Human Speech Recognition. Julia Hirschberg CS4706 (thanks to Francis Ganong and John Paul Hosum for some slides)
|
|
|
- Briana Oliver
- 5 years ago
- Views:
Transcription
1 Human Speech Recognition Julia Hirschberg CS4706 (thanks to Francis Ganong and John Paul Hosum for some slides)
2 Linguistic View of Speech Perception Speech is a sequence of articulatory gestures Many parallel levels of description Phonetic, Phonologic Prosodic Lexical Syntactic, Semantic, Pragmatic Human listeners make use of all these levels in speech perception Multiple cues and strategies used in different contexts
3 ASR Paradigm Given an acoustic observation: What is the most likely sequence of words to explain the input? Using Acoustic Model Language Model Two problems: How to score hypotheses (Modeling) How to pick hypotheses to score (Search)
4 So.What s Human about State of the Art ASR? Input Wave Front End Acoustic Features Acoustic Models Search Lexicon Language Models
5 N1 Front End: MFCC Input Wave Front End Acoustic Features Acoustic Models Search Postprocessing Lexicon Language Input Wave Sampling, Windowing Models FastFourierTransform Mel Filter Bank: cosine transform first 8-12 coefficients Stacking, computation of deltas:normalizations: filtering, etc Linear Transformations:dimensionality reduction Acoustic Features
6 Slide 5 N1 change color of 2nd box to pink; first 1/3 only Nuance, 3/7/2010
7 Input Wave Basic Lexicon Front End Acoustic Features Acoustic Models Search A list of spellings and pronunciations Canonical pronunciations And a few others Limited to 64k entries Support simple stems and suffixes Linguistically naïve No phonological rewrites Doesn t support all languages Lexicon Language Models
8 Lexical Access Frequency sensitive, like ASR We access high frequency words faster and more accurately with less information than low frequency Access in parallel, like ASR We access multiple hypotheses simultaneously Based on multiple cues
9 How Does Human Perception Differ from ASR? Could ASR systems benefit by modeling any of these differences?
10 How Do Humans Identify Speech Sounds? Perceptual Critical Point Perceptual Compensation Model Phoneme Restoration Effect Perceptual Confusability Non Auditory Cues Cultural Dependence Categorical vs. Continuous
11 How Much Information Do We Need to Identify Phones? Furui (1986) truncated CV syllables from the beginning, the end, or both and measured human perception of truncated syllables Identified perceptual critical point as truncation position where there was 80% correct recognition Findings: 10 msec during point of greatest spectral transition is most critical for CV identification Crucial information for C and V is in this region C can be mainly perceived by spectral transition into following V
12
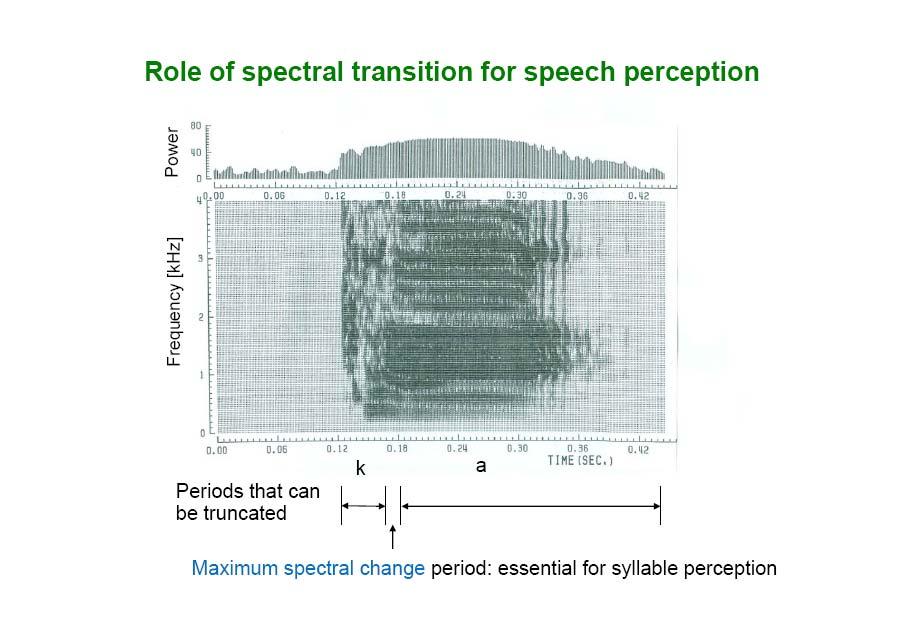
13
14 Can this help ASR?
15 Target Undershoot Vowels may or may not reach their target formant due to coarticulation Amount of undershoot depends on syllable duration, speaking style, How do people compensate in recognition? Lindblom & Studdert Kennedy (1967) Synthetic stimuli in wvw and yvy contexts with V F2 varying from high (/ih/) to low (/uh/) and with different transition slopes from consonant to vowel Subjects asked to judge /ih/ or /uh/
 different in the wvw context and yvy context In")

16 Boundary for perception of /ih/ and /uh/ (given the varying F2 values) different in the wvw context and yvy context In yvy contexts, mid level values of F2 were heard as /uh/, and in wvw contexts, mid level values of F2 heard as /ih/ /w ih w y uh y
17 Perceptual Compensation Model Conclusion: subjects relying on direction and slope of formant transitions to classify vowels Lindblom s PCM: normalize formant frequencies based on formants of the surrounding consonants, canonical vowel targets, syllable duration Application to ASR? Determining locations of consonants and vowels is non trivial
18 Can this help ASR?
19 Phoneme Restoration Effect Warren 1970 presented subjects with The state governors met with their respective legislatures convening in the capital city. Replaced [s] in legislatures with a cough Task: find any missing sounds Result: 19/20 reported no missing sounds (1 thought another sound was missing) Conclusion: much speech processing is top down rather than bottom up
20 Perceptual Confusability Studies Hypothesis: Confusable consonants are confusable in production because they are perceptually similar E.g. [dh/z/d] and [th/f/v] Experiment: Embed syllables beginning with targets in noise Ask listeners to identify Look at confusion matrix
21 Is there confusion between voiced and voiceless sounds? Shepard s similarity metric S ij = P P ij ii + + P P ji jj
22 Can this help ASR?
23 Speech and Visual Information How does visual observation of articulation affect speech perception? McGurk Effect (McGurk & McDonald 1976) Subjects heard simple syllables while watching video of speakers producing phonetically different syllables (demo) E.g. hear [ba] while watching [ga] What do they perceive? Conclusion: Humans have a perceptual map of place of articulation different from auditory
24 Can this help ASR?
25 Speech/Somatosensory Connection Ito et al 2008 show that stretching mouth can influence speech perception Subjects heard head, had, or something on a continuum in between Robotic device stretches mouth up, down, or backward Upward stretch leads to head judgments and downward to had but only when timing of stretch imitates production of vowel What does this mean about our perceptual maps?
26 Can this help ASR?
27 Is Speech Perception Culture Dependent? Mandarin tones High, falling, rising, dipping (usually not fully realized) Tone Sandhi: dipping, dipping rising, dipping Why? Easier to say Dipping and rising tones perceptually similar so high is appropriate substitute Comparison of native and non native speakers tone perception (Huang 2001)
28 Determine perceptual maps of Mandarin and American English subjects Discrimination task, measuring reaction time Two syllables compared, differing only in tone Task: same or different? Averaged reaction times for correct different answers Distance is 1/rt
29 Mandarin High [55] High [55] Rising [35] Dipping [214] Falling [51] Rising [35] Dipping [214] American High [55] Rising [35] Dipping [214] Falling [ Falling [51]
30 Can this help ASR?
31 Is Human Speech Perception Categorical or Continuous? Do we hear discrete symbols, or a continuum of sounds? What evidence should we look for? Categorical: There will be a range of stimuli that yield no perceptual difference, a boundary where perception changes, and another range showing no perceptual difference, e.g. Voice onset time (VOT) If VOT long, people hear unvoiced plosives If VOT short, people hear voiced plosives But people don t hear ambiguous plosives at the boundary between short and long (30 msec).
32 Non categorical, sort of Barclay 1972 presented subjects with a range of stimuli between /b/, /d/, and /g/ Asked to respond only with /b/ or /g/. If perception were completely categorical, responses for /d/ stimuli should have been random, but they were systematic Perception may be continuous but have sharp category boundaries, e.g.
33 Can this help ASR?
34 Where is ASR Going Today? 3 >5 Triphones > Quinphones Trigrams > Pentagrams Bigger acoustic models More parameters More mixtures Bigger lexicons 65k > 256k
35 Bigger language models More data, more parameters Bigger acoustic models More sharing Bigger language models Better back offs More kinds of adaptation Feature space adaptation Discriminative training instead of MLE to penalize error producing parameter settings Rover: combinations of recognizers Finite State Machine architecture to flatten knowledge into uniform structure
36 But not Perceptual Linear Prediction: modify cepstral coefficients by psychophysical findings Use of articulatory constraints Modeling features instead of specific phonemes Neural Nets, SVM / Kernel methods, Example Based Recognition, Segmental Models (frames >segments), Graphical Models (merge graph theory/probability theory) Parsing
37 No Data Like More Data Still Winning Standard statistical problems Curse of dimensionality, long tails Desirability of priors Quite sophisticated statistical models Advances due to increased size and sophistication of models Like Moore s law: no breakthroughs, dozens of small incremental advances Tiny impact of linguistic theory/experiments
38 Next Class Newer tasks for recognition
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Phonological and Phonetic Representations: The Case of Neutralization
 Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Quarterly Progress and Status Report. Voiced-voiceless distinction in alaryngeal speech - acoustic and articula
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Revisiting the role of prosody in early language acquisition. Megha Sundara UCLA Phonetics Lab
 Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Florida Reading Endorsement Alignment Matrix Competency 1
 Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
English Language and Applied Linguistics. Module Descriptions 2017/18
 English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
Rachel E. Baker, Ann R. Bradlow. Northwestern University, Evanston, IL, USA
 LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Rhythm-typology revisited.
 DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
Quarterly Progress and Status Report. VCV-sequencies in a preliminary text-to-speech system for female speech
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
On the nature of voicing assimilation(s)
") On the nature of voicing assimilation(s) Wouter Jansen Clinical Language Sciences Leeds Metropolitan University W.Jansen@leedsmet.ac.uk http://www.kuvik.net/wjansen March 15, 2006 On the nature of voicing
On the nature of voicing assimilation(s) Wouter Jansen Clinical Language Sciences Leeds Metropolitan University W.Jansen@leedsmet.ac.uk http://www.kuvik.net/wjansen March 15, 2006 On the nature of voicing
Universal contrastive analysis as a learning principle in CAPT
 Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Phonological encoding in speech production
 Phonological encoding in speech production Niels O. Schiller Department of Cognitive Neuroscience, Maastricht University, The Netherlands Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands
Phonological encoding in speech production Niels O. Schiller Department of Cognitive Neuroscience, Maastricht University, The Netherlands Max Planck Institute for Psycholinguistics, Nijmegen, The Netherlands
Understanding and Supporting Dyslexia Godstone Village School. January 2017
 Understanding and Supporting Dyslexia Godstone Village School January 2017 By then end of the session I will: Have a greater understanding of Dyslexia and the ways in which children can be affected by
Understanding and Supporting Dyslexia Godstone Village School January 2017 By then end of the session I will: Have a greater understanding of Dyslexia and the ways in which children can be affected by
Program Matrix - Reading English 6-12 (DOE Code 398) University of Florida. Reading
 University of Florida. Reading") Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
On Human Computer Interaction, HCI. Dr. Saif al Zahir Electrical and Computer Engineering Department UBC
 On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
Journal of Phonetics
 Journal of Phonetics 40 (2012) 595 607 Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics How linguistic and probabilistic properties
Journal of Phonetics 40 (2012) 595 607 Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics How linguistic and probabilistic properties
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
The analysis starts with the phonetic vowel and consonant charts based on the dataset:
 Ling 113 Homework 5: Hebrew Kelli Wiseth February 13, 2014 The analysis starts with the phonetic vowel and consonant charts based on the dataset: a) Given that the underlying representation for all verb
Ling 113 Homework 5: Hebrew Kelli Wiseth February 13, 2014 The analysis starts with the phonetic vowel and consonant charts based on the dataset: a) Given that the underlying representation for all verb
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
THE PERCEPTION AND PRODUCTION OF STRESS AND INTONATION BY CHILDREN WITH COCHLEAR IMPLANTS
 THE PERCEPTION AND PRODUCTION OF STRESS AND INTONATION BY CHILDREN WITH COCHLEAR IMPLANTS ROSEMARY O HALPIN University College London Department of Phonetics & Linguistics A dissertation submitted to the
THE PERCEPTION AND PRODUCTION OF STRESS AND INTONATION BY CHILDREN WITH COCHLEAR IMPLANTS ROSEMARY O HALPIN University College London Department of Phonetics & Linguistics A dissertation submitted to the
To appear in the Proceedings of the 35th Meetings of the Chicago Linguistics Society. Post-vocalic spirantization: Typology and phonetic motivations
 Post-vocalic spirantization: Typology and phonetic motivations Alan C-L Yu University of California, Berkeley 0. Introduction Spirantization involves a stop consonant becoming a weak fricative (e.g., B,
Post-vocalic spirantization: Typology and phonetic motivations Alan C-L Yu University of California, Berkeley 0. Introduction Spirantization involves a stop consonant becoming a weak fricative (e.g., B,
Consonants: articulation and transcription
 Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
 " 'rear,.': T OOM 36-41L v CHU
" 'rear,.': T OOM 36-41L v CHU Stages of Literacy Ros Lugg
 Beginning readers in the USA Stages of Literacy Ros Lugg Looked at predictors of reading success or failure Pre-readers readers aged 3-53 5 yrs Looked at variety of abilities IQ Speech and language abilities
Beginning readers in the USA Stages of Literacy Ros Lugg Looked at predictors of reading success or failure Pre-readers readers aged 3-53 5 yrs Looked at variety of abilities IQ Speech and language abilities
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
raıs Factors affecting word learning in adults: A comparison of L2 versus L1 acquisition /r/ /aı/ /s/ /r/ /aı/ /s/ = individual sound
 1 Factors affecting word learning in adults: A comparison of L2 versus L1 acquisition Junko Maekawa & Holly L. Storkel University of Kansas Lexical raıs /r/ /aı/ /s/ 2 = meaning Lexical raıs Lexical raıs
1 Factors affecting word learning in adults: A comparison of L2 versus L1 acquisition Junko Maekawa & Holly L. Storkel University of Kansas Lexical raıs /r/ /aı/ /s/ 2 = meaning Lexical raıs Lexical raıs
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Perceived speech rate: the effects of. articulation rate and speaking style in spontaneous speech. Jacques Koreman. Saarland University
 1 Perceived speech rate: the effects of articulation rate and speaking style in spontaneous speech Jacques Koreman Saarland University Institute of Phonetics P.O. Box 151150 D-66041 Saarbrücken Germany
1 Perceived speech rate: the effects of articulation rate and speaking style in spontaneous speech Jacques Koreman Saarland University Institute of Phonetics P.O. Box 151150 D-66041 Saarbrücken Germany
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Learners Use Word-Level Statistics in Phonetic Category Acquisition
 Learners Use Word-Level Statistics in Phonetic Category Acquisition Naomi Feldman, Emily Myers, Katherine White, Thomas Griffiths, and James Morgan 1. Introduction * One of the first challenges that language
Learners Use Word-Level Statistics in Phonetic Category Acquisition Naomi Feldman, Emily Myers, Katherine White, Thomas Griffiths, and James Morgan 1. Introduction * One of the first challenges that language
Dyslexia/dyslexic, 3, 9, 24, 97, 187, 189, 206, 217, , , 367, , , 397,
 Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Adoption studies, 274 275 Alliteration skill, 113, 115, 117 118, 122 123, 128, 136, 138 Alphabetic writing system, 5, 40, 127, 136, 410, 415 Alphabets (types of ) artificial transparent alphabet, 5 German
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence
 A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
South Carolina English Language Arts
 South Carolina English Language Arts A S O F J U N E 2 0, 2 0 1 0, T H I S S TAT E H A D A D O P T E D T H E CO M M O N CO R E S TAT E S TA N DA R D S. DOCUMENTS REVIEWED South Carolina Academic Content
South Carolina English Language Arts A S O F J U N E 2 0, 2 0 1 0, T H I S S TAT E H A D A D O P T E D T H E CO M M O N CO R E S TAT E S TA N DA R D S. DOCUMENTS REVIEWED South Carolina Academic Content
Books Effective Literacy Y5-8 Learning Through Talk Y4-8 Switch onto Spelling Spelling Under Scrutiny
 By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
L1 Influence on L2 Intonation in Russian Speakers of English
 Portland State University PDXScholar Dissertations and Theses Dissertations and Theses Spring 7-23-2013 L1 Influence on L2 Intonation in Russian Speakers of English Christiane Fleur Crosby Portland State
Portland State University PDXScholar Dissertations and Theses Dissertations and Theses Spring 7-23-2013 L1 Influence on L2 Intonation in Russian Speakers of English Christiane Fleur Crosby Portland State
DEVELOPMENT OF LINGUAL MOTOR CONTROL IN CHILDREN AND ADOLESCENTS
 DEVELOPMENT OF LINGUAL MOTOR CONTROL IN CHILDREN AND ADOLESCENTS Natalia Zharkova 1, William J. Hardcastle 1, Fiona E. Gibbon 2 & Robin J. Lickley 1 1 CASL Research Centre, Queen Margaret University, Edinburgh
DEVELOPMENT OF LINGUAL MOTOR CONTROL IN CHILDREN AND ADOLESCENTS Natalia Zharkova 1, William J. Hardcastle 1, Fiona E. Gibbon 2 & Robin J. Lickley 1 1 CASL Research Centre, Queen Margaret University, Edinburgh
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Journal of Phonetics
 Journal of Phonetics 41 (2013) 297 306 Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics The role of intonation in language and
Journal of Phonetics 41 (2013) 297 306 Contents lists available at SciVerse ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/phonetics The role of intonation in language and
Pobrane z czasopisma New Horizons in English Studies Data: 18/11/ :52:20. New Horizons in English Studies 1/2016
 LANGUAGE Maria Curie-Skłodowska University () in Lublin k.laidler.umcs@gmail.com Online Adaptation of Word-initial Ukrainian CC Consonant Clusters by Native Speakers of English Abstract. The phenomenon
LANGUAGE Maria Curie-Skłodowska University () in Lublin k.laidler.umcs@gmail.com Online Adaptation of Word-initial Ukrainian CC Consonant Clusters by Native Speakers of English Abstract. The phenomenon
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Content Language Objectives (CLOs) August 2012, H. Butts & G. De Anda
 August 2012, H. Butts & G. De Anda") Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Sample Goals and Benchmarks
 Sample Goals and Benchmarks for Students with Hearing Loss In this document, you will find examples of potential goals and benchmarks for each area. Please note that these are just examples. You should
Sample Goals and Benchmarks for Students with Hearing Loss In this document, you will find examples of potential goals and benchmarks for each area. Please note that these are just examples. You should
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Automatic intonation assessment for computer aided language learning
 Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
A comparison of spectral smoothing methods for segment concatenation based speech synthesis
 D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
ELA/ELD Standards Correlation Matrix for ELD Materials Grade 1 Reading
 ELA/ELD Correlation Matrix for ELD Materials Grade 1 Reading The English Language Arts (ELA) required for the one hour of English-Language Development (ELD) Materials are listed in Appendix 9-A, Matrix
ELA/ELD Correlation Matrix for ELD Materials Grade 1 Reading The English Language Arts (ELA) required for the one hour of English-Language Development (ELD) Materials are listed in Appendix 9-A, Matrix
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Acoustic correlates of stress and their use in diagnosing syllable fusion in Tongan. James White & Marc Garellek UCLA
 Acoustic correlates of stress and their use in diagnosing syllable fusion in Tongan James White & Marc Garellek UCLA 1 Introduction Goals: To determine the acoustic correlates of primary and secondary
Acoustic correlates of stress and their use in diagnosing syllable fusion in Tongan James White & Marc Garellek UCLA 1 Introduction Goals: To determine the acoustic correlates of primary and secondary
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty
 Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature
 August/September Strand Topic Standard Notes Reading for Literature") 1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
Demonstration of problems of lexical stress on the pronunciation Turkish English teachers and teacher trainees by computer
 Available online at www.sciencedirect.com Procedia - Social and Behavioral Sciences 46 ( 2012 ) 3011 3016 WCES 2012 Demonstration of problems of lexical stress on the pronunciation Turkish English teachers
Available online at www.sciencedirect.com Procedia - Social and Behavioral Sciences 46 ( 2012 ) 3011 3016 WCES 2012 Demonstration of problems of lexical stress on the pronunciation Turkish English teachers
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Large Kindergarten Centers Icons
 Large Kindergarten Centers Icons To view and print each center icon, with CCSD objectives, please click on the corresponding thumbnail icon below. ABC / Word Study Read the Room Big Book Write the Room
Large Kindergarten Centers Icons To view and print each center icon, with CCSD objectives, please click on the corresponding thumbnail icon below. ABC / Word Study Read the Room Big Book Write the Room
GOLD Objectives for Development & Learning: Birth Through Third Grade
 Assessment Alignment of GOLD Objectives for Development & Learning: Birth Through Third Grade WITH , Birth Through Third Grade aligned to Arizona Early Learning Standards Grade: Ages 3-5 - Adopted: 2013
Assessment Alignment of GOLD Objectives for Development & Learning: Birth Through Third Grade WITH , Birth Through Third Grade aligned to Arizona Early Learning Standards Grade: Ages 3-5 - Adopted: 2013
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION. Adam B. Buchwald
 SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION by Adam B. Buchwald A dissertation submitted to The Johns Hopkins University in conformity with the requirements
SOUND STRUCTURE REPRESENTATION, REPAIR AND WELL-FORMEDNESS: GRAMMAR IN SPOKEN LANGUAGE PRODUCTION by Adam B. Buchwald A dissertation submitted to The Johns Hopkins University in conformity with the requirements
Arabic Orthography vs. Arabic OCR
 Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among