Affective computing. Emotion recognition from speech. Fall 2018
|
|
|
- Mervin Underwood
- 5 years ago
- Views:
Transcription
1 Affective computing Emotion recognition from speech Fall 2018 Henglin Shi,
2 Outlines Introduction to speech features Why speech in emotion analysis Speech Features Speech and speech production Types of speeches Fundamental and resonant frequencies Speech production model Speech feature extraction Short time analysis Acoustic feature extraction Prosodic feature extraction
3 Why speeches in emotion analysis Speech is a main modality for people to express message Speech is more REAL than other modalities
4 Speech Emotion Features Lexical features Acoustic features Prosodic features
5 Lexical Features Explicit affective messages. Affective words, stress, etc.
6 Acoustic Features Traditional acoustic features (MFCC, LPC, PLP, etc.) Many filter bank and prefiltering options Simple signal measures (e.g. zerocrossings, HNR) Other spectral measures (e.g. formants, long term spectrum)
7 Prosodic Features Pitch/F0 Pitch tracker F0 contour and derivative distributions Rhythm/Duration Voiced/unvoiced/silence segmentation Distributions of segments and segment ratios Phoneme segmentation Speech rate Loudness/Intensity FFT and short segment energy Energy contours and spectral parameters Quality Inverse filtering Vocal source parameters
8 Process of Speech Production
9 Process of Speech Production
10 The mechanism of Speech Production Vocal tract begins at the opening of the vocal chord, and ends at the lips Vocal tract is a non-uniform acoustic tube of different diameter. The cross-section area of the vocal, determined by the positions of the tongue, lips, jaw and velum.
11 The mechanism of Speech Production The nasal tract begins at the velum and ends at the nostrilss (Diameter of nasal tract also varies). When velum is lowered, the nasal tract is acoustically coupled to the vocal tract to produce the nasal sounds of speech.
12 Classification of Speech Sounds Voiced Sounds The vocal chord vibrates when air is passing through E.g. vowels like /a/, /e/, /i/ Unvoiced Sounds The Vocal chord does not vibrate E.g. /f/, /s/, /k/ Other Sounds Nasal sounds Plosive sounds
13 Voiced Sound Vocal chords usually vibrate at a particular frequency, which is called the fundamental frequency (F0) of the sound. Different persons have different fundamental frequency 50 to 200 Hz for male speakers 150 to 300 Hz for femal speackers 200 to 400 Hz for child speakers The inverse of the fundamental frequency is the estimation on the pitch period.
14
15 Unvoiced Sound Characterised by high frequency components, just like random noise. For unvoiced sound, the vocal chord is held open, and the air rushes through the lungs, through the vocal tract, shaped by the vocal tract and comes out at the lips.
16 Other Sound Classes Nasal Sounds Vocal chord may vibrate Coupled with nasal cavity Sound radiated from the nostrils and lips E.g. /ing/ Plosive Sounds Generated by pressure behind the closure with sudden releases E.g. /k/, /t/
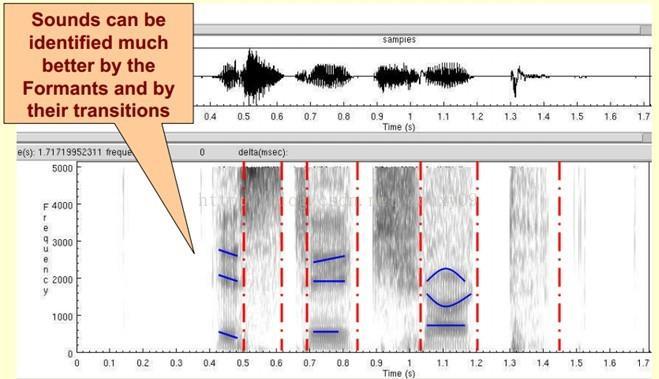
17 Resonant Frequencies of Vocal Tract Vocal tract is a non-uniform acoustic tube of different diameter, i.e. it s diameter varies. Vocal tract with different diameters will generate different resonant frequencies, which are called formants. Three to four formants present below 4kHz of speech.

18 Formants

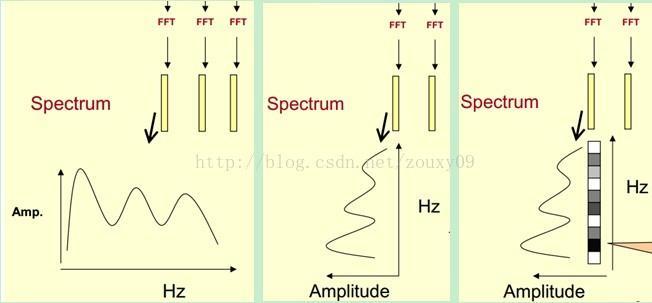
19
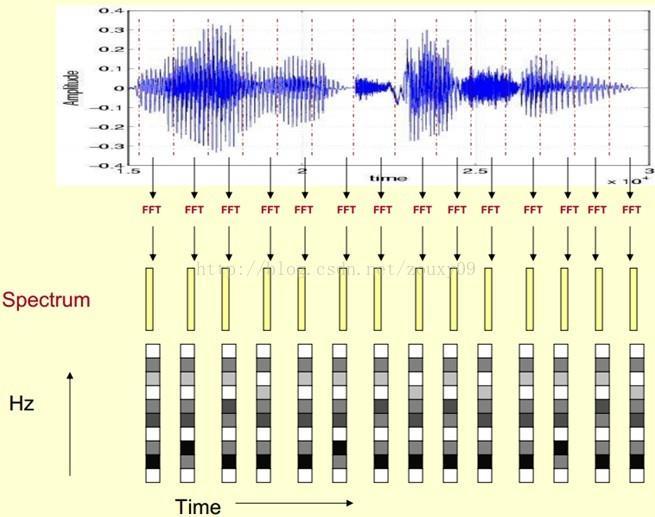
20
21
22 Formants: vowels

 P(f) = U")
23 Speech production P(f) R(f) T(f) U(f) P(f) = U f T f R(f)
24 Linear model of speech production Prosodic parameters Pitch and intonations Quality (Vocal source and tract) Intensity Durations
25 Speech feature extraction Local feature and global feature Local Feature: features describe a frame Global Feature: features describe an utterance Short time analysis
26 Framing/Windowing Using window functions to segment speech signal into small frames 10 to 20 ms for each frame Examples: Rectangular window Hamming window
27 Acoustic Feature: Zero Crossing Count The ZCC refects the signal frequency The ZCC is calculated according to: N 1 ZCC i = 0.5 sign s k sign s k 1 k=1 ZCC reflects the frequency of the signal DC offset should be removed
28 Acoustic Feature: Mel-cepstrum Mel-Frequency Cepstral Coefficients (MFCC) Mel-scale spaced filter bank Corresponds to human auditory system (equal perceived pitch increments) Usually ~12-24 coefficients used with 50% overlapping window Pre-emphasis often used for loudness equalization Mean cepstral subtraction for relative features, Delta and delta-delta features possible for sequences Alternatively, critical band energy features, i.e. logarithms of the band filters, no DCT
29 Pre-emphisize Filtering S z E z = A v z 1 2 P a k z k 1+ k=1 1 z 1 Speech signal is not the original signal from the vocal tract If we want to focus the vocal tract, we have to apply a high-pass filter to cancel factors which are not belong to the vocal tract
30 Prodosic Featur: Short Time Energy Summation of sqares of all samples within a frame Used to distinguish voiced and unvoiced sounds Larger STE: voiced sound Smaller STE: unvoiced sound E m = n s n w m n 2
31 Utilizing the Features STE (high) Voiced Speech ZCC (low) ZCC (high) Unvoiced Speech STE (low)
32 Prodosic Featur: Fundamental Frequency Pitch Period = 1 F 0 F 0 is the fundamental frequency of vocal chord vibration Method for estimating Pitch Period Time domain methods Frequency domain method
33 Extract Pitch Period in Time Domain Short Time Autocorrelation Function Assumption: One signal can be considered as a delayed version of another φ k = 1 N n=0 N 1 s n s n k Finding k to maximize φ k Average Magnitude Difference Function D k = 1 N n=0 N 1 s n n k Finding k to minimize D k
34 Features within an Utterance
35 Emperical Result on Emotional effects in speech
36
37



38 Same text and speakers with different emotions Same text with different speakers and different emotions Emotional F0 contour examples Neutral Bored Angry Happy
39 Features: Prosodic features
40 Emotion recognition from speech Traditional machine learning tools used frequently Feature selection and transformations Sequential floating search (SFFS), principal component analysis (PCA), nonlinear manifold modeling, etc. Classifiers Linear discriminant analysis (LDA), k-nearest neighbors (knn), support vector machines (SVM), hidden markov models (HMM), neural networks (NN) Validation and regularization Cross-validation, cost/penalty functions, Bayesian Information Criterion (BIC), structural risk minimization (SRM), etc.
41 State-of-the-art methods Pitch tracker Autocorrelation is probably the best short term method Need a better estimate of glottal closures e.g. waveform matching (time-domain) Classifier SVM or neural network Any classifier accepting nonlinear data will do deep neural architectures are a current trend Feature training Genetic algorithms, floating search PCA transformation of traditional features seems to help very little, nonlinear methods (e.g. Isomap) are better
42 Deep Learning Current paradigm in ASR State-of-the-art approach used in all major speech recognition solutions (Apple, Google, Facebook, Microsoft, ) Alternative to feature engineering Can use e.g. raw spectrograms and/or (large) sets of traditional acoustic features as inputs Hidden layers used to learn nonlinear features or filter banks Fusion of multimodal sources straightforward Computational costs and overlearning problems, but, if correctly applied, offers very promising performance
43 State-of-the-art performance Theoretical performance according to literature % in an automatic speaker-independent limited emotion case (discrimination) Neutral, sad, happy, angry 55-70% for human reference in a non-limited recognition of basic emotions in multicultural context In practice Neutral, sad, happy, angry, disgusted, surprised, fearful % depending on the scenario constraints, sample size, quality, number of emotions, and available features
44 Linear Predictive Coding (LPC) Very useful for estimating pitch, formants, spectra, and vocal tract parameters Assumption: a speech signal sample can be estimated as a linear combination of past samples.
45 LPC (Cont.) Inverse z-transformation of the vocal tract model : p s n = a k s n k + Gu n k=1 If we can use another set of a k which can make p k=1 Thus we have p a k s n k a k s n k = s n Gu n k=1 p e n = s n a k s n k = Gu n k=1
46 Usage of LPC Measure the pitch period more precisely using e n = s n p k=1 a k s n k = Gu n Questions: If we apply this model on unvoiced speech? Note: These coefficients should be calculated short-timely within frames
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speaker Recognition. Speaker Diarization and Identification
 Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Speaker Recognition Speaker Diarization and Identification A dissertation submitted to the University of Manchester for the degree of Master of Science in the Faculty of Engineering and Physical Sciences
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Speaker recognition using universal background model on YOHO database
 Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
Aalborg University Master Thesis project Speaker recognition using universal background model on YOHO database Author: Alexandre Majetniak Supervisor: Zheng-Hua Tan May 31, 2011 The Faculties of Engineering,
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language
 A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
A Comparison of DHMM and DTW for Isolated Digits Recognition System of Arabic Language Z.HACHKAR 1,3, A. FARCHI 2, B.MOUNIR 1, J. EL ABBADI 3 1 Ecole Supérieure de Technologie, Safi, Morocco. zhachkar2000@yahoo.fr.
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Quarterly Progress and Status Report. VCV-sequencies in a preliminary text-to-speech system for female speech
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report VCV-sequencies in a preliminary text-to-speech system for female speech Karlsson, I. and Neovius, L. journal: STL-QPSR volume: 35
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
International Journal of Computational Intelligence and Informatics, Vol. 1 : No. 4, January - March 2012
 Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Text-independent Mono and Cross-lingual Speaker Identification with the Constraint of Limited Data Nagaraja B G and H S Jayanna Department of Information Science and Engineering Siddaganga Institute of
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
On Developing Acoustic Models Using HTK. M.A. Spaans BSc.
 On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
On Developing Acoustic Models Using HTK M.A. Spaans BSc. On Developing Acoustic Models Using HTK M.A. Spaans BSc. Delft, December 2004 Copyright c 2004 M.A. Spaans BSc. December, 2004. Faculty of Electrical
Segregation of Unvoiced Speech from Nonspeech Interference
 Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Technical Report OSU-CISRC-8/7-TR63 Department of Computer Science and Engineering The Ohio State University Columbus, OH 4321-1277 FTP site: ftp.cse.ohio-state.edu Login: anonymous Directory: pub/tech-report/27
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition
 Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Unvoiced Landmark Detection for Segment-based Mandarin Continuous Speech Recognition Hua Zhang, Yun Tang, Wenju Liu and Bo Xu National Laboratory of Pattern Recognition Institute of Automation, Chinese
Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence
 INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
INTERSPEECH September,, San Francisco, USA Speech Synthesis in Noisy Environment by Enhancing Strength of Excitation and Formant Prominence Bidisha Sharma and S. R. Mahadeva Prasanna Department of Electronics
Perceptual scaling of voice identity: common dimensions for different vowels and speakers
 DOI 10.1007/s00426-008-0185-z ORIGINAL ARTICLE Perceptual scaling of voice identity: common dimensions for different vowels and speakers Oliver Baumann Æ Pascal Belin Received: 15 February 2008 / Accepted:
DOI 10.1007/s00426-008-0185-z ORIGINAL ARTICLE Perceptual scaling of voice identity: common dimensions for different vowels and speakers Oliver Baumann Æ Pascal Belin Received: 15 February 2008 / Accepted:
International Journal of Advanced Networking Applications (IJANA) ISSN No. :
 ISSN No. :") International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
International Journal of Advanced Networking Applications (IJANA) ISSN No. : 0975-0290 34 A Review on Dysarthric Speech Recognition Megha Rughani Department of Electronics and Communication, Marwadi Educational
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment
 Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
Automatic Speaker Recognition: Modelling, Feature Extraction and Effects of Clinical Environment A thesis submitted in fulfillment of the requirements for the degree of Doctor of Philosophy Sheeraz Memon
A comparison of spectral smoothing methods for segment concatenation based speech synthesis
 D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
D.T. Chappell, J.H.L. Hansen, "Spectral Smoothing for Speech Segment Concatenation, Speech Communication, Volume 36, Issues 3-4, March 2002, Pages 343-373. A comparison of spectral smoothing methods for
Body-Conducted Speech Recognition and its Application to Speech Support System
 Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Body-Conducted Speech Recognition and its Application to Speech Support System 4 Shunsuke Ishimitsu Hiroshima City University Japan 1. Introduction In recent years, speech recognition systems have been
Consonants: articulation and transcription
 Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Proceedings of Meetings on Acoustics
 Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Proceedings of Meetings on Acoustics Volume 19, 2013 http://acousticalsociety.org/ ICA 2013 Montreal Montreal, Canada 2-7 June 2013 Speech Communication Session 2aSC: Linking Perception and Production
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation
 UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
UTD-CRSS Systems for 2012 NIST Speaker Recognition Evaluation Taufiq Hasan Gang Liu Seyed Omid Sadjadi Navid Shokouhi The CRSS SRE Team John H.L. Hansen Keith W. Godin Abhinav Misra Ali Ziaei Hynek Bořil
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008
 The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
The NICT/ATR speech synthesis system for the Blizzard Challenge 2008 Ranniery Maia 1,2, Jinfu Ni 1,2, Shinsuke Sakai 1,2, Tomoki Toda 1,3, Keiichi Tokuda 1,4 Tohru Shimizu 1,2, Satoshi Nakamura 1,2 1 National
Phonetics. The Sound of Language
 Phonetics. The Sound of Language 1 The Description of Sounds Fromkin & Rodman: An Introduction to Language. Fort Worth etc., Harcourt Brace Jovanovich Read: Chapter 5, (p. 176ff.) (or the corresponding
Phonetics. The Sound of Language 1 The Description of Sounds Fromkin & Rodman: An Introduction to Language. Fort Worth etc., Harcourt Brace Jovanovich Read: Chapter 5, (p. 176ff.) (or the corresponding
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
Lecture 9: Speech Recognition
 EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
EE E6820: Speech & Audio Processing & Recognition Lecture 9: Speech Recognition 1 Recognizing speech 2 Feature calculation Dan Ellis Michael Mandel 3 Sequence
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
 " 'rear,.': T OOM 36-41L v CHU
" 'rear,.': T OOM 36-41L v CHU Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Quarterly Progress and Status Report. Voiced-voiceless distinction in alaryngeal speech - acoustic and articula
 Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
Dept. for Speech, Music and Hearing Quarterly Progress and Status Report Voiced-voiceless distinction in alaryngeal speech - acoustic and articula Nord, L. and Hammarberg, B. and Lundström, E. journal:
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription
 Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Analysis of Speech Recognition Models for Real Time Captioning and Post Lecture Transcription Wilny Wilson.P M.Tech Computer Science Student Thejus Engineering College Thrissur, India. Sindhu.S Computer
Expressive speech synthesis: a review
 Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Int J Speech Technol (2013) 16:237 260 DOI 10.1007/s10772-012-9180-2 Expressive speech synthesis: a review D. Govind S.R. Mahadeva Prasanna Received: 31 May 2012 / Accepted: 11 October 2012 / Published
Vimala.C Project Fellow, Department of Computer Science Avinashilingam Institute for Home Science and Higher Education and Women Coimbatore, India
 World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
World of Computer Science and Information Technology Journal (WCSIT) ISSN: 2221-0741 Vol. 2, No. 1, 1-7, 2012 A Review on Challenges and Approaches Vimala.C Project Fellow, Department of Computer Science
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Rhythm-typology revisited.
 DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
DFG Project BA 737/1: "Cross-language and individual differences in the production and perception of syllabic prominence. Rhythm-typology revisited." Rhythm-typology revisited. B. Andreeva & W. Barry Jacques
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
age, Speech and Hearii
 age, Speech and Hearii 1 Speech Commun cation tion 2 Sensory Comm, ection i 298 RLE Progress Report Number 132 Section 1 Speech Communication Chapter 1 Speech Communication 299 300 RLE Progress Report
age, Speech and Hearii 1 Speech Commun cation tion 2 Sensory Comm, ection i 298 RLE Progress Report Number 132 Section 1 Speech Communication Chapter 1 Speech Communication 299 300 RLE Progress Report
Automatic segmentation of continuous speech using minimum phase group delay functions
 Speech Communication 42 (24) 429 446 www.elsevier.com/locate/specom Automatic segmentation of continuous speech using minimum phase group delay functions V. Kamakshi Prasad, T. Nagarajan *, Hema A. Murthy
Speech Communication 42 (24) 429 446 www.elsevier.com/locate/specom Automatic segmentation of continuous speech using minimum phase group delay functions V. Kamakshi Prasad, T. Nagarajan *, Hema A. Murthy
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Voice conversion through vector quantization
 J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
J. Acoust. Soc. Jpn.(E)11, 2 (1990) Voice conversion through vector quantization Masanobu Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara A TR Interpreting Telephony Research Laboratories,
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
Digital Signal Processing: Speaker Recognition Final Report (Complete Version)
") Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Digital Signal Processing: Speaker Recognition Final Report (Complete Version) Xinyu Zhou, Yuxin Wu, and Tiezheng Li Tsinghua University Contents 1 Introduction 1 2 Algorithms 2 2.1 VAD..................................................
Automatic intonation assessment for computer aided language learning
 Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
Available online at www.sciencedirect.com Speech Communication 52 (2010) 254 267 www.elsevier.com/locate/specom Automatic intonation assessment for computer aided language learning Juan Pablo Arias a,
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano. Graduate School of Information Science, Nara Institute of Science & Technology
 ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
ISCA Archive SUBJECTIVE EVALUATION FOR HMM-BASED SPEECH-TO-LIP MOVEMENT SYNTHESIS Eli Yamamoto, Satoshi Nakamura, Kiyohiro Shikano Graduate School of Information Science, Nara Institute of Science & Technology
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Support Vector Machines for Speaker and Language Recognition
 Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Support Vector Machines for Speaker and Language Recognition W. M. Campbell, J. P. Campbell, D. A. Reynolds, E. Singer, P. A. Torres-Carrasquillo MIT Lincoln Laboratory, 244 Wood Street, Lexington, MA
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Edinburgh Research Explorer
 Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Edinburgh Research Explorer Personalising speech-to-speech translation Citation for published version: Dines, J, Liang, H, Saheer, L, Gibson, M, Byrne, W, Oura, K, Tokuda, K, Yamagishi, J, King, S, Wester,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
IEEE Proof Print Version
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING 1 Automatic Intonation Recognition for the Prosodic Assessment of Language-Impaired Children Fabien Ringeval, Julie Demouy, György Szaszák, Mohamed
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING 1 Automatic Intonation Recognition for the Prosodic Assessment of Language-Impaired Children Fabien Ringeval, Julie Demouy, György Szaszák, Mohamed
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Audible and visible speech
 Building sensori-motor prototypes from audiovisual exemplars Gérard BAILLY Institut de la Communication Parlée INPG & Université Stendhal 46, avenue Félix Viallet, 383 Grenoble Cedex, France web: http://www.icp.grenet.fr/bailly
Building sensori-motor prototypes from audiovisual exemplars Gérard BAILLY Institut de la Communication Parlée INPG & Université Stendhal 46, avenue Félix Viallet, 383 Grenoble Cedex, France web: http://www.icp.grenet.fr/bailly
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Self-Supervised Acquisition of Vowels in American English
 Self-Supervised Acquisition of Vowels in American English Michael H. Coen MIT Computer Science and Artificial Intelligence Laboratory 32 Vassar Street Cambridge, MA 2139 mhcoen@csail.mit.edu Abstract This
Self-Supervised Acquisition of Vowels in American English Michael H. Coen MIT Computer Science and Artificial Intelligence Laboratory 32 Vassar Street Cambridge, MA 2139 mhcoen@csail.mit.edu Abstract This
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
PHONETIC DISTANCE BASED ACCENT CLASSIFIER TO IDENTIFY PRONUNCIATION VARIANTS AND OOV WORDS
 PHONETIC DISTANCE BASED ACCENT CLASSIFIER TO IDENTIFY PRONUNCIATION VARIANTS AND OOV WORDS Akella Amarendra Babu 1 *, Ramadevi Yellasiri 2 and Akepogu Ananda Rao 3 1 JNIAS, JNT University Anantapur, Ananthapuramu,
PHONETIC DISTANCE BASED ACCENT CLASSIFIER TO IDENTIFY PRONUNCIATION VARIANTS AND OOV WORDS Akella Amarendra Babu 1 *, Ramadevi Yellasiri 2 and Akepogu Ananda Rao 3 1 JNIAS, JNT University Anantapur, Ananthapuramu,
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Self-Supervised Acquisition of Vowels in American English
 Self-Supervised cquisition of Vowels in merican English Michael H. Coen MIT Computer Science and rtificial Intelligence Laboratory 32 Vassar Street Cambridge, M 2139 mhcoen@csail.mit.edu bstract This paper
Self-Supervised cquisition of Vowels in merican English Michael H. Coen MIT Computer Science and rtificial Intelligence Laboratory 32 Vassar Street Cambridge, M 2139 mhcoen@csail.mit.edu bstract This paper
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence
 A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
A Cross-language Corpus for Studying the Phonetics and Phonology of Prominence Bistra Andreeva 1, William Barry 1, Jacques Koreman 2 1 Saarland University Germany 2 Norwegian University of Science and
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions
 26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
26 24th European Signal Processing Conference (EUSIPCO) Noise-Adaptive Perceptual Weighting in the AMR-WB Encoder for Increased Speech Loudness in Adverse Far-End Noise Conditions Emma Jokinen Department
Rachel E. Baker, Ann R. Bradlow. Northwestern University, Evanston, IL, USA
 LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
LANGUAGE AND SPEECH, 2009, 52 (4), 391 413 391 Variability in Word Duration as a Function of Probability, Speech Style, and Prosody Rachel E. Baker, Ann R. Bradlow Northwestern University, Evanston, IL,
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Multivariate k-nearest Neighbor Regression for Time Series data -
 Multivariate k-nearest Neighbor Regression for Time Series data - a novel Algorithm for Forecasting UK Electricity Demand ISF 2013, Seoul, Korea Fahad H. Al-Qahtani Dr. Sven F. Crone Management Science,
Multivariate k-nearest Neighbor Regression for Time Series data - a novel Algorithm for Forecasting UK Electricity Demand ISF 2013, Seoul, Korea Fahad H. Al-Qahtani Dr. Sven F. Crone Management Science,
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations
 A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University
A Privacy-Sensitive Approach to Modeling Multi-Person Conversations Danny Wyatt Dept. of Computer Science University of Washington danny@cs.washington.edu Jeff Bilmes Dept. of Electrical Engineering University