Spoken Language Recognition
|
|
|
- Felicia Goodman
- 5 years ago
- Views:
Transcription

1 Spoken Language Recognition Based on Spoken Language Recognition: From Fundamentals to Practice Haizhou Li; Bin Ma; Kong Aik Lee Stanisław Kacprzak , Kraków, Seminarium DSP
2 Problem definition Given a spoken observation utterance O and set L of target languages we have to decide: Language Recognition / Language Identification (LID) Which of the N languages does O belong to? Language Verification Does O belong to language Li or to the other languages?
3 Why do we need language recogniton? Multilanguage spoken dialog systems (e.g., iformational terminals) Database, archive-search and retrieval systems Human-human communication systems (call-routing, automatic translation, emergency calls) [2]
4 Why do we need language recogniton? 1973: Australia introduces telephone interpretation as a fee-free service to respond to its growing immigrant communities. 1981: The first Over-the-Phone Interpretation (OPI) service is offered in the United States : Telephone interpretation enters major U.S. industries including financial services, telecommunications, healthcare, and public safety. 1990's: The demand for telephone interpretation grows significantly; contributing factors include decreased prices in long distance calls, toll-free number access, and immigration trends. 1995: Language services company Kevmark, later known as CyraCom, patents a multiple-handset phone adapted for telephone interpreting. 1999: AT&T sells language services company Language Line Services. 2000's: Telephone interpretation becomes more sophisticated; quality of interpretation, faster connection speeds, and customer service become important to consumers. 2005: The U.S. telephone interpreting market is estimated at approximately $200 million. 2013: Language Lines Services acquires Pacific Interpreters.


5 Real life example! The company employs approximately 5,000 interpreters and support staff globally who answer 40 million calls each year. [3]
6 How people do it? It was concluded that human beings, with adequate training, are the most accurate language recognizers. This observation still holds after 15 years as confirmed again, provided that the human listeners speak the languages. For languages that they are not familiar with, human listeners can often make subjective judgments with reference to the languages they know, e.g., it sounds like German. This judgments are less precise but show how people apply linguistic knowledge at different levels for distinguishing between certain broad language groups Given only little previous exposure, human listeners can effectively identify a lan-guage without much lexical knowledge. In this case, human listeners rely on prominent phonetic, phonotactic, and prosody cues to characterize the languages.

7 Perceptual cues used for language recognition
8 Perceptual cues used for language recognition The use of phonetic and phonotactic cues is based on the assumption that languages possess partially overlapping sets of phonemes. (Though there are over 6k languages in the world, the total number of phones required to represent all the sounds of these languages ranges only from 200 to 300)

9 Phonotactics cues We can study the phonotactic differences between languages by examining how well a phone n-gram model of one language predicts the phone sequence across different languages in terms of perplexity. A lower perplexity shows that a phone n-gram matches better the phone sequence, in other words, the phone sequence is more predictable.
 Acoustic-phonetic apprach example SDC (Shifted Delata Cepstral")
10 General scheme of acoustic -phonetic and phonotactic approaches Phonotatic approach example PRLM (Phone recognition and language modeling) Acoustic-phonetic apprach example SDC (Shifted Delata Cepstral coefficients)
11 Shift Delta Cepstral coefficients (SDC)

12 Parralel PRLM
13 Vector Space Modeling (VSC)
14 Vector Space Modeling in acoustic-phonetic appraches Creation of supervector m by stacking mean vectors from of all adopted mixture components derived from GMM-UBM. Kullback-Leibler (KL) divergence (approximation) KL Kernel function Bhattacharyya kernel
15 Intersession Variability Vocal Tract Length Normalization (VTLN) feature-level latent factor analysis (flfa) U - session variability matrix Feature compenastaions i-vector paradigm T total variablity matrix
16 Corpora The availability of sufficiently large corpora has been the major driving factor in the development of speech technology in recent decades 1990's OGI telephone speech database OGI-11L, OGI-22L Conversational corpora: CallHome (6 languages) CallFriend (12 languages) NIST LREs 1996, 2003, 2005, 2007, 2009, and 2011.
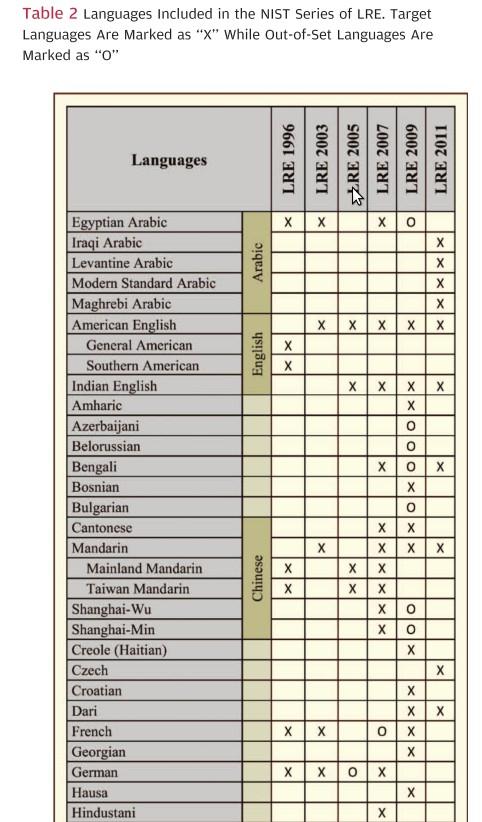
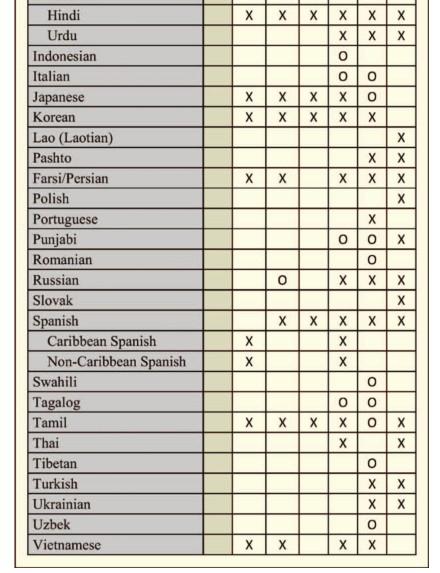
17 NIST LREs
18 Results The MITLL NIST LRE 2011 Language Recognition System [4]
19 Future directions We have not been able to effectively venture beyond acoustic phonetic and phonotactic knowledge, despite the fact that there exists strong evidence in human listening experiments that prosodic information, syllable structure, and morphology are useful knowledge sources.
20 References 1. Haizhou Li; Bin Ma; Kong Aik Lee, "Spoken Language Recognition: From Fundamentals to Practice," Proceedings of the IEEE, vol.101, no.5, pp.1136,1159, May 2013 doi: /JPROC Navratil, Jiri. "Spoken language recognition-a step toward multilinguality in speech processing." Speech and Audio Processing, IEEE Transactions on 9.6 (2001): Singer, Elliot, et al. "The MITLL NIST LRE 2011 language recognition system." Acoustics, Speech and Signal Processing, ICASSP IEEE International Conference on
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Support Vector Machines for Speaker and Language Recognition
 Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Spoofing and countermeasures for automatic speaker verification
 INTERSPEECH 2013 Spoofing and countermeasures for automatic speaker verification Nicholas Evans 1, Tomi Kinnunen 2 and Junichi Yamagishi 3,4 1 EURECOM, Sophia Antipolis, France 2 University of Eastern
INTERSPEECH 2013 Spoofing and countermeasures for automatic speaker verification Nicholas Evans 1, Tomi Kinnunen 2 and Junichi Yamagishi 3,4 1 EURECOM, Sophia Antipolis, France 2 University of Eastern
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
English Language and Applied Linguistics. Module Descriptions 2017/18
 English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Digital Signal Processing: Speaker Recognition Final Report (Complete Version)
") Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY
 MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speaker Recognition For Speech Under Face Cover
 INTERSPEECH 2015 Speaker Recognition For Speech Under Face Cover Rahim Saeidi, Tuija Niemi, Hanna Karppelin, Jouni Pohjalainen, Tomi Kinnunen, Paavo Alku Department of Signal Processing and Acoustics,
INTERSPEECH 2015 Speaker Recognition For Speech Under Face Cover Rahim Saeidi, Tuija Niemi, Hanna Karppelin, Jouni Pohjalainen, Tomi Kinnunen, Paavo Alku Department of Signal Processing and Acoustics,
Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form
 Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
/$ IEEE
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 8, NOVEMBER 2009 1567 Modeling the Expressivity of Input Text Semantics for Chinese Text-to-Speech Synthesis in a Spoken Dialog
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 8, NOVEMBER 2009 1567 Modeling the Expressivity of Input Text Semantics for Chinese Text-to-Speech Synthesis in a Spoken Dialog
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation
 UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Lecture Notes in Artificial Intelligence 4343
 Lecture Notes in Artificial Intelligence 4343 Edited by J. G. Carbonell and J. Siekmann Subseries of Lecture Notes in Computer Science Christian Müller (Ed.) Speaker Classification I Fundamentals, Features,
Lecture Notes in Artificial Intelligence 4343 Edited by J. G. Carbonell and J. Siekmann Subseries of Lecture Notes in Computer Science Christian Müller (Ed.) Speaker Classification I Fundamentals, Features,
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
Acquiring Competence from Performance Data
 Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE
 2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Speech Translation for Triage of Emergency Phonecalls in Minority Languages
 Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
The IRISA Text-To-Speech System for the Blizzard Challenge 2017
 The IRISA Text-To-Speech System for the Blizzard Challenge 2017 Pierre Alain, Nelly Barbot, Jonathan Chevelu, Gwénolé Lecorvé, Damien Lolive, Claude Simon, Marie Tahon IRISA, University of Rennes 1 (ENSSAT),
The IRISA Text-To-Speech System for the Blizzard Challenge 2017 Pierre Alain, Nelly Barbot, Jonathan Chevelu, Gwénolé Lecorvé, Damien Lolive, Claude Simon, Marie Tahon IRISA, University of Rennes 1 (ENSSAT),
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
MMOG Subscription Business Models: Table of Contents
 DFC Intelligence DFC Intelligence Phone 858-780-9680 9320 Carmel Mountain Rd Fax 858-780-9671 Suite C www.dfcint.com San Diego, CA 92129 MMOG Subscription Business Models: Table of Contents November 2007
DFC Intelligence DFC Intelligence Phone 858-780-9680 9320 Carmel Mountain Rd Fax 858-780-9671 Suite C www.dfcint.com San Diego, CA 92129 MMOG Subscription Business Models: Table of Contents November 2007
Demonstration of problems of lexical stress on the pronunciation Turkish English teachers and teacher trainees by computer
 Available online at www.sciencedirect.com Procedia - Social and Behavioral Sciences 46 ( 2012 ) 3011 3016 WCES 2012 Demonstration of problems of lexical stress on the pronunciation Turkish English teachers
Available online at www.sciencedirect.com Procedia - Social and Behavioral Sciences 46 ( 2012 ) 3011 3016 WCES 2012 Demonstration of problems of lexical stress on the pronunciation Turkish English teachers
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment
 Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
Executive Guide to Simulation for Health
 Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
SUPRA-SEGMENTAL FEATURE BASED SPEAKER TRAIT DETECTION
 Odyssey 2014: The Speaker and Language Recognition Workshop 16-19 June 2014, Joensuu, Finland SUPRA-SEGMENTAL FEATURE BASED SPEAKER TRAIT DETECTION Gang Liu, John H.L. Hansen* Center for Robust Speech
Odyssey 2014: The Speaker and Language Recognition Workshop 16-19 June 2014, Joensuu, Finland SUPRA-SEGMENTAL FEATURE BASED SPEAKER TRAIT DETECTION Gang Liu, John H.L. Hansen* Center for Robust Speech
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence
 A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Dialog Act Classification Using N-Gram Algorithms
 Dialog Act Classification Using N-Gram Algorithms Max Louwerse and Scott Crossley Institute for Intelligent Systems University of Memphis {max, scrossley } @ mail.psyc.memphis.edu Abstract Speech act classification
Dialog Act Classification Using N-Gram Algorithms Max Louwerse and Scott Crossley Institute for Intelligent Systems University of Memphis {max, scrossley } @ mail.psyc.memphis.edu Abstract Speech act classification
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Voice conversion through vector quantization
 J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing
 Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Multi-modal Sensing and Analysis of Poster Conversations toward Smart Posterboard
 Multi-modal Sensing and Analysis of Poster Conversations toward Smart Posterboard Tatsuya Kawahara Kyoto University, Academic Center for Computing and Media Studies Sakyo-ku, Kyoto 606-8501, Japan http://www.ar.media.kyoto-u.ac.jp/crest/
Multi-modal Sensing and Analysis of Poster Conversations toward Smart Posterboard Tatsuya Kawahara Kyoto University, Academic Center for Computing and Media Studies Sakyo-ku, Kyoto 606-8501, Japan http://www.ar.media.kyoto-u.ac.jp/crest/
Perceived speech rate: the effects of. articulation rate and speaking style in spontaneous speech. Jacques Koreman. Saarland University
 1 Perceived speech rate: the effects of articulation rate and speaking style in spontaneous speech Jacques Koreman Saarland University Institute of Phonetics P.O. Box 151150 D-66041 Saarbrücken Germany
1 Perceived speech rate: the effects of articulation rate and speaking style in spontaneous speech Jacques Koreman Saarland University Institute of Phonetics P.O. Box 151150 D-66041 Saarbrücken Germany
Dyslexia/dyslexic, 3, 9, 24, 97, 187, 189, 206, 217, , , 367, , , 397,
 Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Introduction. Beáta B. Megyesi. Uppsala University Department of Linguistics and Philology Introduction 1(48)
") Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Phonological and Phonetic Representations: The Case of Neutralization
 Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty
 Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
A new Dataset of Telephone-Based Human-Human Call-Center Interaction with Emotional Evaluation
 A new Dataset of Telephone-Based Human-Human Call-Center Interaction with Emotional Evaluation Ingo Siegert 1, Kerstin Ohnemus 2 1 Cognitive Systems Group, Institute for Information Technology and Communications
A new Dataset of Telephone-Based Human-Human Call-Center Interaction with Emotional Evaluation Ingo Siegert 1, Kerstin Ohnemus 2 1 Cognitive Systems Group, Institute for Information Technology and Communications
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Universal contrastive analysis as a learning principle in CAPT
 Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques
 Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Requirements-Gathering Collaborative Networks in Distributed Software Projects
 Requirements-Gathering Collaborative Networks in Distributed Software Projects Paula Laurent and Jane Cleland-Huang Systems and Requirements Engineering Center DePaul University {plaurent, jhuang}@cs.depaul.edu
Requirements-Gathering Collaborative Networks in Distributed Software Projects Paula Laurent and Jane Cleland-Huang Systems and Requirements Engineering Center DePaul University {plaurent, jhuang}@cs.depaul.edu
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Expressive speech synthesis: a review
 Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Revisiting the role of prosody in early language acquisition. Megha Sundara UCLA Phonetics Lab
 Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Eye Movements in Speech Technologies: an overview of current research
 Eye Movements in Speech Technologies: an overview of current research Mattias Nilsson Department of linguistics and Philology, Uppsala University Box 635, SE-751 26 Uppsala, Sweden Graduate School of Language
Eye Movements in Speech Technologies: an overview of current research Mattias Nilsson Department of linguistics and Philology, Uppsala University Box 635, SE-751 26 Uppsala, Sweden Graduate School of Language
Rachel E. Baker, Ann R. Bradlow. Northwestern University, Evanston, IL, USA
 LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Eyebrows in French talk-in-interaction
 Eyebrows in French talk-in-interaction Aurélie Goujon 1, Roxane Bertrand 1, Marion Tellier 1 1 Aix Marseille Université, CNRS, LPL UMR 7309, 13100, Aix-en-Provence, France Goujon.aurelie@gmail.com Roxane.bertrand@lpl-aix.fr
Eyebrows in French talk-in-interaction Aurélie Goujon 1, Roxane Bertrand 1, Marion Tellier 1 1 Aix Marseille Université, CNRS, LPL UMR 7309, 13100, Aix-en-Provence, France Goujon.aurelie@gmail.com Roxane.bertrand@lpl-aix.fr
Affective Classification of Generic Audio Clips using Regression Models
 Affective Classification of Generic Audio Clips using Regression Models Nikolaos Malandrakis 1, Shiva Sundaram, Alexandros Potamianos 3 1 Signal Analysis and Interpretation Laboratory (SAIL), USC, Los
Affective Classification of Generic Audio Clips using Regression Models Nikolaos Malandrakis 1, Shiva Sundaram, Alexandros Potamianos 3 1 Signal Analysis and Interpretation Laboratory (SAIL), USC, Los
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Age Effects on Syntactic Control in. Second Language Learning
 Age Effects on Syntactic Control in Second Language Learning Miriam Tullgren Loyola University Chicago Abstract 1 This paper explores the effects of age on second language acquisition in adolescents, ages
Age Effects on Syntactic Control in Second Language Learning Miriam Tullgren Loyola University Chicago Abstract 1 This paper explores the effects of age on second language acquisition in adolescents, ages
New Ways of Connecting Reading and Writing
 Sanchez, P., & Salazar, M. (2012). Transnational computer use in urban Latino immigrant communities: Implications for schooling. Urban Education, 47(1), 90 116. doi:10.1177/0042085911427740 Smith, N. (1993).
Sanchez, P., & Salazar, M. (2012). Transnational computer use in urban Latino immigrant communities: Implications for schooling. Urban Education, 47(1), 90 116. doi:10.1177/0042085911427740 Smith, N. (1993).
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.