Taxonomy-Regularized Semantic Deep Convolutional Neural Networks
|
|
|
- Abel Barber
- 6 years ago
- Views:
Transcription
1 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks Wonjoon Goo 1, Juyong Kim 1, Gunhee Kim 1, Sung Ju Hwang 2 1 Computer Science and Engineering, Seoul National University, Seoul, Korea 2 School of Electrical and Computer Engineering, UNIST, Ulsan, South Korea {wonjoon,gem0521,gunhee}@snu.ac.kr, sjhwang@unist.ac.kr Project page: Abstract. We propose a novel convolutional network architecture that abstracts and differentiates the categories based on a given class hierarchy. We exploit grouped and discriminative information provided by the taxonomy, by focusing on the general and specific components that comprise each category, through the min- and difference-pooling operations. Without using any additional parameters or substantial increase in time complexity, our model is able to learn the features that are discriminative for classifying often confused sub-classes belonging to the same superclass, and thus improve the overall classification performance. We validate our method on CIFAR-100, Places-205, and ImageNet Animal datasets, on which our model obtains significant improvements over the base convolutional networks. Keywords: deep learning, object categorization, taxonomy, ontology 1 Introduction Deep convolutional neural networks (CNNs) [12 14, 18] have received much attention in recent years, due to its success on object categorization and many other visual recognition tasks. They have achieved the state-of-the-art performances for challenging categorization datasets such as ImageNet [3], owing to their ability to learn compositional representations for the target tasks, through multiple levels of non-linear transformations. This multi-layer learning is biologically inspired by the human visual system that also processes the visual stimuli through a similar hierarchical cascade. However, while the deep CNNs closely resemble such low-level human visual processing systems, they pay less attention to the high-level reasoning employed for categorization. When performing categorization, humans do not treat each category as an independent entity that is different from everything else. Rather, they understand each object category in relation to others, performing generalization and specialization focusing on their commonalities and differences, either through observations or by the learned knowledge. For example, consider the images of animals at the bottom of Figure 1. Each image shows a different animal species (e.g. cheetah, jaguar, leopard). How can




2 2 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang Cheetah Jaguar Leopard Specialization difference-pooling Felid Base-level Categorization Cheetah Jaguar Leopard Generalization min-pooling Category-specific features Deep Convolutional Neural Network Test instance Training instances Fig. 1: Concept: Our taxonomy-regularized deep CNN learns grouped and discriminative features at multiple semantic levels, by introducing additional regularization layers that abstract and differentiate object categories based on a given class hierarchy. 1) At the generalization step, our network finds the commonalities between similar object categories that help recognize the supercategory, by finding the common components between per-category features. 2) At the specialization step, our network learns subcategory features as different as possible from the supercategory features, to discover unique features that help discriminate between sibling subcategories. These generalization and specialization layers work as regularizers that help the original network learn the features focusing on those commonalities and differences. we tell them apart? We first notice that all these three animals have distinctive feline features, and have spots (i.e. discovery of commonalities). Then, since those common properties are no longer useful to discriminate between the animals, we start focusing on the properties that are specific to each animal, which are disjoint from the common properties that are shared among all the three animals. For example, we notice that they have different shapes of spots, and the leftmost animal has a distinctive tear mark. This fine-grained discrimination is not directly achieved by the low-level visual processing, and requires deliberate observations and reasoning. How can we then construct a CNN such that it can mimic such high-level human reasoning process? Our idea is to implement the generalization/specialization process as additional regularization layers of the CNN, leveraging the class structure provided by a given taxonomy. Specifically, we add in multiple superclass layers on top of the CNN, which are implemented as channel-wise pooling layers that focus on the components shared by multiple sub-categories, which we refer to as min-pooling. After this generalization process, our network performs specialization for each subcategory through difference-pooling between it and its superclass. It enforces the network to learn unique discriminative features for each object category (See Figure 1). These two pooling layers can be readily integrated into any conventional CNN models, to function as regularizers. We validate our taxonomy-regularized CNN
3 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 3 on multiple datasets, including CIFAR-100 [11], Places-205 [25], and ImageNet Animal datasets [22], and obtain significant performance gain over the base CNN models such as AlexNet [12] and NIN [14]. Our contributions are threefold: 1. We show that exploiting grouped and discriminative information in a semantic taxonomy helps learn better features for CNN models. 2. We propose novel generalization and specialization layers implemented with min- and difference-pooling, which can be seamlessly integrated into any conventional CNN models. 3. We perform extensive quantitative and qualitative evaluation of our method, and show that the proposed regularization layers achieve significant classification improvement on multiple benchmark datasets such as CIFAR-100 [11], Places-205 [25], and ImageNet Animal datasets [22]. 2 Related Work Using semantic taxonomies for object categorization. Semantic taxonomies have been extensively explored for object categorization. Most existing work [1, 5, 15] exploits the tree structure for efficient branch-and-bound training and prediction, while a few use taxonomies as sources of relational knowledge between categories [24, 6, 9, 2]. Our method shares the same goal with the latter group of work, and especially focuses on the parent-child and sibling-sibling relations. Deep convolutional neural networks. Deep CNNs [13] have recently gained enormous popularity for their impressive performance on a number of visual recognition tasks. Since Krizhevsky et al. [12] won the ImageNet ILSVRC challenge 2012 [3], many variants of this model have been proposed. GoogLeNet [21], and VGGNet [18] focus on increasing the network depth by adding more convolutional layers to the original model. Lin et al. [14], propose a model structure called Network In Network (NIN) to train non-linear filters with micro neural networks in convolutional layers, and replace the fully connected layers by global average pooling on per-category feature maps. Our model benefits from these recent advances in deep CNNs, as it can leverage any one of these deep networks as the base model. Some existing work has explored the tree structure among tasks to regularize the learning of deep neural networks. Salakhutdinov et al. [17] propose to learn hierarchical Dirichlet process prior over the top-level features of a deep Boltzmann machine, which enables the model to generalize well even with few training examples. Srivastava and Salakhutdinov [19] further extend this idea to the discriminatively learned CNN, with both predefined and automaticallyconstructed tree hierarchies using Chinese Restaurant Process. However, these models only work as priors and do not exploit discriminative information in a class hierarchy that our model aims to learn. Recently, Yan et al. [23] propose a two-staged CNN architecture named HD-CNN, which leverages the taxonomy to separate the categories into easy coarse-grained ones and confusing fine-grained ones, trained in separate networks. However, such separate learning of coarse
4 4 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang and fine grained categories results in larger memory footprints, while our model seamlessly integrates the two with minimal increase in memory usage. The main novelties of our approach in this line of research are twofold. First, we propose a generic regularization layers that can be merged into any types of CNNs. Second and more importantly, we exploit the tree structure to learn discriminative properties not only between supercategories, but also between sibling subcategories belonging to the same parents. Discriminative feature learning by promoting competition. Some recent work in multitask learning focuses on promoting competitions among tasks to learn discriminative features per each task. Zhou et al. [27] introduce an exclusive lasso that regularizes the original least square objective with a l 2 -norm over l 1 -norm on parameters, which encourages competition for the features among different tasks. The orthogonal transfer proposed in [26] leverages the intuition that the classifiers in parent and child nodes of a taxonomy should be different, by minimizing the inner product of the parameters of a parent and a child classifier. A similar idea is explored in [7] in the context of metric learning, but the approach of [7] selects disjoint features instead of simply making the parameters to be different. This idea is further extended to the case of multiple taxonomies [8], where each taxonomy captures different sets of semantically discriminative features, which are combined in the multiple kernel learning framework. A recent work [9] also proposes a similar constraint, to relate the category embeddings learned for both the parent and child, and the sibling classes. Our idea shares a similar goal for learning unique and discriminative features for each class, but it is implemented with a much simpler means of pooling, which fits well into the CNN framework unlike all the other previous frameworks. 3 Architecture Our goal is to exploit the class hierarchy information to learn grouped and discriminative features of categories in a deep convolutional neural network (CNN). We tackle this problem by augmenting the base CNN architecture with two additional generalization and specialization layers, which regularize the learning of the network to focus on the general and specific visual properties between similar visual object classes. Figure 2 illustrates the overview of our network. We assume that a taxonomy of object categories is given as side information, which is either human-defined or constructed from data, and the base network is able to generate a feature map (or a vector) for each category. We will further discuss the details of base models in Section 3.1. Then, leveraging the class structure in the given taxonomy, our model imposes additional layers on top of these per-category feature maps (or vectors), to regularize the learning of the original network. The first set of layers are generalization layers, which have the same structure with the given hierarchy T. They mimic the human generalization process that learns increasingly more general and abstract classes by identifying the commonalities among the classes. Specifically, our network learns the feature maps
 Base CNN Conv. Layer Taxonomy- Regularization Layers [ ] Whale Whale Shark Shark Dolphin Dolphin Conv. Layer CNN Input Fig. 2: Overview of our taxonomy-regularized CNN.")
5 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 5 (Classification loss) (Regularization loss) CNN Output Dolphin Per category Generalization feature maps (Min-pooling) Specialization (Diff-Pooling) Base CNN Conv. Layer Taxonomy- Regularization Layers [ ] Whale Whale Shark Shark Dolphin Dolphin Conv. Layer CNN Input Fig. 2: Overview of our taxonomy-regularized CNN. Our network computes per category feature maps (in green dotted boxes) from the base CNN, and feed them into the taxonomy-regularization layers. Then, the regularization sub-network that is organized by the structure of the given taxonomy first learns supercategory feature maps that capture shared features among the grouped classes through min-pooling (generalization), and then learn exclusive feature maps for each child class that are disjoint from its parent class through difference-pooling (specialization). Rectangles indicate feature maps; red and blue arrows denote min- and difference-pooling respectively. of generalization layers by recursively applying the channel-wise min-pooling operation to grouped subclass feature maps guided by the taxonomy T. Thus, each superclass feature map can identify the common activations among its child subclass feature maps. The generalization layers are learned to minimize the loss of superclass classification (i.e. classifying each superclass from all the other superclasses on the same level) (Section 3.2). On top of the generalization layers are the specialization layers, which have the inverse structure of generalization layers (See Figure 2). The specialization layers uniquely identify each object class as a specialization of a more generic object class. These layers learn a unique feature map for each subclass that is not explained by the feature map of its parent through difference-pooling, which computes the difference between each subclass feature map and its parent feature map. The specialization layers are learned to minimize the loss of subclass classification (Section 3.3). Throughout the paper, we use l = 1,, L to denote the level of taxonomy hierarchy (L for the leaf and 1 for the root), K l for the number of nodes at level l, n k l for the k-th node of the tree at level l, and c k l for children nodes of n k l. 3.1 Base Network Models We can use any types of CNN models as our base network. However, instead of directly using it, we make a small modification to the last convolutional
6 6 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang Fig. 3: Illustration of min- and difference-pooling. (a) The min-pooling operation computes the elementwise minimums across multiple subcategory feature maps. (b) The difference-pooling computes the elementwise differences between the feature maps of each subcategory and its parent. layer, where we learn a per-class feature map ML k Rh w for each class k {1,, C}, where h and w are the height and width of the feature map, and L in the subscript denotes that this feature map is for a base-level class. Note that the per-class features are not required to be two-dimensional maps, but can be one-dimensional vectors (h = 1). However, for generality we assume that the features are 2D maps, since this assumption is necessary for some CNN architectures (e.g. Network in Network (NIN) [14]). For architectures such as AlexNet that do not generate per-category feature maps, we can easily get such a network by simply adding convolutional layer having them to the last convolutional layer. The feature map of each class is linked to the softmax loss layer through a global average pooling layer [14], which simply computes a single average value of 1 all entries of an input feature map M (i.e. h w M(i, j)). The main role of the global average pooling is to learn the network such that each category-specific feature map produces high response for the input images of that category. 3.2 Min-Pooling for Superclasses We learn the feature map for each superclass by exploiting the commonalities among the subclasses that belong to it(e.g. superclass big cat for subclasses tiger, lion, and jaguar). This is implemented by the min-pooling operation across subclass feature maps. The min-pooling simply computes the element-wise minimum over all input siblings feature maps. Equation 1 and Figure 3.(a) describe the min-pooling: Ml 1(i, k j) = min{ml k (i, j)} k C (1) l k where M k l (i, j) is the (i, j)-th element of feature map for class node nk l, and Ck l is the set of its children. This operation captures features that are common across all children subclasses, but not unique to any of them, which can be captured by differencepooling in next section. For example, in Figure 1, using min-pooling on the
7 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 7 feature maps captures only feline-features, such as the shape of the face and light brown color of their fur, but not their distinctive spots. We attach the global-average pooling layer and then the softmax layer on top of the min-pooled superclass feature maps. Next we minimize the superclass loss, which learns the superclass feature maps to focus on the common properties of its children, which in turn propagate to lower layers. Min- vs. max-pooling. Max-pooling is a more widely used downsampling method for object recognition using deep CNNs (e.g. [12]). However, it is not useful in our case where we aim to find general components across multiple object categories. For example, applying max-pooling on the category maps of the three animals in Figure 1, would capture unique spot patterns for each animal as well as the general feline features. This helps recognize the superclass big cat better, but does not help discriminate between the subclass categories, since the model does not know which are common and which are unique. 3.3 Difference-Pooling between Parent and Child Classes Between each subcategory and its parent, we focus on finding the features that are as different as possible. Since the feature map of the parent captures the commonality between siblings, its activations may not be so useful for inter-subcategory discrimination. Thus we apply the difference-pooling between the response maps of the parent and its child subcategories. It retrieves the subcategory-specific entries that are not used in its parent response map. Equation 2 and Figure 3.(b) describe the difference-pooling between a parent and its children. The feature map Dl k(i, j) for node nk l of the difference-pooling layer between a parent and a child is defined as D k l (i, j) = M k l (i, j) M k l 1(i, j), s.t. k C k l 1. (2) The difference-pooling reduces the effect of supercategory-specific features, and thus makes the subcategory discrimination less dependent on supercategoryspecific features. It in turn promotes learning the features that are required for fine-grained categorization at lower layers of the CNN. 1 As with the superclass feature maps, we attach the global average pooling and multinomial classification loss layers to the diff-pooling layers. This enforces the network to learn discriminative features that uniquely identifies each object category. 3.4 Unsupervised Construction of a Taxonomy While the taxonomies for most generic object categories can be obtained from semantic taxonomies such as WordNet [16], such predefined taxonomies may 1 We also test XOR-pooling that assign 0 to the elements of the children feature maps that are also selected at the parent feature map. However, in our experiments, the XOR-pooling results in a worse performance than diff-pooling, perhaps due to excessive sparsity.
8 8 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang be unavailable for domain-specific data. Furthermore, the semantic taxonomies do not always accurately reflect the feature distributions in the training set. Therefore, we propose a simple taxonomy construction method by examining the activations of the feature maps in the base network. Note that we do not declare this method as our major contribution, but as will be shown in experiments, it performs successfully when no taxonomy is available. The key idea is to group the classes that have the similar activations of feature maps, because those are the confusing classes that we want to discriminate. First, we learn a base network using the original category labels, as done in normal image classification. We then define activation vector g k for each category k by averaging the feature response maps for its training images. Next we perform agglomerative clustering on {g k } C k=1 using l 2 distance metric and Ward s linkage criteria. Once we obtain the dendrogram between categories, we can cluster them for any given K number of clusters, which become the superclasses and their members become subclasses. A single application of such agglomerative clustering can generate a two-level taxonomy. We can recursively apply this operation to obtain a multi-level taxonomy. 3.5 Training We attach a softmax loss layer to every level of min- and diff- pooled layers via global average pooling layers (See Figure 2). With the superclass classification loss, the feature maps generated by min-pooling is learned to preserve spatially consistent information across subclasses that belong to the same superclass. That is, the activations on those feature maps are unique to the group of subclasses, and not possessed by other superclass groups. However, the superclass loss can at the same time hamper the network from learning the representation that discriminates between the subclasses that belong to the same group. Thus we add in an additional loss layer on top of the diff-pooling layer, which is the classification loss over the classes in same level. The resulting network has multiple loss layers including the loss layers for the base-level classes, subclasses, and superclasses. However, since we are mostly interested in improving on the base-level categorization accuracy, we balance the contribution of each loss by giving different weights so that the additional losses for min-pooled and diff-pooled layers act as regularizers. The combined loss term is described as follows: l = l L + L wl m l m l + l=2 L wl d l d l. (3) where l L is the original base-level categorization loss, l m l are the losses from min-pooled layers for superclasses, l d l are the losses from diff-pooled layers for subclasses, and wl m, wl d are weights for each loss term. 2 2 Our experiments reveal that the network is not sensitive to these balancing parameters, as long as the base-level categorization loss has a higher weight than others. That is, w m l, w d l < 1. l=2
9 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 9 We implement the min- and diff-pooling layers on top of the publicly available Caffe [10] package. Note that the added pooling layers do not introduce any new parameters and the only additional computational burden is on computing the min- and diff-pooling; thus the increase in memory and computational complexity is minor compared to the original model. The increase in space and time complexity depends on an employed tree structure, specifically on the number of internal nodes. If the number of classes at all levels is C and the memory usage of per class feature maps is U, then the increase in the space complexity will be O(CU), where the worst case happens if the given tree is a full binary tree. In our experiments, the increase in memory usage is less than 3% and the increase in training time is 15% at maximum, compared to those of the base networks. The HD-CNN [23], which is a similar approach that makes use of hierarchical class information, on the other hand, increases the memory usage and the training time by about 50% and 150% each. Thus, our model is more scalable with a much larger number of classes, with a large and complex class hierarchy. Also further speed-up can be achieved with a parallel implementation of the additional layers, although our current implementation does not fully exploit the parallelism on the problem. 4 Experiment We evaluate the multiclass classification performance of our approach on multiple image datasets. Our main focus is to demonstrate that the taxonomy-based generalization and specialization layers improve the performance of base CNN models, by learning the discriminative features at multiple semantic granularity. 4.1 Dataset CIFAR-100. The CIFAR-100 [11] consists of 100 generic object categories (e.g. tiger, bed, palm, and bus), and has been extensively used for the evaluation of deep neural networks. 3 It consists of 600 images per category (i.e. 60,000 images in total) with a size of 32 32, where 500 images are used for training and the remaining 100 images are for testing. We pre-process the images with global contrast normalization and ZCA whitening as done in [14, 23]. For taxonomy, we use the trees provided in [11], [19], and another one discovered using our tree construction method in Section 3.4. Places-205. The Places dataset [25] contains 2, 448, 873 images from 205 scene categories. The set of scene classes includes both indoor scenes (e.g. romantic bedroom, stylish kitchen) and outdoor scenes (e.g. rocky coast, and wintering forest path). We use the provided training and test splits by [25] for our experiments. For taxonomy, we use the discovered class hierarchy using our tree construction method since no predefined one exists for this dataset. 3 datasets_results.html.
10 Accuracy 10 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang Method Top-1 Top-5 Baseline ConvNet of [19] Tree-Based Prior [19] Network in Network (NIN) [14] dasnet [20] HD-CNN [23] NINtri Ensemble of NINtri (Ours:NINtri+min-only) (Ours:NINtri+Tree[11]) (Ours:NINtri+TreeClust) (Ours:NINtri+Tree[19]) (Ours:NINtri+Ensemble) Ours:NINtri+TreeClust 65 NINtri # of training examples per category Fig. 4: Left: The classification results on the CIFAR-100 dataset. We report top-1 and top-5 accuracy in percentage. Right: The classification accuracy with different number of training images per label. ImageNet Animal. ImageNet 1K/22K Animal datasets, suggested in [22], are subsets of the widely-used ImageNet dataset [3]. For ImageNet 1K Animal dataset, we select all 398 animal classes out of the ImageNet 1K and split the images into 501K training images and 18K test images. For ImageNet 22K Animal dataset, we collect 2,266 animal classes out of all ImageNet 22K classes; we only consider the classes that have more than 100 images and are at leaf nodes of ImageNet hierarchy. The dataset consists of 1.6M training images and 282K test images. Our ImageNet 22K Animal dataset has slightly different number of classes from [22] (2,282 classes), but the difference is less than 1%. For taxonomy, we use the generated class hierarchy instead of the existing ImageNet hierarchy since the ImageNet class hierarchy is largely imbalanced and overly deep. As for tree depth in automatic hierarchy construction, we experimentally found that the optimal value is around log 10 k, where k is the number of classes; we used 2-level trees for CIFAR-100 and Places-205, and a 3-level tree for ImageNet 22K-Animals that comes with 2K classes. 4.2 Quantitative Evaluation Results on CIFAR-100. Figure 4 shows the classification results of our method and the baselines on the CIFAR-100 dataset. As our base model, we use the Network-in-Network-triple denoted by (NINtri), which is the same as the original Network-in-Network model in [14], except that it has three times of the number of filters in the original network. This network is also used as a baseline in [23], in which the HD-CNN results in a lower accuracy than the NIN-triple, perhaps due to the difference in the number of learning parameters. We report the performance of our NIN-triple model regularized with different taxonomies. We use three different class hierarchies from [11], [19], and our tree construction method (denoted by a suffix +TreeClust). The performance varies depending on which taxonomy we use, but all of our models outperform the base NIN-triple.
11 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 11 Table 1: Classification results on the Places-205 dataset. Method Top-1 Top-5 Method Top-1 Top-5 Places-AlexNet [25] Places-NIN (Ours:AlexNet+TreeClust) (Ours:NIN+TreeClust) Table 2: Classification results on the ImageNet 1K/22K animal dataset. Dataset / Method Xiao et al. [22] AlexNet-pretrained (Ours) Imagenet 1K Animal Imagenet 22K Animal We obtain the best result using the class hierarchy in [11], which outperforms NIN-triple by 1.7%p. This increase is larger than 0.35%p reported in [19], and we attribute such larger enhancement to the exploitation of discriminative information from the taxonomy, through the proposed two pooling methods. The performance can be further improved by ensemble learning with multiple taxonomies. We obtain a bagging predictor by simply averaging out the predictions of the models with the three taxonomies, and this ensemble model denoted by (Ours:NINtri+Ensemble) achieves 71.81% of accuracy, which is significantly higher than the base network NIN-triple by 4.15%p. Results on Places-205. Table 1 shows the classification results on the Places dataset. As base networks, we test the NIN [14] and the AlexNet [12] trained on ILSVRC2012 dataset. Since no pre-trained model is publicly available for the Places dataset, we fine-tune those base models on the Places dataset, which we report as Places-Alexnet and Places-NIN. We generate the tree hierarchy using the method in Section 3.4, and then fine-tune each base network with the proposed generalization and specialization layers. Our tree-regularized networks outperform the base networks by 1.10%p (Ours:Alexnet) and 2.32%p (Ours:NIN), which are significant improvements. Results on ImageNet Animal. Table 2 shows the classification results on ImageNet Animal datasets. We first pretrain the AlexNet on the ImageNet 1K/22K Animal datasets, reported as AlexNet-pretrained. From the learned base model, we generate the class hierarchy using our tree construction method. We then learn our tree-regularized network by fine-tuning the pretrained base AlexNet with the hierarchy. The resulting network outperforms [22] by 4.33%p in ImageNet 1K Animal, and by 0.43%p in ImageNet 22K Animal dataset. Also our network increases the performance of the base AlexNet model more than 1% in the both datasets. On all datasets, our method achieves larger improvements in top-1 accuracy rather than in top-5 accuracy, which suggest that the key improvement come from the correct category recognition at the fine-grained level. This may be due to our model s ability to learn features that are useful for fine-grained discrimination from class hierarchy, through min- and diff-pooling.
12 12 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang Table 3: Hierarchical results on the CIFAR-100 dataset. Method Network in Network-triple (NINtri) [23] Ensemble of NINtri [23] (Ours:NINtri+min-only) (Ours:NINtri+Tree[11]) (Ours:NINtri+TreeClust) (Ours:NINtri+Tree[19]) (Ours:NINtri+Ensemble) Accuracy as a function of training examples. One can expect that our taxonomy-based regularization might be more effective with fewer training examples; to validate this point, we experiment with different number of training examples per class on CIFAR-100 dataset. We learn our model using 50, 100, 250, and 500 training examples, and plot the accuracy as a function of number of examples in Figure 4 (right). The plot shows that our model becomes increasingly more effective than the base network when using less number of training examples. The largest relative performance gain using our model occurs when using as few as 50 training examples, outperforming the baseline by around 3%p. Semantic prediction performance using hp@k. To validate that our tree-regularized network can obtain semantically meaningful predictions, we also evaluate with the hierarchical precision@k (hp@k) introduced in [4], which is a measure of semantic relevance between the predicted label and the groundtruth label. It is computed as a fraction of the top-k predictions that are in the correct set, when considering the k nearest classes based on the tree distance. For detailed description of the hp@k measure, please refer to [4]. Table 3 shows the results on the CIFAR-100 dataset. We observe that our taxonomy-regularized network obtains high hierarchical precisions, outperforming the base network by more than 7%p, using the semantic taxonomy from [11]. The improvement is less when using the constructed tree, but our network still outperforms the non-regularized base network. This performance gain in the semantic prediction mostly comes from the use of minpooling, which groups the relevant classes together, with the diff-pooling also contributing to some degree with accurate discrimination of fine-grained categories. This point is clearly observed by comparing with the result of min-pooling only with the result of the full model (i.e. the third and fourth rows of Table 3). 4.3 Qualitative analysis Figure 5 shows selected examples of class prediction made using our model and the baseline NIN [14] network on the CIFAR-100 and the Places dataset. We observe that in many cases, our network predicts more semantically relevant categories in the top-5 predictions (See Figure 5.(a-d)). This is even true for the failure case of Figure 5.(e), where the top-5 classes predicted by our model


 Ours")



 Ours")





 Ours Prediction bridge")




.")

.")







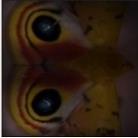








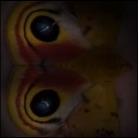




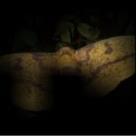
13 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 13 Ours Prediction Baseline Prediction flatfish man man woman trout trout woman girl girl shark (a) Ours Prediction Baseline Prediction shrew rabbit mouse mouse rabbit kangaroo squirrel shrew possum lion aquarium amusement park music studio stage indoor bar bar bowling alley restaurant coffee shop candy store Ours Prediction (b) Ours Prediction amusement park music studio windmill aquarium stage indoor bowling alley bar coffee shop restaurant candy store Baseline Prediction Baseline Prediction Chow Chow (c) Ours Prediction Baseline Prediction woman girl girl skunk Per category man Min Diff woman Per category boy trout feature maps baby pooled pooled flatfish feature maps (e) Min pooled river aqueduct (d) Ours Prediction bridge Diff viaduct Per category highway pooled feature maps (f) bridge river viaduct Min highway pooled aqueduct Baseline Prediction Diff pooled Persian Fig. 5: Example Cat predictions for the CIFAR-100 dataset (left column) and the Places- 205 dataset (right column). For each image, we show the top-5 prediction result using Pomeranian our model and the base network (NIN). The last row shows failure cases. Atlas Moth Chow Chow Persian Cat Pomeranian Imperial Moth Io Moth Atlas Moth Imperial Moth Io Moth Fig. 6: Response maps for the subclasses that belong to the same superclasses in the ImageNet 22K Animal dataset for a given test instance. We superimpose the percategory, min-pooled, and diff-pooled response maps of these sibling classes on top of each input image. The correct feature map for each input image is highlighted in red. (i.e. woman, girl, man, boy, and baby) are all semantically relevant to the correct class girl. On the other hand, the results of the base network include semantically irrelevant categories such as skunk and flatfish in the top-5 predictions. Also, our model is less likely to confuse between similar classes, while the base network is more prone to misclassification between them. Hence, the base network that often lists correct categories in the top-5 predictions still fails to predict the correct top-1 category (See Figure 5.(a-d)). To further analyze where the improvement in classification performance comes from, we examine the response maps for the subcategories that share the same parent categories, in Figure 6. From ImageNet 22K animal dataset, we select one supercategory, moth, for which we select three subcategories. Note that the original feature maps do not represent discriminative activations, but diff-pooled

14 14 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang Fig. 7: Image segmentation results on the CIFAR-100 test images. Our network generates tighter segmentation boundaries compared to the base network. activations clearly capture discriminative local properties for each subcategory. For example, in the moth subclasses, we can see that the diff-pooled activation maps exclusively focus on the wing patterns which are important for distinguishing different moth species. This example confirms that the hierarchical regularization layers can indeed capture discriminative traits for the subclasses, thus significantly eliminating confusions between subcategories. We also compare between the feature maps learned by the base model NIN and our approach on the CIFAR-100 dataset, in Figure 7. Since the base network NIN has only convolution layers except for the last classification loss layer, the forward pass can preserve the spatial information. Therefore, we can segment an image by using activations of the feature map on the image. We show segmentation results in Figure 7. The segmentations by our method are qualitatively better, as they focus more on the target objects compared to the base network, which often generates loose and inaccurate segmentations. These results assure our taxonomy-based model s ability to learn unique features for each category, rather than learning features that are generic across all the categories. 5 Conclusion We propose a regularization method that exploits hierarchical task relations to improve the categorization performance of deep convolutional neural networks. We focus on the task relations between the prediction of a parent and child classes in a taxonomy, and learn features common across semantically related classes through min-pooling, then learn discriminative feature maps for each object class by performing difference-pooling between the feature maps of each child class and its parent superclass. We validate our approach on the CIFAR100, the Places-205, and the ImageNet Animal datasets, on which it achieves significant improvement over the baselines. We further show that our taxonomyregularized network makes semantically meaningful predictions, and could be more useful when the training data is scarce. Acknowledgement. This work was supported by Samsung Research Funding Center of Samsung Electronics under Project Number SRFC-IT
15 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks 15 References 1. Bengio, S., Weston, J., Grangier, D.: Label Embedding Trees for Large Multi-Class Task. In: NIPS (2010) 2. Deng, J., Ding, N., Jia, Y., Frome, A., Murphy, K., Bengio, S., Li, Y., Neven, H., Adam, H.: Large-scale object classification using label relation graphs. In: ECCV (2014) 3. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A Large- Scale Hierarchical Image Database. In: CVPR (2009) 4. Frome, A., Corrado, G., Shlens, J., Bengio, S., Dean, J., Ranzato, M., Mikolov, T.: Devise: A deep visual-semantic embedding model. In: NIPS (2013) 5. Gao, T., Koller, D.: Discriminative Learning of Relaxed Hierarchy for Large-Scale Visual Recognition. In: ICCV (2011) 6. Hwang, S.J.: Discriminative Object Categorization with External Semantic Knowledge. Ph.D. Dissertation, The University of Texas at Austin (2013) 7. Hwang, S.J., Grauman, K., Sha, F.: Learning a Tree of Metrics with Disjoint Visual Features. In: NIPS (2011) 8. Hwang, S.J., Grauman, K., Sha, F.: Semantic Kernel Forests from Multiple Taxonomies. In: NIPS (2012) 9. Hwang, S.J., Sigal, L.: A Unified Semantic Embedding: Relating Taxonomies and Attributes. In: NIPS (2014) 10. Jia, Y.: Caffe: An Open Source Convolutional Architecture for Fast Feature Embedding. In: arxiv: (2013) 11. Krizhevsky, A.: Learning Multiple Layers of Features from Tiny Images. Master s thesis, University of Toronto (2009) 12. Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet Classification with Deep Convolutional Neural Networks. In: NIPS (2012) 13. Lecun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based Learning Applied to Document Recognition. Proceedings of the IEEE 86(11), (1998) 14. Lin, M., Chen, Q., Yan, S.: Network In Network. In: ICLR (2014) 15. Marszalek, M., Schmid, C.: Constructing Category Hierarchies for Visual Recognition. In: ECCV (2008) 16. Miller, G.A., Beckwith, R., Fellbaum, C.D., Gross, D., Miller, K.: WordNet: An Online Lexical Database. Int. J. Lexicograph 3(4), (1990) 17. Salakhutdinov, R.R., Tenenbaum, J.B., Torralba, A.: Learning to Learn with Compound HD Models. In: NIPS (2011) 18. Simonyan, K., Zisserman, A.: Imagenet classification with deep convolutional neural networks. In: ICLR (2015) 19. Srivastava, N., Salakhutdinov, R.R.: Discriminative Transfer Learning with Treebased Priors. In: NIPS (2013) 20. Stollenga, M.F., Masci, J., Gomez, F., Schmidhuber, J.: Deep Networks with Internal Selective Attention through Feedback Connections. In: NIPS (2014) 21. Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., Rabinovich, A.: Going Deeper with Convolutions. In: CVPR (2015) 22. Xiao, T., Zhang, J., Yang, K., Peng, Y., Zhang, Z.: Error-driven Incremental Learning in Deep Convolutional Neural Network for Large-Scale Image Classification. In: ACM MM (2014) 23. Yan, Z., Zhang, H., Jagadeesh, V., DeCoste, D., Di, W., Yu, Y.: HD-CNN: Hierarchical Deep Convolutional Neural Network for Image Classification. In: ICCV (2015)
16 16 Wonjoon Goo, Juyong Kim, Gunhee Kim, and Sung Ju Hwang 24. Zhao, B., Fei-Fei, L., Xing, E.P.: Large-Scale Category Structure Aware Image Categorization. In: NIPS (2011) 25. Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., Oliva, A.: Learning Deep Features for Scene Recognition Using Places Database. In: NIPS (2014) 26. Zhou, D., Xiao, L.,, Wu, M.: Hierarchical Classification via Orthogonal Transfer. In: ICML (2011) 27. Zhou, Y., Jin, R., Hoi, S.C.H.: Exclusive Lasso for Multi-task Feature Selection. JMLR 9, (2010)
Copyright by Sung Ju Hwang 2013
 Copyright by Sung Ju Hwang 2013 The Dissertation Committee for Sung Ju Hwang certifies that this is the approved version of the following dissertation: Discriminative Object Categorization with External
Copyright by Sung Ju Hwang 2013 The Dissertation Committee for Sung Ju Hwang certifies that this is the approved version of the following dissertation: Discriminative Object Categorization with External
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Diverse Concept-Level Features for Multi-Object Classification
 Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
 A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation Chunpeng Wu 1, Wei Wen 1, Tariq Afzal 2, Yongmei Zhang 2, Yiran Chen 3, and Hai (Helen) Li 3 1 Electrical and
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation Chunpeng Wu 1, Wei Wen 1, Tariq Afzal 2, Yongmei Zhang 2, Yiran Chen 3, and Hai (Helen) Li 3 1 Electrical and
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
arxiv: v4 [cs.cv] 13 Aug 2017
![arxiv: v4 [cs.cv] 13 Aug 2017](/thumbs/71/66201702.jpg "arxiv: v4 [cs.cv] 13 Aug 2017") Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
SORT: Second-Order Response Transform for Visual Recognition
 SORT: Second-Order Response Transform for Visual Recognition Yan Wang 1, Lingxi Xie 2( ), Chenxi Liu 2, Siyuan Qiao 2 Ya Zhang 1( ), Wenjun Zhang 1, Qi Tian 3, Alan Yuille 2 1 Cooperative Medianet Innovation
SORT: Second-Order Response Transform for Visual Recognition Yan Wang 1, Lingxi Xie 2( ), Chenxi Liu 2, Siyuan Qiao 2 Ya Zhang 1( ), Wenjun Zhang 1, Qi Tian 3, Alan Yuille 2 1 Cooperative Medianet Innovation
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
arxiv: v2 [cs.cl] 26 Mar 2015
![arxiv: v2 [cs.cl] 26 Mar 2015](/thumbs/71/65580310.jpg "arxiv: v2 [cs.cl] 26 Mar 2015") Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
THE enormous growth of unstructured data, including
 INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2014, VOL. 60, NO. 4, PP. 321 326 Manuscript received September 1, 2014; revised December 2014. DOI: 10.2478/eletel-2014-0042 Deep Image Features in
INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2014, VOL. 60, NO. 4, PP. 321 326 Manuscript received September 1, 2014; revised December 2014. DOI: 10.2478/eletel-2014-0042 Deep Image Features in
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
arxiv:submit/ [cs.cv] 2 Aug 2017
![arxiv:submit/ [cs.cv] 2 Aug 2017](/thumbs/71/66192871.jpg "arxiv:submit/ [cs.cv] 2 Aug 2017") Associative Domain Adaptation Philip Haeusser 1,2 haeusser@in.tum.de Thomas Frerix 1 Alexander Mordvintsev 2 thomas.frerix@tum.de moralex@google.com 1 Dept. of Informatics, TU Munich 2 Google, Inc. Daniel
Associative Domain Adaptation Philip Haeusser 1,2 haeusser@in.tum.de Thomas Frerix 1 Alexander Mordvintsev 2 thomas.frerix@tum.de moralex@google.com 1 Dept. of Informatics, TU Munich 2 Google, Inc. Daniel
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
An Introduction to the Minimalist Program
 An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Webly Supervised Learning of Convolutional Networks
 chihuahua jasmine saxophone Webly Supervised Learning of Convolutional Networks Xinlei Chen Carnegie Mellon University xinleic@cs.cmu.edu Abhinav Gupta Carnegie Mellon University abhinavg@cs.cmu.edu Abstract
chihuahua jasmine saxophone Webly Supervised Learning of Convolutional Networks Xinlei Chen Carnegie Mellon University xinleic@cs.cmu.edu Abhinav Gupta Carnegie Mellon University abhinavg@cs.cmu.edu Abstract
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
arxiv: v2 [cs.cv] 3 Aug 2017
![arxiv: v2 [cs.cv] 3 Aug 2017](/thumbs/71/66064162.jpg "arxiv: v2 [cs.cv] 3 Aug 2017") Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the SAT
 The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees
 Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
A Deep Bag-of-Features Model for Music Auto-Tagging
 1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Ontologies vs. classification systems
 Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Image based Static Facial Expression Recognition with Multiple Deep Network Learning
 Image based Static Facial Expression Recognition with Multiple Deep Network Learning ABSTRACT Zhiding Yu Carnegie Mellon University 5000 Forbes Ave Pittsburgh, PA 1521 yzhiding@andrew.cmu.edu We report
Image based Static Facial Expression Recognition with Multiple Deep Network Learning ABSTRACT Zhiding Yu Carnegie Mellon University 5000 Forbes Ave Pittsburgh, PA 1521 yzhiding@andrew.cmu.edu We report
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Identification of Opinion Leaders Using Text Mining Technique in Virtual Community
 Identification of Opinion Leaders Using Text Mining Technique in Virtual Community Chihli Hung Department of Information Management Chung Yuan Christian University Taiwan 32023, R.O.C. chihli@cycu.edu.tw
Identification of Opinion Leaders Using Text Mining Technique in Virtual Community Chihli Hung Department of Information Management Chung Yuan Christian University Taiwan 32023, R.O.C. chihli@cycu.edu.tw
Automatic Discovery, Association Estimation and Learning of Semantic Attributes for a Thousand Categories
 Automatic Discovery, Association Estimation and Learning of Semantic Attributes for a Thousand Categories Ziad Al-Halah Rainer Stiefelhagen Karlsruhe Institute of Technology, 76131 Karlsruhe, Germany Abstract
Automatic Discovery, Association Estimation and Learning of Semantic Attributes for a Thousand Categories Ziad Al-Halah Rainer Stiefelhagen Karlsruhe Institute of Technology, 76131 Karlsruhe, Germany Abstract
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach
 Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Word Embedding Based Correlation Model for Question/Answer Matching
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Word Embedding Based Correlation Model for Question/Answer Matching Yikang Shen, 1 Wenge Rong, 2 Nan Jiang, 2 Baolin
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Word Embedding Based Correlation Model for Question/Answer Matching Yikang Shen, 1 Wenge Rong, 2 Nan Jiang, 2 Baolin
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability
 Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability Shih-Bin Chen Dept. of Information and Computer Engineering, Chung-Yuan Christian University Chung-Li, Taiwan
Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability Shih-Bin Chen Dept. of Information and Computer Engineering, Chung-Yuan Christian University Chung-Li, Taiwan
WORK OF LEADERS GROUP REPORT
 WORK OF LEADERS GROUP REPORT ASSESSMENT TO ACTION. Sample Report (9 People) Thursday, February 0, 016 This report is provided by: Your Company 13 Main Street Smithtown, MN 531 www.yourcompany.com INTRODUCTION
WORK OF LEADERS GROUP REPORT ASSESSMENT TO ACTION. Sample Report (9 People) Thursday, February 0, 016 This report is provided by: Your Company 13 Main Street Smithtown, MN 531 www.yourcompany.com INTRODUCTION
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
arxiv: v1 [cs.cl] 29 Jun 2016
![arxiv: v1 [cs.cl] 29 Jun 2016](/thumbs/71/66211140.jpg "arxiv: v1 [cs.cl] 29 Jun 2016") Learning Concept Taxonomies from Multi-modal Data Hao Zhang 1, Zhiting Hu 1, Yuntian Deng 1, Mrinmaya Sachan 1, Zhicheng Yan 2, Eric P. Xing 1 1 Carnegie Mellon University, 2 UIUC {hao,zhitingh,yuntiand,mrinmays,epxing}@cs.cmu.edu
Learning Concept Taxonomies from Multi-modal Data Hao Zhang 1, Zhiting Hu 1, Yuntian Deng 1, Mrinmaya Sachan 1, Zhicheng Yan 2, Eric P. Xing 1 1 Carnegie Mellon University, 2 UIUC {hao,zhitingh,yuntiand,mrinmays,epxing}@cs.cmu.edu
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web
 WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web
 WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
Offline Writer Identification Using Convolutional Neural Network Activation Features
 Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline