Unsupervised Methods for Speaker Diarization: An Integrated and Iterative Approach!
|
|
|
- Daisy Andrews
- 5 years ago
- Views:
Transcription
1 Unsupervised Methods for Speaker Diarization: An Integrated and Iterative Approach! Stephen Shum, Najim Dehak, and Jim Glass!! *With help from Reda Dehak, Ekapol Chuangsuwanich, and Douglas Reynolds November 29, 2012

2 Audio Diarization! The task of marking and categorizing the different audio sources within an unmarked audio sequence.! music! Spkr A!commercial! Spkr A!silence!




3 Speaker Diarization! Who is speaking when?! Segmentation! Determine when speaker change has occurred in the speech signal! Clustering! Group together speech segments from the same speaker! Where are speaker changes?! Speaker A Which segments are from the same speaker?! Speaker B

!")
4 Applications! As a pre-processing step for other downstream applications! Annotate transcripts with speaker changes and labels! Provide an overview of speaker activity! Adapt a speech recognition system! Do speaker detection on multi-speaker speech (i.e., speaker tracking)! Speaker Diarization! 1sp detector 1sp detector M A X Utterance score!
5 Take-Home Summary! Extended previous work in applying factor analysis-based speaker modeling to speaker diarization! Castaldo 2008, Kenny 2010, Interspeech ! Integrated variational inference into speaker clustering! Valente 2005, Kenny 2010, SM Thesis 2011! Validated an iterative optimization procedure to refine clustering and segmentation hypotheses! Interspeech 2012! Proposed a duration-proportional sampling scheme to combat issues of i-vector underrepresentation! SM Thesis 2011!
6 Roadmap! Introduction! Summary of Contributions! Background! Diarization System Overview! Speaker Modeling with Factor Analysis! Our Incremental Approach! K-means and Spectral Clustering (Interspeech 2011, 2012)! Towards Probabilistic Clustering Methods! Iterative System Optimization (Re-segmentation/Clustering)! Duration-Proportional Sampling! Analysis and Discussion! Benchmark Comparison (Castaldo 2008)! Conclusion!

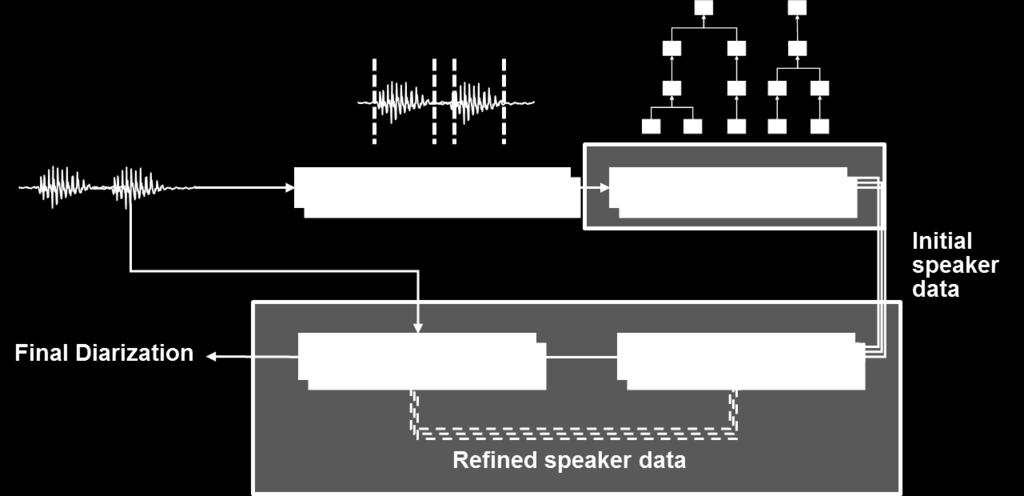
7 Standard Diarization Setup! Segmentation! Clustering! Initial speaker data! Final Diarization! Viterbi Decode! Train GMMs! Refined speaker data! Agglomerative Hierarchical Clustering! Requires methods for model selection! Iterative re-segmentation!
8 Towards Factor Analysis! At the heart of the speaker diarization problem is the problem of speaker modeling! Factor analysis-based methods have achieved success in the speaker recognition community.! Main Idea! Low-dimensional summary of a speaker s distribution of acoustic feature vectors!


 are a common")
9 Modeling Feature Sequences with GMMs! We need to model the distribution of feature vector sequences! e.g., Mel Frequency Cepstral Coefficients (MFCCs)! vectors/sec Gaussian mixture models (GMMs) are a common representation! Signal Space! Many! Training! Utterances! Feature Space! GMM!
 Adapt target model from UBM!")

10 Modeling with Adapted GMM-UBMs! (3) Adapt target model from UBM! Target Model (1) Extract feature vector sequence from speech signal! UBM (2) Train UBM with speech from many speakers!
11 GMM-UBM and MAP Adaptation! Target model is trained by adapting from background model! Couples models together and helps with limited target training data! Adaptation only updates mean parameters representing acoustic events seen in target training data Sparse regions of feature space filled in by UBM mean parameters * Both an advantage and a disadvantage Disadvantage Limited target training data can still prevent some UBM components from being adapted.
12 Intuition! The way the UBM adapts to a given speaker ought to be somewhat constrained.! For a particular speaker, there should exist some correspondence in the way the mean parameters move relative to one another.! Supervector Re-parameterization! Concatenate all mixture mean components of a GMM.! μ 1 μ 2 μ 3
13 Total variability space! A GMM supervector corresponds to a point in space.! Factor analysis captures the directions of maximum betweenutterance variability.!
14 The Total Variability Approach! Assumption (Dehak, 2009)! All pertinent variabilities lie in some low dimensional subspace T * Call it the Total Variability Space! M = m + Tw! t 2! m! * w is the vector of i-vectors!!(identity/intermediate Vectors)!! * m is supervector of un-adapted (UBM) means! * M is supervector of speaker- and channel- dependent means! t 1!
15 Regarding i-vectors! For some speech segment s, its associated i-vector w s can be seen as a low-dimensional summary of that segment s distribution of acoustic features with respect to a UBM.! Low-dimensional random vector (100 << 20,000)! Standard normal prior distribution, N(0, I)! Given some speech data,! Posterior mean à i-vector! Posterior covariance à i-vector covariance! Cosine similarity metric! Can also length-normalize i-vectors onto the unit hypersphere!
16 Roadmap! Introduction! Summary of Contributions! Background! Diarization System Overview! Speaker Modeling with Factor Analysis! Our Incremental Approach! K-means and Spectral Clustering (Interspeech 2011, 2012)! Towards Probabilistic Clustering Methods! Iterative System Optimization (Re-segmentation/Clustering)! Duration-Proportional Sampling! Analysis and Discussion! Benchmark Comparison (Castaldo 2008)! Conclusion!
17 Initialization! i! -! v e c! t o r! i! -! v e c! t o r! i! -! v e c! t o r! i! -! v e c! t o r! i! -! v e c! t o r! Clustering!
18 Clustering History! K-means on 2-speaker conversations (K = 2 known)! Interspeech 2011!
!")
19 Clustering History! K-means on 2-speaker conversations (K = 2 known)! Interspeech 2011! K-means and Spectral Clustering on K-speaker telephone conversations (K both known and unknown)! Interspeech 2012!
20 Clustering History! K-means on 2-speaker conversations (K = 2 known)! Interspeech 2011! K-means and Spectral Clustering on K-speaker telephone conversations (K both known and unknown)! Interspeech 2012! Probabilistic Methods (SM Thesis 2011)! K-means à Gaussian Mixture Models! * Bayesian model selection via variational inference!
21 The Need for Approximate Inference! Consider some observed data Y, a hidden variable set X, and associated parameters θ" For model selection m, we want to maximize! Z log P (Y m) = log P (Y,X, m)dxd à exact computation is intractable in general! x 1! x 2! x 1! x 2! θ 1! θ 2! θ 1! θ 2! Introduce! q(x, )! =q(x)! q( )!to approximate! log P (Y m) =F m (q(x, )) + KL(q(X, ) P (X, Y,m)) P (X, Y,m) * Maximizing the Free Energy minimizes the KL-divergence between the variational posterior and true posterior distributions!
22 Variational Free Energy! F m (q(x)q( )) = Z q(x)q( ) log P (Y,X,m)dXd Expectation, under q(x,θ),! of complete data log-likelihood! +H(q(X)) KL(q( ) P ( m)) Entropy of X! KL-divergence between variational! parameters and actual priors! The act of maximizing F! m (q(x)q( ))!!yields an EM algorithm! VBEM-GMM!
23 Clustering History! K-means on 2-speaker conversations (K = 2 known)! Interspeech 2011! K-means and Spectral Clustering on K-speaker telephone conversations (K both known and unknown)! Interspeech 2012! Probabilistic Methods (SM Thesis 2011)! K-means à Gaussian Mixture Models! * Bayesian model selection via variational inference! Rote application of VBEM-GMM!
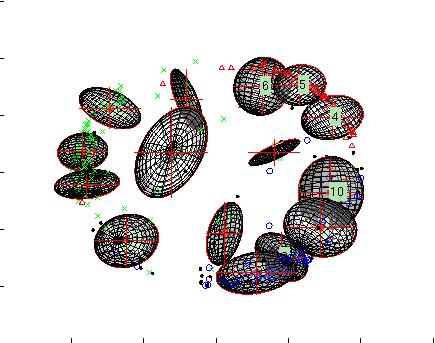
24 VBEM-GMM Visualization!
25 Clustering History! K-means on 2-speaker telephone conversations (K known)! Interspeech 2011! K-means and Spectral Clustering on K-speaker telephone conversations (K both known and unknown)! Interspeech 2012! Probabilistic Methods (SM Thesis 2011)! K-means à Gaussian Mixture Models! * Bayesian model selection via the variational approximation! Rote application of VBEM-GMM! * GMMs are a poor way to model data living on a unit hypersphere.!
26 Dimensionality Reduction! i-vectors are both speaker- and channel-dependent! Channel effect localizes all i-vectors onto one small region on the unit hypersphere! Consider a projection (PCA) onto a lower-dimensional plane!
27 Dimensionality Reduction! i-vectors are both speaker- and channel-dependent! Channel effect localizes all i-vectors onto one small region on the unit hypersphere! Consider a projection (PCA) onto a lower-dimensional plane!
28 PCA Visualization!

29 VBEM-GMM Clustering (after PCA)!
30 Cluster Initialization! Baseline Approach! Over-initialize the number of clusters! * K! 0 = 15 Remove components iteratively! Proposed Refinement! Initialize using eigenvalue roll-off from the affinity matrix generated by the spectral clustering algorithm! *! K 0 = ˆK + d3 Ke Still want to over-initialize clusters, but in a more informed manner.!
31 System Diagram (Clustering)!
32 System Diagram (Baseline)!
33 Experiment Details! Evaluation Data! Multi-lingual CallHome corpus! * 500 recordings, 2-5 minutes each, containing 2-7 speakers! Total Variability! 20-dimensional MFCC acoustic feature vectors! UBM of 1024 Gaussians! Rank of Total Variability matrix = 100! * i.e. 100-dimensional i-vectors! Diarization Error Rate (DER)! Amount of time spent confusing one speaker s speech as from another!
34 Initial Results!
35 Roadmap! Introduction! Summary of Contributions! Background! Diarization System Overview! Speaker Modeling with Factor Analysis! Our Incremental Approach! K-means and Spectral Clustering (Interspeech 2011, 2012)! Towards Probabilistic Clustering Methods! Iterative System Optimization (Re-segmentation/Clustering)! Duration-Proportional Sampling! Analysis and Discussion! Benchmark Comparison (Castaldo 2008)! Conclusion!

36 System Diagram (Baseline)!
37 Iterative Re-segmentation! Initialize a GMM for each cluster.! * Speaker 1, Speaker 2,, Non-speech N! Obtain a posterior probability for each cluster given each feature vector.! * P(S 1 x t ), P(S 2 x t ),, P(N x t )" Pool these probabilities across the entire conversation (t = 1,,T) and use them to re-estimate each respective speaker s GMM.! * The Non-speech GMM is never re-trained.! The Viterbi algorithm re-assigns each frame to the speaker/non-speech model with highest posterior probability.!
38 A Symbiotic Relationship! Clustering assumes some initial segmentation and clusters at the i-vector level! Better speaker representation! Re-segmentation operates at level of acoustic features! Finer temporal resolution!
39 Iterative System Optimization! Defining convergence! DER can be seen as a distance between two diarization hypotheses.!
40 Iterative System Optimization Results!
41 Diarization System So Far!
42 Diarization System So Far!
43 Final Pass Refinements (Interspeech 2011)! Extract a single i-vector for each respective speaker.! * Using the newly defined re-segmentation assignments " Re-assign each newly-extracted segment i-vector w i to the speaker i- vector {w 1, w 2,, w K } that is closer in cosine similarity.! * Winner Takes All! 1! 2! 3!! K! w i!
44 Final Pass Refinements (Interspeech 2011)! Extract a single i-vector for each respective speaker.! * Using the newly defined re-segmentation assignments " Re-assign each newly-extracted segment i-vector w i to the speaker i- vector {w 1, w 2,, w K } that is closer in cosine similarity.! * Winner Takes All! Iterate until convergence.! * i.e. when segment-speaker assignments no longer change!! Essentially a K-means algorithm! * Except determine means {w 1, w 2,, w K } via i-vector extraction!
45 Diarization System So Far!
46 Diarization System So Far!
47 i-vector Underrepresentation! i-vectors have been used as point estimates.! During clustering, we treat them as independent and identically distributed samples from some underlying GMM.! However, some i-vectors may be more equal than others.! i-vector from a 5-second speech segment versus 0.5-second segment! Recall: Given some speech,! The i-vector is a posterior mean of a Gaussian distribution! With an associated posterior covariance! cov( w) ( 1 ) I + T Σ N( u) 1 = T
48 Overcoming Underrepresentation! A Sampling Approach! Size of covariance is inversely proportional to number of frames N(u) in utterance u.! More frames used to extract i-vector à smaller covariance! cov( w) ( 1 ) I + T Σ N( u) 1 = T Consider sampling the i-vector distribution! Let the number of samples drawn be proportional to the number of frames used to extract the i-vector.! * Shorter segments à larger covariance and fewer samples! * Longer segments à smaller covariance and more samples!
49 A Simplified Cartoon! i! -! v e c! t o r! i! -! v e c! t o r! i! -! v e c! t o r! i! -! v e c! t o r! i! -! v e c! t o r!
50 Final System Diagram!
51 Proposed System Refinements! 35 System Configuration Refinements 30 Diarization Error Rate Spectral Initialization...with Iter. Re seg...and Duration Sampling Castaldo (303) 3 (136) 4 (43) 5 (10) 6 (6) 7 (2) Actual Number of Speakers (Number of Conversations)
52 Final System Comparisons! Diarization Error Rate Interspeech 2012 VBEM GMM Final Castaldo 2008 Interspeech 2011 (K = 2) Interspeech 2011 (K = given) Final System Comparisons (303) 3 (136) 4 (43) 5 (10) 6 (6) 7 (2) Actual Number of Speakers (Number of Conversations)
53 Reconciling Our 2-Speaker Results! Interspeech 2011 vs. Kenny 2010 vs. Castaldo 2008! State-of-the-art results on diarization on two-speaker telephone calls (number of speakers given)! Interspeech 2012! On the CallHome corpus, when it is known that the conversation contains only two participants! * DER = 5.2% vs. 8.7% (Castaldo 2008)!
54 DER Observations! Over-detecting the number of speakers! In the conversations where we correctly detect two speakers (136/303),! * DER = 6.5% vs. 8.7% (Castaldo 2008)! But DER is unforgiving towards overestimation! reference! hypothesis! Conversely, underestimation! reference! hypothesis!
55 Roadmap! Introduction! Summary of Contributions! Background! Diarization System Overview! Speaker Modeling with Factor Analysis! Our Incremental Approach! K-means and Spectral Clustering (Interspeech 2011, 2012)! Towards Probabilistic Clustering Methods! Iterative System Optimization (Re-segmentation/Clustering)! Duration-Proportional Sampling! Analysis and Discussion! Benchmark Comparison (Castaldo 2008)! Conclusion!
56 Explaining (Castaldo 2008)! Causal system with fixed output delay! Stream of factor analysis-based features (every 10ms)! 60-second slice! 2-spkr segmentation! Test for 3 rd speaker! Link to previous speakers! 60-second slice!
57 Summary of Differences! Castaldo 2008! Exploits structure of telephone conversations! * Assumes no more than 3 speakers exist in any 60-second slice! Explicit use of speaker recognition system! * Links speakers from current slice to previous slices! Our bag of i-vectors! More general approach to clustering! * Can handle any number of speakers, regardless of temporal conversation dynamics! * Prone to missing speakers that seldom participate! * Prone to separate speakers that participate often!
58 Future Work! Dimensionality Reduction! So far, only using first 3 principal components! t-sne (Stochastic Neighbor Embedding)! * van der Maaten 2008! Within-utterance Factor Analysis! Is there some way to directly exploit variabilities within the acoustic features of a particular conversation?! Temporal Modeling and Bayesian Nonparametric Inference! Hierarchical Dirichlet Process Hidden Markov Model (HDP-HMM)! * Fox 2008, Johnson 2010!
59 Summary! Extended previous work in applying factor analysis-based speaker modeling to speaker diarization! Castaldo 2008, Kenny 2010, Interspeech 2011/2012! Integrated variational inference into speaker clustering! Valente 2005, Kenny 2010, SM Thesis 2011! Validated an iterative optimization procedure to refine clustering and segmentation hypotheses! Interspeech 2012! Proposed a duration-proportional sampling scheme to combat issues of i-vector underrepresentation! SM Thesis 2011!
60 Thanks!! Questions?! csail.mit.edu!
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Digital Signal Processing: Speaker Recognition Final Report (Complete Version)
") Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS
 ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
ACOUSTIC EVENT DETECTION IN REAL LIFE RECORDINGS Annamaria Mesaros 1, Toni Heittola 1, Antti Eronen 2, Tuomas Virtanen 1 1 Department of Signal Processing Tampere University of Technology Korkeakoulunkatu
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing
 Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Using Articulatory Features and Inferred Phonological Segments in Zero Resource Speech Processing Pallavi Baljekar, Sunayana Sitaram, Prasanna Kumar Muthukumar, and Alan W Black Carnegie Mellon University,
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Spoofing and countermeasures for automatic speaker verification
 INTERSPEECH 2013 Spoofing and countermeasures for automatic speaker verification Nicholas Evans 1, Tomi Kinnunen 2 and Junichi Yamagishi 3,4 1 EURECOM, Sophia Antipolis, France 2 University of Eastern
INTERSPEECH 2013 Spoofing and countermeasures for automatic speaker verification Nicholas Evans 1, Tomi Kinnunen 2 and Junichi Yamagishi 3,4 1 EURECOM, Sophia Antipolis, France 2 University of Eastern
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment
 Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH
 STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
STUDIES WITH FABRICATED SWITCHBOARD DATA: EXPLORING SOURCES OF MODEL-DATA MISMATCH Don McAllaster, Larry Gillick, Francesco Scattone, Mike Newman Dragon Systems, Inc. 320 Nevada Street Newton, MA 02160
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques
 Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation
 UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Support Vector Machines for Speaker and Language Recognition
 Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY
 BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
BODY LANGUAGE ANIMATION SYNTHESIS FROM PROSODY AN HONORS THESIS SUBMITTED TO THE DEPARTMENT OF COMPUTER SCIENCE OF STANFORD UNIVERSITY Sergey Levine Principal Adviser: Vladlen Koltun Secondary Adviser:
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER DNN ACOUSTIC MODELS
 LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER DNN ACOUSTIC MODELS Pranay Dighe Afsaneh Asaei Hervé Bourlard Idiap Research Institute, Martigny, Switzerland École Polytechnique Fédérale de Lausanne (EPFL),
LOW-RANK AND SPARSE SOFT TARGETS TO LEARN BETTER DNN ACOUSTIC MODELS Pranay Dighe Afsaneh Asaei Hervé Bourlard Idiap Research Institute, Martigny, Switzerland École Polytechnique Fédérale de Lausanne (EPFL),
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Investigation on Mandarin Broadcast News Speech Recognition
 Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
Investigation on Mandarin Broadcast News Speech Recognition Mei-Yuh Hwang 1, Xin Lei 1, Wen Wang 2, Takahiro Shinozaki 1 1 Univ. of Washington, Dept. of Electrical Engineering, Seattle, WA 98195 USA 2
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations
 A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
arxiv:cmp-lg/ v1 22 Aug 1994
 arxiv:cmp-lg/94080v 22 Aug 994 DISTRIBUTIONAL CLUSTERING OF ENGLISH WORDS Fernando Pereira AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974 pereira@research.att.com Abstract We describe and
arxiv:cmp-lg/94080v 22 Aug 994 DISTRIBUTIONAL CLUSTERING OF ENGLISH WORDS Fernando Pereira AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974 pereira@research.att.com Abstract We describe and
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Finding Your Friends and Following Them to Where You Are
 Finding Your Friends and Following Them to Where You Are Adam Sadilek Dept. of Computer Science University of Rochester Rochester, NY, USA sadilek@cs.rochester.edu Henry Kautz Dept. of Computer Science
Finding Your Friends and Following Them to Where You Are Adam Sadilek Dept. of Computer Science University of Rochester Rochester, NY, USA sadilek@cs.rochester.edu Henry Kautz Dept. of Computer Science
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation
 Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong