Investigating how well language models capture meaning in children s books
|
|
|
- Theresa Tamsin Pitts
- 5 years ago
- Views:
Transcription
1 Investigating how well language models capture meaning in children s books Caitlin Hult Department of Mathematics UNC Chapel Hill Deep Learning Journal Club 11/30/16
2 Paper to discuss The Goldilocks Principle: Reading Children s Books with Explicit Memory Representations Authors: Felix Hill*, Antoine Bordes, Sumit Chopra, Jason Weston Facebook AI Research; University of Cambridge
3 Outline of Talk Motivation The Children s Book Test (CBT) Memory representation with Memory Networks Comparison with other models Conclusions
4 Motivation Humans do not interpret language in insolation Context is important! Guiding questions: How well can statistical models exploit wider contexts to make predictions about natural language? How well can they capture meaning? What is the role of local and wider contextual information in making predictions about different types of words in children s stories? What requirements are necessary for a language model to accurately predict syntatic function words (verbs, prepositions) vs. semantic words (named entities, nouns)? Useful for applications requiring semantic coherence (e.g. language generation, machine translation, dialogue and question-answering systems)
5 Model Overview The problem: Accurately predict missing words in children s stories Types of performance: Humans: predict all word types with similar accuracy, use wider context RNNs with LSTMs: very good at predicting verbs and prepositions, primarily use local contexts Memory Networks: good at predicting nouns and named entities, use both local info and wider context Importance of distinguishing the task of predicting syntactic function words from that of predicting lower-frequency semantic-content words


6 The Goldilocks Principle A sweet spot between word and sentence Optimal performance level is dependent on window choice and self-supervised training: We find the way in which wider context is represented in memory to be critical. If memories are encoded from a small window around important words in the context, there is an optimal size for memory representations between single words and entire sentences, that depends on the class of word to be predicted.
7 The Children s Book Test The basis of experiments in this paper Children s books have clear narrative structure (thus role of context more discernible) Designed to test the role of memory and context in language processing and understanding; directly measures how well language models can exploit wider linguistic context Books allocated to training, validation, or test sets Create example questions by numbering 21 consecutive sentences Definitions: context = first 20 sentences (denoted S) query = 21st sentence (denoted q) answer word = removed word from sentence (denoted a) selection of 10 candidate answers (denoted C) appearing in context sentences and query For a question answer pair (x, a): x = (q, S, C) S = ordered list of sentences q = a sentence (an ordered list q = q₁,, qk) containing a missing word symbol C = bag of unique words such that a C, cardinality C =10, every candidate word ω C satisfies ω q S

8 The Children s Book Test: Example
9 The Children s Book Test, cont. Evaluated four classes of question by removing distinct types of word: Named Entities, (Common) Nouns, Verbs, and Prepositions Classical language modeling evaluations: assume average perplexity across all words in a text > thus proportionally more emphasis on accurate prediction of frequent words CBT: allows focused analyses on semantic content-bearing words > better proxy
10 Comparison to similar models Microsoft Research Sentence Completion Challenge (MSRCC) limited to single sentence, whereas CBT has wider context CBT has nearly 10 times the number of test questions, double the number of candidates on each question, contains larger training and validation sets CNN QA requires models to identify missing entities from bullet-point summaries of online news articles > higher focus on paraphrasing, whereas CBT focuses on making inferences and predicting from contexts it is anonymised (can t apply knowledge that s not apparent from article), whereas CBT is not anonymised MCTest of machine comprehension training set consists of only 300 examples
11 Memory Networks One of a class of contextual models that can interpret language at a given point in text conditioned directly on both local information and explicit representation of the wider context Applying them on the CBT enables us to examine impact of various ways of encoding context on their semantic processing ability over naturally occurring language Good resources include: Weston et al., 2015b; Weston et al., 2015a; Sukhbaatar et al., 2015
12 Encoding memories and queries Options for storing phrases s: Lexical memory: one word per memory slot, incorporates time features to record word order Window memory: each phrase s corresponds to a window of text from context S centered on individual mention of candidate c in S, memory slots are windows of words Sentential memory: phrases of s correspond to complete sentences of S, for the CBT each question will have 20 memories
13 End-to-end memory networks MemN2N architecture allows for direct training of Memory Networks through backpropagation Two main steps: supporting memories are retrieved an answer distribution is returned using a softmax Memory Networks can perform several hops in memory before returning answer
14 Self-supervision for window memories Memory supervision not provided at training time, inferred automatically Train by making gradient steps using SGD. The model selects its top relevant memory using: At test time, candidate score is the sum of the alpha_i of the windows it appears in. Do not exploit new label information beyond the training data (hard attention over memories)
15 Applying different types of language modeling and machine reading architectures to the CBT Non-Learning Baselines N-Gram Language Models Supervised Embedding Models Recurrent Language Models Human Performance
16 Applying different types of language modeling and machine reading architectures to the CBT Non-Learning Baselines: Implemented two simple baselines based on word frequencies. 1) Select most frequent candidate in entire training corpus, 2) For a given question, select most frequent candidate in its context. N-Gram Language Models Supervised Embedding Models Recurrent Language Models Human Performance
17 Applying different types of language modeling and machine reading architectures to the CBT Non-Learning Baselines N-Gram Language Models: Trained an n-gram language model using the KenLM toolkit (Heatfield et al., 2013). Compared with a variant with cache, in which they linearly interpolated n-gram model probabilities with unigram probabilities computed on the context. Supervised Embedding Models Recurrent Language Models Human Performance
18 Applying different types of language modeling and machine reading architectures to the CBT Non-Learning Baselines N-Gram Language Models Supervised Embedding Models: Goal is to directly test how much of CBT can be resolved by word embeddings. Learn both input and output embedding matrices for each word in vocabulary For a given input passage q and possible answer word w, the score is computed as Lobotomised Memory Networks with zero hops (no attention over the memory component) Investigate different input passages: context + query, query, window (sub-sentence of query centered around missing word), window + position (use different embedding matrix for encoding each position of window). Tune window-size d=5 on validation set Recurrent Language Models Human Performance
19 Applying different types of language modeling and machine reading architectures to the CBT Non-Learning Baselines N-Gram Language Models Supervised Embedding Models Recurrent Language Models: Trained RNN language models with LSTM activation units on training stories (5.5M words), used minibatch SGD to maximize negative log-likelihood of next word, hyper-parameters tuned on validation set best model had dimension 512 Investigated 2 variants: context + query (read entire context, then query), query (read only query). All models have access to query words after the missing word. Contextual LSTM learns a convolutional attention over windows of the context (given objective of predicting all words in the query) Tuned window size on validation set Human Performance
20 Applying different types of language modeling and machine reading architectures to the CBT Non-Learning Baselines N-Gram Language Models Supervised Embedding Models Recurrent Language Models Human Performance: 15 native English speakers attempt a randomlyselected 10% from each question type of CBT, either with query only or with query + context. Obtained 2000 answers total.
