Data Classification: Advanced Concepts. Lijun Zhang
|
|
|
- Augusta Henry
- 5 years ago
- Views:
Transcription

1 Data Classification: Advanced Concepts Lijun Zhang
2 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
3 Introduction Difficult Classification Scenarios Multiclass learning Rare class learning Scalable learning Numeric class variables Enhancing Classification Semisupervised learning Active learning Ensemble learning
4 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
5 Multiclass Learning Many classifiers can be directly used for multiclass learning Decision trees, Bayesian methods, Rulebased classifiers Many classifiers can be generalized to multiclass case Support vector machines (SVMs), Neural networks, Logistic regression Generic meta-frameworks Directly use the binary methods for multiclass classification
6 One-against-rest Approach different binary classification problems are created In the th problem, the th class is considered the set of positive examples, whereas all the rest are negative models are applied during testing If the positive class is predicted in the th problem, then the th class is rewarded with a vote Otherwise, each of the remaining classes is rewarded with a vote Weighted vote is also possible
7 One-against-one Approach A training data set is constructed for each of the pairs of classes Results in testing models models are applied during For each model, the prediction provides a vote to the winner Weighted vote is also possible For each model, the size of training data is small ( of the original one)
8 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
9 Rare Class Learning The class distribution is unbalanced Credit card activity: of data are normal and of data are fraudulent Given a test instance, whose nearest 100 neighbors contain 49 rare class instances and 51 normal class instances -nearest neighbor with 100 will output normal However, it is surrounded by large fraction of rare instances relative to expectation Outputting normal achieves accuracy
10 The General Idea Achieving a high accuracy on the rare class is more important The cost of misclassifying a rare class are much higher than those of misclassifying the normal class Cost-weighted Accuracy A misclassification cost with class Two Approaches Example reweighting Example resampling is associated
11 Example Reweighting (1) All instances belonging to the th class are weighted by Existing methods need to be modified Decision trees Gini index and entropy Rule-based classifiers Laplacian measure and information gain Bayes classifiers Class priors and conditional probabilities Instance-based methods Weighted votes
12 Example Reweighting (2) Support vector machines min,,,, 2 s. t. min,,,, 2 s. t.
13 Sampling Methods Different classes are differentially sampled to enhance the rare class The sampling probabilities are typically chosen in proportion to their misclassification costs The rare class can be oversampled The normal class can be undersampled One-sided selection All instances of the rare class are used A small sample of the normal class are used Both efficient and effective
14 Synthetic Oversampling: SMOTE Oversampling the rare class Repeated samples of the same data point Repeated samples cause overfitting The SMOTE approach For each rear instance, its nearest neighbors belonging to the same class are determined A fraction of them are chosen randomly For each sampled example-neighbor pair, a synthetic data example is generated on the line segment connecting them
15 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
16 Scalable Classification Data cannot be loaded in memory Traditional algorithms are not optimized to disk-resident data One solution sampling the data Lose knowledge in the discarded data Some classifiers can be made faster by using more efficient subroutines Associative classifiers: frequent pattern mining Nearest-neighbor methods: nearestneighbor indexing
17 Scalable Decision Trees (1) RainForest The evaluation of the split criteria in univariate decision trees do not need access to the data in its multidimensional form Only the count statistics of distinct attributes values need to be maintained over different classes AVC-set at each node: counts of the distinct values of the attribute for different classes Depends only on the number of features, number of distinct attribute values and the number of classes
18 Scalable Decision Trees (2) Bootstrapped Optimistic Algorithm for Tree construction (BOAT) In bootstrapping, the data is sampled with replacement to create different bootstrapped samples These are used to create different trees BOAT uses them to create a new tree that is very close to the one constructed from all the data It requires only two scans over the database
19 Scalable Support Vector Machines (1) Dual of Kernel SVM variables, and memory The SVMLight approach It is not necessary to solve the entire problem at one time. The support vectors for the SVMs correspond to only a small number of training data points
20 Scalable Support Vector Machines (2) Dual of Kernel SVM variables, and memory The SVMLight approach Select variables as the active working set, and solve Select a working set that leads to the maximum improvement in the objective Shrinking the training data during the optimization process
21 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
22 Semisupervised Learning Labeled data is expensive and hard to acquire Unlabeled data is often copiously available Unlabeled data is useful Unlabeled data can be used to estimate the low-dimensional manifold structure of the data Unlabeled data can be used to estimate the joint probability distribution of features
23 The 1 st Example
24 The 1 st Example Class variables are likely to vary smoothly over dense regions
25 The 2 nd Example The goal is to determine whether documents belong to the Science category. In labeled data, we found the word Physics is associated with the Science category In unlabeled data, we found the word Einstein often co-occur with Physics Thus, the unlabeled documents provide the insight that the word Einstein is also relevant to the Science category
26 Techniques for Semisupervised Learning Meta-algorithms that can use any existing classification algorithm as a subroutine Self-Training Co-training Specific Algorithms Semisupervised Bayes classifiers Transductive support vector machines Graph-Based Semisupervised Learning
27 Self-training The Procedure Initial labeled set and unlabeled set 1. Use algorithm on the current labeled set to identify the instances in the unlabeled data for which the classifier is the most confident 2. Assign labels to the most confidently predicted instances and add them to. Remove these instances from Overfitting Addition of predicted labels may propagate errors
28 Co-training The Procedure Two disjoint feature groups: and Labeled sets and 1. Train classifier using labeled set and feature set, and add most confidently predicted instances from unlabeled set to training data set for classifier 2. Train classifier using labeled set and feature set, and add most confidently predicted instances from unlabeled set to training data set for classifier
29 Techniques for Semisupervised Learning Meta-algorithms that can use any existing classification algorithm as a subroutine Self-Training Co-training Specific Algorithms Semisupervised Bayes classifiers Transductive support vector machines Graph-Based Semisupervised Learning
30 Naive Bayes (1) Model for Classification The goal is to predict Bayes theorem Naive Bayes approximation Bayes probability
31 Naive Bayes (2) Training : estimated as the fraction of training examples taking on value, conditional on the fact, that they belong to class
32 Semisupervised Bayes Classification with EM The Key idea Create semi-supervised clusters from the data, and learn from those clusters The Procedure (E-step) Estimate posterior probability (M-step) Estimate conditional probability
33 Transductive support vector machines Support Vector Machines min,,,, 2 s. t. Adding Unlabeled Data Integer Program Can only be solved approximately
34 Graph-Based Semisupervised Learning Procedures Semisupervised Learning over Graph Zhou et al. Learning with Local and Global Consistency. In NIPS, 2004.
35 Discussions Should we always use unlabeled data? For semisupervised learning to be effective, the class structure of the data should approximately match its clustering structure In practice, semisupervised learning is most effective when the number of labeled examples is extremely small
36 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
37 Active Learning Labels are Expensive Document collections Privacy-constrained data sets Social networks Solutions Utilize the unlabeled data Semisupervised learning Label the most informative data Active learning
38 An Example (1) Random Sampling
39 An Example (2) Active Sampling
40 Modeling The Key Question How do we select instances to label to create the most accurate model at a given cost? Two Primary Components Oracle: The oracle provides labels for queries Query system: The job of the query system is to pose queries to the oracle Two Types of Query Systems Selective Sampling Pool-based Sampling
41 Categories Heterogeneity-based models Uncertainty Sampling Query-by-Committee Expected Model Change Performance-based models Expected Error Reduction Expected Variance Reduction Representativeness-based models
42 Uncertainty Sampling Label those instances for which the value of the label is the least certain Bayes classifiers lower values are indicative of greater uncertainty SVM Distance
43 Expected Error Reduction (1) Denote the unlabeled set as Select samples from to minimizes the prediction error of the remaining samples in Select samples from to minimizes the label uncertainty of the remaining samples in Select samples from to minimizes the expected label uncertainty of the remaining samples in
44 Expected Error Reduction (2) Let be the posterior probability of the label for the query candidate instance, Let be the posterior probability of the label for, after is added to the training set The Error Objective of
45 Representativeness-Based Models Heterogeneity-based models may select outliers Combine the heterogeneity behavior of the queried instance with a representativeness function can be any heterogeneity criteria is simply a measure of the density of with respect to Average similarity of to the instances in
46 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
47 Ensemble Methods 三个臭皮匠顶个诸葛亮 Is it always possible? Ensemble Method Different classifiers may make different predictions on test instances Increase the prediction accuracy by combining the results from multiple classifiers
48 The generic ensemble framework Three freedoms Learners, training data, combination
49 Why Does Ensemble Analysis Work? There are three types of error Bias: Every classifier makes its own modeling assumptions about the decision boundary
50 Why Does Ensemble Analysis Work? There are three types of error Variance: Random variations in the training data will lead to different models
51 Why Does Ensemble Analysis Work? There are three types of error Noise: The noise refers to the intrinsic errors in the target class labeling
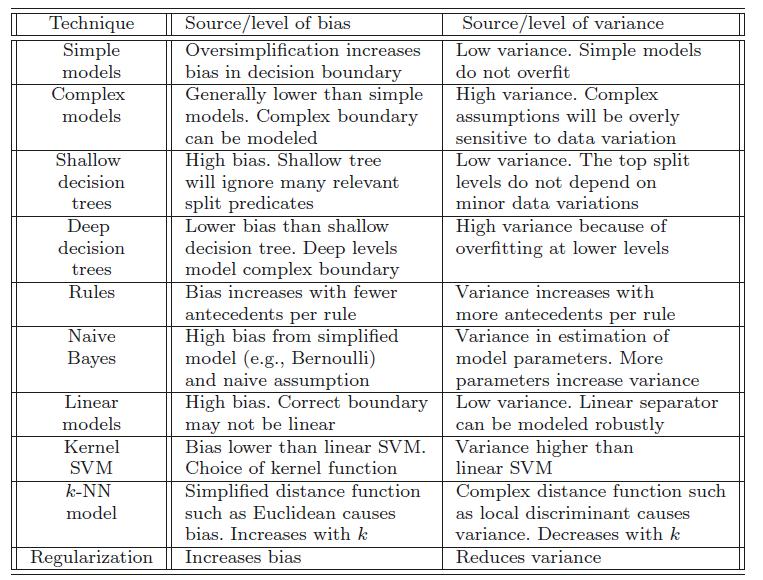
52 Bias-Variance Trade-off
53 Why Does Ensemble Analysis Work? Reduce Bias
54 Why Does Ensemble Analysis Work? Reduce Variance
55 Formal Statement of Bias- Variance Trade-off The Classification Problem is the noise Given training data The Expected Mean Squared Error over
56 Bagging (Bootstrapped Aggregating) The Basic Idea If the variance of a prediction is, then the variance of the average of i.i.d. predictions is / The Procedure A total of different bootstrapped samples are drawn independently Data points are sampled uniformly from the original data with replacement A classifier is trained on each of them Prediction The dominant vote of the different classifiers
57 Random Forests Bagging based on Decision Trees The split choices at the top levels are statistically likely to remain approximately invariant to bootstrapped sampling A generalization of the basic bagging method, as applied to decision trees Reduce the correlation explicitly The Key Idea Use a randomized decision tree model Random-split Selection
58 Random-split Selection Random Input Selection At each node, select of a subset of attributes of size randonly The splits are executed using only this subset 1 log Random Linear Combinations At each node, features are randomly selected and combined linearly with coefficients generated uniformly from 1,1 A total of such combinations are generated in order to create a new subset
59 Boosting The Basic Idea A weight is associated with each training instance The different classifiers are trained with the use of these weights The weights are modified iteratively based on classifier performance Focus on the incorrectly classified instances in future iterations by increasing the relative weight of these instances
60 AdaBoost Aim to Reduce Bias
61 Outline Introduction Multiclass Learning Rare Class Learning Scalable Classification Semisupervised Learning Active Learning Ensemble Methods Summary
62 Summary Multiclass Learning One-against-rest, One-against-one Rare Class Learning Example Reweighting, Sampling Scalable Classification Scalable Decision Trees, Scalable SVM Semisupervised Learning Self-Training, Co-training, Semisupervised Bayes Classification, Transductive SVM, Graph-Based Semisupervised Learning Active Learning Heterogeneity-Based, Performance-Based, Representativeness- Based Ensemble Methods Bais-Variance, Bagging, Random Forests, Boosting
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Data Fusion Through Statistical Matching
 A research and education initiative at the MIT Sloan School of Management Data Fusion Through Statistical Matching Paper 185 Peter Van Der Puttan Joost N. Kok Amar Gupta January 2002 For more information,
A research and education initiative at the MIT Sloan School of Management Data Fusion Through Statistical Matching Paper 185 Peter Van Der Puttan Joost N. Kok Amar Gupta January 2002 For more information,
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Learning Distributed Linguistic Classes
 In: Proceedings of CoNLL-2000 and LLL-2000, pages -60, Lisbon, Portugal, 2000. Learning Distributed Linguistic Classes Stephan Raaijmakers Netherlands Organisation for Applied Scientific Research (TNO)
In: Proceedings of CoNLL-2000 and LLL-2000, pages -60, Lisbon, Portugal, 2000. Learning Distributed Linguistic Classes Stephan Raaijmakers Netherlands Organisation for Applied Scientific Research (TNO)
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
FRAMEWORK FOR IDENTIFYING THE MOST LIKELY SUCCESSFUL UNDERPRIVILEGED TERTIARY STUDY BURSARY APPLICANTS
 South African Journal of Industrial Engineering August 2017 Vol 28(2), pp 59-77 FRAMEWORK FOR IDENTIFYING THE MOST LIKELY SUCCESSFUL UNDERPRIVILEGED TERTIARY STUDY BURSARY APPLICANTS R. Steynberg 1 * #,
South African Journal of Industrial Engineering August 2017 Vol 28(2), pp 59-77 FRAMEWORK FOR IDENTIFYING THE MOST LIKELY SUCCESSFUL UNDERPRIVILEGED TERTIARY STUDY BURSARY APPLICANTS R. Steynberg 1 * #,
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Team Formation for Generalized Tasks in Expertise Social Networks
 IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust Team Formation for Generalized Tasks in Expertise Social Networks Cheng-Te Li Graduate
IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust Team Formation for Generalized Tasks in Expertise Social Networks Cheng-Te Li Graduate
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning
 Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
Multivariate k-nearest Neighbor Regression for Time Series data -
 Multivariate k-nearest Neighbor Regression for Time Series data - a novel Algorithm for Forecasting UK Electricity Demand ISF 2013, Seoul, Korea Fahad H. Al-Qahtani Dr. Sven F. Crone Management Science,
Multivariate k-nearest Neighbor Regression for Time Series data - a novel Algorithm for Forecasting UK Electricity Demand ISF 2013, Seoul, Korea Fahad H. Al-Qahtani Dr. Sven F. Crone Management Science,
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Analysis of Enzyme Kinetic Data
 Analysis of Enzyme Kinetic Data To Marilú Analysis of Enzyme Kinetic Data ATHEL CORNISH-BOWDEN Directeur de Recherche Émérite, Centre National de la Recherche Scientifique, Marseilles OXFORD UNIVERSITY
Analysis of Enzyme Kinetic Data To Marilú Analysis of Enzyme Kinetic Data ATHEL CORNISH-BOWDEN Directeur de Recherche Émérite, Centre National de la Recherche Scientifique, Marseilles OXFORD UNIVERSITY
Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the SAT
 The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Comparison of EM and Two-Step Cluster Method for Mixed Data: An Application
 International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
stateorvalue to each variable in a given set. We use p(x = xjy = y) (or p(xjy) as a shorthand) to denote the probability that X = x given Y = y. We al
 (or p(xjy) as a shorthand) to denote the probability that X = x given Y = y. We al") Dependency Networks for Collaborative Filtering and Data Visualization David Heckerman, David Maxwell Chickering, Christopher Meek, Robert Rounthwaite, Carl Kadie Microsoft Research Redmond WA 98052-6399
Dependency Networks for Collaborative Filtering and Data Visualization David Heckerman, David Maxwell Chickering, Christopher Meek, Robert Rounthwaite, Carl Kadie Microsoft Research Redmond WA 98052-6399
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
STT 231 Test 1. Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point.
 STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes
 Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes Viviana Molano 1, Carlos Cobos 1, Martha Mendoza 1, Enrique Herrera-Viedma 2, and
Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes Viviana Molano 1, Carlos Cobos 1, Martha Mendoza 1, Enrique Herrera-Viedma 2, and
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Welcome to. ECML/PKDD 2004 Community meeting
 Welcome to ECML/PKDD 2004 Community meeting A brief report from the program chairs Jean-Francois Boulicaut, INSA-Lyon, France Floriana Esposito, University of Bari, Italy Fosca Giannotti, ISTI-CNR, Pisa,
Welcome to ECML/PKDD 2004 Community meeting A brief report from the program chairs Jean-Francois Boulicaut, INSA-Lyon, France Floriana Esposito, University of Bari, Italy Fosca Giannotti, ISTI-CNR, Pisa,
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Introduction to Causal Inference. Problem Set 1. Required Problems
 Introduction to Causal Inference Problem Set 1 Professor: Teppei Yamamoto Due Friday, July 15 (at beginning of class) Only the required problems are due on the above date. The optional problems will not
Introduction to Causal Inference Problem Set 1 Professor: Teppei Yamamoto Due Friday, July 15 (at beginning of class) Only the required problems are due on the above date. The optional problems will not
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Exposé for a Master s Thesis
 Exposé for a Master s Thesis Stefan Selent January 21, 2017 Working Title: TF Relation Mining: An Active Learning Approach Introduction The amount of scientific literature is ever increasing. Especially
Exposé for a Master s Thesis Stefan Selent January 21, 2017 Working Title: TF Relation Mining: An Active Learning Approach Introduction The amount of scientific literature is ever increasing. Especially
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees
 Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE. Pierre Foy
 TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,