CSE 291: Advances in Computer Vision. Manmohan Chandraker. Lecture 2: Background
|
|
|
- Owen Stephens
- 5 years ago
- Views:
Transcription







1 CSE 291: Advances in Computer Vision Manmohan Chandraker Lecture 2: Background
2 Recap


![04] HOG](/docs-images/87/95730678/images/3-2.jpg "[Dalal and")



3 Features have been key SIFT [Lowe IJCV 04] HOG [Dalal and Triggs CVPR 05] SPM [Lazebnik et al. CVPR 06] Textons and many others: SURF, MSER, LBP, GLOH,..


4 Learning a Hierarchy of Feature Extractors Hierarchical and expressive feature representations Trained end-to-end, rather than hand-crafted for each task Remarkable in transferring knowledge across tasks




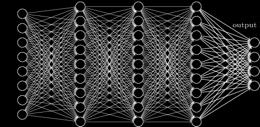
5 Significant recent impact on the field Big labeled datasets Deep learning GPU technology


6 Neuron Inputs are feature values Each feature has a weight Sum is the activation If the activation is: Positive, output +1 Negative, output -1 Slide credit: Pieter Abeel and Dan Klein
7 Two-layer neural network Slide credit: Pieter Abeel and Dan Klein
8 Activation functions

9 From fully connected to convolutional networks image Fully connected layer Slide: Lazebnik
10 From fully connected to convolutional networks feature map learned weights image Convolutional layer Slide: Lazebnik
11 From fully connected to convolutional networks feature map learned weights image Convolutional layer Slide: Lazebnik
12 From fully connected to convolutional networks image Convolutional layer next layer Slide: Lazebnik

13 Learnable filters

14 Number of weights

15 Filters over the whole image

16 Weight sharing Insight: Images have similar features at various spatial locations!

17 Pooling operations Aggregate multiple values into a single value Invariance to small transformations Keep only most important information for next layer Reduces the size of the next layer Fewer parameters, faster computations Observe larger receptive field in next layer Hierarchically extract more abstract features

18 Convolutional Neural Networks
 More data (10 6 images instead of 10 3 images) GPU implementation (50 times speedup")
19 Architectural details of AlexNet Similar framework to LeCun 1998 but: Bigger model (7 hidden layers, 650k units, 60M parameters) More data (10 6 images instead of 10 3 images) GPU implementation (50 times speedup over CPU)

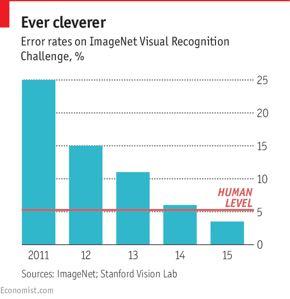
20 VGGNet architecture Much more accurate AlexNet : 18.2% top-5 error VGGNet: 6.8% top-5 error More than twice as many layers Filters are much smaller Harder and slower to train
 No")
21 Deep residual learning Plain Net Simple design Use only 3x3 conv (like VGG) No hidden FC
22 Key ideas for CNN architectures Convolutional layers Same local functions evaluated everywhere Much fewer parameters Pooling Larger receptive field ReLU Maintain a gradient signal over large portion of domain Limit parameters Sequence of 3x3 filters instead of large filters 1x1 convolutions to reduce feature dimensions Skip network Easier optimization with greater depth
23 Optimization in CNNs


24 A 3-layer network for digit recognition MNIST dataset

25 Cost function The network tries to approximate the function y(x) and its output is a We use a quadratic cost function, or MSE, or L2-loss.

26 Gradient descent
27 Stochastic gradient descent Update rules for each parameter: Cost function is a sum over all the training samples: Gradient from entire training set: Usually, n is very large.
28 Stochastic gradient descent Gradient from entire training set: For large training data, gradient computation takes a long time Leads to slow learning Instead, consider a mini-batch with m samples If sample size is large enough, properties approximate the dataset

29 Stochastic gradient descent

30 Stochastic gradient descent
31 Stochastic gradient descent

32 Stochastic gradient descent Build up velocity as a running mean of gradients.
33 Backpropagation This is all you need to know to get the gradients in a neural network! Backpropagation: application of chain rule in certain order, taking advantage of forward propagation to efficiently compute gradients.
34 Backpropagation example [Slides credit: Fei-Fei Li]
35 Backpropagation example
36 Backpropagation example
37 Backpropagation example
38 Backpropagation example
39 Backpropagation example
40 Backpropagation example
41 Backpropagation example
42 Backpropagation example
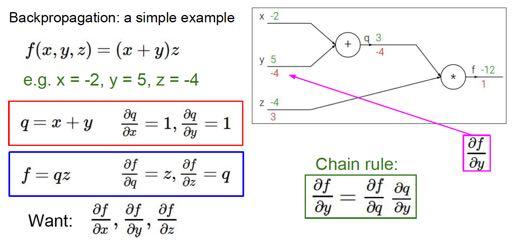
43 Backpropagation example
44 Backpropagation example
45 Backpropagation example
46 Backpropagation example Add gate: gradient distributor Mul gate: gradient switcher
47 Convolutional layer is differentiable

48 Max Pooling
49 Loss Functions and Regularizations
50 Slow learning with sigmoid neurons
51 Slow learning with sigmoid neurons When the neuron s output is close to 1, learning becomes slow.
52 Cross-Entropy Loss
53 Cross-Entropy Loss Rate of learning depends on error in prediction! Prevents the learning slowdown from derivative of sigmoid.
54 Better activation functions Computes f(x) = max (0, x) Does not saturate (in positive region) Computationally efficient Converges faster than sigmoid Same advantages as ReLU Stays alive when x < 0
55 Over-fitting
56 More data prevents over-fitting But not always feasible to have more data that is relevant.
57 Regularization reduces over-fitting
58 L2 regularization L2 regularization: Partial derivatives: Update rule:
59 L1 regularization L1 regularization: Partial derivatives: C 0 is the cross-entropy term. Update rule:

60 L2 or L1 regularization
61 Regularization reduces over-fitting
62 Dropout as a regularization Modify the network itself Randomly delete half the hidden neurons in the network Repeat several times to learn weights and biases At runtime, twice as many neurons, so halve the weights outgoing from a neuron
63 Dropout as a regularization Modify the network itself Randomly delete half the hidden neurons in the network Repeat several times to learn weights and biases At runtime, twice as many neurons, so halve the weights outgoing from a neuron Averaging or voting scheme to decide output Same training data, but random initializations Each network over-fits in a different way Average output not sensitive to particular mode

64 Dropout as a regularization A useful insight from AlexNet paper Reduces complex co-adaptations of neurons, since a neuron cannot rely on presence of others Each neuron forced to learn independent features in conjunction with random other neurons Dropout ensures the model can make robust predictions.

65 Data augmentation as regularization

66 Data augmentation as regularization Horizontal flips


67 Data augmentation as regularization Random crops and scales
68 Data augmentation as regularization Color jitter
69 Data augmentation as regularization Color jitter Can do a lot more: rotation, shear, non-rigid, motion blur, lens distortions,.
70 Transfer Learning in CNNs

71 Transfer Learning Improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned. Weight initialization for CNN Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks [Oquab et al. CVPR 2014] Slide: Jiabin Huang

72 Transfer Learning
73 CNNs are good at transfer learning
74 Fine-tune h T using h S as initialization
75 Initializng ht with hs
76 Initializng ht with hs
77 Initializng ht with hs
78 Initializng ht with hs



79 Strategy for fine-tuning Amount of data needed
80 Use hs as a feature extractor for ht

81 Transfer learning is a common choice
82 Training a Good CNN


83 Verifying that CNN is Trained Well [M. Ranzato]

84 Verifying that CNN is Trained Well [M. Ranzato]
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
SORT: Second-Order Response Transform for Visual Recognition
 SORT: Second-Order Response Transform for Visual Recognition Yan Wang 1, Lingxi Xie 2( ), Chenxi Liu 2, Siyuan Qiao 2 Ya Zhang 1( ), Wenjun Zhang 1, Qi Tian 3, Alan Yuille 2 1 Cooperative Medianet Innovation
SORT: Second-Order Response Transform for Visual Recognition Yan Wang 1, Lingxi Xie 2( ), Chenxi Liu 2, Siyuan Qiao 2 Ya Zhang 1( ), Wenjun Zhang 1, Qi Tian 3, Alan Yuille 2 1 Cooperative Medianet Innovation
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
THE enormous growth of unstructured data, including
 INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2014, VOL. 60, NO. 4, PP. 321 326 Manuscript received September 1, 2014; revised December 2014. DOI: 10.2478/eletel-2014-0042 Deep Image Features in
INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 2014, VOL. 60, NO. 4, PP. 321 326 Manuscript received September 1, 2014; revised December 2014. DOI: 10.2478/eletel-2014-0042 Deep Image Features in
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
 A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation Chunpeng Wu 1, Wei Wen 1, Tariq Afzal 2, Yongmei Zhang 2, Yiran Chen 3, and Hai (Helen) Li 3 1 Electrical and
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation Chunpeng Wu 1, Wei Wen 1, Tariq Afzal 2, Yongmei Zhang 2, Yiran Chen 3, and Hai (Helen) Li 3 1 Electrical and
Distributed Learning of Multilingual DNN Feature Extractors using GPUs
 Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Diverse Concept-Level Features for Multi-Object Classification
 Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Offline Writer Identification Using Convolutional Neural Network Activation Features
 Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
A Deep Bag-of-Features Model for Music Auto-Tagging
 1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
2.B.4 Balancing Crane. The Engineering Design Process in the classroom. Summary
 2.B.4 Balancing Crane The Engineering Design Process in the classroom Grade Level 2 Sessions 1 40 minutes 2 30 minutes Seasonality None Instructional Mode(s) Whole class, groups of 4 5 students, individual
2.B.4 Balancing Crane The Engineering Design Process in the classroom Grade Level 2 Sessions 1 40 minutes 2 30 minutes Seasonality None Instructional Mode(s) Whole class, groups of 4 5 students, individual
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Taxonomy-Regularized Semantic Deep Convolutional Neural Networks
 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks Wonjoon Goo 1, Juyong Kim 1, Gunhee Kim 1, Sung Ju Hwang 2 1 Computer Science and Engineering, Seoul National University, Seoul, Korea 2
Taxonomy-Regularized Semantic Deep Convolutional Neural Networks Wonjoon Goo 1, Juyong Kim 1, Gunhee Kim 1, Sung Ju Hwang 2 1 Computer Science and Engineering, Seoul National University, Seoul, Korea 2
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
arxiv:submit/ [cs.cv] 2 Aug 2017
![arxiv:submit/ [cs.cv] 2 Aug 2017](/thumbs/71/66192871.jpg "arxiv:submit/ [cs.cv] 2 Aug 2017") Associative Domain Adaptation Philip Haeusser 1,2 haeusser@in.tum.de Thomas Frerix 1 Alexander Mordvintsev 2 thomas.frerix@tum.de moralex@google.com 1 Dept. of Informatics, TU Munich 2 Google, Inc. Daniel
Associative Domain Adaptation Philip Haeusser 1,2 haeusser@in.tum.de Thomas Frerix 1 Alexander Mordvintsev 2 thomas.frerix@tum.de moralex@google.com 1 Dept. of Informatics, TU Munich 2 Google, Inc. Daniel
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Dropout improves Recurrent Neural Networks for Handwriting Recognition
 2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand
 Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Improving Fairness in Memory Scheduling
 Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
arxiv: v4 [cs.cv] 13 Aug 2017
![arxiv: v4 [cs.cv] 13 Aug 2017](/thumbs/71/66201702.jpg "arxiv: v4 [cs.cv] 13 Aug 2017") Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
arxiv: v2 [cs.cv] 3 Aug 2017
![arxiv: v2 [cs.cv] 3 Aug 2017](/thumbs/71/66064162.jpg "arxiv: v2 [cs.cv] 3 Aug 2017") Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus
 Spring 2008 Syllabus") Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
A Study of the Effectiveness of Using PER-Based Reforms in a Summer Setting
 A Study of the Effectiveness of Using PER-Based Reforms in a Summer Setting Turhan Carroll University of Colorado-Boulder REU Program Summer 2006 Introduction/Background Physics Education Research (PER)
A Study of the Effectiveness of Using PER-Based Reforms in a Summer Setting Turhan Carroll University of Colorado-Boulder REU Program Summer 2006 Introduction/Background Physics Education Research (PER)
Deep Facial Action Unit Recognition from Partially Labeled Data
 Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
College Pricing. Ben Johnson. April 30, Abstract. Colleges in the United States price discriminate based on student characteristics
 College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE
 2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
arxiv: v2 [stat.ml] 30 Apr 2016 ABSTRACT
![arxiv: v2 [stat.ml] 30 Apr 2016 ABSTRACT](/thumbs/71/66151892.jpg "arxiv: v2 [stat.ml] 30 Apr 2016 ABSTRACT") UNSUPERVISED AND SEMI-SUPERVISED LEARNING WITH CATEGORICAL GENERATIVE ADVERSARIAL NETWORKS Jost Tobias Springenberg University of Freiburg 79110 Freiburg, Germany springj@cs.uni-freiburg.de arxiv:1511.06390v2
UNSUPERVISED AND SEMI-SUPERVISED LEARNING WITH CATEGORICAL GENERATIVE ADVERSARIAL NETWORKS Jost Tobias Springenberg University of Freiburg 79110 Freiburg, Germany springj@cs.uni-freiburg.de arxiv:1511.06390v2
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
 A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
Pentomino Problem. Use the 3 pentominos that are provided to make as many different shapes with 12 sides or less. Use the following 3 shapes:
 Use the 3 pentominos that are provided to make as many different shapes with 12 sides or less. Use the following 3 shapes: 1 of 14 Grade Levels Pre-K-2 Use the 3 pentominos that are provided to make as
Use the 3 pentominos that are provided to make as many different shapes with 12 sides or less. Use the following 3 shapes: 1 of 14 Grade Levels Pre-K-2 Use the 3 pentominos that are provided to make as
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Image based Static Facial Expression Recognition with Multiple Deep Network Learning
 Image based Static Facial Expression Recognition with Multiple Deep Network Learning ABSTRACT Zhiding Yu Carnegie Mellon University 5000 Forbes Ave Pittsburgh, PA 1521 yzhiding@andrew.cmu.edu We report
Image based Static Facial Expression Recognition with Multiple Deep Network Learning ABSTRACT Zhiding Yu Carnegie Mellon University 5000 Forbes Ave Pittsburgh, PA 1521 yzhiding@andrew.cmu.edu We report
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories