Part-of-Speech Tagging
|
|
|
- Pauline Washington
- 5 years ago
- Views:
Transcription
1 Part-of-Speech Tagging Announcements Lit Review Part 2 Written review of 2 articles, due April 1 CS 341: Natural Language Processing Prof. Heather Pon-Barry Final Project Proposal Due Monday April 6
2 Today POS Tagging Process of assigning part of speech marker to each word in a collection! POS Tagging She/pronoun! found/verb! herself/pronoun! falling/verb!...

 Promised to back the bill = verb (VB) The POS tagging")
3 POS Tagging Penn Treebank Tagset Words often have more than one POS: e.g., back The back door = adjective (JJ) On my back = noun (NN) Win the voters back = adverb (RB) Promised to back the bill = verb (VB) The POS tagging problem is to determine the POS tag for a particular instance of a word.
4 Applications Speech synthesis I object vs. This object... Parsing Machine translation Named entity recognition Word sense disambiguation POS Tagging Performance How many tags are correct? (Tag accuracy) State of the art: about 97% But baseline is already 90% Baseline is performance is: Tag every word with its most frequent tag Tag unknown words as nouns Partly easy because Many words are unambiguous You get points for them (the, a, etc.) and for punctuation marks!
5 How difficult is POS Tagging? In the Brown corpus: ~ 11% of the word types are ambiguous with regard to part of speech ~ 40% of the word tokens are ambiguous But they tend to be very common words. E.g., that I know that he is honest = preposition (IN) Yes, that play was nice = determiner (DT) You can t go that far = adverb (RB) Automatic POS Tagging Symbolic Rule-based Transformation-based Probabilistic Hidden Markov models Log-linear models
6 Rule-based Tagging Rule-based Example Start with a dictionary Assign all possible tags to words from the dictionary Write rules by hand to selectively remove tags Leaving the correct tag for each word!!!!! NN!!!!! RB!!!! VBN!! JJ VB! PRP! VBD!! TO VB DT NN! She!promised to back the! bill
7 Rule-based Example Eliminate VBN if VBD is an option when VBN VBD follows <start> PRP!!!! NN! RB!!! VBN! JJ VB! PRP VBD!! TO VB DT NN! She!promised to back the! bill Transformation-based Combines rule-based and probabilistic tagging rules are used to specify tags in a certain environment probabilistic, we use a tagged corpus to find the best performing rules (supervised learning) Input tagged corpus dictionary (with most frequent tags) Example: Brill tagger


8 Automatic POS Tagging Symbolic HMM: Part-of-Speech Transition Probabilities Rule-based Transformation-based Probabilistic Hidden Markov models Log-linear models
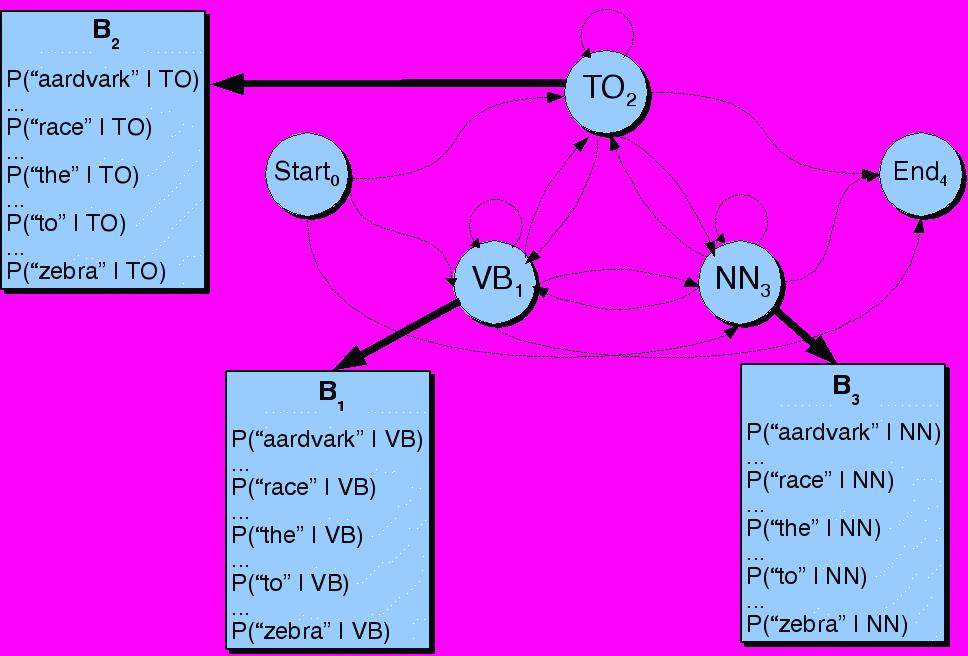
9 Observation Likelihoods: P(word tag) HMM
10 Maxent P(tag word) MEMMs Can do surprisingly well just looking at a word by itself: Word the: the DT Prefixes unfathomable: un- JJ Suffixes Importantly: -ly RB Maximum Entropy Markov Model A sequence version of the maximum entropy classifier. Capitalization Meridian: CAP NNP t i-2 t i-1 Word shapes 35-year: d-x JJ NNP MD VB Then build a classifier to predict tag w i-1 w i-1 w i w i+1 Maxent P(tag word): 93.7% overall / 82.6% unknown <s> Janet will back the bill Slide adapted from Dan Jurafsky

11 MEMMs More Features t i-2 t i-1 NNP MD VB w i-1 w i-1 w i w i+1 <s> Janet will back the bill Slide adapted from Dan Jurafsky
12 MEMM Decoding Simplest algorithm Greedy: at each step in sequence, select tag that maximizes P(tag nearby words, nearby tags) In practice Viterbi algorithm Beam search POS Tagging Accuracies Rough accuracies: Baseline: most freq tag: ~90% Trigram HMM: ~95% Maxent P(t w): 93.7% MEMM tagger: 96.9% Bidirectional MEMM: 97.2% Upper bound: ~98% (human agreement) Slide adapted from Dan Jurafsky
13 More Resources References Stanford POS Tagger (cyclic dependency network, bidirectional version of MEMM) CMU Twitter POS tagger Log-linear models Ratnaparkhi, EMNLP 1996 Toutanova et al., NAACL 2003 Excellent recent survey: Part-of-speech tagging from 97% to 100%: is it time for some linguistics? (Manning, 2011)
14 Summary Training a Tagger Penn Treebank: standard tagset Approaches to POS tagging: Symbolic: rule-based, transformation-based Probabilistic: HMMs, MEMMs Input tagged corpus dictionary (with most frequent tags) These are available for English What about other languages?
")
15 Research in POS Tagging Low resource languages Learning a Part-of-Speech Tagger from Two Hours of Annotation (Garrette and Baldridge, 2013) [video]
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger
 Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly
 ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
Training and evaluation of POS taggers on the French MULTITAG corpus
 Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Improving Accuracy in Word Class Tagging through the Combination of Machine Learning Systems
 Improving Accuracy in Word Class Tagging through the Combination of Machine Learning Systems Hans van Halteren* TOSCA/Language & Speech, University of Nijmegen Jakub Zavrel t Textkernel BV, University
Improving Accuracy in Word Class Tagging through the Combination of Machine Learning Systems Hans van Halteren* TOSCA/Language & Speech, University of Nijmegen Jakub Zavrel t Textkernel BV, University
University of Alberta. Large-Scale Semi-Supervised Learning for Natural Language Processing. Shane Bergsma
 University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
Grammars & Parsing, Part 1:
 Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
An Evaluation of POS Taggers for the CHILDES Corpus
 City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles
 Tagger for Malay Text Articles") A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles Rayner Alfred 1, Adam Mujat 1, and Joe Henry Obit 2 1 School of Engineering and Information Technology, Universiti Malaysia Sabah, Jalan
A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles Rayner Alfred 1, Adam Mujat 1, and Joe Henry Obit 2 1 School of Engineering and Information Technology, Universiti Malaysia Sabah, Jalan
Semi-supervised Training for the Averaged Perceptron POS Tagger
 Semi-supervised Training for the Averaged Perceptron POS Tagger Drahomíra johanka Spoustová Jan Hajič Jan Raab Miroslav Spousta Institute of Formal and Applied Linguistics Faculty of Mathematics and Physics,
Semi-supervised Training for the Averaged Perceptron POS Tagger Drahomíra johanka Spoustová Jan Hajič Jan Raab Miroslav Spousta Institute of Formal and Applied Linguistics Faculty of Mathematics and Physics,
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Three New Probabilistic Models. Jason M. Eisner. CIS Department, University of Pennsylvania. 200 S. 33rd St., Philadelphia, PA , USA
 Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS
 DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS Julia Tmshkina Centre for Text Techitology, North-West University, 253 Potchefstroom, South Africa 2025770@puk.ac.za
DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS Julia Tmshkina Centre for Text Techitology, North-West University, 253 Potchefstroom, South Africa 2025770@puk.ac.za
LTAG-spinal and the Treebank
 LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS
 Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
cmp-lg/ Jan 1998
 Identifying Discourse Markers in Spoken Dialog Peter A. Heeman and Donna Byron and James F. Allen Computer Science and Engineering Department of Computer Science Oregon Graduate Institute University of
Identifying Discourse Markers in Spoken Dialog Peter A. Heeman and Donna Byron and James F. Allen Computer Science and Engineering Department of Computer Science Oregon Graduate Institute University of
Outline. Dave Barry on TTS. History of TTS. Closer to a natural vocal tract: Riesz Von Kempelen:
 Outline LSA 352: Summer 2007. Speech Recognition and Synthesis Dan Jurafsky Lecture 2: TTS: Brief History, Text Normalization and Partof-Speech Tagging IP Notice: lots of info, text, and diagrams on these
Outline LSA 352: Summer 2007. Speech Recognition and Synthesis Dan Jurafsky Lecture 2: TTS: Brief History, Text Normalization and Partof-Speech Tagging IP Notice: lots of info, text, and diagrams on these
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Survey on parsing three dependency representations for English
 Survey on parsing three dependency representations for English Angelina Ivanova Stephan Oepen Lilja Øvrelid University of Oslo, Department of Informatics { angelii oe liljao }@ifi.uio.no Abstract In this
Survey on parsing three dependency representations for English Angelina Ivanova Stephan Oepen Lilja Øvrelid University of Oslo, Department of Informatics { angelii oe liljao }@ifi.uio.no Abstract In this
Unsupervised Dependency Parsing without Gold Part-of-Speech Tags
 Unsupervised Dependency Parsing without Gold Part-of-Speech Tags Valentin I. Spitkovsky valentin@cs.stanford.edu Angel X. Chang angelx@cs.stanford.edu Hiyan Alshawi hiyan@google.com Daniel Jurafsky jurafsky@stanford.edu
Unsupervised Dependency Parsing without Gold Part-of-Speech Tags Valentin I. Spitkovsky valentin@cs.stanford.edu Angel X. Chang angelx@cs.stanford.edu Hiyan Alshawi hiyan@google.com Daniel Jurafsky jurafsky@stanford.edu
Learning Computational Grammars
 Learning Computational Grammars John Nerbonne, Anja Belz, Nicola Cancedda, Hervé Déjean, James Hammerton, Rob Koeling, Stasinos Konstantopoulos, Miles Osborne, Franck Thollard and Erik Tjong Kim Sang Abstract
Learning Computational Grammars John Nerbonne, Anja Belz, Nicola Cancedda, Hervé Déjean, James Hammerton, Rob Koeling, Stasinos Konstantopoulos, Miles Osborne, Franck Thollard and Erik Tjong Kim Sang Abstract
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
UNIVERSITY OF OSLO Department of Informatics. Dialog Act Recognition using Dependency Features. Master s thesis. Sindre Wetjen
 UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
The Indiana Cooperative Remote Search Task (CReST) Corpus
 Corpus") The Indiana Cooperative Remote Search Task (CReST) Corpus Kathleen Eberhard, Hannele Nicholson, Sandra Kübler, Susan Gundersen, Matthias Scheutz University of Notre Dame Notre Dame, IN 46556, USA {eberhard.1,hnichol1,
The Indiana Cooperative Remote Search Task (CReST) Corpus Kathleen Eberhard, Hannele Nicholson, Sandra Kübler, Susan Gundersen, Matthias Scheutz University of Notre Dame Notre Dame, IN 46556, USA {eberhard.1,hnichol1,
Basic Parsing with Context-Free Grammars. Some slides adapted from Julia Hirschberg and Dan Jurafsky 1
 Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
The Role of the Head in the Interpretation of English Deverbal Compounds
 The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
arxiv:cmp-lg/ v1 7 Jun 1997 Abstract
 Comparing a Linguistic and a Stochastic Tagger Christer Samuelsson Lucent Technologies Bell Laboratories 600 Mountain Ave, Room 2D-339 Murray Hill, NJ 07974, USA christer@research.bell-labs.com Atro Voutilainen
Comparing a Linguistic and a Stochastic Tagger Christer Samuelsson Lucent Technologies Bell Laboratories 600 Mountain Ave, Room 2D-339 Murray Hill, NJ 07974, USA christer@research.bell-labs.com Atro Voutilainen
Named Entity Recognition: A Survey for the Indian Languages
 Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
The Ups and Downs of Preposition Error Detection in ESL Writing
 The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
Introduction. Beáta B. Megyesi. Uppsala University Department of Linguistics and Philology Introduction 1(48)
") Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
BULATS A2 WORDLIST 2
 BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
Automatic Translation of Norwegian Noun Compounds
 Automatic Translation of Norwegian Noun Compounds Lars Bungum Department of Informatics University of Oslo larsbun@ifi.uio.no Stephan Oepen Department of Informatics University of Oslo oe@ifi.uio.no Abstract
Automatic Translation of Norwegian Noun Compounds Lars Bungum Department of Informatics University of Oslo larsbun@ifi.uio.no Stephan Oepen Department of Informatics University of Oslo oe@ifi.uio.no Abstract
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
Exploiting Wikipedia as External Knowledge for Named Entity Recognition
 Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
INSTANT VOCABULARY 6-10
 INSTANT 6-10 LY NESS FUL AN - IAN ABLE - IBLE The Suffix "LY," which means LIKE; in the MANNER OF. NOTE: Key no. 5 "LESS" made adjectives out of nouns. Adding "LY" to these adjectives makes adverbs out
INSTANT 6-10 LY NESS FUL AN - IAN ABLE - IBLE The Suffix "LY," which means LIKE; in the MANNER OF. NOTE: Key no. 5 "LESS" made adjectives out of nouns. Adding "LY" to these adjectives makes adverbs out
Short Text Understanding Through Lexical-Semantic Analysis
 Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
The MSR-NRC-SRI MT System for NIST Open Machine Translation 2008 Evaluation
 The MSR-NRC-SRI MT System for NIST Open Machine Translation 2008 Evaluation AUTHORS AND AFFILIATIONS MSR: Xiaodong He, Jianfeng Gao, Chris Quirk, Patrick Nguyen, Arul Menezes, Robert Moore, Kristina Toutanova,
The MSR-NRC-SRI MT System for NIST Open Machine Translation 2008 Evaluation AUTHORS AND AFFILIATIONS MSR: Xiaodong He, Jianfeng Gao, Chris Quirk, Patrick Nguyen, Arul Menezes, Robert Moore, Kristina Toutanova,
THE VERB ARGUMENT BROWSER
 THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
Tagging Urdu Sentences from English POS Taggers
 Tagging Urdu Sentences from English POS Taggers Adnan Naseem COMSATS Institute of Information Technology, Islamabad, Pakistan Muazzama Anwar COMSATS Institute of Information Technology, Islamabad, Pakistan
Tagging Urdu Sentences from English POS Taggers Adnan Naseem COMSATS Institute of Information Technology, Islamabad, Pakistan Muazzama Anwar COMSATS Institute of Information Technology, Islamabad, Pakistan
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
knarrator: A Model For Authors To Simplify Authoring Process Using Natural Language Processing To Portuguese
 knarrator: A Model For Authors To Simplify Authoring Process Using Natural Language Processing To Portuguese Adriano Kerber Daniel Camozzato Rossana Queiroz Vinícius Cassol Universidade do Vale do Rio
knarrator: A Model For Authors To Simplify Authoring Process Using Natural Language Processing To Portuguese Adriano Kerber Daniel Camozzato Rossana Queiroz Vinícius Cassol Universidade do Vale do Rio
Linguistic Variation across Sports Category of Press Reportage from British Newspapers: a Diachronic Multidimensional Analysis
 International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures
 Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Books Effective Literacy Y5-8 Learning Through Talk Y4-8 Switch onto Spelling Spelling Under Scrutiny
 By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2
 Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language
 Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Syntactic surprisal affects spoken word duration in conversational contexts
 Syntactic surprisal affects spoken word duration in conversational contexts Vera Demberg, Asad B. Sayeed, Philip J. Gorinski, and Nikolaos Engonopoulos M2CI Cluster of Excellence and Department of Computational
Syntactic surprisal affects spoken word duration in conversational contexts Vera Demberg, Asad B. Sayeed, Philip J. Gorinski, and Nikolaos Engonopoulos M2CI Cluster of Excellence and Department of Computational
! # %& ( ) ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &,
 ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &,") ! # %& ( ) ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &, 4 The Interaction of Knowledge Sources in Word Sense Disambiguation Mark Stevenson Yorick Wilks University of Shef eld University of Shef eld Word sense
! # %& ( ) ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &, 4 The Interaction of Knowledge Sources in Word Sense Disambiguation Mark Stevenson Yorick Wilks University of Shef eld University of Shef eld Word sense
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Reading Grammar Section and Lesson Writing Chapter and Lesson Identify a purpose for reading W1-LO; W2- LO; W3- LO; W4- LO; W5-
 New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels
 Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Today we examine the distribution of infinitival clauses, which can be
 Infinitival Clauses Today we examine the distribution of infinitival clauses, which can be a) the subject of a main clause (1) [to vote for oneself] is objectionable (2) It is objectionable to vote for
Infinitival Clauses Today we examine the distribution of infinitival clauses, which can be a) the subject of a main clause (1) [to vote for oneself] is objectionable (2) It is objectionable to vote for
Search right and thou shalt find... Using Web Queries for Learner Error Detection
 Search right and thou shalt find... Using Web Queries for Learner Error Detection Michael Gamon Claudia Leacock Microsoft Research Butler Hill Group One Microsoft Way P.O. Box 935 Redmond, WA 981052, USA
Search right and thou shalt find... Using Web Queries for Learner Error Detection Michael Gamon Claudia Leacock Microsoft Research Butler Hill Group One Microsoft Way P.O. Box 935 Redmond, WA 981052, USA
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Introduction to Text Mining
 Prelude Overview Introduction to Text Mining Tutorial at EDBT 06 René Witte Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe, Germany http://rene-witte.net
Prelude Overview Introduction to Text Mining Tutorial at EDBT 06 René Witte Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe, Germany http://rene-witte.net
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
A Syllable Based Word Recognition Model for Korean Noun Extraction
 are used as the most important terms (features) that express the document in NLP applications such as information retrieval, document categorization, text summarization, information extraction, and etc.
are used as the most important terms (features) that express the document in NLP applications such as information retrieval, document categorization, text summarization, information extraction, and etc.
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain
 Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Opportunities for Writing Title Key Stage 1 Key Stage 2 Narrative
 English Teaching Cycle The English curriculum at Wardley CE Primary is based upon the National Curriculum. Our English is taught through a text based curriculum as we believe this is the best way to develop
English Teaching Cycle The English curriculum at Wardley CE Primary is based upon the National Curriculum. Our English is taught through a text based curriculum as we believe this is the best way to develop
Ch VI- SENTENCE PATTERNS.
 Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Development of the First LRs for Macedonian: Current Projects
 Development of the First LRs for Macedonian: Current Projects Ruska Ivanovska-Naskova Faculty of Philology- University St. Cyril and Methodius Bul. Krste Petkov Misirkov bb, 1000 Skopje, Macedonia rivanovska@flf.ukim.edu.mk
Development of the First LRs for Macedonian: Current Projects Ruska Ivanovska-Naskova Faculty of Philology- University St. Cyril and Methodius Bul. Krste Petkov Misirkov bb, 1000 Skopje, Macedonia rivanovska@flf.ukim.edu.mk
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
MWU-aware Part-of-Speech Tagging with a CRF model and lexical resources
 MWU-aware Part-of-Speech Tagging with a CRF model and lexical resources Matthieu Constant, Anthony Sigogne To cite this version: Matthieu Constant, Anthony Sigogne. MWU-aware Part-of-Speech Tagging with
MWU-aware Part-of-Speech Tagging with a CRF model and lexical resources Matthieu Constant, Anthony Sigogne To cite this version: Matthieu Constant, Anthony Sigogne. MWU-aware Part-of-Speech Tagging with
A Dataset of Syntactic-Ngrams over Time from a Very Large Corpus of English Books
 A Dataset of Syntactic-Ngrams over Time from a Very Large Corpus of English Books Yoav Goldberg Bar Ilan University yoav.goldberg@gmail.com Jon Orwant Google Inc. orwant@google.com Abstract We created
A Dataset of Syntactic-Ngrams over Time from a Very Large Corpus of English Books Yoav Goldberg Bar Ilan University yoav.goldberg@gmail.com Jon Orwant Google Inc. orwant@google.com Abstract We created
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Emmaus Lutheran School English Language Arts Curriculum
 Emmaus Lutheran School English Language Arts Curriculum Rationale based on Scripture God is the Creator of all things, including English Language Arts. Our school is committed to providing students with
Emmaus Lutheran School English Language Arts Curriculum Rationale based on Scripture God is the Creator of all things, including English Language Arts. Our school is committed to providing students with
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Parsing with Treebank Grammars: Empirical Bounds, Theoretical Models, and the Structure of the Penn Treebank
 Parsing with Treebank Grammars: Empirical Bounds, Theoretical Models, and the Structure of the Penn Treebank Dan Klein and Christopher D. Manning Computer Science Department Stanford University Stanford,
Parsing with Treebank Grammars: Empirical Bounds, Theoretical Models, and the Structure of the Penn Treebank Dan Klein and Christopher D. Manning Computer Science Department Stanford University Stanford,