Guido Boella Dipartimento di Informatica Università di Torino FP7-ICT-2013-SME-DCA
|
|
|
- Norman Harper
- 6 years ago
- Views:
Transcription


1 EuroVoc classifier Guido Boella Dipartimento di Informatica Università di Torino FP7-ICT-2013-SME-DCA
2 Overview Introduction Background Our approach Pre-processing of the texts Evaluation
3 Introduction Classification of legal text deals with large amount of documents it usually involves intensive manual work (slow and costly) Need of automatization
4 Eurovoc thesaurus Eurovoc, a multilingual, multidisciplinary thesaurus with about 7,000 categories (also called classes, labels, or descriptors from now on) covering the activities of the EU, the European Parliament in particular. It contains terms in several languages and it is managed by the Publications Office of the European Union, an interinstitutional office whose task is to publish the publications of the institutions of European Union. Eurovoc is an ontology-based information collector that groups and links concepts through different types of relationships. The top level of the scheme is defined by 21 general concepts. 4
5 Multi-label Text Classification Background (1) Each document can belong to more than one label / category Problems Most of the algorithms only support mono-labeled datasets Solutions Adaptation of existing algorithms to deal with multi-labels Transformation of multi-labeled datasets into monolabeled
6 Background on transformation algorithms Background (2) Removal of all the documents that have more than one label from the dataset Random selection of one of the multiple labels for each documents, discarding the rest Very naïve solutions! (with bad results)
7 Background on transformation algorithms Background (3) Each different set of labels is considered as a single label (power set) Example: if the labels of a document are A, B, and C, the system transforms the labels of the document in a single label ABC. Weakness: it may lead to datasets with a large number of classes and few examples per class. Learning one binary classifier for each label in the data Classification procedure: to classify a new document, it needs to pass over all the classifiers to determine its associated set of labels) Weakness: in case of thousands of categories (as in the data that we will use), this strategy becomes unsustainable.
8 Main idea Our approach (1) each n-labeled document becomes a collection of n minor documents (each one associated to only one label), and then use a state-of-the-art classification technique for mono-labeled datasets Problem how to segment the original document, that is how to choose the features to maintain for each of the new mono-label documents?

9 Our approach (2) Category A Category A Category B Category C Category B Category C state-of-the-art technique for monolabeled datasets
10 Our approach (3) Segmentation We compute the Pointwise Mutual Information (PMI) between categories and features (terms) P i,j is the probability of having a non-zero co-occurrence value for the i-th feature and the j-th category in the whole corpus P i and P j are the individual probabilities The utility of M is to capture the strength of the associations between features and categories.
11 Segmentation Our approach (4) for each original document vector d to be segmented, given the set of categories S d to which it belongs, the system creates n = S d new document vectors d k (each one associated to exactly one class) in the following way: where k S d (it represents the category associated to the new vector), and where sel(f i ) is a selection function that can assume the following values:
12 Our approach (5) Segmentation variant: selection parameter Q that is, selq(fi) is equal to fi if there exists a subset of Sd named S d of cardinality Q such that each one of its element has a PMI-value with feature fi greater than (or equal to) all the elements outside S d (but in Sd). This way, the system allows the use of feature fi for exactly Q segmented vectors.
13 Pre-processing of the texts
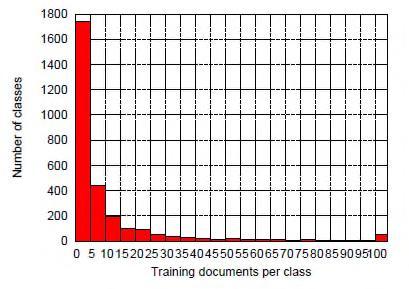
14 Measures Precision and Recall (and F-Measure). Data JRC-Acquis ( documents (5 languages version) Evaluation
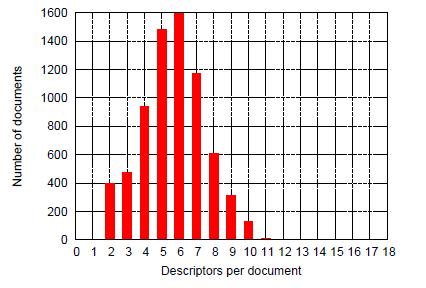
15
16 Evaluation
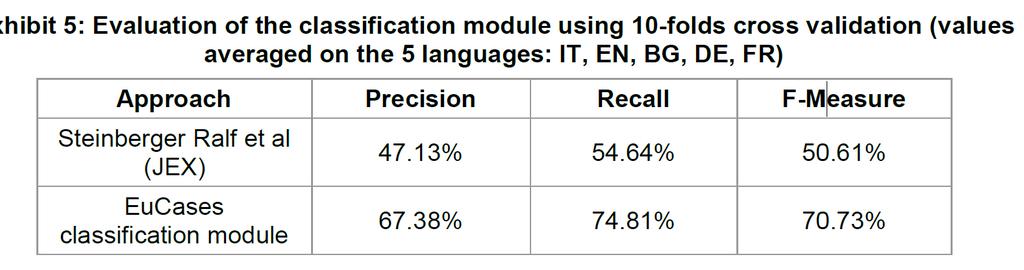
17 Evaluation
18
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Multilingual Document Clustering: an Heuristic Approach Based on Cognate Named Entities
 Multilingual Document Clustering: an Heuristic Approach Based on Cognate Named Entities Soto Montalvo GAVAB Group URJC Raquel Martínez NLP&IR Group UNED Arantza Casillas Dpt. EE UPV-EHU Víctor Fresno GAVAB
Multilingual Document Clustering: an Heuristic Approach Based on Cognate Named Entities Soto Montalvo GAVAB Group URJC Raquel Martínez NLP&IR Group UNED Arantza Casillas Dpt. EE UPV-EHU Víctor Fresno GAVAB
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Cross-Lingual Text Categorization
 Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
The University of Amsterdam s Concept Detection System at ImageCLEF 2011
 The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Using Hashtags to Capture Fine Emotion Categories from Tweets
 Submitted to the Special issue on Semantic Analysis in Social Media, Computational Intelligence. Guest editors: Atefeh Farzindar (farzindaratnlptechnologiesdotca), Diana Inkpen (dianaateecsdotuottawadotca)
Submitted to the Special issue on Semantic Analysis in Social Media, Computational Intelligence. Guest editors: Atefeh Farzindar (farzindaratnlptechnologiesdotca), Diana Inkpen (dianaateecsdotuottawadotca)
Conference Presentation
 Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
A Graph Based Authorship Identification Approach
 A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Using AMT & SNOMED CT-AU to support clinical research
 Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Multi-label classification via multi-target regression on data streams
 Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Automatic document classification of biological literature
 BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic
BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade
 Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade The third grade standards primarily address multiplication and division, which are covered in Math-U-See
Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade The third grade standards primarily address multiplication and division, which are covered in Math-U-See
Mining Student Evolution Using Associative Classification and Clustering
 Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Diverse Concept-Level Features for Multi-Object Classification
 Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Cooperative evolutive concept learning: an empirical study
 Cooperative evolutive concept learning: an empirical study Filippo Neri University of Piemonte Orientale Dipartimento di Scienze e Tecnologie Avanzate Piazza Ambrosoli 5, 15100 Alessandria AL, Italy Abstract
Cooperative evolutive concept learning: an empirical study Filippo Neri University of Piemonte Orientale Dipartimento di Scienze e Tecnologie Avanzate Piazza Ambrosoli 5, 15100 Alessandria AL, Italy Abstract
Analysis: Evaluation: Knowledge: Comprehension: Synthesis: Application:
 In 1956, Benjamin Bloom headed a group of educational psychologists who developed a classification of levels of intellectual behavior important in learning. Bloom found that over 95 % of the test questions
In 1956, Benjamin Bloom headed a group of educational psychologists who developed a classification of levels of intellectual behavior important in learning. Bloom found that over 95 % of the test questions
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Determining the Semantic Orientation of Terms through Gloss Classification
 Determining the Semantic Orientation of Terms through Gloss Classification Andrea Esuli Istituto di Scienza e Tecnologie dell Informazione Consiglio Nazionale delle Ricerche Via G Moruzzi, 1 56124 Pisa,
Determining the Semantic Orientation of Terms through Gloss Classification Andrea Esuli Istituto di Scienza e Tecnologie dell Informazione Consiglio Nazionale delle Ricerche Via G Moruzzi, 1 56124 Pisa,
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio
 SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
Marie Skłodowska-Curie Actions (MSCA)
") Education Marie Skłodowska-Curie Actions (MSCA) South Africa-European Union Space Dialogue Workshop on Scientific, Technical and Entrepreneurial Skills Development for the Space Sector 19 Nov. 2013 Pretoria
Education Marie Skłodowska-Curie Actions (MSCA) South Africa-European Union Space Dialogue Workshop on Scientific, Technical and Entrepreneurial Skills Development for the Space Sector 19 Nov. 2013 Pretoria
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Machine Translation on the Medical Domain: The Role of BLEU/NIST and METEOR in a Controlled Vocabulary Setting
 Machine Translation on the Medical Domain: The Role of BLEU/NIST and METEOR in a Controlled Vocabulary Setting Andre CASTILLA castilla@terra.com.br Alice BACIC Informatics Service, Instituto do Coracao
Machine Translation on the Medical Domain: The Role of BLEU/NIST and METEOR in a Controlled Vocabulary Setting Andre CASTILLA castilla@terra.com.br Alice BACIC Informatics Service, Instituto do Coracao
Matching Similarity for Keyword-Based Clustering
 Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
16.1 Lesson: Putting it into practice - isikhnas
 BAB 16 Module: Using QGIS in animal health The purpose of this module is to show how QGIS can be used to assist in animal health scenarios. In order to do this, you will have needed to study, and be familiar
BAB 16 Module: Using QGIS in animal health The purpose of this module is to show how QGIS can be used to assist in animal health scenarios. In order to do this, you will have needed to study, and be familiar
A Topic Maps-based ontology IR system versus Clustering-based IR System: A Comparative Study in Security Domain
 A Topic Maps-based ontology IR system versus Clustering-based IR System: A Comparative Study in Security Domain Myongho Yi 1 and Sam Gyun Oh 2* 1 School of Library and Information Studies, Texas Woman
A Topic Maps-based ontology IR system versus Clustering-based IR System: A Comparative Study in Security Domain Myongho Yi 1 and Sam Gyun Oh 2* 1 School of Library and Information Studies, Texas Woman
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Speech Translation for Triage of Emergency Phonecalls in Minority Languages
 Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Speech Translation for Triage of Emergency Phonecalls in Minority Languages Udhyakumar Nallasamy, Alan W Black, Tanja Schultz, Robert Frederking Language Technologies Institute Carnegie Mellon University
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Data Modeling and Databases II Entity-Relationship (ER) Model. Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich
 Model. Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich") Data Modeling and Databases II Entity-Relationship (ER) Model Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich Database design Information Requirements Requirements Engineering
Data Modeling and Databases II Entity-Relationship (ER) Model Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich Database design Information Requirements Requirements Engineering
Postprint.
 http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach
 Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
Data Integration through Clustering and Finding Statistical Relations - Validation of Approach Marek Jaszuk, Teresa Mroczek, and Barbara Fryc University of Information Technology and Management, ul. Sucharskiego
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY
 MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
Robust Sense-Based Sentiment Classification
 Robust Sense-Based Sentiment Classification Balamurali A R 1 Aditya Joshi 2 Pushpak Bhattacharyya 2 1 IITB-Monash Research Academy, IIT Bombay 2 Dept. of Computer Science and Engineering, IIT Bombay Mumbai,
Robust Sense-Based Sentiment Classification Balamurali A R 1 Aditya Joshi 2 Pushpak Bhattacharyya 2 1 IITB-Monash Research Academy, IIT Bombay 2 Dept. of Computer Science and Engineering, IIT Bombay Mumbai,
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
The CESAR Project: Enabling LRT for 70M+ Speakers
 The CESAR Project: Enabling LRT for 70M+ Speakers Marko Tadić University of Zagreb, Faculty of Humanities and Social Sciences Zagreb, Croatia marko.tadic@ffzg.hr META-FORUM 2011 Budapest, Hungary, 2011-06-28
The CESAR Project: Enabling LRT for 70M+ Speakers Marko Tadić University of Zagreb, Faculty of Humanities and Social Sciences Zagreb, Croatia marko.tadic@ffzg.hr META-FORUM 2011 Budapest, Hungary, 2011-06-28
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
Writing Research Articles
 Marek J. Druzdzel with minor additions from Peter Brusilovsky University of Pittsburgh School of Information Sciences and Intelligent Systems Program marek@sis.pitt.edu http://www.pitt.edu/~druzdzel Overview
Marek J. Druzdzel with minor additions from Peter Brusilovsky University of Pittsburgh School of Information Sciences and Intelligent Systems Program marek@sis.pitt.edu http://www.pitt.edu/~druzdzel Overview
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Operational Knowledge Management: a way to manage competence
 Operational Knowledge Management: a way to manage competence Giulio Valente Dipartimento di Informatica Universita di Torino Torino (ITALY) e-mail: valenteg@di.unito.it Alessandro Rigallo Telecom Italia
Operational Knowledge Management: a way to manage competence Giulio Valente Dipartimento di Informatica Universita di Torino Torino (ITALY) e-mail: valenteg@di.unito.it Alessandro Rigallo Telecom Italia
Informatics 2A: Language Complexity and the. Inf2A: Chomsky Hierarchy
 Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF GRAPH DATA
 International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
Exploiting multilingual nomenclatures and language-independent text features as an interlingua for cross-lingual text analysis applications
 Exploiting multilingual nomenclatures and language-independent text features as an interlingua for cross-lingual text analysis applications Ralf Steinberger, Bruno Pouliquen & Camelia Ignat European Commission
Exploiting multilingual nomenclatures and language-independent text features as an interlingua for cross-lingual text analysis applications Ralf Steinberger, Bruno Pouliquen & Camelia Ignat European Commission
SME Academia cooperation in research projects in Research for the Benefit of SMEs within FP7 Capacities programme
 SME Academia cooperation in research projects in Research for the Benefit of SMEs within FP7 Capacities programme European Commission Research and Innovation DG Aim of the study Background of the study
SME Academia cooperation in research projects in Research for the Benefit of SMEs within FP7 Capacities programme European Commission Research and Innovation DG Aim of the study Background of the study
Telekooperation Seminar
 Telekooperation Seminar 3 CP, SoSe 2017 Nikolaos Alexopoulos, Rolf Egert. {alexopoulos,egert}@tk.tu-darmstadt.de based on slides by Dr. Leonardo Martucci and Florian Volk General Information What? Read
Telekooperation Seminar 3 CP, SoSe 2017 Nikolaos Alexopoulos, Rolf Egert. {alexopoulos,egert}@tk.tu-darmstadt.de based on slides by Dr. Leonardo Martucci and Florian Volk General Information What? Read
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT