Multilingual Code-switching Identification via LSTM Recurrent Neural Networks
|
|
|
- Prudence Maxwell
- 6 years ago
- Views:
Transcription
1 Multilingual Code-switching Identification via LSTM Recurrent Neural Networks Younes Samih Suraj Mahrjan Mohammed Attia Laura Kallmeyer Thamar Solorio University of Düsseldorf Houston University Google Inc. EMNLP 2016 Second Workshop on Computational Approaches to Code Switching Austin, Texas USA November, 1, 2016
2 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Content Linguistic Background Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 2/27
3 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Content Linguistic Background Dataset Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 2/27
4 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Content Linguistic Background Dataset Neural Network Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 2/27
5 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Content Linguistic Background Dataset Neural Network Approach Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 2/27
6 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Content Linguistic Background Dataset Neural Network Approach Summary Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 2/27
7 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Code-switching Linguistic Background speakers switch from one language or dialect to another within the same context [Bullock and Toribio, 2009] Three types of codes-switching: inter-sentential, Intra-sentential, intra-word Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 3/27
8 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Code-switching Linguistic Background speakers switch from one language or dialect to another within the same context [Bullock and Toribio, 2009] Three types of codes-switching: inter-sentential, Intra-sentential, intra-word Constraints on Code-switching equivalence constraint [Poplack 1980] The Matrix Language-Frame (MLF)[Myers-Scotton 1993] Matrix language (ML) The embedded language (EL) Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 3/27
9 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Shared Task Dataset MSA-Egyptian Data all training dev test tweets 11,241 8,862 1,117 1,262 tokens 227, ,928 20,688 20,713 Table: MSA-Egyptian Data statistics Spanish-English Data all training dev test tweets 21,036 8,733 1,587 10,716 tokens 294, ,539 33, ,446 Table: Spanish-English Data statistics Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 4/27
10 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Corpora Arabic Corpus genre tokens Facebook posts 8,241,244 Tweets 2,813,016 News comments 95,241,480 MSA news texts 276,965,735 total 383,261,475 Table: Arabic corpus statistics Spanish-English Corpus English gigaword corpus(graff et al.,2003) Spanish gigaword corpus (Graff,2006) Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 5/27
11 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Data preprocessing Data preprocessing mapping Arabic scripts to SafeBuckwalter conversion of all Persian numbers to Arabic numbers Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 6/27
12 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Data preprocessing Data preprocessing mapping Arabic scripts to SafeBuckwalter conversion of all Persian numbers to Arabic numbers conversion of Arabic punctuation to Latin punctuation remove kashida (elongation character) and vowel marks Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 6/27
13 Introduction Neural network Approach Results Analysis Summary Road Map Code-switching Dataset Data preprocessing Data preprocessing mapping Arabic scripts to SafeBuckwalter conversion of all Persian numbers to Arabic numbers conversion of Arabic punctuation to Latin punctuation remove kashida (elongation character) and vowel marks separate punctuation marks from words Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 6/27
14 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Neural network Recurrent Neural Network Long short-term memory network Word Embeddings Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 7/27
15 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Reccurent Neural Network Figure by Christopher Olah RNN Given input sequence:x 1, x 2,..., x n Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 8/27
16 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Reccurent Neural Network Figure by Christopher Olah RNN Given input sequence:x 1, x 2,..., x n a standard RNN computes the output vector y t word x t of each Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 8/27
 y t = y hy + b y of each Younes Samih, Suraj Mahrjan Mohammed Attia, Laura")
17 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Reccurent Neural Network Figure by Christopher Olah RNN Given input sequence:x 1, x 2,..., x n a standard RNN computes the output vector y t word x t h t = H(W xh x t + W hh h 1 + b h ) y t = y hy + b y of each Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 8/27
18 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Long-term dependencies Figure by Christopher Olah Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 9/27
19 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Long-term dependencies Figure by Christopher Olah Basics Problem learning long-term dependencies in the data Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 9/27
20 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Long-term dependencies Figure by Christopher Olah Basics Problem learning long-term dependencies in the data Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 9/27
21 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Long-term dependencies Figure by Christopher Olah Basics Problem learning long-term dependencies in the data Vanishing gradients Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 9/27


22 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Long-term dependencies Figure by Christopher Olah Basics Problem learning long-term dependencies in the data Vanishing gradients exploding gradients Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 9/27
 i t = σ(w i.")
![[h t 1, x t ] + b i ) C t = tanh(w C.[h t 1, x t ] + b C ) C t = f t.c t 1 + i t. C t o t = σ(w o.](/docs-images/80/80551207/images/23-1.jpg "[h t 1, x t ] + b o ) h t = o t tanh(c t ) Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer")
23 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Long short-term memory network Figure by Christopher Olah LSTM Basics f t = σ(w f.[h t 1, x t ] + b f ) i t = σ(w i.[h t 1, x t ] + b i ) C t = tanh(w C.[h t 1, x t ] + b C ) C t = f t.c t 1 + i t. C t o t = σ(w o.[h t 1, x t ] + b o ) h t = o t tanh(c t ) Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 10/27
24 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Vector Space Models Vector space models Distributional hypothesis: Words in the same contexts share the same meaning Count-based methods (Latent Semantic Analysis,...) Neural probabilistic language models(word embeddings) Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 11/27
25 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Word2vec The main component of the neural-network approach Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 12/27
26 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Word2vec The main component of the neural-network approach Representation of each feature as a vector in a low dimensional space Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 12/27
27 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Word2vec The main component of the neural-network approach Representation of each feature as a vector in a low dimensional space Continuous Bag-of-Words model (CBOW) vs Skip-Gram model Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 12/27
28 Introduction Neural network Approach Results Analysis Summary RNN LSTM Word Embeddings Word Embeddings Figure by Yoav Goldberg Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 13/27
29 Introduction Neural network Approach Results Analysis Summary Code-switching detection Code-switching detection System Architecture Implementation Details Results Summary Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 14/27
30 Introduction Neural network Approach Results Analysis Summary Code-switching detection System Architecture LSTM-CRF for Code-switching Detection Our neural network architecture consists of the following three layers: Input layer: comprises both character and word embeddings Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 15/27
31 Introduction Neural network Approach Results Analysis Summary Code-switching detection System Architecture LSTM-CRF for Code-switching Detection Our neural network architecture consists of the following three layers: Input layer: comprises both character and word embeddings Hidden layer: two LSTMs map both words and character representations to hidden sequences Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 15/27
32 Introduction Neural network Approach Results Analysis Summary Code-switching detection System Architecture LSTM-CRF for Code-switching Detection Our neural network architecture consists of the following three layers: Input layer: comprises both character and word embeddings Hidden layer: two LSTMs map both words and character representations to hidden sequences Output layer: a Softmax or a CRF computes the probability distribution over all labels Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 15/27
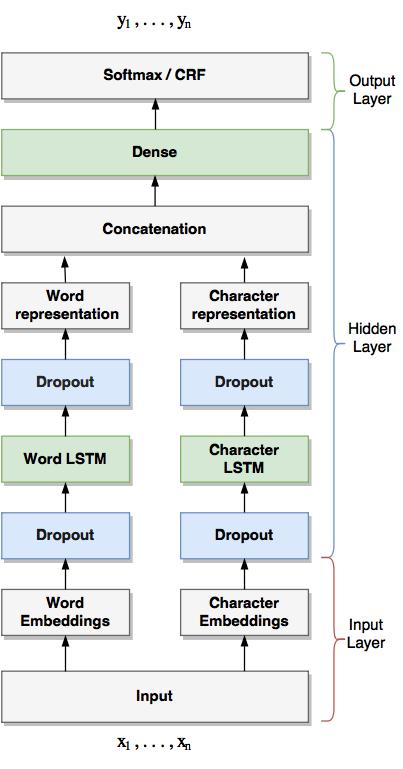
33 System Architecture
34 Introduction Neural network Approach Results Analysis Summary Code-switching detection Implementation Details Pre-trained Word embeddings Character embeddings Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 17/27
35 Introduction Neural network Approach Results Analysis Summary Code-switching detection Implementation Details Pre-trained Word embeddings Character embeddings Optimization: Dropout Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 17/27
36 Introduction Neural network Approach Results Analysis Summary Code-switching detection Implementation Details Pre-trained Word embeddings Character embeddings Optimization: Dropout Output layer: Softmax or CRF Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 17/27
37 Introduction Neural network Approach Results Analysis Summary Code-switching detection Implementation Details Pre-trained Word embeddings Character embeddings Optimization: Dropout Output layer: Softmax or CRF Training: Stochastic gradient descent optimizing Cross-entropy Objective function Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 17/27
38 Introduction Neural network Approach Results Analysis Summary Code-switching detection Implementation Details Pre-trained Word embeddings Character embeddings Optimization: Dropout Output layer: Softmax or CRF Training: Stochastic gradient descent optimizing Cross-entropy Objective function Hyper-parameters tuning on Devset Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 17/27
39 Introduction Neural network Approach Results Analysis Summary Results on Spanish-English Dev set Labels CRF (feats) CRF (emb) CRF (feats+ emb) word LSTM char LSTM char-word LSTM ambiguous fw lang lang mixed ne other unk Accuracy Table: F1 score results on Spanish-English development dataset Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 18/27
40 Introduction Neural network Approach Results Analysis Summary Results on MSA-Egyptian Dev set Labels CRF (feats) CRF (emb) CRF (feats+ emb) word LSTM char LSTM char- word LSTM ambiguous lang lang mixed ne other Accuracy Table: F1 score results on MSA-Egyptian development dataset Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 19/27
41 Introduction Neural network Approach Results Analysis Summary Tweet level results Scores Es-En MSA Monolingual F Code-switched F Weighted F Table: Tweet level results on the test dataset. Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 20/27
42 Introduction Neural network Approach Results Analysis Summary Token level results Label Recall Precision F-score ambiguous fw lang lang mixed ne other unk Accuracy Table: Token level results on Spanish-English test dataset. Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 21/27
43 Introduction Neural network Approach Results Analysis Summary Token level results Label Recall Precision F-score ambiguous fw lang lang mixed ne other unk Accuracy Table: Token level results on MSA-DA test dataset. Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 22/27

44 Introduction Neural network Approach Results Analysis Summary Char-word representation Spanish-English CRF Model Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 23/27

45 Introduction Neural network Approach Results Analysis Summary Char-word representation MSA-Egyptian CRF Model Younes Samih, Suraj Mahrjan Mohammed Attia, Laura Kallmeyer 24/27
46 CRF Model Most likely Score Most unlikely Score unk unk lang 1 mixed ne ne mixed lang fw fw amb other lang1 lang ne mixed lang 2 lang mixed other other other fw lang lang1 ne ne lang other lang unk ne lang2 mixed lang2 lang lang1 other lang1 lang Table: Most likely and unlikely transitions learned by CRF model for the Spanish-English dataset.
47 Summary Automatic identification of code-switching in tweets A unified neural network for language identification rivals state-of-the-art methods that rely on language-specific tools
48 Summary Automatic identification of code-switching in tweets A unified neural network for language identification rivals state-of-the-art methods that rely on language-specific tools What next? Implement character aware Bidirectional LSTM to capture word morphology Employ the More sophisticated CNN-Bidirectional LSTM
49 Thank you for your attention! Questions?
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
arxiv: v1 [cs.cl] 20 Jul 2015
![arxiv: v1 [cs.cl] 20 Jul 2015](/thumbs/71/66201242.jpg "arxiv: v1 [cs.cl] 20 Jul 2015") How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках
 Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation
 2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
A deep architecture for non-projective dependency parsing
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dropout improves Recurrent Neural Networks for Handwriting Recognition
 2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
2014 14th International Conference on Frontiers in Handwriting Recognition Dropout improves Recurrent Neural Networks for Handwriting Recognition Vu Pham,Théodore Bluche, Christopher Kermorvant, and Jérôme
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting
 LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
Moving code-switching research toward more empirically grounded methods
 Moving code-switching research toward more empirically grounded methods Gualberto A. Guzmán, Joseph Ricard, Jacqueline Serigos, Barbara Bullock & Almeida Jacqueline Toribio University of Texas at Austin
Moving code-switching research toward more empirically grounded methods Gualberto A. Guzmán, Joseph Ricard, Jacqueline Serigos, Barbara Bullock & Almeida Jacqueline Toribio University of Texas at Austin
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
 A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Arabic Orthography vs. Arabic OCR
 Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Summarizing Answers in Non-Factoid Community Question-Answering
 Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
arxiv: v5 [cs.ai] 18 Aug 2015
![arxiv: v5 [cs.ai] 18 Aug 2015](/thumbs/71/66241401.jpg "arxiv: v5 [cs.ai] 18 Aug 2015") When Are Tree Structures Necessary for Deep Learning of Representations? Jiwei Li 1, Minh-Thang Luong 1, Dan Jurafsky 1 and Eduard Hovy 2 1 Computer Science Department, Stanford University, Stanford, CA
When Are Tree Structures Necessary for Deep Learning of Representations? Jiwei Li 1, Minh-Thang Luong 1, Dan Jurafsky 1 and Eduard Hovy 2 1 Computer Science Department, Stanford University, Stanford, CA
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Experiments with Cross-lingual Systems for Synthesis of Code-Mixed Text
 Experiments with Cross-lingual Systems for Synthesis of Code-Mixed Text Sunayana Sitaram 1, Sai Krishna Rallabandi 1, Shruti Rijhwani 1 Alan W Black 2 1 Microsoft Research India 2 Carnegie Mellon University
Experiments with Cross-lingual Systems for Synthesis of Code-Mixed Text Sunayana Sitaram 1, Sai Krishna Rallabandi 1, Shruti Rijhwani 1 Alan W Black 2 1 Microsoft Research India 2 Carnegie Mellon University
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM. Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim
 NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim School of Computing KAIST Daejeon, South Korea ABSTRACT
NEURAL DIALOG STATE TRACKER FOR LARGE ONTOLOGIES BY ATTENTION MECHANISM Youngsoo Jang*, Jiyeon Ham*, Byung-Jun Lee, Youngjae Chang, Kee-Eung Kim School of Computing KAIST Daejeon, South Korea ABSTRACT
A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS
 A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka & Richard Socher The University of Tokyo {hassy, tsuruoka}@logos.t.u-tokyo.ac.jp
A JOINT MANY-TASK MODEL: GROWING A NEURAL NETWORK FOR MULTIPLE NLP TASKS Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka & Richard Socher The University of Tokyo {hassy, tsuruoka}@logos.t.u-tokyo.ac.jp
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
arxiv: v2 [cs.cl] 26 Mar 2015
![arxiv: v2 [cs.cl] 26 Mar 2015](/thumbs/71/65580310.jpg "arxiv: v2 [cs.cl] 26 Mar 2015") Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks Rie Johnson RJ Research Consulting Tarrytown, NY, USA riejohnson@gmail.com Tong Zhang Baidu Inc., Beijing, China Rutgers
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Word Embedding Based Correlation Model for Question/Answer Matching
 Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Word Embedding Based Correlation Model for Question/Answer Matching Yikang Shen, 1 Wenge Rong, 2 Nan Jiang, 2 Baolin
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Word Embedding Based Correlation Model for Question/Answer Matching Yikang Shen, 1 Wenge Rong, 2 Nan Jiang, 2 Baolin
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Boosting Named Entity Recognition with Neural Character Embeddings
 Boosting Named Entity Recognition with Neural Character Embeddings Cícero Nogueira dos Santos IBM Research 138/146 Av. Pasteur Rio de Janeiro, RJ, Brazil cicerons@br.ibm.com Victor Guimarães Instituto
Boosting Named Entity Recognition with Neural Character Embeddings Cícero Nogueira dos Santos IBM Research 138/146 Av. Pasteur Rio de Janeiro, RJ, Brazil cicerons@br.ibm.com Victor Guimarães Instituto
Postprint.
 http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
There are some definitions for what Word
 Word Embeddings and Their Use In Sentence Classification Tasks Amit Mandelbaum Hebrew University of Jerusalm amit.mandelbaum@mail.huji.ac.il Adi Shalev bitan.adi@gmail.com arxiv:1610.08229v1 [cs.lg] 26
Word Embeddings and Their Use In Sentence Classification Tasks Amit Mandelbaum Hebrew University of Jerusalm amit.mandelbaum@mail.huji.ac.il Adi Shalev bitan.adi@gmail.com arxiv:1610.08229v1 [cs.lg] 26
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Semantic and Context-aware Linguistic Model for Bias Detection
 Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
arxiv: v3 [cs.cl] 7 Feb 2017
![arxiv: v3 [cs.cl] 7 Feb 2017](/thumbs/71/66154314.jpg "arxiv: v3 [cs.cl] 7 Feb 2017") NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
ARNE - A tool for Namend Entity Recognition from Arabic Text
 24 ARNE - A tool for Namend Entity Recognition from Arabic Text Carolin Shihadeh DFKI Stuhlsatzenhausweg 3 66123 Saarbrücken, Germany carolin.shihadeh@dfki.de Günter Neumann DFKI Stuhlsatzenhausweg 3 66123
24 ARNE - A tool for Namend Entity Recognition from Arabic Text Carolin Shihadeh DFKI Stuhlsatzenhausweg 3 66123 Saarbrücken, Germany carolin.shihadeh@dfki.de Günter Neumann DFKI Stuhlsatzenhausweg 3 66123
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
arxiv: v1 [cs.cv] 2 Jun 2017
![arxiv: v1 [cs.cv] 2 Jun 2017](/thumbs/71/65541647.jpg "arxiv: v1 [cs.cv] 2 Jun 2017") Temporal Action Labeling using Action Sets Alexander Richard, Hilde Kuehne, Juergen Gall University of Bonn, Germany {richard,kuehne,gall}@iai.uni-bonn.de arxiv:1706.00699v1 [cs.cv] 2 Jun 2017 Abstract
Temporal Action Labeling using Action Sets Alexander Richard, Hilde Kuehne, Juergen Gall University of Bonn, Germany {richard,kuehne,gall}@iai.uni-bonn.de arxiv:1706.00699v1 [cs.cv] 2 Jun 2017 Abstract