Behavior Clustering Inverse Reinforcement Learning and Approximate Optimal Control with Temporal Logic Tasks
|
|
|
- Austen Wade
- 5 years ago
- Views:
Transcription

, Jane Li (Co-advisor), Carlo")
1 Behavior Clustering Inverse Reinforcement Learning and Approximate Optimal Control with Temporal Logic Tasks By Siddharthan Rajasekaran Committee: Jie Fu (Advisor), Jane Li (Co-advisor), Carlo Pinciroli
2 Outline Part I Behavior Clustering Inverse Reinforcement Learning Part II Approximate Optimal Control with Temporal Logic Tasks
3 Outline Part I Behavior Clustering Inverse Reinforcement Learning
4 Outline Behavior Clustering Inverse Reinforcement Learning Learning from demonstrations Related work Behavior cloning Reinforcement Learning Background Feature Expectation Maximum Entropy IRL Motivation Method Results Conclusion Future work
5 Related work - Broad Overview Learning from demonstrations Behavioral cloning Reward shaping towards demonstrations Inverse Reinforcement Learning

6 Related work - Broad Overview Learning from demonstrations Behavioral cloning - Bojarski et. al. 2016, Ross et. al Treat demonstrations as labels and perform supervised learning Simple to use and implement Does not generalize well Crash due to positive feedback Given trajectories Learn the function approximation
7 Related work - Broad Overview Learning from demonstrations Reward shaping towards demonstrations - Brys et. al. 2015, Vasan et. al Give auxiliary reward for mimicking the expert Does not generalize well Requires definition of distance metrics Mimicking action Closest point Demonstration
8 Related work Learning from demonstrations Inverse Reinforcement Learning - Abbeel et. al. 2004, Ziebart et. al Finds the reward the expert is maximizing Generalizes well to unseen situations This is the topic of interest
9 Related work Why Inverse Reinforcement Learning? Finding the intent Useful for reasoning the decisions of expert Prediction Plan ahead of time Collaboration Assist humans to complete a task
10 IRL Motivation Motivating example

11 IRL Motivation An autonomous agent practicing IRL Recognize intent Take actions completely different from the expert to serve the intent IRL practitioner Warneken & Tomasello 2006

12 IRL Motivation - Collaboration An autonomous agent practicing IRL Recognize intent Take actions completely different from the expert to serve the intent Warneken & Tomasello 2006
13 Outline Preliminaries
14 Preliminary - Reinforcement Learning (RL) Agent interaction modeling in Reinforcement Learning

15 Preliminary - Reinforcement Learning (RL) Agent interaction modeling in Reinforcement Learning Objective of RL:
16 Preliminary - RL Reinforcement Learning Given Environment Set of actions to choose from Rewards Finds The optimal behavior to maximize cumulative reward
17 Preliminary - RL Reinforcement Learning Given Environment Set of actions to choose from Rewards Finds The optimal behavior to maximize cumulative reward
18 Preliminary - RL VS IRL Inverse Reinforcement Learning Given Environment Set of actions to choose from Expert demonstrations Finds The best reward function that explains the expert demonstrations
19 Preliminary - RL We will introduce Linear Reward Setting Feature expectation Graphical interpretation of RL Required for graphical interpretation of IRL
20 Preliminary - RL Linear Rewards Linear only in weights: Can be complex and nonlinear in states Using non-linear features
21 Linear reward - simple example Grid world Each color is a region
22 Linear reward - simple example Grid world Each color is a region Reward function Red = +5 Yellow = -1
23 Linear reward - simple example Grid world Each color is a region Reward function Red = +5 Yellow = -1 Each dimension in the feature vector is an indicator if we are in that region
24 RL - Linear Setting RL Objective:
25 RL - Linear Setting RL Objective:
26 RL - Linear Setting Feature expectation of any behavior is a vector in n-dimensional space
27 RL - Linear Setting Feature expectation of any behavior is a vector in n-dimensional space
28 RL - Linear Setting RL Geometrically, Objective:
29 RL - Linear Setting RL Geometrically, Objective: Objective: minimize Ψ
30 IRL - Overview IRL algorithms
31 Outline - Background Maximum Entropy Inverse Reinforcement Learning
32 MaxEnt IRL Maximum Entropy IRL (Ziebart 2010) S
33 MaxEnt IRL Maximum Entropy IRL (Ziebart 2010) S

34 MaxEnt IRL Maximum Entropy IRL (Ziebart 2010) S

")

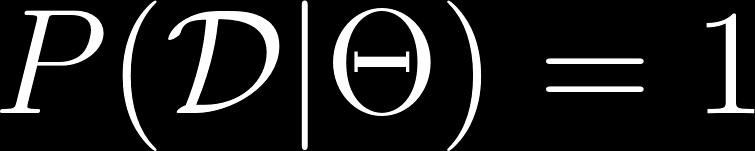
35 MaxEnt IRL Maximum Entropy IRL (Ziebart 2010) Objective function given demonstrations
36 IRL - Linear setting Gradient ascent on likelihood
37 IRL - Linear setting MaxEnt IRL Algorithm
38 IRL - Linear setting
39 IRL - Linear setting
40 IRL - Linear setting
41 IRL - Linear setting
42 IRL - Linear setting
43 IRL - Linear setting
44 IRL - Linear setting
45 IRL - Linear setting Problems with MaxEnt Interprets variance in demonstrations as suboptimality S
46 IRL - Linear setting Problems with MaxEnt Interprets variance in demonstrations as suboptimality Consider these demonstrations S
47 IRL - Linear setting Problems with MaxEnt Interprets variance in demonstrations as suboptimality Consider these demonstrations S
48 IRL - Linear setting Problems with MaxEnt Interprets variance in demonstrations as suboptimality Consider these demonstrations S
49 IRL - Linear setting Why should we not learn the mean behavior Wrong prediction Agent now predicts the mean behavior Learn the unintended behavior Might learn unsafe behavior (think in case of driving) Wrong intent learned. Cannot collaborate Not practical to get consistent demonstrations





50 Behavior Clustering IRL Behavior Clustering IRL Parametric Clusters/behaviors: Soft clustering, learns: Probability that a given demonstration Learns reward parameters: Non-parametric In addition learns the number of clusters: belongs to a class


51 Behavior Clustering IRL Expectation Maximization Missing data: distribution over behaviors Given data: Demonstrations Easier to optimize than



52 Behavior Clustering IRL The new objective function Previous Objective function For a single behavior: For multiple behaviors: where,
53 Behavior Clustering IRL The new objective function Update reward functions using where, is the probability that demonstration comes from behavior Update in vanilla MaxEnt IRL:






54 Behavior Clustering IRL The new objective function Update reward functions using Update the priors using where, is the probability that demonstration comes from behavior Update in vanilla MaxEnt IRL:
55 Non-parametric Behavior Clustering IRL Non-parametric BCIRL Learns the number of clusters We should learn the minimum number of clusters Chinese Restaurant Process (CRP) is used for non-parametric clustering
 Probability of")
56 Non-parametric Behavior Clustering IRL Chinese Restaurant Process (CRP) is used for non-parametric clustering Source: Internet (CS224n NLP course, Stanford) Probability of choosing the table:
57 Non-parametric Behavior Clustering IRL Non-parametric BCIRL Learns the number of clusters We should learn the minimum number of clusters Chinese Restaurant Process (CRP) For our problem, we count the soft cluster assignment mass) (probability
58 Algorithm - BCIRL
59 Algorithm - BCIRL Always some non-zero probability of creating a new cluster
60 Algorithm - BCIRL Always some non-zero probability of creating a new cluster For every demonstration-cluster combination, compute
61 Algorithm - BCIRL Always some non-zero probability of creating a new cluster Weighted resampling to avoid having unlikely clusters (just like particle filters)
62 Algorithm - BCIRL Always some non-zero probability of creating a new cluster Weighted resampling to avoid having unlikely clusters (just like particle filters) Clustering happens here
63 Algorithm - BCIRL Always some non-zero probability of creating a new cluster Weighted resampling to avoid having unlikely clusters (just like particle filters) Clustering happens here Weighted feature expectations
64 Algorithm - BCIRL Always some non-zero probability of creating a new cluster Weighted resampling to avoid having unlikely clusters (just like particle filters) Clustering happens here Weighted feature expectations We need not solve the complete inverse problem at every iteration!
65 Results On a motivating example Actions States





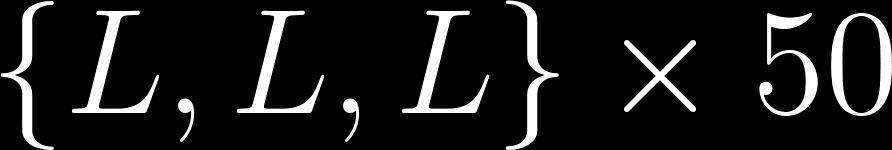
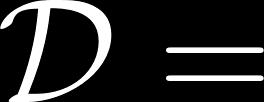
66 Results On a motivating example Policy MaxEnt IRL Non-parametric BCIRL Likelihood of demonstrations (objective)
67 Results Highway task Aggressive demonstrations: F I N I S H S T A R T Path of the car Other cars Evasive demonstrations: S T A R T Agent F I N I S H
68 Results Demonstrations Learned Behaviors
69 Results Demonstrations Likelihood of demonstrations (objective value) at convergence MaxEnt IRL Non-parametric BCIRL
70 Results Demonstrations Likelihood of demonstrations (objective value) at convergence MaxEnt IRL Non-parametric BCIRL Ref:

71 Results Gazebo simulator



72 Results Gazebo simulator Aggressive behavior using potential field controller


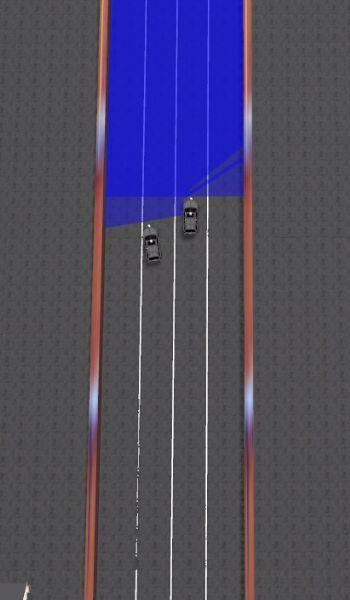
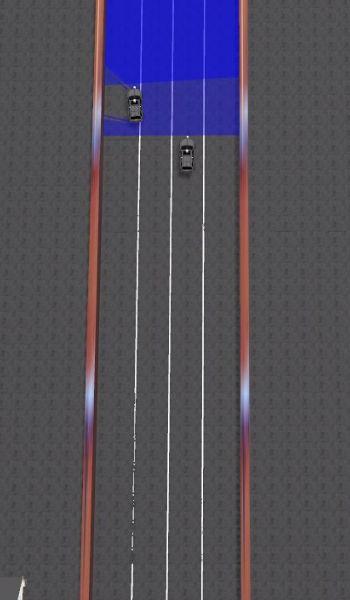

73 Results Gazebo simulator Aggressive behavior using potential field controller
74 Results Discretize the state space based on size of the car Gazebo simulator results Likelihood of demonstrations (objective value) at convergence MaxEnt IRL Non-parametric BCIRL
75 Results Gazebo simulator results Likelihood of demonstrations (objective value) at convergence MaxEnt IRL Non-parametric BCIRL Clustered into - [21, 19, 5, 4, 1]

76 Results Gazebo simulator results Likelihood of demonstrations (objective value) at convergence MaxEnt IRL Non-parametric BCIRL Clustered into - [21, 19, 5, 4, 1] Cluster 1: Evasive Cluster 2: Aggressive Clusters 3,4, and 5: Neither Able to learn the behaviors though we cannot get consistent demonstrations
77 Conclusion Advantages of Behavior Clustering IRL Can cluster demonstrations and learn reward function for each behavior Can predict new samples with high probability Can be used to separate consistent demonstrations from the rest Disadvantages Feature selection is harder Need features to also explain the differences in the behavior Does not scale well (exists in MaxEnt also) Solve multiple IRL problems for each cluster
78 Future work Addressing some of the disadvantages Feature selection Feature construction for IRL (Levine 2010) Guided cost learning (Finn 2016) Scalability (exists in MaxEnt also) Guided Policy search (Levine 2013) Path integral and Metropolis Hasting sampling (Kappen 2009)
79 Outline Part II Approximate Optimal Control with Temporal Logic Tasks
80 Outline Background LTL specifications Reward shaping Policy Gradients Actor critic Method Relation between Reward shaping and Actor critic Heuristic value initialization Results Conclusion

81 Motivation Motivating example Robot Soccer Robot Soccer. Source: IEEE Spectrum, Internet
82 Motivation Simpler task No opponents or teammates Robot Soccer There is a sequence of requirements temporally constrained For example, Get the ball - T1 Go near the goal - T2 Shoot - T3 LTL specification Goal Ball Agent
83 Motivation Simpler task No opponents or teammates Define the reward function +1 if Goal is scored Goal Ball Agent
84 Motivation - Why just RL fails Simpler task No opponents or teammates Define the reward function +1 if Goal is scored Very hard to explore Goal Ball Agent
85 Motivation How to use LTL to accelerate LTL specification Either True when satisfied Or False otherwise There is no signal towards partial completion Exploit structure in actor critic to motivate the agent towards completion Goal Ball Agent
86 Preliminaries
87 Reward Shaping Simpler task No opponents or teammates Define the reward function +1 if Goal is scored We need to satisfy temporally related requirements Get the ball: R = 0.01 (shaping reward) Score a Goal: R = +1 (true reward) Goal Ball Agent
88 Reward Shaping We need to satisfy temporally related requirements Example, Get the ball: R = 0.01 (shaping reward) Score a Goal: R = +1 (true reward) Goal Ball Agent
89 Reward Shaping We need to satisfy temporally related requirements Example, Get the ball: R = 0.01 (shaping reward) Score a Goal: R = +1 (true reward) Result (Andrew Ng 1999) The agent keeps vibrating near the ball Goal Ball Agent
90 Reward Shaping Before shaping Optimal policy was to score a goal After shaping Optimal policy is to vibrate near the ball Optimal policy Invariance (Andrew Ng 1999) Goal Ball Agent
91 Reward Shaping Before shaping Optimal policy was to score a goal After shaping Optimal policy is to vibrate near the ball Optimal policy Invariance (Andrew Ng 1999) Goal Ball Agent
 Goal Ball")
92 Reward Shaping and Policy Invariance Before shaping Optimal policy was to score a goal After shaping Optimal policy is to vibrate near the ball Optimal policy Invariance (Andrew Ng 1999) Goal Ball Agent
 More generally Goal Ball Agent")
93 Reward Shaping and Policy Invariance Before shaping Optimal policy was to score a goal After shaping Optimal policy is to vibrate near the ball Optimal policy Invariance (Andrew Ng 1999) More generally Goal Ball Agent
94 Preliminaries - Policy Gradients Objective of RL
95 Preliminaries - Policy Gradients Objective of RL By parametrizing the policy



96 Preliminaries - Policy Gradients Objective of RL By parametrizing the policy Utility of the parameter Objective:
97 Preliminaries - Policy Gradients Gradient of the utility from samples
98 Preliminaries - Policy Gradients Gradient of the utility from samples
99 Preliminaries - Policy Gradients Gradient of the utility from samples Policy gradient
100 Background - Actor Critic Policy gradients
101 Background - Actor Critic Policy gradients Reward shaping
102 Background - Actor Critic Policy gradients Reward shaping Actor Critic


103 Background - Actor Critic Policy gradients Reward shaping Actor Critic


104 Background - Actor Critic Policy gradients Reward shaping Actor Critic
105 Background - Actor Critic Actor Critic Actor (policy) update Use the empirical estimate of the gradient Critic (value) update Use any supervised learning to learn the targets Critics are shaping functions
106 Background - Actor Critic Actor Critic Actor (policy) update Use the empirical estimate of the gradient Critic (value) update Use any supervised learning to learn the targets Critics are shaping functions
107 Method - Accelerating Actor Critic using LTL Given a specification +10 for satisfying the specification - Agent - R1 - R2 - R3 -O
108 Method - Accelerating Actor Critic using LTL Given a specification Break down into several reach avoid task for critic initialization Task1: Task2:
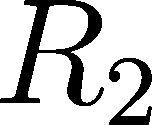
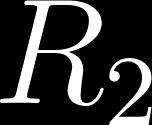
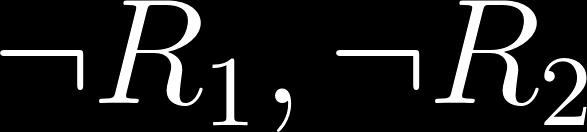
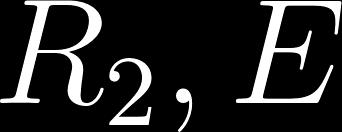


109 Method - Accelerating Actor Critic using LTL Break down into several reach avoid task Task1: Task2: Automata of the original specification
110 Method - Accelerating Actor Critic using LTL Break down into several reach avoid task Task1: Task2: Heuristic value initialization


111 Method - Accelerating Actor Critic using LTL Heuristic value initialization for Task 2 Reward: + 10 if is satisfied. -5 for running into obstacles. - Agent - R1 - R2 - R3


112 Results Learned values Reward: + 10 if is satisfied. -5 for running into obstacles. - Agent - R1 - R2 - R3

113 Results Actor critic with and without heuristic initialization Reward: + 10 if is satisfied. -5 for running into obstacles.
114 Conclusion and Discussions Summary IRL with automated behavior clustering Improve feature selection and scalability Accelerating actor-critic with temporal logic constraints. Automate the decomposition procedure for LTL specifications for scalable systems Possible directions Use LTL specifications to accelerate BCIRL Applications to general domains: Big data Urban planning
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Improving Fairness in Memory Scheduling
 Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
arxiv: v2 [cs.ro] 3 Mar 2017
![arxiv: v2 [cs.ro] 3 Mar 2017](/thumbs/71/66179626.jpg "arxiv: v2 [cs.ro] 3 Mar 2017") Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
LEGO MINDSTORMS Education EV3 Coding Activities
 LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
A Context-Driven Use Case Creation Process for Specifying Automotive Driver Assistance Systems
 A Context-Driven Use Case Creation Process for Specifying Automotive Driver Assistance Systems Hannes Omasreiter, Eduard Metzker DaimlerChrysler AG Research Information and Communication Postfach 23 60
A Context-Driven Use Case Creation Process for Specifying Automotive Driver Assistance Systems Hannes Omasreiter, Eduard Metzker DaimlerChrysler AG Research Information and Communication Postfach 23 60
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Game-based formative assessment: Newton s Playground. Valerie Shute, Matthew Ventura, & Yoon Jeon Kim (Florida State University), NCME, April 30, 2013
, NCME, April 30, 2013") Game-based formative assessment: Newton s Playground Valerie Shute, Matthew Ventura, & Yoon Jeon Kim (Florida State University), NCME, April 30, 2013 Fun & Games Assessment Needs Game-based stealth assessment
Game-based formative assessment: Newton s Playground Valerie Shute, Matthew Ventura, & Yoon Jeon Kim (Florida State University), NCME, April 30, 2013 Fun & Games Assessment Needs Game-based stealth assessment
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses
 Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
ME 4495 Computational Heat Transfer and Fluid Flow M,W 4:00 5:15 (Eng 177)
") ME 4495 Computational Heat Transfer and Fluid Flow M,W 4:00 5:15 (Eng 177) Professor: Daniel N. Pope, Ph.D. E-mail: dpope@d.umn.edu Office: VKH 113 Phone: 726-6685 Office Hours:, Tues,, Fri 2:00-3:00 (or
ME 4495 Computational Heat Transfer and Fluid Flow M,W 4:00 5:15 (Eng 177) Professor: Daniel N. Pope, Ph.D. E-mail: dpope@d.umn.edu Office: VKH 113 Phone: 726-6685 Office Hours:, Tues,, Fri 2:00-3:00 (or
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
DOCTOR OF PHILOSOPHY HANDBOOK
 University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
EXECUTIVE SUMMARY. Online courses for credit recovery in high schools: Effectiveness and promising practices. April 2017
 EXECUTIVE SUMMARY Online courses for credit recovery in high schools: Effectiveness and promising practices April 2017 Prepared for the Nellie Mae Education Foundation by the UMass Donahue Institute 1
EXECUTIVE SUMMARY Online courses for credit recovery in high schools: Effectiveness and promising practices April 2017 Prepared for the Nellie Mae Education Foundation by the UMass Donahue Institute 1
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Teaching a Laboratory Section
 Chapter 3 Teaching a Laboratory Section Page I. Cooperative Problem Solving Labs in Operation 57 II. Grading the Labs 75 III. Overview of Teaching a Lab Session 79 IV. Outline for Teaching a Lab Session
Chapter 3 Teaching a Laboratory Section Page I. Cooperative Problem Solving Labs in Operation 57 II. Grading the Labs 75 III. Overview of Teaching a Lab Session 79 IV. Outline for Teaching a Lab Session
Learning Human Utility from Video Demonstrations for Deductive Planning in Robotics
 Learning Human Utility from Video Demonstrations for Deductive Planning in Robotics Nishant Shukla, Yunzhong He, Frank Chen, and Song-Chun Zhu Center for Vision, Cognition, Learning, and Autonomy University
Learning Human Utility from Video Demonstrations for Deductive Planning in Robotics Nishant Shukla, Yunzhong He, Frank Chen, and Song-Chun Zhu Center for Vision, Cognition, Learning, and Autonomy University
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Transfer Learning Action Models by Measuring the Similarity of Different Domains
 Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Purdue Data Summit Communication of Big Data Analytics. New SAT Predictive Validity Case Study
 Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Social Emotional Learning in High School: How Three Urban High Schools Engage, Educate, and Empower Youth
 SCOPE ~ Executive Summary Social Emotional Learning in High School: How Three Urban High Schools Engage, Educate, and Empower Youth By MarYam G. Hamedani and Linda Darling-Hammond About This Series Findings
SCOPE ~ Executive Summary Social Emotional Learning in High School: How Three Urban High Schools Engage, Educate, and Empower Youth By MarYam G. Hamedani and Linda Darling-Hammond About This Series Findings
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
ECE-492 SENIOR ADVANCED DESIGN PROJECT
 ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm
 Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
Design Of An Automatic Speaker Recognition System Using MFCC, Vector Quantization And LBG Algorithm Prof. Ch.Srinivasa Kumar Prof. and Head of department. Electronics and communication Nalanda Institute
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
EGRHS Course Fair. Science & Math AP & IB Courses
 EGRHS Course Fair Science & Math AP & IB Courses Science Courses: AP Physics IB Physics SL IB Physics HL AP Biology IB Biology HL AP Physics Course Description Course Description AP Physics C (Mechanics)
EGRHS Course Fair Science & Math AP & IB Courses Science Courses: AP Physics IB Physics SL IB Physics HL AP Biology IB Biology HL AP Physics Course Description Course Description AP Physics C (Mechanics)
Toward Probabilistic Natural Logic for Syllogistic Reasoning
 Toward Probabilistic Natural Logic for Syllogistic Reasoning Fangzhou Zhai, Jakub Szymanik and Ivan Titov Institute for Logic, Language and Computation, University of Amsterdam Abstract Natural language
Toward Probabilistic Natural Logic for Syllogistic Reasoning Fangzhou Zhai, Jakub Szymanik and Ivan Titov Institute for Logic, Language and Computation, University of Amsterdam Abstract Natural language
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Lesson plan for Maze Game 1: Using vector representations to move through a maze Time for activity: homework for 20 minutes
 Lesson plan for Maze Game 1: Using vector representations to move through a maze Time for activity: homework for 20 minutes Learning Goals: Students will be able to: Maneuver through the maze controlling
Lesson plan for Maze Game 1: Using vector representations to move through a maze Time for activity: homework for 20 minutes Learning Goals: Students will be able to: Maneuver through the maze controlling
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Answer Key For The California Mathematics Standards Grade 1
 Introduction: Summary of Goals GRADE ONE By the end of grade one, students learn to understand and use the concept of ones and tens in the place value number system. Students add and subtract small numbers
Introduction: Summary of Goals GRADE ONE By the end of grade one, students learn to understand and use the concept of ones and tens in the place value number system. Students add and subtract small numbers
Causal Link Semantics for Narrative Planning Using Numeric Fluents
 Proceedings, The Thirteenth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE-17) Causal Link Semantics for Narrative Planning Using Numeric Fluents Rachelyn Farrell,
Proceedings, The Thirteenth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment (AIIDE-17) Causal Link Semantics for Narrative Planning Using Numeric Fluents Rachelyn Farrell,
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling
 Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Genevieve L. Hartman, Ph.D.
 Curriculum Development and the Teaching-Learning Process: The Development of Mathematical Thinking for all children Genevieve L. Hartman, Ph.D. Topics for today Part 1: Background and rationale Current
Curriculum Development and the Teaching-Learning Process: The Development of Mathematical Thinking for all children Genevieve L. Hartman, Ph.D. Topics for today Part 1: Background and rationale Current