Ed nburgh University of Edinburgh NLP. Understanding Visual Scences. Dependency Graphs, Word Senses, and Multimodal Embeddings
|
|
|
- Rudolph Barry Chambers
- 6 years ago
- Views:
Transcription
1 Understanding Visual Scences Dependency Graphs, Word Senses, and Multimodal Embeddings Mirella Lapata School of Informatics University of Edinburgh Ed nburgh University of Edinburgh NLP Natural Language Processing Mirella Lapata Understanding Visual Scenes 1



2 Joint Work with Representing Visual Structure Carina Silberer Spandana Gella Frank Keller Jasper Uijilings Mirella Lapata Understanding Visual Scenes 2
3 Structure in Multimodal Processing Lots of recent in work on multimodal processing: image description generation; visual question answering; multimodal machine translation; video summarization. Mirella Lapata Understanding Visual Scenes 3
4 Structure in Multimodal Processing Lots of recent in work on multimodal processing: image description generation; visual question answering; multimodal machine translation; video summarization. We need to understand the meaning of images and text: Who does what to whom? Mirella Lapata Understanding Visual Scenes 3
5 Structure in Multimodal Processing Lots of recent in work on multimodal processing: image description generation; visual question answering; multimodal machine translation; video summarization. We need to understand the meaning of images and text: Who does what to whom? Understanding requires structure, not just an unordered set of labels: linguistic structure; image structure. Mirella Lapata Understanding Visual Scenes 3
6 Structure in Multimodal Processing A man is playing a trumpet in front of a little boy. Mirella Lapata Understanding Visual Scenes 4
: http://nlp.stanford.")
7 Linguistic Structure Representing Visual Structure Output of dependency parser (with PoS labels): Mirella Lapata Understanding Visual Scenes 5
: http://cogcomp.cs.illinois.")
8 Linguistic Structure Representing Visual Structure Output of a semantic role labeler (with word senses): Mirella Lapata Understanding Visual Scenes 6
9 Structure in Multimodal Processing Linguistic structure: discrete base units (words), ordered in 1D; span-based labels (e.g., PoS, phrases); tree-based hierarchies; clear distinction between syntax and semantics; canonical representations defined by linguistic theory. Mirella Lapata Understanding Visual Scenes 7
10 Structure in Multimodal Processing Linguistic structure: discrete base units (words), ordered in 1D; span-based labels (e.g., PoS, phrases); tree-based hierarchies; clear distinction between syntax and semantics; canonical representations defined by linguistic theory. Now let s compare this to image structure. Mirella Lapata Understanding Visual Scenes 7
11 Image Structure Representing Visual Structure Output of an image labeler: We could also label: attributes, scene type, colors, textures, etc. Mirella Lapata Understanding Visual Scenes 8

12 Image Structure Representing Visual Structure Output of an object recognizer: Output of FastRCNN model with AlexNet architecture trained on PASCAL VOC Mirella Lapata Understanding Visual Scenes 9

13 Image Structure Representing Visual Structure Hierarchical segmentation (indicates part-whole relationships): Mirella Lapata Understanding Visual Scenes 10
14 Structure in Multimodal Processing Linguistic structure: discrete base units (words), ordered in 1D; span-based labels (e.g., PoS, phrases); tree-based hierarchies; clear distinction between syntax and semantics; canonical representations defined by linguistic theory. Mirella Lapata Understanding Visual Scenes 11
15 Structure in Multimodal Processing Linguistic structure: discrete base units (words), ordered in 1D; span-based labels (e.g., PoS, phrases); tree-based hierarchies; clear distinction between syntax and semantics; canonical representations defined by linguistic theory. Image structure: continuous base units (pixels), ordered in 2D; region-based labels (e.g., objects, attributes); part whole structure; no clear distinction between syntax and semantics; no correct canonical representations. Mirella Lapata Understanding Visual Scenes 11
16 Representational Divergence Representational divergence: for multimodal processing, we need to fuse linguistic and image structures, but they are very different. Mirella Lapata Understanding Visual Scenes 12
17 Representational Divergence Representational divergence: for multimodal processing, we need to fuse linguistic and image structures, but they are very different. Hypothesis: We need to align visual representations. Two examples in this talk: visual dependency representations; visual sense disambiguation. Mirella Lapata Understanding Visual Scenes 12
18 1 Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications 2 Task Definition Dataset Construction 3 Mirella Lapata Understanding Visual Scenes 13
19 Visual Dependency Representations Visual Constituency Representations Applications 1 Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications 2 Task Definition Dataset Construction 3 Mirella Lapata Understanding Visual Scenes 14
20 Spatial Relations Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications We need a grammar that defines the relations between the objects in an image: Visual Dependency Grammar (Elliott & Keller 2013). It assumes eight relations that can hold between pairs of objects, based on three geometric properties: pixel overlap; angle between objects; distance between objects. Mirella Lapata Understanding Visual Scenes 15




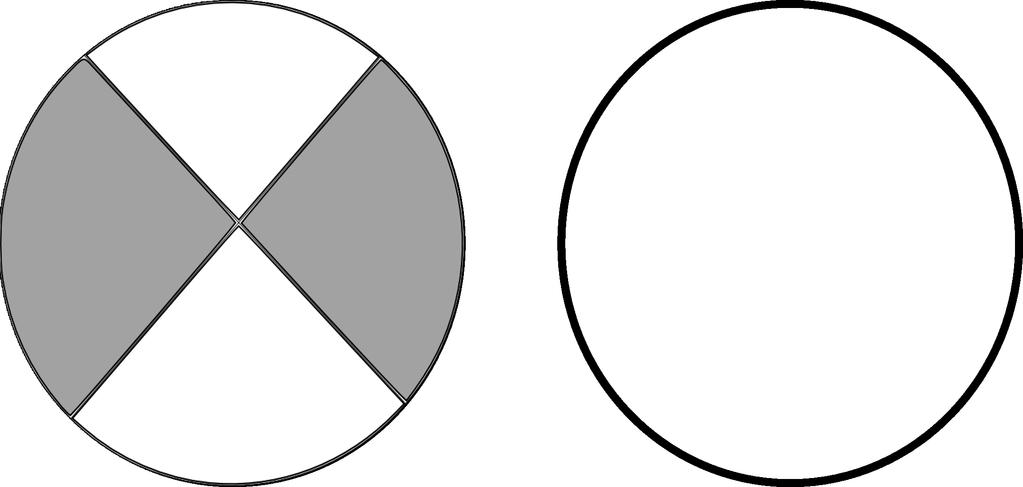
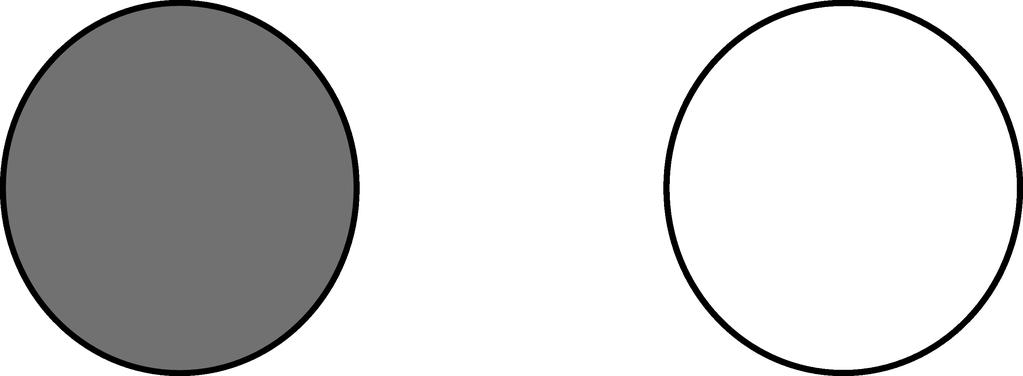

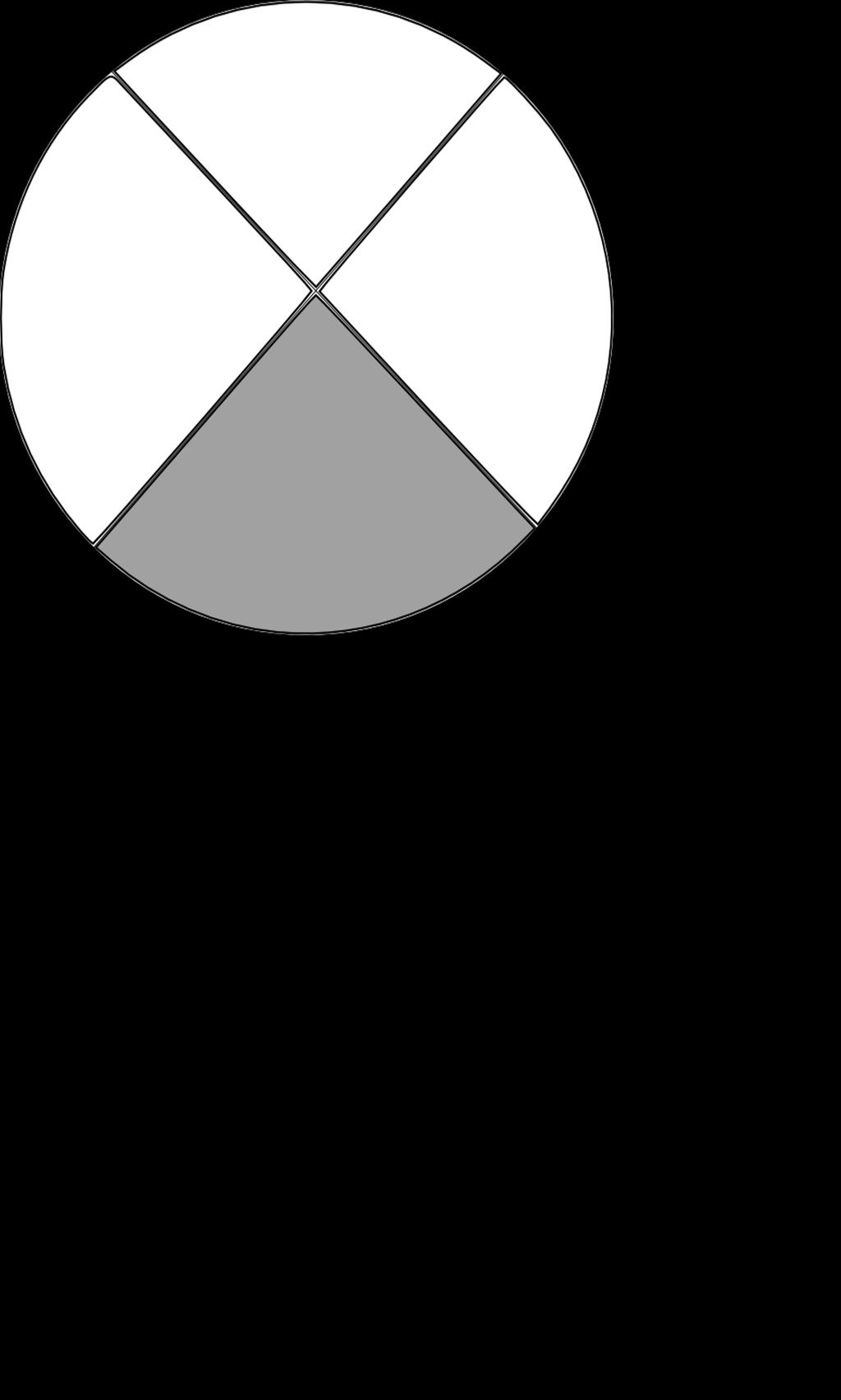



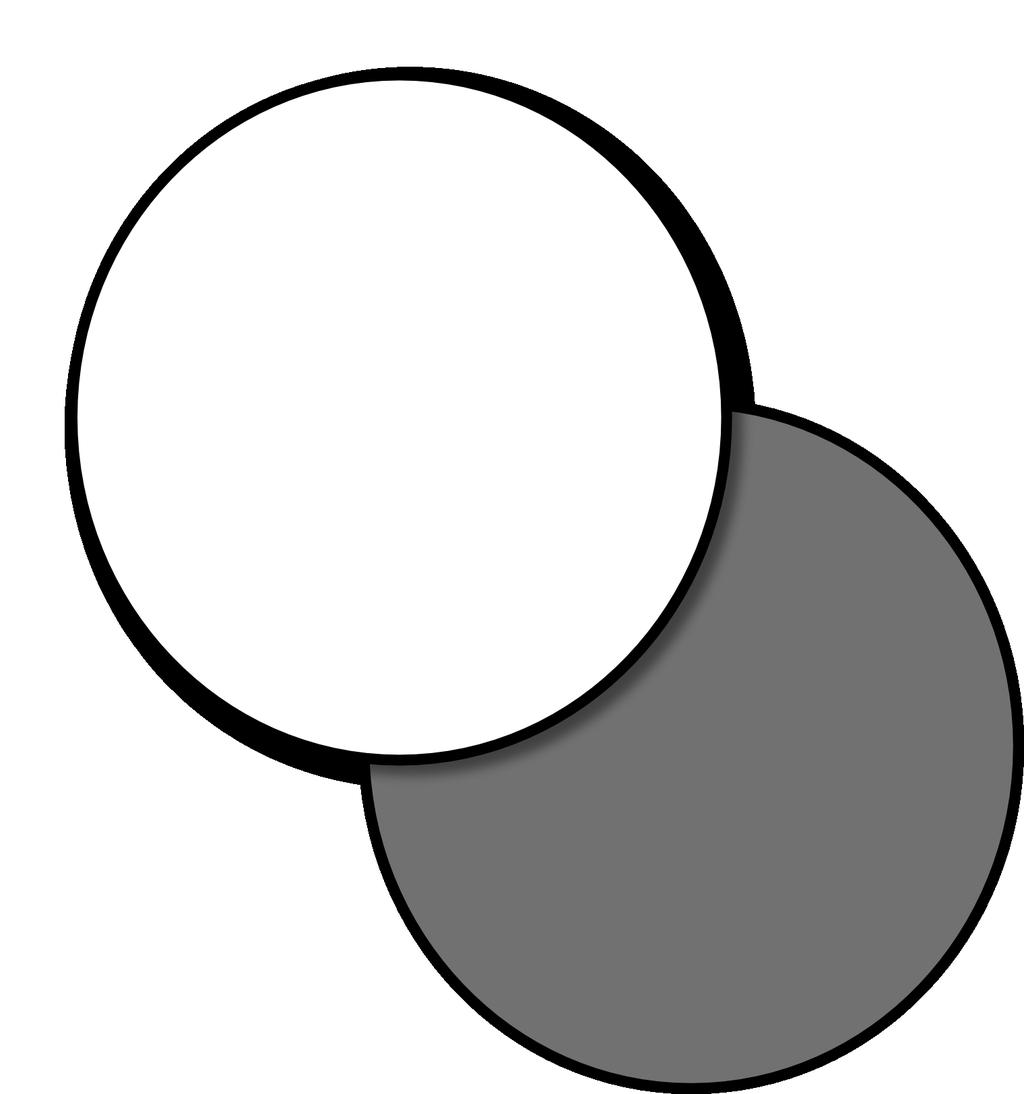

21 Spatial Relations Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications X on Y X surrounds Y X beside Y X opposite Y X above Y X below Y X infront Y X behind Y Mirella Lapata Understanding Visual Scenes 16
22 Visual Tuples Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications An image represented a bag of VDR tuples (Ortiz et al., 2015). person close person person on_beside d_table d_table surrounds cake person near cake person close d_table person above_close cake Mirella Lapata Understanding Visual Scenes 17
23 Visual Dependency Representations Visual Dependency Representations Visual Constituency Representations Applications An image is represented as a dependency tree (Silberer et al., 2017). root on_beside close surrounds person person d_table cake Mirella Lapata Understanding Visual Scenes 18
24 Visual Constituency Representations Visual Dependency Representations Visual Constituency Representations Applications An image is represented as a constituency tree (Silberer et al., 2017). NP NP SR NP SR R NP R NP NP SR R NP close on_beside surrounds person person d_table cake Mirella Lapata Understanding Visual Scenes 19
25 Tree Construction Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications tv d 12 person d 24 bottle d d Build a fully connected graph with all objects as nodes; edge weights correspond to spatial distance; pizza minimum spanning tree (MST): visual dependency representation; use grammar to generate visual constituency representation. table Mirella Lapata Understanding Visual Scenes 20 82
26 Tree Construction Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications root on_beside below_close pizza d_table person Build a fully connected graph with all objects as nodes; edge weights correspond to spatial distance; minimum spanning tree (MST): visual dependency representation; use grammar to generate visual constituency representation. Mirella Lapata Understanding Visual Scenes 20
: visual dependency representation; use grammar to generate visual")
27 Tree Construction Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications NP NP SR NP SR R NP R NP on_beside below_close pizza d_table person Build a fully connected graph with all objects as nodes; edge weights correspond to spatial distance; minimum spanning tree (MST): visual dependency representation; use grammar to generate visual constituency representation. Mirella Lapata Understanding Visual Scenes 20
28 Visual Dependency Representations Visual Constituency Representations Applications Image Description Generation via Machine Translation Repurpose existing NLP technology to construct visual representations; use machine translation models: focus on tree-to-string translation; Mirella Lapata Understanding Visual Scenes 21
29 Visual Dependency Representations Visual Constituency Representations Applications Image Description Generation via Machine Translation Repurpose existing NLP technology to construct visual representations; use machine translation models: focus on tree-to-string translation; trees are task-independent, do not take descriptions into account: Mirella Lapata Understanding Visual Scenes 21
30 Visual Dependency Representations Visual Constituency Representations Applications Image Description Generation via Machine Translation Repurpose existing NLP technology to construct visual representations; use machine translation models: focus on tree-to-string translation; trees are task-independent, do not take descriptions into account: create parallel corpus of trees with multiple descriptions; Mirella Lapata Understanding Visual Scenes 21
31 Visual Dependency Representations Visual Constituency Representations Applications Image Description Generation via Machine Translation Repurpose existing NLP technology to construct visual representations; use machine translation models: focus on tree-to-string translation; trees are task-independent, do not take descriptions into account: create parallel corpus of trees with multiple descriptions; translation is loose: not all visual objects are verbalized; multiple descriptions can focus different aspects of a scene: Mirella Lapata Understanding Visual Scenes 21
32 Visual Dependency Representations Visual Constituency Representations Applications Image Description Generation via Machine Translation Repurpose existing NLP technology to construct visual representations; use machine translation models: focus on tree-to-string translation; trees are task-independent, do not take descriptions into account: create parallel corpus of trees with multiple descriptions; translation is loose: not all visual objects are verbalized; multiple descriptions can focus different aspects of a scene: generation model performs content selection. Mirella Lapata Understanding Visual Scenes 21
33 Parallel Corpus Creation Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications Step 1: Grounding objects to linguistic expressions. person d_table person cake plate cup Little kids sitting around a table that has a birthday cake on it. A group of young children standing around a cake. Mirella Lapata Understanding Visual Scenes 22
34 Parallel Corpus Creation Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications Step 1: Grounding objects to linguistic expressions. person d_table person cake plate cup [Little kids] A1 sitting sit.01 [around a table] A2 that has has.01 [a birthday cake] A2 on it. [A group of young children] A1 standing stand.01 [around a cake] A2. Mirella Lapata Understanding Visual Scenes 23
35 Parallel Corpus Creation Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications Step 1: Grounding objects to linguistic expressions. person d_table person cake plate cup [Little kids] A1 sitting sit.01 [around a table] A2 that has has.01 [a birthday cake] A2 on it. [A group of young children] A1 standing stand.01 [around a cake] A2. Mirella Lapata Understanding Visual Scenes 24
36 Parallel Corpus Creation Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications Step 2: Render scenes as trees and generate corpus. root on_beside close surrounds person person d_table cake Kids sitting around a table. root on_beside close surrounds person person d_table cake A table that has a birthday cake. root on_beside close surrounds person person d_table cake Children standing around a cake. Mirella Lapata Understanding Visual Scenes 25
37 MT Model: Surface Realization Visual Dependency Representations Visual Constituency Representations Applications We train a translation model on our parallel corpus using the MT framework implemented in Moses (Koehn et al., 2007): t = arg max P(t s) t ( K ) P(t s) = arg max λ k h k (d) d k=1 d D(s, t) are derivations in a synchronous grammar; h k feature functions (language model, translation table, word penalty model); constants λ k scale different models, tuned during training. Mirella Lapata Understanding Visual Scenes 26
38 MT Model: Content Selection Visual Dependency Representations Visual Constituency Representations Applications At test time we must decide which objects to talk about: predict whether a detected object is relevant for scene; we use logistic regression with l 2 regularization; trained on positive and negative instances; positives: objects aligned to SRL arguments; negatives: unaligned objects; features: object detection score, relative size, relative distance between two objects, object occurrences, spatial features. Mirella Lapata Understanding Visual Scenes 27

39 Query-by-Example Image Retrieval Visual Dependency Representations Visual Constituency Representations Applications Mirella Lapata Understanding Visual Scenes 28
40 Query-by-Example Image Retrieval Visual Dependency Representations Visual Constituency Representations Applications Let I denote an image collection; for every image q produce a ranking in order of similarity to q; subtree kernels measure similarity of constituent trees; partial tree kernels measure similarly of dependency trees. NP NP SR R NP on_beside pizza d_table SR R NP on_beside d_table SR R NP on_beside d_table on_beside below_close on_beside on_beside pizza d_table personpizza d_table person pizza d_table Mirella Lapata Understanding Visual Scenes 29
41 Results: Image Description Generation CIDEr (%) Visual Dependency Representations Visual Constituency Representations Applications Template Bag-of-Objects Tuples Constituency Dependency NeuralTalk 10 0 COCO 2015 Test Set Mirella Lapata Understanding Visual Scenes 30
42 Results: Image Retrieval Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications Macro-averaged precision Bag-of-Objects Tuples Constituency Dependency NeuralTalk P@1 P@5 P@10 Mirella Lapata Understanding Visual Scenes 31
 a couch has a couch 4) the room has a couch 1) a dog sitting on a couch 2) dog")
 a airplane parked next to a car 1) a large plane with a red tail Mirella Lapata Understanding Visual")
43 Example Output Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications Template Tuples Dependency Constituency Human 5) a couch has a couch 4) the room has a couch 1) a dog sitting on a couch 2) dog laying on a couch 3) a dog is looking at something 2) an airplane is near a car 5) a airplane sitting on a street 3) a airplane parked next to a car 4) a airplane parked next to a car 1) a large plane with a red tail Mirella Lapata Understanding Visual Scenes 32
44 Task Definition Dataset Construction 1 Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications 2 Task Definition Dataset Construction 3 Mirella Lapata Understanding Visual Scenes 33
45 Aligning Actions and Verbs Task Definition Dataset Construction So far, we have looked at syntactic structure only: how do the objects in an image relate to each other. To really understand the content of an image, we need semantics: represent the event depicted, its participants, and the roles they play. We can achieve this using verb senses: well established in linguistics (e.g., WordNet); more general that the action labels used in computer vision; can be aligned with both sentences and images. Mirella Lapata Understanding Visual Scenes 34
46 Word Sense Disambiguation Task Definition Dataset Construction Word sense disambiguation is a standard NLP task: (1) A man is playing a guitar. (2) The children are playing across the street. (3) Two men playing doubles tennis on a grass court. Mirella Lapata Understanding Visual Scenes 35
47 Word Sense Disambiguation Task Definition Dataset Construction Word sense disambiguation is a standard NLP task: (1) A man is playing a guitar. play:1 perform music on musical instrument (2) The children are playing across the street. (3) Two men playing doubles tennis on a grass court. Mirella Lapata Understanding Visual Scenes 35
48 Word Sense Disambiguation Task Definition Dataset Construction Word sense disambiguation is a standard NLP task: (1) A man is playing a guitar. play:1 perform music on musical instrument (2) The children are playing across the street. play:2 engage in a fun or recreational (childlike) activity (3) Two men playing doubles tennis on a grass court. Mirella Lapata Understanding Visual Scenes 35
49 Word Sense Disambiguation Task Definition Dataset Construction Word sense disambiguation is a standard NLP task: (1) A man is playing a guitar. play:1 perform music on musical instrument (2) The children are playing across the street. play:2 engage in a fun or recreational (childlike) activity (3) Two men playing doubles tennis on a grass court. play:3 engage in or make moves related to competition or sport Mirella Lapata Understanding Visual Scenes 35
50 Task Definition Dataset Construction We can apply this task to an image/verb pair: play Mirella Lapata Understanding Visual Scenes 36
51 Task Definition Dataset Construction We can apply this task to an image/verb pair: play play:1 perform music on musical instrument New task: visual sense disambiguation (VSD, Gella et al. 2016). Mirella Lapata Understanding Visual Scenes 36
52 Existing Action Recognition Datasets Task Definition Dataset Construction Dataset Actions PPMI (Yao & Fei-Fei 2010) 24 Stanford 40 (Yao et al. 2011) 40 PASCAL 2012 (Everingham et al. 2015) 11 TUHOI (Le et al. 2014) 2974 Mirella Lapata Understanding Visual Scenes 37
53 Existing Action Recognition Datasets Task Definition Dataset Construction Dataset Verbs Actions Sense PPMI (Yao & Fei-Fei 2010) 2 24 N Stanford 40 (Yao et al. 2011) N PASCAL 2012 (Everingham et al. 2015) 9 11 N TUHOI (Le et al. 2014) 2974 N Actions: verb phrases or verb-object pairs; verb senses are more general than actions; no existing datasets with verb sense annotation. Mirella Lapata Understanding Visual Scenes 37
54 Task Definition Dataset Construction Dataset for Visual Verb Sense Disambiguation Design a new dataset using images from: MSCOCO: 123k images with object labels, image descriptions: not designed for action recognition; use verbs in descriptions as labels. TUHOI: 10,805 images with object labels: labeled with actions (verb-object pairs); use verbs as labels. Mirella Lapata Understanding Visual Scenes 38
55 Task Definition Dataset Construction Dataset for Visual Verb Sense Disambiguation We use the OntoNotes inventory of verb senses (less fine-grained than WordNet). But: not all verb senses are visual. Visual: Mirella Lapata Understanding Visual Scenes 39
56 Task Definition Dataset Construction Dataset for Visual Verb Sense Disambiguation We use the OntoNotes inventory of verb senses (less fine-grained than WordNet). But: not all verb senses are visual. Visual: Non-Visual: Mirella Lapata Understanding Visual Scenes 39
. But: not all verb senses are visual.")
; new annotators select correct visual sense for each image.")
57 Task Definition Dataset Construction Dataset for Visual Verb Sense Disambiguation We use the OntoNotes inventory of verb senses (less fine-grained than WordNet). But: not all verb senses are visual. Visual: Non-Visual: Solution: annotate only the visual senses: annotators decide which senses are visual (about 50% in MSCOCO); new annotators select correct visual sense for each image. Mirella Lapata Understanding Visual Scenes 39

58 Task Definition Dataset Construction Annotating Image and Verb with Visual Sense Mirella Lapata Understanding Visual Scenes 40
59 Task Definition Dataset Construction Annotating Image and Verb with Visual Sense Mirella Lapata Understanding Visual Scenes 40
60 VerSe Dataset Representing Visual Structure Task Definition Dataset Construction Comparison of VerSe with existing action recognition datasets: Dataset Verbs Actions Sense PPMI (Yao & Fei-Fei 2010) 2 24 N Stanford 40 (Yao et al. 2011) N PASCAL 2012 (Everingham et al. 2015) 9 11 N TUHOI (Le et al. 2014) 2974 N VerSe (our dataset) 90 Y (163) Mirella Lapata Understanding Visual Scenes 41
61 VerSe Dataset Representing Visual Structure Task Definition Dataset Construction VerSe dataset divided into motion and non-motion verbs: Verb type Verbs Images Senses Examples Motion run, walk, jump, swing, hit, kick Non-motion sleep, sit, lean, read, write, look Mirella Lapata Understanding Visual Scenes 42
62 O: person, guitar, microphone C: A man playing guitar. Task Definition Dataset Construction Image Representations objects captions CNN-fc7 play Sense Inventory: D s 1 s 2 s 3 engage in competition or sport perform or transmit music engage in a playful activity Scoring Function Φ s 2 Sense Representations Mirella Lapata Understanding Visual Scenes 43
63 O: person, guitar, microphone C: A man playing guitar. Task Definition Dataset Construction Image Representations objects captions CNN-fc7 play Sense Inventory: D s 1 s 2 s 3 engage in competition or sport perform or transmit music engage in a playful activity Scoring Function Φ s 2 Sense Representations Mirella Lapata Understanding Visual Scenes 43
64 Task Definition Dataset Construction O: person, guitar, microphone VGG - CNN CNN-fc7 objects word2vec Object labels obtained using VGG (Simonyan & Zisserman 2014). Mirella Lapata Understanding Visual Scenes 43
65 O: person, guitar, microphone C: A man playing guitar. Task Definition Dataset Construction Image Representations objects captions CNN-fc7 play Sense Inventory: D s 1 s 2 s 3 engage in competition or sport perform or transmit music engage in a playful activity Scoring Function Φ s 2 Sense Representations Mirella Lapata Understanding Visual Scenes 43
66 Task Definition Dataset Construction LSTM VGG - CNN C: A man playing a guitar word2vec Image descriptions from Show and Tell (Vinyals et al. 2015). captions Mirella Lapata Understanding Visual Scenes 43
67 Task Definition Dataset Construction O: person, guitar, microphone C: A man playing guitar. Image Representations objects captions CNN-fc7 play Sense Inventory: D s 1 s 2 s 3 engage in competition or sport perform or transmit music engage in a playful activity Scoring Function Φ s 2 Sense Representations Mirella Lapata Understanding Visual Scenes 43
68 Task Definition Dataset Construction O: person, guitar, microphone C: A man playing guitar. Image Representations objects captions CNN-fc7 play Sense Inventory: D s 1 s 2 s 3 engage in competition or sport perform or transmit music engage in a playful activity Scoring Function Φ s 2 Sense Representations Mirella Lapata Understanding Visual Scenes 43
69 #1 #3 Representing Visual Structure Visual Representation for Senses Task Definition Dataset Construction perform or transmit music play #2 engage in competition or sport..... Mirella Lapata Understanding Visual Scenes 44
70 #1 Representing Visual Structure Visual Representation for Senses Task Definition Dataset Construction perform or transmit music q 11 q 12 q 13 playing guitar playing music playing in a band..... q 21 playing tennis play #2 engage in competition or sport q23 q 22 playing sport #3 playing game Mirella Lapata Understanding Visual Scenes 44
71 #1 Representing Visual Structure Visual Representation for Senses Task Definition Dataset Construction perform or transmit music q 11 q 12 q 13 playing guitar playing music playing in a band..... q 21 playing tennis play #2 engage in competition or sport q23 q 22 playing sport #3 playing game Mirella Lapata Understanding Visual Scenes 44
72 Visual Representation for Senses Task Definition Dataset Construction play #1 #2 perform or transmit music engage in competition or sport q 11 q 12 q 13 q 21 q23 q 22 playing guitar playing music playing in a band..... playing tennis playing sport CNN - fc7 CNN - fc7 CNN - fc7 CNN - fc7 Mean Pooling Mean Pooling play #1 play #2 #3 playing game Mirella Lapata Understanding Visual Scenes 44
73 Task Definition Dataset Construction O: person, guitar, microphone C: A man playing guitar. Image Representations objects captions CNN-fc7 play Sense Inventory: D s 1 s 2 s 3 engage in competition or sport perform or transmit music engage in a playful activity Scoring Function Φ s 2 Sense Representations Mirella Lapata Understanding Visual Scenes 45
74 Scoring Function Representing Visual Structure Task Definition Dataset Construction Use vector similarity (cosine) as scoring function: ŝ = arg max Φ(s, i, v, D) s S(v) Mirella Lapata Understanding Visual Scenes 46
75 Scoring Function Representing Visual Structure Task Definition Dataset Construction Use vector similarity (cosine) as scoring function: Representations: textual: O, C embeddings; ŝ = arg max Φ(s, i, v, D) s S(v) Mirella Lapata Understanding Visual Scenes 46
76 Scoring Function Representing Visual Structure Task Definition Dataset Construction Use vector similarity (cosine) as scoring function: Representations: textual: O, C embeddings; visual: CNN features; ŝ = arg max Φ(s, i, v, D) s S(v) Mirella Lapata Understanding Visual Scenes 46
77 Scoring Function Representing Visual Structure Task Definition Dataset Construction Use vector similarity (cosine) as scoring function: Representations: textual: O, C embeddings; visual: CNN features; ŝ = arg max Φ(s, i, v, D) s S(v) multi-modal: fused textual and visual features using Canonical Correlation Analysis. Mirella Lapata Understanding Visual Scenes 46
78 Results Representing Visual Structure Task Definition Dataset Construction 85 Motion Non-Motion 80.6 Accuracy Scores First-sense Mirella Lapata Understanding Visual Scenes 47
79 Results Representing Visual Structure Task Definition Dataset Construction 85 Motion Non-Motion 80.6 Accuracy Scores First-sense Text Mirella Lapata Understanding Visual Scenes 47
80 Results Representing Visual Structure Task Definition Dataset Construction 85 Motion Non-Motion 80.6 Accuracy Scores First-sense Text Visual Mirella Lapata Understanding Visual Scenes 47
81 Results Representing Visual Structure Task Definition Dataset Construction 85 Motion Non-Motion 80.6 Accuracy Scores First-sense Text Visual Multi-modal Mirella Lapata Understanding Visual Scenes 47
82 Task Definition Dataset Construction Results: Gold Standard Image Descriptions Motion Non-Motion Accuracy Scores First-sense Text Visual Multi-modal Mirella Lapata Understanding Visual Scenes 48
; use multiple instance learning (we do not know which bounding boxes correspond to which verbs).")
83 Verb Prediction Representing Visual Structure Task Definition Dataset Construction ConvNet Classifier Output fc7 (2048,12,12) Linear Sigmoid for each v MIL-Noisy OR play swing throw detect the verbs that are present in an image (250 classes); use multiple instance learning (we do not know which bounding boxes correspond to which verbs). Mirella Lapata Understanding Visual Scenes 49


84 Examples: Verb Prediction Task Definition Dataset Construction play, perform hit, swing, play hold, sit, use Mirella Lapata Understanding Visual Scenes 50
85 Task Definition Dataset Construction Verb Prediction and Sense Disambiguation Mirella Lapata Understanding Visual Scenes 51
86 1 Representing Visual Structure Visual Dependency Representations Visual Constituency Representations Applications 2 Task Definition Dataset Construction 3 Mirella Lapata Understanding Visual Scenes 52
87 Representing Visual Structure Image understanding (like text understanding) requires structured representations; for multimodal tasks, we need to align linguistic and image structure; syntactic example: visual dependency representations align geometric structure of an image with syntactic structure of a sentence; application in image description and image retrieval; semantic example: visual word senses align event depicted in an image with event described in a sentence; unsupervised VSD model using multimodal embeddings. Mirella Lapata Understanding Visual Scenes 53
88 Other Approaches to Image Structure Other approaches that align linguistic structure and image structure: Scene (description) graphs (Johnson et al. 2015; Aditya et al. 2015): triples of object, attribute, relation; aligned with image regions and region descriptions; no explicit alignment with linguistic structure (but could be derived). Visual semantic roles (Yatskar et al. 2016): uses semantic frames from FrameNet; annotates images with frames, participants, and roles; not aligned with regions or image descriptions; no verb senses. Mirella Lapata Understanding Visual Scenes 54

89 Scene Graphs Representing Visual Structure Mirella Lapata Understanding Visual Scenes 55

90 Scene Graphs Representing Visual Structure Mirella Lapata Understanding Visual Scenes 55

91 Visual Semantic Roles Representing Visual Structure Mirella Lapata Understanding Visual Scenes 56
92 References I Representing Visual Structure Aditya, S., Yang, Y., Baral, C., Fermuller, C., & Aloimonos, Y. (2015). From images to sentences through scene description graphs using commonsense reasoning and knowledge. arxiv preprint arxiv: Elliott, D., & Keller, F. (2013). Image description using visual dependency representations. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, (pp ), Seattle, WA. Everingham, M., Eslami, S. M. A., Gool, L. V., Williams, C. K. I., Winn, J. M., & Zisserman, A. (2015). The Pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 111, Gella, S., Lapata, M., & Keller, F. (2016). Unsupervised visual sense disambiguation for verbs using multimodal embedding. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, (pp ), San Diego, CA. Johnson, J., Krishna, R., Stark, M., Li, L.-J., Shamma, D. A., Bernstein, M., & Fei-Fei, L. (2015). Image retrieval using scene graphs. In Proceedings of the Conference on Computer Vision and Pattern Recognition, (pp ), Boston, MA. Le, D.-T., Uijlings, J., & Bernardi, R. (2014). Proceedings of the Third Workshop on Vision and Language, chap. TUHOI: Trento Universal Human Object Interaction Dataset, (pp ). Dublin City University and the Association for Computational Linguistics. Mirella Lapata Understanding Visual Scenes 57
93 References II Representing Visual Structure Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. CoRR, abs/ Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, (pp ). Yao, B., & Fei-Fei, L. (2010). Grouplet: A structured image representation for recognizing human and object interactions. In Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on, (pp. 9 16). IEEE. Yao, B., Jiang, X., Khosla, A., Lin, A. L., Guibas, L., & Fei-Fei, L. (2011). Human action recognition by learning bases of action attributes and parts. In Computer Vision (ICCV), 2011 IEEE International Conference on, (pp ). IEEE. Yatskar, M., Zettlemoyer, L., & Farhadi, A. (2016). Situation recognition: Visual semantic role labeling for image understanding. In Computer Vision and Pattern Recognition. Mirella Lapata Understanding Visual Scenes 58
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
arxiv: v2 [cs.cv] 3 Aug 2017
![arxiv: v2 [cs.cv] 3 Aug 2017](/thumbs/71/66064162.jpg "arxiv: v2 [cs.cv] 3 Aug 2017") Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Lip Reading in Profile
 CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
CHUNG AND ZISSERMAN: BMVC AUTHOR GUIDELINES 1 Lip Reading in Profile Joon Son Chung http://wwwrobotsoxacuk/~joon Andrew Zisserman http://wwwrobotsoxacuk/~az Visual Geometry Group Department of Engineering
Diverse Concept-Level Features for Multi-Object Classification
 Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Diverse Concept-Level Features for Multi-Object Classification Youssef Tamaazousti 12 Hervé Le Borgne 1 Céline Hudelot 2 1 CEA, LIST, Laboratory of Vision and Content Engineering, F-91191 Gif-sur-Yvette,
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
The University of Amsterdam s Concept Detection System at ImageCLEF 2011
 The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Phrase Localization and Visual Relationship Detection with Comprehensive Image-Language Cues
 Phrase Localization and Visual Relationship Detection with Comprehensive Image-Language Cues Bryan A. Plummer Arun Mallya Christopher M. Cervantes Julia Hockenmaier Svetlana Lazebnik University of Illinois
Phrase Localization and Visual Relationship Detection with Comprehensive Image-Language Cues Bryan A. Plummer Arun Mallya Christopher M. Cervantes Julia Hockenmaier Svetlana Lazebnik University of Illinois
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
How to analyze visual narratives: A tutorial in Visual Narrative Grammar
 How to analyze visual narratives: A tutorial in Visual Narrative Grammar Neil Cohn 2015 neilcohn@visuallanguagelab.com www.visuallanguagelab.com Abstract Recent work has argued that narrative sequential
How to analyze visual narratives: A tutorial in Visual Narrative Grammar Neil Cohn 2015 neilcohn@visuallanguagelab.com www.visuallanguagelab.com Abstract Recent work has argued that narrative sequential
Basic Parsing with Context-Free Grammars. Some slides adapted from Julia Hirschberg and Dan Jurafsky 1
 Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web
 WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
Taxonomy-Regularized Semantic Deep Convolutional Neural Networks
 Taxonomy-Regularized Semantic Deep Convolutional Neural Networks Wonjoon Goo 1, Juyong Kim 1, Gunhee Kim 1, Sung Ju Hwang 2 1 Computer Science and Engineering, Seoul National University, Seoul, Korea 2
Taxonomy-Regularized Semantic Deep Convolutional Neural Networks Wonjoon Goo 1, Juyong Kim 1, Gunhee Kim 1, Sung Ju Hwang 2 1 Computer Science and Engineering, Seoul National University, Seoul, Korea 2
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
Word Sense Disambiguation
 Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
arxiv: v4 [cs.cv] 13 Aug 2017
![arxiv: v4 [cs.cv] 13 Aug 2017](/thumbs/71/66201702.jpg "arxiv: v4 [cs.cv] 13 Aug 2017") Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
Ruben Villegas 1 * Jimei Yang 2 Yuliang Zou 1 Sungryull Sohn 1 Xunyu Lin 3 Honglak Lee 1 4 arxiv:1704.05831v4 [cs.cv] 13 Aug 17 Abstract We propose a hierarchical approach for making long-term predictions
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web
 WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
WebLogo-2M: Scalable Logo Detection by Deep Learning from the Web Hang Su Queen Mary University of London hang.su@qmul.ac.uk Shaogang Gong Queen Mary University of London s.gong@qmul.ac.uk Xiatian Zhu
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF GRAPH DATA
 International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures
 Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Informatics 2A: Language Complexity and the. Inf2A: Chomsky Hierarchy
 Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Construction Grammar. University of Jena.
 Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
Construction Grammar Holger Diessel University of Jena holger.diessel@uni-jena.de http://www.holger-diessel.de/ Words seem to have a prototype structure; but language does not only consist of words. What
The Role of the Head in the Interpretation of English Deverbal Compounds
 The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
ENGBG1 ENGBL1 Campus Linguistics. Meeting 2. Chapter 7 (Morphology) and chapter 9 (Syntax) Pia Sundqvist
 and chapter 9 (Syntax) Pia Sundqvist") Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
Meeting 2 Chapter 7 (Morphology) and chapter 9 (Syntax) Today s agenda Repetition of meeting 1 Mini-lecture on morphology Seminar on chapter 7, worksheet Mini-lecture on syntax Seminar on chapter 9, worksheet
1.11 I Know What Do You Know?
 50 SECONDARY MATH 1 // MODULE 1 1.11 I Know What Do You Know? A Practice Understanding Task CC BY Jim Larrison https://flic.kr/p/9mp2c9 In each of the problems below I share some of the information that
50 SECONDARY MATH 1 // MODULE 1 1.11 I Know What Do You Know? A Practice Understanding Task CC BY Jim Larrison https://flic.kr/p/9mp2c9 In each of the problems below I share some of the information that
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
arxiv: v1 [cs.cv] 2 Jun 2017
![arxiv: v1 [cs.cv] 2 Jun 2017](/thumbs/71/65541647.jpg "arxiv: v1 [cs.cv] 2 Jun 2017") Temporal Action Labeling using Action Sets Alexander Richard, Hilde Kuehne, Juergen Gall University of Bonn, Germany {richard,kuehne,gall}@iai.uni-bonn.de arxiv:1706.00699v1 [cs.cv] 2 Jun 2017 Abstract
Temporal Action Labeling using Action Sets Alexander Richard, Hilde Kuehne, Juergen Gall University of Bonn, Germany {richard,kuehne,gall}@iai.uni-bonn.de arxiv:1706.00699v1 [cs.cv] 2 Jun 2017 Abstract
Airplane Rescue: Social Studies. LEGO, the LEGO logo, and WEDO are trademarks of the LEGO Group The LEGO Group.
 Airplane Rescue: Social Studies LEGO, the LEGO logo, and WEDO are trademarks of the LEGO Group. 2010 The LEGO Group. Lesson Overview The students will discuss ways that people use land and their physical
Airplane Rescue: Social Studies LEGO, the LEGO logo, and WEDO are trademarks of the LEGO Group. 2010 The LEGO Group. Lesson Overview The students will discuss ways that people use land and their physical
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY
 TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition
 Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition Roy Bar-Haim,Ido Dagan, Iddo Greental, Idan Szpektor and Moshe Friedman Computer Science Department, Bar-Ilan University,
Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition Roy Bar-Haim,Ido Dagan, Iddo Greental, Idan Szpektor and Moshe Friedman Computer Science Department, Bar-Ilan University,
Annotation Projection for Discourse Connectives
 SFB 833 / Univ. Tübingen Penn Discourse Treebank Workshop Annotation projection Basic idea: Given a bitext E/F and annotation for F, how would the annotation look for E? Examples: Word Sense Disambiguation
SFB 833 / Univ. Tübingen Penn Discourse Treebank Workshop Annotation projection Basic idea: Given a bitext E/F and annotation for F, how would the annotation look for E? Examples: Word Sense Disambiguation
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
Hardhatting in a Geo-World
 Hardhatting in a Geo-World TM Developed and Published by AIMS Education Foundation This book contains materials developed by the AIMS Education Foundation. AIMS (Activities Integrating Mathematics and
Hardhatting in a Geo-World TM Developed and Published by AIMS Education Foundation This book contains materials developed by the AIMS Education Foundation. AIMS (Activities Integrating Mathematics and
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Compositional Semantics
 Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
Compositional Semantics CMSC 723 / LING 723 / INST 725 MARINE CARPUAT marine@cs.umd.edu Words, bag of words Sequences Trees Meaning Representing Meaning An important goal of NLP/AI: convert natural language
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Short Text Understanding Through Lexical-Semantic Analysis
 Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Learning Disability Functional Capacity Evaluation. Dear Doctor,
 Dear Doctor, I have been asked to formulate a vocational opinion regarding NAME s employability in light of his/her learning disability. To assist me with this evaluation I would appreciate if you can
Dear Doctor, I have been asked to formulate a vocational opinion regarding NAME s employability in light of his/her learning disability. To assist me with this evaluation I would appreciate if you can
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Spoken Language Parsing Using Phrase-Level Grammars and Trainable Classifiers
 Spoken Language Parsing Using Phrase-Level Grammars and Trainable Classifiers Chad Langley, Alon Lavie, Lori Levin, Dorcas Wallace, Donna Gates, and Kay Peterson Language Technologies Institute Carnegie
Spoken Language Parsing Using Phrase-Level Grammars and Trainable Classifiers Chad Langley, Alon Lavie, Lori Levin, Dorcas Wallace, Donna Gates, and Kay Peterson Language Technologies Institute Carnegie
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
arxiv: v2 [cs.cv] 4 Mar 2016
![arxiv: v2 [cs.cv] 4 Mar 2016](/thumbs/71/66025285.jpg "arxiv: v2 [cs.cv] 4 Mar 2016") MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS Fisher Yu Princeton University Vladlen Koltun Intel Labs arxiv:1511.07122v2 [cs.cv] 4 Mar 2016 ABSTRACT State-of-the-art models for semantic segmentation
MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS Fisher Yu Princeton University Vladlen Koltun Intel Labs arxiv:1511.07122v2 [cs.cv] 4 Mar 2016 ABSTRACT State-of-the-art models for semantic segmentation
Copyright Corwin 2015
 2 Defining Essential Learnings How do I find clarity in a sea of standards? For students truly to be able to take responsibility for their learning, both teacher and students need to be very clear about
2 Defining Essential Learnings How do I find clarity in a sea of standards? For students truly to be able to take responsibility for their learning, both teacher and students need to be very clear about
Handling Sparsity for Verb Noun MWE Token Classification
 Handling Sparsity for Verb Noun MWE Token Classification Mona T. Diab Center for Computational Learning Systems Columbia University mdiab@ccls.columbia.edu Madhav Krishna Computer Science Department Columbia
Handling Sparsity for Verb Noun MWE Token Classification Mona T. Diab Center for Computational Learning Systems Columbia University mdiab@ccls.columbia.edu Madhav Krishna Computer Science Department Columbia
Generating Natural-Language Video Descriptions Using Text-Mined Knowledge
 Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence Generating Natural-Language Video Descriptions Using Text-Mined Knowledge Niveda Krishnamoorthy UT Austin niveda@cs.utexas.edu
Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence Generating Natural-Language Video Descriptions Using Text-Mined Knowledge Niveda Krishnamoorthy UT Austin niveda@cs.utexas.edu
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
5.1 Sound & Light Unit Overview
 5.1 Sound & Light Unit Overview Enduring Understanding: Sound and light are forms of energy that travel and interact with objects in various ways. Essential Question: How is sound energy transmitted, absorbed,
5.1 Sound & Light Unit Overview Enduring Understanding: Sound and light are forms of energy that travel and interact with objects in various ways. Essential Question: How is sound energy transmitted, absorbed,
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
 A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation Chunpeng Wu 1, Wei Wen 1, Tariq Afzal 2, Yongmei Zhang 2, Yiran Chen 3, and Hai (Helen) Li 3 1 Electrical and
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation Chunpeng Wu 1, Wei Wen 1, Tariq Afzal 2, Yongmei Zhang 2, Yiran Chen 3, and Hai (Helen) Li 3 1 Electrical and
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty
 Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
Atypical Prosodic Structure as an Indicator of Reading Level and Text Difficulty Julie Medero and Mari Ostendorf Electrical Engineering Department University of Washington Seattle, WA 98195 USA {jmedero,ostendor}@uw.edu
A heuristic framework for pivot-based bilingual dictionary induction
 2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,