Crosslinguistic Quantitative Syntax: Dependency Length and Beyond. Richard Futrell work with Kyle Mahowald and Ted Gibson 22 September 2016
|
|
|
- Darcy Wheeler
- 6 years ago
- Views:
Transcription
1 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Richard Futrell work with Kyle Mahowald and Ted Gibson 22 September 2016
2 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Quantitative Syntax with Dependency Corpora Dependency Length Minimization Comparison to Random Baselines Grammar and Usage Residue of Dependency Length Minimization Conclusion
3 Quantitative Syntax and Functional Typology This work is about using crosslinguistic dependency corpora to do quantitative syntax. It s also about communicative functional typology, which posits that languages have developed structures that make utterances easy to use in communication. Such theories make predictions at the level of the utterance, since they predict that the average utterance will have desirable properties. So quantitative corpus syntax is a natural way to test communicative hypotheses for language universals. This talk explores the hypothesis that there is a universal pressure to minimize dependency lengths, which leads to easier parsing and generation of sentences.

4 Preview of Dependency Length Results We find that dependency length of real utterances is shorter than in linguistically motivated random baselines. We develop models of grammatical dependency tree linearizations. In almost all languages, dependency length in real utterances is shorter than random grammatical reorderings of those utterances. Dependency length Ancient Greek Basque Bulgarian Church Slavonic Croatian Czech Danish Dutch English Estonian Finnish French German Gothic Hebrew Hindi Hungarian Indonesian 100 real free random 80 rand_proj_lin_hdr_lic 60 rand_proj_lin_hdr_mle rand_proj_lin_perplex 40 real Irish Italian Japanese Latin Modern Greek Norwegian (Bokmål) Persian Portuguese Romanian Slovenian Spanish Swedish Sentence length grc fa la de tr bn We explore crosslinguistic variation in dependency length and find it is non-uniform. Explaining these results is a challenge for functional typology. Dependency length ar ga id fa la grc de cu got orv nlet zh ru no hr xcl sk da enfi eu ro cssl sv pl he bg pt ca el es fr it hu bn hi tr ta ko ja ar fa grc bn la de cu nl tr got orv et zh hi eu hu ru ga sk da fi xcl nocs sl sven el ta pl ro hehrbg ca id esptit fr ko ja ar cu orv got zh nl hi eu ru hu da fi sk sl ga no cs pl xcl sven ro hr bg el idhe pt fr ca es it et ko ja ta Proportion head final
5 Data Sources There has been a recent effort in the NLP community to develop standardized dependency corpora of many languages for use in training parsers. Results: Universal Dependencies: Hand-parsed or -corrected corpora of 35+ languages, modern and ancient (Nivre et al., 2015) HamleDT: Automatic conversion of hand-parsed corpora to Universal Dependencies style. (Zeman et al., 2012, 2014) Google Universal Treebank: A predecessor to UD, which still has some languages which UD doesn t (McDonald et al., 2013) PROIEL: Texts in Indo-European classical languages (Haug and Jøhndal, 2008). Corpora vary in their public availability but most are easy to get.
6 Language Family/subfamily or Sprachbund Indonesian Austronesian Tamil Dravidian Telugu Dravidian Japanese East Asian Korean East Asian Classical Armenian IE/Armenian Irish IE/Celtic Ancient Greek IE/Classical Latin IE/Classical Danish IE/Germanic German IE/Germanic English IE/Germanic Dutch IE/Germanic Swedish IE/Germanic Gothic IE/Germanic Norwegian (B) IE/Germanic Modern Greek IE/Greek Bengali IE/Indo-Aryan Persian IE/Indo-Aryan Hindi IE/Indo-Aryan Catalan IE/Romance Spanish IE/Romance Language French Italian Portuguese Romanian Bulgarian Church Slavonic Croatian Czech Russian Old Russian Slovak Slovenian Polish Basque Arabic Hebrew Turkish Estonian Finnish Hungarian Mandarin Family/subfamily or Sprachbund IE/Romance IE/Romance IE/Romance IE/Romance IE/Slavic IE/Slavic IE/Slavic IE/Slavic IE/Slavic IE/Slavic IE/Slavic IE/Slavic IE/Slavic Isolate Semitic Semitic Turkic Uralic/Finnic Uralic/Finnic Uralic/Ugric Sino-Tibetan
7 Universal Dependencies Annotation PRON VERB ADP DET NOUN ADP DET NOUN Sentences annotated with dependency tree, dependency arc labels, wordforms, and Google Universal POS tags. For most but not all languages, all of these levels of annotation are available. Data sources are newspapers, novels (inc. some translated novels), blog posts, and some spoken language. (Sentence 99 in the English UD dev set)
8 Universal Dependencies Annotation PRON VERB ADP DET NOUN ADP DET NOUN Some of the annotation decisions are surprising from the perspective of purely syntactic dependencies. (Sentence 99 in the English UD dev set)
9 Universal Dependencies Annotation In order to parse English uniformly with languages that would have item with a case marker and no adposition, UD parses prepositional phrases with the noun as the head and the preposition as a dependent. Similarly, complementizers are dependents of verbs, auxiliary verbs are dependents of content verbs, and predicates are heads of copula verbs (!). The dependencies in their raw from thus reflect grammatical relations more than syntactic dependencies (de Marneffe and Manning, 2008; de Marneffe et al., 2014; Nivre, 2015).
10 Universal Dependencies Annotation PRON VERB ADP DET NOUN ADP DET NOUN Fortunately, it is often possible to convert UD dependencies automatically into syntactic dependencies. And for HamleDT corpora and other non-ud corpora, Praguestyle syntactic dependencies are often available. We prefer syntactic dependencies for dependency length studies.
11 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Quantitative Syntax with Dependency Corpora Dependency Length Minimization Comparison to Random Baselines Grammar and Usage Residue of Dependency Length Minimization Conclusion
12 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Dependency Length Minimization As an empirical phenomenon As a typological theory Cognitive motivations
13 Dependency Length Minimization as an Empirical Phenomenon: Weight Preferences Behaghel s Four Laws of Word Order (1909): 1. Mentally closely related items will be placed close together. 2. Given before new; 3. Modifier before modified 4. Short constituents before long constituents There is good quantitative evidence for this preference in English (e.g. Wasow, 2002) and German (Hawkins, 2004). In extreme cases the shortbefore-long preference produces orders that are otherwise ungrammatical (Heavy NP Shift). Short-before-long produces shorter dependency lengths than long-before-short in head-initial structures: In head-final structures, long-before-short is preferred (Yamashita & Chang, 2001).
14 Dependency Length Minimization as an Empirical Phenomenon: Weight Preferences
15 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Dependency Length Minimization As an empirical phenomenon As a typological theory Cognitive motivations
16 Dependency Length Minimization as a Typological Theory In addition to explaining order preferences within utterances, a pressure to minimize dependency lengths can explain word order universals (Hawkins, 1991, 1994): When dependency trees have low arity, DLM is achieved by consistent head direction: as opposed to Possible explanation for harmonic orders (Greenberg 1963, Vennemann, 1973): OV order is correlated with Noun-Adposition, Adjective-Noun, Determiner-Noun, etc.: consistently head final. VO order is correlated with Adposition-Noun, Noun-Adjective, Noun-Determiner, etc.: consistently head initial.
17 Dependency Length Minimization as a Typological Theory For higher-arity trees, a (projective) grammar should arrange phrases outward from a head in order of increasing average length (Gildea & Temperley, 2007). as opposed to or Consistent with Dryer s (1992) observations that exceptions to harmonic orders are usually for short constituents such as determiners.
18 Dependency Length Minimization as a Typological Theory DLM has been advanced as an explanation for the prevalence of projective dependencies corresponding to context-freeness in language (Ferrer i Cancho, 2004). pobj adjmod pmod object adjmod subject object in nova fert animus mūtātas dīcere formas corpora pobj subject object object adjmod pmod adjmod [animus fert [dīcere [formas [mūtātas [in [nova corpora]]]]]]
19 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Dependency Length Minimization As an empirical phenomenon As a typological theory Cognitive motivations
20 Motivation for Dependency Length Minimization When parsing a sentence incrementally, dependency length is the lower bound on the amount of time you have to hold a word in memory (Abney & Johnson, 1991). Making a syntactic connection between the current word and a previous word might be hard if the previous word has been in memory for a long time, because of decay of memory representations (DLT integration cost: Gibson, 1999, 2000) or similarity-based interference (Vasishth & Lewis, 2006). Reading time evidence for integration cost in controlled experiments (Grodner & Gibson, 2005) (but corpus evidence is mixed: see Demberg & Keller, 2008). Short dependencies means a smaller domain to search for the head of a phrase (Hawkins, 1994).
21 Motivation for Dependency Length Minimization Convergent predictions from multiple theories predicting easier processing when dependency length is minimized. In current work we are agnostic to the precise motivation for DLM.
22 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Quantitative Syntax with Dependency Corpora Dependency Length Minimization Comparison to Random Baselines Grammar and Usage Residue of Dependency Length Minimization Conclusion
23 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Comparison to Random Baselines Motivation and Methodology Free Order Projective Baseline Fixed Order Projective Baseline Consistent Head Direction Projective Baseline
24 DLM is an appealing theory, but But there are other explanations for the putative typological effects of DLM: Consistent head direction might have to do with simplicity of grammar. Projectivity might be motivated by parsing complexity. If actual utterances do not have shorter dependency length than what one would expect from these (and other) independently motivated constraints, then the evidence for DLM as the functional pressure explaining these constraints is weakened. Our research question: Do real utterances in many languages have word orders that minimize dependency length, compared to what one would expect under these constraints?
25 Random Reorderings as a Baseline Do the recently available parsed corpora of 40+ languages show evidence that dependency lengths are shorter than what we would expect under independently motivated constraints? Methodology: Comparison of attested orders to random reorderings of the same dependency trees with various constraints. Methodology of Gildea & Temperley (2007, 2010), Park & Levy (2009), Hawkins (1999), Gildea & Jaeger (ms) Similar approach: comparison to random tree structures (Liu, 2008; Ferrer i Cancho and Liu, 2015; Lu, Xu, and Liu, 2015) Measure dependency length as number of words intervening between head and dependent + 1.
26 Why Random Reorderings? Tree structures / content expressed Dependency length Word order rules and preferences Our approach is to hold tree structure constant and study whether word orders are optimized given those tree structures. Allows us to isolate the specific effect of DLM on word order.
27 Unconstrained Random Baseline Total:
28 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Comparison to Random Baselines Motivation and Methodology Free Order Projective Baseline Fixed Order Projective Baseline Consistent Head Direction Projective Baseline
29 Projective Random Baseline comes from story AP this the
30 Projective Random Baseline comes story from this AP the
31 Projective Random Baseline comes story from this AP the

32 Projective Random Baseline comes story from this AP the
33 Projective Random Baseline Total:
34 Previous Results The random projective baseline was used previously in Gildea & Temperley (2007, 2010) and Park & Levy (2009).
35
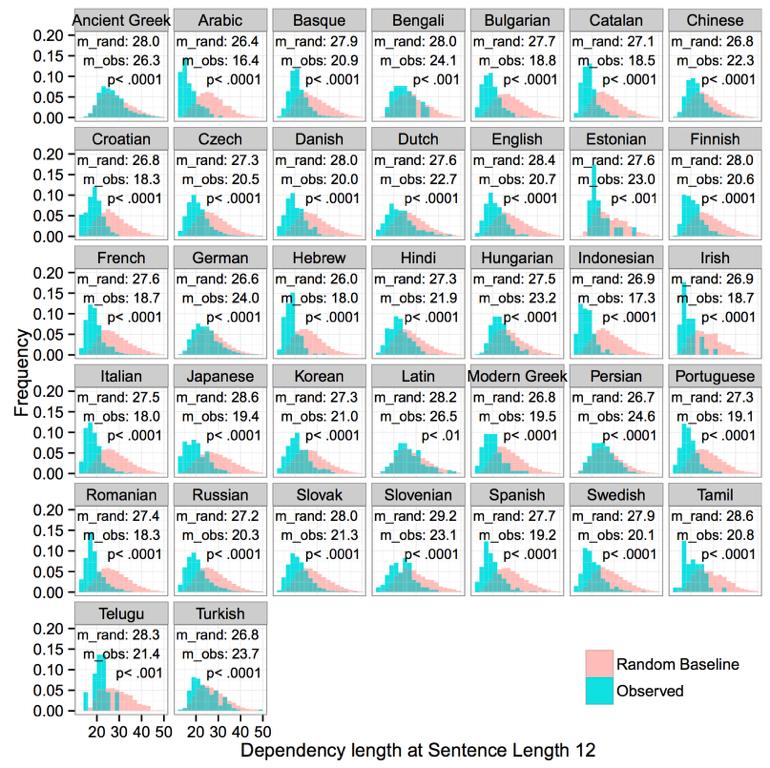
36
37 Statistical Model To test the significance of the effect that real dependency lengths are shorter than the random baseline, we fit a mixed effects regression for each language. For each sentence, predict dependency length of each linearized tree given: (1) Sentence length (squared), (2) Whether the linearization is real [0] or random [1], (3) Random slope of (2) conditional on sentence identity. The coefficient for (1) is the dependency length growth rate for real sentence. The interaction of (1) and (2) is the difference in dependency length growth rate for baseline linearizations as opposed to attested linearizations. This interaction is the coefficient of interest. The interaction of (1) and (2) is significantly positive in all languages (p < 0.001).
38
39 Conclusions So Far Observed dependency length is not explained by projectivity alone.
40 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Comparison to Random Baselines Motivation and Methodology Free Order Projective Baseline Fixed Order Projective Baseline Consistent Head Direction Projective Baseline
41 Fixed Order Projective Baseline The previous baseline simulated languages with no word order restrictions beyond projectivity. Speakers speaking random languages randomly. Here we simulate random linearization grammars with fixed word order for given dependency types. Speakers speaking random languages deterministically. E.g., languages in which subjects always come before verbs, or adjectives always come before nouns, etc. Might affect dependency length because head direction will be more consistent within utterances.
42 Fixed Order Projective Baseline adpmod comes nsubj Linearization Grammar from pobj det AP this story det adpmod: -.9 pobj:.5 det:.4 nsubj: -.3 the Procedure: Assign each dependency type (nsubj, adpmod, etc.) a "weight" in [-1, 1]. Call the mapping of dependency types to weights a linearization grammar G. Linearize the sentence according to G: Place each dependent in order of increasing weight, placing the head as if it had weight 0.
43 Fixed Order Projective Baseline adpmod comes nsubj from the pobj det AP this story det Linearization Grammar adpmod: -.9 pobj:.5 det:.4 nsubj: -.3
44 Fixed Order Projective Baseline adpmod comes nsubj from the pobj det AP this story det Linearization Grammar adpmod: -.9 pobj:.5 det:.4 nsubj: -.3
45 Fixed Order Projective Baseline adpmod comes nsubj from the pobj det AP this story det Linearization Grammar adpmod: -.9 pobj:.5 det:.4 nsubj: -.3
46 Fixed Order Projective Baseline from adpmod pobj AP det the story det comes nsubj this Linearization Grammar adpmod: -.9 pobj:.5 det:.4 nsubj: -.3
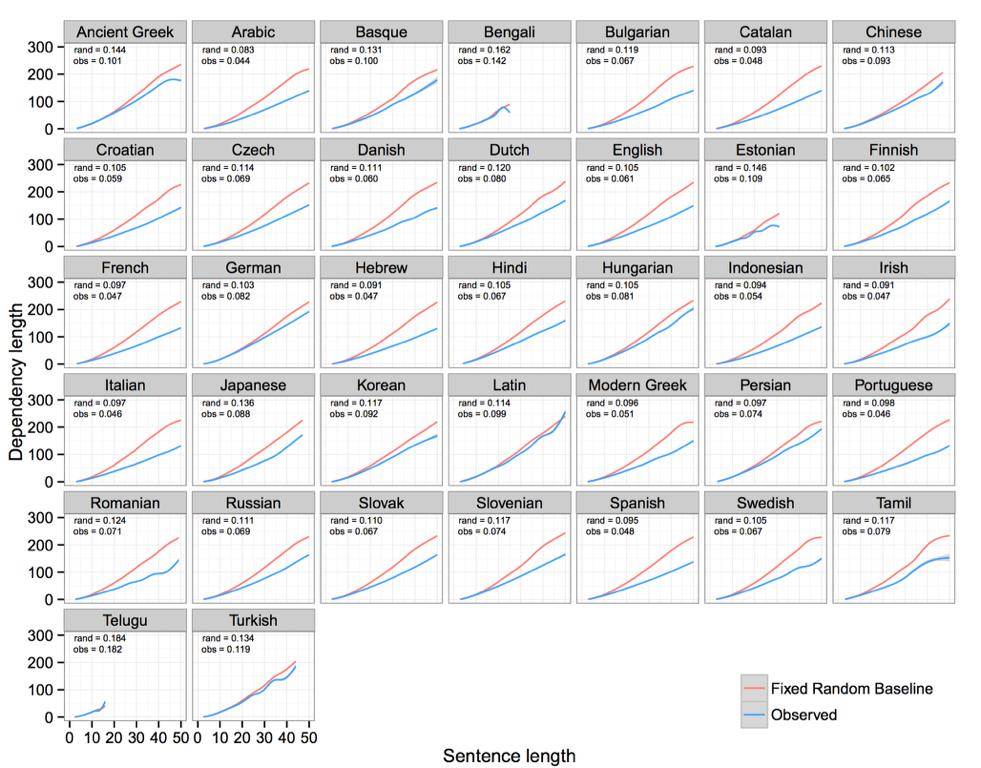
47
48 Conclusions So Far Observed dependency length is not explained by projectivity alone. Observed dependency length is not explained by projectivity in conjunction with fixed word order.
49 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Comparison to Random Baselines Motivation and Methodology Free Order Projective Baseline Fixed Order Projective Baseline Consistent Head Direction Projective Baseline
50 Consistent Head Direction Projective Baseline Could observed dependency length be explained by a combination of (1) projectivity and (2) consistent head direction? Let s compare to random projective reorderings with consistent head direction.
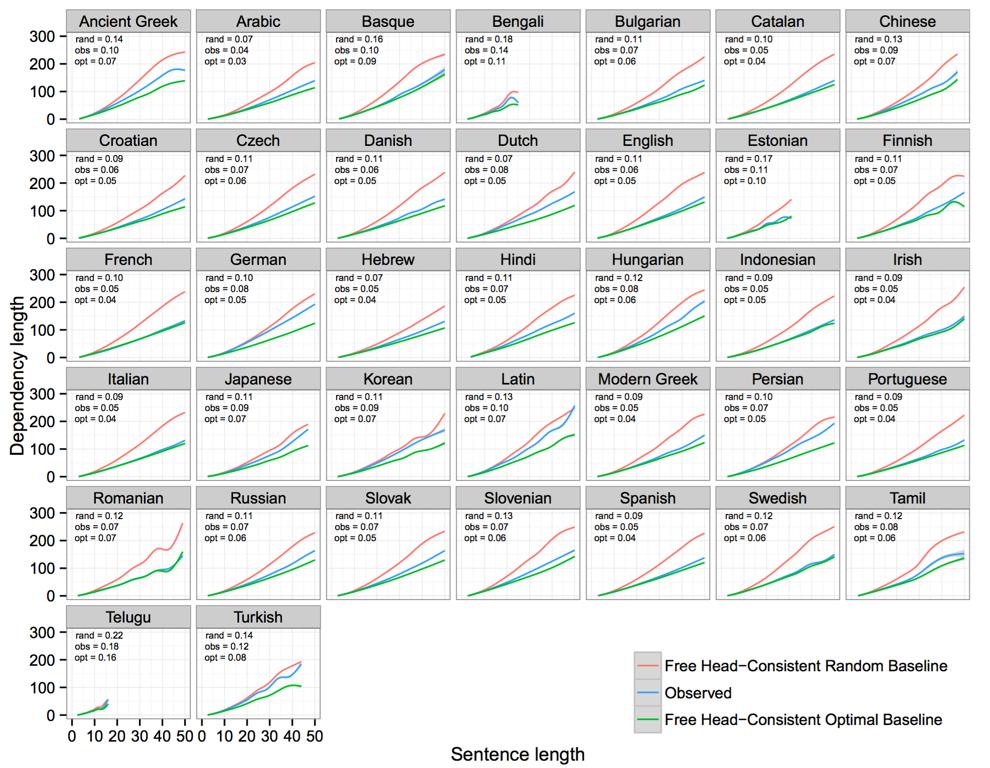
51
52 Conclusions So Far Observed dependency length is not explained by projectivity alone. Observed dependency length is not explained by projectivity in conjunction with fixed word order. Observed dependency length is not explained by a pressure for consistency in head direction. For strongly head-initial and head-final languages, this implies the existence of short-before-long or longbefore-short order preferences. Overall, dependency length minimization effects are not explained by various alternative principles evidence that dependency length minimization is a pressure in itself.
53 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Quantitative Syntax with Dependency Corpora Dependency Length Minimization Comparison to Random Baselines Grammar and Usage Residue of Dependency Length Minimization Conclusion
54 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Grammar and Usage Relevance to Dependency Length Minimization Modeling Grammatical Orders Results
55 Grammar and Usage We can think of each attested linearization of a tree as resulting from application of multiple filters: choose many choose one All orders Grammatical orders (for the particular language) Attested order Where does DLM happen?
56 Grammar and Usage choose many choose one All orders Grammatical orders (for the particular language) Attested order Where does DLM happen? (Not exclusive.) Grammar: The language filters out bad orders. A random sample from the set of grammatical orders will have desirable dependency length. Usage: The speaker chooses orders based on dependency length. There need not be optimization at the grammar step.
57 Grammar and Usage choose many choose one All orders Grammatical orders (for the particular language) Attested order DLM through Usage:
58 Grammar and Usage choose many choose one All orders Grammatical orders (for the particular language) Attested order DLM through Usage: Choosing optimal orderings on a per-sentence basis. With unconstrained grammar, this would give the best dependency length properties.
59 Grammar and Usage choose many choose one All orders Grammatical orders Attested order (for the particular language) DLM through Grammar: tall woman Mars on lives Language 1 V final A-N N-P
60 Grammar and Usage choose many choose one All orders Grammatical orders Attested order (for the particular language) DLM through Grammar: Mars on tall woman lives Language 1 V final A-N N-P
61 Grammar and Usage choose many choose one All orders Grammatical orders Attested order (for the particular language) DLM through Grammar: woman tall on Mars lives Language 2 V final N-A P-N
 DLM through Grammar: on Mars woman tall lives Language 2 V final N-A")
62 Grammar and Usage choose many choose one All orders Grammatical orders Attested order (for the particular language) DLM through Grammar: on Mars woman tall lives Language 2 V final N-A P-N
63 Grammar and Usage choose many choose one All orders Grammatical orders Attested order (for the particular language) DLM through Grammar: For certain sentences, Language 1 is better on average than Language 2. Language 1 V final A-N N-P Language 2 V final N-A P-N
64 Random Grammatical Reorderings Total:
65 Random Grammatical Reorderings Total: 9 Probability
66 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Grammar and Usage Relevance to Dependency Length Minimization Modeling Grammatical Orders Results
67 Linearization Models We want to be able to induce from corpora a model of the possible grammatical linearizations of a given dependency tree. Task: Given an unordered dependency tree U, find the probability distribution over ordered dependency trees T with the same structure as U. This is a known task in NLP, as part of natural language generation pipelines (Belz et al., 2011; Rajkumar & White, 2014). For more details on models and their evaluation, see Futrell & Gibson (2015, EMNLP).
68 Conditioning on Trees NOUN VERB NOUN DET In an ideal world, we would base a linearization model on joint counts of full tree structures and full word orders. But counts of directed tree structures given unordered full tree structures as the conditioning variable would be far too sparse: most tree structures appear only once. Hans sah den Mann: 1 den Mann sah Hans: 0 First thing to do is drop wordforms, and condition on tree structures with POS tags. But even this will still be sparse.
69 Breaking Trees Apart VERB So, we get conditional counts of orders of local subtrees. NOUN NOUN DET
70 Breaking Trees Apart NOUN VERB NOUN NOUN/nsubj VERB/head NOUN/dobj: 55 NOUN/dobj VERB/head NOUN/nsubj: 25 NOUN DET DET/det NOUN/head: 500 NOUN/head DET/det: 1 So, we get conditional counts of orders of local subtrees. Interpretable: We get information about order constraints between sister dependents. Modeling only local subtrees is equivalent to modeling a language with a (strictly headed) PCFG. But: We lose conditioning information from outside the local subtree. Also, we lose the ability to model nonprojective (non-context-free) orders.
71 What s in a Tree? VERB NOUN NOUN NOUN/nsubj X/nsubj VERB/head X/head X/dobj: NOUN/dobj: NOUN/dobj X/dobj VERB/head X/head X/nsubj: NOUN/nsubj: NOUN Then another question is: what aspects of the local subtrees do we condition on? POS tags for head and dependents, and relation types? Or maybe don t consider the POS of the head? Or maybe don t consider the POS of the dependents? DET DET/det X/det X/head: NOUN/head: NOUN/head X/head DET/det: X/det: 54 1
72 Linearization Models To strike a balance between accuracy and data sparsity, we combine models that condition on more and less context to form a backoff distribution. We can also smooth the model by considering N-gram probabilities of orders within local subtrees. Backoff weights determined by Baum-Welch algorithm.
73 Linearization Models from Generative Dependency Models We want a model of ordered trees T conditional on unordered trees U. We can derive these models from head-outward generative models that generate T from scratch (Eisner, 1996; Klein and Manning, 2004). Basic form of these models: comes # from story today # # AP # # this # # # # the # "From the AP comes this story today."
74 Linearization Models from Generative Dependency Models In these models, dependency trees are generated from a set of N-gram models conditional on head word and direction. So if we want a model of ordered trees conditional on unordered trees, we just need a model of ordered sequences conditional on unordered sequences generated by an N-gram model. p(abc) p(abc {A, B, C}) Dynamic programming permutations of w
75
76 Evaluating Linearization Models We have a large parameter space for linearization models. We evaluate different parameters in three ways: 1. Test Set Perplexity: Which model setting gives the highest probability to unseen trees in dependency corpora? 2. Acceptability: Ask people how natural the reordered sentences sound on a scale of 1 to Same meaning: Ask people whether the reordered sentence means the same thing as the original sentence. The last two evaluations were done on Mechanical Turk for English models only.

77 Best Models The best model for perplexity is the one with the most smoothing. The best models for acceptability and same meaning are more conservative models based on POS N-grams within local subtrees. For English, best acceptability is 3.8 / 5 on average. (Original sentences are 4.7 / 5 on average.) For English, the best model produces orders with the same meaning as the original 85% of the time (close to the state of the art).
78 Best Models Models that give higher probability to held-out orders also produce orders that are rated more acceptable in English.
79 Models to Run For dependency length experiments, we compare attested dependency length to random linearizations under three models: 1. The model that selects uniformly among attested orders for local subtrees, conditional on POS tags for head and dependent. 2. The model with the best perplexity score (highly smoothed). 3. The model with the best same-meaning rating for English (more conservative).
80 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Grammar and Usage Relevance to Dependency Length Minimization Modeling Grammatical Orders Results
81 100 Ancient Greek Basque Bulgarian Church Slavonic Croatian Czech Danish Dutch English Estonian Finnish French Dependency length German Gothic Hebrew Hindi Hungarian Indonesian Linearization real free Free random projective rand_proj_lin_hdr_lic Random (licit) rand_proj_lin_hdr_mle Random (same meaning) rand_proj_lin_perplex Random (best perplexity) real Real 100 Irish Italian Japanese Latin Modern Greek Norwegian (Bokmål) Persian Portuguese Romanian Slovenian Spanish Swedish Sentence length
82 100 Ancient Greek Basque Bulgarian Church Slavonic Croatian Czech Danish Dutch English Estonian Finnish French Dependency length German Gothic Hebrew Hindi Hungarian Indonesian Linearization real free Free random projective rand_proj_lin_hdr_lic Random (licit) rand_proj_lin_hdr_mle Random (same meaning) rand_proj_lin_perplex Random (best perplexity) real Real 100 Irish Italian Japanese Latin Modern Greek Norwegian (Bokmål) Persian Portuguese Romanian Slovenian Spanish Swedish Sentence length
83 Conclusions Dependency length of real utterances is shorter than random grammatical linearizations under these models. We would like to conclude that this means: (1) There is a universal pressure in usage for DLM, (2) Grammars are optimized so that the average utterance will have short dependency length. However, our conclusions are only as strong as our linearization models. We only consider projective reorderings within local subtrees. The models are based on limited data and may miss certain licit orders.
84 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Quantitative Syntax with Dependency Corpora Dependency Length Minimization Comparison to Random Baselines Grammar and Usage Residue of Dependency Length Minimization Conclusion
85 Residue of DLM We have studied dependency length with the hypothesis that there is a universal pressure for dependency lengths to be short, and that this affects grammar and usage. But having controlled for various baselines, there remains residual variance between languages in dependency length. No new baselines in this part, rather we ask the question: What linguistic properties determine whether a language has short or long dependencies? We do not have formal explanations for these findings, but offer some directions for explaining them.
86 Residue of DLM
87 Head-Finality We see relatively long dependency length for strongly head-final languages such as Japanese, Korean, Tamil, Turkish. Comparing dependency length at fixed sentence lengths to the proportion of head-final dependencies in a corpus, we find correlations of dependency length with head finality: fa la grc de tr bn cu orv got nl zh hi ko Dependency length ar fa grc la de cu nl got orv et zh eu ru ga sk da fi xcl nocs sl sven el pl ro hehrbg ca id esptit fr bn tr hi hu ta ko ja ar eu ru da fi sk sl ga no cs pl xcl sven ro hr bg el idhe pt fr ca es it et hu ta ja fa la grc 20 ar ga id de cu got orv nlet zh ru no hr xcl sk da enfi pl cs eu rosl sv he bg pt ca el es fr it bn hi tr hu ta ko ja Proportion head final
88 ar bg cs cu da de Weight el en es et eu fa fi fr ga got grc he hi hr hu id it ja la nl no pl pt ro sl sv ta Position
89 Weight ar bg cs cu da de el en es et eu fa fi fr ga got grc he hi hr hu id it ja la nl no pl pt ro sl sv ta Position
90 0.6 ar bg cs cu da de el en es et eu fa fi fr ga got grc he Weight hi hr hu id it ja la nl no pl pt ro sl sv ta Position
91 ar bg cs cu da de el en es et eu fa fi fr ga got grc he Weight hi hr hu id it ja la nl no pl pt ro sl sv ta Position
92 Dependency Length and Head-Finality Under the integration cost theories of processing difficulty, where there is difficulty for linking a word to another word that has been in memory for a long time, we expect no asymmetry between head final and head initial dependencies. But integration cost effects are typically not observed in head-final constructions where many modifiers precede the head (Konieczny, 2000; Vasishth & Lewis, 2006; Levy, 2008). Perhaps head-final dependencies incur less processing cost, so there is less pressure to minimize the distances of the dependencies.
93 Back to this figure
94 Word Order Freedom We measure word order freedom as the conditional entropy of the direction of a word s head, conditional on the part-of-speech of the word and the relation type of the dependency. (Futrell, Mahowald & Gibson, 2015, DepLing) tr de bn fa grc la ko hi zh cu got nl orv Dependency length bn fa grc la de ko tretnl zh cu hi got orv hu eu ru ja ga ta el slsk dafi encs nosv xcl heca bghr pl es it ro frpt ar id ja hu eu ru dafi sl sk ga en cs no ta sv ro pl el bghr ar he fr ptcaid es it et xcl 20 ga fa grc la bn de nl tr zh got etcu hi ja ko orv hu ru ta en sl skdafi eu no cs hr xcl pt he ca el sv ro bgpl it ar es fr id BDE
95 Dependency Length and Word Order Freedom In languages with a high degree of freedom in whether the head of a word is to its right or left, we find longer dependencies. One would think that speakers of languages with lots of word order freedom would use that freedom to select the orders that highly minimize dependency length. On the other hand, such languages typically have complex morphology. If the difficulty of processing long dependencies is due to similarity-based interference (Lewis & Vasishth, 2006), then words with more distinctive morphology will be less confusable and retrieving them from memory will be easier. So we might expect morphologically complex languages to have longer dependencies: long dependencies incur less processing difficulty in such languages.
96 Morphological Complexity We measure morphological complexity as the entropy of words (the information content of words) minus the entropy of lemmas (the information content of lemmas). We estimate these entropies from corpus counts using state-of-the-art entropy estimation methods (the Pitman-Yor Mixture method of Archer et al., 2014) la grc tr hi nl got cu orv mdd nl hi da en no sv ro esptit la et got hu ru ga xcl cs tael sl bg hr grc cu orv eu fi pl tr da en no sv ro pt es it ga cs xcl ta bg el hr et ru hu sl eu pl fi la grc 20 hi nl da en no sv ro pt es it et got ga ru xcl hu hrcs ta sl bg el cu orv eu fi pl tr morpho_entropy
97 Dependency Length and Morphology Consistent with the concept that languages with more informative morphology will have create less difficulty in processing long dependencies, we find longer dependency lengths in such languages. Real formalization of this notion would require a processing model that integrates morphological complexity and dependency length, and a way to find orders that minimize parsing difficulty under such a model.
98 Crosslinguistic Quantitative Syntax: Dependency Length and Beyond Quantitative Syntax with Dependency Corpora Dependency Length Minimization Comparison to Random Baselines Grammar and Usage Residue of Dependency Length Minimization Conclusion
99 Conclusion We have provided large-scale corpus evidence for dependency length minimization beyond what is explained by projectivity, fixedness of word order, and consistency of head direction. Evidence for dependency length minimization as a principle that is independent of those other constraints, or which subsumes those constraints.
100 Conclusion We have shown that attested utterances have shorter dependency length than random grammatical reorderings of those utterances, and that the random grammatical reorderings have shorter dependency length than under random grammars. Evidence for universal DLM in grammar and usage.
101 Conclusion We have shown residual covariance of dependency length with other linguistic features. Suggests that DLM is not enough we need other, more detailed theories to explain the quantitative distribution of dependency lengths.
102 Thanks all! Thanks to Tim O Donnell, Roger Levy, Kristina Gulordava, Paola Merlo, Ramon Ferrer i Cancho, Christian Bentz, and Timothy Osborne for helpful discussions. This work was supported by NSF Doctoral Dissertation Improvement Grant # to Richard Futrell, an NDSEG fellowship to Kyle Mahowald, and NSF grant # to Ted Gibson.
103 This talk is based on these papers (but a lot of it isn t published yet!) Futrell, Mahowald & Gibson (2015). Large-scale evidence of dependency length minimization in 37 languages. PNAS. Futrell, Mahowald & Gibson (2015). Quantifying word order freedom in dependency corpora. Proceedings of DepLing. Futrell & Gibson (2015). Experiments with generative models for dependency tree linearization. Proceedings of EMNLP.
ROSETTA STONE PRODUCT OVERVIEW
 ROSETTA STONE PRODUCT OVERVIEW Method Rosetta Stone teaches languages using a fully-interactive immersion process that requires the student to indicate comprehension of the new language and provides immediate
ROSETTA STONE PRODUCT OVERVIEW Method Rosetta Stone teaches languages using a fully-interactive immersion process that requires the student to indicate comprehension of the new language and provides immediate
Approved Foreign Language Courses
 University of California, Berkeley 1 Approved Foreign Language Courses Approved Foreign Language Courses To find a language, look in the Title column first; many subject codes do not match the language
University of California, Berkeley 1 Approved Foreign Language Courses Approved Foreign Language Courses To find a language, look in the Title column first; many subject codes do not match the language
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels
 Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
LNGT0101 Introduction to Linguistics
 LNGT0101 Introduction to Linguistics Lecture #11 Oct 15 th, 2014 Announcements HW3 is now posted. It s due Wed Oct 22 by 5pm. Today is a sociolinguistics talk by Toni Cook at 4:30 at Hillcrest 103. Extra
LNGT0101 Introduction to Linguistics Lecture #11 Oct 15 th, 2014 Announcements HW3 is now posted. It s due Wed Oct 22 by 5pm. Today is a sociolinguistics talk by Toni Cook at 4:30 at Hillcrest 103. Extra
DETECTING RANDOM STRINGS; A LANGUAGE BASED APPROACH
 DETECTING RANDOM STRINGS; A LANGUAGE BASED APPROACH Mahdi Namazifar, PhD Cisco Talos PROBLEM DEFINITION! Given an arbitrary string, decide whether the string is a random sequence of characters! Disclaimer
DETECTING RANDOM STRINGS; A LANGUAGE BASED APPROACH Mahdi Namazifar, PhD Cisco Talos PROBLEM DEFINITION! Given an arbitrary string, decide whether the string is a random sequence of characters! Disclaimer
The Ohio State University. Colleges of the Arts and Sciences. Bachelor of Science Degree Requirements. The Aim of the Arts and Sciences
 The Ohio State University Colleges of the Arts and Sciences Bachelor of Science Degree Requirements Spring Quarter 2004 (May 4, 2004) The Aim of the Arts and Sciences Five colleges comprise the Colleges
The Ohio State University Colleges of the Arts and Sciences Bachelor of Science Degree Requirements Spring Quarter 2004 (May 4, 2004) The Aim of the Arts and Sciences Five colleges comprise the Colleges
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Minimalism is the name of the predominant approach in generative linguistics today. It was first
 Minimalism Minimalism is the name of the predominant approach in generative linguistics today. It was first introduced by Chomsky in his work The Minimalist Program (1995) and has seen several developments
Minimalism Minimalism is the name of the predominant approach in generative linguistics today. It was first introduced by Chomsky in his work The Minimalist Program (1995) and has seen several developments
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Chapter 5: Language. Over 6,900 different languages worldwide
 Chapter 5: Language Over 6,900 different languages worldwide Language is a system of communication through speech, a collection of sounds that a group of people understands to have the same meaning Key
Chapter 5: Language Over 6,900 different languages worldwide Language is a system of communication through speech, a collection of sounds that a group of people understands to have the same meaning Key
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures
 Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Section V Reclassification of English Learners to Fluent English Proficient
 Section V Reclassification of English Learners to Fluent English Proficient Understanding Reclassification of English Learners to Fluent English Proficient Decision Guide: Reclassifying a Student from
Section V Reclassification of English Learners to Fluent English Proficient Understanding Reclassification of English Learners to Fluent English Proficient Decision Guide: Reclassifying a Student from
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS
 Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Accurate Unlexicalized Parsing for Modern Hebrew
 Accurate Unlexicalized Parsing for Modern Hebrew Reut Tsarfaty and Khalil Sima an Institute for Logic, Language and Computation, University of Amsterdam Plantage Muidergracht 24, 1018TV Amsterdam, The
Accurate Unlexicalized Parsing for Modern Hebrew Reut Tsarfaty and Khalil Sima an Institute for Logic, Language and Computation, University of Amsterdam Plantage Muidergracht 24, 1018TV Amsterdam, The
UNIVERSITY OF OSLO Department of Informatics. Dialog Act Recognition using Dependency Features. Master s thesis. Sindre Wetjen
 UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Developing a TT-MCTAG for German with an RCG-based Parser
 Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Bachelor of Arts in Gender, Sexuality, and Women's Studies
 Bachelor of Arts in Gender, Sexuality, and Women's Studies 1 Bachelor of Arts in Gender, Sexuality, and Women's Studies Summary of Degree Requirements University Requirements: MATH 0701 (4 s.h.) and/or
Bachelor of Arts in Gender, Sexuality, and Women's Studies 1 Bachelor of Arts in Gender, Sexuality, and Women's Studies Summary of Degree Requirements University Requirements: MATH 0701 (4 s.h.) and/or
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Revisiting the role of prosody in early language acquisition. Megha Sundara UCLA Phonetics Lab
 Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Revisiting the role of prosody in early language acquisition Megha Sundara UCLA Phonetics Lab Outline Part I: Intonation has a role in language discrimination Part II: Do English-learning infants have
Words come in categories
 Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
The Acquisition of English Grammatical Morphemes: A Case of Iranian EFL Learners
 105 By Fatemeh Behjat & Firooz Sadighi The Acquisition of English Grammatical Morphemes: A Case of Iranian EFL Learners Fatemeh Behjat fb_304@yahoo.com Islamic Azad University, Abadeh Branch, Iran Fatemeh
105 By Fatemeh Behjat & Firooz Sadighi The Acquisition of English Grammatical Morphemes: A Case of Iranian EFL Learners Fatemeh Behjat fb_304@yahoo.com Islamic Azad University, Abadeh Branch, Iran Fatemeh
The presence of interpretable but ungrammatical sentences corresponds to mismatches between interpretive and productive parsing.
 Lecture 4: OT Syntax Sources: Kager 1999, Section 8; Legendre et al. 1998; Grimshaw 1997; Barbosa et al. 1998, Introduction; Bresnan 1998; Fanselow et al. 1999; Gibson & Broihier 1998. OT is not a theory
Lecture 4: OT Syntax Sources: Kager 1999, Section 8; Legendre et al. 1998; Grimshaw 1997; Barbosa et al. 1998, Introduction; Bresnan 1998; Fanselow et al. 1999; Gibson & Broihier 1998. OT is not a theory
Grammars & Parsing, Part 1:
 Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
ENGBG1 ENGBL1 Campus Linguistics. Meeting 2. Chapter 7 (Morphology) and chapter 9 (Syntax) Pia Sundqvist
 and chapter 9 (Syntax) Pia Sundqvist") Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
Basic Syntax. Doug Arnold We review some basic grammatical ideas and terminology, and look at some common constructions in English.
 Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
Inleiding Taalkunde. Docent: Paola Monachesi. Blok 4, 2001/ Syntax 2. 2 Phrases and constituent structure 2. 3 A minigrammar of Italian 3
 Inleiding Taalkunde Docent: Paola Monachesi Blok 4, 2001/2002 Contents 1 Syntax 2 2 Phrases and constituent structure 2 3 A minigrammar of Italian 3 4 Trees 3 5 Developing an Italian lexicon 4 6 S(emantic)-selection
Inleiding Taalkunde Docent: Paola Monachesi Blok 4, 2001/2002 Contents 1 Syntax 2 2 Phrases and constituent structure 2 3 A minigrammar of Italian 3 4 Trees 3 5 Developing an Italian lexicon 4 6 S(emantic)-selection
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Project in the framework of the AIM-WEST project Annotation of MWEs for translation
 Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Syntactic surprisal affects spoken word duration in conversational contexts
 Syntactic surprisal affects spoken word duration in conversational contexts Vera Demberg, Asad B. Sayeed, Philip J. Gorinski, and Nikolaos Engonopoulos M2CI Cluster of Excellence and Department of Computational
Syntactic surprisal affects spoken word duration in conversational contexts Vera Demberg, Asad B. Sayeed, Philip J. Gorinski, and Nikolaos Engonopoulos M2CI Cluster of Excellence and Department of Computational
Derivational and Inflectional Morphemes in Pak-Pak Language
 Derivational and Inflectional Morphemes in Pak-Pak Language Agustina Situmorang and Tima Mariany Arifin ABSTRACT The objectives of this study are to find out the derivational and inflectional morphemes
Derivational and Inflectional Morphemes in Pak-Pak Language Agustina Situmorang and Tima Mariany Arifin ABSTRACT The objectives of this study are to find out the derivational and inflectional morphemes
Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]
![Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]](/thumbs/71/65954495.jpg "Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]") Towards a MWE-driven A* parsing with LTAGs [WG2,WG3] Jakub Waszczuk, Agata Savary To cite this version: Jakub Waszczuk, Agata Savary. Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]. PARSEME 6th general
Towards a MWE-driven A* parsing with LTAGs [WG2,WG3] Jakub Waszczuk, Agata Savary To cite this version: Jakub Waszczuk, Agata Savary. Towards a MWE-driven A* parsing with LTAGs [WG2,WG3]. PARSEME 6th general
Turkish Vocabulary Developer I / Vokabeltrainer I (Turkish Edition) By Katja Zehrfeld;Ali Akpinar
 By Katja Zehrfeld;Ali Akpinar") Turkish Vocabulary Developer I / Vokabeltrainer I (Turkish Edition) By Katja Zehrfeld;Ali Akpinar If you are looking for the ebook by Katja Zehrfeld;Ali Akpinar Turkish Vocabulary Developer I / Vokabeltrainer
Turkish Vocabulary Developer I / Vokabeltrainer I (Turkish Edition) By Katja Zehrfeld;Ali Akpinar If you are looking for the ebook by Katja Zehrfeld;Ali Akpinar Turkish Vocabulary Developer I / Vokabeltrainer
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Approaches to control phenomena handout Obligatory control and morphological case: Icelandic and Basque
 Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
1/20 idea. We ll spend an extra hour on 1/21. based on assigned readings. so you ll be ready to discuss them in class
 If we cancel class 1/20 idea We ll spend an extra hour on 1/21 I ll give you a brief writing problem for 1/21 based on assigned readings Jot down your thoughts based on your reading so you ll be ready
If we cancel class 1/20 idea We ll spend an extra hour on 1/21 I ll give you a brief writing problem for 1/21 based on assigned readings Jot down your thoughts based on your reading so you ll be ready
AN EXPERIMENTAL APPROACH TO NEW AND OLD INFORMATION IN TURKISH LOCATIVES AND EXISTENTIALS
 AN EXPERIMENTAL APPROACH TO NEW AND OLD INFORMATION IN TURKISH LOCATIVES AND EXISTENTIALS Engin ARIK 1, Pınar ÖZTOP 2, and Esen BÜYÜKSÖKMEN 1 Doguş University, 2 Plymouth University enginarik@enginarik.com
AN EXPERIMENTAL APPROACH TO NEW AND OLD INFORMATION IN TURKISH LOCATIVES AND EXISTENTIALS Engin ARIK 1, Pınar ÖZTOP 2, and Esen BÜYÜKSÖKMEN 1 Doguş University, 2 Plymouth University enginarik@enginarik.com
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
From Empire to Twenty-First Century Britain: Economic and Political Development of Great Britain in the 19th and 20th Centuries 5HD391
 Provisional list of courses for Exchange students Fall semester 2017: University of Economics, Prague Courses stated below are offered by particular departments and faculties at the University of Economics,
Provisional list of courses for Exchange students Fall semester 2017: University of Economics, Prague Courses stated below are offered by particular departments and faculties at the University of Economics,
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
The ParisNLP entry at the ConLL UD Shared Task 2017: A Tale of a #ParsingTragedy
 The ParisNLP entry at the ConLL UD Shared Task 2017: A Tale of a #ParsingTragedy Éric Villemonte de La Clergerie, Benoît Sagot, Djamé Seddah To cite this version: Éric Villemonte de La Clergerie, Benoît
The ParisNLP entry at the ConLL UD Shared Task 2017: A Tale of a #ParsingTragedy Éric Villemonte de La Clergerie, Benoît Sagot, Djamé Seddah To cite this version: Éric Villemonte de La Clergerie, Benoît
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
The Ups and Downs of Preposition Error Detection in ESL Writing
 The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
The Ups and Downs of Preposition Error Detection in ESL Writing Joel R. Tetreault Educational Testing Service 660 Rosedale Road Princeton, NJ, USA JTetreault@ets.org Martin Chodorow Hunter College of CUNY
Experiments with a Higher-Order Projective Dependency Parser
 Experiments with a Higher-Order Projective Dependency Parser Xavier Carreras Massachusetts Institute of Technology (MIT) Computer Science and Artificial Intelligence Laboratory (CSAIL) 32 Vassar St., Cambridge,
Experiments with a Higher-Order Projective Dependency Parser Xavier Carreras Massachusetts Institute of Technology (MIT) Computer Science and Artificial Intelligence Laboratory (CSAIL) 32 Vassar St., Cambridge,
Berlitz Swedish-English Dictionary (Berlitz Bilingual Dictionaries) By Berlitz Guides
 By Berlitz Guides") Berlitz Swedish-English Dictionary (Berlitz Bilingual Dictionaries) By Berlitz Guides If searching for a ebook by Berlitz Guides Berlitz Swedish-English Dictionary (Berlitz Bilingual Dictionaries) in pdf
Berlitz Swedish-English Dictionary (Berlitz Bilingual Dictionaries) By Berlitz Guides If searching for a ebook by Berlitz Guides Berlitz Swedish-English Dictionary (Berlitz Bilingual Dictionaries) in pdf
Language Independent Passage Retrieval for Question Answering
 Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2
 Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Assessing System Agreement and Instance Difficulty in the Lexical Sample Tasks of SENSEVAL-2 Ted Pedersen Department of Computer Science University of Minnesota Duluth, MN, 55812 USA tpederse@d.umn.edu
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) Feb 2015
 Feb 2015") Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Author: Justyna Kowalczys Stowarzyszenie Angielski w Medycynie (PL) www.angielskiwmedycynie.org.pl Feb 2015 Developing speaking abilities is a prerequisite for HELP in order to promote effective communication
Specifying a shallow grammatical for parsing purposes
 Specifying a shallow grammatical for parsing purposes representation Atro Voutilainen and Timo J~irvinen Research Unit for Multilingual Language Technology P.O. Box 4 FIN-0004 University of Helsinki Finland
Specifying a shallow grammatical for parsing purposes representation Atro Voutilainen and Timo J~irvinen Research Unit for Multilingual Language Technology P.O. Box 4 FIN-0004 University of Helsinki Finland
Review in ICAME Journal, Volume 38, 2014, DOI: /icame
 Review in ICAME Journal, Volume 38, 2014, DOI: 10.2478/icame-2014-0012 Gaëtanelle Gilquin and Sylvie De Cock (eds.). Errors and disfluencies in spoken corpora. Amsterdam: John Benjamins. 2013. 172 pp.
Review in ICAME Journal, Volume 38, 2014, DOI: 10.2478/icame-2014-0012 Gaëtanelle Gilquin and Sylvie De Cock (eds.). Errors and disfluencies in spoken corpora. Amsterdam: John Benjamins. 2013. 172 pp.
A Framework for Customizable Generation of Hypertext Presentations
 A Framework for Customizable Generation of Hypertext Presentations Benoit Lavoie and Owen Rambow CoGenTex, Inc. 840 Hanshaw Road, Ithaca, NY 14850, USA benoit, owen~cogentex, com Abstract In this paper,
A Framework for Customizable Generation of Hypertext Presentations Benoit Lavoie and Owen Rambow CoGenTex, Inc. 840 Hanshaw Road, Ithaca, NY 14850, USA benoit, owen~cogentex, com Abstract In this paper,
Derivational: Inflectional: In a fit of rage the soldiers attacked them both that week, but lost the fight.
 Final Exam (120 points) Click on the yellow balloons below to see the answers I. Short Answer (32pts) 1. (6) The sentence The kinder teachers made sure that the students comprehended the testable material
Final Exam (120 points) Click on the yellow balloons below to see the answers I. Short Answer (32pts) 1. (6) The sentence The kinder teachers made sure that the students comprehended the testable material
STT 231 Test 1. Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point.
 STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Intra-talker Variation: Audience Design Factors Affecting Lexical Selections
 Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Tyler Perrachione LING 451-0 Proseminar in Sound Structure Prof. A. Bradlow 17 March 2006 Intra-talker Variation: Audience Design Factors Affecting Lexical Selections Abstract Although the acoustic and
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Linguistics. Undergraduate. Departmental Honors. Graduate. Faculty. Linguistics 1
 Linguistics 1 Linguistics Matthew Gordon, Chair Interdepartmental Program in the College of Arts and Science 223 Tate Hall (573) 882-6421 gordonmj@missouri.edu Kibby Smith, Advisor Office of Multidisciplinary
Linguistics 1 Linguistics Matthew Gordon, Chair Interdepartmental Program in the College of Arts and Science 223 Tate Hall (573) 882-6421 gordonmj@missouri.edu Kibby Smith, Advisor Office of Multidisciplinary
THE VERB ARGUMENT BROWSER
 THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing. Grzegorz Chrupa la
 Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing Grzegorz Chrupa la A dissertation submitted in fulfilment of the requirements for the award of Doctor of Philosophy (Ph.D.)
Towards a Machine-Learning Architecture for Lexical Functional Grammar Parsing Grzegorz Chrupa la A dissertation submitted in fulfilment of the requirements for the award of Doctor of Philosophy (Ph.D.)
The Effect of Multiple Grammatical Errors on Processing Non-Native Writing
 The Effect of Multiple Grammatical Errors on Processing Non-Native Writing Courtney Napoles Johns Hopkins University courtneyn@jhu.edu Aoife Cahill Nitin Madnani Educational Testing Service {acahill,nmadnani}@ets.org
The Effect of Multiple Grammatical Errors on Processing Non-Native Writing Courtney Napoles Johns Hopkins University courtneyn@jhu.edu Aoife Cahill Nitin Madnani Educational Testing Service {acahill,nmadnani}@ets.org
Some Principles of Automated Natural Language Information Extraction
 Some Principles of Automated Natural Language Information Extraction Gregers Koch Department of Computer Science, Copenhagen University DIKU, Universitetsparken 1, DK-2100 Copenhagen, Denmark Abstract
Some Principles of Automated Natural Language Information Extraction Gregers Koch Department of Computer Science, Copenhagen University DIKU, Universitetsparken 1, DK-2100 Copenhagen, Denmark Abstract
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Grammar Extraction from Treebanks for Hindi and Telugu
 Grammar Extraction from Treebanks for Hindi and Telugu Prasanth Kolachina, Sudheer Kolachina, Anil Kumar Singh, Samar Husain, Viswanatha Naidu,Rajeev Sangal and Akshar Bharati Language Technologies Research
Grammar Extraction from Treebanks for Hindi and Telugu Prasanth Kolachina, Sudheer Kolachina, Anil Kumar Singh, Samar Husain, Viswanatha Naidu,Rajeev Sangal and Akshar Bharati Language Technologies Research
The development of a new learner s dictionary for Modern Standard Arabic: the linguistic corpus approach
 BILINGUAL LEARNERS DICTIONARIES The development of a new learner s dictionary for Modern Standard Arabic: the linguistic corpus approach Mark VAN MOL, Leuven, Belgium Abstract This paper reports on the
BILINGUAL LEARNERS DICTIONARIES The development of a new learner s dictionary for Modern Standard Arabic: the linguistic corpus approach Mark VAN MOL, Leuven, Belgium Abstract This paper reports on the
BULATS A2 WORDLIST 2
 BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
EAGLE: an Error-Annotated Corpus of Beginning Learner German
 EAGLE: an Error-Annotated Corpus of Beginning Learner German Adriane Boyd Department of Linguistics The Ohio State University adriane@ling.osu.edu Abstract This paper describes the Error-Annotated German
EAGLE: an Error-Annotated Corpus of Beginning Learner German Adriane Boyd Department of Linguistics The Ohio State University adriane@ling.osu.edu Abstract This paper describes the Error-Annotated German
Introduction to HPSG. Introduction. Historical Overview. The HPSG architecture. Signature. Linguistic Objects. Descriptions.
 to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
Developing Grammar in Context
 Developing Grammar in Context intermediate with answers Mark Nettle and Diana Hopkins PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United
Developing Grammar in Context intermediate with answers Mark Nettle and Diana Hopkins PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United
A Computational Evaluation of Case-Assignment Algorithms
 A Computational Evaluation of Case-Assignment Algorithms Miles Calabresi Advisors: Bob Frank and Jim Wood Submitted to the faculty of the Department of Linguistics in partial fulfillment of the requirements
A Computational Evaluation of Case-Assignment Algorithms Miles Calabresi Advisors: Bob Frank and Jim Wood Submitted to the faculty of the Department of Linguistics in partial fulfillment of the requirements
Ch VI- SENTENCE PATTERNS.
 Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,