Deep Neural Network for Automatic Speech Recognition: from the Industry s View
|
|
|
- Meryl Weaver
- 5 years ago
- Views:
Transcription
1 Deep Neural Network for Automatic Speech Recognition: from the Industry s View Jinyu Li Microsoft September 13, 2014 at Nanyang Technological University







2 Speech Modeling in an SR System Training data base Acoustic Model Training Process Acoustic Model Input Speech Feature Extraction HMM Sequential Pattern Recognition (Decoding) Confidenc e Scoring Hello World (0.9) (0.8) Language Model Word Lexicon
3 Speech Recognition and Acoustic Modeling SR = Finding the most probable sequence of words W=w 1, w 2, w 3, w n, given the speech feature O =o 1, o 2, o 3, o T Max {W} p(w O) = Max {W} p(o W)Pr(W)/p(O) = Max {W} p(o W)Pr(W) where - Pr(W) : probability of W, computed by language model - p(o W) : likelihood of O, computed by an acoustic model p(o W) is produced by a model M, p(o W) p M (O W)
4 Challenges in Computing P M (O W) Model area (M): Computational model: GMM/DNN Feature area (O): Noise-robustness Computing P M (O W) (runtime) SVD-DNN Optimization and parameter estimation (training) Model recipe Infrastructure and engineering Modeling and adapting to speakers Feature normalization algorithms Discriminative transformation Adaptation to short-term variability Confidence/Score evaluation Adaptation/Normalization Quantization
5 Acoustic Modeling of a Word /ih/ /L-ih+t/ /t/ /ih-t+r/
6 DNN for Automatic Speech Recognition DNN Feed-forward artificial neural network More than one layer of hidden units between input and output Apply a nonlinear/linear function in each layer DNN for automatic speech recognition (ASR) Replace the Gaussian mixture model (GMM) in the traditional system with a DNN to evaluate state likelihood IPE Speech Science and Technology
7 Phoneme State Likelihood Modeling sil-b+ah [2] sil-p+ah [2] p-ah+t [2] ah-t+iy [3] t-iy+sil [3] d-iy+sil [4]
8 Phoneme State Likelihood Modeling sil-b+ah [2] sil-p+ah [2] p-ah+t [2] ah-t+iy [3] t-iy+sil [3] d-iy+sil [4]
9 Phoneme State Likelihood Modeling sil-b+ah [2] sil-p+ah [2] p-ah+t [2] ah-t+iy [3] t-iy+sil [3] d-iy+sil [4]
10 Phoneme State Likelihood Modeling sil-b+ah [2] sil-p+ah [2] p-ah+t [2] ah-t+iy [3] t-iy+sil [3] d-iy+sil [4]
11 DNN Fundamental Challenges to Industry 1. How to reduce the runtime without accuracy loss? 2. How to do speaker adaptation with low footprints? 3. How to be robust to noise? 4. How to reduce accuracy gap between large and small DNN? 5. How to deal with large variety of data? 6. How to enable languages with limited training data?
12 Reduce DNN Runtime without Accuracy Loss [Xue13]
13 Motivation The runtime cost of DNN is much larger than that of GMM, which has been fully optimized in product deployment. We need to reduce the runtime cost of DNN in order to ship it.
14 Solution The runtime cost of DNN is much larger than that of GMM, which has been fully optimized in product deployment. We need to reduce the runtime cost of DNN in order to ship it. We propose a new DNN structure by taking advantage of the low-rank property of DNN model to compress it

15 Singular Value Decomposition (SVD) A m n = U m n n n V T n n = u 11 u 1n u m1 u mn ε ε kk 0 0 ε nn v 11 v 1n v n1 v nn
16 SVD Approximation Number of parameters: mn->mk+nk. Runtime cost: O(mn) -> O(mk+nk). E.g., m=2048, n=2048, k= % runtime cost reduction.
17 SVD-Based Model Restructuring
18 SVD-Based Model Restructuring

19 SVD-Based Model Restructuring
20 Proposed Method Train standard DNN model with regular methods: pre-training + cross entropy fine-tuning Use SVD to decompose each weight matrix in standard DNN into two smaller matrices Apply new matrices back Fine-tune the new DNN model if needed
21 A Product Setup Acoustic model WER Number of parameters Original DNN model 25.6% 29M SVD (512) to hidden layer 25.7% 21M All hidden and output layer (192) Before fine-tune 36.7% After fine-tune 25.5% 5.6M
22 Adapting DNN to Speakers with Low Footprints [Xue 14]
23 Motivation Speaker personalization with a DNN model creates a storage size issue: It is not practical to store an entire DNN model for each individual speaker during deployment.
24 Solution Speaker personalization with a DNN model creates a storage size issue: It is not practical to store an entire DNN model for each individual speaker during deployment. We propose low-footprint DNN personalization method based on SVD structure.
25 SVD Personalization SVD Restructure: A m n U m k W k n SVD Personalization: A m n U m k S k k W k n. Initiate S k k as I k k, and then only adapt/store the speaker-dependent S k k.
26 SVD Personalization Structure
27 SVD Personalization Structure
28 Adapt with 100 Utterances 27.00% 25.00% 23.00% 21.00% 19.00% 17.00% 15.00% Full-rank SI model SVD model Standard adaptation SVD adaptation WER 25.21% 25.12% 20.51% 19.95% Number of parameters (M)
29 Noise Robustness

30 DNN Is More Robust to Distortion Multi-conditiontrained DNN on Training Utterances

31 DNN Is More Robust to Distortion Multi-conditiontrained DNN on Training Utterances

32 DNN Is More Robust to Distortion Multi-conditiontrained DNN on Training Utterances

33 DNN Is More Robust to Distortion Multi-conditiontrained DNN on Training Utterances

34 Noise-Robustness Is Still Most Challenging Clean-trained DNN on Test Utterances

35 Noise-Robustness Is Still Most Challenging Clean-trained DNN on Test Utterances

36 Noise-Robustness Is Still Most Challenging Clean-trained DNN on Test Utterances

37 Noise-Robustness Is Still Most Challenging Multicondition-trained DNN on Test Utterances

38 Noise-Robustness Is Still Most Challenging Multicondition-trained DNN on Test Utterances

39 Noise-Robustness Is Still Most Challenging Multicondition-trained DNN on Test Utterances
40 Some Observations DNN works very well on utterances and environments observed. For the unseen test case, DNN cannot generalize very well. Therefore, noise-robustness technologies are still important. For more technologies on noise-robustness, refer to our recent overview paper [Li14] for more studies
41 DNN components: Variable Component DNN Weight matrices, outputs of a hidden layer. For any of the DNN components Training: Model it as a set of polynomial functions of a context variable, e.g. SNR, duration, speaking rate. C l J = j=0 C j l v j 0 < l L (J is the order of polynomials) Recognition: compute the component on-the-fly based on the variable and the associated polynomial functions. Developed VP-DNN, VO-DNN.
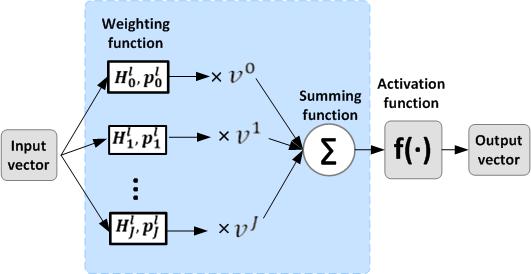
42 VPDNN
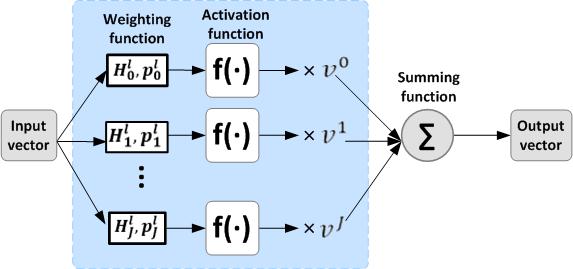
43 VODNN

44 VPDNN Improves Robustness on Noisy Environment Un-seen in the Training The training data has SNR > 10db.
45 Reduce Accuracy Gap between Large and Small DNN
46 To Deploy DNN on Server Low rank matrices are used to reduce the number of DNN parameters and CPU cost. Quantization for SSE evaluation is used for single instruction multiple data processing. Frame skipping or prediction is used to remove the evaluation of some frames.
47 To Deploy DNN on Device The industry has strong interests to have DNN systems on devices due to the increasingly popular mobile scenarios. Even with the technologies mentioned above, the large computational cost is still very challenging due to the limited processing power of devices. A common way to fit CD-DNN-HMM on devices is to reduce the DNN model size by reducing the number of nodes in hidden layers reducing the number of senone targets in the output layer However, these methods significant increase word error rate. In this talk, we explore a better way to reduce the DNN model size with less accuracy loss than the standard training method.
48 Standard DNN Training Process Generate a set of senones as the DNN training target: splits the decision tree by maximizing the increase of likelihood evaluated on single Gaussians Get transcribed training data Train DNN with cross entropy or sequence training criterion Ṭext
49 Significant Accuracy Loss when DNN Size Is Significantly Reduced Better accuracy is obtained if we use the output of large-size DNN for acoustic likelihood evaluation The output of small-size DNN is away from that of large-size DNN, resulting in worse recognition accuracy The problem is solved if the small-size DNN can generate similar output as the large-size DNN Ṭext
50 Can We Make the Small-size DNN Generate Similar Output to the Large-size DNN? No -- if we only have transcribed data. Yes -- in industry, we have almost unlimited un-transcribed data and only a small portion is transcribed
51 Small-Size DNN Training with Output Distribution Learning Use the standard DNN training method to train a large-size teacher DNN using transcribed data Random initialize the small-size student DNN Minimize the KL divergence between the output distribution of the student DNN and teacher DNN with large amount of untranscribed data
52 Minimize the KL Divergence between the Output Distribution of DNNs N t i=1 P L s i x t log P L s i x t P S s i x t s i : i-th senone x t : the observation at time t N t i=1 P L s i x t logp S s i x t P L s i x t, P S s i x t : posterior output distribution of teacher and student DNN, respectively A general form of the standard DNN training criterion where the target is a one-hot vector. Here the target is generated by the output of teacher DNN
53 Experiment Setup 375 hours of transcribed US-English data Large-size DNN: 5*2048 Small-size DNN: 5*512 6k senones
54 EN-US Windows Phone Task Model Training Data Training Criterion WER 5 * hours transcribed data Standard cross entropy * hours transcribed data Standard cross entropy 19.90
55 EN-US Windows Phone Task Use it as the teacher for output distribution learning Model Training Data Training Criterion WER 5 * hours transcribed data Standard cross entropy * hours transcribed data Standard cross entropy 19.90
56 EN-US Windows Phone Task Use it as the teacher for output distribution learning Model Training Data Training Criterion WER 5 * hours transcribed data Standard cross entropy * hours transcribed data Standard cross entropy * hours un-transcribed data Output distribution learning 19.55
57 EN-US Windows Phone Task Use it as the teacher for output distribution learning Model Training Data Training Criterion WER 5 * hours transcribed data Standard cross entropy * hours transcribed data Standard cross entropy * hours un-transcribed data Output distribution learning * hours un-transcribed data Output distribution learning 19.28
58 EN-US Windows Phone Task Use it as the teacher for output distribution learning Model Training Data Training Criterion WER 5 * hours transcribed data Standard cross entropy * hours transcribed data Standard cross entropy * hours un-transcribed data Output distribution learning * hours un-transcribed data Output distribution learning * hours un-transcribed data Output distribution learning 18.89
59 EN-US Windows Phone Task Model Training Data Training Criterion WER 5 * hours transcribed data Standard cross entropy * hours transcribed data Standard cross entropy * hours un-transcribed data Output distribution learning * hours un-transcribed data Output distribution learning * 512 Decode 750 hours untranscribed data to generate transcription Use it as the teacher for output distribution learning Standard cross entropy 20.48
60 Can We Use German Data to Learn EN-US DNN? Model Training Data Training Criterion WER 5 * hours EN-US transcribed data 5 * hours un-transcribed EN-US data 5 * hours un-transcribed German data Use it as the teacher for output distribution learning Standard cross entropy Output distribution learning Output distribution learning?
61 Can We Use German Data to Learn EN-US DNN? Model Training Data Training Criterion WER 5 * hours EN-US transcribed data 5 * hours un-transcribed EN-US data 5 * hours un-transcribed German data Use it as the teacher for output distribution learning Standard cross entropy Output distribution learning Output distribution learning? Please guess a WER 90? 70? 50? 30? 10?
62 Can We Use German Data to Learn EN-US DNN? Model Training Data Training Criterion WER 5 * hours EN-US transcribed data 5 * hours un-transcribed EN-US data 5 * hours un-transcribed German data Use it as the teacher for output distribution learning Standard cross entropy Output distribution learning Output distribution learning 21.71!
63 Better Teacher If the teacher DNN is improved by some other techniques, could the improvement be transferred to a better student DNN?
64 Better Teacher If the teacher DNN is improved by some other techniques, could the improvement be transferred to a better student DNN? Use it as the teacher for output distribution learning Model Training Data Training Criterion WER 5 * hours transcribed data Standard sequence training * hours transcribed data Standard sequence training 17.16
65 Better Teacher If the teacher DNN is improved by some other techniques, could the improvement be transferred to a better student DNN? Use it as the teacher for output distribution learning Model Training Data Training Criterion WER 5 * hours transcribed data Standard sequence training * hours transcribed data Standard sequence training * hours un-transcribed data Output distribution learning 16.66
66 Real Application Setup 2 Million parameter for small-size DNN, compared to 30 Million parameters for teacher DNN Accuracy Teacher DNN trained with standard sequence training Student DNN trained with output distribution learning in this talk Small-size DNN trained with standard sequence training
67 Dealing with Large Variety of Data
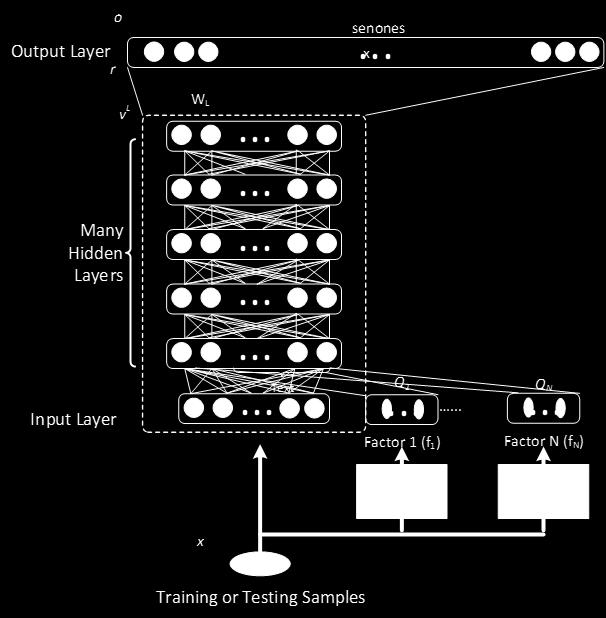
68 Factorization of Speech Signals Output Layer r o... x senones Input Layer v L Many Hidden Layers W L Q 1 Q N Text... Factor 1 (f 1 ) Factor 1 feature extraction Factor N (f N ) Factor N feature extraction R(x) = R(y) + N n=1 Q n f n, x Data Training or Testing Samples
69 Joint Factor Analysis (JFA)-Style Adaptation JFA: M = m + Aa + Bb + Cc, R x R y + Dn + Eh + Fs
70 Vector Tayler Series (VTS)-Style Adaptation x = y + log 1 exp n y y + log 1 exp n 0 y 0 + A y y 0 + B n n 0 R(x) R y + R (Ay + Bn + const. ) y If we make a rather coarse assumption that R y is constant R x R y + Cy + Dn + const
71 Fast Adaptation with Factorization Test set B same microphone Test set D microphone mismatch
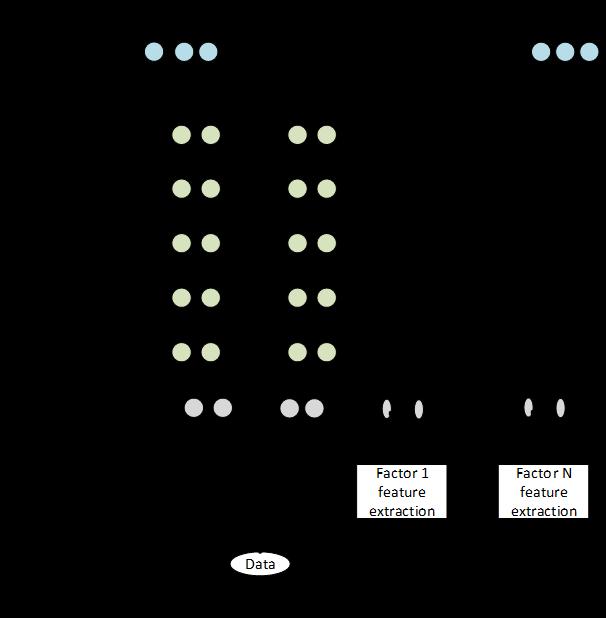
72 Factorization of Speech Signals, Another Solution

73 DNN SR for 8-kHz and 16-kHz Data
74 Performance on Wideband and Narrowband Test Sets Training Data WER (16-kHz) WER (8- khz) 16-kHz VS-1 (B1) kHz VS kHz VS-2 (B2) kHz VS kHz VS-2 (ZP) kHz VS kHz VS-2 (UB)
75 Distance for the Output Vectors between 8-kHz and 16- khz Input Features kHz DNN (UB) Mean Data-mix DNN (ZP) Mean 0 L1 (ED) L4 (ED) L7 (ED) Top (KL)
76 Enable Languages with Limited Training Data [Huang 13]
77 Shared Hidden Layer Multi-lingual DNN
78 Source Languages in Multilingual DNN Benefit Each Other FRA DEU ESP ITA Test Set Size (Words) 40K 37K 18K 31K Monolingual DNN SHL-DNN Relative WER Reduction source languages: FRA: 138 hours, DEU: 195 hours, ESP: 63 hours, and ITA: 93 hours of speech.
79 Transferring from Western Languages to Mandarin Chinese Is Effective CHN CER (%) 3 hrs 9hrs 36hrs 139hrs Baseline DNN (no transfer) SHL-MDNN Model Transfer Relative CER Reduction source languages: FRA: 138 hours, DEU: 195 hours, ESP: 63 hours, and ITA: 93 hours of speech.
80 Reference [Huang 13] Jui-Ting Huang, Jinyu Li, Dong Yu, Li Deng, and Yifan Gong, cross-language knowledge transfer using multilingual deep neural network with shared hidden layers, in ICASSP, 2013 [Li12] Jinyu Li, Dong Yu, Jui-Ting Huang, and Yifan Gong, improving wideband speech recognition using mixedbandwidth training data in CD-DNN-HMM, in IEEE Workshop on Spoken Language Technology, 2012 [Li14] Jinyu Li, Li Deng, Yifan Gong, and Reinhold Haeb-Umbach, An Overview of Noise-Robust Automatic Speech Recognition, in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 22, no. 4, pp , [Li14b] Jinyu Li, Jui-Ting Huang, and Yifan Gong, Factorized adaptation for deep neural network, in ICASSP, 2014 [Li14c] Jinyu Li, Rui Zhao, Jui-Ting Huang and Yifan Gong, Learning Small-Size DNN with Output-Distribution-Based Criteria, in Interspeech, [Xue13] Jian Xue, Jinyu Li, and Yifan Gong, Restructuring of Deep Neural Network Acoustic Models with Singular Value Decomposition, in Interspeech, 2013 [Xue 14] Jian Xue, Jinyu Li, Dong Yu, Mike Seltzer, and Yifan Gong, Singular Value Decomposition Based Lowfootprint Speaker Adaptation and Personalization for Deep Neural Network, in ICASSP, 2014 [Zhao14] Rui Zhao, Jinyu Li and Yifan Gong, Variable-Component Deep Neural Network for Robust Speech Recognition, in Interspeech, [Zhao14b] Rui Zhao, Jinyu Li and Yifan Gong, Variable-activation and variable-input deep neural network for robust speech recognition, in IEEE SLT, 2014.
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE
 2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS
 DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS Jonas Gehring 1 Quoc Bao Nguyen 1 Florian Metze 2 Alex Waibel 1,2 1 Interactive Systems Lab, Karlsruhe Institute of Technology;
DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS Jonas Gehring 1 Quoc Bao Nguyen 1 Florian Metze 2 Alex Waibel 1,2 1 Interactive Systems Lab, Karlsruhe Institute of Technology;
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Distributed Learning of Multilingual DNN Feature Extractors using GPUs
 Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER DNN ACOUSTIC MODELS
 LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER DNN ACOUSTIC MODELS Pranay Dighe Afsaneh Asaei Hervé Bourlard Idiap Research Institute, Martigny, Switzerland École Polytechnique Fédérale de Lausanne (EPFL),
LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER DNN ACOUSTIC MODELS Pranay Dighe Afsaneh Asaei Hervé Bourlard Idiap Research Institute, Martigny, Switzerland École Polytechnique Fédérale de Lausanne (EPFL),
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX,
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions
 26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Vowel mispronunciation detection using DNN acoustic models with cross-lingual training
 INTERSPEECH 2015 Vowel mispronunciation detection using DNN acoustic models with cross-lingual training Shrikant Joshi, Nachiket Deo, Preeti Rao Department of Electrical Engineering, Indian Institute of
INTERSPEECH 2015 Vowel mispronunciation detection using DNN acoustic models with cross-lingual training Shrikant Joshi, Nachiket Deo, Preeti Rao Department of Electrical Engineering, Indian Institute of
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Digital Signal Processing: Speaker Recognition Final Report (Complete Version)
") Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing
 Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation
 UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS
 ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Speech Translation for Triage of Emergency Phonecalls in Minority Languages
 Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method
 Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com