21
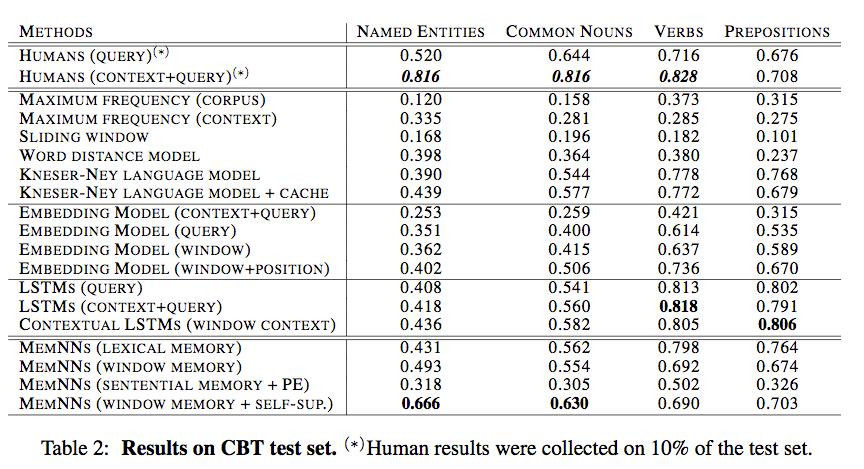
22 Results: Modeling syntactic flow Model performance strongly depends on type of word to be predicted Conventional language models good at verb/preposition prediction, less good at predicting nouns/named entities Interesting results: RNNs with LSTMs slightly better than n-gram models (except for name entities, when cache is used) LSTM models better than humans at preposition prediction (suggests that sometimes several candidate prepositions are correct ) When only query available, LSTMs and n-gram models better than humans at verb prediction (possibly because models better attuned to verb distribution in children s books)
23 Results: Capturing semantic coherence Best performing Memory Networks predict nouns, named entities more accurately than conventional language models Rely on access to wider context LSTMs do not effectively exploit context when it is provided Performance level on nouns, named entities doesn t change Embedding Model (query), which is equivalent to memory network but without contextual memory, performs poorly
24 Results: Getting memory representations just right Trained memory networks exploited context to different degrees when predicting nouns and named entities. For example: Each sentence in C stored as ordered sequence of word embeddings (sentential mem + PE), performance is poor Lexical memory effective for verbs and prepositions, less for nouns and entities Window memories centered around candidate words more useful for nouns and named entities prediction
 outperforms all others at predicting nouns and named entities Simple window-based strategy for question representation Two")
25 Results: Self-supervised memory retrieval Window-based Memory Network with self-supervision (hard attention selection made among window memories during training) outperforms all others at predicting nouns and named entities Simple window-based strategy for question representation Two examples:
 CNN QA dataset: 93000 news articles, each coupled with a question derived from bullet point summary accompanying the article, and a single-word answer which is always a named entity Memory")
26 Testing on the CNN QA task How well do conclusions generalize? Test best-performing Memory Network on CNN QA task (Hermann et al., 2015) CNN QA dataset: news articles, each coupled with a question derived from bullet point summary accompanying the article, and a single-word answer which is always a named entity Memory Network, with self-supervision added and removal of named entities appearing in bullet point summary from candidate list, results in best performance
27 Conclusions CBT is a new semantic language modeling benchmark Memories that encode sub-sentential chunks (windows) of informative text seem to be most useful to neural nets when interpreting and modeling language Most useful text chunk size depends on modeling task (semantic content vs. syntactic function words) Memory Networks that adhere to this principle can be efficiently trained using simple self-supervision to surpass all other methods for predicting named entities on both CBT and CNN QA benchmark
28 Works Cited Hill, F., Bordes, A., Chopra, S., & Weston, J. (2016). The Goldilocks Principle: Reading Children s Books with Explicit Memory Representations. Facebook AI Research. URL Sukhbaatar, Sainbayar, Szlam, Arthur, Weston, Jason. A neural attention model for abstractive sentence summarization. Proceedings of NIPS, Weston, Jason, Bordes, Antoine, Chopra, Sumit, and Mikolov, Tomas. Towards ai-complete question answering: a set of prerequisite toy tasks. arxiv preprint arxiv: , 2015a. Weston, Jason, Chopra, Sumit, and Bordes, Antoine. Memory networks. Proceedings of ICLR, 2015b.
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
arxiv: v3 [cs.cl] 7 Feb 2017
![arxiv: v3 [cs.cl] 7 Feb 2017](/thumbs/71/66154314.jpg "arxiv: v3 [cs.cl] 7 Feb 2017") NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
 A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models
 Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
 Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Arizona s English Language Arts Standards th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS
 Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
What the National Curriculum requires in reading at Y5 and Y6
 What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Formulaic Language and Fluency: ESL Teaching Applications
 Formulaic Language and Fluency: ESL Teaching Applications Formulaic Language Terminology Formulaic sequence One such item Formulaic language Non-count noun referring to these items Phraseology The study
Formulaic Language and Fluency: ESL Teaching Applications Formulaic Language Terminology Formulaic sequence One such item Formulaic language Non-count noun referring to these items Phraseology The study
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Loughton School s curriculum evening. 28 th February 2017
 Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Intra-talker Variation: Audience Design Factors Affecting Lexical Selections
 Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Writing a composition
 A good composition has three elements: Writing a composition an introduction: A topic sentence which contains the main idea of the paragraph. a body : Supporting sentences that develop the main idea. a
A good composition has three elements: Writing a composition an introduction: A topic sentence which contains the main idea of the paragraph. a body : Supporting sentences that develop the main idea. a
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Language Acquisition Chart
 Language Acquisition Chart This chart was designed to help teachers better understand the process of second language acquisition. Please use this chart as a resource for learning more about the way people
Language Acquisition Chart This chart was designed to help teachers better understand the process of second language acquisition. Please use this chart as a resource for learning more about the way people
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks
 Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks Rajarshi Das Manzil Zaheer Siva Reddy and Andrew McCallum College of Information and Computer Sciences, University
Question Answering on Knowledge Bases and Text using Universal Schema and Memory Networks Rajarshi Das Manzil Zaheer Siva Reddy and Andrew McCallum College of Information and Computer Sciences, University
Rubric for Scoring English 1 Unit 1, Rhetorical Analysis
 FYE Program at Marquette University Rubric for Scoring English 1 Unit 1, Rhetorical Analysis Writing Conventions INTEGRATING SOURCE MATERIAL 3 Proficient Outcome Effectively expresses purpose in the introduction
FYE Program at Marquette University Rubric for Scoring English 1 Unit 1, Rhetorical Analysis Writing Conventions INTEGRATING SOURCE MATERIAL 3 Proficient Outcome Effectively expresses purpose in the introduction
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
CAFE ESSENTIAL ELEMENTS O S E P P C E A. 1 Framework 2 CAFE Menu. 3 Classroom Design 4 Materials 5 Record Keeping
 CAFE RE P SU C 3 Classroom Design 4 Materials 5 Record Keeping P H ND 1 Framework 2 CAFE Menu R E P 6 Assessment 7 Choice 8 Whole-Group Instruction 9 Small-Group Instruction 10 One-on-one Instruction 11
CAFE RE P SU C 3 Classroom Design 4 Materials 5 Record Keeping P H ND 1 Framework 2 CAFE Menu R E P 6 Assessment 7 Choice 8 Whole-Group Instruction 9 Small-Group Instruction 10 One-on-one Instruction 11
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках
 Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining
 Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining
 Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Dickinson ISD ELAR Year at a Glance 3rd Grade- 1st Nine Weeks
 3rd Grade- 1st Nine Weeks R3.8 understand, make inferences and draw conclusions about the structure and elements of fiction and provide evidence from text to support their understand R3.8A sequence and
3rd Grade- 1st Nine Weeks R3.8 understand, make inferences and draw conclusions about the structure and elements of fiction and provide evidence from text to support their understand R3.8A sequence and
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Linguistic Variation across Sports Category of Press Reportage from British Newspapers: a Diachronic Multidimensional Analysis
 International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
arxiv: v2 [cs.cl] 26 Mar 2015
![arxiv: v2 [cs.cl] 26 Mar 2015](/thumbs/71/65580310.jpg "arxiv: v2 [cs.cl] 26 Mar 2015") Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Program Matrix - Reading English 6-12 (DOE Code 398) University of Florida. Reading
 University of Florida. Reading") Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
The College Board Redesigned SAT Grade 12
 A Correlation of, 2017 To the Redesigned SAT Introduction This document demonstrates how myperspectives English Language Arts meets the Reading, Writing and Language and Essay Domains of Redesigned SAT.
A Correlation of, 2017 To the Redesigned SAT Introduction This document demonstrates how myperspectives English Language Arts meets the Reading, Writing and Language and Essay Domains of Redesigned SAT.
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Summarizing Answers in Non-Factoid Community Question-Answering
 Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Compositional Semantics
 Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
CEFR Overall Illustrative English Proficiency Scales
 CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Procedia - Social and Behavioral Sciences 141 ( 2014 ) WCLTA Using Corpus Linguistics in the Development of Writing
 WCLTA Using Corpus Linguistics in the Development of Writing") Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 141 ( 2014 ) 124 128 WCLTA 2013 Using Corpus Linguistics in the Development of Writing Blanka Frydrychova
Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 141 ( 2014 ) 124 128 WCLTA 2013 Using Corpus Linguistics in the Development of Writing Blanka Frydrychova
Grade 4. Common Core Adoption Process. (Unpacked Standards)
") Grade 4 Common Core Adoption Process (Unpacked Standards) Grade 4 Reading: Literature RL.4.1 Refer to details and examples in a text when explaining what the text says explicitly and when drawing inferences
Grade 4 Common Core Adoption Process (Unpacked Standards) Grade 4 Reading: Literature RL.4.1 Refer to details and examples in a text when explaining what the text says explicitly and when drawing inferences
Advanced Grammar in Use
 Advanced Grammar in Use A self-study reference and practice book for advanced learners of English Third Edition with answers and CD-ROM cambridge university press cambridge, new york, melbourne, madrid,
Advanced Grammar in Use A self-study reference and practice book for advanced learners of English Third Edition with answers and CD-ROM cambridge university press cambridge, new york, melbourne, madrid,
EQuIP Review Feedback
 EQuIP Review Feedback Lesson/Unit Name: On the Rainy River and The Red Convertible (Module 4, Unit 1) Content Area: English language arts Grade Level: 11 Dimension I Alignment to the Depth of the CCSS
EQuIP Review Feedback Lesson/Unit Name: On the Rainy River and The Red Convertible (Module 4, Unit 1) Content Area: English language arts Grade Level: 11 Dimension I Alignment to the Depth of the CCSS
ELA/ELD Standards Correlation Matrix for ELD Materials Grade 1 Reading
 ELA/ELD Correlation Matrix for ELD Materials Grade 1 Reading The English Language Arts (ELA) required for the one hour of English-Language Development (ELD) Materials are listed in Appendix 9-A, Matrix
ELA/ELD Correlation Matrix for ELD Materials Grade 1 Reading The English Language Arts (ELA) required for the one hour of English-Language Development (ELD) Materials are listed in Appendix 9-A, Matrix
Word Embedding Based Correlation Model for Question/Answer Matching
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Word Embedding Based Correlation Model for Question/Answer Matching Yikang Shen, 1 Wenge Rong, 2 Nan Jiang, 2 Baolin
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Word Embedding Based Correlation Model for Question/Answer Matching Yikang Shen, 1 Wenge Rong, 2 Nan Jiang, 2 Baolin
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Reading Grammar Section and Lesson Writing Chapter and Lesson Identify a purpose for reading W1-LO; W2- LO; W3- LO; W4- LO; W5-
 New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
Dropout improves Recurrent Neural Networks for Handwriting Recognition
 2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) Feb 2015
 Feb 2015") Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Rule-based Expert Systems
 Rule-based Expert Systems What is knowledge? is a theoretical or practical understanding of a subject or a domain. is also the sim of what is currently known, and apparently knowledge is power. Those who
Rule-based Expert Systems What is knowledge? is a theoretical or practical understanding of a subject or a domain. is also the sim of what is currently known, and apparently knowledge is power. Those who
1. Introduction. 2. The OMBI database editor
 OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Sample Goals and Benchmarks
 Sample Goals and Benchmarks for Students with Hearing Loss In this document, you will find examples of potential goals and benchmarks for each area. Please note that these are just examples. You should
Sample Goals and Benchmarks for Students with Hearing Loss In this document, you will find examples of potential goals and benchmarks for each area. Please note that these are just examples. You should
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8