LP&IIS 2013, Springer LNCS Vol. 7912, pp
|
|
|
- Emerald Morton
- 6 years ago
- Views:
Transcription
1 LP&IIS 2013, Springer LNCS Vol. 7912, pp Aaron L.-F. Han, Derek F. Wong, and Lidia S. Chao Hanlifengaaron AT gmail DOT com June 17 th -18 th, 2013, Warsaw, Poland Natural Language Processing & Portuguese-Chinese Machine Translation Laboratory Department of Computer and Information Science University of Macau
2 Motivation and related work in NER (CNER) Problem analysis and the aim of this work A study of Chinese characteristics (in PER, LOC, and ORG) The designed and optimized feature set Employed CRF model Experiments Comparison with related work Different performance of sub features Formal definitions of the problems in CNER Conclusion Reference
3 Related literatures that are influenced by named entity recognition: Information extraction text mining machine translation knowledge management information retrieval, etc. Rapid development of NLP also promotes the NER research Development of computer technology allows the analysis on big data storage capacity computational power
4 Lev and Dan [1] perform NER on English Using unlabeled text and Wikipedia gazetteers. Sang and Meulder [2] conduct NER research on German Special applications of NER: geological text processing [3] biomedical named entity detection [4] Chinese NER (CNER), more difficult. Why? no word boundary in Chinese sentence
5 International CNER shared tasks under the SIGHAN (special interest group for Chinese) and CIPS (Chinese information processing society) before 2008 [5][6] Chinese personal name disambiguation after 2008 by SIGHAN [7][8] Explored methods on CNER: Maximum Entropy [9][10][16] Hidden Markov Model [11] Support Vector Machine [12] Conditional Random Field [13][15] Combination with other researches: Word segmentation, sentence chunking, word detection [14]
6 Problems in the employed methods: Maximum Entropy, local optimal solution, label bias Markov Model, strong independence assumption Support Vector Machine, low performance Conditional Random Field, challenges in features selection Problems in the research work: More discussion with the algorithm, less on the issues in CNER Different features, less or no explanation or backgrounds Less analysis on Chinese characteristics
7 The aim of this work: An introduction of Chinese characteristics Feature optimization based on linguistic analysis PER, LOC, ORG Comparisons of the performances by different algorithms Issues analysis and problem formalization in CNER
8 Chinese personal names (PER): clear format: Surname Given-name (we use x+y) Chinese surnames: 11,939 by Chinese academy of science [19][20]: 5313 of which consist of one character 4311 of two characters 1615 of three characters 571 of four characters, etc. Chinese Given-name: usually contains one or two characters as shown in Table 1.
9 Pl: place; Bud: building; Org: organization; Suf: suffix; Abbr: abbreviation
10 Chinese location names (LOC): Commonly used suffixes: 路 (road), 區 (district), 縣 (county), 市 (city), 省 (province), 洲 (continent), etc. Some standard formats, as in Table 1: use building names place + building place + organization Mix + suffix abbreviations
11 Chinese organization names (ORG): Some ORG entities contain suffixes but the suffixes own various expressions, not formalized Others do not have apparent suffixes: named by the owners of the organization e.g. 笑開花 (XiaoKaiHua, a small art association) Table 2 lists some kinds of ORG entities: including administrative unit, company, arts, public service, association, education and cultural, etc. Potentially implying that ORG may be one of the difficult category
12
13
14 X: the variable representing sequence Y: corresponding label sequence P(Y X): the conditional model in mathematics G=(V, E): a graph G, V of vertices or nodes, E of edges or lines Y = {Y v v V}, Y is indexed by vertices of G (X, Y) is a conditional random field model [24]: P θ y x exp e E,k λ k f k e, y e, x + v V,k μ k g k v, y v, x f k and g k are the feature functions, λ k and μ k are the parameters to be trained
15 Training methods for CRF including: Iterative scaling algorithms [24] Non-preconditioned conjugate-gradient [25] Voted perceptron training [26] Quasi-newton algorithm [27], used in this work online tool:
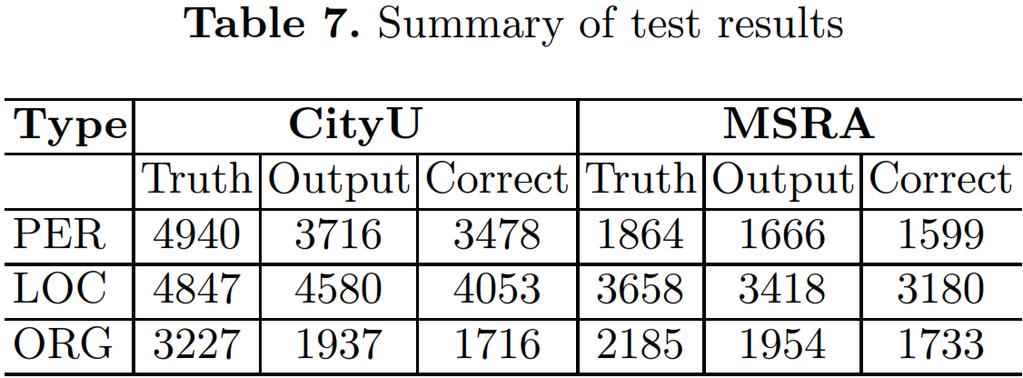
16 Data intro: To deal with an extensive kinds of named entities Using the SIGHAN Bakeoff-4 corpora [6] Containing PER, LOC, and ORG three kinds of entities CityU (traditional Chinese) and MSRA (simplified Chinese) Perform on closed track (without using external resources) Detailed information for training and test data in Table 4 and 5.

17 NE means the total of three kinds of named entities

18 OOV means the entities of the test data that do not exist in the training data, and Roov means the OOV rate
19 The samples of training corpus are shown as Table 6. In the test data, there is only one column of Chinese characters
20 Recognition results:
21 Evaluation metrics: Precision = Recall = number of correct output number of total output number of correct output number of truth F score = Harmonic Precision, Recall = 2 Precision Recall Precision+Recall Evaluation is performed on NE level (not token-per-token). E.g., if a token is supposed to be B-LOC but it is labeled I-LOC instead, then this will not be considered as a correct labeling
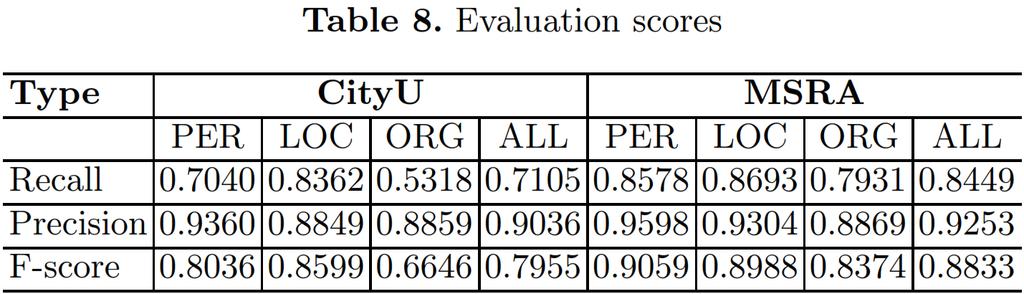
22 Evaluation scores:
23 There are several main conclusions derived: 1. These experiments results corroborate our analysis of the Chinese characteristics: PER and LOC have simpler structures and expressions that make the recognition easier than the ORG the Roov rate (in Table 5) of LOC is the lowest ( and respectively for CityU and MSRA) and the corresponding recognition of LOC performed very well ( and respectively in F-score). in the MSRA corpus, the Roov of ORG (0.3533) is larger than PER (0.3026) and the corresponding F-scores of ORG are lower however, in CityU corpus, the Roov of ORG (0.4884) is much lower than PER (0.7850) while the recognition result of ORG also perform worse ( and respectively of F-scores for them)
24 2. The recognition of the OOV entities is the principal challenge for the automatic systems the total OOV entity number in CityU (0.4882) is larger than MSRA (0.2142), and the corresponding final F-score of CityU (0.7955) is also lower than MSRA (0.8833)

25 Comparison with baselines in Table 9: The baselines are produced by a left-to-right maximum match algorithm applied on the testing data with the named entity lists generated from the training data.
26 The experiments have yielded much higher F-scores than the baselines The baseline scores are unstable on different entities resulting synthetically in the total F-scores of and respectively for CityU and MSRA corpus. On the other hand, our results show that the three kinds of entity recognitions get high scores generally without big twists and turns. This proves that the approaches employed in this research are reasonable and augmented. The improvements on ORG and PER are especially larger on both two corpora, leading to the total increases of F-scores 33.6% and 44.7% respectively.
27 Comparison with related works: Related works that use different features (various window sizes) algorithms (CRF, ME, SVM, etc.) external resources (external vocabularies, POS tools, name lists, etc.) the comparison test on MSRA, some works briefly in Table 10. Due to the fact that most researchers undertake the test only on MSRA corpus use number n to represent the character previous nth character when n<0 the following nth character when n>0 and the current token case when n=0 E.g., B(-10, 01, 12) means the three bigram features (former one and current, current and next one, next two characters).
28
29 From Table 10: when the window size of the features is smaller, the performance shows worse. too large window size cannot ensure good results while it will bring in noises and cost more running time simultaneously. external materials do not necessarily ensure better performances the combination of segmentation and POS will offer more information about the test set; however, the segmentation and POS accuracy also influence the system quality. the experiment of this paper has yielded promising results by employing optimized feature set and a concise model.

30 the performances of different sub features in our experiments the corresponding results respectively in Table 11
31 Table 11 shows: Generally speaking, more features lead to more training time, and when the feature set is small this conclusion also fit the case of iteration number. However, this conclusion does not stand when the feature set gets larger e.g. testing on the MSRA corpus, the feature set (FS) FS4 needs 314 iteration number which is less than 318 by FS2 although the former feature set is larger. This may be due to the fact that the feature set FS2 needs more iterations to converge to a fixed point. Employing the CRF algorithm, the optimized feature set is chosen as FS4 and if we continue to expand the features the recognition accuracy will decrease as in Table 11
32 Due to the changeful and complicated characteristics of Chinese there are some special combinations of characters, and sometimes we can label them with different performances with all results reasonable in practice. These make some confusion for the researchers. How do we deal with these problems? To facilitate further researches, we introduce and provide some formal definitions of the existing issues in CNER
33 First, the Function-overload problem: (also called as metonymy in some place) One word bears two or more meanings in the same text. E.g., the word 大山 (DaShan) means an organization name in the chunk 大山國際銀行 (DaShan International Bank) and the whole chunk means a company While 大山 (DaShan) also represents a person name in the sequence 大山悄悄地走了 (DaShan quietly went away) with the whole sequence meaning a person's action It is difficult for the computer to differ their meaning and assign corresponding different labels (ORG or PER) they must be recognized through the analysis of context and semantics.
34 Furthermore, the Multi-segmentation problem in CNER: one sequence can be segmented into a whole or more fragments according to different meanings, and the labeling will correspondingly end in different results. For example, the sequence 中興實業 (ZhongXing Corporation) can be labeled as a whole chunk as "B-ORG I-ORG I-ORG I-ORG" which means it is an organization name It also can be divided as 中興 / 實業 and labeled as B-ORG I-ORG / N N meaning that the word 中興 (ZhongXing) can represent the organization entity and 實業 (Corporation) specifies common Chinese word, and this usage is widespread in Chinese documents.
35 Another example of the Multi-segmentation problem in CNER: the sequence 杭州西湖 (Hang Zhou Xi Hu) can be labeled as "B-LOC I-LOC I-LOC I-LOC" as a place name but it can also be labeled as "B-LOC I-LOC B-LOC I-LOC" due to the fact that 西湖 (XiHu) is indeed a place that belongs to the city 杭州 (HangZhou). Which label sequences shall we select for them? Both of them are reasonable. This is a difficult problem for manual work, let alone for computer. Above discussed problems are only some of the existing ones in CNER. If we can deal with them well, the performances will be better in the future.
36 This paper undertakes the researches of CNER which is a difficult issue in NLP literature. The characteristics of Chinese named entities are introduced respectively on personal names, location names and organization names. Employing the CRF algorithm, optimized features have shown promising performances compared with related works that use different feature sets and algorithms. Furthermore, to facilitate further researches, this paper discusses the problems existing in the CNER and puts forward some formal definitions combined with instructive solutions. The performance results can be further improved in the open test through employing other high quality resources and tools e.g. externally generated word-frequency counts, common Chinese surnames and internet dictionaries
37 1. Ratinov, L., Roth, D.: Design Challenges and Misconceptions in Named Entity Recognition. In: Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL 2009), pp Association for Computational Linguistics Press, Stroudsburg (2009) 2. Sang, E.F.T.K., Meulder, F.D.: Introduciton to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In: HLT-NAACL, pp ACL Press, USA (2003) 3. Sobhana, N., Mitra, P., Ghosh, S.: Conditional Random Field Based Named Entity Recognition in Geological text. J. IJCA 1(3), (2010) 4. Settles, B.: Biomedical named entity recognition using conditional random fields and rich feature sets. In: Collier, N., Ruch, P., Nazarenko, A. (eds.) International Joint Workshop on Natural Language Processing in Biomedicine and its Applications, pp ACL Press, Stroudsburg (2004) 5. Levow, G.A.: The third international CLP bakeoff: Word segmentation and named entity recognition. In: Proceedings of the Fifth SIGHAN Workshop on CLP, pp ACL Press, Sydney (2006)
38 6. Jin, G., Chen, X.: The fourth international CLP bakeoff: Chinese word segmentation, named entity recognition and Chinese pos tagging. In: Sixth SIGHAN Workshop on CLP, pp ACL Press, Hyderabad (2008) 7. Chen, Y., Jin, P., Li, W., Huang, C.-R.: The Chinese Persons Name Disambiguation Evaluation: Exploration of Personal Name Disambiguation in Chinese News. In: CIPS-SIGHAN Joint Conference on Chinese Language Processing, pp ACL Press, BeiJing (2010) 8. Sun, L., Zhang, Z., Dong, Q.: Overview of the Chinese Word Sense Induction Task at CLP2010. In: CIPS-SIGHAN Joint Conference on CLP (CLP2010), pp ACL Press, BeiJing (2010) 9. Jaynes, E.: The relation of Bayesian and maximum entropy methods. J. Maximumentropy and Bayesian Methods in Science and Engineering 1, (1988) 10. Wong, F., Chao, S., Hao, C.C., Leong, K.S.: A Maximum Entropy (ME) Based Translation Model for Chinese Characters Conversion. J. Advances in Computational Linguistics, Research in Computer Science. 41, (2009)
39 11. Ekbal, A., Bandyopadhyay, S.: A hidden Markov model based named entity recognition system: Bengali and Hindi as case studies. In: Ghosh, A., De, R.K., Pal, S.K. (eds.) PReMI LNCS, vol. 4815, pp Springer, Heidelberg (2007) 12. Mansouri, A., Affendey, L., Mamat, A.: Named entity recognition using a new fuzzy support vector machine. J. IJCSNS 8(2), 320 (2008) 13. Putthividhya, D.P., Hu, J.: Bootstrapped named entity recognition for product attribute extraction. In: EMNLP 2011, pp ACL Press, Stroudsburg (2011) 14. Peng, F., Feng, F., McCallum, A.: Chinese segmentation and new word detection using conditional random fields. In: Proceedings of the 20th international conference on Computational Linguistics (COLING 2004), Article 562. Computational Linguistics Press, Stroudsburg (2004) 15. Chen, W., Zhang, Y., Isahara, H.: Chinese named entity recognition with conditional random fields. In: Fifth SIGHAN Workshop on Chinese Language Process- ing, pp ACL Press, Sydney (2006)
40 16. Zhu, F., Liu, Z., Yang, J., Zhu, P.: Chinese event place phrase recognition of emergency event using Maximum Entropy. In: Cloud Computing and Intelligence Systems (CCIS), pp IEEE, ShangHai (2011) 17. Qin, Y., Yuan, C., Sun, J., Wang, X.: BUPT Systems in the SIGHAN Bakeoff In: Sixth SIGHAN Workshop on CLP, pp ACL Press, Hyderabad (2008) 18. Feng, Y., Huang, R., Sun, L.: Two Step Chinese Named Entity Recognition Based on Conditional Random Fields Models. In: Sixth SIGHAN Workshop on CLP, pp ACL Press, Hyderabad (2008) 19. Yuan, Yida, Zhong, W.: Contemporary Surnames. Jiangxi people s publishing house, China (2006) 20. Yuan, Yida, Qiu, J., Zhang, R.: 300 most common surname in Chinese surnamespopulation genetic and population distribution. East China Normal University Publishing House, China (2007) 21. Huang, D., Sun, X., Jiao, S., Li, L., Ding, Z., Wan, R.: HMM and CRF based hybrid model for chinese lexical analysis. In: Sixth SIGHAN Workshop on CLP, pp ACL Press, Hyderabad (2008)
41 22. Sun, G.-L., Sun, C.-J., Sun, K., Wang, X.-L.: A Study of Chinese Lexical Analysis Based on Discriminative Models. In: Sixth SIGHANWorkshop on CLP, pp ACL Press, Hyderabad (2008) 23. Yang, F., Zhao, J., Zou, B.: CRFs-Based Named Entity Recognition Incorporated with Heuristic Entity List Searching. In: Sixth SIGHAN Workshop on CLP, pp ACL Press, Hyderabad (2008) 24. Lafferty, J., McCallum, A., Pereira, F.C.N.: Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In: Proceeding of 18th International Conference on Machine Learning, pp DBLP, Massachusetts (2001) 25. Shewchuk, J.R.: An introduction to the conjugate gradient method without the agonizing pain. Technical Report CMUCS-TR , Carnegie Mellon University (1994) 26. Collins, M., Duffy, N.: New ranking algorithms for parsing and tagging: kernels over discrete structures, and the voted perceptron. In: Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL 2002), pp Association for Computational Linguistics Press, Stroudsburg (2002)
42 27. The Numerical Algorithms Group. E04 - Minimizing or Maximizing a Function, NAG Library Manual, Mark 23 (retrieved 2012) 28. Zhao, H., Liu, Q.: The CIPS-SIGHAN CLP2010 Chinese Word Segmentation Backoff. In: CIPS-SIGHAN Joint Conference on CLP, pp ACL Press, BeiJing (2010) 29. Zhou, Q., Zhu, J.: Chinese Syntactic Parsing Evaluation. In: CIPS-SIGHAN Joint Conference on CLP (CLP 2010), pp ACL Press, BeiJing (2010) 30. Xu, Z., Qian, X., Zhang, Y., Zhou, Y.: CRF-based Hybrid Model for Word Segmentation, NER and even POS Tagging. In: Sixth SIGHAN Workshop on CLP, pp ACL Press, India (2008)
43 Aaron L.-F. Han, Derek F. Wong, and Lidia S. Chao Hanlifengaaron AT gmail DOT com, {derekfw, lidiasc} AT umac.mo Natural Language Processing & Portuguese-Chinese Machine Translation Laboratory Department of Computer and Information Science University of Macau
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Named Entity Recognition: A Survey for the Indian Languages
 Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches
 NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Exploiting Wikipedia as External Knowledge for Named Entity Recognition
 Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain
 Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews
 Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews Kang Liu, Liheng Xu and Jun Zhao National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy
Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews Kang Liu, Liheng Xu and Jun Zhao National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY
 MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Extracting and Ranking Product Features in Opinion Documents
 Extracting and Ranking Product Features in Opinion Documents Lei Zhang Department of Computer Science University of Illinois at Chicago 851 S. Morgan Street Chicago, IL 60607 lzhang3@cs.uic.edu Bing Liu
Extracting and Ranking Product Features in Opinion Documents Lei Zhang Department of Computer Science University of Illinois at Chicago 851 S. Morgan Street Chicago, IL 60607 lzhang3@cs.uic.edu Bing Liu
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
TextGraphs: Graph-based algorithms for Natural Language Processing
 HLT-NAACL 06 TextGraphs: Graph-based algorithms for Natural Language Processing Proceedings of the Workshop Production and Manufacturing by Omnipress Inc. 2600 Anderson Street Madison, WI 53704 c 2006
HLT-NAACL 06 TextGraphs: Graph-based algorithms for Natural Language Processing Proceedings of the Workshop Production and Manufacturing by Omnipress Inc. 2600 Anderson Street Madison, WI 53704 c 2006
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
BYLINE [Heng Ji, Computer Science Department, New York University,
 INFORMATION EXTRACTION BYLINE [Heng Ji, Computer Science Department, New York University, hengji@cs.nyu.edu] SYNONYMS NONE DEFINITION Information Extraction (IE) is a task of extracting pre-specified types
INFORMATION EXTRACTION BYLINE [Heng Ji, Computer Science Department, New York University, hengji@cs.nyu.edu] SYNONYMS NONE DEFINITION Information Extraction (IE) is a task of extracting pre-specified types
Matching Similarity for Keyword-Based Clustering
 Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
The MSR-NRC-SRI MT System for NIST Open Machine Translation 2008 Evaluation
 The MSR-NRC-SRI MT System for NIST Open Machine Translation 2008 Evaluation AUTHORS AND AFFILIATIONS MSR: Xiaodong He, Jianfeng Gao, Chris Quirk, Patrick Nguyen, Arul Menezes, Robert Moore, Kristina Toutanova,
The MSR-NRC-SRI MT System for NIST Open Machine Translation 2008 Evaluation AUTHORS AND AFFILIATIONS MSR: Xiaodong He, Jianfeng Gao, Chris Quirk, Patrick Nguyen, Arul Menezes, Robert Moore, Kristina Toutanova,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Short Text Understanding Through Lexical-Semantic Analysis
 Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Mining Topic-level Opinion Influence in Microblog
 Mining Topic-level Opinion Influence in Microblog Daifeng Li Dept. of Computer Science and Technology Tsinghua University ldf3824@yahoo.com.cn Jie Tang Dept. of Computer Science and Technology Tsinghua
Mining Topic-level Opinion Influence in Microblog Daifeng Li Dept. of Computer Science and Technology Tsinghua University ldf3824@yahoo.com.cn Jie Tang Dept. of Computer Science and Technology Tsinghua
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
ARNE - A tool for Namend Entity Recognition from Arabic Text
 24 ARNE - A tool for Namend Entity Recognition from Arabic Text Carolin Shihadeh DFKI Stuhlsatzenhausweg 3 66123 Saarbrücken, Germany carolin.shihadeh@dfki.de Günter Neumann DFKI Stuhlsatzenhausweg 3 66123
24 ARNE - A tool for Namend Entity Recognition from Arabic Text Carolin Shihadeh DFKI Stuhlsatzenhausweg 3 66123 Saarbrücken, Germany carolin.shihadeh@dfki.de Günter Neumann DFKI Stuhlsatzenhausweg 3 66123
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
A Class-based Language Model Approach to Chinese Named Entity Identification 1
 Computational Linguistics and Chinese Language Processing Vol. 8, No. 2, August 2003, pp. 1-28 The Association for Computational Linguistics and Chinese Language Processing A Class-based Language Model
Computational Linguistics and Chinese Language Processing Vol. 8, No. 2, August 2003, pp. 1-28 The Association for Computational Linguistics and Chinese Language Processing A Class-based Language Model
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Extracting Verb Expressions Implying Negative Opinions
 Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
What s in a Step? Toward General, Abstract Representations of Tutoring System Log Data
 What s in a Step? Toward General, Abstract Representations of Tutoring System Log Data Kurt VanLehn 1, Kenneth R. Koedinger 2, Alida Skogsholm 2, Adaeze Nwaigwe 2, Robert G.M. Hausmann 1, Anders Weinstein
What s in a Step? Toward General, Abstract Representations of Tutoring System Log Data Kurt VanLehn 1, Kenneth R. Koedinger 2, Alida Skogsholm 2, Adaeze Nwaigwe 2, Robert G.M. Hausmann 1, Anders Weinstein
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Learning Computational Grammars
 Learning Computational Grammars John Nerbonne, Anja Belz, Nicola Cancedda, Hervé Déjean, James Hammerton, Rob Koeling, Stasinos Konstantopoulos, Miles Osborne, Franck Thollard and Erik Tjong Kim Sang Abstract
Learning Computational Grammars John Nerbonne, Anja Belz, Nicola Cancedda, Hervé Déjean, James Hammerton, Rob Koeling, Stasinos Konstantopoulos, Miles Osborne, Franck Thollard and Erik Tjong Kim Sang Abstract
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A heuristic framework for pivot-based bilingual dictionary induction
 2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
A deep architecture for non-projective dependency parsing
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Bug triage in open source systems: a review
 Int. J. Collaborative Enterprise, Vol. 4, No. 4, 2014 299 Bug triage in open source systems: a review V. Akila* and G. Zayaraz Department of Computer Science and Engineering, Pondicherry Engineering College,
Int. J. Collaborative Enterprise, Vol. 4, No. 4, 2014 299 Bug triage in open source systems: a review V. Akila* and G. Zayaraz Department of Computer Science and Engineering, Pondicherry Engineering College,
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models
 Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models Jung-Tae Lee and Sang-Bum Kim and Young-In Song and Hae-Chang Rim Dept. of Computer &
Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models Jung-Tae Lee and Sang-Bum Kim and Young-In Song and Hae-Chang Rim Dept. of Computer &
Multiobjective Optimization for Biomedical Named Entity Recognition and Classification
 Available online at www.sciencedirect.com Procedia Technology 6 (2012 ) 206 213 2nd International Conference on Communication, Computing & Security (ICCCS-2012) Multiobjective Optimization for Biomedical
Available online at www.sciencedirect.com Procedia Technology 6 (2012 ) 206 213 2nd International Conference on Communication, Computing & Security (ICCCS-2012) Multiobjective Optimization for Biomedical
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
ScienceDirect. Malayalam question answering system
 Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
A Named Entity Recognition Method using Rules Acquired from Unlabeled Data
 A Named Entity Recognition Method using Rules Acquired from Unlabeled Data Tomoya Iwakura Fujitsu Laboratories Ltd. 1-1, Kamikodanaka 4-chome, Nakahara-ku, Kawasaki 211-8588, Japan iwakura.tomoya@jp.fujitsu.com
A Named Entity Recognition Method using Rules Acquired from Unlabeled Data Tomoya Iwakura Fujitsu Laboratories Ltd. 1-1, Kamikodanaka 4-chome, Nakahara-ku, Kawasaki 211-8588, Japan iwakura.tomoya@jp.fujitsu.com
Variations of the Similarity Function of TextRank for Automated Summarization
 Variations of the Similarity Function of TextRank for Automated Summarization Federico Barrios 1, Federico López 1, Luis Argerich 1, Rosita Wachenchauzer 12 1 Facultad de Ingeniería, Universidad de Buenos
Variations of the Similarity Function of TextRank for Automated Summarization Federico Barrios 1, Federico López 1, Luis Argerich 1, Rosita Wachenchauzer 12 1 Facultad de Ingeniería, Universidad de Buenos
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
Identification of Opinion Leaders Using Text Mining Technique in Virtual Community
 Identification of Opinion Leaders Using Text Mining Technique in Virtual Community Chihli Hung Department of Information Management Chung Yuan Christian University Taiwan 32023, R.O.C. chihli@cycu.edu.tw
Identification of Opinion Leaders Using Text Mining Technique in Virtual Community Chihli Hung Department of Information Management Chung Yuan Christian University Taiwan 32023, R.O.C. chihli@cycu.edu.tw
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees
 Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Regression for Sentence-Level MT Evaluation with Pseudo References
 Regression for Sentence-Level MT Evaluation with Pseudo References Joshua S. Albrecht and Rebecca Hwa Department of Computer Science University of Pittsburgh {jsa8,hwa}@cs.pitt.edu Abstract Many automatic
Regression for Sentence-Level MT Evaluation with Pseudo References Joshua S. Albrecht and Rebecca Hwa Department of Computer Science University of Pittsburgh {jsa8,hwa}@cs.pitt.edu Abstract Many automatic
arxiv: v1 [math.at] 10 Jan 2016
![arxiv: v1 [math.at] 10 Jan 2016](/thumbs/72/66271209.jpg "arxiv: v1 [math.at] 10 Jan 2016") THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming
 Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz