Audible and visible speech
|
|
|
- Shawn Norman
- 6 years ago
- Views:
Transcription
1 Building sensori-motor prototypes from audiovisual exemplars Gérard BAILLY Institut de la Communication Parlée INPG & Université Stendhal 46, avenue Félix Viallet, 383 Grenoble Cedex, France web: bailly@icp.grenet.fr Abstract This paper shows how an articulatory model, able to produce acoustic signals from articulatory motion, can learn to speak, i.e. coordinate its movements in such a way that it utters meaningful sequences of sounds belonging to a given language. This complex learning procedure is accomplished in four major steps: (a) a babbling phase, where the device builds up a model of the forward transforms, i.e. the articulatory-to-audiovisual mapping; (b) an imitation stage, where it tries to reproduce a limited set of sound sequences produced by a distal teacher; (c) a shaping stage, where phonemes are associated with the most ecient sensorimotor representation; and nally, (d) a rhythmic phase, where it learns the appropriate coordination of the activations of these sensori-motor targets. Linguistic description Planning Distal score Execution Proximal trajectories Plant Audible and visible speech Figure : General framework for articulatory control.. Introduction The generation of synthetic speech from articulatory movements faces two main challenges: (a) the classical problem of the generation of a continuous ow of command parameters from a discrete sequence of symbols and (b) the adequate use of the degrees of freedom in excess of the articulatory-toacoustic transform. An ecient solution is to separate planning from execution (cf. Fig. ): the planning parametrises the linguistic task in adequate representation spaces whereas the execution converts these distal specications into actual commands for the articulatory synthesiser. Concurrent to the Task Dynamics approach [3], where distal objects of speech production are supposed to be constrictions in the vocal tract, our current approach make use of those distal representation spaces best adapted to the sound to be uttered: exteroceptive, haptic or proprioceptive information are collected in course of the movement so as that the planning process could make use of the most appropriate feedbacks.. Emergence of representations.. The control model The control model used here has been developed within the Speech Maps project []. The so-called articulotron is based on the following principles: a positional coding of targets: each sensori-motor region associated with a percept is modelled as an attractor which generates in all speech representation spaces a force eld which attracts the current frame towards that region. a back-projection of these force elds to the motor space of the plant: the controller implements a pseudoinversion of all proximal-to-distal Jacobians. a composite and superpositional control: each sensorimotor target has an emergence function which can overlap those of adjacent targets. Force elds generated in each representation space are thus weighted and added, then back-projected. These motor force elds are then combined and integrated to determine the actual articulatory movement. When computed in dierent representation spaces, backprojected elds may contradict each other. The strategy for resolution of conicts is essential in motor control and we describe in section 5 our current strategy. 3. Audiovisual inversion The simplest way to give our speech robot, the articolotron, the gift of speech is to imitate an audiovisual speech synthesizer via a global inversion. The audiovisual characterisation is delivered by an audiovisual perceptron. This perceptron may deliver a continuous distal specication as in [3] or sample these audiovisual specications at salient events as proposed by []. We adopted the distal-to-proximal inversion proposed by Jordan [] where the inverse Jacobian of the forward - This work was supported by EC ESPRIT/BR n o 6975 cspeech Maps
2 Vfbac.cda avec CDA..:R4; = 96.5% Vfbgeo.cda avec CDA..:R4; = 86.54% Vfbart.cda avec CDA..:R4; = 94.3% (a) ten vowels Cfbac.cda avec CDA..:R4; = 96.5% Cfbgeo.cda avec CDA..:R4; = 98.7% Cfbart.cda avec CDA..:R4; = % (b) three occlusives Figure : The two rst discriminant spaces. From left to right: acoustic, geometric and articulatory spaces. articulatory-to-audiovisual transform - is used to convert the distal gradient into a proximal one. The proximal gradient is augmented by a smoothness criterion with a forgetting factor. This smoothness favours solutions which minimise jerk. Thus starting from an initial articulaory conguration, articulatory movements progressively converge towards gestures producing the appropriate exteroceptive information with minimal jerk. 3.. The plant - proximal parameters The plant has been elaborated using a database of 6 X- rays obtained from a reference subject []. Eight degrees-offreedom [8] will be used here. The model intrinsically couples jaw rotation and translation, controls upper and lower lip relative position and protrusion, controls larynx and velum position and has four degrees-of-freedom for the tongue midsagittal section. 3.. Distal characterisation The perceptron delivers here continuous formant and lip area trajectories of the sounds emitted by some distal teacher. In the following, the distal teacher is the same subject who was X-rayed to build the articulatory model. This avoids normalisation procedures which are beyond the scope of this paper Forward modelling The forward proximal-to-distal transform is learned in the babbling phase. This many-to-one transform from eight articulatory parameters to the rst four formants and area of the lips is modelled by a polynomial interpolator. The four formants were estimated from the area functions delivered by the plant using []. The order for each interpolator was set experimentally to 4. The interpolator was initially estimated using the set of 6 congurations of the X-ray database augmented by a random generation of the articulatory parameters. The actual database has 7368 frames The corpus Our French speaker pronounced two sets of V CV where C is a voiced plosive: (a) with a symmetric context (V =V ) with the ten French vowels and (b) an asymmetric context where V and V are one of the extreme vowels /a,i,u,y/. The set of audiovisual stimuli which will enable our control model to build internal representation of speech sounds consists thus of 78 stimuli, comprising 78 exemplars of voiced plosives and 56 vowels Distal-to-proximal inversion The inversion procedure is done for the whole set of speech items described above. Inversion results have been assessed in two cases: (a) a static case where prototypic articulatory vocalic congurations obtained by a gradient descent towards speaker-specic prototypic acoustic congurations are compared with both the articulatory targets extracted from the X-ray database and well-known structural constraints [7]; (b) kinematic inversion where results on the inversion of VCV sequences are compared with the X-ray data at well-dened time landmarks. The results published in [7, 5, 3] show that such simple global optimisation techniques are able to recover accurate and reliable articulatory movements. 4. Building sensori-motor spaces Once inversion of the whole set of items has been successfully performed, the imitation stage is achieved. The sensorimotor representations obtained by inversion were augmented
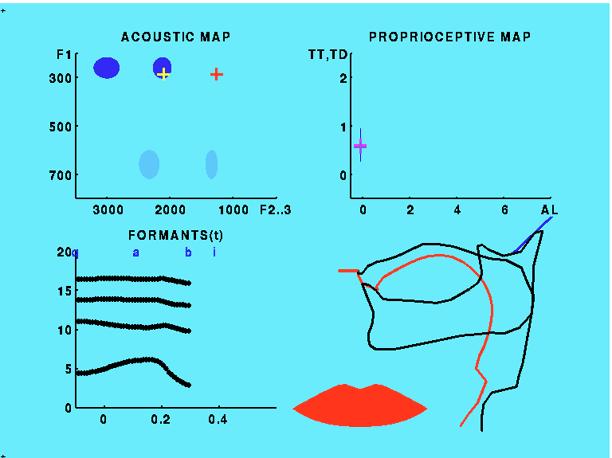
3 with VCV sequences from the original X-ray database, i.e. 78 vowels and 8 occlusives. The so-called Articulotron is supposed to have now sucient sensori-motor representations of context-dependent exemplars of the sounds. These internal representations are sampled at the temporal landmarks delivered by the Perceptron. We selected two landmarks: vocalic targets dened as points of maximum spectral stability consonantal targets dened as points of maximal occlusion 4.. Characterising targets Targets are dened as compact regions of the sensori-motor space. We supposed that separate control channels for different classes of sounds are built: here two channels, one for the vowels and one for the voiced plosives. On these control channels, phonemic targets have been implemented as simple Gaussians: the force eld is created by the derivative of the probability function (see section 5). A simple Gaussian has the advantage of generating a simple force eld with no singularities and builds up intrinsically a compacity constraint. The sensori-motor space is divided into three sub-spaces: The articulatory space consisting of 8 articulators A geometric space consisting of 5 parameters: the area of the lips (Al), the area (Ac) and location (Xc) of the main constriction and two mid-sagittal distances: the minimum distances of the tongue tip (TT) and tongue dorsum (TD) to the palate. These two latter parameters are similar to those used in [3]. An acoustic space consisting of the rst three formants. 4.. Sensori-motor sub-spaces A Canonical Discriminant Analysis was performed and the vocalic and consonantal targets were projected on the rst discriminant planes (see Fig. ). Vowels The examination of the structure of the projections and of the identication scores demonstrates that vowels are best dened in acoustic terms. Some additional arguments may be given in favour of an acoustic control of vocalic trajectories: The most successful procedure for predicting vocalic systems [9] uses a basic criterion of maximal acoustic dispersion of vocalic targets. Although a perceptual weighting of the solutions improves the prediction of the most frequent systems up to 9 vowels, articulatory or geometric data only shape and weights the dimensions of the maximal space. Recent perturbation experiments show that speakers tend to reach the same perceptual/acoustic goals with articulatory strategies that greatly dier from the unperturbed case [4]. Vocalic trajectories tend to be linear in the acoustic space when it is re-analysed in terms of resonances [4]. Occlusives On the other hand, the voiced occlusives are best dened in terms of place of articulation. When the acoustic information is sampled at the vocalic onset as proposed by [5], the identication score is just above chance while the geometric score still rates 97%. Of course, the paradigm of relational invariance may hold but a contextindependent target is no longer available. khz act/barks q 5 5 i u y i y u 3 [f vs f,f3] for vowels e x o e x o q q E X O a E khz X a activations/formants O....3 s u cm std.5.5 [al versus dtt,dtd] for occlusives b d g d g 4 6 cm articulators....3 s Figure 3: A simple modulation of the acoustic force-eld generating [u] from the neutral posture. From left to right, top: F/F3 versus F and TT/TD versus Al. Note the quasilinear3 trajectory in the F/F plane. Bottom: Resulting formant trajectories (thick lines in a Bark scale) superposed with emergence functions (thin lines) and resulting articulatory gesture. Here tongue dorsum and jaw raise whereas tongue tip lowers and lips close. The tongue body is pulled back. 5. Voluntary motion by modulating force elds Once sensori-motor representations of sound targets have been built, we have to verify that sound sequences can effectively be generated using a composite and superpositional control of attractor elds. 5.. Vowels First, wehavetoverify that vocalic sounds may be produced and chained adequately and that force elds generated in a structured acoustic space still pull articulatory gestures towards prototypical articulatory targets. The movement equation is: a A =! A:pinv(J a!a): A, where A!! and a! A are respectively the resulting driving acoustic force and the back-propagated articulatory velocity. The driving force equals the sum of the gradients of the probability function for each vowelvweighted by its emergence k V (t). Each probability function is dened by its mean mean! V and covariance matrix cov V. Only the acoustic characteristics of the vocalic targets [] A are considered as follows:! A! ( A(t) = P V kv (t) cov V dtt dtd! [mean V ] A A(t)); whith td tb jh tt lh
4 P V kv (t) =. Fig. 3 shows the acoustic, geometric and articulatory trajectories produced by modulating the force eld from the neutral attractor towards the /u/ vowel. khz act/barks i u y i y u 3 [f vs f,f3] for vowels e x o e x o q q E X O a E khz X a activations/formants q a b a..4 s O cm std.5.5 [al versus dtt,dtd] for occlusives b d g d g 4 6 cm articulators..4 s Figure 4: Starting from the neutral posture the acoustic force-eld generating [a] is perturbed by the [b] geometric attractor characterised by rst principal axis at A l =. 5.. Occlusives dtt dtd jh lh tb tt td We have shown above how articulation may be driven by a back-propagated modulation of an acoustic eld. We suppose here that this carrier acoustic gesture is primarily modulated by vocalic targets whose emergence functions are characterised by slow and overlapping transition functions whose sum equal to one. We have shown that this carrier gesture may react to unexpected articulatory perturbations [6]. Occlusives may be seen as voluntary perturbations (see Fig. 4): the geometric trajectory deviates from the one produced by the acoustic driving eld because of emergence of plosivespecic geometric attractors. 6. Conclusions We described here a strategy for giving an articulatory model the gift of speech i.e. a learning paradigm that will enrich its internal representations from experience. These internal sensori-motor representation are emergent because they are by-products of a rst global audiovisual-to-articulatory inversion. Thanks an appropriate selective use of these representations the controller produces skilled actions and reacts to unexpected perturbations. Consonants may be seen as planned perturbations. We have to extend this paradigm to other consonants than those studied here. The next step is the learning and control of timing: how temporal relationship can be implemented both in terms of sequential and dynamic constraints and phasing between articulation and phonation can be handled. 7. references. Badin, P. and Fant, G. Notes on vocal tract computations. STL-QPSR /3, 538, Badin, P., Gabioud, B., Beautemps, D., Lallouache, T., Bailly, G., Maeda, S., Zerling, J.P., and Brock, G. Cineradiography of vcv sequences: articulatory-acoustic data for a speech production model. In International Congress on Acoustics, pages 34935, Trondheim - Norway, Badin, P., Mawass, K., Bailly, G., Vescovi, C., Beautemps, D., and Pelorson, X. Articulatory synthesis of fricative consonants : data and models. In ETRW on Speech Production, pages 4, Autrans - France, Bailly, G. Caracterisation of formant trajectories by tracking vocal tract resonances. In Sorin, C., Mariani, J., Méloni, H., and Schoentgen, J., editors, Levels in speech communication :relations and interactions, pages 9. Elsevier, Amsterdam, Bailly, G. Recovering place of articulation for occlusives in vcvs. In International Congress of Phonetic Sciences, volume, pages 333, Stockholm, Sweden, Bailly, G. Sensori-motor control of speech movements. In ETRW on Speech Production Modelling, Autrans, Bailly, G., Boë, L.J., Vallée, N., and Badin, P. Articulatoriacoustic prototypes for speech production. In Proceedings of the European Conference on Speech Communication and Technology, volume, pages 9396, Madrid, Beautemps, D., Badin, P., Bailly, G., Galvàn, A., and Laboissière, R. Evaluation of an articulatory-acoustic model based on a refrence subject. In ETRW on Speech Production, pages 4548, Autrans - France, Boë, L.J., Schwartz, J.L., and Vallée, N. The prediction of vowel systems: perceptual contrast and stability. In Keller, E., editor, Fundamentals of speech synthesis and speech recognition, pages 854. John Wiley and Sons, Chichester, Honda, M. and Kaburagi, T. A dynamical articulatory model using potential task representation. In International Conference on Speech and Language Processing, volume, pages 7984, Yokohama, Japan, Jordan, M.I. Supervised learning and systems with excess degrees of freedom. COINS Tech. Rep. 88-7, University of Massachussetts, Computer and Information Sciences, Amherst, MA, Morasso, P. and Sanguineti, V. Representation of space and time in motor control. In Bailly, G., editor, SPEECH MAPS - WP3: Dynamic constraints and motor controls, chapter Deliverable : Learning with the articulotron I, pages Institut de la Communication Parlée, Grenoble - France, Saltzman, E.L. and Munhall, K.G. A dynamical approach to gestural patterning in speech production. Ecological Psychology, (4):6563, Savariaux, C., Perrier, P., and Orliaguet, J.P. Compensation strategies for the perturbation of the rounded vowel [u] using a lip-tube: A study of the control space in speech production. Journal of the Acoustical Society of America, 5:4844, Sussman, H.M., McCarey, H.A., and Matthews, S.A. An investigation of locus equations as a source of relational invariance for stop place categorization. Journal of the Acoustical Society of America, 9(3):3935, 99.
5
6
7
8
9 Sound File References: [qaba.wav] [qabi.wav] [qada.wav] [qaga.wav]
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Quarterly Progress and Status Report. VCV-sequencies in a preliminary text-to-speech system for female speech
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Phonetics. The Sound of Language
 Phonetics. The Sound of Language 1 The Description of Sounds Fromkin & Rodman: An Introduction to Language. Fort Worth etc., Harcourt Brace Jovanovich Read: Chapter 5, (p. 176ff.) (or the corresponding
Phonetics. The Sound of Language 1 The Description of Sounds Fromkin & Rodman: An Introduction to Language. Fort Worth etc., Harcourt Brace Jovanovich Read: Chapter 5, (p. 176ff.) (or the corresponding
Christine Mooshammer, IPDS Kiel, Philip Hoole, IPSK München, Anja Geumann, Dublin
 1 Title: Jaw and order Christine Mooshammer, IPDS Kiel, Philip Hoole, IPSK München, Anja Geumann, Dublin Short title: Production of coronal consonants Acknowledgements This work was partially supported
1 Title: Jaw and order Christine Mooshammer, IPDS Kiel, Philip Hoole, IPSK München, Anja Geumann, Dublin Short title: Production of coronal consonants Acknowledgements This work was partially supported
Speaking Rate and Speech Movement Velocity Profiles
 Journal of Speech and Hearing Research, Volume 36, 41-54, February 1993 Speaking Rate and Speech Movement Velocity Profiles Scott G. Adams The Toronto Hospital Toronto, Ontario, Canada Gary Weismer Raymond
Journal of Speech and Hearing Research, Volume 36, 41-54, February 1993 Speaking Rate and Speech Movement Velocity Profiles Scott G. Adams The Toronto Hospital Toronto, Ontario, Canada Gary Weismer Raymond
DEVELOPMENT OF LINGUAL MOTOR CONTROL IN CHILDREN AND ADOLESCENTS
 DEVELOPMENT OF LINGUAL MOTOR CONTROL IN CHILDREN AND ADOLESCENTS Natalia Zharkova 1, William J. Hardcastle 1, Fiona E. Gibbon 2 & Robin J. Lickley 1 1 CASL Research Centre, Queen Margaret University, Edinburgh
DEVELOPMENT OF LINGUAL MOTOR CONTROL IN CHILDREN AND ADOLESCENTS Natalia Zharkova 1, William J. Hardcastle 1, Fiona E. Gibbon 2 & Robin J. Lickley 1 1 CASL Research Centre, Queen Margaret University, Edinburgh
Universal contrastive analysis as a learning principle in CAPT
 Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Consonants: articulation and transcription
 Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Quarterly Progress and Status Report. Voiced-voiceless distinction in alaryngeal speech - acoustic and articula
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION. Adam B. Buchwald
 SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION by Adam B. Buchwald A dissertation submitted to The Johns Hopkins University in conformity with the requirements
SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION by Adam B. Buchwald A dissertation submitted to The Johns Hopkins University in conformity with the requirements
Quarterly Progress and Status Report. Sound symbolism in deictic words
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Sound symbolism in deictic words Traunmüller, H. journal: TMH-QPSR volume: 37 number: 2 year: 1996 pages: 147-150 http://www.speech.kth.se/qpsr
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Sound symbolism in deictic words Traunmüller, H. journal: TMH-QPSR volume: 37 number: 2 year: 1996 pages: 147-150 http://www.speech.kth.se/qpsr
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Edinburgh Research Explorer
 Edinburgh Research Explorer The magnetic resonance imaging subset of the mngu0 articulatory corpus Citation for published version: Steiner, I, Richmond, K, Marshall, I & Gray, C 2012, 'The magnetic resonance
Edinburgh Research Explorer The magnetic resonance imaging subset of the mngu0 articulatory corpus Citation for published version: Steiner, I, Richmond, K, Marshall, I & Gray, C 2012, 'The magnetic resonance
age, Speech and Hearii
 age, Speech and Hearii 1 Speech Commun cation tion 2 Sensory Comm, ection i 298 RLE Progress Report Number 132 Section 1 Speech Communication Chapter 1 Speech Communication 299 300 RLE Progress Report
age, Speech and Hearii 1 Speech Commun cation tion 2 Sensory Comm, ection i 298 RLE Progress Report Number 132 Section 1 Speech Communication Chapter 1 Speech Communication 299 300 RLE Progress Report
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
On Developing Acoustic Models Using HTK. M.A. Spaans BSc.
 On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
 " 'rear,.': T OOM 36-41L v CHU
" 'rear,.': T OOM 36-41L v CHU Dyslexia/dyslexic, 3, 9, 24, 97, 187, 189, 206, 217, , , 367, , , 397,
 Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Phonological and Phonetic Representations: The Case of Neutralization
 Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
Perceptual scaling of voice identity: common dimensions for different vowels and speakers
 DOI 10.1007/s00426-008-0185-z ORIGINAL ARTICLE Perceptual scaling of voice identity: common dimensions for different vowels and speakers Oliver Baumann Æ Pascal Belin Received: 15 February 2008 / Accepted:
DOI 10.1007/s00426-008-0185-z ORIGINAL ARTICLE Perceptual scaling of voice identity: common dimensions for different vowels and speakers Oliver Baumann Æ Pascal Belin Received: 15 February 2008 / Accepted:
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Expressive speech synthesis: a review
 Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Human Factors Engineering Design and Evaluation Checklist
 Revised April 9, 2007 Human Factors Engineering Design and Evaluation Checklist Design of: Evaluation of: Human Factors Engineer: Date: Revised April 9, 2007 Created by Jon Mast 2 Notes: This checklist
Revised April 9, 2007 Human Factors Engineering Design and Evaluation Checklist Design of: Evaluation of: Human Factors Engineer: Date: Revised April 9, 2007 Created by Jon Mast 2 Notes: This checklist
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
A comparison of spectral smoothing methods for segment concatenation based speech synthesis
 D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
One major theoretical issue of interest in both developing and
 Developmental Changes in the Effects of Utterance Length and Complexity on Speech Movement Variability Neeraja Sadagopan Anne Smith Purdue University, West Lafayette, IN Purpose: The authors examined the
Developmental Changes in the Effects of Utterance Length and Complexity on Speech Movement Variability Neeraja Sadagopan Anne Smith Purdue University, West Lafayette, IN Purpose: The authors examined the
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Beginning primarily with the investigations of Zimmermann (1980a),
,") Orofacial Movements Associated With Fluent Speech in Persons Who Stutter Michael D. McClean Walter Reed Army Medical Center, Washington, D.C. Stephen M. Tasko Western Michigan University, Kalamazoo, MI
Orofacial Movements Associated With Fluent Speech in Persons Who Stutter Michael D. McClean Walter Reed Army Medical Center, Washington, D.C. Stephen M. Tasko Western Michigan University, Kalamazoo, MI
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
NIH Public Access Author Manuscript Lang Speech. Author manuscript; available in PMC 2011 January 1.
 NIH Public Access Author Manuscript Published in final edited form as: Lang Speech. 2010 ; 53(Pt 1): 49 69. Spatial and Temporal Properties of Gestures in North American English /R/ Fiona Campbell, University
NIH Public Access Author Manuscript Published in final edited form as: Lang Speech. 2010 ; 53(Pt 1): 49 69. Spatial and Temporal Properties of Gestures in North American English /R/ Fiona Campbell, University
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Speech/Language Pathology Plan of Treatment
 Caring for Your Quality of Life Patient s Last Name First Name MI HICN Speech/Language Pathology Plan of Treatment Provider Name LifeCare of Florida Primary Diagnosis(es) Provider No Onset Date SOC Date
Caring for Your Quality of Life Patient s Last Name First Name MI HICN Speech/Language Pathology Plan of Treatment Provider Name LifeCare of Florida Primary Diagnosis(es) Provider No Onset Date SOC Date
Complexity in Second Language Phonology Acquisition
 Complexity in Second Language Phonology Acquisition Complexidade na aquisição da fonologia de segunda língua Ronaldo Mangueira Lima Júnior* Universidade de Brasília (UnB) Brasília/DF Brasil ABSTRACT: This
Complexity in Second Language Phonology Acquisition Complexidade na aquisição da fonologia de segunda língua Ronaldo Mangueira Lima Júnior* Universidade de Brasília (UnB) Brasília/DF Brasil ABSTRACT: This
Given a directed graph G =(N A), where N is a set of m nodes and A. destination node, implying a direction for ow to follow. Arcs have limitations
, where N is a set of m nodes and A. destination node, implying a direction for ow to follow. Arcs have limitations") 4 Interior point algorithms for network ow problems Mauricio G.C. Resende AT&T Bell Laboratories, Murray Hill, NJ 07974-2070 USA Panos M. Pardalos The University of Florida, Gainesville, FL 32611-6595
4 Interior point algorithms for network ow problems Mauricio G.C. Resende AT&T Bell Laboratories, Murray Hill, NJ 07974-2070 USA Panos M. Pardalos The University of Florida, Gainesville, FL 32611-6595
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Rhythm-typology revisited.
 DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
COMPUTER-AIDED DESIGN TOOLS THAT ADAPT
 COMPUTER-AIDED DESIGN TOOLS THAT ADAPT WEI PENG CSIRO ICT Centre, Australia and JOHN S GERO Krasnow Institute for Advanced Study, USA 1. Introduction Abstract. This paper describes an approach that enables
COMPUTER-AIDED DESIGN TOOLS THAT ADAPT WEI PENG CSIRO ICT Centre, Australia and JOHN S GERO Krasnow Institute for Advanced Study, USA 1. Introduction Abstract. This paper describes an approach that enables
Voice conversion through vector quantization
 J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
THE MULTIVOC TEXT-TO-SPEECH SYSTEM
 THE MULTVOC TEXT-TO-SPEECH SYSTEM Olivier M. Emorine and Pierre M. Martin Cap Sogeti nnovation Grenoble Research Center Avenue du Vieux Chene, ZRST 38240 Meylan, FRANCE ABSTRACT n this paper we introduce
THE MULTVOC TEXT-TO-SPEECH SYSTEM Olivier M. Emorine and Pierre M. Martin Cap Sogeti nnovation Grenoble Research Center Avenue du Vieux Chene, ZRST 38240 Meylan, FRANCE ABSTRACT n this paper we introduce
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
arxiv: v2 [cs.ro] 3 Mar 2017
![arxiv: v2 [cs.ro] 3 Mar 2017](/thumbs/71/66179626.jpg "arxiv: v2 [cs.ro] 3 Mar 2017") Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Pobrane z czasopisma New Horizons in English Studies Data: 18/11/ :52:20. New Horizons in English Studies 1/2016
 LANGUAGE Maria Curie-Skłodowska University () in Lublin k.laidler.umcs@gmail.com Online Adaptation of Word-initial Ukrainian CC Consonant Clusters by Native Speakers of English Abstract. The phenomenon
LANGUAGE Maria Curie-Skłodowska University () in Lublin k.laidler.umcs@gmail.com Online Adaptation of Word-initial Ukrainian CC Consonant Clusters by Native Speakers of English Abstract. The phenomenon
Perceived speech rate: the effects of. articulation rate and speaking style in spontaneous speech. Jacques Koreman. Saarland University
 1 Perceived speech rate: the effects of articulation rate and speaking style in spontaneous speech Jacques Koreman Saarland University Institute of Phonetics P.O. Box 151150 D-66041 Saarbrücken Germany
1 Perceived speech rate: the effects of articulation rate and speaking style in spontaneous speech Jacques Koreman Saarland University Institute of Phonetics P.O. Box 151150 D-66041 Saarbrücken Germany
phone hidden time phone
 MODULARITY IN A CONNECTIONIST MODEL OF MORPHOLOGY ACQUISITION Michael Gasser Departments of Computer Science and Linguistics Indiana University Abstract This paper describes a modular connectionist model
MODULARITY IN A CONNECTIONIST MODEL OF MORPHOLOGY ACQUISITION Michael Gasser Departments of Computer Science and Linguistics Indiana University Abstract This paper describes a modular connectionist model
Radical CV Phonology: the locational gesture *
 Radical CV Phonology: the locational gesture * HARRY VAN DER HULST 1 Goals 'Radical CV Phonology' is a variant of Dependency Phonology (Anderson and Jones 1974, Anderson & Ewen 1980, Ewen 1980, Lass 1984,
Radical CV Phonology: the locational gesture * HARRY VAN DER HULST 1 Goals 'Radical CV Phonology' is a variant of Dependency Phonology (Anderson and Jones 1974, Anderson & Ewen 1980, Ewen 1980, Lass 1984,
Articulatory Distinctiveness of Vowels and Consonants: A Data-Driven Approach
 JSLHR Article Articulatory Distinctiveness of Vowels and Consonants: A Data-Driven Approach Jun Wang, a,b Jordan R. Green, a,b Ashok Samal, a and Yana Yunusova c Purpose: To quantify the articulatory distinctiveness
JSLHR Article Articulatory Distinctiveness of Vowels and Consonants: A Data-Driven Approach Jun Wang, a,b Jordan R. Green, a,b Ashok Samal, a and Yana Yunusova c Purpose: To quantify the articulatory distinctiveness
VB-MAPP Guided Notes
 VB-MAPP Guided Notes The VB-MAPP The VB-MAPP is The Verbal Behavior Milestones Assessment and Placement Program. It provides a framework of developmental milestones that can help you stay on course with
VB-MAPP Guided Notes The VB-MAPP The VB-MAPP is The Verbal Behavior Milestones Assessment and Placement Program. It provides a framework of developmental milestones that can help you stay on course with
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Phonological encoding in speech production
 Phonological encoding in speech production Niels O. Schiller Department of Cognitive Neuroscience, Maastricht University, The Netherlands Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands
Phonological encoding in speech production Niels O. Schiller Department of Cognitive Neuroscience, Maastricht University, The Netherlands Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands
To appear in the Proceedings of the 35th Meetings of the Chicago Linguistics Society. Post-vocalic spirantization: Typology and phonetic motivations
 Post-vocalic spirantization: Typology and phonetic motivations Alan C-L Yu University of California, Berkeley 0. Introduction Spirantization involves a stop consonant becoming a weak fricative (e.g., B,
Post-vocalic spirantization: Typology and phonetic motivations Alan C-L Yu University of California, Berkeley 0. Introduction Spirantization involves a stop consonant becoming a weak fricative (e.g., B,
1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature
 August/September Strand Topic Standard Notes Reading for Literature") 1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Content Language Objectives (CLOs) August 2012, H. Butts & G. De Anda
 August 2012, H. Butts & G. De Anda") Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
Special Education Program Continuum
 Special Education Program Continuum 2014-2015 Summit Hill School District 161 maintains a full continuum of special education instructional programs, resource programs and related services options based
Special Education Program Continuum 2014-2015 Summit Hill School District 161 maintains a full continuum of special education instructional programs, resource programs and related services options based
Pp. 176{182 in Proceedings of The Second International Conference on Knowledge Discovery and Data Mining. Predictive Data Mining with Finite Mixtures
 Pp. 176{182 in Proceedings of The Second International Conference on Knowledge Discovery and Data Mining (Portland, OR, August 1996). Predictive Data Mining with Finite Mixtures Petri Kontkanen Petri Myllymaki
Pp. 176{182 in Proceedings of The Second International Conference on Knowledge Discovery and Data Mining (Portland, OR, August 1996). Predictive Data Mining with Finite Mixtures Petri Kontkanen Petri Myllymaki
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
A MULTI-AGENT SYSTEM FOR A DISTANCE SUPPORT IN EDUCATIONAL ROBOTICS
 A MULTI-AGENT SYSTEM FOR A DISTANCE SUPPORT IN EDUCATIONAL ROBOTICS Sébastien GEORGE Christophe DESPRES Laboratoire d Informatique de l Université du Maine Avenue René Laennec, 72085 Le Mans Cedex 9, France
A MULTI-AGENT SYSTEM FOR A DISTANCE SUPPORT IN EDUCATIONAL ROBOTICS Sébastien GEORGE Christophe DESPRES Laboratoire d Informatique de l Université du Maine Avenue René Laennec, 72085 Le Mans Cedex 9, France
Math Placement at Paci c Lutheran University
 Math Placement at Paci c Lutheran University The Art of Matching Students to Math Courses Professor Je Stuart Math Placement Director Paci c Lutheran University Tacoma, WA 98447 USA je rey.stuart@plu.edu
Math Placement at Paci c Lutheran University The Art of Matching Students to Math Courses Professor Je Stuart Math Placement Director Paci c Lutheran University Tacoma, WA 98447 USA je rey.stuart@plu.edu
A Bayesian Model of Imitation in Infants and Robots
 To appear in: Imitation and Social Learning in Robots, Humans, and Animals: Behavioural, Social and Communicative Dimensions, K. Dautenhahn and C. Nehaniv (eds.), Cambridge University Press, 2004. A Bayesian
To appear in: Imitation and Social Learning in Robots, Humans, and Animals: Behavioural, Social and Communicative Dimensions, K. Dautenhahn and C. Nehaniv (eds.), Cambridge University Press, 2004. A Bayesian
Lecture Notes in Artificial Intelligence 4343
 Lecture Notes in Artificial Intelligence 4343 Edited by J. G. Carbonell and J. Siekmann Subseries of Lecture Notes in Computer Science Christian Müller (Ed.) Speaker Classification I Fundamentals, Features,
Lecture Notes in Artificial Intelligence 4343 Edited by J. G. Carbonell and J. Siekmann Subseries of Lecture Notes in Computer Science Christian Müller (Ed.) Speaker Classification I Fundamentals, Features,
On Human Computer Interaction, HCI. Dr. Saif al Zahir Electrical and Computer Engineering Department UBC
 On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Individual Differences & Item Effects: How to test them, & how to test them well
 Individual Differences & Item Effects: How to test them, & how to test them well Individual Differences & Item Effects Properties of subjects Cognitive abilities (WM task scores, inhibition) Gender Age
Individual Differences & Item Effects: How to test them, & how to test them well Individual Differences & Item Effects Properties of subjects Cognitive abilities (WM task scores, inhibition) Gender Age
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
9 Sound recordings: acoustic and articulatory data
 9 Sound recordings: acoustic and articulatory data Robert J. Podesva and Elizabeth Zsiga 1 Introduction Linguists, across the subdisciplines of the field, use sound recordings for a great many purposes
9 Sound recordings: acoustic and articulatory data Robert J. Podesva and Elizabeth Zsiga 1 Introduction Linguists, across the subdisciplines of the field, use sound recordings for a great many purposes
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Hynninen and Zacharov; AES 106 th Convention - Munich 2 performing such tests on a regular basis, the manual preparation can become tiresome. Manual p
 GuineaPig A generic subjective test system for multichannel audio Jussi Hynninen Laboratory of Acoustics and Audio Signal Processing Helsinki University of Technology, Espoo, Finland hynde@acoustics.hut.fi
GuineaPig A generic subjective test system for multichannel audio Jussi Hynninen Laboratory of Acoustics and Audio Signal Processing Helsinki University of Technology, Espoo, Finland hynde@acoustics.hut.fi
The Effect of Discourse Markers on the Speaking Production of EFL Students. Iman Moradimanesh
 The Effect of Discourse Markers on the Speaking Production of EFL Students Iman Moradimanesh Abstract The research aimed at investigating the relationship between discourse markers (DMs) and a special
The Effect of Discourse Markers on the Speaking Production of EFL Students Iman Moradimanesh Abstract The research aimed at investigating the relationship between discourse markers (DMs) and a special
Integrating simulation into the engineering curriculum: a case study
 Integrating simulation into the engineering curriculum: a case study Baidurja Ray and Rajesh Bhaskaran Sibley School of Mechanical and Aerospace Engineering, Cornell University, Ithaca, New York, USA E-mail:
Integrating simulation into the engineering curriculum: a case study Baidurja Ray and Rajesh Bhaskaran Sibley School of Mechanical and Aerospace Engineering, Cornell University, Ithaca, New York, USA E-mail:
A Retrospective Study
 Evaluating Students' Course Evaluations: A Retrospective Study Antoine Al-Achi Robert Greenwood James Junker ABSTRACT. The purpose of this retrospective study was to investigate the influence of several
Evaluating Students' Course Evaluations: A Retrospective Study Antoine Al-Achi Robert Greenwood James Junker ABSTRACT. The purpose of this retrospective study was to investigate the influence of several
Evaluation of Various Methods to Calculate the EGG Contact Quotient
 Diploma Thesis in Music Acoustics (Examensarbete 20 p) Evaluation of Various Methods to Calculate the EGG Contact Quotient Christian Herbst Mozarteum, Salzburg, Austria Work carried out under the ERASMUS
Diploma Thesis in Music Acoustics (Examensarbete 20 p) Evaluation of Various Methods to Calculate the EGG Contact Quotient Christian Herbst Mozarteum, Salzburg, Austria Work carried out under the ERASMUS