Natural Language Processing and Information Retrieval
|
|
|
- Moris George
- 6 years ago
- Views:
Transcription

1 Natural Language Processing and Information Retrieval Part of Speech Tagging and Named Entity Recognition Alessandro Moschitti Department of information and communication technology University of Trento
2 Parts of Speech! 8 traditional parts of speech for IndoEuropean languages! Noun, verb, adjective, preposition, adverb, article, interjection, pronoun, conjunction, etc! Around for over 2000 years (Dionysius Thrax of Alexandria, c. 100 B.C.)! Called: parts-of-speech, lexical category, word classes, morphological classes, lexical tags, POS
3 POS examples for English! N noun chair, bandwidth, pacing! V verb study, debate, munch! ADJ adj purple, tall, ridiculous! ADV adverb unfortunately, slowly! P preposition of, by, to! PRO pronoun I, me, mine! DET determiner the, a, that, those! CONJ conjunction and, or
4 Open vs. Closed classes! Closed:! determiners: a, an, the! pronouns: she, he, I! prepositions: on, under, over, near, by,! Open:! Nouns, Verbs, Adjectives, Adverbs.
5 Open Class Words! Nouns! Proper nouns (Penn, Philadelphia, Davidson)! English capitalizes these.! Common nouns (the rest).! Count nouns and mass nouns! Count: have plurals, get counted: goat/goats, one goat, two goats! Mass: don t get counted (snow, salt, communism) (*two snows)! Adverbs: tend to modify things! Unfortunately, John walked home extremely slowly yesterday! Directional/locative adverbs (here,home, downhill)! Degree adverbs (extremely, very, somewhat)! Manner adverbs (slowly, slinkily, delicately)! Verbs! In English, have morphological affixes (eat/eats/eaten)
6 Closed Class Words! Differ more from language to language than open class words! Examples:! prepositions: on, under, over,! particles: up, down, on, off,! determiners: a, an, the,! pronouns: she, who, I,..! conjunctions: and, but, or,! auxiliary verbs: can, may should,! numerals: one, two, three, third,
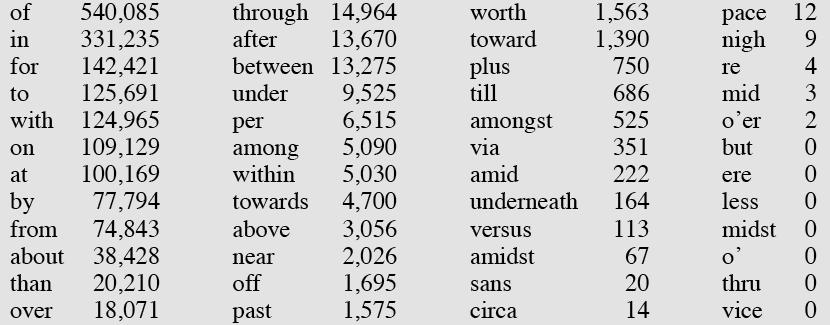
7 Prepositions from CELEX

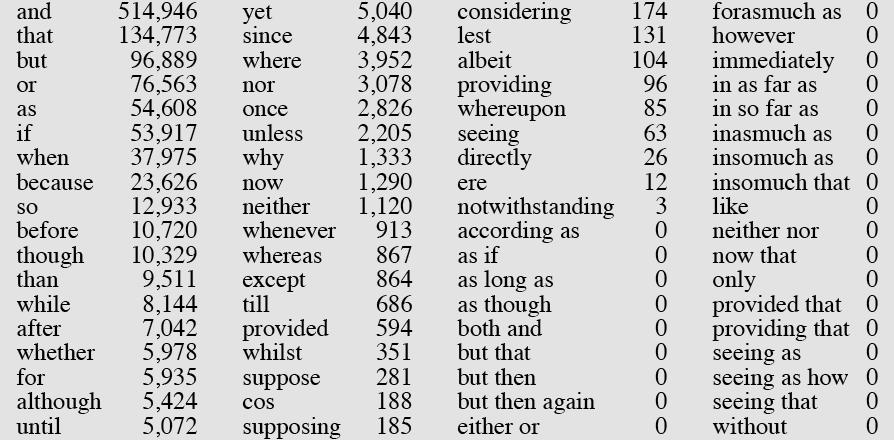
8 Conjunctions

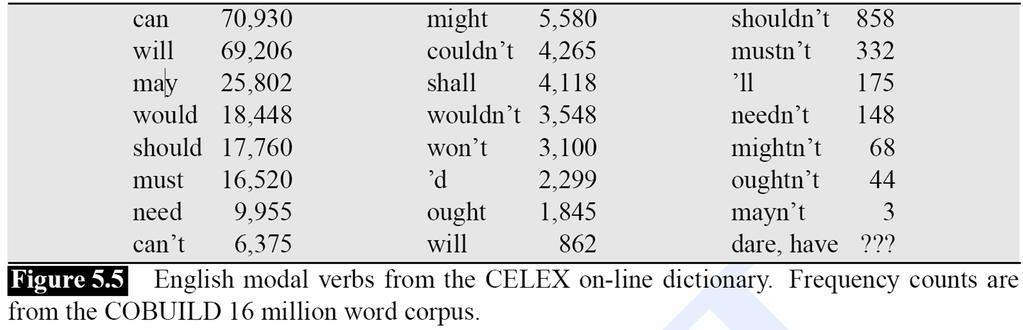
9 Auxiliaries

10 POS Tagging: Choosing a Tagset! There are so many parts of speech, potential distinctions we can draw! To do POS tagging, we need to choose a standard set of tags to work with! Could pick very coarse tagsets! N, V, Adj, Adv.! More commonly used set is finer grained, the Penn TreeBank tagset, 45 tags! PRP$, WRB, WP$, VBG! Even more fine-grained tagsets exist

11 Penn TreeBank POS Tagset
12 Using the Penn Tagset! The/DT grand/jj jury/nn commmented/vbd on/ IN a/dt number/nn of/in other/jj topics/nns./.! Prepositions and subordinating conjunctions marked IN ( although/in I/PRP.. )! Except the preposition/complementizer to is just marked TO.
13 Deciding on the correct part of speech can be difficult even for people! Mrs/NNP Shaefer/NNP never/rb got/vbd around/rp to/to joining/vbg! All/DT we/prp gotta/vbn do/vb is/vbz go/vb around/in the/dt corner/nn! Chateau/NNP Petrus/NNP costs/vbz around/rb 250/CD
14 POS Tagging: Definition! The process of assigning a part-of-speech or lexical class marker to each word in a corpus: WORDS the koala put the keys on the table TAGS N V P DET
15 POS Tagging example WORD tag the DET koala N put V the DET keys N on P the DET table N

16 POS Tagging! Words often have more than one POS: back! The back door = JJ! On my back = NN! Win the voters back = RB! Promised to back the bill = VB! The POS tagging problem is to determine the POS tag for a particular instance of a word.


17 How Hard is POS Tagging? Measuring Ambiguity
18 How difficult is POS tagging?! About 11% of the word types in the Brown corpus are ambiguous with regard to part of speech! But they tend to be very common words! 40% of the word tokens are ambiguous
19 Rule-Based Tagging! Start with a dictionary! Assign all possible tags to words from the dictionary! Write rules by hand to selectively remove tags! Leaving the correct tag for each word.
20 Start With a Dictionary she: PRP promised: VBN,VBD to TO back: VB, JJ, RB, NN the: DT bill: NN, VB Etc for the ~100,000 words of English with more than 1 tag
21 Assign Every Possible Tag and apply rules NN RB VBN JJ VB PRP VBD TO VB DT NN She promised to back the bill
22 Simple Statistical Approaches: Idea 1
23 Simple Statistical Approaches: Idea 2 For a string of words find the string of POS tags which maximizes P(T W) W = w 1 w 2 w 3 w n T = t 1 t 2 t 3 t n! i.e., the probability of tag string T given that the word string was W! i.e., that W was tagged T
24 Again, The Sparse Data Problem A Simple, Impossible Approach to Compute P(T W): Count up instances of the string "heat oil in a large pot" in the training corpus, and pick the most common tag assignment to the string..
25 A Practical Statistical Tagger
26 A Practical Statistical Tagger II But we can't accurately estimate more than tag bigrams or so Again, we change to a model that we CAN estimate:
27 A Practical Statistical Tagger III So, for a given string W = w 1 w 2 w 3 w n, the tagger needs to find the string of tags T which maximizes
28 Training and Performance! To estimate the parameters of this model, given an annotated training corpus:! Because many of these counts are small, smoothing is necessary for best results! Such taggers typically achieve about 95-96% correct tagging, for tag sets of tags.
29 Assigning tags to unseen words! Pretend that each unknown word is ambiguous among all possible tags, with equal probability! Assume that the probability distribution of tags over unknown words is like the distribution of tags over words seen only once! Morphological clues! Combination
30 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier NNP
31 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier VBD
32 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier DT
33 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier NN
34 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier CC
35 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier VBD
36 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier TO
37 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier VB
38 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier PRP
39 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier IN
40 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier DT
41 Sequence Labeling as Classification! Classify each token independently but use as input features, information about the surrounding tokens (sliding window). John saw the saw and decided to take it to the table. classifier NN

42 Sequence Labeling as Classification Using Outputs as Inputs! Better input features are usually the categories of the surrounding tokens, but these are not available yet.! Can use category of either the preceding or succeeding tokens by going forward or back and using previous output.
43 SVMs for tagging! h"p:// SVMTool.v1.4.ps! We can use SVMs in a similar way! We can use a window around the word! % on WSJ
44 SVMs for tagging from Jimenez & Marquez
45 An example of Features
46 No sequence modeling
47 Evaluation! So once you have you POS tagger running how do you evaluate it?! Overall error rate with respect to a gold-standard test set.! Error rates on particular tags! Error rates on particular words! Tag confusions...
48 Evaluation! The result is compared with a manually coded Gold Standard! Typically accuracy reaches 96-97%! This may be compared with result for a baseline tagger (one that uses no context).! Important: 100% is impossible even for human annotators.

 vs Participle (VBN)")
49 Error Analysis! Look at a confusion matrix! See what errors are causing problems! Noun (NN) vs ProperNoun (NNP) vs Adj (JJ)! Past tense verb form (VBD) vs Participle (VBN) vs Adjective (JJ)
50 Named Entity Recognition
51 Linguistically Difficult Problem! NE involves identification of proper names in texts, and classification into a set of predefined categories of interest.! Three universally accepted categories: person, location and organisation! Other common tasks: recognition of date/time expressions, measures (percent, money, weight etc), addresses etc.! Other domain-specific entities: names of drugs, medical conditions, names of ships, bibliographic references etc.
52 Problems in NE Task Definition! Category definitions are intuitively quite clear, but there are many grey areas.! Many of these grey area are caused by metonymy.! Organisation vs. Location : England won the World Cup vs. The World Cup took place in England.! Company vs. Artefact: shares in MTV vs. watching MTV! Location vs. Organisation: she met him at Heathrow vs. the Heathrow authorities
53 NE System Architecture documents tokeniser gazetteer NE grammar NEs
54 Approach con t! Again Text Categorization! N-grams in a window centered on the NER! Features similar to POS-tagging! Gazetteer! Capitalize! Beginning of the sentence! Is it all capitalized
55 Approach con t! NE task in two parts:! Recognising the entity boundaries! Classifying the entities in the NE categories! Tokens in text are often coded with the IOB scheme! O outside, B-XXX first word in NE, I-XXX all other words in NE! Easy to convert to/from inline MUC-style markup! Argentina B-LOC played O with O Del B-PER Bosque I-PER

56 Feature types! Word- level features! List lookup features! Document & corpus features
57 Word- level features
58 List lookup features Exact match vs. flexible match Stems (remove inflecponal and derivaponal suffixes) Lemmas (remove inflecponal suffixes only) Small lexical variapons (small edit distance) Normalize words to their Soundex codes
59 Document and corpus features
60 Examples of uses of document and corpus features! Meta- informapon (e.g. names in headers)! MulPword enppes that do not contain rare lowercase words of a relapvely long size are candidate NEs! Frequency of a word (e.g. Life) divided by its frequency in case insensipve form

61 NER! Description! Performance
62 Name Entity Recognition! IndentiFinder (Bikel et al, 1999)! Given a set of Named Entities (NE)! PERSON, ORGANIZATION, LOCATION, MONEY, DATE, TIME, PERCENT! Predict NEs of a sentence with Hidden Markov models!! P( NC NC 1, w) P w w ) ( 1 1
63
64 Probability of Mr. John eats.
65 Other characteristics! Probabilities are learned from annotated documents! Features! Levels of back-off! Unknown models
66
67 Back-off levels
68 Current Status! Software Implementation! Learner and classifier in C++! Classifier in Java (to be integrated in Chaos)! Named Entity Recognizer for English! Trained on MUC-6 data! Named Entity Recognizer for Italian! Trained our annotated documents
69 Contributions on Italian Versions! Annotation of 220 documents from La Repubblica! Modification of some features, e.g. date! Accent treatments, e.g Cinecittà
70 English Results ACT REC PRE SUBTASK SCORES enamex organization person location timex date time numex money percent Precision = 91% Recall = 87% F1 = 88.61
71 Italian Corpus from La Repubblica Training data Class Subtype N Total ENAMEX Person Organization 769 Location 1292 TIMEX Date Time 102 NUMEX Money Percent 118
72 Italian Corpus from La Repubblica Test data Class Subtype N Total ENAMEX Person Organization 129 Location 75 TIMEX Date Time 3 NUMEX Money 5 13 Percent 8
73 Results of the Italian NER! 11-fold cross validation (confidence at 99%) Basic Model +Modified Features +Accent treatment Average F ± ± ±2.5! Results on the development set 88.7 %! We acted only on improving annotation
74 Learning Curve F Number of Documents
75 Applica=ons of NER! Yellow pages with local search capabilipes! Monitoring trends and senpment in textual social media! InteracPons between genes and cells in biology and genepcs
76 Chunking! Chunking useful for entity recognition! Segment and label multi-token sequences! Each of these larger boxes is called a chunk 76

77 Chunking! The CoNLL 2000 corpus contains 270k words of Wall Street Journal text, annotated with part-ofspeech tags and chunk tags. Three chunk types in CoNLL 2000: NP chunks VP chunks PP chunks 77
78 No Path Feature available 78 From Dan Kein s CS 288 slides (UC Berkeley)
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly
 ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger
 Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Outline. Dave Barry on TTS. History of TTS. Closer to a natural vocal tract: Riesz Von Kempelen:
 Outline LSA 352: Summer 2007. Speech Recognition and Synthesis Dan Jurafsky Lecture 2: TTS: Brief History, Text Normalization and Partof-Speech Tagging IP Notice: lots of info, text, and diagrams on these
Outline LSA 352: Summer 2007. Speech Recognition and Synthesis Dan Jurafsky Lecture 2: TTS: Brief History, Text Normalization and Partof-Speech Tagging IP Notice: lots of info, text, and diagrams on these
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Grammars & Parsing, Part 1:
 Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
BULATS A2 WORDLIST 2
 BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
University of Alberta. Large-Scale Semi-Supervised Learning for Natural Language Processing. Shane Bergsma
 University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
Ch VI- SENTENCE PATTERNS.
 Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS
 Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Words come in categories
 Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Introduction to HPSG. Introduction. Historical Overview. The HPSG architecture. Signature. Linguistic Objects. Descriptions.
 to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
Basic Syntax. Doug Arnold We review some basic grammatical ideas and terminology, and look at some common constructions in English.
 Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
ARNE - A tool for Namend Entity Recognition from Arabic Text
 24 ARNE - A tool for Namend Entity Recognition from Arabic Text Carolin Shihadeh DFKI Stuhlsatzenhausweg 3 66123 Saarbrücken, Germany carolin.shihadeh@dfki.de Günter Neumann DFKI Stuhlsatzenhausweg 3 66123
24 ARNE - A tool for Namend Entity Recognition from Arabic Text Carolin Shihadeh DFKI Stuhlsatzenhausweg 3 66123 Saarbrücken, Germany carolin.shihadeh@dfki.de Günter Neumann DFKI Stuhlsatzenhausweg 3 66123
A Graph Based Authorship Identification Approach
 A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Syllable Based Word Recognition Model for Korean Noun Extraction
 are used as the most important terms (features) that express the document in NLP applications such as information retrieval, document categorization, text summarization, information extraction, and etc.
are used as the most important terms (features) that express the document in NLP applications such as information retrieval, document categorization, text summarization, information extraction, and etc.
Exploiting Wikipedia as External Knowledge for Named Entity Recognition
 Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
UNIVERSITY OF OSLO Department of Informatics. Dialog Act Recognition using Dependency Features. Master s thesis. Sindre Wetjen
 UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
An Evaluation of POS Taggers for the CHILDES Corpus
 City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
What the National Curriculum requires in reading at Y5 and Y6
 What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
Taught Throughout the Year Foundational Skills Reading Writing Language RF.1.2 Demonstrate understanding of spoken words,
 First Grade Standards These are the standards for what is taught in first grade. It is the expectation that these skills will be reinforced after they have been taught. Taught Throughout the Year Foundational
First Grade Standards These are the standards for what is taught in first grade. It is the expectation that these skills will be reinforced after they have been taught. Taught Throughout the Year Foundational
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Named Entity Recognition: A Survey for the Indian Languages
 Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Extracting Verb Expressions Implying Negative Opinions
 Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Training and evaluation of POS taggers on the French MULTITAG corpus
 Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Developing Grammar in Context
 Developing Grammar in Context intermediate with answers Mark Nettle and Diana Hopkins PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United
Developing Grammar in Context intermediate with answers Mark Nettle and Diana Hopkins PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United
LTAG-spinal and the Treebank
 LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS
 DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS Julia Tmshkina Centre for Text Techitology, North-West University, 253 Potchefstroom, South Africa 2025770@puk.ac.za
DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS Julia Tmshkina Centre for Text Techitology, North-West University, 253 Potchefstroom, South Africa 2025770@puk.ac.za
Linguistic Variation across Sports Category of Press Reportage from British Newspapers: a Diachronic Multidimensional Analysis
 International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
Today we examine the distribution of infinitival clauses, which can be
 Infinitival Clauses Today we examine the distribution of infinitival clauses, which can be a) the subject of a main clause (1) [to vote for oneself] is objectionable (2) It is objectionable to vote for
Infinitival Clauses Today we examine the distribution of infinitival clauses, which can be a) the subject of a main clause (1) [to vote for oneself] is objectionable (2) It is objectionable to vote for
Reading Grammar Section and Lesson Writing Chapter and Lesson Identify a purpose for reading W1-LO; W2- LO; W3- LO; W4- LO; W5-
 New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles
 Tagger for Malay Text Articles") A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles Rayner Alfred 1, Adam Mujat 1, and Joe Henry Obit 2 1 School of Engineering and Information Technology, Universiti Malaysia Sabah, Jalan
A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles Rayner Alfred 1, Adam Mujat 1, and Joe Henry Obit 2 1 School of Engineering and Information Technology, Universiti Malaysia Sabah, Jalan
Basic Parsing with Context-Free Grammars. Some slides adapted from Julia Hirschberg and Dan Jurafsky 1
 Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
Chapter 4: Valence & Agreement CSLI Publications
 Chapter 4: Valence & Agreement Reminder: Where We Are Simple CFG doesn t allow us to cross-classify categories, e.g., verbs can be grouped by transitivity (deny vs. disappear) or by number (deny vs. denies).
Chapter 4: Valence & Agreement Reminder: Where We Are Simple CFG doesn t allow us to cross-classify categories, e.g., verbs can be grouped by transitivity (deny vs. disappear) or by number (deny vs. denies).
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Houghton Mifflin Reading Correlation to the Common Core Standards for English Language Arts (Grade1)
") Houghton Mifflin Reading Correlation to the Standards for English Language Arts (Grade1) 8.3 JOHNNY APPLESEED Biography TARGET SKILLS: 8.3 Johnny Appleseed Phonemic Awareness Phonics Comprehension Vocabulary
Houghton Mifflin Reading Correlation to the Standards for English Language Arts (Grade1) 8.3 JOHNNY APPLESEED Biography TARGET SKILLS: 8.3 Johnny Appleseed Phonemic Awareness Phonics Comprehension Vocabulary
cmp-lg/ Jan 1998
 Identifying Discourse Markers in Spoken Dialog Peter A. Heeman and Donna Byron and James F. Allen Computer Science and Engineering Department of Computer Science Oregon Graduate Institute University of
Identifying Discourse Markers in Spoken Dialog Peter A. Heeman and Donna Byron and James F. Allen Computer Science and Engineering Department of Computer Science Oregon Graduate Institute University of
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
ELD CELDT 5 EDGE Level C Curriculum Guide LANGUAGE DEVELOPMENT VOCABULARY COMMON WRITING PROJECT. ToolKit
 Unit 1 Language Development Express Ideas and Opinions Ask for and Give Information Engage in Discussion ELD CELDT 5 EDGE Level C Curriculum Guide 20132014 Sentences Reflective Essay August 12 th September
Unit 1 Language Development Express Ideas and Opinions Ask for and Give Information Engage in Discussion ELD CELDT 5 EDGE Level C Curriculum Guide 20132014 Sentences Reflective Essay August 12 th September
Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form
 Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Specifying a shallow grammatical for parsing purposes
 Specifying a shallow grammatical for parsing purposes representation Atro Voutilainen and Timo J~irvinen Research Unit for Multilingual Language Technology P.O. Box 4 FIN-0004 University of Helsinki Finland
Specifying a shallow grammatical for parsing purposes representation Atro Voutilainen and Timo J~irvinen Research Unit for Multilingual Language Technology P.O. Box 4 FIN-0004 University of Helsinki Finland
Writing a composition
 A good composition has three elements: Writing a composition an introduction: A topic sentence which contains the main idea of the paragraph. a body : Supporting sentences that develop the main idea. a
A good composition has three elements: Writing a composition an introduction: A topic sentence which contains the main idea of the paragraph. a body : Supporting sentences that develop the main idea. a
Improving Accuracy in Word Class Tagging through the Combination of Machine Learning Systems
 Improving Accuracy in Word Class Tagging through the Combination of Machine Learning Systems Hans van Halteren* TOSCA/Language & Speech, University of Nijmegen Jakub Zavrel t Textkernel BV, University
Improving Accuracy in Word Class Tagging through the Combination of Machine Learning Systems Hans van Halteren* TOSCA/Language & Speech, University of Nijmegen Jakub Zavrel t Textkernel BV, University
Adjectives tell you more about a noun (for example: the red dress ).
.") Curriculum Jargon busters Grammar glossary Key: Words in bold are examples. Words underlined are terms you can look up in this glossary. Words in italics are important to the definition. Term Adjective
Curriculum Jargon busters Grammar glossary Key: Words in bold are examples. Words underlined are terms you can look up in this glossary. Words in italics are important to the definition. Term Adjective
Accurate Unlexicalized Parsing for Modern Hebrew
 Accurate Unlexicalized Parsing for Modern Hebrew Reut Tsarfaty and Khalil Sima an Institute for Logic, Language and Computation, University of Amsterdam Plantage Muidergracht 24, 1018TV Amsterdam, The
Accurate Unlexicalized Parsing for Modern Hebrew Reut Tsarfaty and Khalil Sima an Institute for Logic, Language and Computation, University of Amsterdam Plantage Muidergracht 24, 1018TV Amsterdam, The
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
Derivational: Inflectional: In a fit of rage the soldiers attacked them both that week, but lost the fight.
 Final Exam (120 points) Click on the yellow balloons below to see the answers I. Short Answer (32pts) 1. (6) The sentence The kinder teachers made sure that the students comprehended the testable material
Final Exam (120 points) Click on the yellow balloons below to see the answers I. Short Answer (32pts) 1. (6) The sentence The kinder teachers made sure that the students comprehended the testable material
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain
 Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Bootstrapping and Evaluating Named Entity Recognition in the Biomedical Domain Andreas Vlachos Computer Laboratory University of Cambridge Cambridge, CB3 0FD, UK av308@cl.cam.ac.uk Caroline Gasperin Computer
Part of Speech Template
 Part of Speech Template (available at www.panl10n.net/wiki/partofspeech) (If any local language font is used in this document, please provide it with the document) Please fill the template for each part
Part of Speech Template (available at www.panl10n.net/wiki/partofspeech) (If any local language font is used in this document, please provide it with the document) Please fill the template for each part
The Indiana Cooperative Remote Search Task (CReST) Corpus
 Corpus") The Indiana Cooperative Remote Search Task (CReST) Corpus Kathleen Eberhard, Hannele Nicholson, Sandra Kübler, Susan Gundersen, Matthias Scheutz University of Notre Dame Notre Dame, IN 46556, USA {eberhard.1,hnichol1,
The Indiana Cooperative Remote Search Task (CReST) Corpus Kathleen Eberhard, Hannele Nicholson, Sandra Kübler, Susan Gundersen, Matthias Scheutz University of Notre Dame Notre Dame, IN 46556, USA {eberhard.1,hnichol1,
Development of the First LRs for Macedonian: Current Projects
 Development of the First LRs for Macedonian: Current Projects Ruska Ivanovska-Naskova Faculty of Philology- University St. Cyril and Methodius Bul. Krste Petkov Misirkov bb, 1000 Skopje, Macedonia rivanovska@flf.ukim.edu.mk
Development of the First LRs for Macedonian: Current Projects Ruska Ivanovska-Naskova Faculty of Philology- University St. Cyril and Methodius Bul. Krste Petkov Misirkov bb, 1000 Skopje, Macedonia rivanovska@flf.ukim.edu.mk
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Advanced Grammar in Use
 Advanced Grammar in Use A self-study reference and practice book for advanced learners of English Third Edition with answers and CD-ROM cambridge university press cambridge, new york, melbourne, madrid,
Advanced Grammar in Use A self-study reference and practice book for advanced learners of English Third Edition with answers and CD-ROM cambridge university press cambridge, new york, melbourne, madrid,
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Introduction to Text Mining
 Prelude Overview Introduction to Text Mining Tutorial at EDBT 06 René Witte Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe, Germany http://rene-witte.net
Prelude Overview Introduction to Text Mining Tutorial at EDBT 06 René Witte Faculty of Informatics Institute for Program Structures and Data Organization (IPD) Universität Karlsruhe, Germany http://rene-witte.net
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
First Grade Curriculum Highlights: In alignment with the Common Core Standards
 First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature
 August/September Strand Topic Standard Notes Reading for Literature") 1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
The Role of the Head in the Interpretation of English Deverbal Compounds
 The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Three New Probabilistic Models. Jason M. Eisner. CIS Department, University of Pennsylvania. 200 S. 33rd St., Philadelphia, PA , USA
 Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
THE VERB ARGUMENT BROWSER
 THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
Opportunities for Writing Title Key Stage 1 Key Stage 2 Narrative
 English Teaching Cycle The English curriculum at Wardley CE Primary is based upon the National Curriculum. Our English is taught through a text based curriculum as we believe this is the best way to develop
English Teaching Cycle The English curriculum at Wardley CE Primary is based upon the National Curriculum. Our English is taught through a text based curriculum as we believe this is the best way to develop
The College Board Redesigned SAT Grade 12
 A Correlation of, 2017 To the Redesigned SAT Introduction This document demonstrates how myperspectives English Language Arts meets the Reading, Writing and Language and Essay Domains of Redesigned SAT.
A Correlation of, 2017 To the Redesigned SAT Introduction This document demonstrates how myperspectives English Language Arts meets the Reading, Writing and Language and Essay Domains of Redesigned SAT.
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language
 Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
ScienceDirect. Malayalam question answering system
 Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Grade 7. Prentice Hall. Literature, The Penguin Edition, Grade Oregon English/Language Arts Grade-Level Standards. Grade 7
 Grade 7 Prentice Hall Literature, The Penguin Edition, Grade 7 2007 C O R R E L A T E D T O Grade 7 Read or demonstrate progress toward reading at an independent and instructional reading level appropriate
Grade 7 Prentice Hall Literature, The Penguin Edition, Grade 7 2007 C O R R E L A T E D T O Grade 7 Read or demonstrate progress toward reading at an independent and instructional reading level appropriate
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization
 LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
LQVSumm: A Corpus of Linguistic Quality Violations in Multi-Document Summarization Annemarie Friedrich, Marina Valeeva and Alexis Palmer COMPUTATIONAL LINGUISTICS & PHONETICS SAARLAND UNIVERSITY, GERMANY
Emmaus Lutheran School English Language Arts Curriculum
 Emmaus Lutheran School English Language Arts Curriculum Rationale based on Scripture God is the Creator of all things, including English Language Arts. Our school is committed to providing students with
Emmaus Lutheran School English Language Arts Curriculum Rationale based on Scripture God is the Creator of all things, including English Language Arts. Our school is committed to providing students with
Construction Grammar. University of Jena.
 Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
Learning Computational Grammars
 Learning Computational Grammars John Nerbonne, Anja Belz, Nicola Cancedda, Hervé Déjean, James Hammerton, Rob Koeling, Stasinos Konstantopoulos, Miles Osborne, Franck Thollard and Erik Tjong Kim Sang Abstract
Learning Computational Grammars John Nerbonne, Anja Belz, Nicola Cancedda, Hervé Déjean, James Hammerton, Rob Koeling, Stasinos Konstantopoulos, Miles Osborne, Franck Thollard and Erik Tjong Kim Sang Abstract
4 th Grade Reading Language Arts Pacing Guide
 TN Ready Domains Foundational Skills Writing Standards to Emphasize in Various Lessons throughout the Entire Year State TN Ready Standards I Can Statement Assessment Information RF.4.3 : Know and apply
TN Ready Domains Foundational Skills Writing Standards to Emphasize in Various Lessons throughout the Entire Year State TN Ready Standards I Can Statement Assessment Information RF.4.3 : Know and apply
The Discourse Anaphoric Properties of Connectives
 The Discourse Anaphoric Properties of Connectives Cassandre Creswell, Kate Forbes, Eleni Miltsakaki, Rashmi Prasad, Aravind Joshi Λ, Bonnie Webber y Λ University of Pennsylvania 3401 Walnut Street Philadelphia,
The Discourse Anaphoric Properties of Connectives Cassandre Creswell, Kate Forbes, Eleni Miltsakaki, Rashmi Prasad, Aravind Joshi Λ, Bonnie Webber y Λ University of Pennsylvania 3401 Walnut Street Philadelphia,