Machine Translation using Deep Learning Methods Max Fomin Michael Zolotov
|
|
|
- Dana Henderson
- 5 years ago
- Views:
Transcription


1 Machine Translation using Deep Learning Methods Max Fomin Michael Zolotov Sequence to Sequence Learning with Neural Networks Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation





2 Topics Ahead Problem Definition Network Architecture Network Training Results
3 History of Machine Translation Source Sentence Source Sentence Source Sentence Source Sentence Traditional SMT Traditional SMT Traditional SMT Neural Network Neural Network Neural Network Target Sentence Target Sentence Target Sentence Target Sentence A few years ago Recently More recently
4 Problem Definition

5 Types of RNN Problems Regular CNN Model Image Captioning Sentiment Analysis Machine Translation Video Classification

6 Limitations of current methods Only fixed inputs! Only problems whose inputs and targets can be encoded with fixed dimensionality.

7 Text Translation! English to French Translation The WMT 14 English to French dataset was used. The models were trained on a subset of 12M sentences consisting of 348M French words and 304M English words. Vocabulary Filtering As typical neural language models rely on a vector representation for each word, we used a fixed vocabulary for both languages. We used 160,000 of the most frequent words for the source language and 80,000 of the most frequent words for the target language. Every out-of-vocabulary word was replaced with a special UNK token.




8 The BLEU Score Higher is Better More reference human translations Better and more accurate scores Scores over 30: Understandable translations Scores over 50: Good and fluent translations
9 Some Background

10 Classical RNNs Memory is a powerful tool! Humans don t start their thinking from scratch every second. Sequential Data A recurrent neural network can be thought of as multiple copies of the same network, each passing a message to a successor. This chain-like nature makes them a natural architecture for sequential data.



11 Long-Term Dependencies the clouds are in the sky, I grew up in France I speak fluent French.


12 LSTMs Long Short-Term Memory Networks A special kind of RNN, capable of learning long-term dependencies. They work tremendously well on a large variety of problems, and are now widely used. Long-Term Dependencies LSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!
13 LSTMs
14 LSTMs
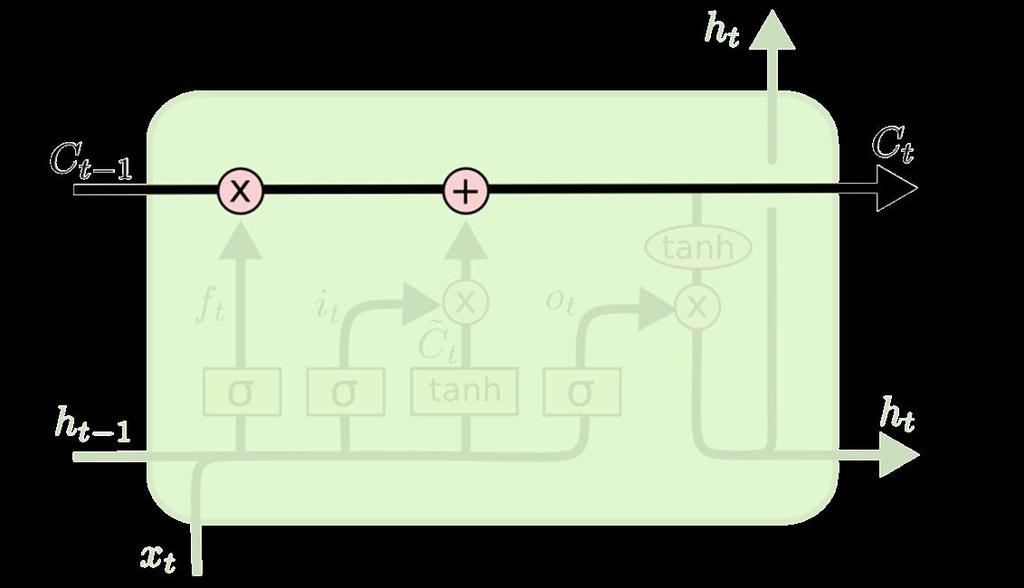

15 LSTMs
16 LSTMs



17 GRUs Must Be Mentioned! A slightly more dramatic variation on the LSTM It combines the forget and input gates into a single update gate. It also merges the cell state and hidden state, and makes some other changes. The resulting model is simpler than standard LSTM models, and has been growing increasingly popular.
18 Network Architecture

19 High Level Architecture Sequence Input The idea is to use one LSTM to read the input sequence, one time step at a time, to obtain large fixed dimensional vector representation Sequence Output We use another LSTM to extract the output sequence from that vector. The second LSTM is essentially a recurrent neural network language model except that it is conditioned on the input sequence. W X Y Z <EOS> W X Y Z A B C <EOL>
20 High Level Architecture Overall Process Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector LSTM ENCODER Comment Allez Vous <EOL> How Are You <EOL> LSTM DECODER

21 A Similar Concept: Word Embeddings
22 A Similar Concept: Word Embeddings

23 A Similar Concept: Image Embeddings

24 A Similar Concept: Multiple Object Embeddings
25 A Classical Approach: Statistical Machine Translation Definition A machine translation paradigm where translations are generated on the basis of statistical models whose parameters are derived from the analysis of bilingual text corpora Goal Finding a translation f, given a source sentence e, which maximizes the p f e p e f) p(f) Phrase Based Creating translation probabilities of matching phrases in the source and target sentences in order to factorize p e f)
26 Network Training



27 Classic LSTMs VS Our Model we used two different LSTMs: one for the input sequence and another for the output sequence p y 1,, y T x 1,, x T = T p(y t v, y 1,, y t 1 t=1 Deep LSTMs significantly outperformed shallow LSTMs, so we chose an LSTM with four layers where, x 1,, x T the input sequence y 1,, y T the output sequence It was extremely valuable to reverse the order of the words of the input sentence

28 Reversed Word Order! LSTM ENCODER α β γ <EOL> C B A <EOL> LSTM DECODER
29 Training Details 4 layers of LSTMs 1000 cells at each layer 1000 dimensional word embeddings An input vocabulary of 160,000 An output vocabulary of 80,000
30 Training Details Each additional layer reduced perplexity by nearly 10%. We used a naive softmax over 80,000 words at each output. The resulting LSTM has 380M parameters of which 64M are pure recurrent connections (32M for the encoder LSTM and 32M for the decoder LSTM).
31 Training Details We initialized all of the LSTM s parameters with the uniform distribution between and We used SGD without momentum, with a fixed learning rate of 0.7. After 5 epochs, we begun halving the learning rate every half epoch. We trained our models for a total of 7.5 epochs. We used batches of 128 sequences for the gradient and divided it the size of the batch. Thus we enforced a hard constraint on the norm of the gradient by scaling it when its norm exceeded a threshold. Different sentences have different lengths. Most sentences are short but some sentences are long. We made sure that all sentences within a mini-batch were roughly of the same length, resulting in a 2x speedup.
32 Training Details A C++ implementation of deep LSTM with the configuration from the previous section on a single GPU processes a speed of approximately 1,700 words per second. We parallelized our model using an 8-GPU machine. Each layer of the LSTM was executed on a different GPU and communicated its activations to the next GPU (or layer) as soon as they were computed. The remaining 4 GPUs were used to parallelize the softmax, so each GPU was responsible for multiplying by a matrix. The resulting implementation achieved a speed of 6,300 (both English and French) words per second with a minibatch size of 128. Training took about a ten days with this implementation.
33 Beam-Search Decoder Heuristic Search Algorithm Explores a graph by expanding the most promising node in a limited set. Beam search is an optimization of best-first search that reduces its memory requirements. Greedy Algorithm Best-first search is a graph search which orders all partial solutions (states) according to some heuristic which attempts to predict how close a partial solution is to a complete solution. In beam search, only a predetermined number of best partial solutions are kept as candidates. S A B C D E F G H
34 Beam-Search Decoder We search for the most likely translation using a simple left-to-right beam search decoder. We maintain a small number B of partial hypotheses. At each time step, we extend each partial hypothesis in the beam with every possible word. we discard all but the B most likely hypotheses according to the model s log probability. As soon as the symbol is appended to a hypothesis, it is removed from the beam. A beam of size 2 provides most of the benefits of beam search. S A B C D E F G H
35 Results

36 Some Tables

37 Some Tables

38 Some Plots
39 LSTM Hidden States The figure shows a 2D PCA projection of the LSTM hidden states. Notice that both clusters have similar internal structure.
40 Conclusions A large deep LSTM with a limited vocabulary can outperform a standard SMT-based system with an unlimited vocabulary Reversing the words in the source sentences gave surprising results The ability of the LSTM to correctly translate very long sentences was surprising A simple straightforward approach can outperform a mature SMT system

41 Thank You!
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
arxiv: v4 [cs.cl] 28 Mar 2016
![arxiv: v4 [cs.cl] 28 Mar 2016](/thumbs/71/65993810.jpg "arxiv: v4 [cs.cl] 28 Mar 2016") LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
LSTM-BASED DEEP LEARNING MODELS FOR NON- FACTOID ANSWER SELECTION Ming Tan, Cicero dos Santos, Bing Xiang & Bowen Zhou IBM Watson Core Technologies Yorktown Heights, NY, USA {mingtan,cicerons,bingxia,zhou}@us.ibm.com
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
arxiv: v1 [cs.cl] 27 Apr 2016
![arxiv: v1 [cs.cl] 27 Apr 2016](/thumbs/71/66223940.jpg "arxiv: v1 [cs.cl] 27 Apr 2016") The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
The IBM 2016 English Conversational Telephone Speech Recognition System George Saon, Tom Sercu, Steven Rennie and Hong-Kwang J. Kuo IBM T. J. Watson Research Center, Yorktown Heights, NY, 10598 gsaon@us.ibm.com
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Distributed Learning of Multilingual DNN Feature Extractors using GPUs
 Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
Large vocabulary off-line handwriting recognition: A survey
 Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Pattern Anal Applic (2003) 6: 97 121 DOI 10.1007/s10044-002-0169-3 ORIGINAL ARTICLE A. L. Koerich, R. Sabourin, C. Y. Suen Large vocabulary off-line handwriting recognition: A survey Received: 24/09/01
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Improvements to the Pruning Behavior of DNN Acoustic Models
 Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Improvements to the Pruning Behavior of DNN Acoustic Models Matthias Paulik Apple Inc., Infinite Loop, Cupertino, CA 954 mpaulik@apple.com Abstract This paper examines two strategies that positively influence
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017
 What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
What Can Neural Networks Teach us about Language? Graham Neubig a2-dlearn 11/18/2017 Supervised Training of Neural Networks for Language Training Data Training Model this is an example the cat went to
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Offline Writer Identification Using Convolutional Neural Network Activation Features
 Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
Pattern Recognition Lab Department Informatik Universität Erlangen-Nürnberg Prof. Dr.-Ing. habil. Andreas Maier Telefon: +49 9131 85 27775 Fax: +49 9131 303811 info@i5.cs.fau.de www5.cs.fau.de Offline
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing
 Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
Ask Me Anything: Dynamic Memory Networks for Natural Language Processing Ankit Kumar*, Ozan Irsoy*, Peter Ondruska*, Mohit Iyyer*, James Bradbury, Ishaan Gulrajani*, Victor Zhong*, Romain Paulus, Richard
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval
 A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval Yelong Shen Microsoft Research Redmond, WA, USA yeshen@microsoft.com Xiaodong He Jianfeng Gao Li Deng Microsoft Research
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках
 Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
Глубокие рекуррентные нейронные сети для аспектно-ориентированного анализа тональности отзывов пользователей на различных языках Тарасов Д. С. (dtarasov3@gmail.com) Интернет-портал reviewdot.ru, Казань,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
arxiv: v3 [cs.cl] 7 Feb 2017
![arxiv: v3 [cs.cl] 7 Feb 2017](/thumbs/71/66154314.jpg "arxiv: v3 [cs.cl] 7 Feb 2017") NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
NEWSQA: A MACHINE COMPREHENSION DATASET Adam Trischler Tong Wang Xingdi Yuan Justin Harris Alessandro Sordoni Philip Bachman Kaheer Suleman {adam.trischler, tong.wang, eric.yuan, justin.harris, alessandro.sordoni,
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
A deep architecture for non-projective dependency parsing
 Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
Universidade de São Paulo Biblioteca Digital da Produção Intelectual - BDPI Departamento de Ciências de Computação - ICMC/SCC Comunicações em Eventos - ICMC/SCC 2015-06 A deep architecture for non-projective
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation
 2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,
2014 14th International Conference on Frontiers in Handwriting Recognition The A2iA Multi-lingual Text Recognition System at the second Maurdor Evaluation Bastien Moysset,Théodore Bluche, Maxime Knibbe,