Accepted Manuscript. Title: Region Growing Based Segmentation Algorithm for Typewritten, Handwritten Text Recognition
|
|
|
- Coleen Stephens
- 6 years ago
- Views:
Transcription

1 Title: Region Growing Based Segmentation Algorithm for Typewritten, Handwritten Text Recognition Authors: Khalid Saeed, Majida Albakoor PII: S (08) DOI: doi: /j.asoc Reference: ASOC 520 To appear in: Applied Soft Computing Received date: Revised date: Accepted date: Please cite this article as: K. Saeed, M. Albakoor, Region Growing Based Segmentation Algorithm for Typewritten, Handwritten Text Recognition, Applied Soft Computing Journal (2007), doi: /j.asoc This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
2 Region Growing Based Segmentation Algorithm for Typewritten and Handwritten Text Recognition Khalid Saeed, Faculty of computer Science, Bialystok Technical University, Bialystok, Poland Majida Albakoor, Faculty of Science, Aleppo University, Aleppo, Syria Abstract- This paper presents a new technique of high accuracy to recognize both typewritten and handwritten English and Arabic texts without thinning. After segmenting the text into lines (horizontal segmentation) and the lines into words, it separates the word into its letters. Separating a text line (row) into words and a word into letters is performed by using the region growing technique (implicit segmentation) on the basis of three essential lines in a text row. This saves time as there is no need to skeletonize or to physically isolate letters from the tested word whilst the input data involves only the basic information the scanned text. The baseline is detected, the word contour is defined and the word is implicitly segmented into its letters according to a novel algorithm described in the paper. The extracted letter with its dots is used as one unit in the system of recognition. It is resized into a 9x9 matrix following bilinear interpolation after applying a lowpass filter to reduce aliasing. Then the elements are scaled to the interval [0,1]. The resulting array is considered as the input to the designed Neural Network. For typewritten texts, three types of Arabic letter fonts are used Arial, Arabic Transparent and Simplified Arabic. The results showed an average recognition success rate of 93% for Arabic typewriting. This segmentation approach has also found its application in handwritten text where words are classified with a relatively high recognition rate for both Arabic and English languages. The experiments were performed in MATLAB and have shown promising results that can be a good base for further analysis and considerations of Arabic and other cursive language text recognition as well as English handwritten texts. For English handwritten classification, a success rate of about 80% in average was achieved while for Arabic handwritten text, the algorithm performance was successful in about 90%. The recent results have shown increasing success for both Arabic and English texts. Keywords: Arabic Handwritten Text Recognition, Region Growing Segmentation, Implicit Segmentation, Contour detection, Horizontal Segmentation, Slant Correction 1. Introduction Research on written texts and in particular written character recognition is as old as the computer itself, a proof of which is Dinnen's work of 1955 [1]. However, its challenging nature and the continuously increasing demand for a fast cheap and more practical to implement recognition system has made it open for further research [2], [3]. OCR (Optical Character Recognition) systems have advanced far for typewritten texts of almost all typewritten languages including Arabic or other languages that use the Arabic alphabet (like Farsi, Kurdish and Urdu). However, the handwritten texts of these languages have received the least attention in this field [4-6]. This maybe is due to the lack or little interest in the field in addition to the specification of the Arabic language itself. The cursive nature of the Arabic text is the main obstacle to any Arabic OCR system [7]. In fact, the problem of cursive text classification exists even in English Page 1 of 40
3 language texts; most of the commercial classifying systems suffer from finding a solution to the problems of slant, slope and letter aliasing occurring in every handwritten text and even in many machine texts of cursive character [8], [9]. The cursive character causes problems resulting mainly from the concept of letter overlapping which is a steady feature of the handwritten texts taking place in all handwriting alphabets. Researchers have paid special attention to the problem of overlapping and developed many algorithms to segment the text into words and words into letters using varieties of techniques to overcome this problem, particularly in Arabic alphabet [10-12]. Many Arabic character recognition systems have been proposed [13]. Different approaches on both machine and handwritten texts have been presented and applied with efficient approaches to handwriting recognition [14-17]. In most of the text recognition systems, the character thinning to a one-pixel skeleton is required. Thinning methodologies can be found in detail in [18] and [19]. More methods and new approaches can also be found in [8] and [20]. However, thinning stage is bypassed in the work shown in this paper. The major contribution of this paper is represented by implicitly segmenting (without visual cutting) the cursive words into their letters, and without thinning. Simply, the segmentation of the cursive word is impliedly achieved by only the idea of the baseline, the contour of the word and the growing region. This, noticeably, has saved time and the results are not worse than the known methods and rather better in some odd cases of poor handwriting. The procedure of the new technique used in this paper starts with simple preprocessing stages. The image is converted into its binary equivalence by thresholding; the threshold is defined automatically when performing with MATLAB [21] in such a way that the handwritten text under consideration is completely separated from the background. The binarized image is also applied to a median-filter-supported 3x3 window [22], [23] for smoothing and noise elimination. In Matlab, the function ordfilt2 is used for enhancing the quality of the text image. After the preprocessing stage, the text is separated into lines and the lines into words. The text segmentation into lines also implies the problem of overlapping but of horizontal type. Segmenting lines into words is also shown in this work in the section of vertical segmentation. The next step is to detect the baseline of the words and their contour by following the authors' previously implemented algorithms [8], [19], [24], [25]. Then the word is ready for further processing. For the sake of classification and recognition, the letter is considered together with its dots as one unit. It is then resized into an array of 81 elements with a bilinear interpolation by applying a lowpass filter. The size of the default filter is3 3. The elements are rescaled into the interval [0, 1]. Finally, the array is entered as the input to the classifying Neural Network. The NN consists of one input layer of 81 neurons, one hidden layer of 200 neurons and an output layer of 28 neurons. Three types of Arabic typewritten-letter fonts with three different sizes are used; Arial, Arabic Transparent and Simplified Arabic. For the Arabic and English handwritten text classification, the following Darwin proverb is used: "It's not the strongest that survives, nor the most intelligent; it's the one most adaptable to change." In Arabic, 2 Page 2 of 40
4 2. Text Processing for Region Detection: Lines and Words The technique of histogram gives a good guidance to split the image into regions of similar type. However, the fundamental drawback of histogram-based region detection is that histograms provide no spatial information except the grey level distribution [26], [27]. From the other side, authors' experiments on Arabic words have shown that the region growing technique allows treating the close pixels as ones of similar grey values [27]. On the basis of this idea and following the idea of the original methods of region growing [26-28] the authors have developed a modified region growing algorithm. This has enhanced the histogram to detect the region of words in a line and letters in a word without using the conventional segmentation. Thus, implicit segmentation is achieved. We will first consider the idea of baseline, upper and lower lines, and the region growing together with the algorithm that implies the new approach to the implicit segmentation of lines into words and words into their letters. An example on the typewritten word BAATIN باطن will accompany the explanation of the algorithm. 2.1 Word Detection This starts with the detection of the baseline, the other two upper and lower lines and ends with contour detection. The word BAATIN باطن is considered for simplicity of,باطن algorithm explanation. To show how to extract the four letters from the word consider the following steps: a. The main baseline is detected. The baseline plays an essential role in Arabic writing. Most letters are connected to each other at the baseline to form a zone of the highest pixel-concentration on the writing line. The baseline detection is performed by detecting the peak in the projection profile of the image (the horizontal histogram) of the written line. The baseline has the highest number of black pixels (Fig. 1). 3 Page 3 of 40
5 Fig. 1. The baseline of the text line computed on the basis of the compound word باطن - Baatin b. There are two other lines to be detected, the upper and the lower lines. They efficiently help to find the positions of the letter-joining pixels on the baseline and they play an essential role in finding the word body. The position of the baseline is parameterized by the positions of these two lines, and vice versa. They are defined as the upper and the lower rows of largest number of pixels above and below the already evaluated baseline (Fig. 2). The baseline pixels in their major number are included between these two rows. Fig. 2 shows the plot of the horizontal projection profile of an Arabic text line. It illustrates the position of the upper and lower lines together with the baseline. (a) (b) Fig. 2. The plot of the horizontal histogram of the text line consisting of the word با طن - Baatin is illustrating the positions of the three basic lines. c. The contour of the word image is determined (Fig. 3). There are many methods available to thin the word to its contour. The method used here is given in detail in [8]. Fig. 3. The contour of the word باطن -Baatin together with the upper, base and lower lines 2.2 Region growing method for letter detection Here the basic idea of applying the region growing [26] to achieve implicit segmentation for letter detection is explained. Region Growing is an approach to image segmentation in which neighbouring pixels are examined and added to a region class (the word body here) if no edges are detected [27]. This process is repeated for each boundary pixel in the region. At the end of the section, a general region-merging algorithm is introduced together with its brief computer flowchart. Thus, the extracted word is first detected by defining the word shape without dots. The set of baseline points from the body of the word are extracted. These points, as stated before, exist only between the upper line and 4 Page 4 of 40
6 lower line. The region growing concept is performed as shown in Fig. 4, which, in detail, illustrates the basic idea of the modified region growing algorithm as applied to با - the first part of the Arabic word باطن. It shows the extension of the connected neighbourhood pixels of the points and their next neighbours. More details on the basic region growing algorithms and their applications in Computer Graphics and Image Processing can be found in [26], [27] and [28]. After showing the method performance (Fig. 4) in MATLAB, the algorithm is then given. Fig. 4 (a) Fig. 4(b) Fig. 4(c) 1-10 Fig. 4. The growing region. (a) shows the stages of the growing region for the subword."با" (b) and (c) show the performance stages of the modified growing region algorithm between step 1 and step 2 in (a). Notice the series of images 1-10 in (c) are given from left to right to show the step-by-step on-line scanning from right to left (Arabic text is read from right). in (a) shows an example of the first scanned feature points; they are the points between the upper and lower lines while in (c). shows a pixel x with its 8 neighbours and the way the region growing extends Algorithm This algorithm summarizes the detailed steps of the region growing in letter extraction. 1. After evaluating the word contour, first without dots, the vertical histogram of the resulted image his vert (word) is computed. 2. The resulted word is scanned vertically from right to left. 3. If there is a pixel p(x i, y j ) satisfying the following conditions, then the pixel p(x i,y j ) is a joint pixel called p joint (x i,y j ), where i = d,..., 1, and j = 1,..., d1while d and d 1 are the width and height of the word image, respectively. b. The position of p(x i,y j ) ε [upper line, lower line] and p(x i,y j ) =1 & his vert (x i,y) =2 c. The position of P(x i-1,y j ) ε [upper line, lower line]& p(x i-1,y j ) =1 & his vert (x i-1,y) =2 d. The position of P(x i-2,y j ) ε [upper line, lower line]& p(x i-2,y j ) =1 & his vert (x i-1,y) =2 5 Page 5 of 40
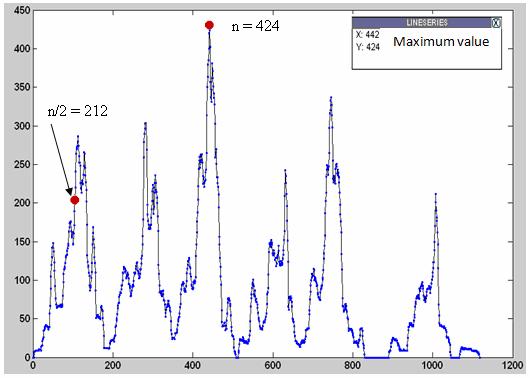
7 4. The point p joint (x i,y j ) is not a joint pixel if the first pixel p(x k,y min ) satisfies the following conditions, where his ( x k, y ) > 2 for k = i 1, i 2,..., 1. vert ii. p( x k, y min ) = 1 iii. p ( x k 1, y min ) = 1 iv. y a < y b where y a, y b are y-coordinates of p(x k,y min ) and p(x k-1,y min ), respectively v. his ver t ( x k 2, y ) = 0 Consequently, the other points belonging to the same letter, are defined. 5. Else, the point p joint (x i,y j ) is a joint pixel and the letter is extracted. The start of a letter is indicated by the column of the scanned start and the end of the letter is indicated by the column of the joint pixel. For higher efficiency, the removed dots are added to the extracted letter. This is done as follows: e. The column of the joint pixel p joint (x i,y j ) is checked for dots in the stored dot array. f. If there are dots and their number is tenacious to the extracted letter then the body of dots is considered as a part of that letter. g. Else, the body of dots is considered as a part of the next letter. 6. Repeat the steps from (1-5) until the word is scanned completely. 3. Segmentation Using Region Growing Algorithm After we have seen how the algorithm of region growing works and how the word is implicitly segmented into its letters, we will now show the application of the algorithm to handwritten texts. The growing region is applied to both word detection in a line and letter detection in a word. Thus, the concept of both horizontal and vertical overlapping is considered. In the following section the horizontal segmentation is considered for both cases - with and without word overlapping - in Arabic and English handwritten texts. 3.1 Horizontal segmentation text into lines The horizontal histogram is first evaluated and used to extract the text lines (text line will be called a row to avoid confusion with the base, upper or lower lines of a text line) from the image. This is done by computing the maximum value n in the horizontal histogram of the row (its peak). Experiments have shown that n / 2 is the optimal number of baseline total pixels per row in a text. Figure 5 illustrates the histogram of the first row showing the position of the base-line on it. Fig. 5 The first text row and its histogram to show the way of selecting the baseline position. Then the row separation starts by considering the Arabic text from right to left downwards searching for the pixel line that contains n / 2 pixels or more. This line is then 6 Page 6 of 40
8 the baseline of the first text line (row); its total number of pixels is evaluated and used as the essential parameter in the growing region algorithm. On the other hand, the number of pixels that exist above this line in the first text line will be the basis of upper and lower parts verification of the considered line-text. Figure 6a shows the Arabic text under testing while Fig. 6b shows the text after line separation. (a) Overlapping in Arabic text (b) Line separation Fig. 6. Arabic handwritten text showing the horizontal overlapping problem. Notice the extreme case of how the letter part that belongs to the word of the fifth row appears as a part of the fourth row. Such cases are really the most difficult ones and sometimes need the human check. In fact, it is this and similar problems that cause the success rate to decrease below the expectation of researchers. The same procedure in Arabic text processing is applied to English texts (Fig. 7a), but the scanning is now from left to right. The text looks like Fig. 7b after line separation. (a) Overlapping in English text (b) The text after row separation Fig. 7 English handwritten text showing the horizontal overlapping problem. The word letters that belong to one row but share space with the body of another word in the preceding or following rows will find their correct place and belonging. Accordingly, the "double l" in the word intelligent (Fig. 7a), which actually belong to the second row are then evaluated to be within the second line and not the first although they are part of both of the first and the second lines. 7 Page 7 of 40
9 To show the detailed procedure of line separation from each other consider the English text part in Fig. 8. The extracted text row is divided into eight parts and the lower line is computed for each part. There are two lower lines, one for parts 1-3 and 6-8, the other for parts 4-5. (a) (b) Fig. 8 Separating two lines in English text According to the algorithm the text parts of height d 1 in Fig. 8a (parts 4-5) is first looked at as part of the word strongest. When the region growing algorithm is applied, it will test the word strongest within the first row. When it finds the large number of pixels within d 1 but below the lower line of the row of the word strongest, it will automatically exclude the additional pixels from this row and will therefore change direction from the letter g to the letter e and so on. This means the lower line of parts 1-3 and 6-8 is the actual line between the rows 1 and 2. The same is repeated with the next rows until the end of the page. 3.2 Vertical segmentation words into letters The vertical histogram is used to extract the words from the text line. Here also the idea of region growing is used. Before scanning for letters in a word, both the slope and the slant are corrected. This will be shown on Arabic text. Slope correction The row is divided into four parts. The base-line in the first quarter (the most right) is found and then the other words in the row will be corrected according to it. This is because we assume people start writing straight but after the first words they write with an inclination and hence the first word would definitely decide in a high percentage the actual horizontal level of writing. All the words in a row are then shifted up to have their base-line at the same level of that in the first word. Fig. 9 shows what actually takes place when correcting the base-line of a row. This is the row baseline, drawn according to that of the first word 8 Page 8 of 40
10 (a) The baseline of each word in a row is evaluated (b) The slope correction Fig. 9 Slope problem: the text row (a) before correction, (b) after correction. Slant Correction After the word slope is corrected, it is tested for the need to any slant correction. Figure 10 shows the word to be rotated for slant correction. It is then rotated by an angle calculated by the inclination of the baseline from the horizontal level (Fig. 10). This is easy to implement. (a) Fig. 10 Slant correction. The word in (a) is rotated to the horizontal level in (b). The whole text row containing the part illustrated in Fig. 10 is shown in Fig. 11 after slant correction. (a) (b) Fig. 11 Slope correction Word stretching There are two letters س and ص in Arabic alphabet which appear as a word rather than a letter as they seem to be composed of fragments similar to letters in a word. However, the system usually recognizes such cases by considering the distances between their composing parts and their heights. Moreover, in many cases we use the stretching technique, which solves many problems. Figure 12 illustrates the idea of stretching a word. It simply depends on extending the silence region around the baseline. If in the resulting object there are dots above or under the object, it means there exists a letter that was difficult to extract before stretching. Otherwise, if no dots exist, then the heights belong to only one letter. On the other hand, after stretching, we can see that the word is easy to look at as a whole and with clarity to see its letters. The region growing algorithm can easily find that the object in Fig. 12b is a word of three letters (Fig. 12c). This (b) 9 Page 9 of 40
11 technique will enlarge the area of pixel connection between letters in a word and will certainly increas the probability of probability of getting the right place of segmentation. (a) A word (b) The word in (a) after stretching (c) The three letters of the word in (a) Fig. 12 Stretching technique as a tool in word segmentation into letters. 4. Neural Network Based Classification In previous works other classifiers were used [29], [30], for example the conventional point-to-point comparison (or the nearest neighbour) classifiers. When classifying with these methods of simple comparison, the word feature vector x i is compared with the vectors y i describing the word in the Base Set to search for the nearest neighbour of the tested word. We used 1-norm distance d, the Manhattan distance, as shown in Eq. (1), for those calculations: d = n i= x i y i 1 (1) This allowed achieving around 90% correctly recognized words with Arabic type writing. In some cases, the method of Nearest Neighbours is quite inconvenient because it needs to maintain big database of already classified vectors, and in order to recognize a word all the vectors from the database are compared with the vector describing the tested word. In cases of huge databases it becomes a time-consuming task and hence inefficient. The use of artificial neural networks avoided such inconvenience. In our research we use a simple classic feed-forward neural network, with one hidden layer, trained by the backpropagation method [30]. As a transfer function, we took the bipolar logistic sigmoid function (Eq. 2) 2 F ( x) = 1 (2) x 1+ e Two sets of documents are considered in this work. They are written in Arial, Arabic Transparent and simplified Arabic fonts of sizes 10, 12, 14 and 16. The first set is taken 10 Page 10 of 40
12 of only size 14 for all fonts to be used in the training and teaching processes. The second set is taken of sizes 10, 12 and 16 of the considered fonts for the test process. All the documents are scanned at a resolution of 600 dots per inch. Each letter in the Arabic alphabet has four possible forms depending on their position in the word. They are isolated, beginning, middle or ending letters (see Table 1). Therefore, there are four cases in letter consideration and evaluation and hence, we use four NNs to classify the primary parts of the Arabic word. These NNs are trained to classify the Arabic letters as summarized in the results section below. 5. Results and Applications In this section we show how to apply the neural networks to classify the Arabic word image after segmenting it into letters using the growing region technique. First, we consider the letters in their isolated forms (this is the case when the word structure ر ا ز ي involves letters in their isolated form separated from each other like the word in Table ), then we show the classification results of the other three letter forms. 5.1 Arabic letters Since the English typewritten letters are easy to recognize, we here consider only Arabic alphabet. The extracted letter image matrix is resized into a 9 9 matrix using the nearest neighbor interpolation. The resulted matrix is considered as an input to the NN. It is represented by one hidden layer of 200 neurons existing between an input layer of 81 neurons and output layer of 29 neurons due to the 28 Arabic basic letters plus the LamAlif لا (some references consider لا as the 29 th letter in the Arabic alphabet). Table 1 shows the output of the NN. Table 1. Arabic alphabet in its 28 main letters with each given in its four different possible forms (from [8], I Isolated, E Ending, M Middle, B Beginning.) This number of neurons in the hidden layer was found experimentally. We have experienced 100 and 200 neurons. The highest performance was at 200 neurons. Moreover, the number of iterations was 555 for 100 neurons, while it was only 338 for 200, with the best success rate. For example, the recognition rate of the letter jeem ج is 66.66% at 100 neurons while it is 91.66% at 200 neurons in the hidden layer. Table 2 shows how the rate of successful recognition increases when increasing the number of neurons from 100 to 200 in the hidden layer. Table 2. The behaviour of NN classifiers for two different numbers of neurons in the hidden layer The NN is trained on the first set depending on the default values as training parameters. The momentum coefficient is 0.25, learning rate is 0.05 and the sum square error is examined on NN uses bipolar function as an activation function while the 11 Page 11 of 40
13 NN weights and biases are generated randomly, and the range of input vector values is ranked between 0 and +1. The first set contains 87 letters used as examples through the training and learning processes while the second set contains 261 letters for the testing process. Figure 13 shows the plot of NN training. Fig. 13 The plot of NN training The output of the NN is set to 29, The NN is trained on 87 Arabic letters of size 14 of Arial, Arabic Transparent and Simplified Arabic fonts, and is recalled for 87 letters. The experiments held at these conditions gave a 100 % recognition rate at training time of 3 [seconds] with 338 [epochs]. For Arial font at size 10 and 16, the rate of recognition was 100% but for size 12, the rate of recognition was For the Simplified Arabic font of size 10, the recognition rate was 96.5% while for sizes 12 and 16 it was 100%. For the Arabic Transparent font of sizes 10 and 16, the recognition rate was 100% but for size 12, however, the recognition rate dropped to 93.10%. 5.2 Other possible letter forms The same discussion applies to the letters in other sizes for different positions. Table 3 shows the classification results for other considered letters of different fonts and sizes. Table 3. Classification results The same discussion applies to the hand written text in Arabic and English for different letter positions. Table 4 shows the classification results for both Arabic and English letters in a word after implicit segmentation. Table 4. Classification results 6. DISCUSSION and CONCLUSIONS In this paper a new method is exploited for automatic recognition of printed and handwritten Arabic and English words. The developed method proved to be a good wordsegmenting tool. The examined word Baatin باطن was chosen for demonstration because it resembles two words as it contains two subwords. The novelty of the algorithm lies in applying the idea of implicit segmentation using the region growing principle. The criterion is based on dividing the text into rows (text lines) and then finding the baseline of the row with two other lines (upper and lower). Together with the contour of the word, these lines are the base for examining the pixels of the word body for the letterconnecting points using the region growing algorithm. The resulting data array from the processing is entered to a Neural Network for classification. In Arabic type written text 12 Page 12 of 40
14 three types of Arabic letter fonts of three different sizes were used - Arial, Arabic Transparent and Simplified Arabic. The performance was by MATLAB. The results of the experiments proved high performance and high speed of the recognising system. They also showed the successful application of the classical NN in classifying the word letters using the optimal number of iterations for the given number of neurons per hidden layer. Other Neural Networks were also tested but the results were not better. This is because the more precise the stages preceding classification are, the better classification results are. Therefore, any reasonable classifying tool would be a possibility. To increase the rate of success in handwritten recognition, the slant and slope of the text rows were corrected using easy-to-implement techniques. As a result, the recognition reached about 90% in the case of Arabic text and above 80% for the English text. The results, however, were so promising that the authors have decided to go further with this new approach. The current and future work is on handwriting with bilingual texts using larger database size with more training of the neural networks. Acknowledgement This work was supported by the Rector of Bialystok University of Technology (grant number W/WI/10/07). The authors are indebted to the anonymous Referees for their constructive remarks and comments. In fact, it is these comments which changed the direction of research to cover both typewritten and handwritten texts written in both Arabic and English languages, the subject in which we have obtained promising results. REFERENCES [1] Dinnen G. P.: Programming Patteren Recognition, Proc. West. Joint Comp. Conf., New York 1955, [2] Elgammal A. and Ismail M. A.: Techniques for Language Identification for Hybrid Arabic-English Document Images, Sixth International Conference on Document Analysis and Recognition (ICDAR 01), Seattle, Washington, U.S.A, September, [3] Nagy A.: Twenty Years of Document Image Analysis in PAMI, IEEE Transactions on Pattern Analysis and Machine Intelligence 22, January 2000, [4] Sarfraz M., Nawaz S. N., and Al-Khuraidly A.: Offline Arabic Text Recognition System, International Conference on Geometric Modeling and Graphics (GMAG'03, London, England, UK, July 16-18, 2003, [5] Pal U., Sarkar A.: Recognition of Printed Urdu Script, Seventh International Conference on Document Analysis and Recognition (ICDAR'03), Edinburgh, Scotland), August 2003, [6] Cheung A., Bennamoun M., Bergman N. W.: An Arabic Optical Letter Recognition System Using Recognition-Based Segmentation. Pattern Recognition, vol. 34, no. 2, 2001, Page 13 of 40
15 [7] Steinherz T, Rivlin E, Intrator N.: Off-line cursive word recognition: A survey, International Journal on Document Analysis and Recognition, Volume 2, Issue 2-3, 1999, [8] Saeed K.: Image Analysis for Object Recognition. Bialystok Technical University Press, Bialystok, Poland, [9] Ghuwar M., Skarbek W.: Recognition of Arabic Characters A Survey. Polish Academy of Sciences, Release no. 740, Warsaw, Poland, [10] Zidouri A., Sarfraz M., Shahab S. A., Jafri S. M.: Adaptive Dissection Based Subword Segmentation of Printed Arabic Text, Ninth International Conference on Information Visualisation (IV'05), London, July 2005, [11] Hamid A., Haraty R.: A Neuro-Heuristic Approach for Segmenting Handwritten Arabic Text, ACS/IEEE International Conference on Computer Systems and Applications (AICCSA'01), Beirut, Lebanon, June 2001, [12] Lorigo L.M., Govindaraju V.: Offline Arabic Handwriting Recognition: A Survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 28, no. 5, May, 2006, [13] Amin A.: Off-Line Arabic Character recognition: the-state-of-art. Pattern Recognition, vol. 31, no. 5, 1998, [14] Farooq F., Govindaraju V., Perrone M.: Preprocessing Methods for Handwritten Arabic Documents. Int. Conf. Document Analysis and Recognition, 2002, [15] Pechwitz M., Margner V.: HMM based Approach for Handwritten Arabic Word Recognitipon Using the IFN/ENIT-Database. Int. Conf. Document Analysis and Recognition, 2003, [16] Khorsheed M.S.: Recognising Handwritten Arabic Manuscripts Using a Single Hidden Marcov Model. Pattern ecognition Letters, vol. 24, 2003, [17] Amin A.: Recognition of Hand-Printed Latin Characters Based on Generalized Hough Transform and Decision Tree Learning Techniques, International Journal of Pattern Recognition and Artificial Intelligence, 2000, vol. 14; part 3, [18] Lam L., Lee S.-W., Suen C.Y.: Thinning Methodologies - A Comprehensive Survey. IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 14, no. 9, 1992, [19] Saeed K., Rybnik M., Tabędzki M.: Implementation and Advanced Results on the Non-interrupted Skeletonization Algorithm. In: Skarbek W. (Ed.), Lecture Notes in Computer Science LNCS 2124, Springer-Verlag Heidelberg, Germany, 2001, [20] Saeed K.: Computer Graphics and Analysis: A Method for Arbitrary Image Shape Description. Intern. Journal of Machine Graphics and Vision - MGV, vol. 10, no. 2, Institute of Computer Science, Polish Academy of Sciences, Warsaw, Poland, 2001, [21] MATLAB, Version (R12.1) on PCWIN [22] Rafael C. G., Richard E. W.: Digital Image Processing, 2nd Edition, Prentice Hall, NJ, Page 14 of 40
16 [23] Umbaugh S. E.: Computer Imaging Digital Image Analysis and Processing, CRC Press, FL [24] Saeed K.: New Approaches for Cursive Language Recognition: Machine and Handwritten Scripts and Texts. Invited Paper to Intern. Conf. on Advances in Neural Networks and Applications, Tenerife, In: Advances in Neural Networks and Applications, World Scientific Engineering Society Press, 2001, 92-97, () [25] Albakoor M., Dabsh M., and Sukkar F.: BPCC Approach for Arabic Letters Recognition. The 2006 International Conference on Image Processing, Computer Vision and Pattern Recognition (IPCV'06), Las Vegas, USA, June 26-29, 2006, [26] Haralick R. M., Shapiro L. G.: Image Segmentation Techniques. Computer Vision, Graphics, and Image Processing, vol. 29, 1985, [27] Besl P. J., Jain R. C.: Segmentation through Variable-Order Surface Fitting. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 10, no. 2, March 1988, [28] Adams R., Bischof L.: Seeded Region Growing. IEEE Transactions on Pattern Analysis and Machine Intelligence, Volume 16, Issue 6 (June 1994), [29] Tabędzki M., Saeed K.: View-Based Word Recognition System. Proc. 4 th Intern. Conf. on Neural Networks and Artificial Intelligence - ICNNAI 06, Brest, Belarus, 2006, [30] Tabędzki M., Saeed K.: Hybrid Word Recognition System. Proc. 13th Intern. MultiConf. on Advanced Computer Systems ACS-AIBITS/CISIM 06, Miedzyzdroje, Poland, 2006, Page 15 of 40
17 Page 16 of 40
18 Page 17 of 40
19 Page 18 of 40
20 Page 19 of 40

21 Page 20 of 40


22 Page 21 of 40


23 Page 22 of 40

24 Page 23 of 40

25 Page 24 of 40

26 Page 25 of 40

27 Page 26 of 40

28 Page 27 of 40
29 Page 28 of 40
30 This is the row baseline, drawn according to that of the first word Page 29 of 40
31 Page 30 of 40

32 Page 31 of 40
33 Page 32 of 40
34 Page 33 of 40
35 Page 34 of 40


36 Page 35 of 40
37 Table Table 1. Arabic alphabet in its 28 main letters with each given in its four different possible forms (from [8], I Isolated, E Ending, M Middle, B Beginning.) Sq. Letter, Name I E M B Sq. Letter, Name I E M B ض ض ض ض 15 Dh, Dhad ا ا ا ا 1,A Alif ط ط ط ط 16 Tth, Ttaa ب ب ب ب 2,B Baa ظ ظ ظ ظ 17 Zh, Zhaa ت ت ت ت 3,T Taa ر- ر- ز- ز- 4 Th,( ) Thaa ث ث ث ث 18 Ea, Ain ع ع ع ع 5,J Jeem ج ج ج ج 19 Gh, Ghain غ غ غ غ 6 Hh, Hhaa ح ح ح ح 20,F Faa ف ف ف ف 7 Kh, Khaa خ خ خ خ 21 Qq, Qqaf ق ق ق ق 8,D Dal د د د د 22,K Kaf ک ک ک ک 9 Th, Thal ذ ذ ذ ذ 23,L Lam ل ل ل ل 10,R Raa ر ر 24,M Meem م م م م 11,Z Zay ز ز 25,N Noon ن ن ن ن 12,S Seen س س س س 26,H Haa ه ھ ھ ھ 13 Sh, Sheen ش ش ش ش 27,W Waw و و و و 14 Ss, Ssad ص ص ص ص 28,Y Yaa ي ي ي ي Page 36 of 40
38 Table Table 2. The behaviour of NN classifiers for two different numbers of neurons in the hidden layer Number of hidden layer neurons Recognition letters % Isolated Beginning Middle End Page 37 of 40
39 Page 38 of 40
40 Table Fonts and Sizes Arabic Transparent Simplified Arabic Arial Table 3. Classification results Recognition Rate of letters % Isolated Beginning all letters in م in مھند ر ا ز ي Middle in ھ مھند End in د مھند Size Size Size Size Size Size Size Size Size Size Size Size Page 39 of 40
41 Table Letter position (Arabic Handwritten) Recognition Rate of letters % Letter position (English Handwritten) Recognition Rate of letters % Isolated all letters in Table 4. Classification results Beginning ل in Middle ی in End س in Isolated all letters in Beginning c in Middle h-g in End e in Page 40 of 40
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Division of Arts, Humanities & Wellness Department of World Languages and Cultures. Course Syllabus اللغة والثقافة العربية ١ LAN 115
 Division of Arts, Humanities & Wellness Department of World Languages and Cultures Course Syllabus Semester and Year: Course and Section number: Meeting Times: INSTRUCTOR: Office Location: Phone: Office
Division of Arts, Humanities & Wellness Department of World Languages and Cultures Course Syllabus Semester and Year: Course and Section number: Meeting Times: INSTRUCTOR: Office Location: Phone: Office
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Problems of the Arabic OCR: New Attitudes
 Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
Arabic Orthography vs. Arabic OCR
 Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Longest Common Subsequence: A Method for Automatic Evaluation of Handwritten Essays
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 6, Ver. IV (Nov Dec. 2015), PP 01-07 www.iosrjournals.org Longest Common Subsequence: A Method for
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 6, Ver. IV (Nov Dec. 2015), PP 01-07 www.iosrjournals.org Longest Common Subsequence: A Method for
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Large vocabulary off-line handwriting recognition: A survey
 Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Off-line handwritten Thai name recognition for student identification in an automated assessment system
 Griffith Research Online https://research-repository.griffith.edu.au Off-line handwritten Thai name recognition for student identification in an automated assessment system Author Suwanwiwat, Hemmaphan,
Griffith Research Online https://research-repository.griffith.edu.au Off-line handwritten Thai name recognition for student identification in an automated assessment system Author Suwanwiwat, Hemmaphan,
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
ASR for Tajweed Rules: Integrated with Self- Learning Environments
 I.J. Information Engineering and Electronic Business, 2017, 6, 1-9 Published Online November 2017 in MECS (http://www.mecs-press.org/) DOI: 10.5815/ijieeb.2017.06.01 ASR for Tajweed Rules: Integrated with
I.J. Information Engineering and Electronic Business, 2017, 6, 1-9 Published Online November 2017 in MECS (http://www.mecs-press.org/) DOI: 10.5815/ijieeb.2017.06.01 ASR for Tajweed Rules: Integrated with
Study Center in Amman, Jordan
 Study Center in Amman, Jordan Course name: Modern Standard Arabic, Superior I Course number: ARAB 4011 AMJO Programs offering course: Advanced Arabic Language Language of instruction: Arabic U.S. Semester
Study Center in Amman, Jordan Course name: Modern Standard Arabic, Superior I Course number: ARAB 4011 AMJO Programs offering course: Advanced Arabic Language Language of instruction: Arabic U.S. Semester
A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING
 A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING Yong Sun, a * Colin Fidge b and Lin Ma a a CRC for Integrated Engineering Asset Management, School of Engineering Systems, Queensland
A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING Yong Sun, a * Colin Fidge b and Lin Ma a a CRC for Integrated Engineering Asset Management, School of Engineering Systems, Queensland
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Getting into top colleges. Farrukh Azmi, MD, PhD
 Getting into top colleges Farrukh Azmi, MD, PhD But Why? The first revealed word of the Quran? Verily, in the creation of the heavens and of the earth, and the succession of night and day: and in the
Getting into top colleges Farrukh Azmi, MD, PhD But Why? The first revealed word of the Quran? Verily, in the creation of the heavens and of the earth, and the succession of night and day: and in the
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Data Fusion Models in WSNs: Comparison and Analysis
 Proceedings of 2014 Zone 1 Conference of the American Society for Engineering Education (ASEE Zone 1) Data Fusion s in WSNs: Comparison and Analysis Marwah M Almasri, and Khaled M Elleithy, Senior Member,
Proceedings of 2014 Zone 1 Conference of the American Society for Engineering Education (ASEE Zone 1) Data Fusion s in WSNs: Comparison and Analysis Marwah M Almasri, and Khaled M Elleithy, Senior Member,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C
 Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation
 2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Montana Content Standards for Mathematics Grade 3. Montana Content Standards for Mathematical Practices and Mathematics Content Adopted November 2011
 Montana Content Standards for Mathematics Grade 3 Montana Content Standards for Mathematical Practices and Mathematics Content Adopted November 2011 Contents Standards for Mathematical Practice: Grade
Montana Content Standards for Mathematics Grade 3 Montana Content Standards for Mathematical Practices and Mathematics Content Adopted November 2011 Contents Standards for Mathematical Practice: Grade
An Ocr System For Printed Nasta liq Script: A Segmentation Based Approach
 An Ocr System For Printed Nasta liq Script: A Segmentation Based Approach Saeeda Naz, Arif Iqbal Umar, Saad Bin Ahmed,, Syed Hamad Shirazi, M. Imran Razzak,, Imran Siddiqi Department Of Information Technology,
An Ocr System For Printed Nasta liq Script: A Segmentation Based Approach Saeeda Naz, Arif Iqbal Umar, Saad Bin Ahmed,, Syed Hamad Shirazi, M. Imran Razzak,, Imran Siddiqi Department Of Information Technology,
Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge
 Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Extending Place Value with Whole Numbers to 1,000,000
 Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Ph.D in Advance Machine Learning (computer science) PhD submitted, degree to be awarded on convocation, sept B.Tech in Computer science and
 PhD submitted, degree to be awarded on convocation, sept B.Tech in Computer science and") Name Qualification Sonia Thomas Ph.D in Advance Machine Learning (computer science) PhD submitted, degree to be awarded on convocation, sept. 2016. M.Tech in Computer science and Engineering. B.Tech in
Name Qualification Sonia Thomas Ph.D in Advance Machine Learning (computer science) PhD submitted, degree to be awarded on convocation, sept. 2016. M.Tech in Computer science and Engineering. B.Tech in
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Diagnostic Test. Middle School Mathematics
 Diagnostic Test Middle School Mathematics Copyright 2010 XAMonline, Inc. All rights reserved. No part of the material protected by this copyright notice may be reproduced or utilized in any form or by
Diagnostic Test Middle School Mathematics Copyright 2010 XAMonline, Inc. All rights reserved. No part of the material protected by this copyright notice may be reproduced or utilized in any form or by
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
AUTOMATED FABRIC DEFECT INSPECTION: A SURVEY OF CLASSIFIERS
 AUTOMATED FABRIC DEFECT INSPECTION: A SURVEY OF CLASSIFIERS Md. Tarek Habib 1, Rahat Hossain Faisal 2, M. Rokonuzzaman 3, Farruk Ahmed 4 1 Department of Computer Science and Engineering, Prime University,
AUTOMATED FABRIC DEFECT INSPECTION: A SURVEY OF CLASSIFIERS Md. Tarek Habib 1, Rahat Hossain Faisal 2, M. Rokonuzzaman 3, Farruk Ahmed 4 1 Department of Computer Science and Engineering, Prime University,
The Use of Inflectional Morphemes by Kuwaiti EFL Learners
 English Language and Literature Studies; Vol. 6, No. 3; 2016 ISSN 1925-4768 E-ISSN 1925-4776 Published by Canadian Center of Science and Education The Use of Inflectional Morphemes by Kuwaiti EFL Learners
English Language and Literature Studies; Vol. 6, No. 3; 2016 ISSN 1925-4768 E-ISSN 1925-4776 Published by Canadian Center of Science and Education The Use of Inflectional Morphemes by Kuwaiti EFL Learners
A Corpus and Phonetic Dictionary for Tunisian Arabic Speech Recognition
 A Corpus and Phonetic Dictionary for Tunisian Arabic Speech Recognition Abir Masmoudi 1,2, Mariem Ellouze Khemakhem 1,Yannick Estève 2, Lamia Hadrich Belguith 1 and Nizar Habash 3 (1) ANLP Research group,
A Corpus and Phonetic Dictionary for Tunisian Arabic Speech Recognition Abir Masmoudi 1,2, Mariem Ellouze Khemakhem 1,Yannick Estève 2, Lamia Hadrich Belguith 1 and Nizar Habash 3 (1) ANLP Research group,
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS
 COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Mining Association Rules in Student s Assessment Data
 www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
A Note on Structuring Employability Skills for Accounting Students
 A Note on Structuring Employability Skills for Accounting Students Jon Warwick and Anna Howard School of Business, London South Bank University Correspondence Address Jon Warwick, School of Business, London
A Note on Structuring Employability Skills for Accounting Students Jon Warwick and Anna Howard School of Business, London South Bank University Correspondence Address Jon Warwick, School of Business, London
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Automating the E-learning Personalization
 Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Chamilo 2.0: A Second Generation Open Source E-learning and Collaboration Platform
 Chamilo 2.0: A Second Generation Open Source E-learning and Collaboration Platform doi:10.3991/ijac.v3i3.1364 Jean-Marie Maes University College Ghent, Ghent, Belgium Abstract Dokeos used to be one of
Chamilo 2.0: A Second Generation Open Source E-learning and Collaboration Platform doi:10.3991/ijac.v3i3.1364 Jean-Marie Maes University College Ghent, Ghent, Belgium Abstract Dokeos used to be one of
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
Primary National Curriculum Alignment for Wales
 Mathletics and the Welsh Curriculum This alignment document lists all Mathletics curriculum activities associated with each Wales course, and demonstrates how these fit within the National Curriculum Programme
Mathletics and the Welsh Curriculum This alignment document lists all Mathletics curriculum activities associated with each Wales course, and demonstrates how these fit within the National Curriculum Programme
SIX DISCOURSE MARKERS IN TUNISIAN ARABIC: A SYNTACTIC AND PRAGMATIC ANALYSIS. Chris Adams Bachelor of Arts, Asbury College, May 2006
 SIX DISCOURSE MARKERS IN TUNISIAN ARABIC: A SYNTACTIC AND PRAGMATIC ANALYSIS by Chris Adams Bachelor of Arts, Asbury College, May 2006 A Thesis Submitted to the Graduate Faculty of the University of North
SIX DISCOURSE MARKERS IN TUNISIAN ARABIC: A SYNTACTIC AND PRAGMATIC ANALYSIS by Chris Adams Bachelor of Arts, Asbury College, May 2006 A Thesis Submitted to the Graduate Faculty of the University of North
Standards for Members of the American Handwriting Analysis Foundation
 Standards for Members of the American Handwriting Analysis Foundation A. Purpose The purpose of this document is to provide a foundation for the development and evaluation of a set of standards for education,
Standards for Members of the American Handwriting Analysis Foundation A. Purpose The purpose of this document is to provide a foundation for the development and evaluation of a set of standards for education,
Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming
 Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
PROJECT MANAGEMENT AND COMMUNICATION SKILLS DEVELOPMENT STUDENTS PERCEPTION ON THEIR LEARNING
 PROJECT MANAGEMENT AND COMMUNICATION SKILLS DEVELOPMENT STUDENTS PERCEPTION ON THEIR LEARNING Mirka Kans Department of Mechanical Engineering, Linnaeus University, Sweden ABSTRACT In this paper we investigate
PROJECT MANAGEMENT AND COMMUNICATION SKILLS DEVELOPMENT STUDENTS PERCEPTION ON THEIR LEARNING Mirka Kans Department of Mechanical Engineering, Linnaeus University, Sweden ABSTRACT In this paper we investigate
2 nd grade Task 5 Half and Half
 2 nd grade Task 5 Half and Half Student Task Core Idea Number Properties Core Idea 4 Geometry and Measurement Draw and represent halves of geometric shapes. Describe how to know when a shape will show
2 nd grade Task 5 Half and Half Student Task Core Idea Number Properties Core Idea 4 Geometry and Measurement Draw and represent halves of geometric shapes. Describe how to know when a shape will show
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach
 Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
Digital Fabrication and Aunt Sarah: Enabling Quadratic Explorations via Technology. Michael L. Connell University of Houston - Downtown
 Digital Fabrication and Aunt Sarah: Enabling Quadratic Explorations via Technology Michael L. Connell University of Houston - Downtown Sergei Abramovich State University of New York at Potsdam Introduction
Digital Fabrication and Aunt Sarah: Enabling Quadratic Explorations via Technology Michael L. Connell University of Houston - Downtown Sergei Abramovich State University of New York at Potsdam Introduction
What s in a Step? Toward General, Abstract Representations of Tutoring System Log Data
 What s in a Step? Toward General, Abstract Representations of Tutoring System Log Data Kurt VanLehn 1, Kenneth R. Koedinger 2, Alida Skogsholm 2, Adaeze Nwaigwe 2, Robert G.M. Hausmann 1, Anders Weinstein
What s in a Step? Toward General, Abstract Representations of Tutoring System Log Data Kurt VanLehn 1, Kenneth R. Koedinger 2, Alida Skogsholm 2, Adaeze Nwaigwe 2, Robert G.M. Hausmann 1, Anders Weinstein
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Math 96: Intermediate Algebra in Context
 : Intermediate Algebra in Context Syllabus Spring Quarter 2016 Daily, 9:20 10:30am Instructor: Lauri Lindberg Office Hours@ tutoring: Tutoring Center (CAS-504) 8 9am & 1 2pm daily STEM (Math) Center (RAI-338)
: Intermediate Algebra in Context Syllabus Spring Quarter 2016 Daily, 9:20 10:30am Instructor: Lauri Lindberg Office Hours@ tutoring: Tutoring Center (CAS-504) 8 9am & 1 2pm daily STEM (Math) Center (RAI-338)
PENGUASAAN PELAJAR STAM TERHADAP IMBUHAN KATA BAHASA ARAB
 PENGUASAAN PELAJAR STAM TERHADAP IMBUHAN KATA BAHASA ARAB MUHAMAD FAHMI BIN ABD JALIL DISERTASI DISERAHKAN UNTUK MEMENUHI KEPERLUAN BAGI IJAZAH SARJANA PENGAJIAN BAHASA MODEN FAKULTI BAHASA DAN LINGUISTIK
PENGUASAAN PELAJAR STAM TERHADAP IMBUHAN KATA BAHASA ARAB MUHAMAD FAHMI BIN ABD JALIL DISERTASI DISERAHKAN UNTUK MEMENUHI KEPERLUAN BAGI IJAZAH SARJANA PENGAJIAN BAHASA MODEN FAKULTI BAHASA DAN LINGUISTIK