Reinforcement Learning cont. CS434
|
|
|
- Leo Copeland
- 5 years ago
- Views:
Transcription
1 Reinforcement Learning cont. CS434
2 Passive learning Assume that the agent executes a fixed policy π Goal is to compute U π (s), based on some sequence of training trials performed by the agent ADP: model based learning With each observation, update the underlying MDP model Solve the resulting policy evaluation problem under the current MDP model TD: model free learning Directly estimate using online estimation of mean When observe a transition S -> S, the update rule is:
3 Comparison between ADP and TD Advantages of ADP: Converges to the true utilities faster Utility estimates don t vary as much from the true utilities Advantages of TD: Simpler, less computation per observation Crude but efficient first approximation to ADP Don t need to build a transition model in order to perform its updates (this is important because we can interleave computation with exploration rather than having to wait for the whole model to be built first)
4 Passive learning Learning U π (s) does not lead to a optimal policy, why? the models are incomplete/inaccurate the agent has only tried limited actions, we cannot gain a good overall understanding of T This is why we need active learning
5 Goal of active learning Let s first assume that we still have access to some sequence of trials performed by the agent The agent is not following any specific policy We can assume for now that the sequences should include a thorough exploration of the space We will talk about how to get such sequences later The goal is to learn an optimal policy from such sequences
6 Active Reinforcement Learning Agents We will describe two types of Active Reinforcement Learning agents: Active ADP agent Q learner (based on TD algorithm)
7 Active ADP Agent (Model based) Using the data from its trials, the agent learns a transition model and a reward function With (s,s ) and (s), it has an estimate of the underlying MDP It can compute the optimal policy by solving the Bellman equations using value iteration or policy iteration U ( s) Rˆ( s) max a If and are accurate estimation of the underlying MDP model, we can find the optimal policy this way s' Tˆ( s, s') U ( s')
8 Issues with ADP approach Need to maintain MDP model can be very large Also, finding the optimal action requires solving the bellman equations time consuming Can we avoid this large computational complexity both in terms of time and space?
9 Q learning So far, we have focused on the utilities for states U(s) = utility of state s = expected maximum future rewards An alternative is to store Q values, which are defined as: Q(s) = utility of taking action a at state s = expected maximum future reward if action a at state s Relationship between U(s) and Q( s)? U ( s) maxq( s) a
10 Q learning can be model free Note that after computing U(s), to obtain the optimal policy, we need to compute: ' ( s) max T ( s, s ) U ( s' ) a s' This requires T, the model of world So even if we use TD learning (model free), we still need the model to get the optimal policy However, if you successfully estimate Q(s) for all a and s, we can compute the optimal policy without using the model: ( s) maxq( s) a
11 Q learning At equilibrium when the Q values are correct, we can write the constraint equation: Q( s) R( s) s' Note that this requires learning a transition model T ( s, s') maxq( a', s') a'
12 Q learning At equilibrium when the Q values are correct, we can write the constraint equation: Q( s) R( s) s' T ( s, s') maxq( a', s') a' Reward at state s Best expected value for action-state pair ( s) Best value averaged over all possible states s that can be reached from s after executing action a Best value at the next state = max over all actions in state s
13 Q learning Without a Model We can use a temporal differencing approach which is model free After moving from state s to state s using action a: Q( s) Q( s) ( R( s) maxq( a', a' s') Q( s)) New estimate of Q(s) Learning rate 0 < α < 1 Old estimate of Q(s) Difference between old estimate Q(s) and the new noisy sample after taking action a
14 Q learning: Estimating the Policy Q-Update: After moving from state s to state s using action a: Q( s) Q( s) ( R( s) maxq( a', a' s') Q( s)) Note that T(s,s ) does not appear anywhere! Further, once we converge, the optimal policy can be computed without T. This is a completely model-free learning algorithm.
15 Q learning Convergence Guaranteed to converge to the true Q values given enough exploration Very general procedure (because it s model free) Converges slower than ADP agent (because it is completely model free and it doesn t enforce consistency among values through the model)
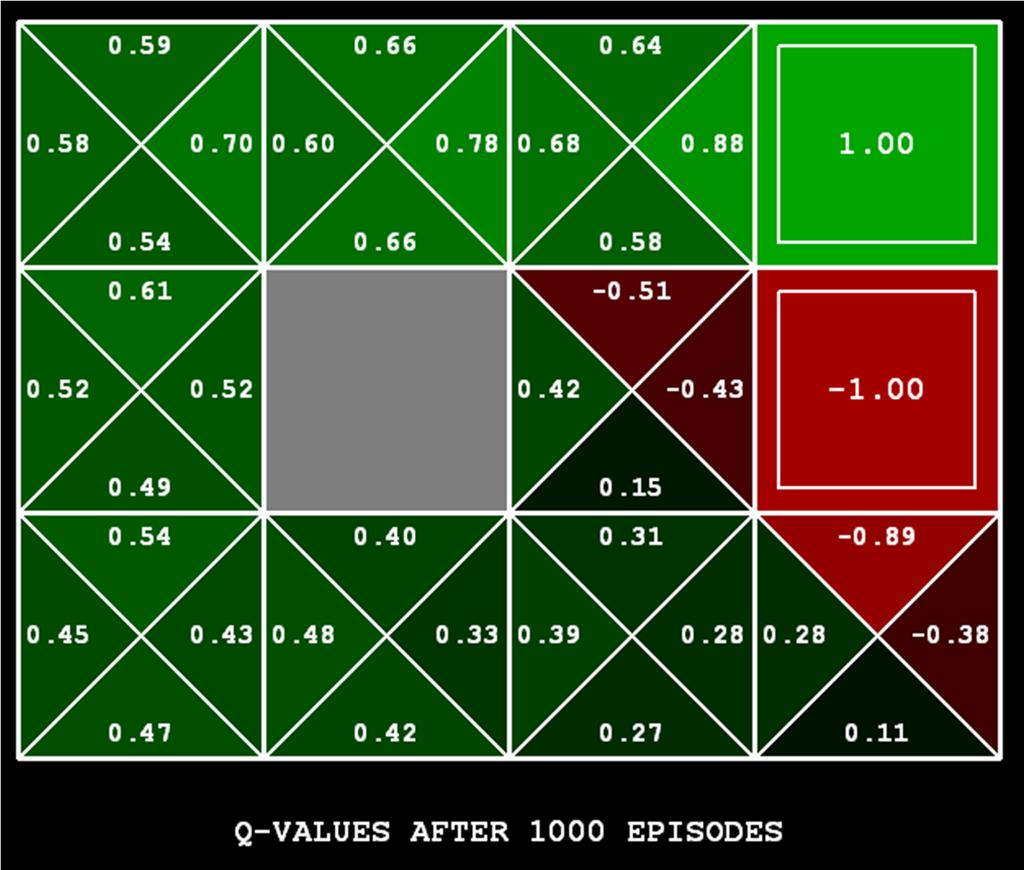
16
17 So far, we have assumed that all training sequences are given and they fully explore the state space and action space But how do we generate all the training trials? We can have the agents random explore first, to collect training trials Once we accumulate enough trials, we perform the learning (eith ADP, or Q learning) We then choose the optimal policy How much exploration do we need to do? What if the agent is expected to learn and perform reasonably constantly, not just at the end
18 A greedy agent At any point, the agent has a current set of training trials, and we ve got a policy that is optimal based on our current understanding of the world A greedy agent can execute the optimal policy for the learned model at each time step
19 A greedy Q learning agent function Q learning agent(percept) returns an action inputs: percept, a percept indicating the current state s and reward signal r static: Q, a table of action values index by state and action N sa a table of frequencies for state action pairs, initially zero s, r the previous state and action, initially null if s is not null, then do increment N sa [s,a] Q( s, a) Q( s, a) ( r max Q( s', a') Q( s, a)) a' if TERMINAL?[s ] then s, a null else s, r s, arg maxq( s', a), r return a a Always choose the action that is deemed the best based on current Q table
20 The Greedy Agent The agent finds the lower route to get to the goal state but never finds the optimal upper route. The agent is stubborn and doesn t change so it doesn t learn the true utilities or the true optimal policy
21 What happened? How can choosing an optimal action lead to suboptimal results? What we have learned (T/R, or Q) may not truly reflect the true environment In fact, the set of trials observed by the agent was often insufficient How can we address this issue? We need good training experience
22 Exploitation vs Exploration Actions are always taken for one of the two following purposes: Exploitation: Execute the current optimal policy to get high payoff Exploration: Try new sequences of (possibly random) actions to improve the agent s knowledge of the environment even though current model doesn t believe they have high payoff Pure exploitation: gets stuck in a rut Pure exploration: not much use if you don t put that knowledge into practice
23 Optimal Exploration Strategy? What is the optimal exploration strategy? Greedy? Random? Mixed? (Sometimes use greedy sometimes use random) It turns out that the optimal exploration strategy has been studied in depth in the N armed bandit problem
24 N armed Bandits We have N slot machines, each can yield $1 with some probability (different for each machine) What order should we try the machines? Stay with the machine with the highest observed probability so far? Random? Something else? Bottom line: It s not obvious In fact, an exact solution is usually intractable
25 GLIE Fortunately it is possible to come up with a reasonable exploration method that eventually leads to optimal behavior by the agent Any such exploration method needs to be Greedy in the Limit of Infinite Exploration (GLIE) Properties: Must try each action in each state an unbounded number of times so that it doesn t miss any optimal actions Must eventually become greedy
26 Examples of GLIE schemes greedy: Choose optimal action with probability (1 ) Choose a random action with probability /(number of actions 1) Active ε greedy agent 1. Start from the original sequence of trials 2. Compute the optimal policy under the current understanding of the world 3. Take action use the ε greedy exploitation exploration strategy 4. Update learning, go to 2
27 Another approach Favor actions the agent has not tried very often, avoid actions believed to be of low utility (based on past experience) We can achieve this using an exploration function
28 An exploratory Q learning agent function Q learning agent(percept) returns an action inputs: percept, a percept indicating the current state s and reward signal r static: Q, a table of action values index by state and action N sa a table of frequencies for state action pairs, initially zero s, r the previous state and action, initially null if s is not null, then do increment N sa [s,a] Q( s) Q( s) ( r maxq( a', s') Q( s)) a' if TERMINAL?[s ] then s, a null else s, r s, arg max f ( Q( a', s'), N sa[ s', a']), r a' return a Exploration function: R if n N e f ( u, n) u otherwise
29 Exploration Function Exploration function f(q,n): f ( q, n) R if n N q otherwise e - Trades off greedy (preference for high utilities q) against curiosity (preference for low values of n the number of times a state-action pair has been tried) - R+ is an optimistic estimate of the best possible reward obtainable in any state with any action - If a hasn t been tried enough in s, you assume it will somehow lead to gold optimistic - N e is a limit on the number of tries for a state-action pair
30 Model based/model free Two broad categories of reinforcement learning algorithms: 1. Model based eg. ADP 2. Model free eg. TD, Q learning Which is better? Model baesed approach is a knowledge based approach (ie. model represents known aspects of the environment) Book claims that as environment becomes more complex, a knowledge based approach is better
31 What You Should Know Exploration vs exploitation GLIE schemes Difference between model free and modelbased methods Q learning
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design
 Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Evidence for Reliability, Validity and Learning Effectiveness
 PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
P-4: Differentiate your plans to fit your students
 Putting It All Together: Middle School Examples 7 th Grade Math 7 th Grade Science SAM REHEARD, DC 99 7th Grade Math DIFFERENTATION AROUND THE WORLD My first teaching experience was actually not as a Teach
Putting It All Together: Middle School Examples 7 th Grade Math 7 th Grade Science SAM REHEARD, DC 99 7th Grade Math DIFFERENTATION AROUND THE WORLD My first teaching experience was actually not as a Teach
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Pod Assignment Guide
 Pod Assignment Guide Document Version: 2011-08-02 This guide covers features available in NETLAB+ version 2010.R5 and later. Copyright 2010, Network Development Group, Incorporated. NETLAB Academy Edition
Pod Assignment Guide Document Version: 2011-08-02 This guide covers features available in NETLAB+ version 2010.R5 and later. Copyright 2010, Network Development Group, Incorporated. NETLAB Academy Edition
College Pricing and Income Inequality
 College Pricing and Income Inequality Zhifeng Cai U of Minnesota, Rutgers University, and FRB Minneapolis Jonathan Heathcote FRB Minneapolis NBER Income Distribution, July 20, 2017 The views expressed
College Pricing and Income Inequality Zhifeng Cai U of Minnesota, Rutgers University, and FRB Minneapolis Jonathan Heathcote FRB Minneapolis NBER Income Distribution, July 20, 2017 The views expressed
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
College Pricing and Income Inequality
 College Pricing and Income Inequality Zhifeng Cai U of Minnesota and FRB Minneapolis Jonathan Heathcote FRB Minneapolis OSU, November 15 2016 The views expressed herein are those of the authors and not
College Pricing and Income Inequality Zhifeng Cai U of Minnesota and FRB Minneapolis Jonathan Heathcote FRB Minneapolis OSU, November 15 2016 The views expressed herein are those of the authors and not
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
How to make an A in Physics 101/102. Submitted by students who earned an A in PHYS 101 and PHYS 102.
 How to make an A in Physics 101/102. Submitted by students who earned an A in PHYS 101 and PHYS 102. PHYS 102 (Spring 2015) Don t just study the material the day before the test know the material well
How to make an A in Physics 101/102. Submitted by students who earned an A in PHYS 101 and PHYS 102. PHYS 102 (Spring 2015) Don t just study the material the day before the test know the material well
Inside the mind of a learner
 Inside the mind of a learner - Sampling experiences to enhance learning process INTRODUCTION Optimal experiences feed optimal performance. Research has demonstrated that engaging students in the learning
Inside the mind of a learner - Sampling experiences to enhance learning process INTRODUCTION Optimal experiences feed optimal performance. Research has demonstrated that engaging students in the learning
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Machine Learning and Development Policy
 Machine Learning and Development Policy Sendhil Mullainathan (joint papers with Jon Kleinberg, Himabindu Lakkaraju, Jure Leskovec, Jens Ludwig, Ziad Obermeyer) Magic? Hard not to be wowed But what makes
Machine Learning and Development Policy Sendhil Mullainathan (joint papers with Jon Kleinberg, Himabindu Lakkaraju, Jure Leskovec, Jens Ludwig, Ziad Obermeyer) Magic? Hard not to be wowed But what makes
Shockwheat. Statistics 1, Activity 1
 Statistics 1, Activity 1 Shockwheat Students require real experiences with situations involving data and with situations involving chance. They will best learn about these concepts on an intuitive or informal
Statistics 1, Activity 1 Shockwheat Students require real experiences with situations involving data and with situations involving chance. They will best learn about these concepts on an intuitive or informal
EDIT 576 DL1 (2 credits) Mobile Learning and Applications Fall Semester 2014 August 25 October 12, 2014 Fully Online Course
 Mobile Learning and Applications Fall Semester 2014 August 25 October 12, 2014 Fully Online Course") GEORGE MASON UNIVERSITY COLLEGE OF EDUCATION AND HUMAN DEVELOPMENT GRADUATE SCHOOL OF EDUCATION INSTRUCTIONAL DESIGN AND TECHNOLOGY PROGRAM EDIT 576 DL1 (2 credits) Mobile Learning and Applications Fall
GEORGE MASON UNIVERSITY COLLEGE OF EDUCATION AND HUMAN DEVELOPMENT GRADUATE SCHOOL OF EDUCATION INSTRUCTIONAL DESIGN AND TECHNOLOGY PROGRAM EDIT 576 DL1 (2 credits) Mobile Learning and Applications Fall
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Self Study Report Computer Science
 Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses
 Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Learning Cases to Resolve Conflicts and Improve Group Behavior
 From: AAAI Technical Report WS-96-02. Compilation copyright 1996, AAAI (www.aaai.org). All rights reserved. Learning Cases to Resolve Conflicts and Improve Group Behavior Thomas Haynes and Sandip Sen Department
From: AAAI Technical Report WS-96-02. Compilation copyright 1996, AAAI (www.aaai.org). All rights reserved. Learning Cases to Resolve Conflicts and Improve Group Behavior Thomas Haynes and Sandip Sen Department
Acquiring Competence from Performance Data
 Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS
 CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS Pirjo Moen Department of Computer Science P.O. Box 68 FI-00014 University of Helsinki pirjo.moen@cs.helsinki.fi http://www.cs.helsinki.fi/pirjo.moen
CONCEPT MAPS AS A DEVICE FOR LEARNING DATABASE CONCEPTS Pirjo Moen Department of Computer Science P.O. Box 68 FI-00014 University of Helsinki pirjo.moen@cs.helsinki.fi http://www.cs.helsinki.fi/pirjo.moen
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Conceptual and Procedural Knowledge of a Mathematics Problem: Their Measurement and Their Causal Interrelations
 Conceptual and Procedural Knowledge of a Mathematics Problem: Their Measurement and Their Causal Interrelations Michael Schneider (mschneider@mpib-berlin.mpg.de) Elsbeth Stern (stern@mpib-berlin.mpg.de)
Conceptual and Procedural Knowledge of a Mathematics Problem: Their Measurement and Their Causal Interrelations Michael Schneider (mschneider@mpib-berlin.mpg.de) Elsbeth Stern (stern@mpib-berlin.mpg.de)
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
9.85 Cognition in Infancy and Early Childhood. Lecture 7: Number
 9.85 Cognition in Infancy and Early Childhood Lecture 7: Number What else might you know about objects? Spelke Objects i. Continuity. Objects exist continuously and move on paths that are connected over
9.85 Cognition in Infancy and Early Childhood Lecture 7: Number What else might you know about objects? Spelke Objects i. Continuity. Objects exist continuously and move on paths that are connected over
Cognitive Thinking Style Sample Report
 Cognitive Thinking Style Sample Report Goldisc Limited Authorised Agent for IML, PeopleKeys & StudentKeys DISC Profiles Online Reports Training Courses Consultations sales@goldisc.co.uk Telephone: +44
Cognitive Thinking Style Sample Report Goldisc Limited Authorised Agent for IML, PeopleKeys & StudentKeys DISC Profiles Online Reports Training Courses Consultations sales@goldisc.co.uk Telephone: +44
Towards a Robuster Interpretive Parsing
 J Log Lang Inf (2013) 22:139 172 DOI 10.1007/s10849-013-9172-x Towards a Robuster Interpretive Parsing Learning from Overt Forms in Optimality Theory Tamás Biró Published online: 9 April 2013 Springer
J Log Lang Inf (2013) 22:139 172 DOI 10.1007/s10849-013-9172-x Towards a Robuster Interpretive Parsing Learning from Overt Forms in Optimality Theory Tamás Biró Published online: 9 April 2013 Springer
Practitioner s Lexicon What is meant by key terminology.
 Learners at the center. Practitioner s Lexicon What is meant by key terminology. An Initiative of Convergence INTRODUCTION This is a technical document that clarifies key terms found in A Transformational
Learners at the center. Practitioner s Lexicon What is meant by key terminology. An Initiative of Convergence INTRODUCTION This is a technical document that clarifies key terms found in A Transformational
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany
 Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Using AMT & SNOMED CT-AU to support clinical research
 Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Executive Guide to Simulation for Health
 Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
EDIT 576 (2 credits) Mobile Learning and Applications Fall Semester 2015 August 31 October 18, 2015 Fully Online Course
 Mobile Learning and Applications Fall Semester 2015 August 31 October 18, 2015 Fully Online Course") GEORGE MASON UNIVERSITY COLLEGE OF EDUCATION AND HUMAN DEVELOPMENT INSTRUCTIONAL DESIGN AND TECHNOLOGY PROGRAM EDIT 576 (2 credits) Mobile Learning and Applications Fall Semester 2015 August 31 October
GEORGE MASON UNIVERSITY COLLEGE OF EDUCATION AND HUMAN DEVELOPMENT INSTRUCTIONAL DESIGN AND TECHNOLOGY PROGRAM EDIT 576 (2 credits) Mobile Learning and Applications Fall Semester 2015 August 31 October
STUDENTS' RATINGS ON TEACHER
 STUDENTS' RATINGS ON TEACHER Faculty Member: CHEW TECK MENG IVAN Module: Activity Type: DATA STRUCTURES AND ALGORITHMS I CS1020 LABORATORY Class Size/Response Size/Response Rate : 21 / 14 / 66.67% Contact
STUDENTS' RATINGS ON TEACHER Faculty Member: CHEW TECK MENG IVAN Module: Activity Type: DATA STRUCTURES AND ALGORITHMS I CS1020 LABORATORY Class Size/Response Size/Response Rate : 21 / 14 / 66.67% Contact
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
IMGD Technical Game Development I: Iterative Development Techniques. by Robert W. Lindeman
 IMGD 3000 - Technical Game Development I: Iterative Development Techniques by Robert W. Lindeman gogo@wpi.edu Motivation The last thing you want to do is write critical code near the end of a project Induces
IMGD 3000 - Technical Game Development I: Iterative Development Techniques by Robert W. Lindeman gogo@wpi.edu Motivation The last thing you want to do is write critical code near the end of a project Induces
How to Do Research. Jeff Chase Duke University
 How to Do Research Jeff Chase Duke University Sadly... Nobody can tell you how to do research. It is difficult enough just to define what research is, or define how to separate the wheat from the chaff.
How to Do Research Jeff Chase Duke University Sadly... Nobody can tell you how to do research. It is difficult enough just to define what research is, or define how to separate the wheat from the chaff.
Results In. Planning Questions. Tony Frontier Five Levers to Improve Learning 1
 Key Tables and Concepts: Five Levers to Improve Learning by Frontier & Rickabaugh 2014 Anticipated Results of Three Magnitudes of Change Characteristics of Three Magnitudes of Change Examples Results In.
Key Tables and Concepts: Five Levers to Improve Learning by Frontier & Rickabaugh 2014 Anticipated Results of Three Magnitudes of Change Characteristics of Three Magnitudes of Change Examples Results In.
Improving Conceptual Understanding of Physics with Technology
 INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
First Line Manager Development. Facilitated Blended Accredited
 First Line Manager Development Facilitated Blended Accredited Why is First Line Manager development so critical? We combine The Oxford Group s expertise in leadership & management development and experienced
First Line Manager Development Facilitated Blended Accredited Why is First Line Manager development so critical? We combine The Oxford Group s expertise in leadership & management development and experienced
Number Line Moves Dash -- 1st Grade. Michelle Eckstein
 Number Line Moves Dash -- 1st Grade Michelle Eckstein Common Core Standards CCSS.MATH.CONTENT.1.NBT.C.4 Add within 100, including adding a two-digit number and a one-digit number, and adding a two-digit
Number Line Moves Dash -- 1st Grade Michelle Eckstein Common Core Standards CCSS.MATH.CONTENT.1.NBT.C.4 Add within 100, including adding a two-digit number and a one-digit number, and adding a two-digit
Level 1 Mathematics and Statistics, 2015
 91037 910370 1SUPERVISOR S Level 1 Mathematics and Statistics, 2015 91037 Demonstrate understanding of chance and data 9.30 a.m. Monday 9 November 2015 Credits: Four Achievement Achievement with Merit
91037 910370 1SUPERVISOR S Level 1 Mathematics and Statistics, 2015 91037 Demonstrate understanding of chance and data 9.30 a.m. Monday 9 November 2015 Credits: Four Achievement Achievement with Merit
CPS122 Lecture: Identifying Responsibilities; CRC Cards. 1. To show how to use CRC cards to identify objects and find responsibilities
 Objectives: CPS122 Lecture: Identifying Responsibilities; CRC Cards last revised February 7, 2012 1. To show how to use CRC cards to identify objects and find responsibilities Materials: 1. ATM System
Objectives: CPS122 Lecture: Identifying Responsibilities; CRC Cards last revised February 7, 2012 1. To show how to use CRC cards to identify objects and find responsibilities Materials: 1. ATM System
Pedagogical Content Knowledge for Teaching Primary Mathematics: A Case Study of Two Teachers
 Pedagogical Content Knowledge for Teaching Primary Mathematics: A Case Study of Two Teachers Monica Baker University of Melbourne mbaker@huntingtower.vic.edu.au Helen Chick University of Melbourne h.chick@unimelb.edu.au
Pedagogical Content Knowledge for Teaching Primary Mathematics: A Case Study of Two Teachers Monica Baker University of Melbourne mbaker@huntingtower.vic.edu.au Helen Chick University of Melbourne h.chick@unimelb.edu.au
ADDIE: A systematic methodology for instructional design that includes five phases: Analysis, Design, Development, Implementation, and Evaluation.
 ADDIE: A systematic methodology for instructional design that includes five phases: Analysis, Design, Development, Implementation, and Evaluation. I first was exposed to the ADDIE model in April 1983 at
ADDIE: A systematic methodology for instructional design that includes five phases: Analysis, Design, Development, Implementation, and Evaluation. I first was exposed to the ADDIE model in April 1983 at
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
Individual Differences & Item Effects: How to test them, & how to test them well
 Individual Differences & Item Effects: How to test them, & how to test them well Individual Differences & Item Effects Properties of subjects Cognitive abilities (WM task scores, inhibition) Gender Age
Individual Differences & Item Effects: How to test them, & how to test them well Individual Differences & Item Effects Properties of subjects Cognitive abilities (WM task scores, inhibition) Gender Age
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Greedy Decoding for Statistical Machine Translation in Almost Linear Time
 in: Proceedings of HLT-NAACL 23. Edmonton, Canada, May 27 June 1, 23. This version was produced on April 2, 23. Greedy Decoding for Statistical Machine Translation in Almost Linear Time Ulrich Germann
in: Proceedings of HLT-NAACL 23. Edmonton, Canada, May 27 June 1, 23. This version was produced on April 2, 23. Greedy Decoding for Statistical Machine Translation in Almost Linear Time Ulrich Germann
Firms and Markets Saturdays Summer I 2014
 PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Community Rhythms. Purpose/Overview NOTES. To understand the stages of community life and the strategic implications for moving communities
 community rhythms Community Rhythms Purpose/Overview To understand the stages of community life and the strategic implications for moving communities forward. NOTES 5.2 #librariestransform Community Rhythms
community rhythms Community Rhythms Purpose/Overview To understand the stages of community life and the strategic implications for moving communities forward. NOTES 5.2 #librariestransform Community Rhythms
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Backwards Numbers: A Study of Place Value. Catherine Perez
 Backwards Numbers: A Study of Place Value Catherine Perez Introduction I was reaching for my daily math sheet that my school has elected to use and in big bold letters in a box it said: TO ADD NUMBERS
Backwards Numbers: A Study of Place Value Catherine Perez Introduction I was reaching for my daily math sheet that my school has elected to use and in big bold letters in a box it said: TO ADD NUMBERS
10.2. Behavior models
 User behavior research 10.2. Behavior models Overview Why do users seek information? How do they seek information? How do they search for information? How do they use libraries? These questions are addressed
User behavior research 10.2. Behavior models Overview Why do users seek information? How do they seek information? How do they search for information? How do they use libraries? These questions are addressed
The Effect of Discourse Markers on the Speaking Production of EFL Students. Iman Moradimanesh
 The Effect of Discourse Markers on the Speaking Production of EFL Students Iman Moradimanesh Abstract The research aimed at investigating the relationship between discourse markers (DMs) and a special
The Effect of Discourse Markers on the Speaking Production of EFL Students Iman Moradimanesh Abstract The research aimed at investigating the relationship between discourse markers (DMs) and a special
GERM 3040 GERMAN GRAMMAR AND COMPOSITION SPRING 2017
 GERM 3040 GERMAN GRAMMAR AND COMPOSITION SPRING 2017 Instructor: Dr. Claudia Schwabe Class hours: TR 9:00-10:15 p.m. claudia.schwabe@usu.edu Class room: Old Main 301 Office: Old Main 002D Office hours:
GERM 3040 GERMAN GRAMMAR AND COMPOSITION SPRING 2017 Instructor: Dr. Claudia Schwabe Class hours: TR 9:00-10:15 p.m. claudia.schwabe@usu.edu Class room: Old Main 301 Office: Old Main 002D Office hours:
While you are waiting... socrative.com, room number SIMLANG2016
 While you are waiting... socrative.com, room number SIMLANG2016 Simulating Language Lecture 4: When will optimal signalling evolve? Simon Kirby simon@ling.ed.ac.uk T H E U N I V E R S I T Y O H F R G E
While you are waiting... socrative.com, room number SIMLANG2016 Simulating Language Lecture 4: When will optimal signalling evolve? Simon Kirby simon@ling.ed.ac.uk T H E U N I V E R S I T Y O H F R G E
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
ABC of Programming Linda
 ABC of Programming Linda Liukas @lindaliukas (Programmer) (Illustrator) (Author) Business school dropout How many here have programmed before? Who is nervous about bringing computing to kindergartens and
ABC of Programming Linda Liukas @lindaliukas (Programmer) (Illustrator) (Author) Business school dropout How many here have programmed before? Who is nervous about bringing computing to kindergartens and
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD
 TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling