnarch Computer Science Department Bar-Ilan University Ramat-Gan 52900, Israel shey@cs.biu.ac.il Libby Barak Dept. of Computer Science University
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
The Structure of Multiple Complements to V
 The Structure of Multiple Complements to Mitsuaki YONEYAMA 1. Introduction I have recently been concerned with the syntactic and semantic behavior of two s in English. In this paper, I will examine the
The Structure of Multiple Complements to Mitsuaki YONEYAMA 1. Introduction I have recently been concerned with the syntactic and semantic behavior of two s in English. In this paper, I will examine the
Can Human Verb Associations help identify Salient Features for Semantic Verb Classification?
 Can Human Verb Associations help identify Salient Features for Semantic Verb Classification? Sabine Schulte im Walde Institut für Maschinelle Sprachverarbeitung Universität Stuttgart Seminar für Sprachwissenschaft,
Can Human Verb Associations help identify Salient Features for Semantic Verb Classification? Sabine Schulte im Walde Institut für Maschinelle Sprachverarbeitung Universität Stuttgart Seminar für Sprachwissenschaft,
A Statistical Approach to the Semantics of Verb-Particles
 A Statistical Approach to the Semantics of Verb-Particles Colin Bannard School of Informatics University of Edinburgh 2 Buccleuch Place Edinburgh EH8 9LW, UK c.j.bannard@ed.ac.uk Timothy Baldwin CSLI Stanford
A Statistical Approach to the Semantics of Verb-Particles Colin Bannard School of Informatics University of Edinburgh 2 Buccleuch Place Edinburgh EH8 9LW, UK c.j.bannard@ed.ac.uk Timothy Baldwin CSLI Stanford
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Segmentation of Multi-Sentence Questions: Towards Effective Question Retrieval in cqa Services
 Segmentation of Multi-Sentence s: Towards Effective Retrieval in cqa Services Kai Wang, Zhao-Yan Ming, Xia Hu, Tat-Seng Chua Department of Computer Science School of Computing National University of Singapore
Segmentation of Multi-Sentence s: Towards Effective Retrieval in cqa Services Kai Wang, Zhao-Yan Ming, Xia Hu, Tat-Seng Chua Department of Computer Science School of Computing National University of Singapore
A heuristic framework for pivot-based bilingual dictionary induction
 2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
Natural Language Arguments: A Combined Approach
 Natural Language Arguments: A Combined Approach Elena Cabrio 1 and Serena Villata 23 Abstract. With the growing use of the Social Web, an increasing number of applications for exchanging opinions with
Natural Language Arguments: A Combined Approach Elena Cabrio 1 and Serena Villata 23 Abstract. With the growing use of the Social Web, an increasing number of applications for exchanging opinions with
Cross-lingual Text Fragment Alignment using Divergence from Randomness
 Cross-lingual Text Fragment Alignment using Divergence from Randomness Sirvan Yahyaei, Marco Bonzanini, and Thomas Roelleke Queen Mary, University of London Mile End Road, E1 4NS London, UK {sirvan,marcob,thor}@eecs.qmul.ac.uk
Cross-lingual Text Fragment Alignment using Divergence from Randomness Sirvan Yahyaei, Marco Bonzanini, and Thomas Roelleke Queen Mary, University of London Mile End Road, E1 4NS London, UK {sirvan,marcob,thor}@eecs.qmul.ac.uk
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
Words come in categories
 Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
Compositional Semantics
 Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Bug triage in open source systems: a review
 Int. J. Collaborative Enterprise, Vol. 4, No. 4, 2014 299 Bug triage in open source systems: a review V. Akila* and G. Zayaraz Department of Computer Science and Engineering, Pondicherry Engineering College,
Int. J. Collaborative Enterprise, Vol. 4, No. 4, 2014 299 Bug triage in open source systems: a review V. Akila* and G. Zayaraz Department of Computer Science and Engineering, Pondicherry Engineering College,
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Beyond the contextual: the importance of theoretical knowledge in vocational qualifications & the implications for work
 Griffith Research Online https://research-repository.griffith.edu.au Beyond the contextual: the importance of theoretical knowledge in vocational qualifications & the implications for work Author Wheelahan,
Griffith Research Online https://research-repository.griffith.edu.au Beyond the contextual: the importance of theoretical knowledge in vocational qualifications & the implications for work Author Wheelahan,
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting
 LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
What is a Mental Model?
 Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
A Grammar for Battle Management Language
 Bastian Haarmann 1 Dr. Ulrich Schade 1 Dr. Michael R. Hieb 2 1 Fraunhofer Institute for Communication, Information Processing and Ergonomics 2 George Mason University bastian.haarmann@fkie.fraunhofer.de
Bastian Haarmann 1 Dr. Ulrich Schade 1 Dr. Michael R. Hieb 2 1 Fraunhofer Institute for Communication, Information Processing and Ergonomics 2 George Mason University bastian.haarmann@fkie.fraunhofer.de
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
Intermediate Academic Writing
 Intermediate Academic Writing COURSE DESIGNATOR: MONT 3xxx NUMBER OF CREDITS: 3 LANGUAGE OF INSTRUCTION: French CONTACT HOURS: 45 COURSE DESCRIPTION This class is designed to introduce students to the
Intermediate Academic Writing COURSE DESIGNATOR: MONT 3xxx NUMBER OF CREDITS: 3 LANGUAGE OF INSTRUCTION: French CONTACT HOURS: 45 COURSE DESCRIPTION This class is designed to introduce students to the