ENLP Lecture 21b Word & Document Representations; Distributional Similarity
|
|
|
- Grant Golden
- 6 years ago
- Views:
Transcription
1 ENLP Lecture 21b Word & Document Representations; Distributional Similarity Nathan Schneider (some slides by Marine Carpuat, Sharon Goldwater, Dan Jurafsky) 28 November
2 Topics Similarity Thesauri & their limitations Distributional hypothesis Clustering (Brown clusters, LDA) Vector representations (count-based, dimensionality reduction, embeddings) 2
3 Word & Document Similarity 3
4 Question Answering Q: What is a good way to remove wine stains? A1: Salt is a great way to eliminate wine stains A2: How to get rid of wine stains A3: How to get red wine out of clothes A4: Oxalic acid is infallible in removing iron-rust and ink stains. 4




5 Document Similarity Given a movie script, recommend similar movies. 5
6 Word Similarity 6
7 Intuition of Semantic Similarity Semantically close bank money apple fruit tree forest bank river pen paper run walk mistake error car wheel Semantically distant doctor beer painting January money river apple penguin nurse fruit pen river clown tramway car algebra 7
8 Why are 2 words similar? Meaning The two concepts are close in terms of their meaning World knowledge The two concepts have similar properties, often occur together, or occur in similar contexts Psychology We often think of the two concepts together 8
 interchangeable Semantic")

9 Two Types of Relations Synonymy: two words are (roughly) interchangeable Semantic similarity (distance): somehow related Sometimes, explicit lexical semantic relationship, often, not 9
10 Validity of Semantic Similarity Is semantic distance a valid linguistic phenomenon? Experiment (Rubenstein and Goodenough, 1965) Compiled a list of word pairs Subjects asked to judge semantic distance (from 0 to 4) for each of the word pairs Results: Rank correlation between subjects is ~0.9 People are consistent! 10
11 Why do this? Task: automatically compute semantic similarity between words Can be useful for many applications: Detecting paraphrases (i.e., automatic essay grading, plagiarism detection) Information retrieval Machine translation Why? Because similarity gives us a way to generalize beyond word identities 11
12 Evaluation: Correlation with Humans Ask automatic method to rank word pairs in order of semantic distance Compare this ranking with human-created ranking Measure correlation 12
13 Evaluation: Word-Choice Problems Identify that alternative which is closest in meaning to the target: accidental wheedle ferment inadvertent abominate imprison incarcerate writhe meander inhibit 13
14 Evaluation: Malapropisms Jack withdrew money from the ATM next to the band. band is unrelated to all of the other words in its context 14
15 Word Similarity: Two Approaches Thesaurus-based We ve invested in all these resources let s exploit them! Distributional Count words in context 15
16 Thesaurus-based Similarity Use the structure of a resource like WordNet Examine the relationship between the two concepts, use a metric that converts the relationship into a real number E.g., path length: sim(c 1, c 2 ) = log path(c 1, c 2 ) How would you deal with ambiguous words? 16
17 Thesaurus Methods: Limitations Measure is only as good as the resource Limited in scope Assumes IS-A relations Works mostly for nouns Role of context not accounted for Not easily domain-adaptable Resources not available in many languages 17
18 Distributional Similarity Differences of meaning correlates with differences of distribution (Harris, 1970) Idea: similar linguistic objects have similar contents (for documents, sentences) or contexts (for words) 18
19 Two Kinds of Distributional Contexts 1. Documents as bags-of-words Similar documents contain similar words; similar words appear in similar documents 2. Words in terms of neighboring words You shall know a word by the company it keeps! (Firth, 1957) Similar words occur near similar sets of other words (e.g., in a 5-word window) 19
20 20
21 Word Vectors A word type can be represented as a vector of features indicating the contexts in which it occurs in a corpus w (f, f, f,... f N ) 21


22 Context Features Word co-occurrence within a window: Grammatical relations: 22
23 Context Features Feature values Boolean Raw counts Some other weighting scheme (e.g., idf, tf.idf) Association values (next slide) 23
24 Association Metric Commonly-used metric: Pointwise Mutual Information association PMI ( w, f ) log 2 P( w, f P( w) P( ) f ) Can be used as a feature value or by itself 24
25 Computing Similarity Semantic similarity boils down to computing some measure on context vectors Cosine distance: borrowed from 25
26 Words in a Vector Space In 2 dimensions: v = (v1, v2) v = cat w = computer w = (w1, w2) 26
27 Euclidean Distance Σi (vi wi)² Can be oversensitive to extreme values 27
28 Cosine Similarity 28 Cosine distance: borrowed from information retrieval N i i N i i N i i i w v w v w v w v w v cosine ), ( sim
29 Distributional Approaches: Discussion No thesauri needed: data driven Can be applied to any pair of words Can be adapted to different domains 29
30 Distributional Profiles: Example 30

31 Distributional Profiles: Example 31
32 Problem? 32

33 Distributional Profiles of Concepts 33

34 Semantic Similarity: Celebrity Semantically distant 34

35 Semantic Similarity: Celestial body Semantically close! 35
36 Word Clusters E.g., Brown clustering algorithm produces hierarchical clusters based on word context vectors Words in similar parts of hierarchy occur in similar contexts Chairman,is,0010,, months,=,01,,and,verbs,=, CEO November October chairman president Brown clusters created from Twitter data: run sprint walk
37 Document-Word Models Features in the word vector can be word context counts or PMI scores Also, features can be the documents in which this word occurs Document occurrence features useful for topical/ thematic similarity 37
38 Topic Models Latent Dirichlet Allocation (LDA) and variants are known as topic models Learned on a large document collection (unsupervised) Latent probabilistic clustering of words that tend to occur in the same document. Each topic cluster is a distribution over words. Generative model: Each document is a sparse mixture of topics. Each word in the document is chosen by sampling a topic from the document-specific topic distribution, then sampling a word from that topic. Learn with EM or other techniques (e.g., Gibbs sampling) 38
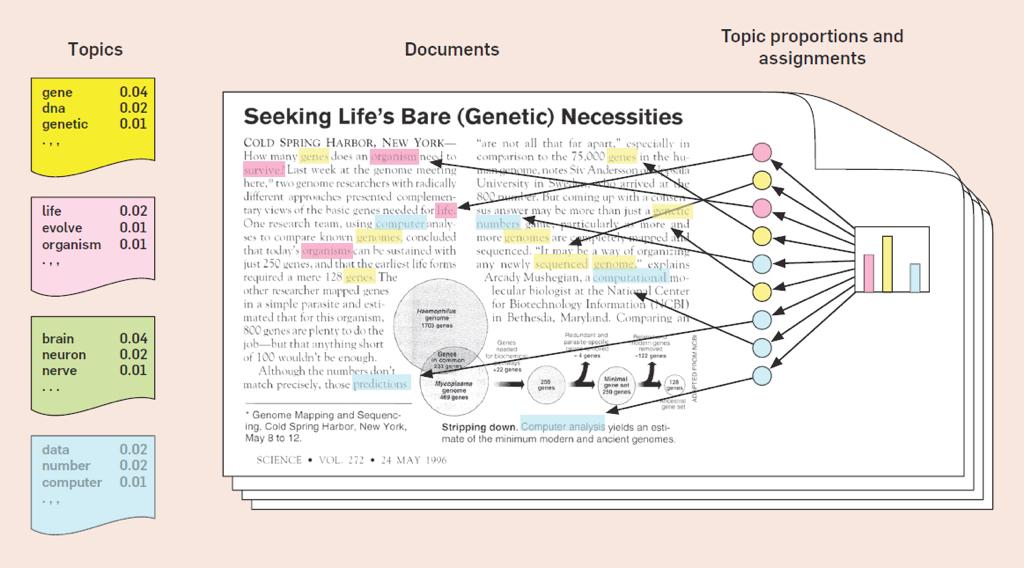
39 Topic Models 39
40 More on topic models Mark Dredze (JHU) Topic Models for Identifying Public Health Trends Tomorrow, 11:00 in STM
41 DIMENSIONALITY REDUCTION 41 Slides based on presentation by Christopher Potts
42 Why dimensionality reduction? So far, we ve defined word representations as rows in F, a m x n matrix m = vocab size n = number of context dimensions / features Problems: n is very large, F is very sparse Solution: find a low rank approximation of F Matrix of size m x d where d << n 42
43 Methods Latent Semantic Analysis Also: Principal component analysis Probabilistic LSA Latent Dirichlet Allocation Word2vec 43
44 Latent Semantic Analysis Based on Singular Value Decomposition 44
45 LSA illustrated: SVD + select top k dimensions 45
46 Word embeddings based on neural language models So far: Distributional vector representations constructed based on counts (+ dimensionality reduction) Recent finding: Neural networks trained to predict neighboring words (i.e., language models) learn useful low-dimensional word vectors Dimensionality reduction is built into the NN learning objective Once the neural LM is trained on massive data, the word embeddings can be reused for other tasks 46
47 Word vectors as a byproduct of language modeling A neural probabilistic Language Model. Bengio et al. JMLR
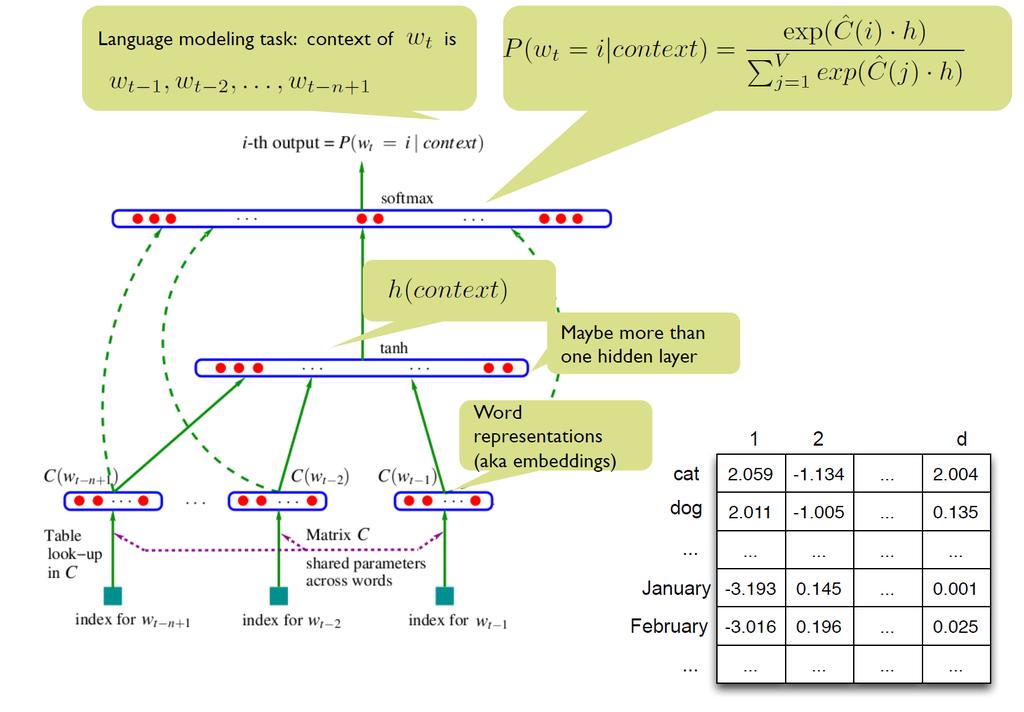
48 48
49 Using neural word representations in NLP word representations from neural LMs aka distributed word representations aka word embeddings How would you use these word vectors? Turian et al. [2010] word representations as features consistently improve performance of Named-Entity Recognition Text chunking tasks 49
50 Word2vec [Mikolov et al. 2013] introduces simpler models 50
51 Word2vec claims Useful representations for NLP applications Can discover relations between words using vector arithmetic king male + female = queen Paper+tool received lots of attention even outside the NLP research community try it out at word2vec playground : 51
52 Summary Given a large corpus, the meanings of words can be approximated in terms of words occurring nearby: distributional context. Each word represented as a vector of integer or real values. Different ways to choose context, e.g. context windows Different ways to count cooccurrence, e.g. (positive) PMI Vectors can be sparse (1 dimension for every context) or dense (reduced dimensionality, e.g. with Brown clustering or LSA) This facilities measuring similarity between words useful for many NLP tasks! Different similarity measures, e.g. cosine (= normalized dot product) Evaluations: human relatedness judgments; extrinsic tasks 52
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Matching Similarity for Keyword-Based Clustering
 Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Word Sense Disambiguation
 Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Differential Evolutionary Algorithm Based on Multiple Vector Metrics for Semantic Similarity Assessment in Continuous Vector Space
 Differential Evolutionary Algorithm Based on Multiple Vector Metrics for Semantic Similarity Assessment in Continuous Vector Space Yuanyuan Cai, Wei Lu, Xiaoping Che, Kailun Shi School of Software Engineering
Differential Evolutionary Algorithm Based on Multiple Vector Metrics for Semantic Similarity Assessment in Continuous Vector Space Yuanyuan Cai, Wei Lu, Xiaoping Che, Kailun Shi School of Software Engineering
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Vocabulary Usage and Intelligibility in Learner Language
 Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Controlled vocabulary
 Indexing languages 6.2.2. Controlled vocabulary Overview Anyone who has struggled to find the exact search term to retrieve information about a certain subject can benefit from controlled vocabulary. Controlled
Indexing languages 6.2.2. Controlled vocabulary Overview Anyone who has struggled to find the exact search term to retrieve information about a certain subject can benefit from controlled vocabulary. Controlled
Performance Analysis of Optimized Content Extraction for Cyrillic Mongolian Learning Text Materials in the Database
 Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Short Text Understanding Through Lexical-Semantic Analysis
 Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Compositional Semantics
 Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting
 LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
LIM-LIG at SemEval-2017 Task1: Enhancing the Semantic Similarity for Arabic Sentences with Vectors Weighting El Moatez Billah Nagoudi Laboratoire d Informatique et de Mathématiques LIM Université Amar
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Latent Semantic Analysis
 Latent Semantic Analysis Adapted from: www.ics.uci.edu/~lopes/teaching/inf141w10/.../lsa_intro_ai_seminar.ppt (from Melanie Martin) and http://videolectures.net/slsfs05_hofmann_lsvm/ (from Thomas Hoffman)
Latent Semantic Analysis Adapted from: www.ics.uci.edu/~lopes/teaching/inf141w10/.../lsa_intro_ai_seminar.ppt (from Melanie Martin) and http://videolectures.net/slsfs05_hofmann_lsvm/ (from Thomas Hoffman)
arxiv: v1 [cs.cl] 20 Jul 2015
![arxiv: v1 [cs.cl] 20 Jul 2015](/thumbs/71/66201242.jpg "arxiv: v1 [cs.cl] 20 Jul 2015") How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
How to Generate a Good Word Embedding? Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao National Laboratory of Pattern Recognition (NLPR) Institute of Automation, Chinese Academy of Sciences, China {swlai, kliu,
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF GRAPH DATA
 International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
Text-mining the Estonian National Electronic Health Record
 Text-mining the Estonian National Electronic Health Record Raul Sirel rsirel@ut.ee 13.11.2015 Outline Electronic Health Records & Text Mining De-identifying the Texts Resolving the Abbreviations Terminology
Text-mining the Estonian National Electronic Health Record Raul Sirel rsirel@ut.ee 13.11.2015 Outline Electronic Health Records & Text Mining De-identifying the Texts Resolving the Abbreviations Terminology
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
A Semantic Similarity Measure Based on Lexico-Syntactic Patterns
 A Semantic Similarity Measure Based on Lexico-Syntactic Patterns Alexander Panchenko, Olga Morozova and Hubert Naets Center for Natural Language Processing (CENTAL) Université catholique de Louvain Belgium
A Semantic Similarity Measure Based on Lexico-Syntactic Patterns Alexander Panchenko, Olga Morozova and Hubert Naets Center for Natural Language Processing (CENTAL) Université catholique de Louvain Belgium
Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features
 collocations by integrating features") Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features Sriram Venkatapathy Language Technologies Research Centre, International Institute of Information Technology
Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features Sriram Venkatapathy Language Technologies Research Centre, International Institute of Information Technology
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Lexical Similarity based on Quantity of Information Exchanged - Synonym Extraction
 Intl. Conf. RIVF 04 February 2-5, Hanoi, Vietnam Lexical Similarity based on Quantity of Information Exchanged - Synonym Extraction Ngoc-Diep Ho, Fairon Cédrick Abstract There are a lot of approaches for
Intl. Conf. RIVF 04 February 2-5, Hanoi, Vietnam Lexical Similarity based on Quantity of Information Exchanged - Synonym Extraction Ngoc-Diep Ho, Fairon Cédrick Abstract There are a lot of approaches for
Unsupervised Learning of Narrative Schemas and their Participants
 Unsupervised Learning of Narrative Schemas and their Participants Nathanael Chambers and Dan Jurafsky Stanford University, Stanford, CA 94305 {natec,jurafsky}@stanford.edu Abstract We describe an unsupervised
Unsupervised Learning of Narrative Schemas and their Participants Nathanael Chambers and Dan Jurafsky Stanford University, Stanford, CA 94305 {natec,jurafsky}@stanford.edu Abstract We describe an unsupervised
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Concepts and Properties in Word Spaces
 Concepts and Properties in Word Spaces Marco Baroni 1 and Alessandro Lenci 2 1 University of Trento, CIMeC 2 University of Pisa, Department of Linguistics Abstract Properties play a central role in most
Concepts and Properties in Word Spaces Marco Baroni 1 and Alessandro Lenci 2 1 University of Trento, CIMeC 2 University of Pisa, Department of Linguistics Abstract Properties play a central role in most
Which verb classes and why? Research questions: Semantic Basis Hypothesis (SBH) What verb classes? Why the truth of the SBH matters
 What verb classes? Why the truth of the SBH matters") Which verb classes and why? ean-pierre Koenig, Gail Mauner, Anthony Davis, and reton ienvenue University at uffalo and Streamsage, Inc. Research questions: Participant roles play a role in the syntactic
Which verb classes and why? ean-pierre Koenig, Gail Mauner, Anthony Davis, and reton ienvenue University at uffalo and Streamsage, Inc. Research questions: Participant roles play a role in the syntactic
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
A Domain Ontology Development Environment Using a MRD and Text Corpus
 A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Longest Common Subsequence: A Method for Automatic Evaluation of Handwritten Essays
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 6, Ver. IV (Nov Dec. 2015), PP 01-07 www.iosrjournals.org Longest Common Subsequence: A Method for
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 6, Ver. IV (Nov Dec. 2015), PP 01-07 www.iosrjournals.org Longest Common Subsequence: A Method for
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
 A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
Assessing Entailer with a Corpus of Natural Language From an Intelligent Tutoring System
 Assessing Entailer with a Corpus of Natural Language From an Intelligent Tutoring System Philip M. McCarthy, Vasile Rus, Scott A. Crossley, Sarah C. Bigham, Arthur C. Graesser, & Danielle S. McNamara Institute
Assessing Entailer with a Corpus of Natural Language From an Intelligent Tutoring System Philip M. McCarthy, Vasile Rus, Scott A. Crossley, Sarah C. Bigham, Arthur C. Graesser, & Danielle S. McNamara Institute
UMass at TDT Similarity functions 1. BASIC SYSTEM Detection algorithms. set globally and apply to all clusters.
 UMass at TDT James Allan, Victor Lavrenko, David Frey, and Vikas Khandelwal Center for Intelligent Information Retrieval Department of Computer Science University of Massachusetts Amherst, MA 3 We spent
UMass at TDT James Allan, Victor Lavrenko, David Frey, and Vikas Khandelwal Center for Intelligent Information Retrieval Department of Computer Science University of Massachusetts Amherst, MA 3 We spent
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
What's My Value? Using "Manipulatives" and Writing to Explain Place Value. by Amanda Donovan, 2016 CTI Fellow David Cox Road Elementary School
 What's My Value? Using "Manipulatives" and Writing to Explain Place Value by Amanda Donovan, 2016 CTI Fellow David Cox Road Elementary School This curriculum unit is recommended for: Second and Third Grade
What's My Value? Using "Manipulatives" and Writing to Explain Place Value by Amanda Donovan, 2016 CTI Fellow David Cox Road Elementary School This curriculum unit is recommended for: Second and Third Grade
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models
 Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
APES Summer Work PURPOSE: THE ASSIGNMENT: DUE DATE: TEST:
 APES Summer Work PURPOSE: Like most science courses, APES involves math, data analysis, and graphing. Simple math concepts, like dealing with scientific notation, unit conversions, and percent increases,
APES Summer Work PURPOSE: Like most science courses, APES involves math, data analysis, and graphing. Simple math concepts, like dealing with scientific notation, unit conversions, and percent increases,
Abstractions and the Brain
 Abstractions and the Brain Brian D. Josephson Department of Physics, University of Cambridge Cavendish Lab. Madingley Road Cambridge, UK. CB3 OHE bdj10@cam.ac.uk http://www.tcm.phy.cam.ac.uk/~bdj10 ABSTRACT
Abstractions and the Brain Brian D. Josephson Department of Physics, University of Cambridge Cavendish Lab. Madingley Road Cambridge, UK. CB3 OHE bdj10@cam.ac.uk http://www.tcm.phy.cam.ac.uk/~bdj10 ABSTRACT
Literal or idiomatic? Identifying the reading of single occurrences of German multiword expressions using word embeddings
 Literal or idiomatic? Identifying the reading of single occurrences of German multiword expressions using word embeddings Rafael Ehren Dept. of Computational Linguistics Heinrich Heine University Düsseldorf,
Literal or idiomatic? Identifying the reading of single occurrences of German multiword expressions using word embeddings Rafael Ehren Dept. of Computational Linguistics Heinrich Heine University Düsseldorf,
Let's Learn English Lesson Plan
 Let's Learn English Lesson Plan Introduction: Let's Learn English lesson plans are based on the CALLA approach. See the end of each lesson for more information and resources on teaching with the CALLA
Let's Learn English Lesson Plan Introduction: Let's Learn English lesson plans are based on the CALLA approach. See the end of each lesson for more information and resources on teaching with the CALLA
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Mining Topic-level Opinion Influence in Microblog
 Mining Topic-level Opinion Influence in Microblog Daifeng Li Dept. of Computer Science and Technology Tsinghua University ldf3824@yahoo.com.cn Jie Tang Dept. of Computer Science and Technology Tsinghua
Mining Topic-level Opinion Influence in Microblog Daifeng Li Dept. of Computer Science and Technology Tsinghua University ldf3824@yahoo.com.cn Jie Tang Dept. of Computer Science and Technology Tsinghua
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Data-driven Type Checking in Open Domain Question Answering
 Data-driven Type Checking in Open Domain Question Answering Stefan Schlobach a,1 David Ahn b,2 Maarten de Rijke b,3 Valentin Jijkoun b,4 a AI Department, Division of Mathematics and Computer Science, Vrije
Data-driven Type Checking in Open Domain Question Answering Stefan Schlobach a,1 David Ahn b,2 Maarten de Rijke b,3 Valentin Jijkoun b,4 a AI Department, Division of Mathematics and Computer Science, Vrije
UC Santa Cruz Graduate Research Symposium 2016
 UC Santa Cruz Graduate Research Symposium 2016 Title When and Why is it Wrong to Copy from Others? Variability in Students' Evaluations of Plagiarism Permalink https://escholarship.org/uc/item/7fx40158
UC Santa Cruz Graduate Research Symposium 2016 Title When and Why is it Wrong to Copy from Others? Variability in Students' Evaluations of Plagiarism Permalink https://escholarship.org/uc/item/7fx40158
The University of Amsterdam s Concept Detection System at ImageCLEF 2011
 The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
Algebra 2- Semester 2 Review
 Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Experts Retrieval with Multiword-Enhanced Author Topic Model
 NAACL 10 Workshop on Semantic Search Experts Retrieval with Multiword-Enhanced Author Topic Model Nikhil Johri Dan Roth Yuancheng Tu Dept. of Computer Science Dept. of Linguistics University of Illinois
NAACL 10 Workshop on Semantic Search Experts Retrieval with Multiword-Enhanced Author Topic Model Nikhil Johri Dan Roth Yuancheng Tu Dept. of Computer Science Dept. of Linguistics University of Illinois
As a high-quality international conference in the field
 The New Automated IEEE INFOCOM Review Assignment System Baochun Li and Y. Thomas Hou Abstract In academic conferences, the structure of the review process has always been considered a critical aspect of
The New Automated IEEE INFOCOM Review Assignment System Baochun Li and Y. Thomas Hou Abstract In academic conferences, the structure of the review process has always been considered a critical aspect of
Copyright by Sung Ju Hwang 2013
 Copyright by Sung Ju Hwang 2013 The Dissertation Committee for Sung Ju Hwang certifies that this is the approved version of the following dissertation: Discriminative Object Categorization with External
Copyright by Sung Ju Hwang 2013 The Dissertation Committee for Sung Ju Hwang certifies that this is the approved version of the following dissertation: Discriminative Object Categorization with External
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Summarizing Answers in Non-Factoid Community Question-Answering
 Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Summarizing Answers in Non-Factoid Community Question-Answering Hongya Song Zhaochun Ren Shangsong Liang hongya.song.sdu@gmail.com zhaochun.ren@ucl.ac.uk shangsong.liang@ucl.ac.uk Piji Li Jun Ma Maarten
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance
 A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance a Assistant Professor a epartment of Computer Science Memoona Khanum a Tahira Mahboob b b Assistant Professor
A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance a Assistant Professor a epartment of Computer Science Memoona Khanum a Tahira Mahboob b b Assistant Professor
Syntactic and Semantic Factors in Processing Difficulty: An Integrated Measure
 Syntactic and Semantic Factors in Processing Difficulty: An Integrated Measure Jeff Mitchell, Mirella Lapata, Vera Demberg and Frank Keller University of Edinburgh Edinburgh, United Kingdom jeff.mitchell@ed.ac.uk,
Syntactic and Semantic Factors in Processing Difficulty: An Integrated Measure Jeff Mitchell, Mirella Lapata, Vera Demberg and Frank Keller University of Edinburgh Edinburgh, United Kingdom jeff.mitchell@ed.ac.uk,
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
A Re-examination of Lexical Association Measures
 A Re-examination of Lexical Association Measures Hung Huu Hoang Dept. of Computer Science National University of Singapore hoanghuu@comp.nus.edu.sg Su Nam Kim Dept. of Computer Science and Software Engineering
A Re-examination of Lexical Association Measures Hung Huu Hoang Dept. of Computer Science National University of Singapore hoanghuu@comp.nus.edu.sg Su Nam Kim Dept. of Computer Science and Software Engineering
MASTER OF SCIENCE (M.S.) MAJOR IN COMPUTER SCIENCE
 MAJOR IN COMPUTER SCIENCE") Master of Science (M.S.) Major in Computer Science 1 MASTER OF SCIENCE (M.S.) MAJOR IN COMPUTER SCIENCE Major Program The programs in computer science are designed to prepare students for doctoral research,
Master of Science (M.S.) Major in Computer Science 1 MASTER OF SCIENCE (M.S.) MAJOR IN COMPUTER SCIENCE Major Program The programs in computer science are designed to prepare students for doctoral research,
Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter
 ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
The Role of String Similarity Metrics in Ontology Alignment
 The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
ME 4495 Computational Heat Transfer and Fluid Flow M,W 4:00 5:15 (Eng 177)
") ME 4495 Computational Heat Transfer and Fluid Flow M,W 4:00 5:15 (Eng 177) Professor: Daniel N. Pope, Ph.D. E-mail: dpope@d.umn.edu Office: VKH 113 Phone: 726-6685 Office Hours:, Tues,, Fri 2:00-3:00 (or
ME 4495 Computational Heat Transfer and Fluid Flow M,W 4:00 5:15 (Eng 177) Professor: Daniel N. Pope, Ph.D. E-mail: dpope@d.umn.edu Office: VKH 113 Phone: 726-6685 Office Hours:, Tues,, Fri 2:00-3:00 (or
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer