POS tagging. Intro to NLP - ETHZ - 11/03/2013
|
|
|
- Tamsin Clark
- 6 years ago
- Views:
Transcription
1 POS tagging Intro to NLP - ETHZ - 11/03/2013
2 Summary Parts of speech Tagsets Part of speech tagging HMM Tagging: Most likely tag sequence Probability of an observation Parameter estimation Evaluation
3 POS ambiguity "Squad helps dog bite victim" bite -> verb? bite -> noun?
4 Parts of Speech (PoS) Traditional parts of speech: Noun, verb, adjective, preposition, adverb, article, interjection, pronoun, conjunction, etc. Called: parts-of-speech, lexical categories, word classes, morphological classes, lexical tags...
5 Examples N (noun): car, squad, dog, bite, victim V (verb): help, bite ADJ (adjective): purple, tall ADV (adverb): unfortunately, slowly P (preposition): of, by, to PRO (pronoun): I, me, mine DET (determiner): the, a, that, those
6 Open and closed classes 1. Closed class: small stable set a. Auxiliaries: may, can, will, been,... b. Prepositions: of, in, by,... c. Pronouns: I, you, she, mine, his, them,... d. Usually function words, short, grammar role 2. Open class: a. new ones are created all the time ("to google/tweet", "e-quaintance", "captcha", "cloud computing", "netbook", "webinar", "widget") b. English has 4: Nouns, Verbs, Adjectives, Adverbs c. Many languages have these 4, not all!
7 Open class words 1. Nouns: a. Proper nouns: Zurich, IBM, Albert Einstein, The Godfather,... Capitalized in many languages. b. Common nouns: the rest, also capitalized in German, mass/count nouns (goat/goats, snow/*snows) 2. Verbs: a. Morphological affixes in English: eat/eats/eaten 3. Adverbs: tend to modify things: a. John walked home extremely slowly yesterday b. Directional/locative adverbs (here, home, downhill) c. Degree adverbs (extremely, very, somewhat) d. Manner adverbs (slowly, slinkily, delicately) 4. Adjectives: qualify nouns and noun phrases
8 Closed class words 1. prepositions: on, under, over, particles: up, down, on, off, determiners: a, an, the, pronouns: she, who, I,.. 5. conjunctions: and, but, or, auxiliary verbs: can, may should, numerals: one, two, three, third,.

9 Prepositions with corpus frequencies

10 Conjunctions
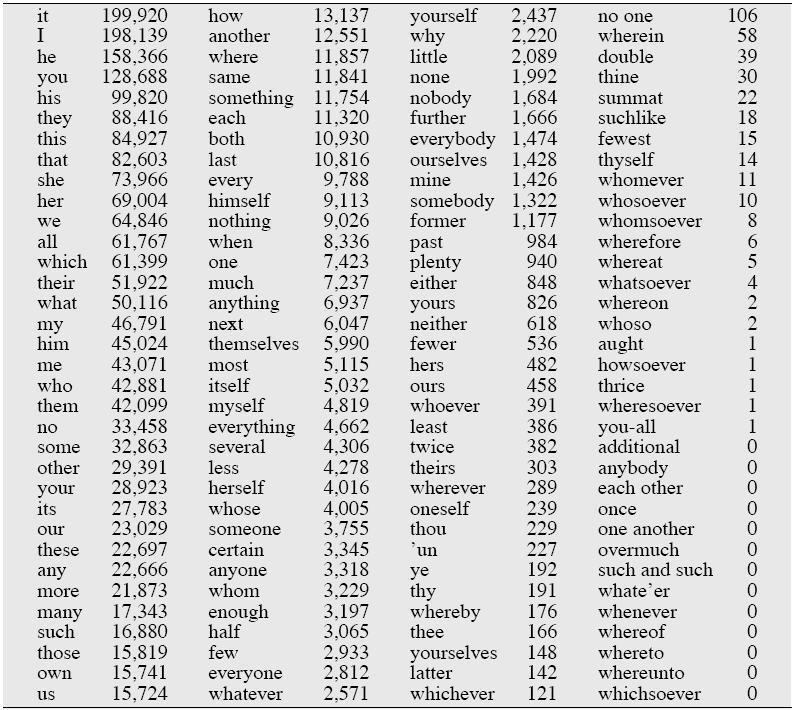
11 Pronouns
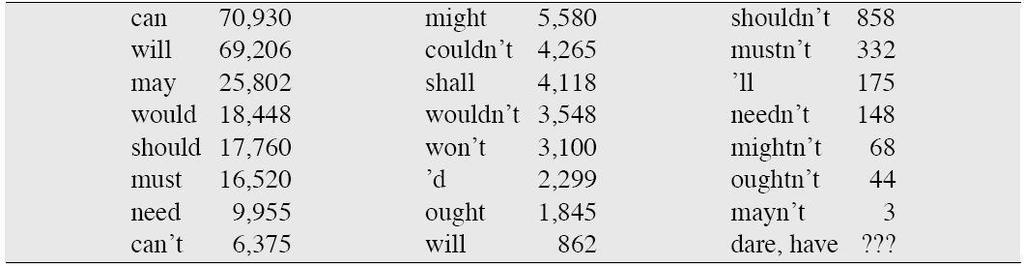
12 Auxiliaries
13 Applications A useful pre-processing step in many tasks Syntactic parsing: important source of information for syntactic analysis Machine translation Information retrieval: stemming, filtering Named entity recognition Summarization?
14 Applications Speech synthesis, for correct pronunciation of "ambiguous" words: lead /lid/ (guide) vs. /led/ (chemical) insult vs. INsult object vs. OBject overflow vs. OVERflow content vs. CONtent
15 Summarization Idea: Filter out sentences starting with certain PoS tags Use PoS statistics from gold standard titles (might need cross-validation)
16 Summarization Idea: Filter out sentences starting with certain PoS tags: Title1: "Apple introduced Siri, an intelligent personal assistant to which you can ask questions" Title2: "Especially now that a popular new feature from Apple is bound to make other phones users envious: voice control with Siri" Title3: "But Siri, Apple's personal assistant application on the iphone 4s, doesn't
17 Summarization Idea: Filter out sentences starting with certain PoS tags: Title1: "Apple introduced Siri, an intelligent personal assistant to which you can ask questions" Title2: "Especially now that a popular new feature from Apple is bound to make other phones users envious: voice control with Siri" Title3: "But Siri, Apple's personal assistant application on the iphone 4s, doesn't
18 PoS tagging The process of assigning a part-of-speech tag (label) to each word in a text. Pre-processing: tokenization Word Squad helps dog bite victim Tag N V N N N
19 Choosing a tagset 1. There are many parts of speech, potential distinctions we can draw 2. For POS tagging, we need to choose a standard set of tags to work with 3. Coarse tagsets N, V, Adj, Adv. a. A universal PoS tagset? org/wiki/part-of-speech_tagging 4. More commonly used set is finer grained, the Penn TreeBank tagset, 45 tags

20 PTB tagset
21 Examples* 1. I/PRP need/vbp a/dt flight/nn from/in Atlanta/NN 2. Does/VBZ this/dt flight/nn serve/vb dinner/nns 3. I/PRP have/vb a/dt friend/nn living/vbg in/in Denver/NNP 4. Can/VBP you/prp list/vb the/dt nonstop/jj afternoon/nn flights/nns
22 Examples* 1. I/PRP need/vbp a/dt flight/nn from/in Atlanta/NNP 2. Does/VBZ this/dt flight/nn serve/vb dinner/nns 3. I/PRP have/vb a/dt friend/nn living/vbg in/in Denver/NNP 4. Can/VBP you/prp list/vb the/dt nonstop/jj afternoon/nn flights/nns
23 Examples* 1. I/PRP need/vbp a/dt flight/nn from/in Atlanta/NNP 2. Does/VBZ this/dt flight/nn serve/vb dinner/nn 3. I/PRP have/vb a/dt friend/nn living/vbg in/in Denver/NNP 4. Can/VBP you/prp list/vb the/dt nonstop/jj afternoon/nn flights/nns
24 Examples* 1. I/PRP need/vbp a/dt flight/nn from/in Atlanta/NNP 2. Does/VBZ this/dt flight/nn serve/vb dinner/nn 3. I/PRP have/vbp a/dt friend/nn living/vbg in/in Denver/NNP 4. Can/VBP you/prp list/vb the/dt nonstop/jj afternoon/nn flights/nns
25 Examples* 1. I/PRP need/vbp a/dt flight/nn from/in Atlanta/NNP 2. Does/VBZ this/dt flight/nn serve/vb dinner/nn 3. I/PRP have/vbp a/dt friend/nn living/vbg in/in Denver/NNP 4. Can/MD you/prp list/vb the/dt nonstop/jj afternoon/nn flights/nns
26 Complexities Book/VB that/dt flight/nn./. There/EX are/vbp 70/CD children/nns there/rb./. Mrs./NNP Shaefer/NNP never/rb got/vbd around/rp to/to joining/vbg./. All/DT we/prp gotta/vbn do/vb is/vbz go/vb around/in the/dt corner/nn./. Unresolvable ambiguity: The Duchess was entertaining last night.
27 Words PoS WSJ PoS Universal The DT DET oboist NN NOUN Heinz NNP NOUN Holliger NNP NOUN has VBZ VERB taken VBN VERB a DT DET hard JJ ADJ line NN NOUN about IN ADP the DT DET problems NNS NOUN...
28 POS Tagging Words often have more than one POS: back The back door = JJ On my back = NN Win the voters back = RB Promised to back the bill = VB The POS tagging problem is to determine the POS tag for a particular instance of a word.

29 Word type tag ambiguity
30 Methods 1. Rule-based a. Start with a dictionary b. Assign all possible tags c. Write rules by hand to remove tags in context 2. Stochastic a. Supervised/Unsupervised b. Generative/discriminative c. independent/structured output d. HMMs
31 Rule-based tagging 1. Start with a dictionary: she promised to back the bill PRP VBN, VBD TO VB, JJ, RB, NN DT NN, VB
32 Rule-based tagging 2. Assign all possible tags: NN RB VBN JJ NN PRP VBD TO VB DT VB she promised to back the bill
33 Rule-based tagging 3. Introduce rules to reduce ambiguity: NN RB VBN JJ NN PRP VBD TO VB DT VB she promised to back the bill Rule: "<start> PRP {VBN, VBD}" -> "<start> PRP VBD"
34 Statistical models for POS tagging 1. A classic: one of the first successful applications of statistical methods in NLP 2. Extensively studied with all possible approaches (sequence models benchmark) 3. Simple to get started on: data, eval, literature 4. An introduction to more complex segmentation and labelling tasks: NER, shallow parsing, global optimization 5. An introduction to HMMs, used in many variants in POS tagging and related tasks.
35 Supervision and resources 1. Supervised case: data with words manually annotated with POS tags 2. Partially supervised: annotated data + unannotated data 3. Unsupervised: only raw text available 4. Resources: dictionaries with words possible tags 5. Start with the supervised task
36 HMMs HMM = (Q,O,A,B) 1. States: Q=q 1..q N [the part of speech tags] 2. Observation symbols: O = o 1..o V [words] 3. Transitions: a. A = {a ij }; a ij = P(t s =q j t s-1 =q i ) b. t s t s-1 = q i ~ Multi(a i ) c. Special vector of initial/final probabilities 4. Emissions: a. B = {b ik }; b ik = P(w s = o k t s =q i ) b. w s t s = q i ~ Multi(b i )
37 Markov Chain Interpretation Tagging process as a (hidden) Markov process Independence assumptions 1. Limited horizon 2. Time-invariant 3. Observation depends only on the state
38 Complete data likelihood The joint probability of a sequence of words and tags, given a model: Generative process: 1. generate a tag sequence 2. emit the words for each tag
39 Inference in HMMs Three fundamental problems: 1. Given an observation (e.g., a sentence) find the most likely sequence of states (e.g., pos tags) 2. Given an observation, compute its probability 3. Given a dataset of observation (sequences) estimate the model's parameters: theta = (A,B)
40 HMMs and FSA

41 HMMs and FSA also Bayes nets, directed graphical models, etc.
42 Other applications of HMMs NLP - Named entity recognition, shallow parsing - Word segmentation - Optical Character Recognition Speech recognition Computer Vision image segmentation Biology - Protein structure prediction Economics, Climatology, Robotics...
43 POS as sequence classification Observation: a sequence of N words w 1:N Response: a sequence of N tags t 1:N Task: find the predicted t' 1:N such that: The best possible tagging for the sequence.
44 Bayes rule reformulation
45 HMM POS tagging How can we find t' 1:N? Enumeration of all possible sequences?
46 HMM POS tagging How can we find t' 1:N? Enumeration of all possible sequences? O( Tagset N )! Dynamic programming: Viterbi algorithm
47 Viterbi algorithm
48 Example: model A = N V END V N START B = board backs plan V N
49 Example: observation Sentence: "Board backs plan" Find the most likely tag sequence d s (t) = probability of most likely path ending at state s at time t
50 Viterbi algorithm: example END V N START board backs plan Time 1 2 3
51 Viterbi: forward pass END V N START board backs plan Time 1 2 3
52 Viterbi: forward pass END V d=.12 N START d=.24 board backs plan Time 1 2 3
53 Viterbi: forward pass END V d=.12 N START d=.24 board backs plan Time 1 2 3
54 Viterbi: forward pass END V d=.12 d=.050 N START d=.24 d=.019 board backs plan Time 1 2 3
55 Viterbi: forward pass END V d=.12 d=.050 N START d=.24 d=.019 board backs plan Time 1 2 3
56 Viterbi: forward pass END V d=.12 d=.050 d=.005 N START d=.24 d=.019 d=.016 board backs plan Time 1 2 3
57 Viterbi: forward pass END V d=.12 d=.050 d=.005 N START d=.24 d=.019 d=.016 board backs plan Time 1 2 3
58 Viterbi: forward pass END V d=.12 d=.050 d=.005 d=.011 N START d=.24 d=.019 d=.016 board backs plan Time 1 2 3
59 Viterbi: backtrack END V d=.12 d=.050 d=.005 d=.011 N START d=.24 d=.019 d=.016 board backs plan Time 1 2 3
60 Viterbi: backtrack END V d=.12 d=.050 d=.005 d=.011 N START d=.24 d=.019 d=.016 board backs plan Time 1 2 3
61 Viterbi: backtrack END V d=.12 d=.050 d=.005 d=.011 N START d=.24 d=.019 d=.016 board backs plan Time 1 2 3
62 Viterbi: output END V d=.011 N START board/n backs/v plan/n Time 1 2 3
63 Observation probability Given HMM theta = (A,B) and observation sequence w 1:N compute P(w 1:N theta) Applications: language modeling Complete data likelihood: Sum over all possible tag sequences:
64 Forward algorithm Dynamic programming: each state of the trellis stores a value alpha i (s) = probability of being in state s having observed w 1:i Sum over all paths up to i-1 leading to s Init:
65 Forward algorithm
66 Forward computation END V a=.12 N START a=.24 board backs plan Time 1 2 3
67 Forward computation END V a=.12 a=.058 N START a=.24 a=.034 board backs plan Time 1 2 3
68 Forward computation END V a=.12 a=.058 a=.014 N START a=.24 a=.034 a=.022 board backs plan Time 1 2 3
69 Forward computation END V a=.12 a=.058 a=.014 a=0.2 N START a=.24 a=.034 a=.022 board backs plan Time 1 2 3
70 Parameter estimation Maximum likelihood estimates (MLE) on data 1. Transition probabilities: 2. Emission probabilities:
71 Implementation details 1. Start/End states 2. Log space/rescaling 3. Vocabularies: model pruning 4. Higher order models: a. states representation b. Estimation and sparsity: deleted interpolation
72 Evaluation So once you have you POS tagger running how do you evaluate it? 1. Overall error rate with respect to a goldstandard test set. a. ER = # words incorrectly tagged/# words tagged 2. Error rates on particular tags (and pairs) 3. Error rates on particular words (especially unknown words)
73 Evaluation The result is compared with a manually coded Gold Standard Typically accuracy > 97% on WSJ PTB This may be compared with result for a baseline tagger (one that uses no context). Baselines (most frequent tag) can achieve up to 90% accuracy. Important: 100% is impossible even for human annotators.
74 Summary Parts of speech Tagsets Part of speech tagging HMM Tagging: Most likely tag sequence (decoding) Probability of an observation (word sequence) Parameter estimation (supervised) Evaluation
75 Next class Unsupervised POS tagging models (HMMs) Parameter estimation: forward-backward algorithm Discriminative sequence models: MaxEnt, CRF, Perceptron, SVM, etc. Read J&M 5-6 Pre-process and POS tag the data: report problems & baselines
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly
 ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Context Free Grammars. Many slides from Michael Collins
 Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Context Free Grammars Many slides from Michael Collins Overview I An introduction to the parsing problem I Context free grammars I A brief(!) sketch of the syntax of English I Examples of ambiguous structures
Grammars & Parsing, Part 1:
 Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
Grammars & Parsing, Part 1: Rules, representations, and transformations- oh my! Sentence VP The teacher Verb gave the lecture 2015-02-12 CS 562/662: Natural Language Processing Game plan for today: Review
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger
 Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
Page 1 of 35 Heuristic Sample Selection to Minimize Reference Standard Training Set for a Part-Of-Speech Tagger Kaihong Liu, MD, MS, Wendy Chapman, PhD, Rebecca Hwa, PhD, and Rebecca S. Crowley, MD, MS
A Graph Based Authorship Identification Approach
 A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
BULATS A2 WORDLIST 2
 BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
BULATS A2 WORDLIST 2 INTRODUCTION TO THE BULATS A2 WORDLIST 2 The BULATS A2 WORDLIST 21 is a list of approximately 750 words to help candidates aiming at an A2 pass in the Cambridge BULATS exam. It is
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
University of Alberta. Large-Scale Semi-Supervised Learning for Natural Language Processing. Shane Bergsma
 University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS
 Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
Daffodil International University Institutional Repository DIU Journal of Science and Technology Volume 8, Issue 1, January 2013 2013-01 BANGLA TO ENGLISH TEXT CONVERSION USING OPENNLP TOOLS Uddin, Sk.
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
Outline. Dave Barry on TTS. History of TTS. Closer to a natural vocal tract: Riesz Von Kempelen:
 Outline LSA 352: Summer 2007. Speech Recognition and Synthesis Dan Jurafsky Lecture 2: TTS: Brief History, Text Normalization and Partof-Speech Tagging IP Notice: lots of info, text, and diagrams on these
Outline LSA 352: Summer 2007. Speech Recognition and Synthesis Dan Jurafsky Lecture 2: TTS: Brief History, Text Normalization and Partof-Speech Tagging IP Notice: lots of info, text, and diagrams on these
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
LTAG-spinal and the Treebank
 LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
LTAG-spinal and the Treebank a new resource for incremental, dependency and semantic parsing Libin Shen (lshen@bbn.com) BBN Technologies, 10 Moulton Street, Cambridge, MA 02138, USA Lucas Champollion (champoll@ling.upenn.edu)
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
Training and evaluation of POS taggers on the French MULTITAG corpus
 Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
Training and evaluation of POS taggers on the French MULTITAG corpus A. Allauzen, H. Bonneau-Maynard LIMSI/CNRS; Univ Paris-Sud, Orsay, F-91405 {allauzen,maynard}@limsi.fr Abstract The explicit introduction
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
Words come in categories
 Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
Nouns Words come in categories D: A grammatical category is a class of expressions which share a common set of grammatical properties (a.k.a. word class or part of speech). Words come in categories Open
An Evaluation of POS Taggers for the CHILDES Corpus
 City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
City University of New York (CUNY) CUNY Academic Works Dissertations, Theses, and Capstone Projects Graduate Center 9-30-2016 An Evaluation of POS Taggers for the CHILDES Corpus Rui Huang The Graduate
Basic Parsing with Context-Free Grammars. Some slides adapted from Julia Hirschberg and Dan Jurafsky 1
 Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Semi-supervised Training for the Averaged Perceptron POS Tagger
 Semi-supervised Training for the Averaged Perceptron POS Tagger Drahomíra johanka Spoustová Jan Hajič Jan Raab Miroslav Spousta Institute of Formal and Applied Linguistics Faculty of Mathematics and Physics,
Semi-supervised Training for the Averaged Perceptron POS Tagger Drahomíra johanka Spoustová Jan Hajič Jan Raab Miroslav Spousta Institute of Formal and Applied Linguistics Faculty of Mathematics and Physics,
Ch VI- SENTENCE PATTERNS.
 Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
Ch VI- SENTENCE PATTERNS faizrisd@gmail.com www.pakfaizal.com It is a common fact that in the making of well-formed sentences we badly need several syntactic devices used to link together words by means
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Natural Language Processing: Interpretation, Reasoning and Machine Learning
 Natural Language Processing: Interpretation, Reasoning and Machine Learning Roberto Basili (Università di Roma, Tor Vergata) dblp: http://dblp.uni-trier.de/pers/hd/b/basili:roberto.html Google scholar:
Natural Language Processing: Interpretation, Reasoning and Machine Learning Roberto Basili (Università di Roma, Tor Vergata) dblp: http://dblp.uni-trier.de/pers/hd/b/basili:roberto.html Google scholar:
UNIVERSITY OF OSLO Department of Informatics. Dialog Act Recognition using Dependency Features. Master s thesis. Sindre Wetjen
 UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
UNIVERSITY OF OSLO Department of Informatics Dialog Act Recognition using Dependency Features Master s thesis Sindre Wetjen November 15, 2013 Acknowledgments First I want to thank my supervisors Lilja
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Specifying a shallow grammatical for parsing purposes
 Specifying a shallow grammatical for parsing purposes representation Atro Voutilainen and Timo J~irvinen Research Unit for Multilingual Language Technology P.O. Box 4 FIN-0004 University of Helsinki Finland
Specifying a shallow grammatical for parsing purposes representation Atro Voutilainen and Timo J~irvinen Research Unit for Multilingual Language Technology P.O. Box 4 FIN-0004 University of Helsinki Finland
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Named Entity Recognition: A Survey for the Indian Languages
 Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Exploiting Wikipedia as External Knowledge for Named Entity Recognition
 Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
Exploiting Wikipedia as External Knowledge for Named Entity Recognition Jun ichi Kazama and Kentaro Torisawa Japan Advanced Institute of Science and Technology (JAIST) Asahidai 1-1, Nomi, Ishikawa, 923-1292
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Houghton Mifflin Reading Correlation to the Common Core Standards for English Language Arts (Grade1)
") Houghton Mifflin Reading Correlation to the Standards for English Language Arts (Grade1) 8.3 JOHNNY APPLESEED Biography TARGET SKILLS: 8.3 Johnny Appleseed Phonemic Awareness Phonics Comprehension Vocabulary
Houghton Mifflin Reading Correlation to the Standards for English Language Arts (Grade1) 8.3 JOHNNY APPLESEED Biography TARGET SKILLS: 8.3 Johnny Appleseed Phonemic Awareness Phonics Comprehension Vocabulary
Developing Grammar in Context
 Developing Grammar in Context intermediate with answers Mark Nettle and Diana Hopkins PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United
Developing Grammar in Context intermediate with answers Mark Nettle and Diana Hopkins PUBLISHED BY THE PRESS SYNDICATE OF THE UNIVERSITY OF CAMBRIDGE The Pitt Building, Trumpington Street, Cambridge, United
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Loughton School s curriculum evening. 28 th February 2017
 Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Extracting Verb Expressions Implying Negative Opinions
 Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
California Department of Education English Language Development Standards for Grade 8
 Section 1: Goal, Critical Principles, and Overview Goal: English learners read, analyze, interpret, and create a variety of literary and informational text types. They develop an understanding of how language
Section 1: Goal, Critical Principles, and Overview Goal: English learners read, analyze, interpret, and create a variety of literary and informational text types. They develop an understanding of how language
1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature
 August/September Strand Topic Standard Notes Reading for Literature") 1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
The Role of the Head in the Interpretation of English Deverbal Compounds
 The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles
 Tagger for Malay Text Articles") A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles Rayner Alfred 1, Adam Mujat 1, and Joe Henry Obit 2 1 School of Engineering and Information Technology, Universiti Malaysia Sabah, Jalan
A Ruled-Based Part of Speech (RPOS) Tagger for Malay Text Articles Rayner Alfred 1, Adam Mujat 1, and Joe Henry Obit 2 1 School of Engineering and Information Technology, Universiti Malaysia Sabah, Jalan
Linguistic Variation across Sports Category of Press Reportage from British Newspapers: a Diachronic Multidimensional Analysis
 International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
International Journal of Arts Humanities and Social Sciences (IJAHSS) Volume 1 Issue 1 ǁ August 216. www.ijahss.com Linguistic Variation across Sports Category of Press Reportage from British Newspapers:
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Three New Probabilistic Models. Jason M. Eisner. CIS Department, University of Pennsylvania. 200 S. 33rd St., Philadelphia, PA , USA
 Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
Three New Probabilistic Models for Dependency Parsing: An Exploration Jason M. Eisner CIS Department, University of Pennsylvania 200 S. 33rd St., Philadelphia, PA 19104-6389, USA jeisner@linc.cis.upenn.edu
Writing a composition
 A good composition has three elements: Writing a composition an introduction: A topic sentence which contains the main idea of the paragraph. a body : Supporting sentences that develop the main idea. a
A good composition has three elements: Writing a composition an introduction: A topic sentence which contains the main idea of the paragraph. a body : Supporting sentences that develop the main idea. a
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
! # %& ( ) ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &,
 ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &,") ! # %& ( ) ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &, 4 The Interaction of Knowledge Sources in Word Sense Disambiguation Mark Stevenson Yorick Wilks University of Shef eld University of Shef eld Word sense
! # %& ( ) ( + ) ( &, % &. / 0!!1 2/.&, 3 ( & 2/ &, 4 The Interaction of Knowledge Sources in Word Sense Disambiguation Mark Stevenson Yorick Wilks University of Shef eld University of Shef eld Word sense
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Reading Grammar Section and Lesson Writing Chapter and Lesson Identify a purpose for reading W1-LO; W2- LO; W3- LO; W4- LO; W5-
 New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
New York Grade 7 Core Performance Indicators Grades 7 8: common to all four ELA standards Throughout grades 7 and 8, students demonstrate the following core performance indicators in the key ideas of reading,
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels
 Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
First Grade Curriculum Highlights: In alignment with the Common Core Standards
 First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
First Grade Curriculum Highlights: In alignment with the Common Core Standards ENGLISH LANGUAGE ARTS Foundational Skills Print Concepts Demonstrate understanding of the organization and basic features
Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form
 Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Orthographic Form 1 Improved Effects of Word-Retrieval Treatments Subsequent to Addition of the Orthographic Form The development and testing of word-retrieval treatments for aphasia has generally focused
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
What the National Curriculum requires in reading at Y5 and Y6
 What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
Taught Throughout the Year Foundational Skills Reading Writing Language RF.1.2 Demonstrate understanding of spoken words,
 First Grade Standards These are the standards for what is taught in first grade. It is the expectation that these skills will be reinforced after they have been taught. Taught Throughout the Year Foundational
First Grade Standards These are the standards for what is taught in first grade. It is the expectation that these skills will be reinforced after they have been taught. Taught Throughout the Year Foundational
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
THE VERB ARGUMENT BROWSER
 THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
THE VERB ARGUMENT BROWSER Bálint Sass sass.balint@itk.ppke.hu Péter Pázmány Catholic University, Budapest, Hungary 11 th International Conference on Text, Speech and Dialog 8-12 September 2008, Brno PREVIEW
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language
 Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Basic Syntax. Doug Arnold We review some basic grammatical ideas and terminology, and look at some common constructions in English.
 Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
Basic Syntax Doug Arnold doug@essex.ac.uk We review some basic grammatical ideas and terminology, and look at some common constructions in English. 1 Categories 1.1 Word level (lexical and functional)
a) analyse sentences, so you know what s going on and how to use that information to help you find the answer.
 analyse sentences, so you know what s going on and how to use that information to help you find the answer.") Tip Sheet I m going to show you how to deal with ten of the most typical aspects of English grammar that are tested on the CAE Use of English paper, part 4. Of course, there are many other grammar points
Tip Sheet I m going to show you how to deal with ten of the most typical aspects of English grammar that are tested on the CAE Use of English paper, part 4. Of course, there are many other grammar points
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
The Indiana Cooperative Remote Search Task (CReST) Corpus
 Corpus") The Indiana Cooperative Remote Search Task (CReST) Corpus Kathleen Eberhard, Hannele Nicholson, Sandra Kübler, Susan Gundersen, Matthias Scheutz University of Notre Dame Notre Dame, IN 46556, USA {eberhard.1,hnichol1,
The Indiana Cooperative Remote Search Task (CReST) Corpus Kathleen Eberhard, Hannele Nicholson, Sandra Kübler, Susan Gundersen, Matthias Scheutz University of Notre Dame Notre Dame, IN 46556, USA {eberhard.1,hnichol1,
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Today we examine the distribution of infinitival clauses, which can be
 Infinitival Clauses Today we examine the distribution of infinitival clauses, which can be a) the subject of a main clause (1) [to vote for oneself] is objectionable (2) It is objectionable to vote for
Infinitival Clauses Today we examine the distribution of infinitival clauses, which can be a) the subject of a main clause (1) [to vote for oneself] is objectionable (2) It is objectionable to vote for
Grade 7. Prentice Hall. Literature, The Penguin Edition, Grade Oregon English/Language Arts Grade-Level Standards. Grade 7
 Grade 7 Prentice Hall Literature, The Penguin Edition, Grade 7 2007 C O R R E L A T E D T O Grade 7 Read or demonstrate progress toward reading at an independent and instructional reading level appropriate
Grade 7 Prentice Hall Literature, The Penguin Edition, Grade 7 2007 C O R R E L A T E D T O Grade 7 Read or demonstrate progress toward reading at an independent and instructional reading level appropriate
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
A Syllable Based Word Recognition Model for Korean Noun Extraction
 are used as the most important terms (features) that express the document in NLP applications such as information retrieval, document categorization, text summarization, information extraction, and etc.
are used as the most important terms (features) that express the document in NLP applications such as information retrieval, document categorization, text summarization, information extraction, and etc.