Deep Ensemble Learning ABDELHAK LEMKHENTER 07/03/2017
|
|
|
- Sarah Shepherd
- 5 years ago
- Views:
Transcription
1 Deep Ensemble Learning ABDELHAK LEMKHENTER 07/03/2017
2 Presentation Outline 2 Ensemble Learning Stacking Boosting Simple Deep Ensemble Learning A heterogenous stack More Advanced Deep Ensemble Learning Multi-Resolution Stacking Deep Incremental Boosting
3 Ensemble Learning 3 An ensemble learning is the practice of training multiple estimators and combining them into one robust estimators. For ensemble learning to be efficient, the set of learners should be as diverse as possible : this allows each learner to capture a different pattern. Diversity can be obtain by : Using different hyperparameters when using the same base learner; Subsampling the training data (useful when we have too little data, or too much data ); Using different algorithms.
4 Different ensemble techniques 4 Ensemble learning includes various techniques. The most commonly used ones are the following : Stacking Boosting
5 Stacking 5 In stacking, we train a meta-learner to combine our base learners. The base learners are different machine learning algorithms. [1] Output Meta-learner Model 2 Model n Model 1 Model 3 Input
6 Boosting 6 In boosting, we iteratively combine a set of weak estimators using the same machine learning algorithm- into a strong learner. Weak learner only needs to be slightly better than random guessing.[2] Gradient boosting
7 Adaptive Boosting 7 At each iteration step: We train a weak learner using a sampling distribution D i ; We update D i by giving more weight to miss labeled data points.
8 Deep Learning and Ensemble Learning 8 The two field share some similar guide lines (symmetry breaking ~ increasing diversity). Deep Neural Networks have various architectures and many hyperparameters which make them a good candidate for creating diverse sets of learners.
9 Ensemble Deep Learning for Speech Recognition[4] 9 A simple Ensemble model by stacking 3 types of Neural Nets.

10 Evaluation of the model 10 Evaluation on the TIMIT phone recognition task : Training set : 462 speakers Dev set : 50 speakers Test set : 24 speakers
11 Monaural Speech Separation 11 Task of separating a speech signal of a target from background noise or an interfering a speech signal, using data from a single microphone. We will focus on three approach : A Masking method using a DNN; A Mapping method using a DNN; Multi-Resolution Stacking.
12 Masking based DNN 12 We are trying to predict the Ideal Ratio Mask, where each T-F unit encodes the ratio of the target signal over the mixed signal.
13 Mapping based DNN 13 In this approach, we are trying to learn how to directly the mixed signal to the target signal.
14 Multi-resolution stacking 14 Module n Postprocessing Output Module 1 Input Preprocessing
15 Preprocessing and post-processing 15 Preprocessing Postprocessing Mixed Signal Target signal Inverse STFT STFT Target signal in TF domain Phase of the mixed signal y n Estimated RM y n
16 A Learning module 16 Output of the previous module + spectra of the mixed signal Expanding features in resolution R1 Expanding features in resolution R2 Expanding features in resolution Rp DNN 1 DNN 2 DNN p RM 1 RM 2 RM p The last module only has one DNN
17 Feature expansion 17 For a given resolution R, For each frame m, we expand the input with window of size 2*R+1 centered around the frame m. This is done for each RM passed down from the previous module and for the magnitude spectra of the STFT of the mixed signal
18 Model evaluation 18 Training and test set are generated using the SSC,TIMIT and IEEE-TIMIT datasets. Three different settings are used : Same target and interfering speakers with : Different SNR lev els Randomly chosen SNR lev el Same target but using a different interfering speaker

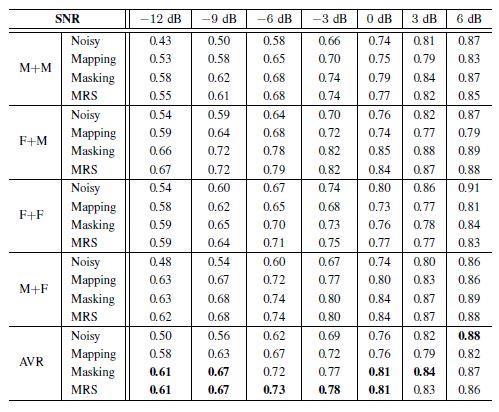
19 Results 1/3 19 SSC TIMIT

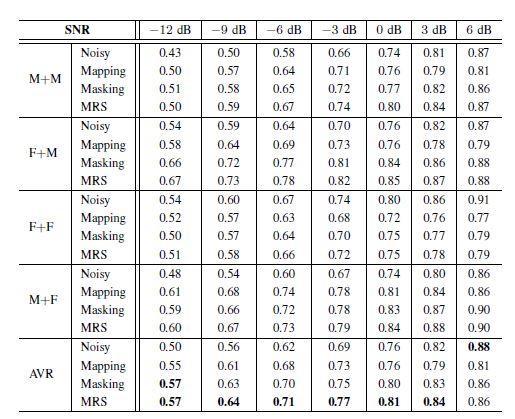
20 Results 2/3 20 SSC TIMIT

21 Results 3/3 21
22 Deep Incremental Boosting 22 Deep Ensemble Learning requires training more Neural Nets DIB is a combination of deep learning, transfer learning and ensemble learning, suggested to tackle this issue.

23 Application of Transfer Learning 23
24 DIB 24

25 Benchmark 25 Mislabeling ratio Training time
26 DIB for Spoken digit recognition 26 Data set : Training set :10 digits x 10 utterance x 66 speakers (Male and female) Test set : 10 digits x 10 utterance x 33 speakers (Male and female)
27 Architecture and results 27 Architecture Conv2D : 64 2x2 MaxPooling :1x2 Conv2D :128 2x2 MaxPooling :1x2 For 0 to 8 Conv2D :64 2x2 Fully connected layer :128 Softmax output layer Results For 2 epoch per training One CNN : DIB : If we use equivalent time (40 epoch) for the single CNN :
28 Thank you for your attention 28
29 Reference 29 [1] Wolpert, D. H., (1992). Stacked Generalization, Neural Networks, 5, 241. [2] Y. Freund, R.E. Schapire, A short introduction to boosting, in: Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence, Morgan Kaufmann, 1999, pp [2] Alan Mosca and George Magoulas. Deep incremental boosting. In Christoph Benzmuller, Geoff Sutcliffe, and Raul Rojas (eds.), GCAI nd Global Conference on Artificial Intelligence, volume 41 of EPiC Series in Computing, pp EasyChair, 2016a. [3] L. Deng and John Platt, Ensemble Deep Learning for Speech Recognition, Interspeech, [4] Zhang, Xiao-Lei, and Deliang Wang. "A Deep Ensemble Learning Method for Monaural Speech Separation." IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 24.5 (2016): Web. 23 Jan [5] Alan Mosca and George Magoulas. Deep incremental boosting. In Christoph Benzmuller, Geoff Sutcliffe, and Raul Rojas (eds.), GCAI nd Global Conference on Artificial Intelligence, volume 41 of EPiC Series in Computing, pp EasyChair, 2016a.
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions
 26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Grounding Language for Interactive Task Learning
 Grounding Language for Interactive Task Learning Peter Lindes, Aaron Mininger, James R. Kirk, and John E. Laird Computer Science and Engineering University of Michigan, Ann Arbor, MI 48109-2121 {plindes,
Grounding Language for Interactive Task Learning Peter Lindes, Aaron Mininger, James R. Kirk, and John E. Laird Computer Science and Engineering University of Michigan, Ann Arbor, MI 48109-2121 {plindes,
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE
 2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Activity Recognition from Accelerometer Data
 Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
ScienceDirect. A Framework for Clustering Cardiac Patient s Records Using Unsupervised Learning Techniques
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
THE enormous growth of unstructured data, including
 INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2014, VOL. 60, NO. 4, PP. 321 326 Manuscript received September 1, 2014; revised December 2014. DOI: 10.2478/eletel-2014-0042 Deep Image Features in
INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2014, VOL. 60, NO. 4, PP. 321 326 Manuscript received September 1, 2014; revised December 2014. DOI: 10.2478/eletel-2014-0042 Deep Image Features in
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX,
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
Opinion on Private Garbage Collection in Scarborough Mixed
 FOR IMMEDIATE RELEASE Opinion on Private Garbage Collection in Scarborough Mixed Toronto, February 8 th In a random sampling of public opinion taken by The Forum Poll among 1,090 Toronto voters, support
FOR IMMEDIATE RELEASE Opinion on Private Garbage Collection in Scarborough Mixed Toronto, February 8 th In a random sampling of public opinion taken by The Forum Poll among 1,090 Toronto voters, support
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
A Deep Bag-of-Features Model for Music Auto-Tagging
 1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
Knowledge-Based - Systems
 Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Mining Association Rules in Student s Assessment Data
 www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS
 DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS Jonas Gehring 1 Quoc Bao Nguyen 1 Florian Metze 2 Alex Waibel 1,2 1 Interactive Systems Lab, Karlsruhe Institute of Technology;
DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS Jonas Gehring 1 Quoc Bao Nguyen 1 Florian Metze 2 Alex Waibel 1,2 1 Interactive Systems Lab, Karlsruhe Institute of Technology;
Deep Facial Action Unit Recognition from Partially Labeled Data
 Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term