Cross-Lingual Information Retrieval. Language Technology I
|
|
|
- Martina Brooks
- 5 years ago
- Views:
Transcription

1 Cross-Lingual Information Retrieval Language Technology I
2 Terminology monolingual, multilingual, cross-lingual Query (en) monolingual Documents (en) Query (en) Query (de) multilingual Documents (en) Documents (de) Query (en) Query (de) croslingual Documents (en) Documents (de)
3 Use Scenarios (I) a user has no knowledge of a target language, i.e., she cannot search for documents in that language at all with CLIR she can make use of media data pools that are indexed with captions in that language, for example for picture pools, music databases, etc. with CLIR she can get a pre-selection of documents that can then be passed on to a translator
4 Use Scenarios (II) a user has only passive knowledge of a target language, i.e., she cannot actively search for documents in that language with CLIR she can make use of relevant texts
5 Use Scenarios (III) a document collection has such a large number of languages that it would be impractical to formulate a query in each of these languages with CLIR one could get relevant documents with only a search query in one of these languages
6 CLIR approaches Machine translation: uses NLP tools like PoS-tagger, parser, morphological analyzers, etc. Thesaurus-based approaches manual use of thesauri: controlled vocabulary systems automatic use of thesauri: concept retrieval systems Corpus-based methods: work with frequency analysis Implication: aboutness of the two collections should be similar
7 MT Approach - Architecture CLIR Index (de)??? Query (en) Documents (de) Document Translation Query (en) Index (de) Index (en) Documents (de) Documents (en) Index Translation Query (en) Index (de) Index (en) Documents (de) Query (de) Index (de) Documents (de) Query (en) Query Translation
8 Document Translation Problem solved by multiplying the texts Make texts available in all languages multilingual (= several monolingual) retrieval Feasibility: Required in some applications Patents, multilingual states (EG, Belgium, ) Impossible in other areas (Internet) Evaluation: From costly to impossible Results depend on translation quality translation dictionary updates invalidate search on existing document pool (->retranslate everything)
9 Index Translation Idea: multilingual Index Analyze query in query language, translate terms Search with all document language index terms (Problem of retranslation of the hits) Feasibility: Not feasible Ambiguity of index terms Multiword terms not in index Context dependency of translations Fehler: mistake, fault, error, bug nuclear: Kern~, zentral, nuklear power: Macht, Kraft, Strom plant: Pflanze, Unternehmen => Organize the index as a special resource!
