This lecture. Automatic speech recognition (ASR) Applying HMMs to ASR, Practical aspects of ASR, and Levenshtein distance. CSC401/2511 Spring
|
|
|
- Paula Sherman
- 6 years ago
- Views:
Transcription

1
2 This lecture Automatic speech recognition (ASR) Applying HMMs to ASR, Practical aspects of ASR, and Levenshtein distance. CSC401/2511 Spring



3 Consider what we want speech to do Buy ticket... AC yes My hands are in the air. Dictation Telephony Put this there. Multimodal interaction Can we just use GMMs? CSC401/2511 Spring

4 Speech is dynamic Speech changes over time. GMMs are good for high-level clustering, but they encode no notion of order, sequence, or time. Speech is an expression of language. We want to incorporate knowledge of how phonemes and words are ordered with language models. CSC401/2511 Spring






 not really")
5 Speech is sequences of phonemes (*) /ow p ah n dh ah p aa d b ey d ao r z/ open(podbay.doors); open the pod bay doors We want to convert a series of MFCC vectors into a sequence of phonemes. (*) not really CSC401/2511 Spring
6 Phoneme dictionaries There are many phonemic dictionaries that map words to pronunciations (i.e., lists of phoneme sequences). The CMU dictionary ( is popular. 127K words transcribed with the ARPAbet. Includes some rudimentary prosody markers. EVOLUTION EVOLUTION(2) EVOLUTION(3) EVOLUTION(4) EVOLUTIONARY EH2 V AH0 L UW1 SH AH0 N IY2 V AH0 L UW1 SH AH0 N EH2 V OW0 L UW1 SH AH0 N IY2 V OW0 L UW1 SH AH0 N EH2 V AH0 L UW1 SH AH0 N EH2 R IY0 CSC401/2511 Spring


7 Annotation/transcription Speech data must be segmented and annotated in order to be useful to an ASR learning component. Programs like Wavesurfer or Praat allow you to demarcate where a phoneme begins and ends in time. CSC401/2511 Spring




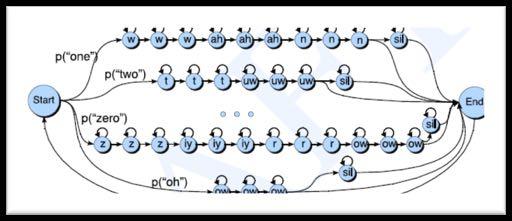
8 Putting it together? open the pod bay doors Language model Acoustic model CSC401/2511 Spring





2(*)")
9 The noisy channel model for ASR Language model Source!(#) W Acoustic model Channel!(% #) ( Word sequence * # Decoder Observed % * = argmax 1 CSC401/2511 Spring (( *)2(*) Acoustic sequence ( How to encode 2(( *)?

 ship 0.1 pass 0.05 camp 0.05 frock 0.")
 ship 0.25 pass 0.25 camp 0.")
 ship 0.3 pass 0 camp 0 frock 0.")
10 Reminder discrete HMMs Previously we saw discrete HMMs: at each state we observed a discrete symbol from a finite set of discrete symbols. word P(word) ship 0.1 pass 0.05 camp 0.05 frock 0.6 soccer 0.05 mother 0.1 tops 0.05 word P(word) ship 0.25 pass 0.25 camp 0.05 frock 0.3 soccer 0.05 mother 0.09 tops 0.01 word P(word) ship 0.3 pass 0 camp 0 frock 0.2 soccer 0.05 mother 0.05 tops 0.4 CSC401/2511 Spring
11 Continuous HMMs (CHMM) A continuous HMM has observations that are distributed over continuous variables. Observation probabilities, 3 4, are also continuous. E.g., here 3 5 (6 ) tells us the probability of seeing the (multivariate) continuous observation 6 while in state 0. 6 = b0 b1 b2 CSC401/2511 Spring

12 Defining CHMMs Continuous HMMs are very similar to discrete HMMs. 8 = {: ;,, : > } : set of states (e.g., subphones) ( = R BC : continuous observation space Π = {E ;,, E > } R F = G 4H, I, J 8 L = 3 4 6, I 8, 6 ( yielding M = {N 5,, N O }, N 4 8 P = o 5,, o O, o 4 ( : initial state probabilities : state transition probabilities : state output probabilities (i.e., Gaussian mixtures) : state sequence : observation sequence CSC401/2511 Spring
13 Word-level HMMs? Imagine that we want to learn an HMM for each word in our lexicon (e.g., 60K words 60K HMMs). No, thank you! Zipf s law tells us that many words occur very infrequently. 1 (or a few) training examples of a word is not enough to train a model as highly parameterized as a CHMM. In a word-level HMM, each state might be a phoneme. b0 b1 b2 CSC401/2511 Spring
14 Phoneme HMMs Phonemes change over time we model these dynamics by building one HMM for each phoneme. Tristate phoneme models are popular. The centre state is often the steady part. b0 b1 b2 tristate phoneme model (e.g., /oi/) CSC401/2511 Spring

15 Phoneme HMMs We train each phoneme HMM using all sequences of that phoneme. Even from different words. Phoneme HMMs /iy/ /ih/ ae sh epi m... MFCC Time, S /eh/ /s/ 42 /sh/ annotation observations CSC401/2511 Spring
16 Combining models We can learn an N-gram language model from word-level transcriptions of speech data. These models are discrete and are trained using MLE. Our phoneme HMMs together constitute our acoustic model. Each phoneme HMM tells us how a phoneme sounds. We can combine these models by concatenating phoneme HMMs together according to a known lexicon. We use a word-to-phoneme dictionary. CSC401/2511 Spring
17 Combining models If we know how phonemes combine to make words, we can simply concatenate together our phoneme models by inserting and adjusting transition weights. e.g., Zipf is pronounced /z ih f/, so (It s a tiny bit more complicated than this normally phoneme HMMs have special handle states at either end that connect to other HMMs) CSC401/2511 Spring

18 Co-articulation and triphones Co-articulation: n. When a phoneme is influenced by adjacent phonemes. A triphone HMM captures co-articulation. Triphone model /a-b+c/ is phoneme b when preceded by a and followed by c. Two (of many) triphone HMMs for /t/ /s-t+iy/ /iy-t+eh/ CSC401/2511 Spring

19 Combining triphone HMMs Triphone models can only connect to other triphone models that match. /z+ih/ /z-ih+f/ /ih-f/ CSC401/2511 Spring

20 Concatenating phoneme models We can easily incorporate unigram probabilities through transitions, too. From Jurafsky & Martin text CSC401/2511 Spring


21 Bigram models From Jurafsky & Martin text CSC401/2511 Spring

, as we did before with discrete HMMs.")


22 Using CHMMs As before, these HMMs are generative models that encode statistical knowledge of how output is generated. We train CHMMs with Baum-Welch (a type of Expectation- Maximization), as we did before with discrete HMMs. Here, the observation parameters, 3 4 6, are adjusted using the GMM training recipe from last lecture. We find the best state sequences using Viterbi, as before. Here, the best state sequence gives us a sequence of phonemes and words. CSC401/2511 Spring

 Gaussian")


23 Speech recognition architecture Cepstral feature extraction ( MFCC features 2(( *) Gaussian Mixture models Phoneme likelihoods HMM lexicon 2(*) N-gram language model Viterbi decoder a real poncho * CSC401/2511 Spring
24 Speech databases Large-vocabulary continuous ASR is meant to encode full conversational speech, with a vocabulary of >64K words. This requires lots of data to train our models. The Switchboard corpus contains 2430 conversations spread out over about 240 hours of data (~14 GB). The TIMIT database contains 63,000 sentences from 630 speakers. Relatively small (~750 MB), but very popular. Speech data from conferences (e.g., TED) or from broadcast news tends to be between 3 GB and 30 GB. CSC401/2511 Spring
25 Aspects of ASR systems in the world Speaking mode: Isolated word (e.g., yes ) vs. continuous (e.g., Siri, ask Cortana for the weather ) Speaking style: Read speech vs. spontaneous speech; the latter contains many dysfluencies Enrolment: Vocabulary: Transducer: (e.g., stuttering, uh, like, ) Speaker-dependent (all training data from one speaker) vs. speaker-independent (training data from many speakers). Small (<20 words) or large (>50,000 words). Cell phone? Noise-cancelling microphone? Teleconference microphone? CSC401/2511 Spring
, Signal degradation. This is normally white noise produced by the medium of transmission.")
26 Signal-to-noise ratio We are often concerned with the signal-to-noise ratio (SNR), which measures the ratio between the power of a desired signal within a recording (2 T4UVWX, e.g., the human speech) and additive noise (2 VY4TZ ). Noise typically includes: Background noise (e.g., people talking, wind), Signal degradation. This is normally white noise produced by the medium of transmission. 8[\ ]^ = 10 log ;5 2 T4UVWX 2 VY4TZ High 8[\ ]^ is >30dB. Low 8[\ ]^ is < 10 db. CSC401/2511 Spring You don t have to memorize this formula.

27 Audio-visual speech methods Observing the vocal tract directly, rather than through inference, can be very helpful in automatic speech recognition. The shape and aperture of the mouth gives some clues as to the phoneme being uttered. Depending on the level of invasiveness, we can even measure the glottis and tongue directly. CSC401/2511 Spring
.")
28 Example of articulatory data TORGO was built to train augmented ASR systems. 9 subjects with cerebral palsy (1 with ALS), 9 matched controls. Each reads prompts over 3 hours that cover phonemes and articulatory contrasts (e.g., meat vs. beat). Electromagnetic articulography (and video) track points to <1 mm. CSC401/2511 Spring




29 Example Lip aperture and nasals /m/ /n/ /ng/ Lip apertures over time Acoustic spectrograms CSC401/2511 Spring
30 Evaluating ASR accuracy How can you tell how good an ASR system at recognizing speech? E.g., if somebody said Reference: how to recognize speech but an ASR system heard Hypothesis: how to wreck a nice beach how do we quantify the error? One measure is word accuracy: #CorrectWords/#ReferenceWords E.g., 2/4, above This runs into problems similar to those we saw with SMT. E.g., the hypothesis how to recognize speech boing boing boing boing boing has 100% accuracy by this measure. Normalizing by #HypothesisWords also has problems CSC401/2511 Spring
31 Word-error rates (WER) ASR enthusiasts are often concerned with word-error rate (WER), which counts different kinds of errors that can be made by ASR at the word-level. Substitution error: One word being mistook for another Deletion error: Insertion error: e.g., shift given ship An input word that is skipped e.g. I Torgo given I am Torgo A hallucinated word that was not in the input. e.g., This Norwegian parrot is no more given This parrot is no more CSC401/2511 Spring
32 Evaluating ASR accuracy But how to decide which errors are of each type? E.g., Reference: how to recognize speech Hypothesis: how to wreck a nice beach, It s not so simple: speech seems to be mistaken for beach, except the /s/ phoneme is incorporated into the preceding hypothesis word, nice (/n ay s/). Here, recognize seems to be mistaken for wreck a nice Are each of wreck a nice substitutions of recognize? Is wreck a substitution for recognize? If so, the words a and nice must be insertions. Is nice a substitution for recognize? If so, the words wreck and a must be insertions. CSC401/2511 Spring
33 Levenshtein distance In practice, ASR people are often more concerned with overall WER, and don t care about how those errors are partitioned. E.g., 3 substitution errors are equivalent to 1 substitution plus 2 insertions. The Levenshtein distance is a straightforward algorithm based on dynamic programming that allows us to compute overall WER. CSC401/2511 Spring
![Levenshtein distance Allocate matrix \[g + 1, i + 1] // where g is the number of reference words // and i is the number of hypothesis words Initialize \ 0,0 0, and \ I, J for all other I = 0 or J = 0](/docs-images/72/67855318/images/34-2.jpg "for I 1.. g // #ReferenceWords for J 1.")
34 Levenshtein distance Allocate matrix \[g + 1, i + 1] // where g is the number of reference words // and i is the number of hypothesis words Initialize \ 0,0 0, and \ I, J for all other I = 0 or J = 0 for I 1.. g // #ReferenceWords for J 1.. i // #Hypothesis words \[I, J] min ( \ I 1, J + 1, // deletion \ I 1, J 1, // if the I qr reference word and // the J qr hypothesis word match \ I 1, J 1 + 1, // if they differ, i.e., substitution \ I, J ) // insertion Return 100 \ g, i /g CSC401/2511 Spring
35 Levenshtein distance initialization hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech The value at cell (I, J) is the minimum number of errors necessary to align I with J. CSC401/2511 Spring
36 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how 0 to recognize speech \ 1,1 = min + 1, (0), + 1 = 0 (match) We put a little arrow in place to indicate the choice. Arrows are normally stored in a backtrace matrix. CSC401/2511 Spring
37 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech We continue along for the first reference word These are all insertion errors CSC401/2511 Spring
38 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech And onto the second reference word CSC401/2511 Spring
39 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech Since recognize wreck, we have a substitution error. At some points, you have >1 possible path as indicated. We can prioritize types of errors arbitrarily. CSC401/2511 Spring
40 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech And we finish the grid. There are \ g, i = 4 word errors and a WER of 4 4 = 100%. WER can be greater than 100% (relative to the reference). CSC401/2511 Spring
