Methods for End-to-End Handwritten Paragraph Recognition. Théodore Bluche Valencia - 2 Dec. 2016
|
|
|
- Marilynn Randall
- 5 years ago
- Views:
Transcription

1 Methods for End-to-End Handwritten Paragraph Recognition Théodore Bluche Valencia - 2 Dec. 2016
2 Offline Handwriting Recognition Challenges the input is a variable-sized two dimensional image the output is a variable-sized sequence of characters the cursive nature of handwriting makes a prior segmentation into characters difficult Methods Isolated character classification Over-segmentation and group-of-segments scoring (90s) Sliding window approach with HMMs (2000s) or neural nets ( s) MDLSTM = models handling both the 2D aspect of the input and the sequential aspect of the prediction state-of-the-art
3 Limitations Current systems require segmented text lines For training = tedious annotation effort or error-prone automatic mapping methods For decoding = need to provide text line images which rarely are the actual input of a production system Document processing pipelines rely on automatic line segmentation algorithms How to process full pages without requiring an explicit line segmentation?
4 "We believe that the use of selective attention is a correct approach for connected character recognition of cursive handwriting." --- Fukushima et al. 1993
5 trends neural networks implementing a sort of attention mechanism end-to-end systems that learn to focus on specific parts of their input in order to make predictions Machine translation Speech Recognition Image captioning Question Answering We propose to replace line segmentation with this kind of attention model
6 Talk Overview Introduction Handwriting Recognition with Multi-Dimensional LSTM networks Limitations Motivations of the proposed approach Learning Reading Order - Character-wise Attention Implicit Line Segmentation - Speeding Up Paragraph Recognition Conclusion

7 Handwriting Recognition with MDLSTM Text line images are fed to a Multi-Dimensional LSTM layer Feature maps are subsampled by convolutional layers At the end, there is one feature map per character They are collapsed in the vertical dimension to obtain sequences of character predictions
 ordering as the feature maps Prevents the recognition of several text lines")
8 The Collapse layer 1. all the feature vectors in the same column j are given the same importance 2. the same error is backpropagated in a given column j 3. the output sequence will have length W, i.e. the width of the feature maps, so at most W characters can be recognized 4. the ordering in the sequence will follow the same (spatial) ordering as the feature maps Prevents the recognition of several text lines

9 Side effects
10 Proposed modification Augment the collapse layer with an attention module, which can learn to focus on specific locations in the feature maps Attention on characters or text lines Takes the form of a neural network, which, applied several times can sequentially transcribe a whole paragraph
11 Weighted Summary: predict one character at a time the length of the output sequence is independent of the dimensions of the image at each timestep, a map of weights {ω(t)ij} is computed with a neural network the feature maps are multiplied by these weights, and summed to obtain one vector (summary) zt the t-th character is predicted from vector zt This is the "Scan, Attend and Read" model.
12 Weighted Collapse recognize one line at a time intermediate solution between the weighted summary and the standard collapse amounts to a standard collapse on the weighted sum the length of the t-th sequence is the width of the feature maps the weights are recomputed at each time step the t-th text line is recognized from sequence z(t) This is the "Joint Line Segmentation and Transcription" model.

13 Proposed modifications

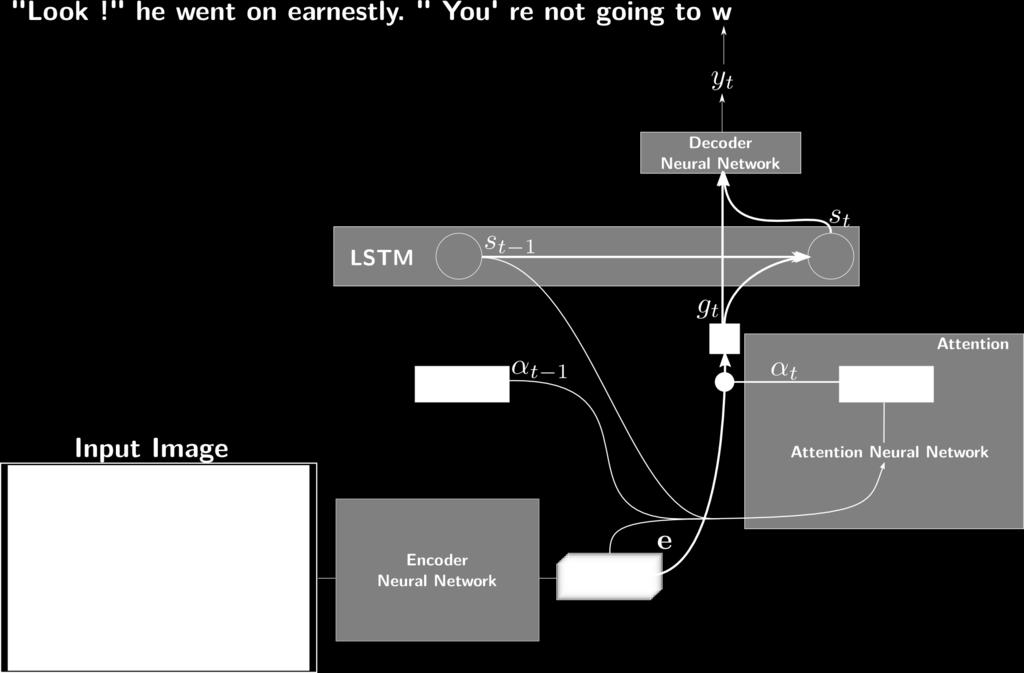
14 Scan, Attend and Read

15 Network s architecture Encoder Attention State Decoder
16 The attention mechanism The attention mechanism provides a summary of the encoded image at each timestep The attention network computes a score for the feature vectors at every positions. The scores are normalized with a softmax. Attention = MDLSTM layer, the attention potentially depends on the context of the whole image. the LSTM gating system allows the network to use the content at one location to predict the attention weight for another location. (overt and covert attention).


17 Model Training We include a special token EOS at the end of the target sequences (also predicted by the network to indicate when to stop reading at test time) No "blank/garbage" token as in CTC The net has to predict the correct character at each timestep
18 Training tricks In order to get the model to converge, or to converge faster, a few tricks helped: Pretraining use an MDLSTM network (no attention) trained on single lines with CTC as a pretrained encoder Data augmentation add to the training set all possible sub-paragraphs (i.e. one, two, three,... consecutive lines) Curriculum (0/2) training the attention model on word images or single line images works quite well, do this as a first step Curriculum (1/2) (Louradour et al., 2014) draw short paragraphs (1 or 2 lines) samples with higher probability at the beginning of training Curriculum (2/2): incremental learning. Run the attention model on the paragraph images N times (e.g. 30 times) during the first epoch, and train to output the first N characters (don't add EOS here). Then, in the second epoch, train on the first 2N characters, etc. Truncated BPTT to avoid memory issues
19 Text Lines

20 Learning Line Breaks
21 Paragraph Recognition

22 Results (Character Error Rate / IAM)

23 Encoder s Activations
24 Pros & Cons Can potentially handle any reading order Can output character sequences of any length Can recognize paragraphs (and maybe complete document?) Very slow (one fprop in the attention network and decoder for each character = about 500 times for a complete paragraph) + Requires a lot of memory during training (same reasons) How to integrate with language models? Not quite close to state-of-the-art performance on paragraphs (for now...)

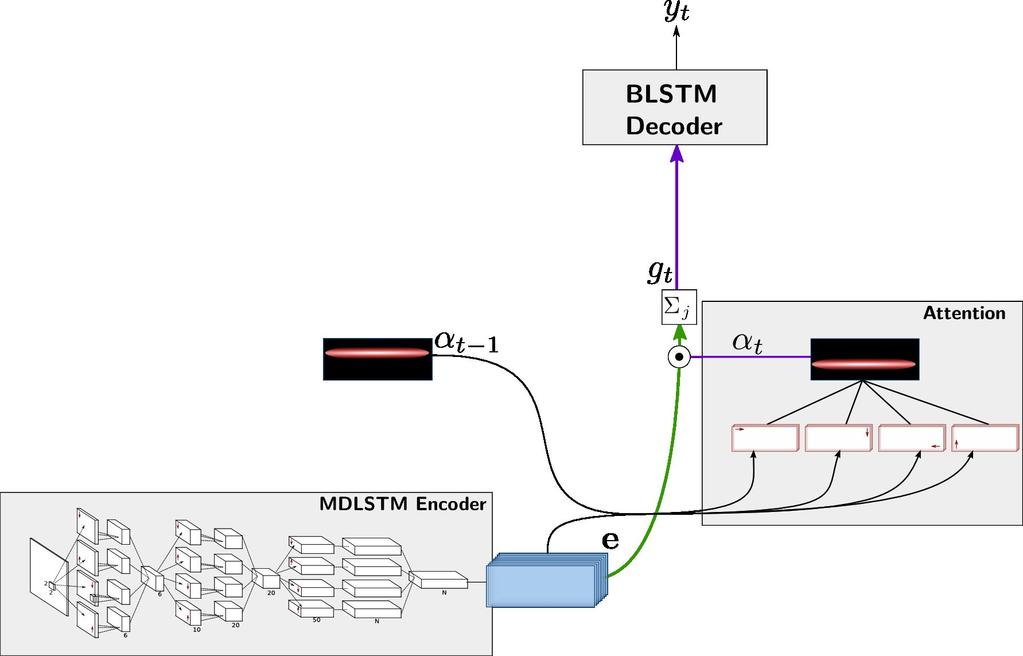
25 Joint Line Segmentation and Transcription The previous model is too slow and time consuming Because of one costly operation for each character Idea of this model : one timestep per line i.e. put attention on text lines = reduced from 500+ to ~10 timesteps
 Modified attention to output full")

26 Network s architecture Similar Architecture (encoder, attention, decoder) Modified attention to output full lines : softmax on lines + collapse No state BLSTM decoder that can model linguistic dependencies across text lines
 Otherwise CTC at the paragraph level Less tricks required to train (only pretraining and 1 epoch on")
27 Training In this model we have more predictions than characters CTC If the line breaks are known CTC on each segment (attention step) Otherwise CTC at the paragraph level Less tricks required to train (only pretraining and 1 epoch on two-line inputs)

28 Qualitative Results
 line segmentation With the proposed model, they are even lower than when using ground-truth")
29 Comparison with Explicit Line Segmentation Because of segmentation errors, CERs increase with automatic (explicit) line segmentation With the proposed model, they are even lower than when using ground-truth positions

30 Comparison with Explicit Line Segmentation partly because the BLSTM decoder can model dependencies across text lines BLSTM after collapse but limited to textlines BLSTM after attention on full paragraphs
31 Processing Times On average, the first method (Scan, Attend and Read) is 100x slower than recognition from known text lines 30x slower than a standard segment+reco pipeline The second method is 30-40x faster than the first one (expected from fewer attention steps) about the same speed as a standard segment+reco pipeline
32 Final Results
33 Pros & Cons Much faster than "Scan, Attend and Read" Easier paragraph training Results are competitive with state-of-the-art models The attention spans the whole image width, so the method is limited to paragraphs (not full, complex, documents) The reading order is not learnt
34 Conclusions & Challenges Inspired from recent advances in deep learning Attention-based model for end-to-end paragraph recognition A model that can learn reading order (but difficult to train) A faster model that implicitly performs line segmentation Could be trained with limited data (only Rimes or IAM ) Challenges: How to define attention to smaller blocks to recognize full, complex documents? How do we get training data / evaluation in that context? How to make the models faster / more efficient?
35 Thanks! Gracias! Questions /Discussion Theodore Bluche

36 Scan, Attend and Read
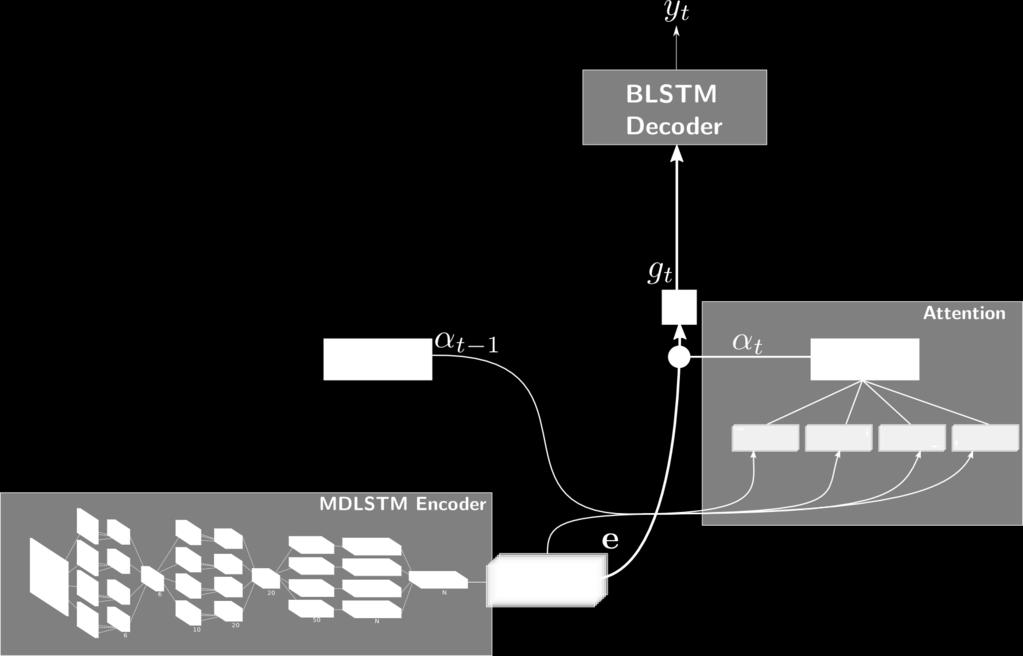
37
Dropout improves Recurrent Neural Networks for Handwriting Recognition
 2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation
 2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Offline Writer Identification Using Convolutional Neural Network Activation Features
 Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках
 Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Large Kindergarten Centers Icons
 Large Kindergarten Centers Icons To view and print each center icon, with CCSD objectives, please click on the corresponding thumbnail icon below. ABC / Word Study Read the Room Big Book Write the Room
Large Kindergarten Centers Icons To view and print each center icon, with CCSD objectives, please click on the corresponding thumbnail icon below. ABC / Word Study Read the Room Big Book Write the Room
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Hardhatting in a Geo-World
 Hardhatting in a Geo-World TM Developed and Published by AIMS Education Foundation This book contains materials developed by the AIMS Education Foundation. AIMS (Activities Integrating Mathematics and
Hardhatting in a Geo-World TM Developed and Published by AIMS Education Foundation This book contains materials developed by the AIMS Education Foundation. AIMS (Activities Integrating Mathematics and
Accelerated Learning Online. Course Outline
 Accelerated Learning Online Course Outline Course Description The purpose of this course is to make the advances in the field of brain research more accessible to educators. The techniques and strategies
Accelerated Learning Online Course Outline Course Description The purpose of this course is to make the advances in the field of brain research more accessible to educators. The techniques and strategies
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Longest Common Subsequence: A Method for Automatic Evaluation of Handwritten Essays
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 6, Ver. IV (Nov Dec. 2015), PP 01-07 www.iosrjournals.org Longest Common Subsequence: A Method for
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 6, Ver. IV (Nov Dec. 2015), PP 01-07 www.iosrjournals.org Longest Common Subsequence: A Method for
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
The Conversational User Interface
 The Conversational User Interface Ronald Kaplan Nuance Sunnyvale NL/AI Lab Department of Linguistics, Stanford May, 2013 ron.kaplan@nuance.com GUI: The problem Extensional 2 CUI: The solution Intensional
The Conversational User Interface Ronald Kaplan Nuance Sunnyvale NL/AI Lab Department of Linguistics, Stanford May, 2013 ron.kaplan@nuance.com GUI: The problem Extensional 2 CUI: The solution Intensional
Large vocabulary off-line handwriting recognition: A survey
 Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Stages of Literacy Ros Lugg
 Beginning readers in the USA Stages of Literacy Ros Lugg Looked at predictors of reading success or failure Pre-readers readers aged 3-53 5 yrs Looked at variety of abilities IQ Speech and language abilities
Beginning readers in the USA Stages of Literacy Ros Lugg Looked at predictors of reading success or failure Pre-readers readers aged 3-53 5 yrs Looked at variety of abilities IQ Speech and language abilities
arxiv: v1 [math.at] 10 Jan 2016
![arxiv: v1 [math.at] 10 Jan 2016](/thumbs/72/66271209.jpg "arxiv: v1 [math.at] 10 Jan 2016") THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Predicting Future User Actions by Observing Unmodified Applications
 From: AAAI-00 Proceedings. Copyright 2000, AAAI (www.aaai.org). All rights reserved. Predicting Future User Actions by Observing Unmodified Applications Peter Gorniak and David Poole Department of Computer
From: AAAI-00 Proceedings. Copyright 2000, AAAI (www.aaai.org). All rights reserved. Predicting Future User Actions by Observing Unmodified Applications Peter Gorniak and David Poole Department of Computer
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Moodle 2 Assignments. LATTC Faculty Technology Training Tutorial
 LATTC Faculty Technology Training Tutorial Moodle 2 Assignments This tutorial begins with the instructor already logged into Moodle 2. http://moodle.lattc.edu/ Faculty login id is same as email login id.
LATTC Faculty Technology Training Tutorial Moodle 2 Assignments This tutorial begins with the instructor already logged into Moodle 2. http://moodle.lattc.edu/ Faculty login id is same as email login id.
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Running Head: STUDENT CENTRIC INTEGRATED TECHNOLOGY
 SCIT Model 1 Running Head: STUDENT CENTRIC INTEGRATED TECHNOLOGY Instructional Design Based on Student Centric Integrated Technology Model Robert Newbury, MS December, 2008 SCIT Model 2 Abstract The ADDIE
SCIT Model 1 Running Head: STUDENT CENTRIC INTEGRATED TECHNOLOGY Instructional Design Based on Student Centric Integrated Technology Model Robert Newbury, MS December, 2008 SCIT Model 2 Abstract The ADDIE
Extending Place Value with Whole Numbers to 1,000,000
 Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
Types of curriculum. Definitions of the different types of curriculum
 Types of Definitions of the different types of Leslie Owen Wilson. Ed. D. Contact Leslie When I asked my students what means to them, they always indicated that it means the overt or written thinking of
Types of Definitions of the different types of Leslie Owen Wilson. Ed. D. Contact Leslie When I asked my students what means to them, they always indicated that it means the overt or written thinking of
CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS
 CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS Pirjo Moen Department of Computer Science P.O. Box 68 FI-00014 University of Helsinki pirjo.moen@cs.helsinki.fi http://www.cs.helsinki.fi/pirjo.moen
CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS Pirjo Moen Department of Computer Science P.O. Box 68 FI-00014 University of Helsinki pirjo.moen@cs.helsinki.fi http://www.cs.helsinki.fi/pirjo.moen
How to read a Paper ISMLL. Dr. Josif Grabocka, Carlotta Schatten
 How to read a Paper ISMLL Dr. Josif Grabocka, Carlotta Schatten Hildesheim, April 2017 1 / 30 Outline How to read a paper Finding additional material Hildesheim, April 2017 2 / 30 How to read a paper How
How to read a Paper ISMLL Dr. Josif Grabocka, Carlotta Schatten Hildesheim, April 2017 1 / 30 Outline How to read a paper Finding additional material Hildesheim, April 2017 2 / 30 How to read a paper How
Missouri Mathematics Grade-Level Expectations
 A Correlation of to the Grades K - 6 G/M-223 Introduction This document demonstrates the high degree of success students will achieve when using Scott Foresman Addison Wesley Mathematics in meeting the
A Correlation of to the Grades K - 6 G/M-223 Introduction This document demonstrates the high degree of success students will achieve when using Scott Foresman Addison Wesley Mathematics in meeting the
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Distributed Learning of Multilingual DNN Feature Extractors using GPUs
 Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
GACE Computer Science Assessment Test at a Glance
 GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Page 1 of 11. Curriculum Map: Grade 4 Math Course: Math 4 Sub-topic: General. Grade(s): None specified
: None specified") Curriculum Map: Grade 4 Math Course: Math 4 Sub-topic: General Grade(s): None specified Unit: Creating a Community of Mathematical Thinkers Timeline: Week 1 The purpose of the Establishing a Community
Curriculum Map: Grade 4 Math Course: Math 4 Sub-topic: General Grade(s): None specified Unit: Creating a Community of Mathematical Thinkers Timeline: Week 1 The purpose of the Establishing a Community
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Firms and Markets Saturdays Summer I 2014
 PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
Education: Integrating Parallel and Distributed Computing in Computer Science Curricula
 IEEE DISTRIBUTED SYSTEMS ONLINE 1541-4922 2006 Published by the IEEE Computer Society Vol. 7, No. 2; February 2006 Education: Integrating Parallel and Distributed Computing in Computer Science Curricula
IEEE DISTRIBUTED SYSTEMS ONLINE 1541-4922 2006 Published by the IEEE Computer Society Vol. 7, No. 2; February 2006 Education: Integrating Parallel and Distributed Computing in Computer Science Curricula
Florida Reading Endorsement Alignment Matrix Competency 1
 Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
A Handwritten French Dataset for Word Spotting - CFRAMUZ
 A Handwritten French Dataset for Word Spotting - CFRAMUZ Nikolaos Arvanitopoulos School of Computer and Communication Sciences (IC) Ecole Polytechnique Federale de Lausanne (EPFL) nick.arvanitopoulos@epfl.ch
A Handwritten French Dataset for Word Spotting - CFRAMUZ Nikolaos Arvanitopoulos School of Computer and Communication Sciences (IC) Ecole Polytechnique Federale de Lausanne (EPFL) nick.arvanitopoulos@epfl.ch