10 Query Translation Approach: Translation of query Analyse and translate the query terms Search in (monolingual) Backend-System Evaluation Backend database stays unchanged Translation changes do not affect document base Cross-lingual component as system frontend contains multilingual linguistic resource Which is also usable for re-translation And can be maintained independently Cross-linguality is transparent for the users Fine-tuning between frontend and backend required
11 MT Approach pros: straightforward (if an MT system is available) user can directly use the retrieved documents documents usually have more context which allows more robust MT than for query translation cons: translation of document collections may be very time consuming offline translation of document collections may require lots of additional storage inherits most weaknesses of MT and MT system implementations
12 Thesaurus-Based Approach: Thesauri thesaurus: a resource which organizes the terminology of a domain of knowledge, i.e., an ontology for terminology multilingual thesauri encode usually: cross-linguistic synonymy sometimes: hierarchical relations between terms (hyperonymy,hyponymy, etc.) seldom: associative relations between terms the thesaurus-based approach to CLIR uses multilingual thesauri has a rather broad definition of a thesaurus examples of multilingual thesauri used for CLIR: simple cross-language synonym lists collection of concepts with attached cross-lingual information classic syntax and semantics lexicons
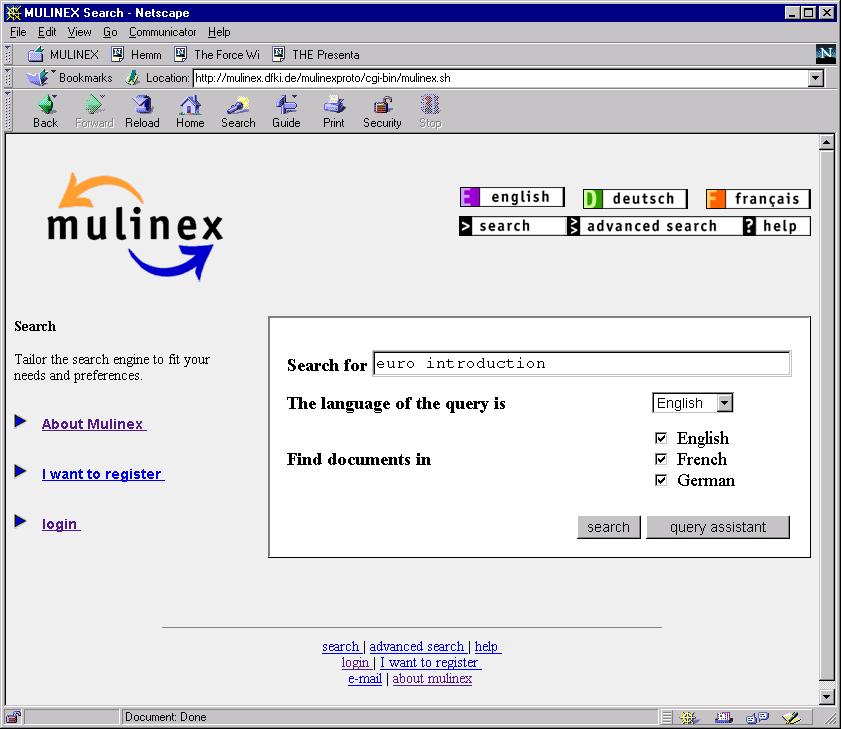
13
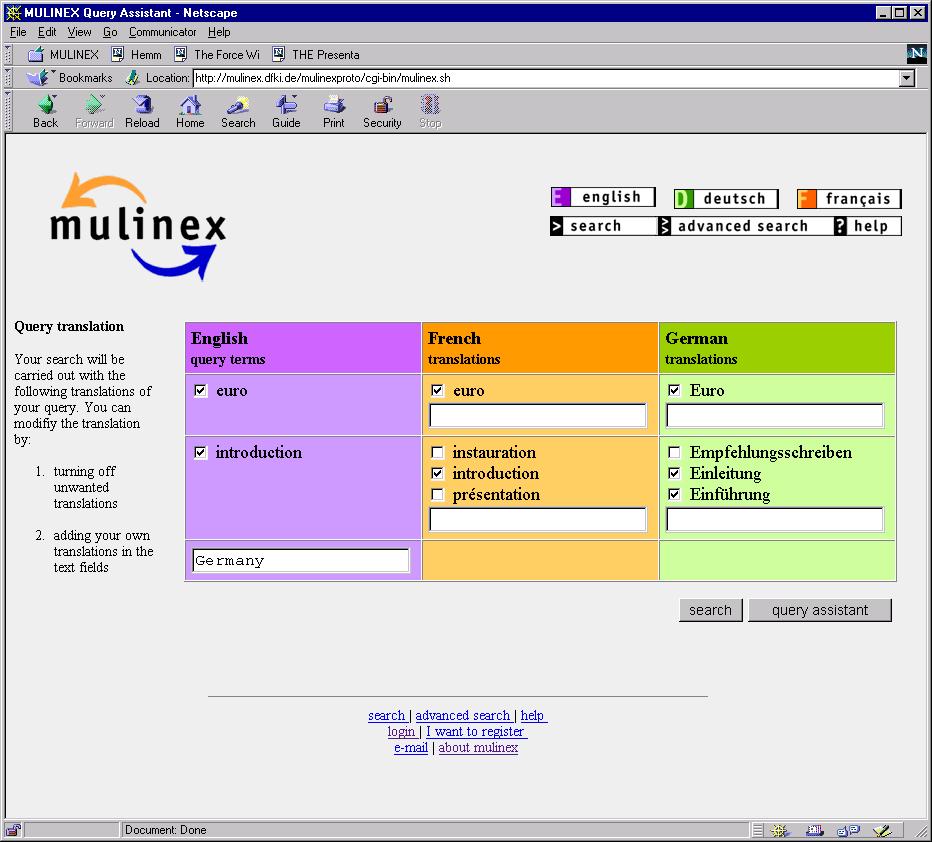
14
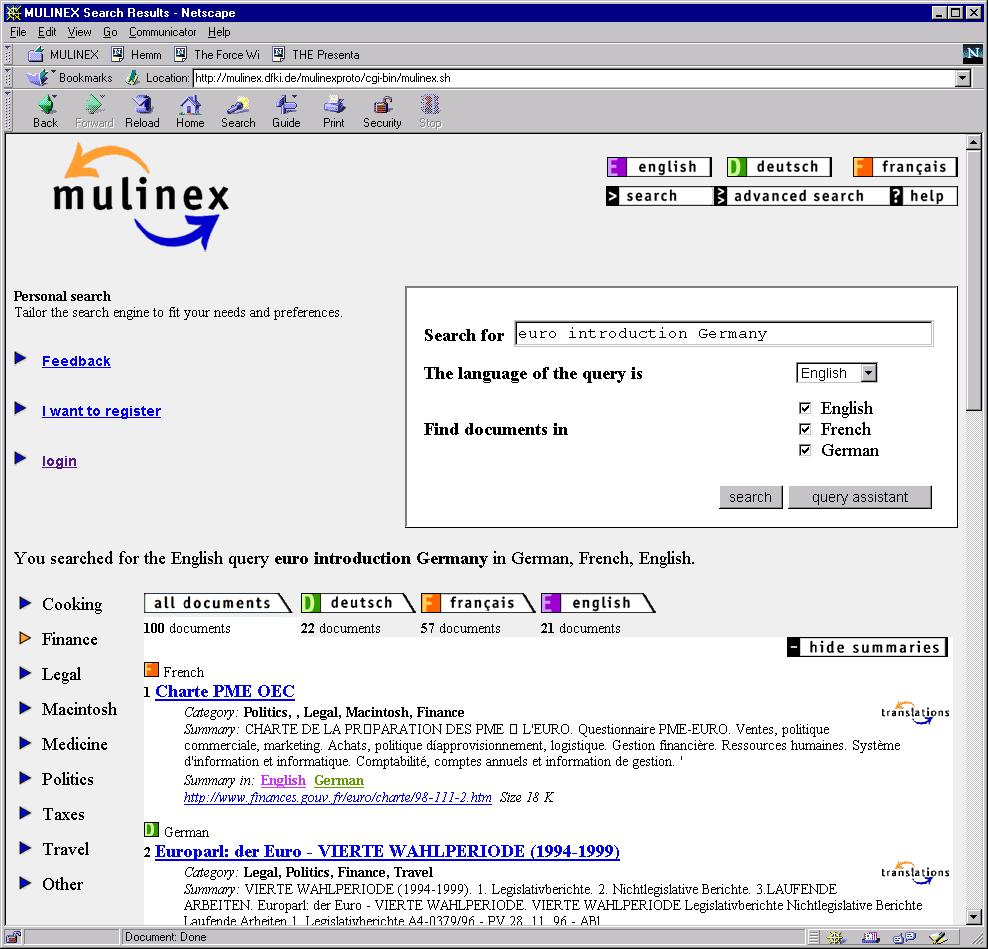
15
16 Thesaurus-Based Approach: Thesauri pros: very productive, especially for skilled users works transparently for the user unambiguous mapping between the query and the target document cons: very expensive to create good thesauri target documents must be labeled with concepts may be difficult to use for unexperienced users (e.g., because of the manual selection of the intended concept) doesn t scale restricted to certain domains IR queries can only be as precise as the predefined thesaurus concepts
17 Corpus-Based Approach use of statistical information about term usage from parallel corpora usually based on two general retrieval principles: target documents with frequent usage of query terms are potentially more relevant than target documents with infrequent query term usage rare query terms are more useful than query terms that are very frequent in the overall target document collection pros: usage of recent terminology (as provided by the corpora) is possible cons: parallel corpora needed restricted to the domains of the parallel corpora
18 Pseudo-Relevance Feedback Enter query terms in French Find top French documents in parallel corpus Construct a query from English translations Perform a monolingual free text search
19 Learning From Document Pairs Count how often each term occurs in each pair Treat each pair as a single document English Terms Spanish Terms E1 E2 E3 E4 E5 S1 S2 S3 S4 Doc 1 Doc 2 Doc 3 Doc 4 Doc
20 Similarity based Dictionaries Automatically developed from aligned documents Terms E1 and E3 are used in similar ways Terms E1 & S1 (or E3 & S4) are even more similar For each term, find most similar in other language Retain only the top few (5 or so)
21 CLIR Research Community Text REtrieval Conference (TREC, Arabic, English, Spanish, Chinese, etc. CLIR at TREC: Cross-Language Evaluation Forum (CLEF) European languages NTCIR (NII Test Collection for IR Systems) with related workshops Information Retrieval for Asian Language (IRAL) internaltional workshop and quite a few others
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY
 MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
MULTILINGUAL INFORMATION ACCESS IN DIGITAL LIBRARY Chen, Hsin-Hsi Department of Computer Science and Information Engineering National Taiwan University Taipei, Taiwan E-mail: hh_chen@csie.ntu.edu.tw Abstract
Cross-Lingual Text Categorization
 Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Multilingual Information Access Douglas W. Oard College of Information Studies, University of Maryland, College Park
 Multilingual Information Access Douglas W. Oard College of Information Studies, University of Maryland, College Park Keywords Information retrieval, Information seeking behavior, Multilingual, Cross-lingual,
Multilingual Information Access Douglas W. Oard College of Information Studies, University of Maryland, College Park Keywords Information retrieval, Information seeking behavior, Multilingual, Cross-lingual,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Combining Bidirectional Translation and Synonymy for Cross-Language Information Retrieval
 Combining Bidirectional Translation and Synonymy for Cross-Language Information Retrieval Jianqiang Wang and Douglas W. Oard College of Information Studies and UMIACS University of Maryland, College Park,
Combining Bidirectional Translation and Synonymy for Cross-Language Information Retrieval Jianqiang Wang and Douglas W. Oard College of Information Studies and UMIACS University of Maryland, College Park,
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Ontological spine, localization and multilingual access
 Start Ontological spine, localization and multilingual access Some reflections and a proposal New Perspectives on Subject Indexing and Classification in an International Context International Symposium
Start Ontological spine, localization and multilingual access Some reflections and a proposal New Perspectives on Subject Indexing and Classification in an International Context International Symposium
Matching Meaning for Cross-Language Information Retrieval
 Matching Meaning for Cross-Language Information Retrieval Jianqiang Wang Department of Library and Information Studies University at Buffalo, the State University of New York Buffalo, NY 14260, U.S.A.
Matching Meaning for Cross-Language Information Retrieval Jianqiang Wang Department of Library and Information Studies University at Buffalo, the State University of New York Buffalo, NY 14260, U.S.A.
Controlled vocabulary
 Indexing languages 6.2.2. Controlled vocabulary Overview Anyone who has struggled to find the exact search term to retrieve information about a certain subject can benefit from controlled vocabulary. Controlled
Indexing languages 6.2.2. Controlled vocabulary Overview Anyone who has struggled to find the exact search term to retrieve information about a certain subject can benefit from controlled vocabulary. Controlled
Language Independent Passage Retrieval for Question Answering
 Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
CROSS LANGUAGE INFORMATION RETRIEVAL: IN INDIAN LANGUAGE PERSPECTIVE
 CROSS LANGUAGE INFORMATION RETRIEVAL: IN INDIAN LANGUAGE PERSPECTIVE Pratibha Bajpai 1, Dr. Parul Verma 2 1 Research Scholar, Department of Information Technology, Amity University, Lucknow 2 Assistant
CROSS LANGUAGE INFORMATION RETRIEVAL: IN INDIAN LANGUAGE PERSPECTIVE Pratibha Bajpai 1, Dr. Parul Verma 2 1 Research Scholar, Department of Information Technology, Amity University, Lucknow 2 Assistant
Resolving Ambiguity for Cross-language Retrieval
 Resolving Ambiguity for Cross-language Retrieval Lisa Ballesteros balleste@cs.umass.edu Center for Intelligent Information Retrieval Computer Science Department University of Massachusetts Amherst, MA
Resolving Ambiguity for Cross-language Retrieval Lisa Ballesteros balleste@cs.umass.edu Center for Intelligent Information Retrieval Computer Science Department University of Massachusetts Amherst, MA
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
BYLINE [Heng Ji, Computer Science Department, New York University,
 INFORMATION EXTRACTION BYLINE [Heng Ji, Computer Science Department, New York University, hengji@cs.nyu.edu] SYNONYMS NONE DEFINITION Information Extraction (IE) is a task of extracting pre-specified types
INFORMATION EXTRACTION BYLINE [Heng Ji, Computer Science Department, New York University, hengji@cs.nyu.edu] SYNONYMS NONE DEFINITION Information Extraction (IE) is a task of extracting pre-specified types
Test Blueprint. Grade 3 Reading English Standards of Learning
 Test Blueprint Grade 3 Reading 2010 English Standards of Learning This revised test blueprint will be effective beginning with the spring 2017 test administration. Notice to Reader In accordance with the
Test Blueprint Grade 3 Reading 2010 English Standards of Learning This revised test blueprint will be effective beginning with the spring 2017 test administration. Notice to Reader In accordance with the
Modeling full form lexica for Arabic
 Modeling full form lexica for Arabic Susanne Alt Amine Akrout Atilf-CNRS Laurent Romary Loria-CNRS Objectives Presentation of the current standardization activity in the domain of lexical data modeling
Modeling full form lexica for Arabic Susanne Alt Amine Akrout Atilf-CNRS Laurent Romary Loria-CNRS Objectives Presentation of the current standardization activity in the domain of lexical data modeling
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
A heuristic framework for pivot-based bilingual dictionary induction
 2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
2013 International Conference on Culture and Computing A heuristic framework for pivot-based bilingual dictionary induction Mairidan Wushouer, Toru Ishida, Donghui Lin Department of Social Informatics,
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data
 Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Target Language Preposition Selection an Experiment with Transformation-Based Learning and Aligned Bilingual Data Ebba Gustavii Department of Linguistics and Philology, Uppsala University, Sweden ebbag@stp.ling.uu.se
Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data
 Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data Maja Popović and Hermann Ney Lehrstuhl für Informatik VI, Computer
Exploiting Phrasal Lexica and Additional Morpho-syntactic Language Resources for Statistical Machine Translation with Scarce Training Data Maja Popović and Hermann Ney Lehrstuhl für Informatik VI, Computer
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels
 Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
Cross-Lingual Dependency Parsing with Universal Dependencies and Predicted PoS Labels Jörg Tiedemann Uppsala University Department of Linguistics and Philology firstname.lastname@lingfil.uu.se Abstract
ScienceDirect. Malayalam question answering system
 Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Comparing different approaches to treat Translation Ambiguity in CLIR: Structured Queries vs. Target Co occurrence Based Selection
 1 Comparing different approaches to treat Translation Ambiguity in CLIR: Structured Queries vs. Target Co occurrence Based Selection X. Saralegi, M. Lopez de Lacalle Elhuyar R&D Zelai Haundi kalea, 3.
1 Comparing different approaches to treat Translation Ambiguity in CLIR: Structured Queries vs. Target Co occurrence Based Selection X. Saralegi, M. Lopez de Lacalle Elhuyar R&D Zelai Haundi kalea, 3.
Word Sense Disambiguation
 Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
Word Sense Disambiguation D. De Cao R. Basili Corso di Web Mining e Retrieval a.a. 2008-9 May 21, 2009 Excerpt of the R. Mihalcea and T. Pedersen AAAI 2005 Tutorial, at: http://www.d.umn.edu/ tpederse/tutorials/advances-in-wsd-aaai-2005.ppt
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Text-to-Speech Application in Audio CASI
 Text-to-Speech Application in Audio CASI Evaluation of Implementation and Deployment Jeremy Kraft and Wes Taylor International Field Directors & Technologies Conference 2006 May 21 May 24 www.uwsc.wisc.edu
Text-to-Speech Application in Audio CASI Evaluation of Implementation and Deployment Jeremy Kraft and Wes Taylor International Field Directors & Technologies Conference 2006 May 21 May 24 www.uwsc.wisc.edu
Evaluation for Scenario Question Answering Systems
 Evaluation for Scenario Question Answering Systems Matthew W. Bilotti and Eric Nyberg Language Technologies Institute Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, Pennsylvania 15213 USA {mbilotti,
Evaluation for Scenario Question Answering Systems Matthew W. Bilotti and Eric Nyberg Language Technologies Institute Carnegie Mellon University 5000 Forbes Avenue Pittsburgh, Pennsylvania 15213 USA {mbilotti,
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Constructing Parallel Corpus from Movie Subtitles
 Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
Constructing Parallel Corpus from Movie Subtitles Han Xiao 1 and Xiaojie Wang 2 1 School of Information Engineering, Beijing University of Post and Telecommunications artex.xh@gmail.com 2 CISTR, Beijing
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
1. Introduction. 2. The OMBI database editor
 OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
Dictionary-based techniques for cross-language information retrieval q
 Information Processing and Management 41 (2005) 523 547 www.elsevier.com/locate/infoproman Dictionary-based techniques for cross-language information retrieval q Gina-Anne Levow a, *, Douglas W. Oard b,
Information Processing and Management 41 (2005) 523 547 www.elsevier.com/locate/infoproman Dictionary-based techniques for cross-language information retrieval q Gina-Anne Levow a, *, Douglas W. Oard b,
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Project in the framework of the AIM-WEST project Annotation of MWEs for translation
 Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Project in the framework of the AIM-WEST project Annotation of MWEs for translation 1 Agnès Tutin LIDILEM/LIG Université Grenoble Alpes 30 october 2014 Outline 2 Why annotate MWEs in corpora? A first experiment
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
English-German Medical Dictionary And Phrasebook By A.H. Zemback
 English-German Medical Dictionary And Phrasebook By A.H. Zemback If you are searching for a ebook English-German Medical Dictionary and Phrasebook by A.H. Zemback in pdf form, then you've come to loyal
English-German Medical Dictionary And Phrasebook By A.H. Zemback If you are searching for a ebook English-German Medical Dictionary and Phrasebook by A.H. Zemback in pdf form, then you've come to loyal
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Integrating Semantic Knowledge into Text Similarity and Information Retrieval
 Integrating Semantic Knowledge into Text Similarity and Information Retrieval Christof Müller, Iryna Gurevych Max Mühlhäuser Ubiquitous Knowledge Processing Lab Telecooperation Darmstadt University of
Integrating Semantic Knowledge into Text Similarity and Information Retrieval Christof Müller, Iryna Gurevych Max Mühlhäuser Ubiquitous Knowledge Processing Lab Telecooperation Darmstadt University of
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
LANGUAGE IN INDIA Strength for Today and Bright Hope for Tomorrow Volume 11 : 12 December 2011 ISSN
 LANGUAGE IN INDIA Strength for Today and Bright Hope for Tomorrow Volume ISSN 1930-2940 Managing Editor: M. S. Thirumalai, Ph.D. Editors: B. Mallikarjun, Ph.D. Sam Mohanlal, Ph.D. B. A. Sharada, Ph.D.
LANGUAGE IN INDIA Strength for Today and Bright Hope for Tomorrow Volume ISSN 1930-2940 Managing Editor: M. S. Thirumalai, Ph.D. Editors: B. Mallikarjun, Ph.D. Sam Mohanlal, Ph.D. B. A. Sharada, Ph.D.
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
arxiv:cs/ v2 [cs.cl] 7 Jul 1999
![arxiv:cs/ v2 [cs.cl] 7 Jul 1999](/thumbs/71/66212057.jpg "arxiv:cs/ v2 [cs.cl] 7 Jul 1999") Cross-Language Information Retrieval for Technical Documents Atsushi Fujii and Tetsuya Ishikawa University of Library and Information Science 1-2 Kasuga Tsukuba 35-855, JAPAN {fujii,ishikawa}@ulis.ac.jp
Cross-Language Information Retrieval for Technical Documents Atsushi Fujii and Tetsuya Ishikawa University of Library and Information Science 1-2 Kasuga Tsukuba 35-855, JAPAN {fujii,ishikawa}@ulis.ac.jp
Performance Analysis of Optimized Content Extraction for Cyrillic Mongolian Learning Text Materials in the Database
 Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS
 DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS Julia Tmshkina Centre for Text Techitology, North-West University, 253 Potchefstroom, South Africa 2025770@puk.ac.za
DEVELOPMENT OF A MULTILINGUAL PARALLEL CORPUS AND A PART-OF-SPEECH TAGGER FOR AFRIKAANS Julia Tmshkina Centre for Text Techitology, North-West University, 253 Potchefstroom, South Africa 2025770@puk.ac.za
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
The role of the first language in foreign language learning. Paul Nation. The role of the first language in foreign language learning
 1 Article Title The role of the first language in foreign language learning Author Paul Nation Bio: Paul Nation teaches in the School of Linguistics and Applied Language Studies at Victoria University
1 Article Title The role of the first language in foreign language learning Author Paul Nation Bio: Paul Nation teaches in the School of Linguistics and Applied Language Studies at Victoria University
2.1 The Theory of Semantic Fields
 2 Semantic Domains In this chapter we define the concept of Semantic Domain, recently introduced in Computational Linguistics [56] and successfully exploited in NLP [29]. This notion is inspired by the
2 Semantic Domains In this chapter we define the concept of Semantic Domain, recently introduced in Computational Linguistics [56] and successfully exploited in NLP [29]. This notion is inspired by the
Using Virtual Manipulatives to Support Teaching and Learning Mathematics
 Using Virtual Manipulatives to Support Teaching and Learning Mathematics Joel Duffin Abstract The National Library of Virtual Manipulatives (NLVM) is a free website containing over 110 interactive online
Using Virtual Manipulatives to Support Teaching and Learning Mathematics Joel Duffin Abstract The National Library of Virtual Manipulatives (NLVM) is a free website containing over 110 interactive online
A Topic Maps-based ontology IR system versus Clustering-based IR System: A Comparative Study in Security Domain
 A Topic Maps-based ontology IR system versus Clustering-based IR System: A Comparative Study in Security Domain Myongho Yi 1 and Sam Gyun Oh 2* 1 School of Library and Information Studies, Texas Woman
A Topic Maps-based ontology IR system versus Clustering-based IR System: A Comparative Study in Security Domain Myongho Yi 1 and Sam Gyun Oh 2* 1 School of Library and Information Studies, Texas Woman
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The development of a new learner s dictionary for Modern Standard Arabic: the linguistic corpus approach
 BILINGUAL LEARNERS DICTIONARIES The development of a new learner s dictionary for Modern Standard Arabic: the linguistic corpus approach Mark VAN MOL, Leuven, Belgium Abstract This paper reports on the
BILINGUAL LEARNERS DICTIONARIES The development of a new learner s dictionary for Modern Standard Arabic: the linguistic corpus approach Mark VAN MOL, Leuven, Belgium Abstract This paper reports on the
Machine Translation on the Medical Domain: The Role of BLEU/NIST and METEOR in a Controlled Vocabulary Setting
 Machine Translation on the Medical Domain: The Role of BLEU/NIST and METEOR in a Controlled Vocabulary Setting Andre CASTILLA castilla@terra.com.br Alice BACIC Informatics Service, Instituto do Coracao
Machine Translation on the Medical Domain: The Role of BLEU/NIST and METEOR in a Controlled Vocabulary Setting Andre CASTILLA castilla@terra.com.br Alice BACIC Informatics Service, Instituto do Coracao
Introduction, Organization Overview of NLP, Main Issues
 HG2051 Language and the Computer Computational Linguistics with Python Introduction, Organization Overview of NLP, Main Issues Francis Bond Division of Linguistics and Multilingual Studies http://www3.ntu.edu.sg/home/fcbond/
HG2051 Language and the Computer Computational Linguistics with Python Introduction, Organization Overview of NLP, Main Issues Francis Bond Division of Linguistics and Multilingual Studies http://www3.ntu.edu.sg/home/fcbond/
Postprint.
 http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
CROSS LANGUAGE INFORMATION RETRIEVAL FOR LANGUAGES WITH SCARCE RESOURCES. Christian E. Loza. Thesis Prepared for the Degree of MASTER OF SCIENCE
 CROSS LANGUAGE INFORMATION RETRIEVAL FOR LANGUAGES WITH SCARCE RESOURCES Christian E. Loza Thesis Prepared for the Degree of MASTER OF SCIENCE UNIVERSITY OF NORTH TEXAS May 2009 APPROVED: Rada Mihalcea,
CROSS LANGUAGE INFORMATION RETRIEVAL FOR LANGUAGES WITH SCARCE RESOURCES Christian E. Loza Thesis Prepared for the Degree of MASTER OF SCIENCE UNIVERSITY OF NORTH TEXAS May 2009 APPROVED: Rada Mihalcea,
A Minimalist Approach to Code-Switching. In the field of linguistics, the topic of bilingualism is a broad one. There are many
 Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Schmidt 1 Eric Schmidt Prof. Suzanne Flynn Linguistic Study of Bilingualism December 13, 2013 A Minimalist Approach to Code-Switching In the field of linguistics, the topic of bilingualism is a broad one.
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities
 on Natural Language Processing for Digital Humanities") Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities Simon Clematide, Isabel Meraner, Noah Bubenhofer, Martin Volk Institute of Computational Linguistics
Lessons from a Massive Open Online Course (MOOC) on Natural Language Processing for Digital Humanities Simon Clematide, Isabel Meraner, Noah Bubenhofer, Martin Volk Institute of Computational Linguistics
Semantic Evidence for Automatic Identification of Cognates
 Semantic Evidence for Automatic Identification of Cognates Andrea Mulloni CLG, University of Wolverhampton Stafford Street Wolverhampton WV SB, United Kingdom andrea@wlv.ac.uk Viktor Pekar CLG, University
Semantic Evidence for Automatic Identification of Cognates Andrea Mulloni CLG, University of Wolverhampton Stafford Street Wolverhampton WV SB, United Kingdom andrea@wlv.ac.uk Viktor Pekar CLG, University
Analysis of Lexical Structures from Field Linguistics and Language Engineering
 Analysis of Lexical Structures from Field Linguistics and Language Engineering P. Wittenburg, W. Peters +, S. Drude ++ Max-Planck-Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands
Analysis of Lexical Structures from Field Linguistics and Language Engineering P. Wittenburg, W. Peters +, S. Drude ++ Max-Planck-Institute for Psycholinguistics Wundtlaan 1, 6525 XD Nijmegen, The Netherlands
CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS
 CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS Pirjo Moen Department of Computer Science P.O. Box 68 FI-00014 University of Helsinki pirjo.moen@cs.helsinki.fi http://www.cs.helsinki.fi/pirjo.moen
CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS Pirjo Moen Department of Computer Science P.O. Box 68 FI-00014 University of Helsinki pirjo.moen@cs.helsinki.fi http://www.cs.helsinki.fi/pirjo.moen
English-Chinese Cross-Lingual Retrieval Using a Translation Package
 English-Chinese Cross-Lingual Retrieval Using a Translation Package K. L. Kwok 23 January, 1999 Paper ID Code: 139 Submission type: Thematic Topic Area: I1 Word Count: 3100 (excluding refereneces & tables)
English-Chinese Cross-Lingual Retrieval Using a Translation Package K. L. Kwok 23 January, 1999 Paper ID Code: 139 Submission type: Thematic Topic Area: I1 Word Count: 3100 (excluding refereneces & tables)
The Moodle and joule 2 Teacher Toolkit
 The Moodle and joule 2 Teacher Toolkit Moodlerooms Learning Solutions The design and development of Moodle and joule continues to be guided by social constructionist pedagogy. This refers to the idea that
The Moodle and joule 2 Teacher Toolkit Moodlerooms Learning Solutions The design and development of Moodle and joule continues to be guided by social constructionist pedagogy. This refers to the idea that
The Verbmobil Semantic Database. Humboldt{Univ. zu Berlin. Computerlinguistik. Abstract
 The Verbmobil Semantic Database Karsten L. Worm Univ. des Saarlandes Computerlinguistik Postfach 15 11 50 D{66041 Saarbrucken Germany worm@coli.uni-sb.de Johannes Heinecke Humboldt{Univ. zu Berlin Computerlinguistik
The Verbmobil Semantic Database Karsten L. Worm Univ. des Saarlandes Computerlinguistik Postfach 15 11 50 D{66041 Saarbrucken Germany worm@coli.uni-sb.de Johannes Heinecke Humboldt{Univ. zu Berlin Computerlinguistik
The CESAR Project: Enabling LRT for 70M+ Speakers
 The CESAR Project: Enabling LRT for 70M+ Speakers Marko Tadić University of Zagreb, Faculty of Humanities and Social Sciences Zagreb, Croatia marko.tadic@ffzg.hr META-FORUM 2011 Budapest, Hungary, 2011-06-28
The CESAR Project: Enabling LRT for 70M+ Speakers Marko Tadić University of Zagreb, Faculty of Humanities and Social Sciences Zagreb, Croatia marko.tadic@ffzg.hr META-FORUM 2011 Budapest, Hungary, 2011-06-28
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
The MEANING Multilingual Central Repository
 The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Ontologies vs. classification systems
 Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Computer Software Evaluation Form
 Computer Software Evaluation Form Title: ereader Pro Evaluator s Name: Bradley A. Lavite Date: 25 Oct 2005 Subject Area: Various Grade Level: 6 th to 12th 1. Program Requirements (Memory, Operating System,
Computer Software Evaluation Form Title: ereader Pro Evaluator s Name: Bradley A. Lavite Date: 25 Oct 2005 Subject Area: Various Grade Level: 6 th to 12th 1. Program Requirements (Memory, Operating System,
Procedia - Social and Behavioral Sciences 154 ( 2014 )
") Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 154 ( 2014 ) 263 267 THE XXV ANNUAL INTERNATIONAL ACADEMIC CONFERENCE, LANGUAGE AND CULTURE, 20-22 October
Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 154 ( 2014 ) 263 267 THE XXV ANNUAL INTERNATIONAL ACADEMIC CONFERENCE, LANGUAGE AND CULTURE, 20-22 October
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov [Folie 1] 6.1 Type-token ratio
![Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov [Folie 1] 6.1 Type-token ratio](/thumbs/71/65795140.jpg "Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov [Folie 1] 6.1 Type-token ratio") Content 1. Empirical linguistics 2. Text corpora and corpus linguistics 3. Concordances 4. Application I: The German progressive 5. Part-of-speech tagging 6. Fequency analysis 7. Application II: Compounds
Content 1. Empirical linguistics 2. Text corpora and corpus linguistics 3. Concordances 4. Application I: The German progressive 5. Part-of-speech tagging 6. Fequency analysis 7. Application II: Compounds
Proceedings of the 19th COLING, , 2002.
 Crosslinguistic Transfer in Automatic Verb Classication Vivian Tsang Computer Science University of Toronto vyctsang@cs.toronto.edu Suzanne Stevenson Computer Science University of Toronto suzanne@cs.toronto.edu
Crosslinguistic Transfer in Automatic Verb Classication Vivian Tsang Computer Science University of Toronto vyctsang@cs.toronto.edu Suzanne Stevenson Computer Science University of Toronto suzanne@cs.toronto.edu
Taking into Account the Oral-Written Dichotomy of the Chinese language :
 Taking into Account the Oral-Written Dichotomy of the Chinese language : The division and connections between lexical items for Oral and for Written activities Bernard ALLANIC 安雄舒长瑛 SHU Changying 1 I.
Taking into Account the Oral-Written Dichotomy of the Chinese language : The division and connections between lexical items for Oral and for Written activities Bernard ALLANIC 安雄舒长瑛 SHU Changying 1 I.
Loughton School s curriculum evening. 28 th February 2017
 Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
GACE Computer Science Assessment Test at a Glance
 GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
Session Six: Software Evaluation Rubric Collaborators: Susan Ferdon and Steve Poast
 EDTECH 554 (FA10) Susan Ferdon Session Six: Software Evaluation Rubric Collaborators: Susan Ferdon and Steve Poast Task The principal at your building is aware you are in Boise State's Ed Tech Master's
EDTECH 554 (FA10) Susan Ferdon Session Six: Software Evaluation Rubric Collaborators: Susan Ferdon and Steve Poast Task The principal at your building is aware you are in Boise State's Ed Tech Master's
Systematic reviews in theory and practice for library and information studies
 Systematic reviews in theory and practice for library and information studies Sue F. Phelps, Nicole Campbell Abstract This article is about the use of systematic reviews as a research methodology in library
Systematic reviews in theory and practice for library and information studies Sue F. Phelps, Nicole Campbell Abstract This article is about the use of systematic reviews as a research methodology in library
K 1 2 K 1 2. Iron Mountain Public Schools Standards (modified METS) Checklist by Grade Level Page 1 of 11
 Checklist by Grade Level Page 1 of 11") Iron Mountain Public Schools Standards (modified METS) - K-8 Checklist by Grade Levels Grades K through 2 Technology Standards and Expectations (by the end of Grade 2) 1. Basic Operations and Concepts.
Iron Mountain Public Schools Standards (modified METS) - K-8 Checklist by Grade Levels Grades K through 2 Technology Standards and Expectations (by the end of Grade 2) 1. Basic Operations and Concepts.
Cross-Language Information Retrieval
 Cross-Language Information Retrieval ii Synthesis One liner Lectures Chapter in Title Human Language Technologies Editor Graeme Hirst, University of Toronto Synthesis Lectures on Human Language Technologies
Cross-Language Information Retrieval ii Synthesis One liner Lectures Chapter in Title Human Language Technologies Editor Graeme Hirst, University of Toronto Synthesis Lectures on Human Language Technologies
Developing a TT-MCTAG for German with an RCG-based Parser
 Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
Developing a TT-MCTAG for German with an RCG-based Parser Laura Kallmeyer, Timm Lichte, Wolfgang Maier, Yannick Parmentier, Johannes Dellert University of Tübingen, Germany CNRS-LORIA, France LREC 2008,
Introduction. Beáta B. Megyesi. Uppsala University Department of Linguistics and Philology Introduction 1(48)
") Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
Introduction Beáta B. Megyesi Uppsala University Department of Linguistics and Philology beata.megyesi@lingfil.uu.se Introduction 1(48) Course content Credits: 7.5 ECTS Subject: Computational linguistics
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
What is a Mental Model?
 Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011
 The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
The Karlsruhe Institute of Technology Translation Systems for the WMT 2011 Teresa Herrmann, Mohammed Mediani, Jan Niehues and Alex Waibel Karlsruhe Institute of Technology Karlsruhe, Germany firstname.lastname@kit.edu
A process by any other name
 January 05, 2016 Roger Tregear A process by any other name thoughts on the conflicted use of process language What s in a name? That which we call a rose By any other name would smell as sweet. William
January 05, 2016 Roger Tregear A process by any other name thoughts on the conflicted use of process language What s in a name? That which we call a rose By any other name would smell as sweet. William
Knowledge-Based - Systems
 Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Effect of Word Complexity on L2 Vocabulary Learning
 Effect of Word Complexity on L2 Vocabulary Learning Kevin Dela Rosa Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave. Pittsburgh, PA kdelaros@cs.cmu.edu Maxine Eskenazi Language
Effect of Word Complexity on L2 Vocabulary Learning Kevin Dela Rosa Language Technologies Institute Carnegie Mellon University 5000 Forbes Ave. Pittsburgh, PA kdelaros@cs.cmu.edu Maxine Eskenazi Language