Aligning Sentences from Standard Wikipedia to Simple Wikipedia. Written by Hwang et al. Presented by Xia Cui for
|
|
|
- Constance Bruce
- 5 years ago
- Views:
Transcription

1 Aligning Sentences from Standard Wikipedia to Simple Wikipedia Written by Hwang et al. Presented by Xia Cui for
2 Overview Wikipedia Simple Article shorter sentences and simpler words and grammars Standard Article Aim: Sentence Alignment for every simple sentence, find corresponding sentence(or sentence fragments) in standard Wikipedia Problem not strictly parallel & very different presentation ordering Solution Sentence-Level Scoring Sequence-Level Search
3 Sentence-Level Scoring Kauchak, 2013 cosine distance between vector representations of tf.idf scores of words in each sentence tf.idf: term frequency inverse document frequency, how important a word to a document Wu and Plamer, 1994 word-level pairwise semantic similarity score
4 Sequence-Level Search Zhu et al., 2010 without constraint, can be one-to-many two sentences are aligned if similarity score > threshold Coster and Kauchak, 2011; Barzilay and Elhadad, 2003 with a sequential constraint dynamic programming, recursively optimization relies on consistent ordering, not always hold for Wikipedia
5 Simplification Datasets Good semantics of simple and standard completely matches Good Partial a sentence covers the other, but contains additional info Partial discuss unrelated concepts, but share short related phrase Bad discuss unrelated concepts
6 Simplification Datasets(Cont.) Manually Annotated native speaker, 67,853 pairs(277 good, 281 good partial, 117 partial and 67,178 bad) Automatically Aligned threshold > 0.45; good: 0.67; good partial: K good, 130K good partial, 110K unlabelled 51.5M potential(threshold < 0.45)
7 Sentence Alignment Sentence-Level Score builds on Word-Level Similarity WikNet Similarity Structural Semantic Similarity Greedy Search
")
8 Word-Level Similarity WikNet Similarity WikNet: a graph leverage synonym info in Wiktionary + word-definition co-occurrence Word: a node if word w2 appears in any sense of definitions of word w1 an edge: Preprocess w1 morphological variations are mapped to baseform atypical word senses are removed stopwords are removed Extended Jaccard Coefficient Jaccard Coefficient(Salton and Mcgill, 1983) Number of shared neighbors for two words w2
9 WikNet Similarity(Cont.) Extended Jaccard Coefficient neighbors with n-step reach(fogaras and Racz, 2005) additional term: direct neighbor or not if words or neighbors have synonym sets in Wiktionary, then the shared synonyms are used if two words are in each other s synonym lists, the similarity is set to 1 otherwise:» is l-step neighbor set of wi
10 Structural Semantic Similarity Between words +dependency structure between words in a sentence Stanford s dependency parser(de Marneffe et al., 2006) create triplet for each word w: given word, h: head word, r: relationship between w and h Similarity between w1 and w2 : WikNet Similarity; : dependency similarity between relations r1 and r2 same category: ; otherwise:
11 Greedy Sequence-Level Alignment Compute similarity between all sentences Sj in simple and Ai in standard Select most similar sentence pair, remove all other pairs with respective sentences S*, A* = argmaxs(sj, Ai) Repeat until all sentences in shorter document are aligned Good Good Partial Ai (fragments of standard sentence Ai)
12 Experiments Preprocess topic names, list markers and non-english are removed data was tokenized, lemmatized and parsed by Stanford CoreNLP ( Evaluation Precision-recall; max F1; AUC Comparison(Greedy Structural WikNet) Unconstrained WordNet(Mohler and Mihalcea, 2009) an unconstrained search for aligning sentences and WordNet Semantic Similarity Unconstrained Vector Space(Zhu et al., 2010) vector space representation and an unconstrained search for aligning sentences Ordered Vector Space(Coster and Kauchak, 2011) dynamic programming for sentence alignment and vector space scoring
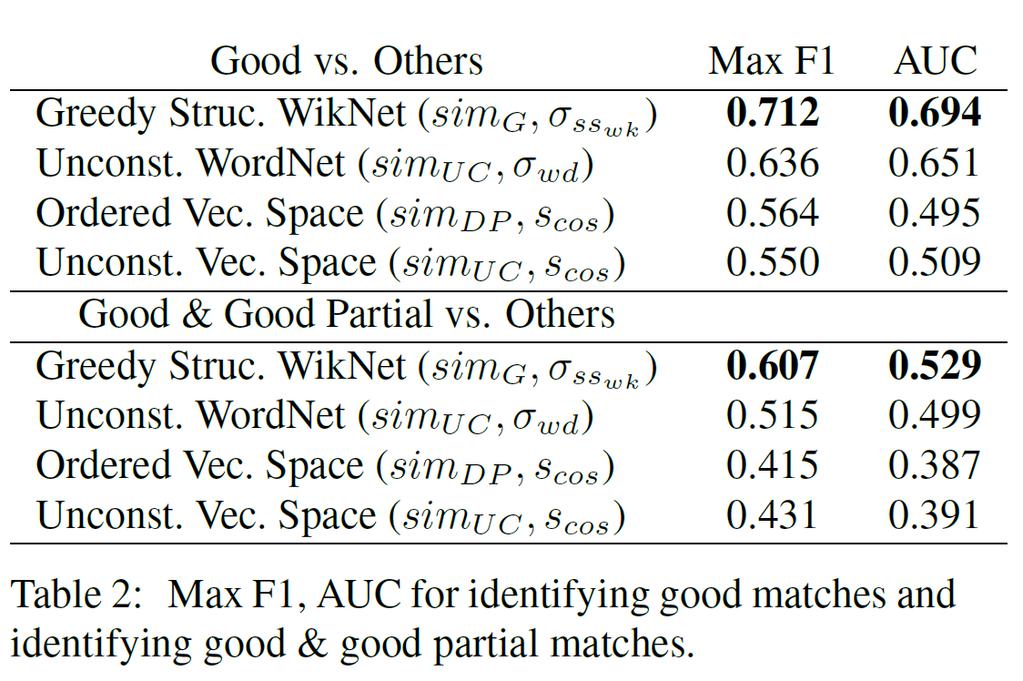
13 Results
14 Results(Cont.)
15 Future Work Introducing other techniques using introduced datasets Better text preprocessing Learning similarities Phrase alignment to obtain better partial matches
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF GRAPH DATA
 International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
International Journal of Semantic Computing Vol. 5, No. 4 (2011) 433 462 c World Scientific Publishing Company DOI: 10.1142/S1793351X1100133X A DISTRIBUTIONAL STRUCTURED SEMANTIC SPACE FOR QUERYING RDF
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
The Role of String Similarity Metrics in Ontology Alignment
 The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Variations of the Similarity Function of TextRank for Automated Summarization
 Variations of the Similarity Function of TextRank for Automated Summarization Federico Barrios 1, Federico López 1, Luis Argerich 1, Rosita Wachenchauzer 12 1 Facultad de Ingeniería, Universidad de Buenos
Variations of the Similarity Function of TextRank for Automated Summarization Federico Barrios 1, Federico López 1, Luis Argerich 1, Rosita Wachenchauzer 12 1 Facultad de Ingeniería, Universidad de Buenos
A Graph Based Authorship Identification Approach
 A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Graph Based Authorship Identification Approach Notebook for PAN at CLEF 2015 Helena Gómez-Adorno 1, Grigori Sidorov 1, David Pinto 2, and Ilia Markov 1 1 Center for Computing Research, Instituto Politécnico
A Semantic Similarity Measure Based on Lexico-Syntactic Patterns
 A Semantic Similarity Measure Based on Lexico-Syntactic Patterns Alexander Panchenko, Olga Morozova and Hubert Naets Center for Natural Language Processing (CENTAL) Université catholique de Louvain Belgium
A Semantic Similarity Measure Based on Lexico-Syntactic Patterns Alexander Panchenko, Olga Morozova and Hubert Naets Center for Natural Language Processing (CENTAL) Université catholique de Louvain Belgium
Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models
 Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models Jung-Tae Lee and Sang-Bum Kim and Young-In Song and Hae-Chang Rim Dept. of Computer &
Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models Jung-Tae Lee and Sang-Bum Kim and Young-In Song and Hae-Chang Rim Dept. of Computer &
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
Graph Alignment for Semi-Supervised Semantic Role Labeling
 Graph Alignment for Semi-Supervised Semantic Role Labeling Hagen Fürstenau Dept. of Computational Linguistics Saarland University Saarbrücken, Germany hagenf@coli.uni-saarland.de Mirella Lapata School
Graph Alignment for Semi-Supervised Semantic Role Labeling Hagen Fürstenau Dept. of Computational Linguistics Saarland University Saarbrücken, Germany hagenf@coli.uni-saarland.de Mirella Lapata School
An Effective Framework for Fast Expert Mining in Collaboration Networks: A Group-Oriented and Cost-Based Method
 Farhadi F, Sorkhi M, Hashemi S et al. An effective framework for fast expert mining in collaboration networks: A grouporiented and cost-based method. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(3): 577
Farhadi F, Sorkhi M, Hashemi S et al. An effective framework for fast expert mining in collaboration networks: A grouporiented and cost-based method. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(3): 577
A Dataset of Syntactic-Ngrams over Time from a Very Large Corpus of English Books
 A Dataset of Syntactic-Ngrams over Time from a Very Large Corpus of English Books Yoav Goldberg Bar Ilan University yoav.goldberg@gmail.com Jon Orwant Google Inc. orwant@google.com Abstract We created
A Dataset of Syntactic-Ngrams over Time from a Very Large Corpus of English Books Yoav Goldberg Bar Ilan University yoav.goldberg@gmail.com Jon Orwant Google Inc. orwant@google.com Abstract We created
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Integrating Semantic Knowledge into Text Similarity and Information Retrieval
 Integrating Semantic Knowledge into Text Similarity and Information Retrieval Christof Müller, Iryna Gurevych Max Mühlhäuser Ubiquitous Knowledge Processing Lab Telecooperation Darmstadt University of
Integrating Semantic Knowledge into Text Similarity and Information Retrieval Christof Müller, Iryna Gurevych Max Mühlhäuser Ubiquitous Knowledge Processing Lab Telecooperation Darmstadt University of
Matching Similarity for Keyword-Based Clustering
 Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
AN EXAMPLE OF THE GOMORY CUTTING PLANE ALGORITHM. max z = 3x 1 + 4x 2. 3x 1 x x x x N 2
 AN EXAMPLE OF THE GOMORY CUTTING PLANE ALGORITHM Consider the integer programme subject to max z = 3x 1 + 4x 2 3x 1 x 2 12 3x 1 + 11x 2 66 The first linear programming relaxation is subject to x N 2 max
AN EXAMPLE OF THE GOMORY CUTTING PLANE ALGORITHM Consider the integer programme subject to max z = 3x 1 + 4x 2 3x 1 x 2 12 3x 1 + 11x 2 66 The first linear programming relaxation is subject to x N 2 max
Loughton School s curriculum evening. 28 th February 2017
 Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Information-theoretic evaluation of predicted ontological annotations
 BIOINFORMATICS Vol. 29 ISMB/ECCB 2013, pages i53 i61 doi:10.1093/bioinformatics/btt228 Information-theoretic evaluation of predicted ontological annotations Wyatt T. Clark and Predrag Radivojac* Department
BIOINFORMATICS Vol. 29 ISMB/ECCB 2013, pages i53 i61 doi:10.1093/bioinformatics/btt228 Information-theoretic evaluation of predicted ontological annotations Wyatt T. Clark and Predrag Radivojac* Department
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Problems in Current Text Simplification Research: New Data Can Help
 Problems in Current Text Simplification Research: New Data Can Help Wei Xu 1 and Chris Callison-Burch 1 and Courtney Napoles 2 1 Computer and Information Science Department University of Pennsylvania {xwe,
Problems in Current Text Simplification Research: New Data Can Help Wei Xu 1 and Chris Callison-Burch 1 and Courtney Napoles 2 1 Computer and Information Science Department University of Pennsylvania {xwe,
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Program Matrix - Reading English 6-12 (DOE Code 398) University of Florida. Reading
 University of Florida. Reading") Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
Program Requirements Competency 1: Foundations of Instruction 60 In-service Hours Teachers will develop substantive understanding of six components of reading as a process: comprehension, oral language,
A Re-examination of Lexical Association Measures
 A Re-examination of Lexical Association Measures Hung Huu Hoang Dept. of Computer Science National University of Singapore hoanghuu@comp.nus.edu.sg Su Nam Kim Dept. of Computer Science and Software Engineering
A Re-examination of Lexical Association Measures Hung Huu Hoang Dept. of Computer Science National University of Singapore hoanghuu@comp.nus.edu.sg Su Nam Kim Dept. of Computer Science and Software Engineering
Term Weighting based on Document Revision History
 Term Weighting based on Document Revision History Sérgio Nunes, Cristina Ribeiro, and Gabriel David INESC Porto, DEI, Faculdade de Engenharia, Universidade do Porto. Rua Dr. Roberto Frias, s/n. 4200-465
Term Weighting based on Document Revision History Sérgio Nunes, Cristina Ribeiro, and Gabriel David INESC Porto, DEI, Faculdade de Engenharia, Universidade do Porto. Rua Dr. Roberto Frias, s/n. 4200-465
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing
 Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing Jan C. Scholtes Tim H.W. van Cann University of Maastricht, Department of Knowledge Engineering.
Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing Jan C. Scholtes Tim H.W. van Cann University of Maastricht, Department of Knowledge Engineering.
A Domain Ontology Development Environment Using a MRD and Text Corpus
 A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
The Role of the Head in the Interpretation of English Deverbal Compounds
 The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
The Role of the Head in the Interpretation of English Deverbal Compounds Gianina Iordăchioaia i, Lonneke van der Plas ii, Glorianna Jagfeld i (Universität Stuttgart i, University of Malta ii ) Wen wurmt
Florida Reading Endorsement Alignment Matrix Competency 1
 Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
MetaPAD: Meta Pattern Discovery from Massive Text Corpora
 MetaPAD: Meta Pattern Discovery from Massive Text Corpora Meng Jiang 1, Jingbo Shang 1, Taylor Cassidy 2, Xiang Ren 1 Lance M. Kaplan 2, Timothy P. Hanratty 2, Jiawei Han 1 1 Department of Computer Science,
MetaPAD: Meta Pattern Discovery from Massive Text Corpora Meng Jiang 1, Jingbo Shang 1, Taylor Cassidy 2, Xiang Ren 1 Lance M. Kaplan 2, Timothy P. Hanratty 2, Jiawei Han 1 1 Department of Computer Science,
Short Text Understanding Through Lexical-Semantic Analysis
 Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews
 Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews Kang Liu, Liheng Xu and Jun Zhao National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy
Syntactic Patterns versus Word Alignment: Extracting Opinion Targets from Online Reviews Kang Liu, Liheng Xu and Jun Zhao National Laboratory of Pattern Recognition Institute of Automation, Chinese Academy
Performance Analysis of Optimized Content Extraction for Cyrillic Mongolian Learning Text Materials in the Database
 Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
HLTCOE at TREC 2013: Temporal Summarization
 HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition
 Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition Roy Bar-Haim,Ido Dagan, Iddo Greental, Idan Szpektor and Moshe Friedman Computer Science Department, Bar-Ilan University,
Semantic Inference at the Lexical-Syntactic Level for Textual Entailment Recognition Roy Bar-Haim,Ido Dagan, Iddo Greental, Idan Szpektor and Moshe Friedman Computer Science Department, Bar-Ilan University,
Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter
 ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
Introduction to HPSG. Introduction. Historical Overview. The HPSG architecture. Signature. Linguistic Objects. Descriptions.
 to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
to as a linguistic theory to to a member of the family of linguistic frameworks that are called generative grammars a grammar which is formalized to a high degree and thus makes exact predictions about
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Semantic and Context-aware Linguistic Model for Bias Detection
 Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Semantic and Context-aware Linguistic Model for Bias Detection Sicong Kuang Brian D. Davison Lehigh University, Bethlehem PA sik211@lehigh.edu, davison@cse.lehigh.edu Abstract Prior work on bias detection
Handling Sparsity for Verb Noun MWE Token Classification
 Handling Sparsity for Verb Noun MWE Token Classification Mona T. Diab Center for Computational Learning Systems Columbia University mdiab@ccls.columbia.edu Madhav Krishna Computer Science Department Columbia
Handling Sparsity for Verb Noun MWE Token Classification Mona T. Diab Center for Computational Learning Systems Columbia University mdiab@ccls.columbia.edu Madhav Krishna Computer Science Department Columbia
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Extracting Verb Expressions Implying Negative Opinions
 Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence Extracting Verb Expressions Implying Negative Opinions Huayi Li, Arjun Mukherjee, Jianfeng Si, Bing Liu Department of Computer
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes
 Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes Viviana Molano 1, Carlos Cobos 1, Martha Mendoza 1, Enrique Herrera-Viedma 2, and
Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes Viviana Molano 1, Carlos Cobos 1, Martha Mendoza 1, Enrique Herrera-Viedma 2, and
Vocabulary Usage and Intelligibility in Learner Language
 Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
Semantic Inference at the Lexical-Syntactic Level
 Semantic Inference at the Lexical-Syntactic Level Roy Bar-Haim Department of Computer Science Ph.D. Thesis Submitted to the Senate of Bar Ilan University Ramat Gan, Israel January 2010 This work was carried
Semantic Inference at the Lexical-Syntactic Level Roy Bar-Haim Department of Computer Science Ph.D. Thesis Submitted to the Senate of Bar Ilan University Ramat Gan, Israel January 2010 This work was carried
Re-evaluating the Role of Bleu in Machine Translation Research
 Re-evaluating the Role of Bleu in Machine Translation Research Chris Callison-Burch Miles Osborne Philipp Koehn School on Informatics University of Edinburgh 2 Buccleuch Place Edinburgh, EH8 9LW callison-burch@ed.ac.uk
Re-evaluating the Role of Bleu in Machine Translation Research Chris Callison-Burch Miles Osborne Philipp Koehn School on Informatics University of Edinburgh 2 Buccleuch Place Edinburgh, EH8 9LW callison-burch@ed.ac.uk
1.11 I Know What Do You Know?
 50 SECONDARY MATH 1 // MODULE 1 1.11 I Know What Do You Know? A Practice Understanding Task CC BY Jim Larrison https://flic.kr/p/9mp2c9 In each of the problems below I share some of the information that
50 SECONDARY MATH 1 // MODULE 1 1.11 I Know What Do You Know? A Practice Understanding Task CC BY Jim Larrison https://flic.kr/p/9mp2c9 In each of the problems below I share some of the information that
Search right and thou shalt find... Using Web Queries for Learner Error Detection
 Search right and thou shalt find... Using Web Queries for Learner Error Detection Michael Gamon Claudia Leacock Microsoft Research Butler Hill Group One Microsoft Way P.O. Box 935 Redmond, WA 981052, USA
Search right and thou shalt find... Using Web Queries for Learner Error Detection Michael Gamon Claudia Leacock Microsoft Research Butler Hill Group One Microsoft Way P.O. Box 935 Redmond, WA 981052, USA
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Unsupervised Learning of Narrative Schemas and their Participants
 Unsupervised Learning of Narrative Schemas and their Participants Nathanael Chambers and Dan Jurafsky Stanford University, Stanford, CA 94305 {natec,jurafsky}@stanford.edu Abstract We describe an unsupervised
Unsupervised Learning of Narrative Schemas and their Participants Nathanael Chambers and Dan Jurafsky Stanford University, Stanford, CA 94305 {natec,jurafsky}@stanford.edu Abstract We describe an unsupervised
Cross-lingual Text Fragment Alignment using Divergence from Randomness
 Cross-lingual Text Fragment Alignment using Divergence from Randomness Sirvan Yahyaei, Marco Bonzanini, and Thomas Roelleke Queen Mary, University of London Mile End Road, E1 4NS London, UK {sirvan,marcob,thor}@eecs.qmul.ac.uk
Cross-lingual Text Fragment Alignment using Divergence from Randomness Sirvan Yahyaei, Marco Bonzanini, and Thomas Roelleke Queen Mary, University of London Mile End Road, E1 4NS London, UK {sirvan,marcob,thor}@eecs.qmul.ac.uk
Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features
 collocations by integrating features") Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features Sriram Venkatapathy Language Technologies Research Centre, International Institute of Information Technology
Measuring the relative compositionality of verb-noun (V-N) collocations by integrating features Sriram Venkatapathy Language Technologies Research Centre, International Institute of Information Technology
SEMAFOR: Frame Argument Resolution with Log-Linear Models
 SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
SEMAFOR: Frame Argument Resolution with Log-Linear Models Desai Chen or, The Case of the Missing Arguments Nathan Schneider SemEval July 16, 2010 Dipanjan Das School of Computer Science Carnegie Mellon
UMass at TDT Similarity functions 1. BASIC SYSTEM Detection algorithms. set globally and apply to all clusters.
 UMass at TDT James Allan, Victor Lavrenko, David Frey, and Vikas Khandelwal Center for Intelligent Information Retrieval Department of Computer Science University of Massachusetts Amherst, MA 3 We spent
UMass at TDT James Allan, Victor Lavrenko, David Frey, and Vikas Khandelwal Center for Intelligent Information Retrieval Department of Computer Science University of Massachusetts Amherst, MA 3 We spent
An Investigation into Team-Based Planning
 An Investigation into Team-Based Planning Dionysis Kalofonos and Timothy J. Norman Computing Science Department University of Aberdeen {dkalofon,tnorman}@csd.abdn.ac.uk Abstract Models of plan formation
An Investigation into Team-Based Planning Dionysis Kalofonos and Timothy J. Norman Computing Science Department University of Aberdeen {dkalofon,tnorman}@csd.abdn.ac.uk Abstract Models of plan formation
Unsupervised Cross-Lingual Scaling of Political Texts
 Unsupervised Cross-Lingual Scaling of Political Texts Goran Glavaš and Federico Nanni and Simone Paolo Ponzetto Data and Web Science Group University of Mannheim B6, 26, DE-68159 Mannheim, Germany {goran,
Unsupervised Cross-Lingual Scaling of Political Texts Goran Glavaš and Federico Nanni and Simone Paolo Ponzetto Data and Web Science Group University of Mannheim B6, 26, DE-68159 Mannheim, Germany {goran,
Data Modeling and Databases II Entity-Relationship (ER) Model. Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich
 Model. Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich") Data Modeling and Databases II Entity-Relationship (ER) Model Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich Database design Information Requirements Requirements Engineering
Data Modeling and Databases II Entity-Relationship (ER) Model Gustavo Alonso, Ce Zhang Systems Group Department of Computer Science ETH Zürich Database design Information Requirements Requirements Engineering
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Parallel Evaluation in Stratal OT * Adam Baker University of Arizona
 Parallel Evaluation in Stratal OT * Adam Baker University of Arizona tabaker@u.arizona.edu 1.0. Introduction The model of Stratal OT presented by Kiparsky (forthcoming), has not and will not prove uncontroversial
Parallel Evaluation in Stratal OT * Adam Baker University of Arizona tabaker@u.arizona.edu 1.0. Introduction The model of Stratal OT presented by Kiparsky (forthcoming), has not and will not prove uncontroversial
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
arxiv: v2 [cs.cv] 3 Aug 2017
![arxiv: v2 [cs.cv] 3 Aug 2017](/thumbs/71/66064162.jpg "arxiv: v2 [cs.cv] 3 Aug 2017") Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
Visual Relationship Detection with Internal and External Linguistic Knowledge Distillation Ruichi Yu, Ang Li, Vlad I. Morariu, Larry S. Davis University of Maryland, College Park Abstract Linguistic Knowledge
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Content Language Objectives (CLOs) August 2012, H. Butts & G. De Anda
 August 2012, H. Butts & G. De Anda") Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Honors Mathematics. Introduction and Definition of Honors Mathematics
 Honors Mathematics Introduction and Definition of Honors Mathematics Honors Mathematics courses are intended to be more challenging than standard courses and provide multiple opportunities for students
Honors Mathematics Introduction and Definition of Honors Mathematics Honors Mathematics courses are intended to be more challenging than standard courses and provide multiple opportunities for students
Project in the framework of the AIM-WEST project Annotation of MWEs for translation
 Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Combining a Chinese Thesaurus with a Chinese Dictionary
 Combining a Chinese Thesaurus with a Chinese Dictionary Ji Donghong Kent Ridge Digital Labs 21 Heng Mui Keng Terrace Singapore, 119613 dhji @krdl.org.sg Gong Junping Department of Computer Science Ohio
Combining a Chinese Thesaurus with a Chinese Dictionary Ji Donghong Kent Ridge Digital Labs 21 Heng Mui Keng Terrace Singapore, 119613 dhji @krdl.org.sg Gong Junping Department of Computer Science Ohio