Neural models in NLP. Natural Language Processing: Lecture Kairit Sirts
|
|
|
- Kristina Horton
- 5 years ago
- Views:
Transcription
1 Neural models in NLP Natural Language Processing: Lecture Kairit Sirts
2 The goal of today s lecture Explain word embeddings Explain the recurrent neural models used in NLP 2
3 Log-linear language model y the next word to predict x the context sequence: words, annotations etc v model parameters f(x, y) feature vector for the input-output pair (x, y) 3
4 The problem with log-linear models Feature engineering Developing feature templates Which features are relevant to which problems? Experiment with subsets of features Features can be very complex 4
5 What if we could let the model learn the relevant features automatically? Neural networks 5
6 1-hot representation the girl with flowers is cute are were flower The girl with the flowers is cute flower

7 What is the similarity between vectors for flower and flowers? the girl with flowers is cute are were flower flowers flower
8 Features as distributed representations Deep Learning: What is meant by a distributed representation? 8
9 Distributed word representations f1 f2 f3 f4 flower flowers What is the cosine similarity between flower and flowers now? 9
10 Learning distributed word representations The girl with the flowers is cute. She has the flowers in her hand. I picked these flowers myself. The girl with a flower is cute. She has a flower in her hand. I picked this flower myself. with the has the flowers is cute in her with a has a flower is cute in her picked the myself picked a myself 10
11 11
12 12
13 Word2Vec Mikolov et al., Efficient Estimation of Word Representations in Vector Space 13
, w(t-1), w(t+1), w(t+2)")


14 CBOW continuous bag of words w(t-2), w(t-1), w(t+1), w(t+2) one-hot vectors a row in the parameter matrix C the set of context vectors c the size of the context window - linear projection d embedding size 14



15 Skip-gram model Predict the context words w(t) one-hot vector Maximize: z
 In case of skip-gram: Given T training words in context Maximize:")
16 Training word embeddings General principle maximize the probability of the: Middle word, given the context words (CBOW) Context words, given the middle word (skip-gram) In case of skip-gram: Given T training words in context Maximize: Minimize: 16
 Repeat until convergence: - the set of all trainable parameters - learning")
17 Training word embeddings Typically trained with gradient descent You will learn more sophisticated methods in other courses Initialize the parameter vectors/matrices (somehow) Repeat until convergence: - the set of all trainable parameters - learning rate 17
18 Softmax vs log-linear model Softmax is a log-linear model Log-linear: Softmax: 18
19 The gradient of a log-linear model Empirical count Expected count 19

20 The gradients in skip-gram model c context word w middle word 20
21 The problem with softmax gradients Computing is computationally very expensive. Why? The gradients always include the sum over the whole vocabulary This makes computation very inefficient 21
 pairs that came")
 Previously: maximize Now:")
22 Negative sampling The general idea: Maximize the probability of the (word, context) pairs that came from the training data (instead of the probability of the context given the word) Previously: maximize Now: maximize 22

23 Skip-gram objective with negative sampling Maximize: - the set of random negative samples In practice, the number of negative samples per each positive sample is between
24 Tools for training word embeddings Word2vec Gensim includes both CBOW and skip-gram implementations Glove optimizes the predictions of co-occurrence counts between words Polyglot Dependency-based word embeddings 24
25 Further reading on word embeddings Mikolov et al., Distributed representations of words and phrases and their compositionality Mikolov et al., Efficient estimation of word representations in vector space Goldberg and Levy, word2vec Explained: Deriving Mikolov et al. s Negative-Sampling Word-Embedding Method Pennington et al., GloVe: Global Vectors for Word Representation Al-Rfou et al., Polyglot: Distributed Word Representations for Multilingual NLP Levy and Goldberg, Dependency-based word embeddings 25
26 Regularities between word embeddings Vector Representations of Words: 26
 Word embeddings The row corresponding To the input word in CS231n Convolutional Neural Networks for Visual Recognition: http://cs231n.github.io/assets/nn1/neural_net.")
27 Word embedding models as neural networks One-hot vector of the input word Prediction of the context word (softmax) or whether the (context, word) pair belongs to the Data (negative sampling) Word embeddings The row corresponding To the input word in CS231n Convolutional Neural Networks for Visual Recognition: 27
28 Recurrent Neural Networks 28
29 RNN Language Model 29
30 Machine Translation with RNN 30
31 RNN music generation Music Language Modeling with Recurrent Neural Networks: 31

32 Sequence Models The Unreasonable Effectiveness of Recurrent Neural Models: 32
33 Recurrent Neural Networks - Initial state - a nonlinear function and so on <s> 33
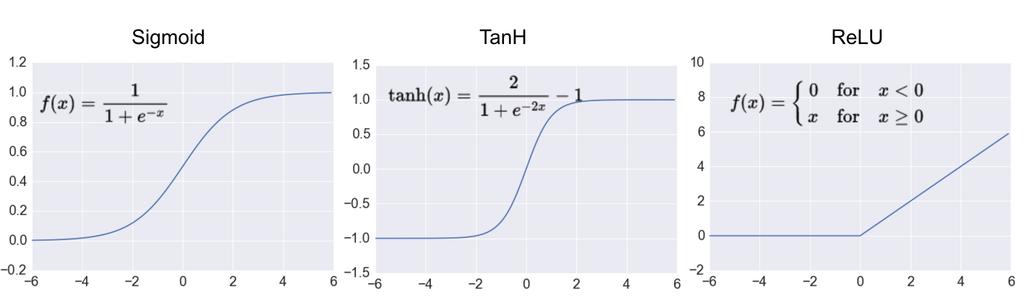
34 Non-linear activation functions 34
35 Cross-entropy loss function 35
36 Training neural networks Typically with stochastic or mini-batch gradient descent (full batch) GD gradients are computed based on all training items Mini-batch GD at each step compute the gradients based on a small number (a mini-batch) of training samples: for instance 20 or 32 or 128 etc Stochastic GD gradients are computed based on a single training item Gradients are computed using back-propagation BP is an algorithm for an efficient application of the chain rule There are several versions of gradient descent that set the learning rates in a clever way RMSProp, AdaGrad, AdaDelta, Momentum, Adam 36

37 Gated units RNN-s are supposed to remember long contexts but in practice they don t Gated units, such as LSTM or GRU include gates that control: How much from the next input is read in How much from the previous hidden state is remembered or forgotten How much from the cell state is used in the output Figure 12 from Herath et al., Going Deeper into Action Recognition: A Survey. 37
38 Tools for creating and training neural networks Python libraries that perform symbolic gradient computation Keras Tensorflow Theano PyTorch Dynet The field is developing rapidly 38
39 RNN LM and word embeddings Inputs x one-hot vectors Parameter matrix embeddings - word Training embeddings with word2vec or a similar model is faster than with RNNLM Pretrained word embeddings can be used to initialise the U matrix in RNNLM Transfer learning 39
40 Further reading Understanding LSTM networks Mikolov et al., Linguistic Regularities in Continuous Space Word Representations 40
41 Recap Word embeddings are dense distributed representations of words Word embeddings are trained from (word, context) pairs using neural models Word embeddings can be viewed as automatically learned feature vectors Recurrent neural networks are neural sequence models often used in NLP Pretrained word embeddings can be used to initialize the embedding layer of the recurrent neural models with textual input 41
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
arxiv: v1 [cs.cl] 20 Jul 2015
![arxiv: v1 [cs.cl] 20 Jul 2015](/thumbs/71/66201242.jpg "arxiv: v1 [cs.cl] 20 Jul 2015") How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
A deep architecture for non-projective dependency parsing
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках
 Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
CS224d Deep Learning for Natural Language Processing. Richard Socher, PhD
 CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
CS224d Deep Learning for Natural Language Processing, PhD Welcome 1. CS224d logis7cs 2. Introduc7on to NLP, deep learning and their intersec7on 2 Course Logis>cs Instructor: (Stanford PhD, 2014; now Founder/CEO
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
 A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
arxiv: v3 [cs.cl] 7 Feb 2017
![arxiv: v3 [cs.cl] 7 Feb 2017](/thumbs/71/66154314.jpg "arxiv: v3 [cs.cl] 7 Feb 2017") NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
There are some definitions for what Word
 Word Embeddings and Their Use In Sentence Classification Tasks Amit Mandelbaum Hebrew University of Jerusalm amit.mandelbaum@mail.huji.ac.il Adi Shalev bitan.adi@gmail.com arxiv:1610.08229v1 [cs.lg] 26
Word Embeddings and Their Use In Sentence Classification Tasks Amit Mandelbaum Hebrew University of Jerusalm amit.mandelbaum@mail.huji.ac.il Adi Shalev bitan.adi@gmail.com arxiv:1610.08229v1 [cs.lg] 26
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
Unsupervised Cross-Lingual Scaling of Political Texts
 Unsupervised Cross-Lingual Scaling of Political Texts Goran Glavaš and Federico Nanni and Simone Paolo Ponzetto Data and Web Science Group University of Mannheim B6, 26, DE-68159 Mannheim, Germany {goran,
Unsupervised Cross-Lingual Scaling of Political Texts Goran Glavaš and Federico Nanni and Simone Paolo Ponzetto Data and Web Science Group University of Mannheim B6, 26, DE-68159 Mannheim, Germany {goran,
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE
 2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
 Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS
 A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka & Richard Socher The University of Tokyo {hassy, tsuruoka}@logos.t.u-tokyo.ac.jp
A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka & Richard Socher The University of Tokyo {hassy, tsuruoka}@logos.t.u-tokyo.ac.jp
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Dropout improves Recurrent Neural Networks for Handwriting Recognition
 2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Semantic and Context-aware Linguistic Model for Bias Detection
 Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM. Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim
 NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim School of Computing KAIST Daejeon, South Korea ABSTRACT
NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim School of Computing KAIST Daejeon, South Korea ABSTRACT
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting
 LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX,
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
FBK-HLT-NLP at SemEval-2016 Task 2: A Multitask, Deep Learning Approach for Interpretable Semantic Textual Similarity
 FBK-HLT-NLP at SemEval-2016 Task 2: A Multitask, Deep Learning Approach for Interpretable Semantic Textual Similarity Simone Magnolini Fondazione Bruno Kessler University of Brescia Brescia, Italy magnolini@fbkeu
FBK-HLT-NLP at SemEval-2016 Task 2: A Multitask, Deep Learning Approach for Interpretable Semantic Textual Similarity Simone Magnolini Fondazione Bruno Kessler University of Brescia Brescia, Italy magnolini@fbkeu
School of Innovative Technologies and Engineering
 School of Innovative Technologies and Engineering Department of Applied Mathematical Sciences Proficiency Course in MATLAB COURSE DOCUMENT VERSION 1.0 PCMv1.0 July 2012 University of Technology, Mauritius
School of Innovative Technologies and Engineering Department of Applied Mathematical Sciences Proficiency Course in MATLAB COURSE DOCUMENT VERSION 1.0 PCMv1.0 July 2012 University of Technology, Mauritius
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter
 ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation
 2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Summarizing Answers in Non-Factoid Community Question-Answering
 Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the SAT
 The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.