Pronunciation Modeling. Te Rutherford
|
|
|
- Clinton Potter
- 6 years ago
- Views:
Transcription
1 Pronunciation Modeling Te Rutherford

2 Bottom Line Fixing pronunciation is much easier and cheaper than LM and AM. The improvement from the pronunciation model alone can be sizeable.
3
4 Overview of Speech Recognition

5 Audio to Feature Vector Chop up the audio Take Fourier Transform power of each frequency Featurize MFCC, Cepstrum, PLP, etc. Clip out the silence Stacking (windowing) use t-1 t-2 t-3 and t+1 t+2 t+3 as features
6

7 Frame to State Acoustic model a classifier (e.g. Neural Network) input : a feature vector output : a triphone state What is a triphone state? type 1 /t/ : {vowel} + /t/ + {vowel} type 2 /t/ : {nasal} + /t/ + {vowel} Use decision trees to cluster /t/ sounds from different environment.
8
9 Phone Lattice time 1 time 2 time 3 type 1 t - beginning type 1 t - middle type 1 t - end type 2 t - beginning type 2 t - middle type 2 t - end type 1 k - beginning type 2 k - middle type 3 k end time 4
10 Weighted Finite State Transducer Essentially a search graph In speech, FST composition is used to prune the search graph and score the results.
11
12 HMM conversion Limiting what sequence of states is valid. k1 k1 k3 k3 ao1 ao2 ao2 ao3 l1 l2 l3 l3 not okay k1 k1 k2 k2 l1 l1 l2 l3 l3 not okay k1 k2 k2 k2 k3 k3 ao1 ao2 ao3 ao3 l1 l1 l2 l3 okay Use FST composition to prune the phone lattice
13 State to Phoneme Converting context-dependent triphone state back into phoneme type 1 /t/ : {vowel} + /t/ + {vowel} à /t/ type 2 /t/ : {nasal} + /t/ + {vowel} à /t/ Use FST Composition operation to convert (transduce)

14 Phoneme to Word List of valid phoneme sequences Example pronunciation dictionary: call : k ao l dad : d ae d mom : m aa m Backbone of the recognizer the best phoneme sequence " might not make a word
15 d ey t ax" d ey dx ax" d ae t ax" d ae dx ax Pronunciation FSTs
16 Recognizing sequence of words Language model and grammar are a finite state transducers. P(is intuition) P(is data)
17 Search meets machine learning Compose a well-pruned search graph (HCLG) HMM FSTsà pruned phone graph Context-independent FSTs à phoneme graph Lexicon FSTsà word graph " (heavily pruned phoneme graph) Grammar and LM FSTs à pruned and scored word graph
18 Search meets machine learning Compose a well-pruned search graph (HCLG) HMM FSTsà pruned phone graph Context-independent FSTs à phoneme graph Lexicon FSTsà word graph " (heavily pruned phoneme graph) Grammar and LM FSTs à pruned and scored word graph Classify a sequence of feature vector (by acoustic model) à phone lattice Compose the phone lattice with HCLG and search

19 Overview of Speech Recognition
20 Lexicon is the key component The lexicon makes training and decoding possible. limiting the size of the search graph The lexicon determines the words that can possibly be recognized.
21 Motivations for Pronunciation Modeling Suppose you are making a speech recognizer for a new language. Base dictionary and specialized dictionary How is a dictionary made? Can we automate it? semi-automate it?
22 Motivations for Pronunciation Modeling Suppose you are making a speech recognizer for a new language. Base dictionary and specialized dictionary How is a dictionary made? Can we automate it? semi-automate it? The errors from pronunciation modeling can be isolated and fixed relatively easily.


23 Pronunciation can be hard For a dictation task, we face new words all the time. Play a song by Ke$ha Install Spotify Who sings Gangnam Style? Tell me about Zoe Deschanel
24 Ask linguists for help These new words are usually hard and might require several pronunciations Gotye Rihanna Gangnam Style Ellie Goulding
25 Ask linguists for help These new words are usually hard and might require several pronunciations Gotye Rihanna Gangnam Style Ellie Goulding Disadvantages Expensive Too accurate Slow(er) turn-around time
26 Refresh the pronunciation dictionary Apply Grapheme-to-Phoneme conversion (G2P) to a list of new words Rule-based approach
27 Refresh the pronunciation dictionary Apply Grapheme-to-Phoneme conversion (G2P) to a list of new words Rule-based approach Statistical approach: Hidden Markov Model trained with Baum-Welch on the base dictionary state : set of phonemes observation : letters or groups of letters
28 Performance of statistical approach HMM-based models perform quite well. English, Dutch, German, and French which is the hardest?


29 Performance of statistical approach HMM-based models perform quite well. English, Dutch, German, and French which is the hardest? Jiampojamarn et al, 2007

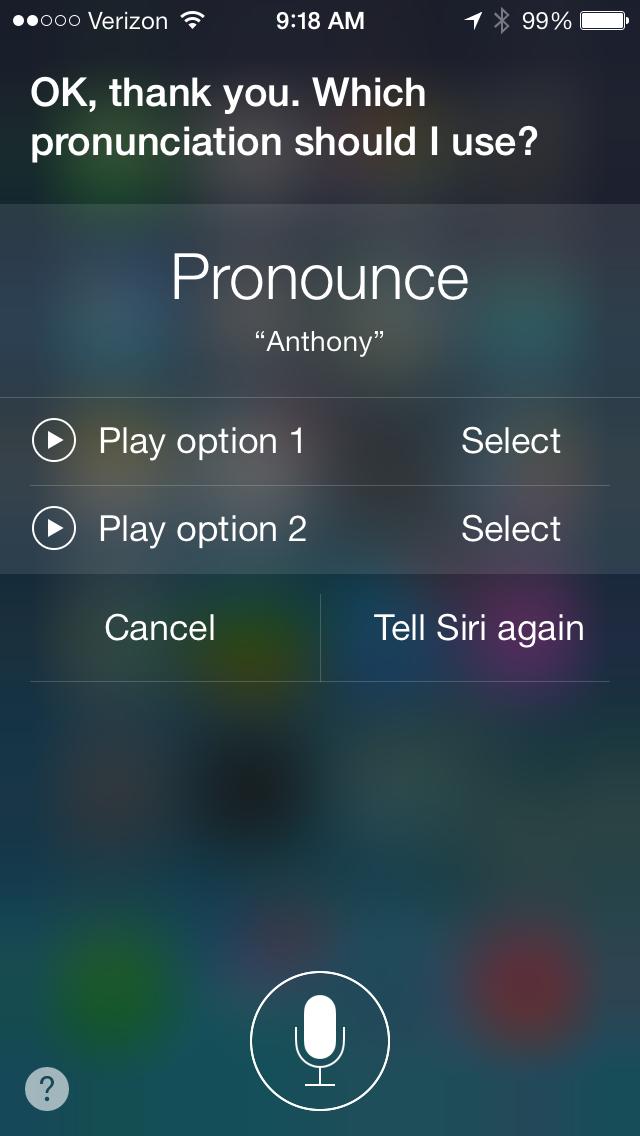
30 Semi-automatic approach Learn the pronunciation of a word from a native speaker but not a linguist. Why is this possible?
31

32 Pronunciation Learning from Crowd-sourcing Rutherford et al., 2014
33 Learn automatically from human For each word or phrase (transcription), get people to pronounce it use the speech recognizer to extract the pronunciation we already have the acoustic model + transcription! Fast : <1 day turn-around Cheap : ~5 cents/transcription Sounds great. But would it work?
34 Overview of the algorithm
35 Data Acquisition Picked top 1,000 downloaded entries from Google Play Store for each of the four categories Artist names Song titles TV show names Movie titles Made 4 data sets Send them to Amazon Mechanical Turk 10 different Turkers pronounce the same transcription 7 utterances for pronunciation learning 3 utterances for testing
36 Pronunciation candidate generation Use Grapheme-to-Phoneme conversion to generate 20 pronunciations per word If a word is already in the dictionary, use that pronunciation too.
37 Extract pronunciation Force-aligned G2P: find the triphone state sequences that best align with the utterance
38 Pronunciation selection Evaluated 3 possibilities Use all of the learned pronunciations Use the pronunciations that occur more than once Majority vote
39 Experiment results: " Use all learned pronunciations
40 Conclusion so far Improved SACC across all datasets Highest impact on artist names
41 Question How should we select pronunciations? How many should we keep?

42 How many pronunciations should we use?
43 Question So far we tested on matching data only Why can t we test it on the standard test set? Would it help to use the new pronunciations in the real setting?

44 Beyond WER Use majority vote to select pronunciations to add the base pronunciation dictionary Test on the voice search task MTurkers rate the quality of the voice search result.

45 Results Voice Search
46 Testing out the pipeline Extract 14,000 Google Map typed search queries that occur rarely in the log. Pick 5,000 words that are not in the lexicon. Can we do better than fully automatic G2P?
47 Results Voice Google Map Search
48 Question Where do the learned pronunciations come from with respect to G2P rankings? Our baseline system uses the top G2P candidate.
49 Distribution of G2P Ranks
50 Learned pronunciations from artist data Artist name! Learned pronunciations! G2P Rank! Dan Omelio! AX M EH L IY OW! 20! Tyga! T AY G ER! 20! Mat Kearney! K EH EH R N IY! 20! Jadakiss! JH EY D AX K IH S! 20! Nasri Atweh! N AA Z R IY! 19! Sonny Uwaezuoke! Y UW W EY Z UW OW K! 15! Flo Rida! R AY D AX! 2! Amadeus Mozart! AX M AX D EY AX S! 4! David Guetta! G W EH T AX! 6!

51 Limitations Word boundary Call Me Fitz F IH T Gwen Stefani G W EH N Z + S T EY F AX N IY Need to enforce boundary constraints

52 Conclusion Crowdsourcing pronunciations proved a viable quick path to refresh the pronunciation dictionary. The forcealigned-g2p algorithm can be used to learn pronunciation from audio data. Pronunciation in English is hard because it s such an international language.
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches
 NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Letter-based speech synthesis
 Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Vimala.C Project Fellow, Department of Computer Science Avinashilingam Institute for Home Science and Higher Education and Women Coimbatore, India
 World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
21st Century Community Learning Center
 21st Century Community Learning Center Grant Overview This Request for Proposal (RFP) is designed to distribute funds to qualified applicants pursuant to Title IV, Part B, of the Elementary and Secondary
21st Century Community Learning Center Grant Overview This Request for Proposal (RFP) is designed to distribute funds to qualified applicants pursuant to Title IV, Part B, of the Elementary and Secondary
Characterizing and Processing Robot-Directed Speech
 Characterizing and Processing Robot-Directed Speech Paulina Varchavskaia, Paul Fitzpatrick, Cynthia Breazeal AI Lab, MIT, Cambridge, USA [paulina,paulfitz,cynthia]@ai.mit.edu Abstract. Speech directed
Characterizing and Processing Robot-Directed Speech Paulina Varchavskaia, Paul Fitzpatrick, Cynthia Breazeal AI Lab, MIT, Cambridge, USA [paulina,paulfitz,cynthia]@ai.mit.edu Abstract. Speech directed
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
International Journal of Advanced Networking Applications (IJANA) ISSN No. :
 ISSN No. :") International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improved Hindi Broadcast ASR by Adapting the Language Model and Pronunciation Model Using A Priori Syntactic and Morphophonemic Knowledge
 Improved Hindi Broadcast ASR by Adapting the Language Model and Pronunciation Model Using A Priori Syntactic and Morphophonemic Knowledge Preethi Jyothi 1, Mark Hasegawa-Johnson 1,2 1 Beckman Institute,
Improved Hindi Broadcast ASR by Adapting the Language Model and Pronunciation Model Using A Priori Syntactic and Morphophonemic Knowledge Preethi Jyothi 1, Mark Hasegawa-Johnson 1,2 1 Beckman Institute,
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Noisy SMS Machine Translation in Low-Density Languages
 Noisy SMS Machine Translation in Low-Density Languages Vladimir Eidelman, Kristy Hollingshead, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department of
Noisy SMS Machine Translation in Low-Density Languages Vladimir Eidelman, Kristy Hollingshead, and Philip Resnik UMIACS Laboratory for Computational Linguistics and Information Processing Department of
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Effect of Word Complexity on L2 Vocabulary Learning
 Effect of Word Complexity on L2 Vocabulary Learning Kevin Dela Rosa Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave. Pittsburgh, PA kdelaros@cs.cmu.edu Maxine Eskenazi Language
Effect of Word Complexity on L2 Vocabulary Learning Kevin Dela Rosa Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave. Pittsburgh, PA kdelaros@cs.cmu.edu Maxine Eskenazi Language
Books Effective Literacy Y5-8 Learning Through Talk Y4-8 Switch onto Spelling Spelling Under Scrutiny
 By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Unit 9. Teacher Guide. k l m n o p q r s t u v w x y z. Kindergarten Core Knowledge Language Arts New York Edition Skills Strand
 q r s Kindergarten Core Knowledge Language Arts New York Edition Skills Strand a b c d Unit 9 x y z a b c d e Teacher Guide a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m
q r s Kindergarten Core Knowledge Language Arts New York Edition Skills Strand a b c d Unit 9 x y z a b c d e Teacher Guide a b c d e f g h i j k l m n o p q r s t u v w x y z a b c d e f g h i j k l m
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
English-German Medical Dictionary And Phrasebook By A.H. Zemback
 English-German Medical Dictionary And Phrasebook By A.H. Zemback If you are searching for a ebook English-German Medical Dictionary and Phrasebook by A.H. Zemback in pdf form, then you've come to loyal
English-German Medical Dictionary And Phrasebook By A.H. Zemback If you are searching for a ebook English-German Medical Dictionary and Phrasebook by A.H. Zemback in pdf form, then you've come to loyal
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Longman English Interactive
 Longman English Interactive Level 3 Orientation Quick Start 2 Microphone for Speaking Activities 2 Course Navigation 3 Course Home Page 3 Course Overview 4 Course Outline 5 Navigating the Course Page 6
Longman English Interactive Level 3 Orientation Quick Start 2 Microphone for Speaking Activities 2 Course Navigation 3 Course Home Page 3 Course Overview 4 Course Outline 5 Navigating the Course Page 6
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
CEFR Overall Illustrative English Proficiency Scales
 CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
SIE: Speech Enabled Interface for E-Learning
 SIE: Speech Enabled Interface for E-Learning Shikha M.Tech Student Lovely Professional University, Phagwara, Punjab INDIA ABSTRACT In today s world, e-learning is very important and popular. E- learning
SIE: Speech Enabled Interface for E-Learning Shikha M.Tech Student Lovely Professional University, Phagwara, Punjab INDIA ABSTRACT In today s world, e-learning is very important and popular. E- learning
Common Core Standards Alignment Chart Grade 5
 Common Core Standards Alignment Chart Grade 5 Units 5.OA.1 5.OA.2 5.OA.3 5.NBT.1 5.NBT.2 5.NBT.3 5.NBT.4 5.NBT.5 5.NBT.6 5.NBT.7 5.NF.1 5.NF.2 5.NF.3 5.NF.4 5.NF.5 5.NF.6 5.NF.7 5.MD.1 5.MD.2 5.MD.3 5.MD.4
Common Core Standards Alignment Chart Grade 5 Units 5.OA.1 5.OA.2 5.OA.3 5.NBT.1 5.NBT.2 5.NBT.3 5.NBT.4 5.NBT.5 5.NBT.6 5.NBT.7 5.NF.1 5.NF.2 5.NF.3 5.NF.4 5.NF.5 5.NF.6 5.NF.7 5.MD.1 5.MD.2 5.MD.3 5.MD.4
Small-Vocabulary Speech Recognition for Resource- Scarce Languages
 Small-Vocabulary Speech Recognition for Resource- Scarce Languages Fang Qiao School of Computer Science Carnegie Mellon University fqiao@andrew.cmu.edu Jahanzeb Sherwani iteleport LLC j@iteleportmobile.com
Small-Vocabulary Speech Recognition for Resource- Scarce Languages Fang Qiao School of Computer Science Carnegie Mellon University fqiao@andrew.cmu.edu Jahanzeb Sherwani iteleport LLC j@iteleportmobile.com
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company
 Houghton Mifflin Harcourt Publishing Company") WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
Large vocabulary off-line handwriting recognition: A survey
 Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Information for Candidates
 Information for Candidates BULATS This information is intended principally for candidates who are intending to take Cambridge ESOL's BULATS Test. It has sections to help them familiarise themselves with
Information for Candidates BULATS This information is intended principally for candidates who are intending to take Cambridge ESOL's BULATS Test. It has sections to help them familiarise themselves with
1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature
 August/September Strand Topic Standard Notes Reading for Literature") 1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
TEKS Comments Louisiana GLE
 Side-by-Side Comparison of the Texas Educational Knowledge Skills (TEKS) Louisiana Grade Level Expectations (GLEs) ENGLISH LANGUAGE ARTS: Kindergarten TEKS Comments Louisiana GLE (K.1) Listening/Speaking/Purposes.
Side-by-Side Comparison of the Texas Educational Knowledge Skills (TEKS) Louisiana Grade Level Expectations (GLEs) ENGLISH LANGUAGE ARTS: Kindergarten TEKS Comments Louisiana GLE (K.1) Listening/Speaking/Purposes.
Read&Write Gold is a software application and can be downloaded in Macintosh or PC version directly from https://download.uky.edu
 UK 101 - READ&WRITE GOLD LESSON PLAN I. Goal: Students will be able to describe features of Read&Write Gold that will benefit themselves and/or their peers. II. Materials: There are two options for demonstrating
UK 101 - READ&WRITE GOLD LESSON PLAN I. Goal: Students will be able to describe features of Read&Write Gold that will benefit themselves and/or their peers. II. Materials: There are two options for demonstrating
Experience: Virtual Travel Digital Path
 Experience: Virtual Travel Digital Path Introduction Content Organization This guide explores the digital content on myworldgeography.com and look at how it allows students to connect, experience, and
Experience: Virtual Travel Digital Path Introduction Content Organization This guide explores the digital content on myworldgeography.com and look at how it allows students to connect, experience, and
ROSETTA STONE PRODUCT OVERVIEW
 ROSETTA STONE PRODUCT OVERVIEW Method Rosetta Stone teaches languages using a fully-interactive immersion process that requires the student to indicate comprehension of the new language and provides immediate
ROSETTA STONE PRODUCT OVERVIEW Method Rosetta Stone teaches languages using a fully-interactive immersion process that requires the student to indicate comprehension of the new language and provides immediate
Mini Lesson Ideas for Expository Writing
 Mini LessonIdeasforExpositoryWriting Expository WheredoIbegin? (From3 5Writing:FocusingonOrganizationandProgressiontoMoveWriters, ContinuousImprovementConference2016) ManylessonideastakenfromB oxesandbullets,personalandpersuasiveessaysbylucycalkins
Mini LessonIdeasforExpositoryWriting Expository WheredoIbegin? (From3 5Writing:FocusingonOrganizationandProgressiontoMoveWriters, ContinuousImprovementConference2016) ManylessonideastakenfromB oxesandbullets,personalandpersuasiveessaysbylucycalkins
Reading Horizons. A Look At Linguistic Readers. Nicholas P. Criscuolo APRIL Volume 10, Issue Article 5
 Reading Horizons Volume 10, Issue 3 1970 Article 5 APRIL 1970 A Look At Linguistic Readers Nicholas P. Criscuolo New Haven, Connecticut Public Schools Copyright c 1970 by the authors. Reading Horizons
Reading Horizons Volume 10, Issue 3 1970 Article 5 APRIL 1970 A Look At Linguistic Readers Nicholas P. Criscuolo New Haven, Connecticut Public Schools Copyright c 1970 by the authors. Reading Horizons
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Language Acquisition Chart
 Language Acquisition Chart This chart was designed to help teachers better understand the process of second language acquisition. Please use this chart as a resource for learning more about the way people
Language Acquisition Chart This chart was designed to help teachers better understand the process of second language acquisition. Please use this chart as a resource for learning more about the way people
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Introduction to Causal Inference. Problem Set 1. Required Problems
 Introduction to Causal Inference Problem Set 1 Professor: Teppei Yamamoto Due Friday, July 15 (at beginning of class) Only the required problems are due on the above date. The optional problems will not
Introduction to Causal Inference Problem Set 1 Professor: Teppei Yamamoto Due Friday, July 15 (at beginning of class) Only the required problems are due on the above date. The optional problems will not
Application of Virtual Instruments (VIs) for an enhanced learning environment
 for an enhanced learning environment") Application of Virtual Instruments (VIs) for an enhanced learning environment Philip Smyth, Dermot Brabazon, Eilish McLoughlin Schools of Mechanical and Physical Sciences Dublin City University Ireland
Application of Virtual Instruments (VIs) for an enhanced learning environment Philip Smyth, Dermot Brabazon, Eilish McLoughlin Schools of Mechanical and Physical Sciences Dublin City University Ireland
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
Problems of the Arabic OCR: New Attitudes
 Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
Revisiting the role of prosody in early language acquisition. Megha Sundara UCLA Phonetics Lab
 Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining
 Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl