Interactive Approaches to Video Lecture Assessment
|
|
|
- Dora Fisher
- 5 years ago
- Views:
Transcription

1 Interactive Approaches to Video Lecture Assessment August 13, 2012 Korbinian Riedhammer Group Pattern Lab
2 Motivation 2
3
4
5
6
7 key phrases of the phrase occurrences Search spoken text
8 Outline Data Acquisition Textual Summary
9 Data Acquisition
10 LMELectures A Corpus of Academic Spoken English Two lecture series read in 2009 Pattern Analysis (PA) Interventional Medical Image Processing (IMIP) 18 recordings per series About 40 hours of audio/video data Audio: 48 khz, 16 bit (AIFF), resampled to 16 khz Video: HD, reduced resolutions available due to bandwidth Clip-on cordless speaker microphone, room microphones Constant recording setting RRZE E-Studio Single speaker Same recording equipment 10
11 Transcription Semi-automatic segmentation into speech turns Based on speech pauses and silences 23,857 turns Average duration of 4.4 seconds Total of about 29 hours of speech Manual transcription New tool for the rapid transcription of speech Time effort: about 5 times real time Transcription results On average 14 words per speech turn 300,500 words transcribed Vocabulary size: 5,383 (excluding foreign words and word fragments) 11
12 Annotations Individual lecture PA06 Based on edited manual transcript 5 human subjects 20 phrases Salience: from 1 (very relevant) to 6 (useless) Further annotations Lecturer s key terms for series PA Presentation slides in PDF format 12
13 Data Acquisition
14 The Kaldi Toolkit State of the art, open source 4-layer system modeled by weighted finite state transducers (WFST) Statistical n-gram language model Lexicon with pronunciation alternatives Context dependent phonemes Hidden Markov models Acoustic frontend Mel-frequency cepstral coefficients (MFCC), 1 st and 2 nd order derivatives Phoneme dependent linear transformations Acoustic modeling: subspace Gaussian mixture models 14
15 The LMELectures System 600 Gaussian components, 5,500 HMM states Vocabulary size: 5,383 Language model 5,370,040 bi- and tri-grams Trained on 500+ million words (including spontaneous lecture speech) Name Duration # Turns # Words % WER train 25h 31m 20, ,536 - development 2h 07m 1,802 21, test 2h 12m 1,750 23, WER: word error rate 15
16 Data Acquisition
17 Candidate Selection A verb alone may be vague discuss what? An isolated noun may be ambiguous question difficult or easy? Information about the topic is often in the noun phrase He asked a difficult question about the modified processing of words. Apply part-of-speech tagging Extract noun phrases based on regular expression 17

 + )* ADJ NN NUM AR ADJ NN")
18 Example it computes the principal axes that s the one d axis PRP VBZ AR ADJ NN IN VBZ AR NUM NN NN that shows the highest spread of the points IN VBZ AR ADJ NN AR AR NN adjective* (noun,number) + (article + adjective* (noun,number) + )* ADJ NN NUM AR ADJ NN NUM 18
19 Example it computes the principal axes that s the one d axis that shows the highest spread of the points axes principal axes one d axis one d d axis spread highest spread points spread of the points highest spread of the points 19
20 Unsupervised Frequent phrases may be salient With a similar occurrence count, longer phrases may be more salient Motivated by Didactics: less confusion by literal repetition Psycholinguistics: lexical entrainment weight phrase f =, n = 1 f (n + 1), n > 1 Data and domain independent: simple and reliable Other investigated strategies include prior world or domain knowledge 20
21 Comparison of s Compare a target ranking against a reference (human) ranking Standard measure: Normalized Distributed Cumulative Gain Award credit for placing valuable phrases at high ranks Compare lists of a certain length, e.g., top 10 phrases Phrases annotated with salience from 1 (very useful) to 6 (useless) gain phrase = 2 ( )/ 1 NDCG N = C gain(phrase ) ld (1 + i) 21
22 Multiple Annotators Objective Results NDCG for pair-wise comparison only 5 human annotators Human score average NDCG value of all human-human pairings 20 individual pairings score average NDCG value for all human-machine pairings 5 individual pairings Scores based on manual (TRL) and automatic (ASR) transcripts 22
23 Evaluation of Human and s NDCG human automatic/trl automatic/asr Only small differences due to ASR errors 0.6 Similar quality 0.5 of human and automatic 1 ranking Number of phrases considered Fairly high human average agreement 23
24 Data Acquisition

25 Motivation Key phrases give a topical overview of the lecture Phrase occurrences can serve as a visual index or navigation aid Simple example: clickable occurrence bar 25
 Stream wideness: Current phrase dominance Dominance: Number of occurrences within certain time")
26 StreamGraphs Popular in the visualization community Stacked splines Left to right: Playback time (as with occurrence bar) Stream wideness: Current phrase dominance Dominance: Number of occurrences within certain time frame 26
27 Advantages Comfortably display 3 to 6 phrases simultaneously Stream width can suggest topical relations of phrases Similar widths at the same time indicate co-occurrence possibly related Different widths indicate rare or no co-occurrence possibly unrelated User Interactions Click into the stream jump to closest occurrence Change the phrases on display learn about topics and relations Interactions can be logged to collect data for customized rankings 27
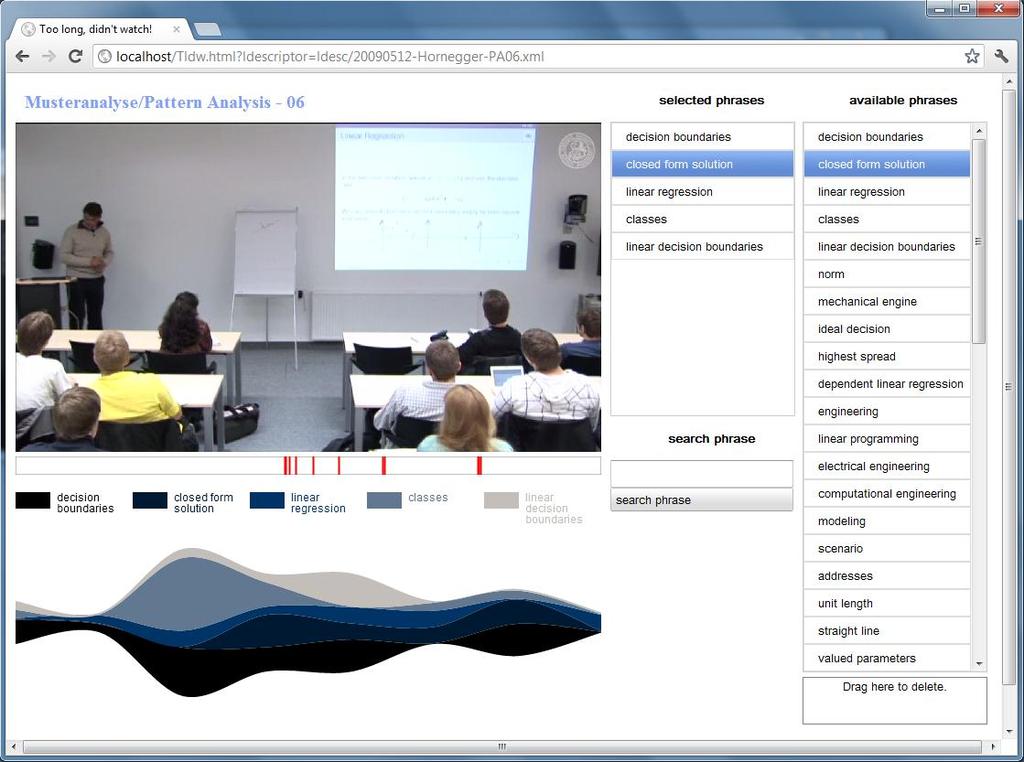
28
29 Implementation Details 29

30 User Study
31 Task Based Evaluation Typical scenario: preparation for an exam Task should be independent of prior knowledge and comprehension Locate those segments of the video that cover certain topics Two groups of CS graduate students test and control Familiar with topic, speaker and lecture 5 subjects per group Each participant is provided with 3 lecture topics with short description Control group: Video only Test group: the presented interface Post-use questionnaire for test group to gather feedback 31
32 Results Group Accuracy Average time Control 68 % 30 Test 69 % 21 average time in minutes Both groups have a similar accuracy Video duration: 42 minutes The test group was on average about 29% faster Most users found the interface to be helpful and easy to use key phrase visualization to give a good overview 32
33 Summary Data Acquisition LMELectures, a new corpus of academic spoken English Extraction & speech recognition system for the LMELectures with a word error rate of 11% Unsupervised key phrase extraction and ranking that highly correlates to human rankings Novel video lecture browser that helps students to quickly assess the contents 33
34 Outlook Data Acquisition Extraction & More transcriptions for better acoustic and language models Integration of prior knowledge about speaker, room and topic Supervised methods for user-tailored rankings Larger user study on more lectures 34
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Intra-talker Variation: Audience Design Factors Affecting Lexical Selections
 Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Longman English Interactive
 Longman English Interactive Level 3 Orientation Quick Start 2 Microphone for Speaking Activities 2 Course Navigation 3 Course Home Page 3 Course Overview 4 Course Outline 5 Navigating the Course Page 6
Longman English Interactive Level 3 Orientation Quick Start 2 Microphone for Speaking Activities 2 Course Navigation 3 Course Home Page 3 Course Overview 4 Course Outline 5 Navigating the Course Page 6
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Speech Translation for Triage of Emergency Phonecalls in Minority Languages
 Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Vimala.C Project Fellow, Department of Computer Science Avinashilingam Institute for Home Science and Higher Education and Women Coimbatore, India
 World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Formulaic Language and Fluency: ESL Teaching Applications
 Formulaic Language and Fluency: ESL Teaching Applications Formulaic Language Terminology Formulaic sequence One such item Formulaic language Non-count noun referring to these items Phraseology The study
Formulaic Language and Fluency: ESL Teaching Applications Formulaic Language Terminology Formulaic sequence One such item Formulaic language Non-count noun referring to these items Phraseology The study
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Think A F R I C A when assessing speaking. C.E.F.R. Oral Assessment Criteria. Think A F R I C A - 1 -
 C.E.F.R. Oral Assessment Criteria Think A F R I C A - 1 - 1. The extracts in the left hand column are taken from the official descriptors of the CEFR levels. How would you grade them on a scale of low,
C.E.F.R. Oral Assessment Criteria Think A F R I C A - 1 - 1. The extracts in the left hand column are taken from the official descriptors of the CEFR levels. How would you grade them on a scale of low,
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
DOES RETELLING TECHNIQUE IMPROVE SPEAKING FLUENCY?
 DOES RETELLING TECHNIQUE IMPROVE SPEAKING FLUENCY? Noor Rachmawaty (itaw75123@yahoo.com) Istanti Hermagustiana (dulcemaria_81@yahoo.com) Universitas Mulawarman, Indonesia Abstract: This paper is based
DOES RETELLING TECHNIQUE IMPROVE SPEAKING FLUENCY? Noor Rachmawaty (itaw75123@yahoo.com) Istanti Hermagustiana (dulcemaria_81@yahoo.com) Universitas Mulawarman, Indonesia Abstract: This paper is based
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC PP. VI, 282)
 (LONDON, BLOOMSBURY ACADEMIC PP. VI, 282)") B. PALTRIDGE, DISCOURSE ANALYSIS: AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC. 2012. PP. VI, 282) Review by Glenda Shopen _ This book is a revised edition of the author s 2006 introductory
B. PALTRIDGE, DISCOURSE ANALYSIS: AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC. 2012. PP. VI, 282) Review by Glenda Shopen _ This book is a revised edition of the author s 2006 introductory
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
THE VERB ARGUMENT BROWSER
 THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
Affective Classification of Generic Audio Clips using Regression Models
 Affective Classification of Generic Audio Clips using Regression Models Nikolaos Malandrakis 1, Shiva Sundaram, Alexandros Potamianos 3 1 Signal Analysis and Interpretation Laboratory (SAIL), USC, Los
Affective Classification of Generic Audio Clips using Regression Models Nikolaos Malandrakis 1, Shiva Sundaram, Alexandros Potamianos 3 1 Signal Analysis and Interpretation Laboratory (SAIL), USC, Los
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) Feb 2015
 Feb 2015") Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
BULATS A2 WORDLIST 2
 BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
Secondary English-Language Arts
 Secondary English-Language Arts Assessment Handbook January 2013 edtpa_secela_01 edtpa stems from a twenty-five-year history of developing performance-based assessments of teaching quality and effectiveness.
Secondary English-Language Arts Assessment Handbook January 2013 edtpa_secela_01 edtpa stems from a twenty-five-year history of developing performance-based assessments of teaching quality and effectiveness.
ENGBG1 ENGBL1 Campus Linguistics. Meeting 2. Chapter 7 (Morphology) and chapter 9 (Syntax) Pia Sundqvist
 and chapter 9 (Syntax) Pia Sundqvist") Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
CEFR Overall Illustrative English Proficiency Scales
 CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS
 ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
REVIEW OF CONNECTED SPEECH
 Language Learning & Technology http://llt.msu.edu/vol8num1/review2/ January 2004, Volume 8, Number 1 pp. 24-28 REVIEW OF CONNECTED SPEECH Title Connected Speech (North American English), 2000 Platform
Language Learning & Technology http://llt.msu.edu/vol8num1/review2/ January 2004, Volume 8, Number 1 pp. 24-28 REVIEW OF CONNECTED SPEECH Title Connected Speech (North American English), 2000 Platform
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2
 Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
READ 180 Next Generation Software Manual
 READ 180 Next Generation Software Manual including ereads For use with READ 180 Next Generation version 2.3 and Scholastic Achievement Manager version 2.3 or higher Copyright 2014 by Scholastic Inc. All
READ 180 Next Generation Software Manual including ereads For use with READ 180 Next Generation version 2.3 and Scholastic Achievement Manager version 2.3 or higher Copyright 2014 by Scholastic Inc. All
Characterizing and Processing Robot-Directed Speech
 Characterizing and Processing Robot-Directed Speech Paulina Varchavskaia, Paul Fitzpatrick, Cynthia Breazeal AI Lab, MIT, Cambridge, USA [paulina,paulfitz,cynthia]@ai.mit.edu Abstract. Speech directed
Characterizing and Processing Robot-Directed Speech Paulina Varchavskaia, Paul Fitzpatrick, Cynthia Breazeal AI Lab, MIT, Cambridge, USA [paulina,paulfitz,cynthia]@ai.mit.edu Abstract. Speech directed
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Houghton Mifflin Reading Correlation to the Common Core Standards for English Language Arts (Grade1)
") Houghton Mifflin Reading Correlation to the Standards for English Language Arts (Grade1) 8.3 JOHNNY APPLESEED Biography TARGET SKILLS: 8.3 Johnny Appleseed Phonemic Awareness Phonics Comprehension Vocabulary
Houghton Mifflin Reading Correlation to the Standards for English Language Arts (Grade1) 8.3 JOHNNY APPLESEED Biography TARGET SKILLS: 8.3 Johnny Appleseed Phonemic Awareness Phonics Comprehension Vocabulary
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Learning Disability Functional Capacity Evaluation. Dear Doctor,
 Dear Doctor, I have been asked to formulate a vocational opinion regarding NAME s employability in light of his/her learning disability. To assist me with this evaluation I would appreciate if you can
Dear Doctor, I have been asked to formulate a vocational opinion regarding NAME s employability in light of his/her learning disability. To assist me with this evaluation I would appreciate if you can
Edexcel GCSE. Statistics 1389 Paper 1H. June Mark Scheme. Statistics Edexcel GCSE
 Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Creating Travel Advice
 Creating Travel Advice Classroom at a Glance Teacher: Language: Grade: 11 School: Fran Pettigrew Spanish III Lesson Date: March 20 Class Size: 30 Schedule: McLean High School, McLean, Virginia Block schedule,
Creating Travel Advice Classroom at a Glance Teacher: Language: Grade: 11 School: Fran Pettigrew Spanish III Lesson Date: March 20 Class Size: 30 Schedule: McLean High School, McLean, Virginia Block schedule,
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty
 Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
An Evaluation of POS Taggers for the CHILDES Corpus
 City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data
 Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data Maja Popović and Hermann Ney Lehrstuhl für Informatik VI, Computer
Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data Maja Popović and Hermann Ney Lehrstuhl für Informatik VI, Computer
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
OPAC and User Perception in Law University Libraries in the Karnataka: A Study
 ISSN 2229-5984 (P) 29-5576 (e) OPAC and User Perception in Law University Libraries in the Karnataka: A Study Devendra* and Khaiser Nikam** To Cite: Devendra & Nikam, K. (20). OPAC and user perception
ISSN 2229-5984 (P) 29-5576 (e) OPAC and User Perception in Law University Libraries in the Karnataka: A Study Devendra* and Khaiser Nikam** To Cite: Devendra & Nikam, K. (20). OPAC and user perception
Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form
 Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company
 Houghton Mifflin Harcourt Publishing Company") WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES. Judith Gaspers and Philipp Cimiano
 LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES Judith Gaspers and Philipp Cimiano Semantic Computing Group, CITEC, Bielefeld University {jgaspers cimiano}@cit-ec.uni-bielefeld.de ABSTRACT Semantic parsers
LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES Judith Gaspers and Philipp Cimiano Semantic Computing Group, CITEC, Bielefeld University {jgaspers cimiano}@cit-ec.uni-bielefeld.de ABSTRACT Semantic parsers
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger
 Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
First Grade Curriculum Highlights: In alignment with the Common Core Standards
 First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Making the ELPS-TELPAS Connection Grades K 12 Overview
 Making the ELPS-TELPAS Connection Grades K 12 Overview 2017-2018 Texas Education Agency Student Assessment Division. Disclaimer These slides have been prepared by the Student Assessment Division of the
Making the ELPS-TELPAS Connection Grades K 12 Overview 2017-2018 Texas Education Agency Student Assessment Division. Disclaimer These slides have been prepared by the Student Assessment Division of the
Evaluation of a Simultaneous Interpretation System and Analysis of Speech Log for User Experience Assessment
 Evaluation of a Simultaneous Interpretation System and Analysis of Speech Log for User Experience Assessment Akiko Sakamoto, Kazuhiko Abe, Kazuo Sumita and Satoshi Kamatani Knowledge Media Laboratory,
Evaluation of a Simultaneous Interpretation System and Analysis of Speech Log for User Experience Assessment Akiko Sakamoto, Kazuhiko Abe, Kazuo Sumita and Satoshi Kamatani Knowledge Media Laboratory,
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
Appendix L: Online Testing Highlights and Script
 Online Testing Highlights and Script for Fall 2017 Ohio s State Tests Administrations Test administrators must use this document when administering Ohio s State Tests online. It includes step-by-step directions,
Online Testing Highlights and Script for Fall 2017 Ohio s State Tests Administrations Test administrators must use this document when administering Ohio s State Tests online. It includes step-by-step directions,
Using SAM Central With iread
 Using SAM Central With iread January 1, 2016 For use with iread version 1.2 or later, SAM Central, and Student Achievement Manager version 2.4 or later PDF0868 (PDF) Houghton Mifflin Harcourt Publishing
Using SAM Central With iread January 1, 2016 For use with iread version 1.2 or later, SAM Central, and Student Achievement Manager version 2.4 or later PDF0868 (PDF) Houghton Mifflin Harcourt Publishing
Introduction to HPSG. Introduction. Historical Overview. The HPSG architecture. Signature. Linguistic Objects. Descriptions.
 to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global