Machine Learning with Weka
|
|
|
- Anne Grant
- 6 years ago
- Views:
Transcription
1 Machine Learning with Weka SLIDES BY (TOTAL 5 Session of 1.5 Hours Each) ANJALI GOYAL & ASHISH SUREKA ( CS 309 INFORMATION RETRIEVAL COURSE ASHOKA UNIVERSITY NOTE: Slides created and edited using existing teaching resources on Internet
2 WEKA: the software Machine learning/data mining software written in Java (distributed under the GNU Public License) Used for research, education, and applications Main features: Comprehensive set of data pre-processing tools, learning algorithms and evaluation methods Graphical user interfaces (incl. data visualization) Environment for comparing learning algorithms 2
3 WEKA: download and install Go to website: 3
4 WEKA: download and install Go to website: 4
5 WEKA only deals with flat age sex { female, chest_pain_type { typ_angina, asympt, non_anginal, cholesterol exercise_induced_angina { no, class { present, 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present... 5
6 WEKA only deals with flat age sex { female, chest_pain_type { typ_angina, asympt, non_anginal, cholesterol exercise_induced_angina { no, class {present, 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present... 6

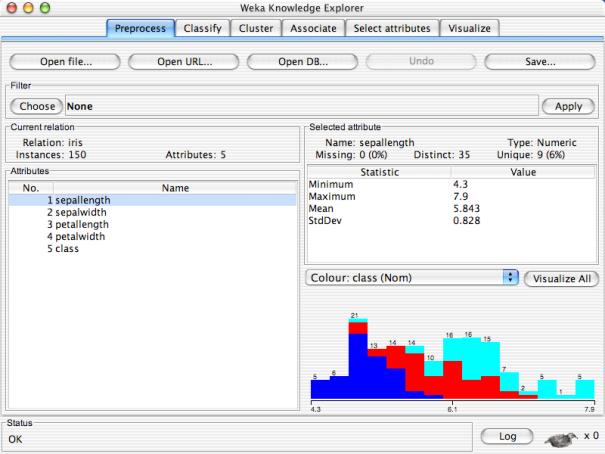
7 7
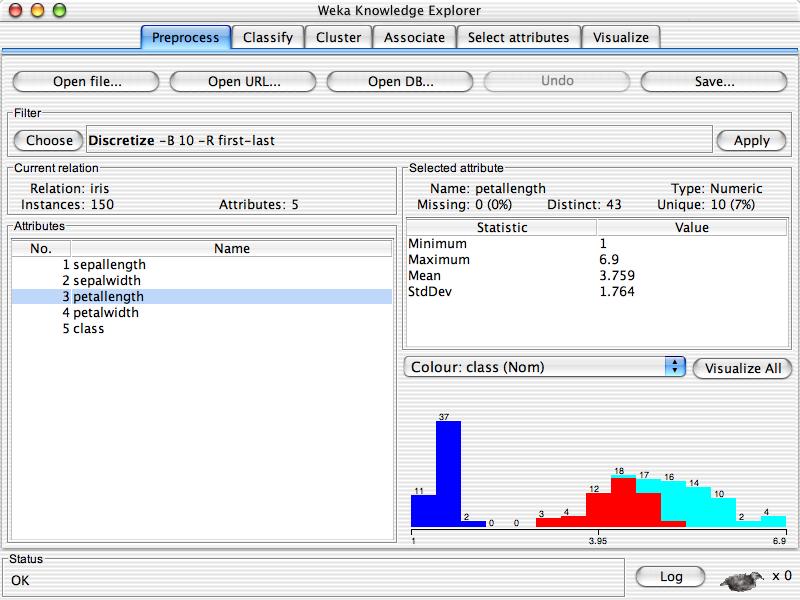
8 Explorer: pre-processing the data Data can be imported from a file in various formats: ARFF, CSV Data can also be read from a URL or from an SQL database (using JDBC) Pre-processing tools in WEKA are called filters WEKA contains filters for: Discretization, normalization, resampling, attribute selection, transforming and combining attributes, 8
9 12/27/2017 University of Waikato 9

10 12/27/2017 University of Waikato 10
11 Iris Dataset 11

12 Iris Dataset 12
13 Iris Dataset- Arff 13
14 Distinct is no. of distinct values i.e. total no. of instances if you removed all duplicates. Unique is no. of values that appear only once. What do you observe from this graph? ? Colors? 5, 6,? What do they add to? Is sepallength a good predictor? 12/27/2017 University of Waikato 14
15 Check if sepalwidth is good predictor? 12/27/2017 University of Waikato 15
16 12/27/2017 University of Waikato 16
17 12/27/2017 University of Waikato 17
18 12/27/2017 University of Waikato 18

19 Which of the 4 attributes is better predictor? 12/27/2017 University of Waikato 19
20 Data Processing 12/27/2017 University of Waikato 20
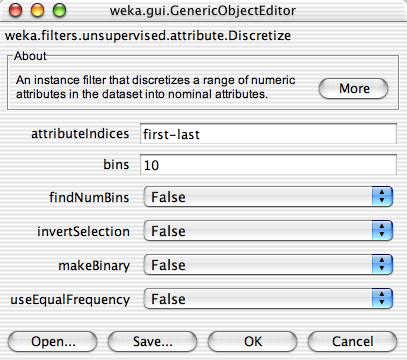
21 Discretization Discretization is the process of putting values into buckets so that there are a limited number of possible states. (continuous to categorical ) Many classification algorithms produce better results on discretized data. 21
22 22
23 23
24 24
25 12/27/2017 University of Waikato 25
26 12/27/2017 University of Waikato 26
27 12/27/2017 University of Waikato 27
28 12/27/2017 University of Waikato 28
29 12/27/2017 University of Waikato 29
30 12/27/2017 University of Waikato 30
31 12/27/2017 University of Waikato 31
32 12/27/2017 University of Waikato 32
33 12/27/2017 University of Waikato 33
34 12/27/2017 University of Waikato 34
35 What should be the best no. of bins? 12/27/2017 University of Waikato 35
36 Explorer: data visualization Visualization very useful in practice: e.g. helps to determine difficulty of the learning problem WEKA can visualize single attributes (1-d) and pairs of attributes (2-d) To do: rotating 3-d visualizations (Xgobi-style) Color-coded class values Jitter option to deal with nominal attributes (and to detect hidden data points) Zoom-in function 36

37 12/27/2017 University of Waikato 37
38 Which two attributes are linearly correlated? 12/27/2017 University of Waikato 38
39 12/27/2017 University of Waikato 39
40 12/27/2017 University of Waikato 40

41 12/27/2017 University of Waikato 41
42 12/27/2017 University of Waikato 42
43 12/27/2017 University of Waikato 43

44 12/27/2017 University of Waikato 44
45 12/27/2017 University of Waikato 45

46 12/27/2017 University of Waikato 46
47 Explorer: attribute selection Panel that can be used to investigate which (subsets of) attributes are the most predictive ones Attribute selection methods contain two parts: A search method: best-first, forward selection, random, exhaustive, genetic algorithm, ranking An evaluation method: correlation-based, wrapper, information gain, chi-squared, Very flexible: WEKA allows (almost) arbitrary combinations of these two 47

48 12/27/2017 University of Waikato 48

49 12/27/2017 University of Waikato 49

50 12/27/2017 University of Waikato 50

51 12/27/2017 University of Waikato 51
52 12/27/2017 University of Waikato 52
53 12/27/2017 University of Waikato 53

54 12/27/2017 University of Waikato 54
55 12/27/2017 University of Waikato 55

56 12/27/2017 University of Waikato 56
57 Add a new feature to existing dataset such that new feature is most beneficial? Add a feature which has distinct values for all classes. Add a new feature to existing dataset such that new feature is least beneficial? Add a feature which has same values for all classes. 57
58 Lets try with Iris dataset! 12/27/2017 University of Waikato 58

59 12/27/2017 University of Waikato 59

60 12/27/2017 University of Waikato 60

61 12/27/2017 University of Waikato 61
62 Explorer: building classifiers Classifiers in WEKA are models for predicting nominal or numeric quantities Implemented learning schemes include: Decision trees and lists, instance-based classifiers, support vector machines, multi-layer perceptrons, logistic regression, Bayes nets, Meta -classifiers include: Bagging, boosting, stacking, error-correcting output codes, locally weighted learning, 62

63 12/27/2017 University of Waikato 63
64 12/27/2017 University of Waikato 64
65 12/27/2017 University of Waikato 65

66 12/27/2017 University of Waikato 66
67 12/27/2017 University of Waikato 67
68 12/27/2017 University of Waikato 68
69 12/27/2017 University of Waikato 69
70 12/27/2017 University of Waikato 70
71 12/27/2017 University of Waikato 71
72 12/27/2017 University of Waikato 72

73 12/27/2017 University of Waikato 73
74 12/27/2017 University of Waikato 74
75 Training data is again used for testing model. Training data is used for model development and an unseen set of data is used for testing model. It is held one out scheme. Train on a certain percentage of data and then test on rest of data. 12/27/2017 University of Waikato 75

76 12/27/2017 University of Waikato 76
77 Cross Validation Cross Validation is the method for estimating the accuracy of an inducer by dividing the data into K mutually exclusive subsets (folds) of approximately equal size. Simplest and most widely used method for estimating prediction error. 77
.")
78 We use Cross Validation as follows: Divide data into K folds; hold-out one part and fit using the remaining data (compute error rate on hold-out data); repeat K times. CV Error Rate: average over the K errors we have computed. (Let us suppose, K = 5) Original Data Testing Data Training Data K=1 K=2 K=3 K=4 K=5
79 How many folds needed (k=?) Large K: small bias, large variance as well as high computational time. Small K: Computational time reduced, small variance, large bias. A common choice for K is
80 12/27/2017 University of Waikato 80
81 12/27/2017 University of Waikato 81
82 12/27/2017 University of Waikato 82

83 12/27/2017 University of Waikato 83
84 12/27/2017 University of Waikato 84
85 12/27/2017 University of Waikato 85
86 12/27/2017 University of Waikato 86

87 12/27/2017 University of Waikato 87

88 12/27/2017 University of Waikato 88
89 tp fn fp tn 12/27/2017 University of Waikato 89

90 tn fp fn tp 12/27/2017 University of Waikato 90

91 12/27/2017 University of Waikato 91
92 12/27/2017 University of Waikato 92

93 Add a new feature to existing dataset such that new feature is most beneficial? Add a feature which has distinct values for all classes. Add a new feature to existing dataset such that new feature is least beneficial? Add a feature which has same values for all classes. 93

94 Add a new feature to existing dataset such that new feature is most beneficial? Add a feature which has distinct values for all classes. Add a new feature to existing dataset such that new feature is least beneficial? Add a feature which has same values for all classes. 94
95 Lets try with Iris dataset! 12/27/2017 University of Waikato 95
96 12/27/2017 University of Waikato 96
97 12/27/2017 University of Waikato 97
98 12/27/2017 University of Waikato 98

99 12/27/2017 University of Waikato 99

100 12/27/2017 University of Waikato 100
101 12/27/2017 University of Waikato 101

102 12/27/2017 University of Waikato 102
103 12/27/2017 University of Waikato 103

104 Attribute Selection+ Classification (Weather.arff) 104

105 12/27/2017 University of Waikato 105

106 12/27/2017 University of Waikato 106

107 12/27/2017 University of Waikato 107

108 12/27/2017 University of Waikato 108
109 Discretization Discretization is the process of putting values into buckets so that there are a limited number of possible states. (continuous to categorical ) Many classification algorithms produce better results on discretized data. 109
110 110
111 111
112 112
113 12/27/2017 University of Waikato 113
114 12/27/2017 University of Waikato 114

115 12/27/2017 University of Waikato 115

116 12/27/2017 University of Waikato 116
117 12/27/2017 University of Waikato 117
118 12/27/2017 University of Waikato 118
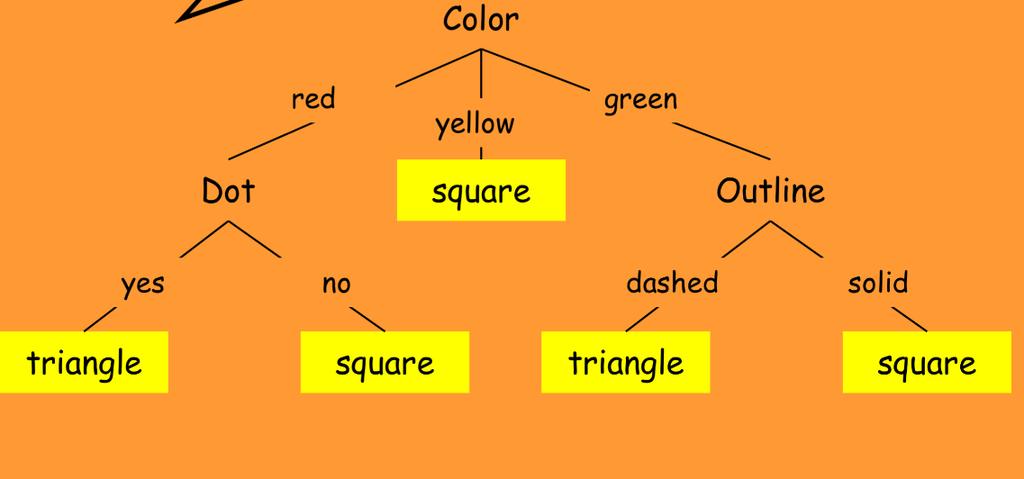
119 12/27/2017 University of Waikato 119
120 12/27/2017 University of Waikato 120
121 12/27/2017 University of Waikato 121

122 12/27/2017 University of Waikato 122
123 Naïve Bayes Classifier Consider each attribute and class label as random variables Given a record with attributes (A 1, A 2,,A n ) Goal is to predict class C Specifically, we want to find the value of C that maximizes P(C A 1, A 2,,A n ) 123
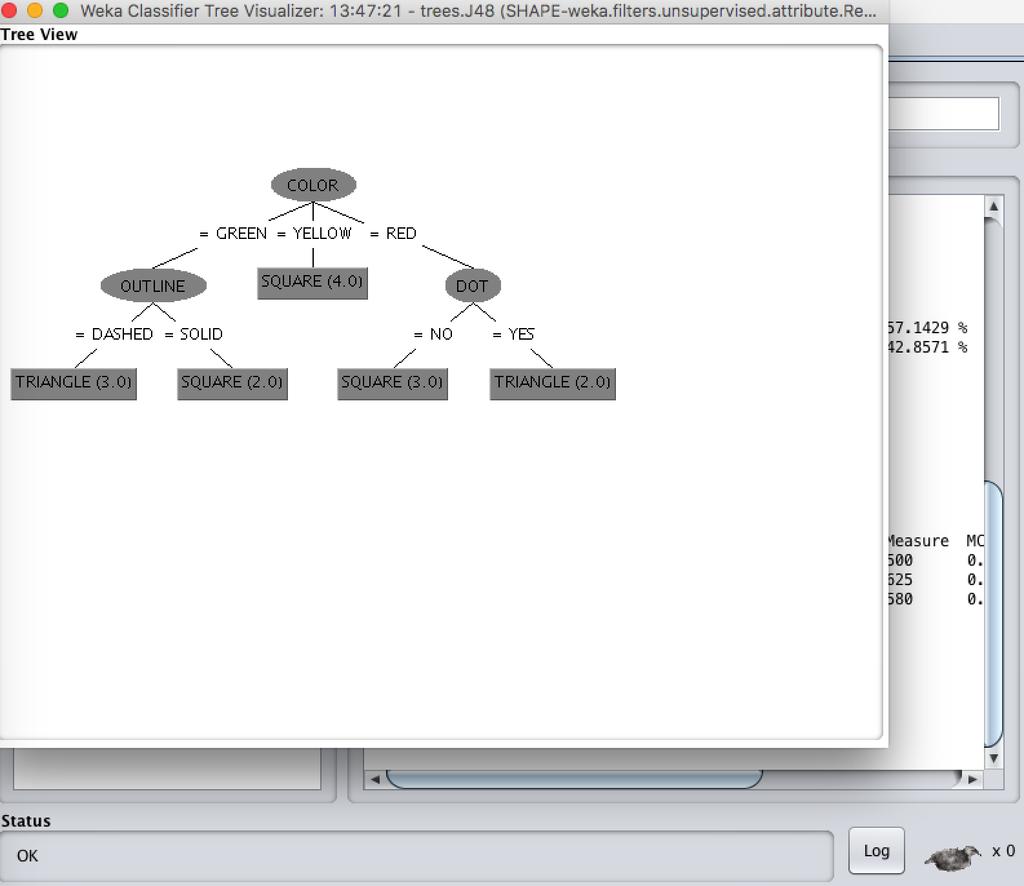
124 Shape Dataset: 124

125 12/27/2017 University of Waikato 125

126 12/27/2017 University of Waikato 126
127 P(Triangle) = 5/14= 0.38 P(Square) = 9/14= 0.63 Color: Triangle Square Green 3 4 4/ /11 Original: P( A C) Laplace: P( A C) i N N COLORi ic OUTLINE classes DOT SHAPE c N N ic c 1 c c: number of GREEN DASHED NO? p: prior probability Yellow 0 1 1/ /11 Red 2 3 3/ /11 Outline: Triangle Square Dashed 4 5 5/ /11 Solid 1 2 2/ /11 4/7 *5/7 *3/7 *5/14 = Dot: Triangle Square Yes 3 4 4/ /11 No 2 3 3/ /11 3/11 *4/11 *7/11 *9/14 =
128 COLOR OUTLINE DOT SHAPE GREEN DASHED NO? Shapetest.csv 128

129 12/27/2017 University of Waikato 129
130 tp fn Confusion Matrix: fp tn True positive rate(tpr)/ Sensitivity,= False positive rate(fpr)/ Specificity,= No.of true positives No.of true positives+no.of false negatives No.of true negatives No.of true negatives+no.of false positives
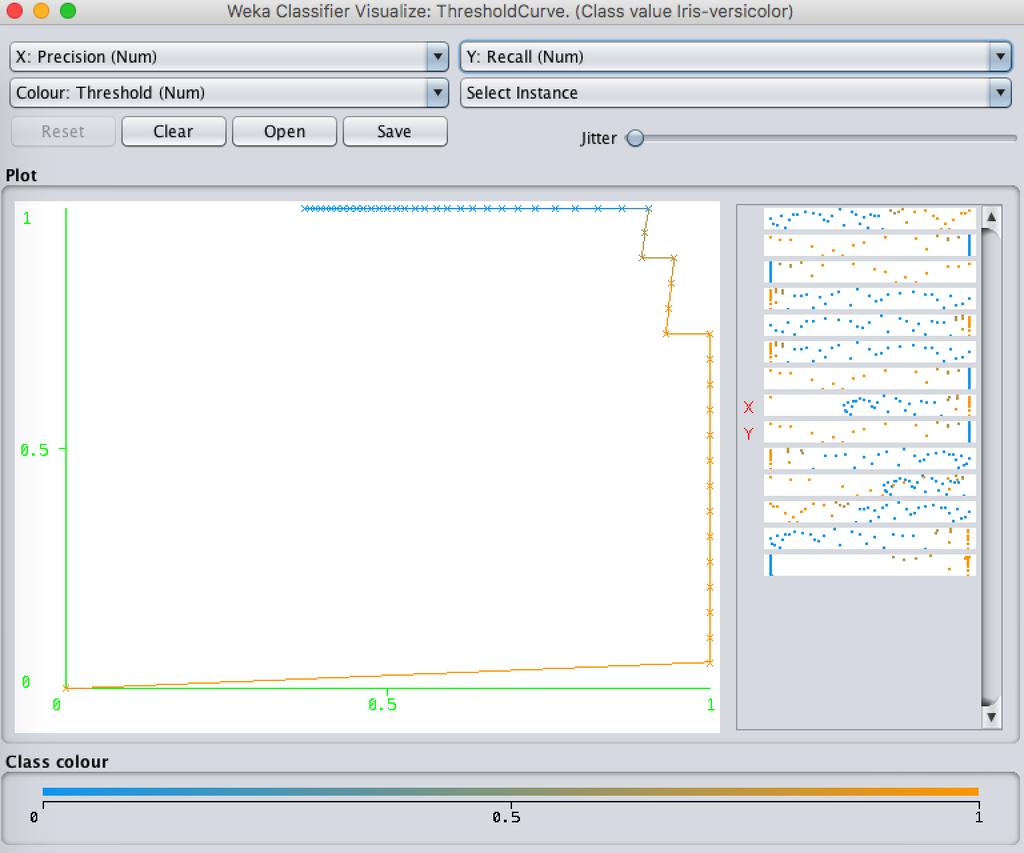
131 tp fn Confusion Matrix: fp tn MCC (Matthews Correlation Coefficient): Measure of quality of binary classification
132 tn fp Confusion Matrix: fn tp True positive rate(tpr)/ Sensitivity,= False positive rate(fpr)/ Specificity,= No.of true positives No.of true positives+no.of false negatives No.of true negatives No.of true negatives+no.of false positives
133 tn fp Confusion Matrix: fn tp MCC (Matthews Correlation Coefficient): Measure of quality of binary classification
 give the same score to the same data item. Step 1: Calculate P o (Observed Agreement). P 0 = (1+6)/14= 0.")
134 Kappa Statistic: Cohen s kappa statistic measures interrater reliability (sometimes called inter-observer agreement). Interrater reliability, or precision, happens when your data raters (or collectors) give the same score to the same data item. Step 1: Calculate P o (Observed Agreement). P 0 = (1+6)/14= 0.5 Step 2: Calculate P e (Expected Agreement). P(Triangle)=(5/14)*(4/14) P(Square)=(9/14)*(10/14) P e = (90/196)+(20/196)= K= ( )/( )=
135 STATUS FLOOR DEPT. OFFICE-SIZE RECYCLING- BIN? faculty four CS medium yes student four EE large yes staff five CS medium no student three EE small yes staff four CS medium no STATUS=student, FLOOR=four, DEPT. =CS, OFFICE SIZE=small Recycling Bin=? 135

136 Lets try with Iris dataset! 12/27/2017 University of Waikato 136

137 12/27/2017 University of Waikato 137
138 12/27/2017 University of Waikato 138
139 ROC Curve ROC: Receiver Operating Characteristic. Developed by British in World War II as part of Chain Home radar system. Used to analyze radar data to differentiate between enemy aircraft and signal noise. It is a performance graphing method. A plot of True Positive Rates and False Positive Rates. Used for evaluating data mining schemes. 139
140 ROC Curve 140
141 Example ROC Curve 141
142 Example ROC Curve 142
143 Why we need ROC curve? Consider a scenario: Design a ML tool. Training Data: Training Data Class: Should be test conducted for cancer by doctor? Create model. Tool will assign the patient a score between 0 and 1. High Score-? Tool is confident about the risk that patient has cancer. Low Score-?Tool is confident that patient is not at risk of having cancer. Test model. What evaluation measure-?. Before you measure anything, make a choicefamily history, age, weight, etc. Patient end up having cancer or not. True Positive Rate: How many ill people were recommended test? False Positive Rate: How many not-ill people were recommended test? False Negative Rate: How many ill people were not recommended test? True Negative Rate: How many not-ill people were not recommended test? Goal: To maximize TP, TN Rate and to minimize FP, FN Rate. Should not be test conducted for cancer by doctor? what threshold score do you use to decide whether or not patient needs test? 143
144 Consider a scenario: Design a ML tool. Should be tested conducted for cancer by doctor Training Data: family history, age, weight, etc. Training Data Class: Patient end up having cancer or not. Create model. Tool will assign the patient a score between 0 and 1. High Score-? Tool is confident about the risk of having cancer Low Score-? Tool Tool is is confident confident that that patient patient is is not not at at risk risk of of having having cancer. cancer. Test model. Should not be tested conducted for cancer by doctor What evaluation measure-?. Goal: To maximize TP, TN Rate and to minimize FP, FN Rate. Before you measure anything, make a choice- what threshold score do you use to decide whether or not patient needs test? As everyone with non-zero score has some risk. Low Threshold-?. Lot of Tests. High Threshold-?Ȯnly people with cancer will get tested. But there would be false negatives as well. (A lot of people with cancer would not be tested)
145 Non-diseased cases Diseased cases Threshold Test result value or subjective judgement of likelihood that case is diseased 145
146 Non-diseased cases Diseased cases more typically: Test result value or subjective judgement of likelihood that case is diseased 146
147 TPF, sensitivity Non-diseased cases Diseased cases Threshold less aggressive mindset FPF, 1-specificity 147
148 TPF, sensitivity Non-diseased cases Threshold moderate mindset Diseased cases FPF, 1-specificity 148
149 TPF, sensitivity Non-diseased cases more aggressive mindset Threshold Diseased cases FPF, 1-specificity 149
150 TPF, sensitivity Non-diseased cases Entire ROC curve Threshold Diseased cases FPF, 1-specificity 150
151 TPF, sensitivity Entire ROC curve Reader Skill and/or Level of Technology FPF, 1-specificity 151
152 Sensitivity: Refers to the test's ability to correctly detect ill patients who have cancer. Sensitivity = No.of true positives No.of true positives+no.of false negatives = probability of positive test given that patient is ill Specificity: Refers to the test's ability to correctly reject healthy patients who do not have cancer. Specificity = No.of true negatives No.of true negatives+no.of false positives = probability of negative test given that patent is not ill. 152
153 True positive rate (TPR) = False positive rate (FPR) = No.of true positives No.of true positives+no.of false negatives No.of false positives No.of true negatives+no.of false positives Move threshold from high to low. True positive rate increases (you test a higher proportion of those who do actually have cancer ) False positive rate increases (you incorrectly tell more people to get tested when they don t need to). 153
154 As you step through the threshold values from high to low, you put dots on the above graph from left to right - joining up the dots gives the ROC curve. 12/27/2017 University of Waikato 154

155 Score: 155
156
157 As you step through the threshold values from high to low, you put dots on the above graph from left to right - joining up the dots gives the ROC curve. 12/27/2017 University of Waikato 157


158 Comparing different classifiers: ROC curves provide a better look at where different learners minimize cost Which curve is better? Area under ROC curve: depicts how good classifier is? 158
159 Precision-Recall Curve 159
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence
 Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand
 Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
ScienceDirect. A Framework for Clustering Cardiac Patient s Records Using Unsupervised Learning Techniques
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
STT 231 Test 1. Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point.
 STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
An Empirical Analysis of the Effects of Mexican American Studies Participation on Student Achievement within Tucson Unified School District
 An Empirical Analysis of the Effects of Mexican American Studies Participation on Student Achievement within Tucson Unified School District Report Submitted June 20, 2012, to Willis D. Hawley, Ph.D., Special
An Empirical Analysis of the Effects of Mexican American Studies Participation on Student Achievement within Tucson Unified School District Report Submitted June 20, 2012, to Willis D. Hawley, Ph.D., Special
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Comparison of EM and Two-Step Cluster Method for Mixed Data: An Application
 International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Linking the Ohio State Assessments to NWEA MAP Growth Tests *
 Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Evaluation of Teach For America:
 EA15-536-2 Evaluation of Teach For America: 2014-2015 Department of Evaluation and Assessment Mike Miles Superintendent of Schools This page is intentionally left blank. ii Evaluation of Teach For America:
EA15-536-2 Evaluation of Teach For America: 2014-2015 Department of Evaluation and Assessment Mike Miles Superintendent of Schools This page is intentionally left blank. ii Evaluation of Teach For America:
For Jury Evaluation. The Road to Enlightenment: Generating Insight and Predicting Consumer Actions in Digital Markets
 FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO The Road to Enlightenment: Generating Insight and Predicting Consumer Actions in Digital Markets Jorge Moreira da Silva For Jury Evaluation Mestrado Integrado
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO The Road to Enlightenment: Generating Insight and Predicting Consumer Actions in Digital Markets Jorge Moreira da Silva For Jury Evaluation Mestrado Integrado
Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio
 SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
16.1 Lesson: Putting it into practice - isikhnas
 BAB 16 Module: Using QGIS in animal health The purpose of this module is to show how QGIS can be used to assist in animal health scenarios. In order to do this, you will have needed to study, and be familiar
BAB 16 Module: Using QGIS in animal health The purpose of this module is to show how QGIS can be used to assist in animal health scenarios. In order to do this, you will have needed to study, and be familiar
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
On-the-Fly Customization of Automated Essay Scoring
 Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
End-of-Module Assessment Task
 Student Name Date 1 Date 2 Date 3 Topic E: Decompositions of 9 and 10 into Number Pairs Topic E Rubric Score: Time Elapsed: Topic F Topic G Topic H Materials: (S) Personal white board, number bond mat,
Student Name Date 1 Date 2 Date 3 Topic E: Decompositions of 9 and 10 into Number Pairs Topic E Rubric Score: Time Elapsed: Topic F Topic G Topic H Materials: (S) Personal white board, number bond mat,
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Historical maintenance relevant information roadmap for a self-learning maintenance prediction procedural approach
 IOP Conference Series: Materials Science and Engineering PAPER OPEN ACCESS Historical maintenance relevant information roadmap for a self-learning maintenance prediction procedural approach To cite this
IOP Conference Series: Materials Science and Engineering PAPER OPEN ACCESS Historical maintenance relevant information roadmap for a self-learning maintenance prediction procedural approach To cite this
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE. Pierre Foy
 TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Ricopili: Postimputation Module. WCPG Education Day Stephan Ripke / Raymond Walters Toronto, October 2015
 Ricopili: Postimputation Module WCPG Education Day Stephan Ripke / Raymond Walters Toronto, October 2015 Ricopili Overview Ricopili Overview postimputation, 12 steps 1) Association analysis 2) Meta analysis
Ricopili: Postimputation Module WCPG Education Day Stephan Ripke / Raymond Walters Toronto, October 2015 Ricopili Overview Ricopili Overview postimputation, 12 steps 1) Association analysis 2) Meta analysis
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Research Design & Analysis Made Easy! Brainstorming Worksheet
 Brainstorming Worksheet 1) Choose a Topic a) What are you passionate about? b) What are your library s strengths? c) What are your library s weaknesses? d) What is a hot topic in the field right now that
Brainstorming Worksheet 1) Choose a Topic a) What are you passionate about? b) What are your library s strengths? c) What are your library s weaknesses? d) What is a hot topic in the field right now that
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur)
 (Some slides, pony-based examples from Blase Ur)") Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE. Mingon Kang, PhD Computer Science, Kennesaw State University
 CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE Mingon Kang, PhD Computer Science, Kennesaw State University Self Introduction Mingon Kang, PhD Homepage: http://ksuweb.kennesaw.edu/~mkang9
CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE Mingon Kang, PhD Computer Science, Kennesaw State University Self Introduction Mingon Kang, PhD Homepage: http://ksuweb.kennesaw.edu/~mkang9
Spinners at the School Carnival (Unequal Sections)
") Spinners at the School Carnival (Unequal Sections) Maryann E. Huey Drake University maryann.huey@drake.edu Published: February 2012 Overview of the Lesson Students are asked to predict the outcomes of
Spinners at the School Carnival (Unequal Sections) Maryann E. Huey Drake University maryann.huey@drake.edu Published: February 2012 Overview of the Lesson Students are asked to predict the outcomes of
Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming
 Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Evidence for Reliability, Validity and Learning Effectiveness
 PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations
 Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Data Structures and Algorithms
 CS 3114 Data Structures and Algorithms 1 Trinity College Library Univ. of Dublin Instructor and Course Information 2 William D McQuain Email: Office: Office Hours: wmcquain@cs.vt.edu 634 McBryde Hall see
CS 3114 Data Structures and Algorithms 1 Trinity College Library Univ. of Dublin Instructor and Course Information 2 William D McQuain Email: Office: Office Hours: wmcquain@cs.vt.edu 634 McBryde Hall see
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Instructor: Mario D. Garrett, Ph.D. Phone: Office: Hepner Hall (HH) 100
 100") San Diego State University School of Social Work 610 COMPUTER APPLICATIONS FOR SOCIAL WORK PRACTICE Statistical Package for the Social Sciences Office: Hepner Hall (HH) 100 Instructor: Mario D. Garrett,
San Diego State University School of Social Work 610 COMPUTER APPLICATIONS FOR SOCIAL WORK PRACTICE Statistical Package for the Social Sciences Office: Hepner Hall (HH) 100 Instructor: Mario D. Garrett,
AP Statistics Summer Assignment 17-18
 AP Statistics Summer Assignment 17-18 Welcome to AP Statistics. This course will be unlike any other math class you have ever taken before! Before taking this course you will need to be competent in basic
AP Statistics Summer Assignment 17-18 Welcome to AP Statistics. This course will be unlike any other math class you have ever taken before! Before taking this course you will need to be competent in basic
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
GDP Falls as MBA Rises?
 Applied Mathematics, 2013, 4, 1455-1459 http://dx.doi.org/10.4236/am.2013.410196 Published Online October 2013 (http://www.scirp.org/journal/am) GDP Falls as MBA Rises? T. N. Cummins EconomicGPS, Aurora,
Applied Mathematics, 2013, 4, 1455-1459 http://dx.doi.org/10.4236/am.2013.410196 Published Online October 2013 (http://www.scirp.org/journal/am) GDP Falls as MBA Rises? T. N. Cummins EconomicGPS, Aurora,
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Case study Norway case 1
 Case study Norway case 1 School : B (primary school) Theme: Science microorganisms Dates of lessons: March 26-27 th 2015 Age of students: 10-11 (grade 5) Data sources: Pre- and post-interview with 1 teacher
Case study Norway case 1 School : B (primary school) Theme: Science microorganisms Dates of lessons: March 26-27 th 2015 Age of students: 10-11 (grade 5) Data sources: Pre- and post-interview with 1 teacher
A Coding System for Dynamic Topic Analysis: A Computer-Mediated Discourse Analysis Technique
 A Coding System for Dynamic Topic Analysis: A Computer-Mediated Discourse Analysis Technique Hiromi Ishizaki 1, Susan C. Herring 2, Yasuhiro Takishima 1 1 KDDI R&D Laboratories, Inc. 2 Indiana University
A Coding System for Dynamic Topic Analysis: A Computer-Mediated Discourse Analysis Technique Hiromi Ishizaki 1, Susan C. Herring 2, Yasuhiro Takishima 1 1 KDDI R&D Laboratories, Inc. 2 Indiana University
An Empirical and Computational Test of Linguistic Relativity
 An Empirical and Computational Test of Linguistic Relativity Kathleen M. Eberhard* (eberhard.1@nd.edu) Matthias Scheutz** (mscheutz@cse.nd.edu) Michael Heilman** (mheilman@nd.edu) *Department of Psychology,
An Empirical and Computational Test of Linguistic Relativity Kathleen M. Eberhard* (eberhard.1@nd.edu) Matthias Scheutz** (mscheutz@cse.nd.edu) Michael Heilman** (mheilman@nd.edu) *Department of Psychology,
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models
 What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
University of Cincinnati College of Medicine. DECISION ANALYSIS AND COST-EFFECTIVENESS BE-7068C: Spring 2016
 1 DECISION ANALYSIS AND COST-EFFECTIVENESS BE-7068C: Spring 2016 Instructor Name: Mark H. Eckman, MD, MS Office:, Division of General Internal Medicine (MSB 7564) (ML#0535) Cincinnati, Ohio 45267-0535
1 DECISION ANALYSIS AND COST-EFFECTIVENESS BE-7068C: Spring 2016 Instructor Name: Mark H. Eckman, MD, MS Office:, Division of General Internal Medicine (MSB 7564) (ML#0535) Cincinnati, Ohio 45267-0535
VOL. 3, NO. 5, May 2012 ISSN Journal of Emerging Trends in Computing and Information Sciences CIS Journal. All rights reserved.
 Exploratory Study on Factors that Impact / Influence Success and failure of Students in the Foundation Computer Studies Course at the National University of Samoa 1 2 Elisapeta Mauai, Edna Temese 1 Computing
Exploratory Study on Factors that Impact / Influence Success and failure of Students in the Foundation Computer Studies Course at the National University of Samoa 1 2 Elisapeta Mauai, Edna Temese 1 Computing
Multi-label classification via multi-target regression on data streams
 Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
Using EEG to Improve Massive Open Online Courses Feedback Interaction
 Using EEG to Improve Massive Open Online Courses Feedback Interaction Haohan Wang, Yiwei Li, Xiaobo Hu, Yucong Yang, Zhu Meng, Kai-min Chang Language Technologies Institute School of Computer Science Carnegie
Using EEG to Improve Massive Open Online Courses Feedback Interaction Haohan Wang, Yiwei Li, Xiaobo Hu, Yucong Yang, Zhu Meng, Kai-min Chang Language Technologies Institute School of Computer Science Carnegie
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,