Introduction to Computational Linguistics
|
|
|
- Myles Simmons
- 5 years ago
- Views:
Transcription
1 Introduction to Computational Linguistics Olga Zamaraeva (2018) Based on Bender (prev. years) and Levow (2016) University of Washington May 8, / 54
2 Projects Please remember that Error Analysis goes beyond just running the package and obtaining numbers Make sure to discuss your EA strategy for Milestone 3 Assignment 4 If you already did, expand Can start after today s lecture Assignment 5 Midterms: Can start after next Tuesday DO NOT DELAY Training and Test data Precision and Recall 2 / 54
3 Why statistical parsing? s Estimating rule probabilities Ways to improve 3 / 54
4 Why statistical parsing? Your turn 4 / 54
5 Why statistical parsing? Parsing = making explicit structure that is inherent (implicit) in natural language strings Most application scenarios that use parser output want just one parse Have to choose among all the possible analyses (disambiguation) CKY represents the ambiguities efficiently but does not solve them Most application scenarios need robust parsers Need some output for every input, even if its not grammatical 5 / 54
6 Probabilistic Context Free Grammars N: a set of non-terminal symbols : a set of terminal symbols (disjoint from N) R: a set of rules, of the form A β [p] A: non-terminal β: string of symbols from or N p: probability of β given A S: a designated start symbol 6 / 54
7 How does this differ from CFG? How do we use it to calculate the probability of a parse? The probability of a sentence? What assumptions does that require? 7 / 54
8 How does this differ from CFG? added probability to each rule How do we use it to calculate the probability of a parse? multiply the probabilities of used rules The probability of a sentence? sum of probabilities of all trees What assumptions does that require? expansion of a node does not depend on the context 8 / 54
9 Augment each production with probability that LHS will be expanded as RHS P(A B) or P(A B A), P(RHS LHS) Sum over all possible expansions is 1 β P(A β) = 1 A is consistent if sum of probabilities of all sentences in language is 1. Recursive rules can yield inconsistent grammars We look at consistent grammars in this class 9 / 54
10 Example: probabilities (Assume some small CFG grammar of the kind we saw before.) I have a cat. Do you have a cat? I have a dog. What is P(Det a)? What is P(N cat)? What is P(S NP VP)? 10 / 54

11 Example: fragment How would a real-life trained grammar differ from this one? 11 / 54
12 Disambiguation A assigns probability to each parse tree T for input S Probability of T: product of all rules to derive T (i is step in derivation) Why? 12 / 54
13 Disambiguation A assigns probability to each parse tree T for input S Probability of T: product of all rules to derive T Why? Because P(S T) = 1 13 / 54
14 Parsing problem for Select T such that: ˆT(S) = argmaxts.t.s=yield(t) P(T) String of S is yield of parse tree over S Select tree that maximizes probability of parse Extend existing algorithms, e.g. CKY Most modern parsers based on CKY 14 / 54
15 Argmax Recall: the argmax function over a parameter: returns the value for the parameter at which the value of the function is maximum E.g. f(x) is maximum when x=0.5 (suppose f(0.5) = 1) max(f(x)) = 1 argmax x (f(x)) = / 54
16 Parsing problem for ˆT(S) = argmaxts.t.s=yield(t) P(T S) P(T,S) ˆT(S) = argmaxts.t.s=yield(t) P(S) But P(S) is constant for each tree Why? ˆT(S) = argmaxts.t.s=yield(t) P(T, S) P(T, S) = P(T) So, ˆT(S) = argmaxts.t.s=yield(t) P(T) 16 / 54
17 Parsing problem for ˆT(S) = argmaxts.t.s=yield(t) P(T S) P(T,S) ˆT(S) = argmaxts.t.s=yield(t) P(S) But P(S) is constant for each tree Because it is the same sentence! (NB: it is not 1 but it still is the same number for all trees, so doesn t matter in finding the max) ˆT(S) = argmaxts.t.s=yield(t) P(T, S) P(T, S) = P(T) So, ˆT(S) = argmaxts.t.s=yield(t) P(T) 17 / 54
18 Disambiguation 18 / 54
19 Assigning probability to a string can tell us what the probability of a sentence is (joint with structure) What s this useful for? 19 / 54
20 Assigning probability to a string can tell us what the probability of a sentence is (joint with structure) What s this useful for? Language modeling Where have we seen language modeling? 20 / 54
21 Assigning probability to a string can tell us what is the probability of a sentence What s this useful for? Language modeling Where have we seen language modeling? N-grams are models which account for more context than N-grams What are some applications? 21 / 54
22 Assigning probability to a string can tell us what is the probability of a sentence What s this useful for? Language modeling Where have we seen language modeling? N-grams are models which account for more context than N-grams What are some applications? MT, ASR, Spelling correction, Grammar correction / 54
23 How to estimate rule probabilities? Get a Treebank Gather all instances of each non-terminal For each expansion of the non-terminal (= rule), count how many times it occurs P(α β α = C(α β) C(α) ) 23 / 54
24 (Ney, 1991): in each cell, store just the most probable edge for each non-terminal (Btw, CKY does not appear to have a canonical citation?.. Several papers, from late 50s into 70s) 24 / 54
25 Like regular CKY Assume grammar in Chomsky Normal Form (CNF) Productions: A B C or A w Represent input with indices b/t words E.g., 0 Book 1 that 2 flight 3 through 4 Houston 5 For input string length n and non-terminals V Cell [i,j,a] in (n + 1)x(n + 1)xV matrix contains the probability that constituent A spans [i,j] V is a 3rd dimension, for each nonterminal V stores the probabilities 25 / 54
26 Note: this is pseudocode generally means assignment (e.g. x = 2) downto 0 means the number is decreasing with each iteration until it is 0 26 / 54
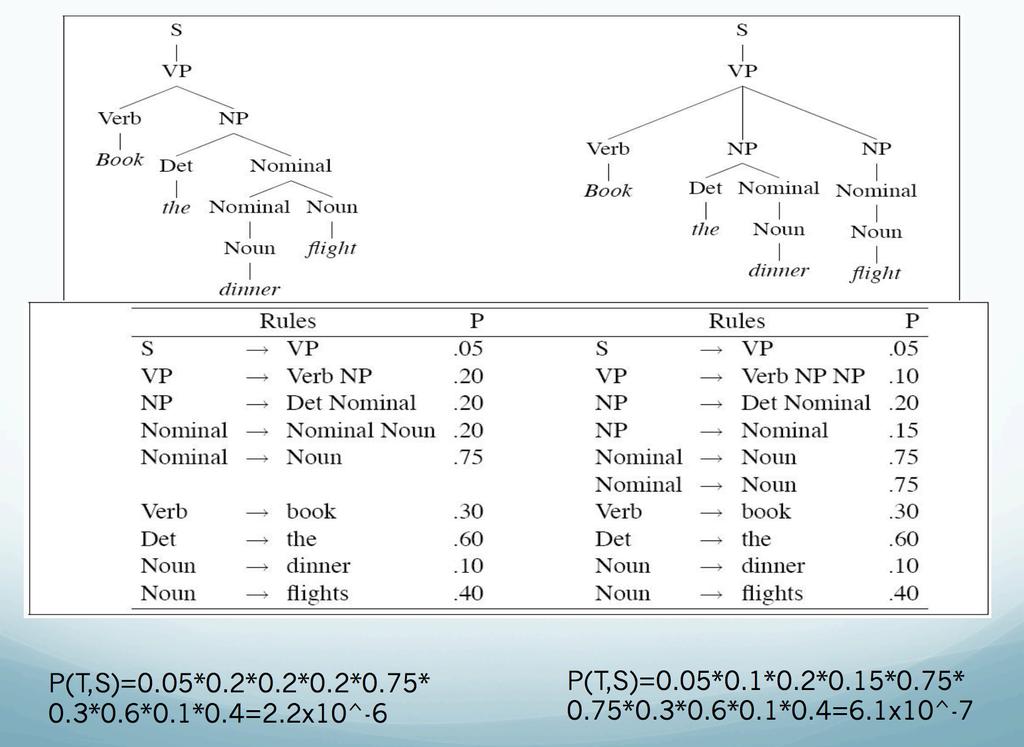
27 PCKY grammar segment S NP VP [0.80] NP Det N [0.30] VP V NP [0.20] V includes [0.05] Det the [0.40] Det a [0.40] N flight [0.02] N meal [0.05] 27 / 54

28 This flight includes a meal 28 / 54
29 Problems with Independence assumption is problematic What does independence assumption mean? What is the evidence that it s wrong? Not sensitive to lexical dependencies What does that mean? 29 / 54
30 Problems with Independence assumption is problematic What does independence assumption mean? NP Pronoun vs NP Noun The choice will be made independently of other things going on in the tree What is the evidence that it s wrong? NP Pronoun is much more likely to be in the subject position Not sensitive to lexical dependencies What does that mean? Verb/preposition subcategorization Coordination ambiguity 30 / 54
31 Problems with Switchboard corpus (Francis et al., 1999): Pronoun Non-Pronoun Subject 91% 9% Object 34% 66% But estimated probabilities: NP DT NN [0.28] NP PRP [0.25] 31 / 54
32 Problems with 32 / 54
33 Problems with 33 / 54
34 Problems with NP NP PP has fairly high probability in English (aka WSJ) So a trained on it will always prefer this kind of attachment Remember how pervasive this issue was shown to be in Kummerfeld et al. 34 / 54
35 Lexical dependenices The workers dumped the sacks into a bin How to capture the fact that there is grater affinity between dumped and into than between sacks and into? 35 / 54
36 Coordination Why would these parses have exactly the same probabilities? 36 / 54
37 Ways to improve Split the non-terminals Rename each non-terminal based on its parent (NP-S vs. NP-VP) Hand-written rules to split pre-terminal categories Automatically search for optimal splits through split and merge algorithm Lexicalized s: add identity of lexical head to each node label Data sparsity problem smoothing again 37 / 54
38 Parent annotation Can distinguish Subject from Object now (how?) 38 / 54
39 Parent annotation Advantages: Captures structural dependency in grammars Disadvantages? 39 / 54
40 Parent annotation Did parent annotation help with the left tree? What did we do in the right tree? 40 / 54
41 Parent annotation Advantages: Captures structural dependency in grammars Disadvantages? Increases number of rules in grammar Decreases amount of data available for training per rule 41 / 54
42 Lexicalized CFG Lexicalized rules: Best known parsers: Collins, Charniak parsers Each non-terminal annotated with its lexical head E.g. verb with verb phrase, noun with noun phrase Each rule must identify RHS element as head Heads propagate up tree Conceptually like adding 1 rule per head value VP(dumped) VBD(dumped)NP(sacks)PP(into) VP(dumped) VBD(dumped)NP(cats)PP(into) In practice, data would be very sparse to train something like this 42 / 54
43 Lexicalized CFG 43 / 54
44 Disambiguation example 44 / 54

45 Disambiguation example 45 / 54
46 Improving s: Tradeoffs Tensions: Note: The running time of the parser is not just O(n 3 ) It is actually O(n 3 G ) where G is the size of the grammar Increasing accuracy increases the grammar size Lexicalized and specialized grammars can be huge This increases processing times And increases training data requirements (why?) How can we balance? 46 / 54
47 Improving s: Tradeoffs Tensions: Note: The running time of the parser is not just O(n 3 ) It is actually O(n 3 G ) where G is the size of the grammar Increasing accuracy increases the grammar size Lexicalized and specialized grammars can be huge This increases processing times And increases training data requirements (why?) sparsity (remember why we couldn t compute joint probabilities directly for N-gram models?) How can we balance? 47 / 54
48 Solutions Beam Thresholding (inspired by Beam Search algorithm) Main idea: Keep only top k most probable partial parses Retain only k choices per cell Collins parser Make further independence assumptions 48 / 54
49 Solutions Beam Thresholding (inspired by Beam Search algorithm) Main idea: Keep only top k most probable partial parses Retain only k choices per cell Collins parser Make further independence assumptions Aren t we going in circles? related: is CFG a theory of human language? 49 / 54
50 Gold Standard Obtained from a Treebank What is the problem with this? 50 / 54
51 metric: Parseval 51 / 54

52 metric: Parseval 52 / 54
53 Example: Precision and Recall Gold standard: Hypothesis: (S (NP (A a) ) (VP (B b) (NP (C c)) (PP (D d)))) (S (NP (A a)) (VP (B b) (NP (C c) (PP (D d))))) G: S(0,4) NP(0,1) VP (1,4) NP (2,3) PP(3,4) H: S(0,4) NP(0,1) VP (1,4) NP (2,4) PP(3,4) LP: 4/5 LR: 4/5 F1: 4/5 53 / 54
54 Balancing efficiency with accuracy in : Fixing one problem often creates new problems don t seem to help us understand much about language Why do we need to implement parsers for that anyway? : Syntactic theory and then unification-based parsing 54 / 54
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
Basic Parsing with Context-Free Grammars. Some slides adapted from Julia Hirschberg and Dan Jurafsky 1
 Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Grammars & Parsing, Part 1:
 Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Accurate Unlexicalized Parsing for Modern Hebrew
 Accurate Unlexicalized Parsing for Modern Hebrew Reut Tsarfaty and Khalil Sima an Institute for Logic, Language and Computation, University of Amsterdam Plantage Muidergracht 24, 1018TV Amsterdam, The
Accurate Unlexicalized Parsing for Modern Hebrew Reut Tsarfaty and Khalil Sima an Institute for Logic, Language and Computation, University of Amsterdam Plantage Muidergracht 24, 1018TV Amsterdam, The
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures
 Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Informatics 2A: Language Complexity and the. Inf2A: Chomsky Hierarchy
 Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS
 Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
UNIVERSITY OF OSLO Department of Informatics. Dialog Act Recognition using Dependency Features. Master s thesis. Sindre Wetjen
 UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
RANKING AND UNRANKING LEFT SZILARD LANGUAGES. Erkki Mäkinen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TAMPERE REPORT A ER E P S I M S
 N S ER E P S I M TA S UN A I S I T VER RANKING AND UNRANKING LEFT SZILARD LANGUAGES Erkki Mäkinen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TAMPERE REPORT A-1997-2 UNIVERSITY OF TAMPERE DEPARTMENT OF
N S ER E P S I M TA S UN A I S I T VER RANKING AND UNRANKING LEFT SZILARD LANGUAGES Erkki Mäkinen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF TAMPERE REPORT A-1997-2 UNIVERSITY OF TAMPERE DEPARTMENT OF
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
An Efficient Implementation of a New POP Model
 An Efficient Implementation of a New POP Model Rens Bod ILLC, University of Amsterdam School of Computing, University of Leeds Nieuwe Achtergracht 166, NL-1018 WV Amsterdam rens@science.uva.n1 Abstract
An Efficient Implementation of a New POP Model Rens Bod ILLC, University of Amsterdam School of Computing, University of Leeds Nieuwe Achtergracht 166, NL-1018 WV Amsterdam rens@science.uva.n1 Abstract
Domain Adaptation for Parsing
 Domain Adaptation for Parsing Barbara Plank CLCG The work presented here was carried out under the auspices of the Center for Language and Cognition Groningen (CLCG) at the Faculty of Arts of the University
Domain Adaptation for Parsing Barbara Plank CLCG The work presented here was carried out under the auspices of the Center for Language and Cognition Groningen (CLCG) at the Faculty of Arts of the University
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Compositional Semantics
 Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Analysis of Probabilistic Parsing in NLP
 Analysis of Probabilistic Parsing in NLP Krishna Karoo, Dr.Girish Katkar Research Scholar, Department of Electronics & Computer Science, R.T.M. Nagpur University, Nagpur, India Head of Department, Department
Analysis of Probabilistic Parsing in NLP Krishna Karoo, Dr.Girish Katkar Research Scholar, Department of Electronics & Computer Science, R.T.M. Nagpur University, Nagpur, India Head of Department, Department
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
LTAG-spinal and the Treebank
 LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
Some Principles of Automated Natural Language Information Extraction
 Some Principles of Automated Natural Language Information Extraction Gregers Koch Department of Computer Science, Copenhagen University DIKU, Universitetsparken 1, DK-2100 Copenhagen, Denmark Abstract
Some Principles of Automated Natural Language Information Extraction Gregers Koch Department of Computer Science, Copenhagen University DIKU, Universitetsparken 1, DK-2100 Copenhagen, Denmark Abstract
The Interface between Phrasal and Functional Constraints
 The Interface between Phrasal and Functional Constraints John T. Maxwell III* Xerox Palo Alto Research Center Ronald M. Kaplan t Xerox Palo Alto Research Center Many modern grammatical formalisms divide
The Interface between Phrasal and Functional Constraints John T. Maxwell III* Xerox Palo Alto Research Center Ronald M. Kaplan t Xerox Palo Alto Research Center Many modern grammatical formalisms divide
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR
 COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR ROLAND HAUSSER Institut für Deutsche Philologie Ludwig-Maximilians Universität München München, West Germany 1. CHOICE OF A PRIMITIVE OPERATION The
COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR ROLAND HAUSSER Institut für Deutsche Philologie Ludwig-Maximilians Universität München München, West Germany 1. CHOICE OF A PRIMITIVE OPERATION The
Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]
![Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]](/thumbs/71/65954495.jpg "Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]") Towards a MWE-driven A* parsing with LTAGs [WG2,WG3] Jakub Waszczuk, Agata Savary To cite this version: Jakub Waszczuk, Agata Savary. Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]. PARSEME 6th general
Towards a MWE-driven A* parsing with LTAGs [WG2,WG3] Jakub Waszczuk, Agata Savary To cite this version: Jakub Waszczuk, Agata Savary. Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]. PARSEME 6th general
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
arxiv:cmp-lg/ v1 7 Jun 1997 Abstract
 Comparing a Linguistic and a Stochastic Tagger Christer Samuelsson Lucent Technologies Bell Laboratories 600 Mountain Ave, Room 2D-339 Murray Hill, NJ 07974, USA christer@research.bell-labs.com Atro Voutilainen
Comparing a Linguistic and a Stochastic Tagger Christer Samuelsson Lucent Technologies Bell Laboratories 600 Mountain Ave, Room 2D-339 Murray Hill, NJ 07974, USA christer@research.bell-labs.com Atro Voutilainen
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Three New Probabilistic Models. Jason M. Eisner. CIS Department, University of Pennsylvania. 200 S. 33rd St., Philadelphia, PA , USA
 Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
Training and evaluation of POS taggers on the French MULTITAG corpus
 Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Parsing with Treebank Grammars: Empirical Bounds, Theoretical Models, and the Structure of the Penn Treebank
 Parsing with Treebank Grammars: Empirical Bounds, Theoretical Models, and the Structure of the Penn Treebank Dan Klein and Christopher D. Manning Computer Science Department Stanford University Stanford,
Parsing with Treebank Grammars: Empirical Bounds, Theoretical Models, and the Structure of the Penn Treebank Dan Klein and Christopher D. Manning Computer Science Department Stanford University Stanford,
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Developing a TT-MCTAG for German with an RCG-based Parser
 Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
ENGBG1 ENGBL1 Campus Linguistics. Meeting 2. Chapter 7 (Morphology) and chapter 9 (Syntax) Pia Sundqvist
 and chapter 9 (Syntax) Pia Sundqvist") Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Introduction to HPSG. Introduction. Historical Overview. The HPSG architecture. Signature. Linguistic Objects. Descriptions.
 to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
1/20 idea. We ll spend an extra hour on 1/21. based on assigned readings. so you ll be ready to discuss them in class
 If we cancel class 1/20 idea We ll spend an extra hour on 1/21 I ll give you a brief writing problem for 1/21 based on assigned readings Jot down your thoughts based on your reading so you ll be ready
If we cancel class 1/20 idea We ll spend an extra hour on 1/21 I ll give you a brief writing problem for 1/21 based on assigned readings Jot down your thoughts based on your reading so you ll be ready
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly
 ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
Basic Syntax. Doug Arnold We review some basic grammatical ideas and terminology, and look at some common constructions in English.
 Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
"f TOPIC =T COMP COMP... OBJ
 TREATMENT OF LONG DISTANCE DEPENDENCIES IN LFG AND TAG: FUNCTIONAL UNCERTAINTY IN LFG IS A COROLLARY IN TAG" Aravind K. Joshi Dept. of Computer & Information Science University of Pennsylvania Philadelphia,
TREATMENT OF LONG DISTANCE DEPENDENCIES IN LFG AND TAG: FUNCTIONAL UNCERTAINTY IN LFG IS A COROLLARY IN TAG" Aravind K. Joshi Dept. of Computer & Information Science University of Pennsylvania Philadelphia,
Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing. Grzegorz Chrupa la
 Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing Grzegorz Chrupa la A dissertation submitted in fulfilment of the requirements for the award of Doctor of Philosophy (Ph.D.)
Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing Grzegorz Chrupa la A dissertation submitted in fulfilment of the requirements for the award of Doctor of Philosophy (Ph.D.)
The Ups and Downs of Preposition Error Detection in ESL Writing
 The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
A Domain Ontology Development Environment Using a MRD and Text Corpus
 A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
Derivational: Inflectional: In a fit of rage the soldiers attacked them both that week, but lost the fight.
 Final Exam (120 points) Click on the yellow balloons below to see the answers I. Short Answer (32pts) 1. (6) The sentence The kinder teachers made sure that the students comprehended the testable material
Final Exam (120 points) Click on the yellow balloons below to see the answers I. Short Answer (32pts) 1. (6) The sentence The kinder teachers made sure that the students comprehended the testable material
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
Chapter 4: Valence & Agreement CSLI Publications
 Chapter 4: Valence & Agreement Reminder: Where We Are Simple CFG doesn t allow us to cross-classify categories, e.g., verbs can be grouped by transitivity (deny vs. disappear) or by number (deny vs. denies).
Chapter 4: Valence & Agreement Reminder: Where We Are Simple CFG doesn t allow us to cross-classify categories, e.g., verbs can be grouped by transitivity (deny vs. disappear) or by number (deny vs. denies).
Hyperedge Replacement and Nonprojective Dependency Structures
 Hyperedge Replacement and Nonprojective Dependency Structures Daniel Bauer and Owen Rambow Columbia University New York, NY 10027, USA {bauer,rambow}@cs.columbia.edu Abstract Synchronous Hyperedge Replacement
Hyperedge Replacement and Nonprojective Dependency Structures Daniel Bauer and Owen Rambow Columbia University New York, NY 10027, USA {bauer,rambow}@cs.columbia.edu Abstract Synchronous Hyperedge Replacement
Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge
 Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
A Computational Evaluation of Case-Assignment Algorithms
 A Computational Evaluation of Case-Assignment Algorithms Miles Calabresi Advisors: Bob Frank and Jim Wood Submitted to the faculty of the Department of Linguistics in partial fulfillment of the requirements
A Computational Evaluation of Case-Assignment Algorithms Miles Calabresi Advisors: Bob Frank and Jim Wood Submitted to the faculty of the Department of Linguistics in partial fulfillment of the requirements
Inleiding Taalkunde. Docent: Paola Monachesi. Blok 4, 2001/ Syntax 2. 2 Phrases and constituent structure 2. 3 A minigrammar of Italian 3
 Inleiding Taalkunde Docent: Paola Monachesi Blok 4, 2001/2002 Contents 1 Syntax 2 2 Phrases and constituent structure 2 3 A minigrammar of Italian 3 4 Trees 3 5 Developing an Italian lexicon 4 6 S(emantic)-selection
Inleiding Taalkunde Docent: Paola Monachesi Blok 4, 2001/2002 Contents 1 Syntax 2 2 Phrases and constituent structure 2 3 A minigrammar of Italian 3 4 Trees 3 5 Developing an Italian lexicon 4 6 S(emantic)-selection
Using computational modeling in language acquisition research
 Chapter 8 Using computational modeling in language acquisition research Lisa Pearl 1. Introduction Language acquisition research is often concerned with questions of what, when, and how what children know,
Chapter 8 Using computational modeling in language acquisition research Lisa Pearl 1. Introduction Language acquisition research is often concerned with questions of what, when, and how what children know,
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Role of the Head in the Interpretation of English Deverbal Compounds
 The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The presence of interpretable but ungrammatical sentences corresponds to mismatches between interpretive and productive parsing.
 Lecture 4: OT Syntax Sources: Kager 1999, Section 8; Legendre et al. 1998; Grimshaw 1997; Barbosa et al. 1998, Introduction; Bresnan 1998; Fanselow et al. 1999; Gibson & Broihier 1998. OT is not a theory
Lecture 4: OT Syntax Sources: Kager 1999, Section 8; Legendre et al. 1998; Grimshaw 1997; Barbosa et al. 1998, Introduction; Bresnan 1998; Fanselow et al. 1999; Gibson & Broihier 1998. OT is not a theory
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
University of Alberta. Large-Scale Semi-Supervised Learning for Natural Language Processing. Shane Bergsma
 University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
First Grade Curriculum Highlights: In alignment with the Common Core Standards
 First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
Approaches to control phenomena handout Obligatory control and morphological case: Icelandic and Basque
 Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
An Introduction to the Minimalist Program
 An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
Language Model and Grammar Extraction Variation in Machine Translation
 Language Model and Grammar Extraction Variation in Machine Translation Vladimir Eidelman, Chris Dyer, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department
Language Model and Grammar Extraction Variation in Machine Translation Vladimir Eidelman, Chris Dyer, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department
Coordination Structure Analysis using Dual Decomposition
 Coordination Structure Analysis using Dual Decomposition Atsushi Hanamoto 1 Takuya Matsuzaki 1 Jun ichi Tsujii 2 1. Department of Computer Science, University of Tokyo, Japan 2. Web Search & Mining Group,
Coordination Structure Analysis using Dual Decomposition Atsushi Hanamoto 1 Takuya Matsuzaki 1 Jun ichi Tsujii 2 1. Department of Computer Science, University of Tokyo, Japan 2. Web Search & Mining Group,
Parsing natural language
 Rochester Institute of Technology RIT Scholar Works Theses Thesis/Dissertation Collections 1983 Parsing natural language Leonard E. Wilcox Follow this and additional works at: http://scholarworks.rit.edu/theses
Rochester Institute of Technology RIT Scholar Works Theses Thesis/Dissertation Collections 1983 Parsing natural language Leonard E. Wilcox Follow this and additional works at: http://scholarworks.rit.edu/theses
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Adapting Stochastic Output for Rule-Based Semantics
 Adapting Stochastic Output for Rule-Based Semantics Wissenschaftliche Arbeit zur Erlangung des Grades eines Diplom-Handelslehrers im Fachbereich Wirtschaftswissenschaften der Universität Konstanz Februar
Adapting Stochastic Output for Rule-Based Semantics Wissenschaftliche Arbeit zur Erlangung des Grades eines Diplom-Handelslehrers im Fachbereich Wirtschaftswissenschaften der Universität Konstanz Februar
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
PRODUCT PLATFORM DESIGN: A GRAPH GRAMMAR APPROACH
 Proceedings of DETC 99: 1999 ASME Design Engineering Technical Conferences September 12-16, 1999, Las Vegas, Nevada DETC99/DTM-8762 PRODUCT PLATFORM DESIGN: A GRAPH GRAMMAR APPROACH Zahed Siddique Graduate
Proceedings of DETC 99: 1999 ASME Design Engineering Technical Conferences September 12-16, 1999, Las Vegas, Nevada DETC99/DTM-8762 PRODUCT PLATFORM DESIGN: A GRAPH GRAMMAR APPROACH Zahed Siddique Graduate
An Interactive Intelligent Language Tutor Over The Internet
 An Interactive Intelligent Language Tutor Over The Internet Trude Heift Linguistics Department and Language Learning Centre Simon Fraser University, B.C. Canada V5A1S6 E-mail: heift@sfu.ca Abstract: This
An Interactive Intelligent Language Tutor Over The Internet Trude Heift Linguistics Department and Language Learning Centre Simon Fraser University, B.C. Canada V5A1S6 E-mail: heift@sfu.ca Abstract: This
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
Construction Grammar. University of Jena.
 Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
Pre-Processing MRSes
 Pre-Processing MRSes Tore Bruland Norwegian University of Science and Technology Department of Computer and Information Science torebrul@idi.ntnu.no Abstract We are in the process of creating a pipeline
Pre-Processing MRSes Tore Bruland Norwegian University of Science and Technology Department of Computer and Information Science torebrul@idi.ntnu.no Abstract We are in the process of creating a pipeline