41 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech If we want, we can backtrack using our arrows to find the proportion of substitution, deletion, and insertion errors. CSC401/2511 Spring
42 Levenshtein distance hypothesis - how to wreck a nice beach - 0 Reference how to recognize speech Here, we estimate 2 substitution errors and 2 insertion errors. Arrows can be encoded within a special backtrace matrix. CSC401/2511 Spring
43 Recent performance Corpus Speech type Lexicon size ASR WER (%) Human WER (%) Digits Spontaneous % % Phone directory Wall Street Journal Read % 0.1 % Read 64, % 1 % Radio news Mixed 64, % - Switchboard (telephone) conversation 10, % 4 % CSC401/2511 Spring
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Characterizing and Processing Robot-Directed Speech
 Characterizing and Processing Robot-Directed Speech Paulina Varchavskaia, Paul Fitzpatrick, Cynthia Breazeal AI Lab, MIT, Cambridge, USA [paulina,paulfitz,cynthia]@ai.mit.edu Abstract. Speech directed
Characterizing and Processing Robot-Directed Speech Paulina Varchavskaia, Paul Fitzpatrick, Cynthia Breazeal AI Lab, MIT, Cambridge, USA [paulina,paulfitz,cynthia]@ai.mit.edu Abstract. Speech directed
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches
 NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS
 ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
On Developing Acoustic Models Using HTK. M.A. Spaans BSc.
 On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Bi-Annual Status Report For. Improved Monosyllabic Word Modeling on SWITCHBOARD
 INSTITUTE FOR SIGNAL AND INFORMATION PROCESSING Bi-Annual Status Report For Improved Monosyllabic Word Modeling on SWITCHBOARD submitted by: J. Hamaker, N. Deshmukh, A. Ganapathiraju, and J. Picone Institute
INSTITUTE FOR SIGNAL AND INFORMATION PROCESSING Bi-Annual Status Report For Improved Monosyllabic Word Modeling on SWITCHBOARD submitted by: J. Hamaker, N. Deshmukh, A. Ganapathiraju, and J. Picone Institute
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Consonants: articulation and transcription
 Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Letter-based speech synthesis
 Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
Letter-based speech synthesis Oliver Watts, Junichi Yamagishi, Simon King Centre for Speech Technology Research, University of Edinburgh, UK O.S.Watts@sms.ed.ac.uk jyamagis@inf.ed.ac.uk Simon.King@ed.ac.uk
LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES. Judith Gaspers and Philipp Cimiano
 LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES Judith Gaspers and Philipp Cimiano Semantic Computing Group, CITEC, Bielefeld University {jgaspers cimiano}@cit-ec.uni-bielefeld.de ABSTRACT Semantic parsers
LEARNING A SEMANTIC PARSER FROM SPOKEN UTTERANCES Judith Gaspers and Philipp Cimiano Semantic Computing Group, CITEC, Bielefeld University {jgaspers cimiano}@cit-ec.uni-bielefeld.de ABSTRACT Semantic parsers
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques
 Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
International Journal of Advanced Networking Applications (IJANA) ISSN No. :
 ISSN No. :") International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Vimala.C Project Fellow, Department of Computer Science Avinashilingam Institute for Home Science and Higher Education and Women Coimbatore, India
 World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Listening and Speaking Skills of English Language of Adolescents of Government and Private Schools
 Listening and Speaking Skills of English Language of Adolescents of Government and Private Schools Dr. Amardeep Kaur Professor, Babe Ke College of Education, Mudki, Ferozepur, Punjab Abstract The present
Listening and Speaking Skills of English Language of Adolescents of Government and Private Schools Dr. Amardeep Kaur Professor, Babe Ke College of Education, Mudki, Ferozepur, Punjab Abstract The present
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty
 Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Improved Hindi Broadcast ASR by Adapting the Language Model and Pronunciation Model Using A Priori Syntactic and Morphophonemic Knowledge
 Improved Hindi Broadcast ASR by Adapting the Language Model and Pronunciation Model Using A Priori Syntactic and Morphophonemic Knowledge Preethi Jyothi 1, Mark Hasegawa-Johnson 1,2 1 Beckman Institute,
Improved Hindi Broadcast ASR by Adapting the Language Model and Pronunciation Model Using A Priori Syntactic and Morphophonemic Knowledge Preethi Jyothi 1, Mark Hasegawa-Johnson 1,2 1 Beckman Institute,
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Large vocabulary off-line handwriting recognition: A survey
 Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
PHONETIC DISTANCE BASED ACCENT CLASSIFIER TO IDENTIFY PRONUNCIATION VARIANTS AND OOV WORDS
 PHONETIC DISTANCE BASED ACCENT CLASSIFIER TO IDENTIFY PRONUNCIATION VARIANTS AND OOV WORDS Akella Amarendra Babu 1 *, Ramadevi Yellasiri 2 and Akepogu Ananda Rao 3 1 JNIAS, JNT University Anantapur, Ananthapuramu,
PHONETIC DISTANCE BASED ACCENT CLASSIFIER TO IDENTIFY PRONUNCIATION VARIANTS AND OOV WORDS Akella Amarendra Babu 1 *, Ramadevi Yellasiri 2 and Akepogu Ananda Rao 3 1 JNIAS, JNT University Anantapur, Ananthapuramu,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company
 Houghton Mifflin Harcourt Publishing Company") WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
WiggleWorks Software Manual PDF0049 (PDF) Houghton Mifflin Harcourt Publishing Company Table of Contents Welcome to WiggleWorks... 3 Program Materials... 3 WiggleWorks Teacher Software... 4 Logging In...
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Rachel E. Baker, Ann R. Bradlow. Northwestern University, Evanston, IL, USA
 LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
Large Kindergarten Centers Icons
 Large Kindergarten Centers Icons To view and print each center icon, with CCSD objectives, please click on the corresponding thumbnail icon below. ABC / Word Study Read the Room Big Book Write the Room
Large Kindergarten Centers Icons To view and print each center icon, with CCSD objectives, please click on the corresponding thumbnail icon below. ABC / Word Study Read the Room Big Book Write the Room
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
CEFR Overall Illustrative English Proficiency Scales
 CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
UDL Lesson Plan Template : Module 01 Group 4 Page 1 of 5 Shannon Bates, Sandra Blefko, Robin Britt
 Page 1 of 5 Shannon Bates, Sandra Blefko, Robin Britt Objective/s: Demonstrate physical care in relation to needs. Assessment/s: Demonstrations, formative assessments, personal reflections Learner Objectives:
Page 1 of 5 Shannon Bates, Sandra Blefko, Robin Britt Objective/s: Demonstrate physical care in relation to needs. Assessment/s: Demonstrations, formative assessments, personal reflections Learner Objectives:
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing
 Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Characteristics of the Text Genre Realistic fi ction Text Structure
 LESSON 14 TEACHER S GUIDE by Oscar Hagen Fountas-Pinnell Level A Realistic Fiction Selection Summary A boy and his mom visit a pond and see and count a bird, fish, turtles, and frogs. Number of Words:
LESSON 14 TEACHER S GUIDE by Oscar Hagen Fountas-Pinnell Level A Realistic Fiction Selection Summary A boy and his mom visit a pond and see and count a bird, fish, turtles, and frogs. Number of Words:
Books Effective Literacy Y5-8 Learning Through Talk Y4-8 Switch onto Spelling Spelling Under Scrutiny
 By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
By the End of Year 8 All Essential words lists 1-7 290 words Commonly Misspelt Words-55 working out more complex, irregular, and/or ambiguous words by using strategies such as inferring the unknown from
Noisy Channel Models for Corrupted Chinese Text Restoration and GB-to-Big5 Conversion
 Computational Linguistics and Chinese Language Processing vol. 3, no. 2, August 1998, pp. 79-92 79 Computational Linguistics Society of R.O.C. Noisy Channel Models for Corrupted Chinese Text Restoration
Computational Linguistics and Chinese Language Processing vol. 3, no. 2, August 1998, pp. 79-92 79 Computational Linguistics Society of R.O.C. Noisy Channel Models for Corrupted Chinese Text Restoration
Fountas-Pinnell Level P Informational Text
 LESSON 7 TEACHER S GUIDE Now Showing in Your Living Room by Lisa Cocca Fountas-Pinnell Level P Informational Text Selection Summary This selection spans the history of television in the United States,
LESSON 7 TEACHER S GUIDE Now Showing in Your Living Room by Lisa Cocca Fountas-Pinnell Level P Informational Text Selection Summary This selection spans the history of television in the United States,
The IRISA Text-To-Speech System for the Blizzard Challenge 2017
 The IRISA Text-To-Speech System for the Blizzard Challenge 2017 Pierre Alain, Nelly Barbot, Jonathan Chevelu, Gwénolé Lecorvé, Damien Lolive, Claude Simon, Marie Tahon IRISA, University of Rennes 1 (ENSSAT),
The IRISA Text-To-Speech System for the Blizzard Challenge 2017 Pierre Alain, Nelly Barbot, Jonathan Chevelu, Gwénolé Lecorvé, Damien Lolive, Claude Simon, Marie Tahon IRISA, University of Rennes 1 (ENSSAT),
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models
 Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
UNIVERSITY OF OSLO Department of Informatics. Dialog Act Recognition using Dependency Features. Master s thesis. Sindre Wetjen
 UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja