Speech Recognition Lecture 1: Introduction. Mehryar Mohri Courant Institute and Google Research
|
|
|
- Hollie Armstrong
- 5 years ago
- Views:
Transcription
1 Speech Recognition Lecture 1: Introduction Mehryar Mohri Courant Institute and Google Research
2 Logistics Prerequisites: basics in analysis of algorithms and probability. No specific knowledge about signal processing. Workload: 2-3 homework assignments, 1 project (your choice). Textbooks: no single textbook covering the material presented in this course. Lecture slides available electronically. 2
3 Objectives Computer science view of automatic speech recognition (ASR) (no signal processing). Essential algorithms for large-vocabulary speech recognition. But, emphasis on general algorithms: automata and transducer algorithms. statistical learning algorithms. 3
4 Topics introduction, formulation, components, features. weighted transducer software library. weighted automata algorithms. statistical language modeling software library. ngram models. maximum entropy models. pronunciation models, decision trees, contextdependent models. 4
5 Topics search algorithms, transducer optimizations, Viterbi decoder. search algorithms, N-best algorithms, lattice generation, rescoring. structured prediction algorithms. adaptation. active learning. semi-supervised learning. 5
6 This Lecture Speech recognition problem Statistical formulation Acoustic features 6
7 Speech Recognition Problem Definition: find accurate written transcription of spoken utterances. transcriptions may be in words, phonemes, syllables, or other units. Accuracy: typically measured in terms of the editdistance between reference transcription and sequence output by the model. 7
8 Other Related Problems Speaker verification. Speaker identification. Spoken-dialog systems. Detection of voice features, e.g., gender, age, dialect, emotion, height, weight! Speech synthesis. 8
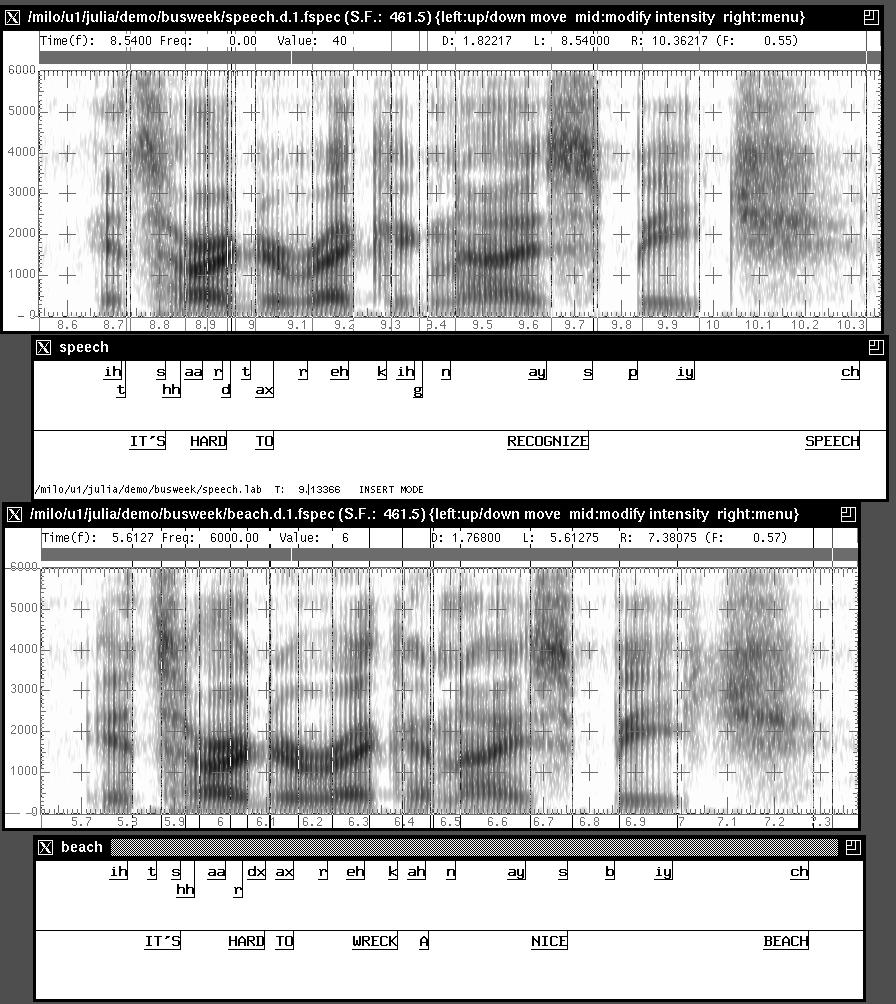
9 Speech Spectogram 9
10 Speech Recognition Is Difficult Highly variable: the same words pronounced by the same person in the same conditions typically lead to different waveforms. source variation: speaking rate, volume, accent, dialect, pitch, coarticulation. channel variation: microphone (type, position), noise (background, distortion). Key problem: robustness to such variations. 10
11 ASR Characteristics Vocabulary size: small (digit recognition, 10), medium (Resource Management, 1000), large (Broadcast News, 100,000), very large (+1M). Speaker-dependent or speaker-independent. Domain-specific or unconstrained, e.g., travel reservation, modern spoken-dialog systems. Isolated (pause between units) or continuous. Read or spontaneous, e.g., dictation, news broadcast, conversational speech. 11

12 Example - Broadcast News 12
13 History See (Juang and Rabiner, 1995) 1922: Radio Rex, toy, single-word recognizer (rex). 1939: voder and vocoder (mechanical synthesizer), Dudley (Bell Labs). 1952: isolated digit recognition, single speaker (Bell Labs). 1950s: 10 syllables of single speaker, Olson and Belar, (RCA Labs). 1950s: speaker-independent 10-vowel recognizer (MIT). 13
14 History 1960s: Linear Predictive Coding (LPC), Atal and Itakura. 1969: John Pierce s negative comments about ASR (Bell Labs). 1970s: Advanced Research Projects Agency (ARPA) funds speech understanding program. CMU s Harpy system based on automata had reasonable accuracy for 1,000 words. 14
15 History 1980s: n-gram models. ARPA Resource Management, Wall Street Journal, and ATIS tasks. Delta/delta-delta cepstra, mel cepstra. mid-1980s: Hidden Markov models (HMMs) become the preferred technique for speech recognition. 1990s: Discriminative training, vocal tract normalization, speaker adaptation. Very largevocabulary speech recognition, e.g., 1M names recognizer (Bell Labs), 500,000 words North American Business News (NAB) recognizer. 15
16 History mid 1990s: FSM library. Weighted transducers major component of almost all modern speech recognition and understanding systems. SVMs, kernel methods. Dictation systems, Dragon, IBM speaker-dependent system. 2000s: Broadcast News, conversational speech, e.g., Switchboard, Call Home, real-time largevocabulary systems, unconstrained spoken-dialog systems, e.g., HMIHY. 16
17 History (Juang and Rabiner, 1995)!"#$%&'($%)"()*+$$,-).(/)!0#&"1'/.#)2$,-('#'34)5$%$.6,-) *1.##) =.%$/!!$/"01) <',.=0#.64>) 2$1+#.&$A =.%$/! B.63$) <',.=0#.64>) *&.&"%&",.#A =.%$/! B.63$) <',.=0#.649) *4(&.C>) *$1.(&",%>)! <$64)B.63$) <',.=0#.649) *$1.(&",%>)!0#&"1'/.#) ;".#'3>)22*! 7%'#.&$/) 8'6/%! 7%'#.&$/)8'6/%9) :'(($,&$/) ;"3"&%9) :'(&"(0'0%) *+$$,- :'(($,&$/) 8'6/%9) :'(&"(0'0%) *+$$,- :'(&"(0'0%) *+$$,-9) *+$$,-) *+'D$()/".#'39)!0#&"+#$) 1'/.#"&"$% )*+,-./0123! *56! 7*8-/ *:1,*926! ;4218*<! *56! A+B5,-.*2>! 0B*+E*2>6 G*EE-2!H1.39D!!! 89E-+56!!!!!!!!! 89E-+*2>6 F,9<C15,*<!+12>B1>-! B2E-.5,12E*2>6! )*2*,-/5,1,-! 81<C*2-56!! F,1,*5,*<1+!+-1.2*2>6! A92<1,-21,*D-! 542,C-5*56!H1<C*2-! +-1.2*2>6!!H*I-E/ '#!N:604A' 17

18 Unscontrained Spoken-Dialog Systems 18
19 This Lecture Speech recognition problem Statistical formulation Acoustic features 19
20 This Lecture Speech recognition problem Statistical formulation Maximum likelihood and maximum a posteriori Statistical formulation of speech recognition Components of a speech recognizer Acoustic features 20
21 Problem Data: sample drawn i.i.d. from set some distribution D, x 1,...,x m X. X according to Problem: find distribution p out of a set P that best estimates D. 21
22 Maximum Likelihood Likelihood: probability of observing sample under distribution p P, which, given the independence assumption is m Pr[x 1,...,x m ]= p(x i ). Principle: select distribution maximizing sample probability m p = argmax p(x i ), p P i=1 m or p = argmax log p(x i ). p P i=1 i=1 22
23 Example: Bernoulli Trials Problem: find most likely Bernoulli distribution, given sequence of coin flips H, T, T, H, T, H, T, H, H, H, T, T,..., H. Bernoulli distribution: p(h) =θ, p(t )=1 θ. dl(p) dθ Likelihood: Solution: l = N(H) θ l(p) = log θ N(H) (1 θ) N(T ) = N(H) log θ + N(T ) log(1 θ). is differentiable and concave; N(T ) 1 θ =0 θ = N(H) N(H)+N(T ). 23
24 Example: Gaussian Distribution Problem: find most likely Gaussian distribution, given sequence of real-valued observations Normal distribution: Likelihood: Solution: p(x) µ =0 µ = 1 m l 3.18, 2.35,.95, 1.175,... ( 1 p(x) = exp (x µ)2 2πσ 2 2σ 2 l(p) = 1 m 2 m (x i µ) 2 log(2πσ2 ) 2σ 2. is differentiable and concave; m i=1 x i p(x) σ 2 i=1 =0 σ 2 = 1 m ) m x 2 i µ 2. i=1. 24
25 Properties Problems: the underlying distribution may not be among those searched. overfitting: number of examples too small wrt number of parameters. 25
26 Maximum A Posteriori (MAP) Principle: select the most likely hypothesis h H given the sample, with some prior distribution over the hypotheses, Pr[h], h = argmax h H = argmax h H = argmax h H Pr[h S] Pr[S h] Pr[h] Pr[S] Pr[S h]pr[h]. Note: for a uniform prior, MAP coincides with maximum likelihood. 26
27 This Lecture Speech recognition problem Statistical formulation Maximum likelihood and maximum a posteriori Statistical formulation of speech recognition Components of a speech recognizer Acoustic features 27
28 General Ideas Probabilistic formulation: given a spoken utterance, find the most likely transcription. Decomposition: mapping from spoken utterances to word sequences decomposed into intermediate units. observ. seq. o1 o2 o3 o4 o5 o6 o7 o8 o9 o10 o11 o12 o13 o14 o15 o16 CD phone seq. phoneme seq. word seq. c1 c2 c3 c4 c5 c6 c7 c8 c9 c10 c11 c12 c13 c14 p1 p2 p3 p4 p5 p6 p7 p8 p9 p10 w1 w2 w3 w4 28
29 Statistical Formulation Observation sequence produced by signal processing system: o = o 1...o m. Sequence of words over alphabet Σ : w = w 1...w k. Formulation (maximum a posteriori decoding): ŵ = argmax Pr[w o] w Σ = argmax w Σ Pr[o w]pr[w] Pr[o] = argmax w Σ Pr[o w] }{{} Pr[w] }{{}. acoustic & pronunciation model (Bahl, Jelinek, and Mercer, 1983) language model 29

30 Fred Jelinek 18 November September
31 Components Acoustic and pronunciation model: Pr(o w) = d,c,p Pr(o d)pr(d c)pr(c p)pr(p w). acoustic model Pr(o d) : observation seq. distribution seq. Pr(d c) : distribution seq. CD phone seq. Pr(c p) : CD phone seq. phoneme seq. Pr(p w) : phoneme seq. word seq. Language model: seq. Pr(w), distribution over word 31
32 Notes Formulation does not match the way speech recognition errors are typically measured: editdistance between hypothesis and reference transcription. 32
33 Speech recognition problem Statistical formulation Maximum likelihood and maximum a posteriori Statistical formulation of speech recognition Components of a speech recognizer Acoustic features This Lecture 33
34 Acoustic Observations Discretization time: local spectral analysis of the speech waveform at regular intervals, t = t 1,...,t m, Parameter vectors t i+1 t i = 10ms (typically). o = o 1...o m, o i R N,N = 39 (typically). magnitude. Note: other perceptual information, e.g., visual information is ignored. 34
35 Acoustic Model Three-state hidden Markov models (HMMs) d0:! d1:! d2:! (Rabiner and Juang, 1993) 0 d0:! 1 d1:! 2 d2:ae b,d 3 Distributions: Full covariance multivariate Gaussians: 1 Pr[ω] = (2π) N/2 σ 1/2 e 1 2 (ω µ) Diagonal covariance Gaussian mixture. Semi-continuous, tied mixtures. T σ 1 (ω µ). 35
36 Idea: Context-Dependent Model phoneme pronunciation depends on environment (allophones, co-articulation). model phone in context Context-dependent rules: Context-dependent units: Allophonic rules: t/v better accuracy. Complex contexts: regular expressions. (Lee, 1990; Young et al., 1994) ae/b d ae b,d. V dx. 36
37 Pronunciation Dictionary Phonemic transcription Example: word data in American English. data D ey dx ax 0.32 data D ey t ax 0.08 data D ae dx ax 0.48 data D ae t ax 0.12 Representation d:!/ ey:!/0.4 ae:!/0.6 2 dx:!/0.8 t:!/0.2 3 ax:data/1.0 4/1 37
38 Language Model Definition: probabilistic model for sequences of words w = w 1...w k. By the chain rule, k Pr[w] = Pr[w i w 1...w i 1 ]. i=1 Modeling simplifications: Clustering of histories: (w 1,...,w i 1 ) c(w 1,...,w i 1 ). Example: nth order Markov assumption, i, Pr[w i w 1...w i 1 ]=Pr[w i h i ], h i n 1. 38
39 Recognition Cascade Combination of components observ. seq. CD phone seq. phoneme seq. word seq. word seq. HMM CD Model Pron. Model Lang. Model Viterbi approximation ŵ = argmax w argmax w d,c,p max d,c,p Pr[o d]pr[d c]pr[c p]pr[p w]pr[w] Pr[o d]pr[d c]pr[c p]pr[p w]pr[w]. 39
40 Speech Recognition Problems Learning: how to create accurate models for each component? Search: how to efficiently combine models and determine best transcription? Representation: compact data structure for the computational representation of the models. common representation and algorithmic framework based on weighted transducers (next lectures). 40
41 This Lecture Speech recognition problem Statistical formulation Acoustic features 41
42 Feature Selection Short-time Fourier analysis: log x(t)w(t τ)e iωt dt power (db) freq. (Hz) Short-time (25 msec. Hamming window) spectrum of /ae/. Idea: find smooth approximation eliminating large variations over short frequency intervals. 42
43 Cepstral Coefficients Let x(ω) denote the Fourier transform of the signal. Definition: the 13 cepstral coefficients are the energy and the 12 first coefficients of the expansion log x(ω) = c n e inω. n= Other coefficients: 13 first-order (delta-cepstra) and 13 second-order (delta-delta cepstra) differentials. 43
44 Mel Frequency Cepstral Coefficients Refinement: non-linear scale, approximation of human perception of distance between frequencies, e.g., mel frequency scale: MFCCs: f mel = 2595 log 10 (1 + f/700). signal first transformed using the Mel frequency band. extraction of cepstral coefficients. (Stevens and Volkman, 1940) 44
45 Other Refinements Speaker/Channel adaptation: mean cepstral subtraction. vocal tract normalization. linear transformations. 45
46 References Bahl, L. R., Jelinek, F., and Mercer, R. (1983). A Maximum Likelihood Approach to Continuous Speech Recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 5(2), Biing-Hwang Juang and Lawrence R. Rabiner. Automatic Speech Recognition - A Brief History of the Technology. Elsevier Encyclopedia of Language and Linguistics, Second Edition, Frederick Jelinek. Statistical Methods for Speech Recognition. MIT Press, Cambridge, MA, Kai-Fu Lee. Context-Dependent Phonetic Hidden Markov Models for Continuous Speech Recognition. IEEE International Conference on Acoustics, Speech, and Signal Processing, 38(4): , Lawrence Rabiner and Biing-Hwang Juang. Fundamentals of Speech Recognition. Prentice Hall,
47 References S.S. Stevens and J. Volkman. The relation of pitch to frequency. American Journal of Psychology, 53:329, Steve Young, J. Odell, and Phil Woodland. Tree-Based State-Tying for High Accuracy Acoustic Modelling. In Proceedings of ARPA Human Language Technology Workshop, Morgan Kaufmann, San Francisco,
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
On Developing Acoustic Models Using HTK. M.A. Spaans BSc.
 On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
Support Vector Machines for Speaker and Language Recognition
 Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Vimala.C Project Fellow, Department of Computer Science Avinashilingam Institute for Home Science and Higher Education and Women Coimbatore, India
 World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Digital Signal Processing: Speaker Recognition Final Report (Complete Version)
") Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques
 Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
International Journal of Advanced Networking Applications (IJANA) ISSN No. :
 ISSN No. :") International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation
 UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Letter-based speech synthesis
 Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS
 ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
Statistical Parametric Speech Synthesis
 Statistical Parametric Speech Synthesis Heiga Zen a,b,, Keiichi Tokuda a, Alan W. Black c a Department of Computer Science and Engineering, Nagoya Institute of Technology, Gokiso-cho, Showa-ku, Nagoya,
Statistical Parametric Speech Synthesis Heiga Zen a,b,, Keiichi Tokuda a, Alan W. Black c a Department of Computer Science and Engineering, Nagoya Institute of Technology, Gokiso-cho, Showa-ku, Nagoya,
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Voice conversion through vector quantization
 J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
Dyslexia/dyslexic, 3, 9, 24, 97, 187, 189, 206, 217, , , 367, , , 397,
 Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Rhythm-typology revisited.
 DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Large vocabulary off-line handwriting recognition: A survey
 Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
English Language and Applied Linguistics. Module Descriptions 2017/18
 English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment
 Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method
 Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions
 26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
 " 'rear,.': T OOM 36-41L v CHU
" 'rear,.': T OOM 36-41L v CHU The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Expressive speech synthesis: a review
 Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Spoofing and countermeasures for automatic speaker verification
 INTERSPEECH 2013 Spoofing and countermeasures for automatic speaker verification Nicholas Evans 1, Tomi Kinnunen 2 and Junichi Yamagishi 3,4 1 EURECOM, Sophia Antipolis, France 2 University of Eastern
INTERSPEECH 2013 Spoofing and countermeasures for automatic speaker verification Nicholas Evans 1, Tomi Kinnunen 2 and Junichi Yamagishi 3,4 1 EURECOM, Sophia Antipolis, France 2 University of Eastern
Speech Translation for Triage of Emergency Phonecalls in Minority Languages
 Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Quarterly Progress and Status Report. VCV-sequencies in a preliminary text-to-speech system for female speech
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics