Corpus Linguistics. Anca Dinu February, 2017
|
|
|
- Louisa Weaver
- 6 years ago
- Views:
Transcription
1 Corpus Linguistics Anca Dinu February, 2017
2 Where did corpus linguistics come from? Understanding that language in use is worthy of study; Understanding that large quantities of authentic language are needed for meaningful study; Understanding that context is important; General shift in social sciences to empiricism; Rise of technology; Recognition that a data-based approach opens up research.
3 Corpus Linguistics Corpus linguistics is a method of carrying out linguistic analyses. Corpus linguistics is the analysis of naturally occurring language on the basis of computerized corpora. Usually, the analysis is performed with the help of the computer, i.e. with specialized software, and takes into account the frequency of the phenomena investigated.
4 Corpus Linguistics It has become one of the most wide-spread methods of linguistic investigation. It can be used for the investigation of many kinds of linguistic questions. It has the potential to yield highly interesting, fundamental, and often surprising new insights about language.
5 Linguistic Data What data do linguists use to investigate linguistic phenomena? Roughly, four types of data can be distinguished: 1) data gained by intuition a) the researcher s own intuition ( introspection ) b) other people s intuition (accessed, for example, by elicitation tests) 2) naturally occurring language a) randomly collected texts or occurrences ( anecdotal evidence ) b) systematic collections of texts - CORPORA
6 Corpora A corpus is as a systematic collection of naturally occurring texts (of both written and spoken language). Systematic means that the structure and contents of the corpus follows certain extralinguistic principles or criteria.
7 Corpora For example, the texts or transcriptions of a corpus are often restricted to certain time span, domain, genre, style, dialect, language, etc... If several of these subcategories are present in a corpus, these are often represented by the same amount of text and separated as such in the corpus. Different types of corpora are used for different kind of analysis.
8 Use of corpora In linguistics, the typical use of corpora is: the (in)validation of linguistic hypothesis and statistical analysis of the linguistic data (Corpus Pattern Analysis, frequency lists, word cooccurrences, concordances, idioms, structures). The (semi-)automated data extraction (like argumental structure, thematic role) for the creation of electronic lexicons.
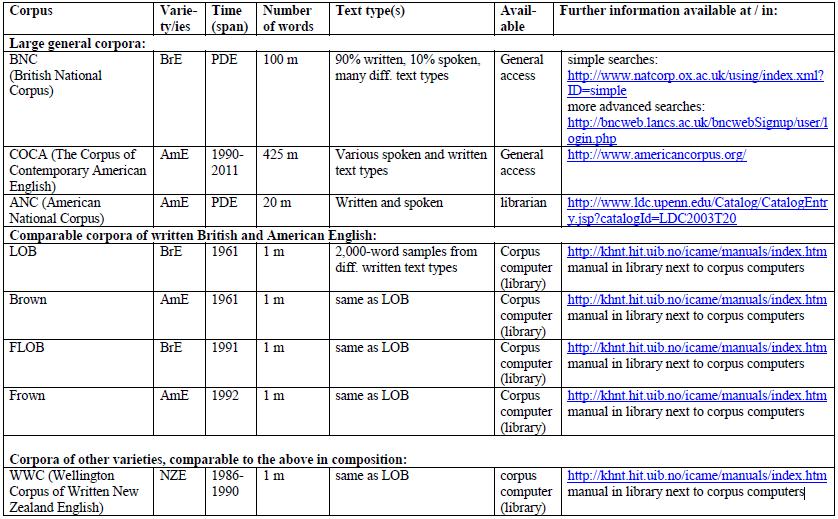
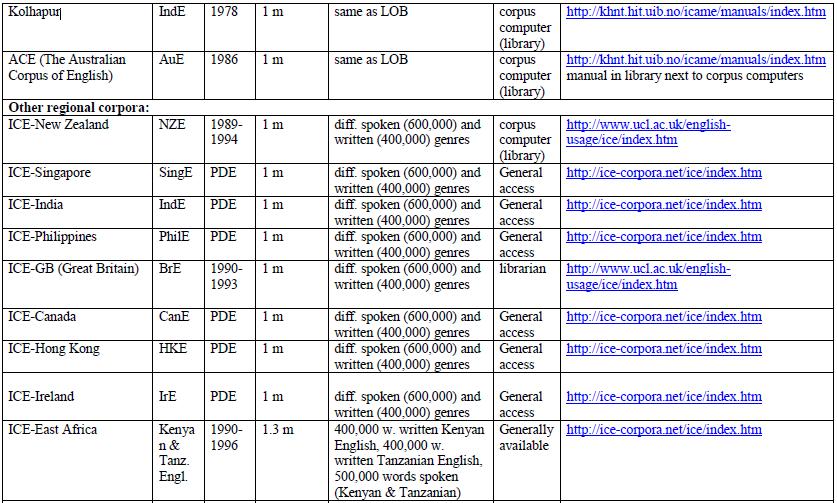
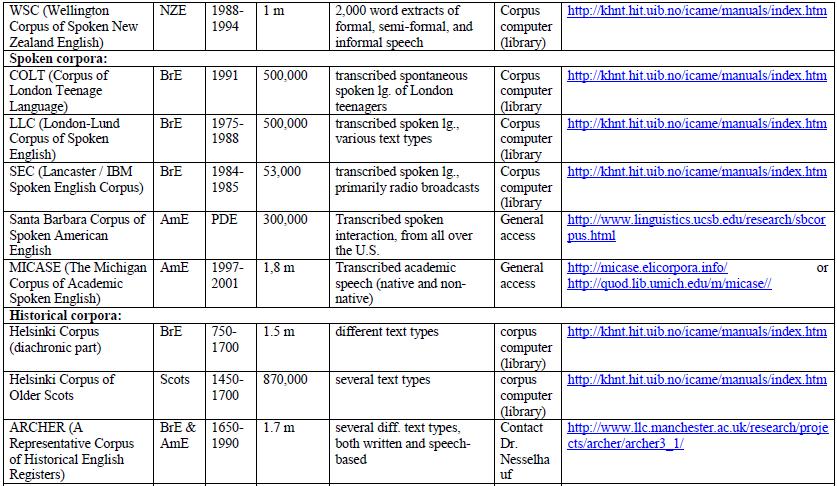
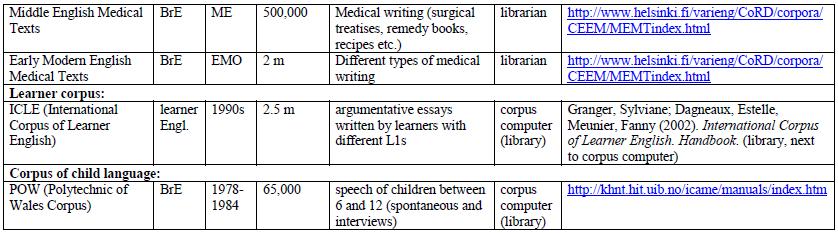
9 What corpora are there? Depending of the type of text or transcript, corpora can be: general/reference corpora (vs. specialized corpora) (e.g. BNC = British National Corpus, or Bank of English) aim at representing a language or variety as a whole (contain both spoken and written language, different text types etc.) historical corpora (vs. corpora of present-day language) (e.g. Helsinki Corpus, ARCHER) aim at representing an earlier stage or earlier stages of a language.
10 What corpora are there? regional corpora (vs. corpora containing more than one variety) (e.g. WCNZE = Wellington Corpus of Written New Zealand English) aim at representing one regional variety of a language. learner corpora (vs. native speaker corpora) (e.g. ICLE = International Corpus of Learner English) aim at representing the language as produced by learners of this language. multilingual corpora (vs. one-language corpora) aim at representing several, at least two, different languages, often with the same text types (for contrastive analyses). spoken (vs. written vs. mixed corpora) (e.g. LLC = London- Lund Corpus of Spoken English) aim at representing spoken language.
11 Annotation Annotation of corpora means that some kind of linguistic analysis has already been performed and marked on the texts, such as sentence analysis, or part of speach tagging. Depending of the type of annotation made on the text or transcript, a corpus can be: un-annotated (ortographic, raw, with just meta-annotation), phonetically, morphologically, syntactically, semantically or pragmatically annotated.
12 Annotation Annotation schemata should focus on a single coherent theme: Different linguistic phenomena should be annotated separately over the same corpus. Annotations must be consistent with each other: Unification and merging of multiple annotation is necessary.
13 Example of semantic annotation Predicators and their named arguments: [The man]agent painted [the wall]patient. Anaphors and their antecedents: [The protein] inhibits growth in yeast. [It] blocks production... Acronyms and their long forms: [Platelet-derived growth factor] (known as [pdgf]) impacts... Semantic Typing of entities: [The man]human fired [the gun]firearm.
14 Annotation Corpus annotation is usually made in a standardized manner with: XML (extensible Markup Language), designed to be both human- and machine-readable, via intuitive tags. Or TEI (Text Encoding Initiative), a text-centric community of practice that defined text guidelines in XML format).
15
16
17
18
19
20 Corpus Software Two types of software for corpus analysis can be distinguished in principle: software that is tailored to one specific corpus, (such as SARA and BNCWeb for BNC, or ICE-CUP for ICE-GB) and software that can be used with almost any kind of corpus (such as AntConc, MonoConc Pro and WordSmith Tools, which is probably the most widely used corpus software) We will use AntConc.
21 What can the software do? While there are many differences between the software packages designed for corpus analysis, certain basic functions can be performed by practically all the available software. For most kinds of linguistic analyses, the most important one of these is the possibility of searching the corpus in question for the (co-)occurrence of certain strings (words or phrases).
22 What can the software do? As output, the software then usually gives information on: the number of these strings occurring in the corpus, on the text in which they were found, and the so-called concordance-lines, which show the string in question in context (with the search term(s) highlighted).
23 Bibliography Nadja Nesselhauf, Corpus Linguistics: A Practical Introduction, 2011 Charlotte Taylor, What is corpus linguistics? What the data says, ICAME Journal No. 32, 2008
Procedia - Social and Behavioral Sciences 141 ( 2014 ) WCLTA Using Corpus Linguistics in the Development of Writing
 WCLTA Using Corpus Linguistics in the Development of Writing") Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 141 ( 2014 ) 124 128 WCLTA 2013 Using Corpus Linguistics in the Development of Writing Blanka Frydrychova
Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 141 ( 2014 ) 124 128 WCLTA 2013 Using Corpus Linguistics in the Development of Writing Blanka Frydrychova
Review in ICAME Journal, Volume 38, 2014, DOI: /icame
 Review in ICAME Journal, Volume 38, 2014, DOI: 10.2478/icame-2014-0012 Gaëtanelle Gilquin and Sylvie De Cock (eds.). Errors and disfluencies in spoken corpora. Amsterdam: John Benjamins. 2013. 172 pp.
Review in ICAME Journal, Volume 38, 2014, DOI: 10.2478/icame-2014-0012 Gaëtanelle Gilquin and Sylvie De Cock (eds.). Errors and disfluencies in spoken corpora. Amsterdam: John Benjamins. 2013. 172 pp.
Introduction. Beáta B. Megyesi. Uppsala University Department of Linguistics and Philology Introduction 1(48)
") Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization
 LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Intra-talker Variation: Audience Design Factors Affecting Lexical Selections
 Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Procedia - Social and Behavioral Sciences 154 ( 2014 )
") Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 154 ( 2014 ) 263 267 THE XXV ANNUAL INTERNATIONAL ACADEMIC CONFERENCE, LANGUAGE AND CULTURE, 20-22 October
Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 154 ( 2014 ) 263 267 THE XXV ANNUAL INTERNATIONAL ACADEMIC CONFERENCE, LANGUAGE AND CULTURE, 20-22 October
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Program Matrix - Reading English 6-12 (DOE Code 398) University of Florida. Reading
 University of Florida. Reading") Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
The following information has been adapted from A guide to using AntConc.
 1 7. Practical application of genre analysis in the classroom In this part of the workshop, we are going to analyse some of the texts from the discipline that you teach. Before we begin, we need to get
1 7. Practical application of genre analysis in the classroom In this part of the workshop, we are going to analyse some of the texts from the discipline that you teach. Before we begin, we need to get
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Modeling full form lexica for Arabic
 Modeling full form lexica for Arabic Susanne Alt Amine Akrout Atilf-CNRS Laurent Romary Loria-CNRS Objectives Presentation of the current standardization activity in the domain of lexical data modeling
Modeling full form lexica for Arabic Susanne Alt Amine Akrout Atilf-CNRS Laurent Romary Loria-CNRS Objectives Presentation of the current standardization activity in the domain of lexical data modeling
Project in the framework of the AIM-WEST project Annotation of MWEs for translation
 Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY
 MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov [Folie 1] 6.1 Type-token ratio
![Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov [Folie 1] 6.1 Type-token ratio](/thumbs/71/65795140.jpg "Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov [Folie 1] 6.1 Type-token ratio") Content 1. Empirical linguistics 2. Text corpora and corpus linguistics 3. Concordances 4. Application I: The German progressive 5. Part-of-speech tagging 6. Fequency analysis 7. Application II: Compounds
Content 1. Empirical linguistics 2. Text corpora and corpus linguistics 3. Concordances 4. Application I: The German progressive 5. Part-of-speech tagging 6. Fequency analysis 7. Application II: Compounds
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The Language of Football England vs. Germany (working title) by Elmar Thalhammer. Abstract
 by Elmar Thalhammer. Abstract") The Language of Football England vs. Germany (working title) by Elmar Thalhammer Abstract As opposed to about fifteen years ago, football has now become a socially acceptable phenomenon in both Germany
The Language of Football England vs. Germany (working title) by Elmar Thalhammer Abstract As opposed to about fifteen years ago, football has now become a socially acceptable phenomenon in both Germany
Florida Reading Endorsement Alignment Matrix Competency 1
 Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
English Language and Applied Linguistics. Module Descriptions 2017/18
 English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
English Language and Applied Linguistics Module Descriptions 2017/18 Level I (i.e. 2 nd Yr.) Modules Please be aware that all modules are subject to availability. If you have any questions about the modules,
Linguistics. Undergraduate. Departmental Honors. Graduate. Faculty. Linguistics 1
 Linguistics 1 Linguistics Matthew Gordon, Chair Interdepartmental Program in the College of Arts and Science 223 Tate Hall (573) 882-6421 gordonmj@missouri.edu Kibby Smith, Advisor Office of Multidisciplinary
Linguistics 1 Linguistics Matthew Gordon, Chair Interdepartmental Program in the College of Arts and Science 223 Tate Hall (573) 882-6421 gordonmj@missouri.edu Kibby Smith, Advisor Office of Multidisciplinary
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Bigrams in registers, domains, and varieties: a bigram gravity approach to the homogeneity of corpora
 Bigrams in registers, domains, and varieties: a bigram gravity approach to the homogeneity of corpora Stefan Th. Gries Department of Linguistics University of California, Santa Barbara stgries@linguistics.ucsb.edu
Bigrams in registers, domains, and varieties: a bigram gravity approach to the homogeneity of corpora Stefan Th. Gries Department of Linguistics University of California, Santa Barbara stgries@linguistics.ucsb.edu
Language Independent Passage Retrieval for Question Answering
 Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Ontologies vs. classification systems
 Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Developing a TT-MCTAG for German with an RCG-based Parser
 Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Variation of English passives used by Swedes
 School of Language and Literature G3, Bachelor s course English Linguistics Course code: 2EN10E Supervisor: Mikko Laitinen Credits: 15 Examiner: Ibolya Maricic Date: 18 January, 2014 Variation of English
School of Language and Literature G3, Bachelor s course English Linguistics Course code: 2EN10E Supervisor: Mikko Laitinen Credits: 15 Examiner: Ibolya Maricic Date: 18 January, 2014 Variation of English
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form
 Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Task Tolerance of MT Output in Integrated Text Processes
 Task Tolerance of MT Output in Integrated Text Processes John S. White, Jennifer B. Doyon, and Susan W. Talbott Litton PRC 1500 PRC Drive McLean, VA 22102, USA {white_john, doyon jennifer, talbott_susan}@prc.com
Task Tolerance of MT Output in Integrated Text Processes John S. White, Jennifer B. Doyon, and Susan W. Talbott Litton PRC 1500 PRC Drive McLean, VA 22102, USA {white_john, doyon jennifer, talbott_susan}@prc.com
Linguistic Variation across Sports Category of Press Reportage from British Newspapers: a Diachronic Multidimensional Analysis
 International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
Lexical Collocations (Verb + Noun) Across Written Academic Genres In English
 Across Written Academic Genres In English") Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 182 ( 2015 ) 433 440 4th WORLD CONFERENCE ON EDUCATIONAL TECHNOLOGY RESEARCHES, WCETR- 2014 Lexical Collocations
Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 182 ( 2015 ) 433 440 4th WORLD CONFERENCE ON EDUCATIONAL TECHNOLOGY RESEARCHES, WCETR- 2014 Lexical Collocations
A First-Pass Approach for Evaluating Machine Translation Systems
 [Proceedings of the Evaluators Forum, April 21st 24th, 1991, Les Rasses, Vaud, Switzerland; ed. Kirsten Falkedal (Geneva: ISSCO).] A First-Pass Approach for Evaluating Machine Translation Systems Pamela
[Proceedings of the Evaluators Forum, April 21st 24th, 1991, Les Rasses, Vaud, Switzerland; ed. Kirsten Falkedal (Geneva: ISSCO).] A First-Pass Approach for Evaluating Machine Translation Systems Pamela
Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing. Grzegorz Chrupa la
 Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing Grzegorz Chrupa la A dissertation submitted in fulfilment of the requirements for the award of Doctor of Philosophy (Ph.D.)
Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing Grzegorz Chrupa la A dissertation submitted in fulfilment of the requirements for the award of Doctor of Philosophy (Ph.D.)
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
The influence of written task descriptions in Wizard of Oz experiments
 The influence of written task descriptions in Wizard of Oz experiments Heidi Brøseth Department of Language and Communication Studies Norwegian University of Science and Technology NO-7491 Trondheim broseth@hf.ntnu.no
The influence of written task descriptions in Wizard of Oz experiments Heidi Brøseth Department of Language and Communication Studies Norwegian University of Science and Technology NO-7491 Trondheim broseth@hf.ntnu.no
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
1. Introduction. 2. The OMBI database editor
 OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
Case government vs Case agreement: modelling Modern Greek case attraction phenomena in LFG
 Case government vs Case agreement: modelling Modern Greek case attraction phenomena in LFG Dr. Kakia Chatsiou, University of Essex achats at essex.ac.uk Explorations in Syntactic Government and Subcategorisation,
Case government vs Case agreement: modelling Modern Greek case attraction phenomena in LFG Dr. Kakia Chatsiou, University of Essex achats at essex.ac.uk Explorations in Syntactic Government and Subcategorisation,
The MEANING Multilingual Central Repository
 The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
Adjusting a semantic taxonomy and annotation tool for historical corpora
 Adjusting a semantic taxonomy and annotation tool for historical corpora Dr Paul Rayson @perayson Director of UCREL research centre, School of Computing and Communications, Lancaster, UK Joint work with
Adjusting a semantic taxonomy and annotation tool for historical corpora Dr Paul Rayson @perayson Director of UCREL research centre, School of Computing and Communications, Lancaster, UK Joint work with
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC PP. VI, 282)
 (LONDON, BLOOMSBURY ACADEMIC PP. VI, 282)") B. PALTRIDGE, DISCOURSE ANALYSIS: AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC. 2012. PP. VI, 282) Review by Glenda Shopen _ This book is a revised edition of the author s 2006 introductory
B. PALTRIDGE, DISCOURSE ANALYSIS: AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC. 2012. PP. VI, 282) Review by Glenda Shopen _ This book is a revised edition of the author s 2006 introductory
Development of the First LRs for Macedonian: Current Projects
 Development of the First LRs for Macedonian: Current Projects Ruska Ivanovska-Naskova Faculty of Philology- University St. Cyril and Methodius Bul. Krste Petkov Misirkov bb, 1000 Skopje, Macedonia rivanovska@flf.ukim.edu.mk
Development of the First LRs for Macedonian: Current Projects Ruska Ivanovska-Naskova Faculty of Philology- University St. Cyril and Methodius Bul. Krste Petkov Misirkov bb, 1000 Skopje, Macedonia rivanovska@flf.ukim.edu.mk
Let's Learn English Lesson Plan
 Let's Learn English Lesson Plan Introduction: Let's Learn English lesson plans are based on the CALLA approach. See the end of each lesson for more information and resources on teaching with the CALLA
Let's Learn English Lesson Plan Introduction: Let's Learn English lesson plans are based on the CALLA approach. See the end of each lesson for more information and resources on teaching with the CALLA
Yoshida Honmachi, Sakyo-ku, Kyoto, Japan 1 Although the label set contains verb phrases, they
 FlowGraph2Text: Automatic Sentence Skeleton Compilation for Procedural Text Generation 1 Shinsuke Mori 2 Hirokuni Maeta 1 Tetsuro Sasada 2 Koichiro Yoshino 3 Atsushi Hashimoto 1 Takuya Funatomi 2 Yoko
FlowGraph2Text: Automatic Sentence Skeleton Compilation for Procedural Text Generation 1 Shinsuke Mori 2 Hirokuni Maeta 1 Tetsuro Sasada 2 Koichiro Yoshino 3 Atsushi Hashimoto 1 Takuya Funatomi 2 Yoko
- «Crede Experto:,,,». 2 (09) (http://ce.if-mstuca.ru) '36
 (http://ce.if-mstuca.ru) '36") - «Crede Experto:,,,». 2 (09). 2016 (http://ce.if-mstuca.ru) 811.512.122'36 Ш163.24-2 505.. е е ы, Қ х Ц Ь ғ ғ ғ,,, ғ ғ ғ, ғ ғ,,, ғ че ые :,,,, -, ғ ғ ғ, 2016 D. A. Alkebaeva Almaty, Kazakhstan NOUTIONS
- «Crede Experto:,,,». 2 (09). 2016 (http://ce.if-mstuca.ru) 811.512.122'36 Ш163.24-2 505.. е е ы, Қ х Ц Ь ғ ғ ғ,,, ғ ғ ғ, ғ ғ,,, ғ че ые :,,,, -, ғ ғ ғ, 2016 D. A. Alkebaeva Almaty, Kazakhstan NOUTIONS
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data
 Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data Maja Popović and Hermann Ney Lehrstuhl für Informatik VI, Computer
Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data Maja Popović and Hermann Ney Lehrstuhl für Informatik VI, Computer
Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities
 on Natural Language Processing for Digital Humanities") Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities Simon Clematide, Isabel Meraner, Noah Bubenhofer, Martin Volk Institute of Computational Linguistics
Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities Simon Clematide, Isabel Meraner, Noah Bubenhofer, Martin Volk Institute of Computational Linguistics
Analysis of Lexical Structures from Field Linguistics and Language Engineering
 Analysis of Lexical Structures from Field Linguistics and Language Engineering P. Wittenburg, W. Peters +, S. Drude ++ Max-Planck-Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands
Analysis of Lexical Structures from Field Linguistics and Language Engineering P. Wittenburg, W. Peters +, S. Drude ++ Max-Planck-Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands
Approaches to control phenomena handout Obligatory control and morphological case: Icelandic and Basque
 Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
Outline. Web as Corpus. Using Web Data for Linguistic Purposes. Ines Rehbein. NCLT, Dublin City University. nclt
 Outline Using Web Data for Linguistic Purposes NCLT, Dublin City University Outline Outline 1 Corpora as linguistic tools 2 Limitations of web data Strategies to enhance web data 3 Corpora as linguistic
Outline Using Web Data for Linguistic Purposes NCLT, Dublin City University Outline Outline 1 Corpora as linguistic tools 2 Limitations of web data Strategies to enhance web data 3 Corpora as linguistic
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
A corpus-based sociolinguistic study of amplifiers in British English
 Sociolinguistic Studies ISSN: 1750-8649 (print) ISSN: 1750-8657 (online) Article A corpus-based sociolinguistic study of amplifiers in British English Richard Xiao and Hongyin Tao Abstract Amplifiers such
Sociolinguistic Studies ISSN: 1750-8649 (print) ISSN: 1750-8657 (online) Article A corpus-based sociolinguistic study of amplifiers in British English Richard Xiao and Hongyin Tao Abstract Amplifiers such
Which verb classes and why? Research questions: Semantic Basis Hypothesis (SBH) What verb classes? Why the truth of the SBH matters
 What verb classes? Why the truth of the SBH matters") Which verb classes and why? ean-pierre Koenig, Gail Mauner, Anthony Davis, and reton ienvenue University at uffalo and Streamsage, Inc. Research questions: Participant roles play a role in the syntactic
Which verb classes and why? ean-pierre Koenig, Gail Mauner, Anthony Davis, and reton ienvenue University at uffalo and Streamsage, Inc. Research questions: Participant roles play a role in the syntactic
AN EXPERIMENTAL APPROACH TO NEW AND OLD INFORMATION IN TURKISH LOCATIVES AND EXISTENTIALS
 AN EXPERIMENTAL APPROACH TO NEW AND OLD INFORMATION IN TURKISH LOCATIVES AND EXISTENTIALS Engin ARIK 1, Pınar ÖZTOP 2, and Esen BÜYÜKSÖKMEN 1 Doguş University, 2 Plymouth University enginarik@enginarik.com
AN EXPERIMENTAL APPROACH TO NEW AND OLD INFORMATION IN TURKISH LOCATIVES AND EXISTENTIALS Engin ARIK 1, Pınar ÖZTOP 2, and Esen BÜYÜKSÖKMEN 1 Doguş University, 2 Plymouth University enginarik@enginarik.com
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
PRAAT ON THE WEB AN UPGRADE OF PRAAT FOR SEMI-AUTOMATIC SPEECH ANNOTATION
 PRAAT ON THE WEB AN UPGRADE OF PRAAT FOR SEMI-AUTOMATIC SPEECH ANNOTATION SUMMARY 1. Motivation 2. Praat Software & Format 3. Extended Praat 4. Prosody Tagger 5. Demo 6. Conclusions What s the story behind?
PRAAT ON THE WEB AN UPGRADE OF PRAAT FOR SEMI-AUTOMATIC SPEECH ANNOTATION SUMMARY 1. Motivation 2. Praat Software & Format 3. Extended Praat 4. Prosody Tagger 5. Demo 6. Conclusions What s the story behind?
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Routledge Library Editions: The English Language: Pronouns And Word Order In Old English: With Particular Reference To The Indefinite Pronoun Man
 Routledge Library Editions: The English Language: Pronouns And Word Order In Old English: With Particular Reference To The Indefinite Pronoun Man (Routledge Library Edition: The English Language) By Linda
Routledge Library Editions: The English Language: Pronouns And Word Order In Old English: With Particular Reference To The Indefinite Pronoun Man (Routledge Library Edition: The English Language) By Linda
Interactive Corpus Annotation of Anaphor Using NLP Algorithms
 Interactive Corpus Annotation of Anaphor Using NLP Algorithms Catherine Smith 1 and Matthew Brook O Donnell 1 1. Introduction Pronouns occur with a relatively high frequency in all forms English discourse.
Interactive Corpus Annotation of Anaphor Using NLP Algorithms Catherine Smith 1 and Matthew Brook O Donnell 1 1. Introduction Pronouns occur with a relatively high frequency in all forms English discourse.
A heuristic framework for pivot-based bilingual dictionary induction
 2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Postprint.
 http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
Construction Grammar. University of Jena.
 Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
MYCIN. The embodiment of all the clichés of what expert systems are. (Newell)
") MYCIN The embodiment of all the clichés of what expert systems are. (Newell) What is MYCIN? A medical diagnosis assistant A wild success Better than the experts Prototype for many other systems A disappointing
MYCIN The embodiment of all the clichés of what expert systems are. (Newell) What is MYCIN? A medical diagnosis assistant A wild success Better than the experts Prototype for many other systems A disappointing
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Constraining X-Bar: Theta Theory
 Constraining X-Bar: Theta Theory Carnie, 2013, chapter 8 Kofi K. Saah 1 Learning objectives Distinguish between thematic relation and theta role. Identify the thematic relations agent, theme, goal, source,
Constraining X-Bar: Theta Theory Carnie, 2013, chapter 8 Kofi K. Saah 1 Learning objectives Distinguish between thematic relation and theta role. Identify the thematic relations agent, theme, goal, source,
MILITARY ENGLISH VERSUS GENERAL ENGLISH A CASE STUDY OF AN ENGLISH PROFICIENCY TEST IN THE ITALIAN MILITARY
 MILITARY ENGLISH VERSUS GENERAL ENGLISH A CASE STUDY OF AN ENGLISH PROFICIENCY TEST IN THE ITALIAN MILITARY Dissertation submitted in partial fulfilment of the requirements for the degree of M.A. in Language
MILITARY ENGLISH VERSUS GENERAL ENGLISH A CASE STUDY OF AN ENGLISH PROFICIENCY TEST IN THE ITALIAN MILITARY Dissertation submitted in partial fulfilment of the requirements for the degree of M.A. in Language
Eyebrows in French talk-in-interaction
 Eyebrows in French talk-in-interaction Aurélie Goujon 1, Roxane Bertrand 1, Marion Tellier 1 1 Aix Marseille Université, CNRS, LPL UMR 7309, 13100, Aix-en-Provence, France Goujon.aurelie@gmail.com Roxane.bertrand@lpl-aix.fr
Eyebrows in French talk-in-interaction Aurélie Goujon 1, Roxane Bertrand 1, Marion Tellier 1 1 Aix Marseille Université, CNRS, LPL UMR 7309, 13100, Aix-en-Provence, France Goujon.aurelie@gmail.com Roxane.bertrand@lpl-aix.fr
Introduction to HPSG. Introduction. Historical Overview. The HPSG architecture. Signature. Linguistic Objects. Descriptions.
 to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
An Introduction to the Minimalist Program
 An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
CEFR Overall Illustrative English Proficiency Scales
 CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
Memory for questions and amount of processing
 Memory & Cognition 1978, Vol. 6 (5), 496-501 Memory for questions and amount of processing P. N. JOHNSON-LAIRD and C. E. BETHELL-FOX Centre for Research on Perception and Cognition, Laboratory of Experimental
Memory & Cognition 1978, Vol. 6 (5), 496-501 Memory for questions and amount of processing P. N. JOHNSON-LAIRD and C. E. BETHELL-FOX Centre for Research on Perception and Cognition, Laboratory of Experimental
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Minimalism is the name of the predominant approach in generative linguistics today. It was first
 Minimalism Minimalism is the name of the predominant approach in generative linguistics today. It was first introduced by Chomsky in his work The Minimalist Program (1995) and has seen several developments
Minimalism Minimalism is the name of the predominant approach in generative linguistics today. It was first introduced by Chomsky in his work The Minimalist Program (1995) and has seen several developments
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain
 Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty
 Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
BYLINE [Heng Ji, Computer Science Department, New York University,
 INFORMATION EXTRACTION BYLINE [Heng Ji, Computer Science Department, New York University, hengji@cs.nyu.edu] SYNONYMS NONE DEFINITION Information Extraction (IE) is a task of extracting pre-specified types
INFORMATION EXTRACTION BYLINE [Heng Ji, Computer Science Department, New York University, hengji@cs.nyu.edu] SYNONYMS NONE DEFINITION Information Extraction (IE) is a task of extracting pre-specified types
A Corpus of Dutch Aphasic Speech: Sketching the Design and Performing a Pilot Study. E. N. Westerhout November 10, 2005
 A Corpus of Dutch Aphasic Speech: Sketching the Design and Performing a Pilot Study E. N. Westerhout November 10, 2005 Abstract In this thesis, a pilot study for the development of a corpus of Dutch aphasic
A Corpus of Dutch Aphasic Speech: Sketching the Design and Performing a Pilot Study E. N. Westerhout November 10, 2005 Abstract In this thesis, a pilot study for the development of a corpus of Dutch aphasic
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Revisiting the role of prosody in early language acquisition. Megha Sundara UCLA Phonetics Lab
 Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF GRAPH DATA
 International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,