Reinforcement Learning
|
|
|
- Joseph Watkins
- 5 years ago
- Views:
Transcription
1 School of Computer Science Introduction to Machine Learning Reinforcement Learning Readings: Mitchell Ch. 13 Matt Gormley Lecture 22 November 30,
2 Poster Session Reminders Fri, Dec 2: 2:30pm 5:30 pm Final Report due Fri, Dec 9 2
3 REINFORCEMENT LEARNING 3
4 What is Learning? Learning takes place as a result of interaction between an agent and the world, the idea behind learning is that Percepts received by an agent should be used not only for understanding/interpreting/prediction, as in the machine learning tasks we have addressed so far, but also for acting, and further more for improving the agent s ability to behave optimally in the future to achieve the goal. 4
5 Types of Learning Supervised Learning A situation in which sample (input, output) pairs of the function to be learned can be perceived or are given You can think it as if there is a kind teacher - Training data: (X,Y). (features, label) - Predict Y, minimizing some loss. - Regression, Classification. Unsupervised Learning - Training data: X. (features only) - Find similar points in high-dim X-space. - Clustering. 5
 Predict whether a patient, hospitalized due to a heart attack, will have a second heart attack.")
6 Example of Supervised Learning Predict the price of a stock in 6 months from now, based on economic data. (Regression) Predict whether a patient, hospitalized due to a heart attack, will have a second heart attack. The prediction is to be based on demographic, diet and clinical measurements for that patient. (Logistic Regression) Identify the numbers in a handwritten ZIP code, from a digitized image (pixels). (Classification) 6

7 Example of Unsupervised Learning From the DNA micro-array data, determine which genes are most similar in terms of their expression profiles. (Clustering) 7
8 Types of Learning (Cont d) Reinforcement Learning in the case of the agent acts on its environment, it receives some evaluation of its action (reinforcement), but is not told of which action is the correct one to achieve its goal - Training data: (S, A, R). (State-Action-Reward) - Develop an optimal policy (sequence of decision rules) for the learner so as to maximize its long-term reward. - Robotics, Board game playing programs. 8
9 RL is learning from interaction 9

 How to automate the motion")
 How to make a good")
10 Examples of Reinforcement Learning How should a robot behave so as to optimize its performance? (Robotics) How to automate the motion of a helicopter? (Control Theory) How to make a good chess-playing program? (Artificial Intelligence) 10
11 Autonomous Helicopter Video: 11
12 Robot in a room what s the strategy to achieve max reward? what if the actions were NOT deterministic? 12
13 Pole Balancing Task: Move car left/right to keep the pole balanced State representation Position and velocity of the car Angle and angular velocity of the pole 13
14 History of Reinforcement Learning Roots in the psychology of animal learning (Thorndike,1911). Another independent thread was the problem of optimal control, and its solution using dynamic programming (Bellman, 1957). Idea of temporal difference learning (on-line method), e.g., playing board games (Samuel, 1959). A major breakthrough was the discovery of Q-learning (Watkins, 1989). 14
15 What is special about RL? RL is learning how to map states to actions, so as to maximize a numerical reward over time. Unlike other forms of learning, it is a multistage decisionmaking process (often Markovian). An RL agent must learn by trial-and-error. (Not entirely supervised, but interactive) Actions may affect not only the immediate reward but also subsequent rewards (Delayed effect). 15
16 Elements of RL A policy - A map from state space to action space. - May be stochastic. A reward function - It maps each state (or, state-action pair) to a real number, called reward. A value function - Value of a state (or, state-action pair) is the total expected reward, starting from that state (or, state-action pair). 16
17 Maze Example Start Rewards: -1 per time-step Actions: N, E, S, W States: Agent s location Goal Slide from David Silver (Intro RL lecture) 17
18 Maze Example Policy: Start Goal Arrows represent policy (s) for each state s Slide from David Silver (Intro RL lecture) 18
19 Maze Example Value Function: (Expected Future Reward) Start Goal Numbers represent value v (s) of each state s Slide from David Silver (Intro RL lecture) 19
20 Maze Example Model: Start Goal Agent may have an internal model of the environment Dynamics: how actions change the state Rewards: how much reward from each state The model may be imperfect Grid layout represents transition model P a ss 0 Numbers represent immediate reward R a s from each state s (same for all a) Slide from David Silver (Intro RL lecture) 20
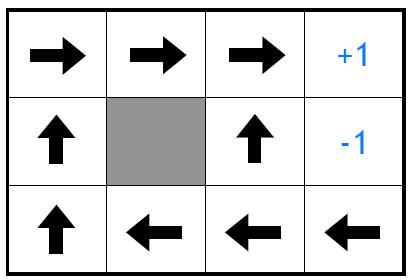
21 Policy 21
22 Reward for each step -2 22

23 Reward for each step:

24 Reward for each step:
25 The Precise Goal To find a policy that maximizes the Value function. transitions and rewards usually not available There are different approaches to achieve this goal in various situations. Value iteration and Policy iteration are two more classic approaches to this problem. But essentially both are dynamic programming. Q-learning is a more recent approaches to this problem. Essentially it is a temporal-difference method. 25
26 MARKOV DECISION PROCESSES 26
27 Markov Decision Processes A Markov decision process is a tuple where: 27
28 The dynamics of an MDP We start in some state s 0, and get to choose some action a 0 A As a result of our choice, the state of the MDP randomly transitions to some successor state s 1, drawn according to s 1 ~ P s0a0 Then, we get to pick another action a 1 28
29 The dynamics of an MDP, (Cont d) Upon visiting the sequence of states s 0, s 1,, with actions a 0, a 1,, our total payoff is given by Or, when we are writing rewards as a function of the states only, this becomes For most of our development, we will use the simpler state-rewards R(s), though the generalization to state-action rewards R(s; a) offers no special diffculties. Our goal in reinforcement learning is to choose actions over time so as to maximize the expected value of the total payoff: 29
30 FIXED POINT ITERATION 30
 dj( ) =0=f( ) d i 0=f( ) ) i = g( ) (t+1) i = g( (t) ) 1. Given objective function: 2. Compute derivative, set to zero (call this function f ). 3. Rearrange the equation s.t. one of parameters appears on the LHS.")
31 Fixed Point Iteration for Optimization Fixed point iteration is a general tool for solving systems of equations It can also be applied to optimization. J( ) dj( ) =0=f( ) d i 0=f( ) ) i = g( ) (t+1) i = g( (t) ) 1. Given objective function: 2. Compute derivative, set to zero (call this function f ). 3. Rearrange the equation s.t. one of parameters appears on the LHS. 4. Initialize the parameters. 5. For i in {1,...,K}, update each parameter and increment t: 6. Repeat #5 until convergence 31
 = x3 3 + 3 2 x2 +2x dj(x) dx = f(x) =x2 3x +2=0 ) x = x2 +2 3 x 2 +2 x 3 = g(x) 1.")

32 Fixed Point Iteration for Optimization Fixed point iteration is a general tool for solving systems of equations It can also be applied to optimization. J(x) = x x2 +2x dj(x) dx = f(x) =x2 3x +2=0 ) x = x x 2 +2 x 3 = g(x) 1. Given objective function: 2. Compute derivative, set to zero (call this function f ). 3. Rearrange the equation s.t. one of parameters appears on the LHS. 4. Initialize the parameters. 5. For i in {1,...,K}, update each parameter and increment t: 6. Repeat #5 until convergence 32
33 Fixed Point Iteration for Optimization J(x) = x x2 +2x dj(x) dx = f(x) =x2 3x +2=0 ) x = x x 2 +2 x 3 = g(x) We can implement our example in a few lines of python. 33
34 Fixed Point Iteration for Optimization J(x) = x x2 +2x dj(x) dx = f(x) =x2 3x +2=0 ) x = x x 2 +2 x 3 = g(x) $ python fixed-point-iteration.py i= 0 x= f(x)= i= 1 x= f(x)= i= 2 x= f(x)= i= 3 x= f(x)= i= 4 x= f(x)= i= 5 x= f(x)= i= 6 x= f(x)= i= 7 x= f(x)= i= 8 x= f(x)= i= 9 x= f(x)= i=10 x= f(x)= i=11 x= f(x)= i=12 x= f(x)= i=13 x= f(x)= i=14 x= f(x)= i=15 x= f(x)= i=16 x= f(x)= i=17 x= f(x)= i=18 x= f(x)= i=19 x= f(x)= i=20 x= f(x)=
35 VALUE ITERATION 35
36 Elements of RL A policy - A map from state space to action space. - May be stochastic. A reward function - It maps each state (or, state-action pair) to a real number, called reward. A value function - Value of a state (or, state-action pair) is the total expected reward, starting from that state (or, state-action pair). 36
37 Policy A policy is any function mapping from the states to the actions. We say that we are executing some policy if, whenever we are in state s, we take action a = π(s). We also define the value function for a policy π according to V π (s) is simply the expected sum of discounted rewards upon starting in state s, and taking actions according to π. 37
38 Value Function Given a fixed policy π, its value function V π satisfies the Bellman equations: Immediate reward expected sum of future discounted rewards Bellman's equations can be used to efficiently solve for V π (see later) 38
39 The Grid world M = 0.8 in direction you want to go 0.2 in perpendicular Policy: mapping from states to actions An optimal policy for the stochastic environmen t: Environment left 0.1 right utilities of states: Observable (accessible): percept identifies the state Partially observable Markov property: Transition probabilities depend on state only, not on the path to the state. Markov decision problem (MDP). Partially observable MDP (POMDP): percepts does not have enough info to identify 39
40 Optimal value function We define the optimal value function according to (1) In other words, this is the best possible expected sum of discounted rewards that can be attained using any policy There is a version of Bellman's equations for the optimal value function: (2) Why? 40
41 Optimal policy We also define a policy : as follows: (3) Fact: Policy π * has the interesting property that it is the optimal policy for all states s. It is not the case that if we were starting in some state s then there'd be some optimal policy for that state, and if we were starting in some other state s 0 then there'd be some other policy that's optimal policy for s 0. The same policy π * attains the maximum above for all states s. This means that we can use the same policy no matter what the initial state of our MDP is. 41
42 The Basic Setting for Learning Training data: n finite horizon trajectories, of the form s, a, r,..., s, a, r, s }. { T T T T + 1 Deterministic or stochastic policy: A sequence of decision rules π, π,..., π }. { 0 1 T Each π maps from the observable history (states and actions) to the action space at that time point. 42
43 Algorithm 1: Value iteration Consider only MDPs with finite state and action spaces The value iteration algorithm: synchronous update asynchronous updates It can be shown that value iteration will cause V to converge to V *. Having found V*, we can then use Equation (3) to find the optimal policy. 43
44 Algorithm 2: Policy iteration The policy iteration algorithm: The inner-loop repeatedly computes the value function for the current policy, and then updates the policy using the current value function. Greedy update After at most a finite number of iterations of this algorithm, V will converge to V*, and π will converge to π*. 44
45 Convergence The utility values for selected states at each iteration step in the application of VALUE-ITERATION to the 4x3 world in our example start Thrm: As tà, value iteration converges to exact U even if updates are done asynchronously & i is picked randomly at every step. 45
46 Convergence When to stop value iteration? 46
47 Q- LEARNING 47
48 Q learning Define Q-value function Q-value function updating rule See subsequent slides Key idea of TD-Q learning Combined with temporal difference approach Rule to chose the action to take 48
49 Algorithm 3: Q learning For each pair (s, a), initialize Q(s,a) Observe the current state s Loop forever { Select an action a (optionally with ε-exploration) and execute it Receive immediate reward r and observe the new state s Update Q(s,a) } s=s 49
50 Exploration Tradeoff between exploitation (control) and exploration (identification) Extremes: greedy vs. random acting (n-armed bandit models) Q-learning converges to optimal Q-values if Every state is visited infinitely often (due to exploration), The action selection becomes greedy as time approaches infinity, and The learning rate a is decreased fast enough but not too fast (as we discussed in TD learning) 50
51 RL EXAMPLES 51

52 A Success Story TD Gammon (Tesauro, G., 1992) - A Backgammon playing program. - Application of temporal difference learning. - The basic learner is a neural network. - It trained itself to the world class level by playing against itself and learning from the outcome. So smart!! - More information: tdl.html 52


 observation action Ot At")
53 Atari Example: Reinforcement Learni Playing Atari with Deep RL Setup: RL system observes the pixels on the screen It receives rewards as the game score Actions decide how to move the joystick / buttons Figures from David Silver (Intro RL lecture) observation action Ot At reward Rt 53
54 Playing Atari with Deep RL Figure 1: Screen shots from five Atari 2600 Games: (Left-to-right) Pong, Breakout, Space Invaders, Seaquest, Beam Rider Videos: Atari: v=v1eynij0rnk Space Invaders: v=epv0fs9cggu Figures from Mnih et al. (2013) 54
 Pong, Breakout, Space Invaders, Seaquest, Beam Rider B.")

![2 129 19 614 665 271 Contingency [4] 1743 6 159 17 960 723 268 DQN 4092 168 470 20 1952](/docs-images/81/84581505/images/55-2.jpg "1705 581 Human 7456 31 368 3 18900 28010 3690 HNeat Best [8] 3616 52 106 19 1800 920 1720")
![HNeat Pixel [8] 1332 4 91 16 1325 800 1145 DQN Best 5184 225 661 21 4500 1740 1075 Table](/docs-images/81/84581505/images/55-3.jpg "1: The upper table compares average total reward for various learning methods by running")

55 Playing Atari with Deep RL Figure 1: Screen shots from five Atari 2600 Games: (Left-to-right) Pong, Breakout, Space Invaders, Seaquest, Beam Rider B. Rider Breakout Enduro Pong Q*bert Seaquest S. Invaders Random Sarsa [3] Contingency [4] DQN Human HNeat Best [8] HNeat Pixel [8] DQN Best Table 1: The upper table compares average total reward for various learning methods by running an -greedy policy with =0.05 for a fixed number of steps. The lower table reports results of the single best performing episode for HNeat and DQN. HNeat produces deterministic policies that always get the same score while DQN used an -greedy policy with =0.05. Figures from Mnih et al. (2013) 55
56 Alpha Go Game of Go ( 圍棋 ) 19x19 board Players alternately play black/white stones Goal is to fully encircle the largest region on the board Simple rules, but extremely complex game play Figure from Silver et al. (2016) Game 1 Fan Hui (Black), AlphaGo (White) AlphaGo wins by 2.5 points at at at at G A A
 Go: b=250 and d=150 Chess: b=35 and d=80 Key idea: Define a")


 Self Play Regression Self-play positions Neural network Data s s the")
57 Alpha Go State space is too large to represent explicitly since # of sequences of moves is O(b d ) Go: b=250 and d=150 Chess: b=35 and d=80 Key idea: Define a neural network to approximate the value function Train by policy gradient a Rollout policy SL policy network RL policy network Value network Policy network Value network b p p p p (a s) (s ) Classification Classification Human expert positions Policy gradient Figure 1 Neural network training pipeline and architecture. a, A fast Figure from Silver et al. (2016) Self Play Regression Self-play positions Neural network Data s s the current player wins) in positions from the self-play data set. 57
 9p 7p 5p 3p 1p 3,500 GnuGo Fuego Pachi Crazy Stone Fan Hui AlphaGo")
: a 230 point gap corresponds to a 79% probability of winning Va Po Figure 4 Tournament")
.")
58 Alpha Go 3,000 9d 7d 2,000 5d 1,500 3d 1,000 1d 1k 5k 7k 0 Beginner kyu (k) 3k 500 Amateur dan (d) Elo Rating 2,500 Professional dan (p) 9p 7p 5p 3p 1p 3,500 GnuGo Fuego Pachi Crazy Stone Fan Hui AlphaGo Figure from Silver et al. (2016) a AlphaGo distributed Results of a tournament From Silver et al. (2016): a 230 point gap corresponds to a 79% probability of winning Va Po Figure 4 Tournament evaluation of AlphaGo. a, Results of a tournament between different Go programs (see Extended Dat 6 11). Each program used approximately 5 s computation time 58 (pa To provide a greater challenge to AlphaGo, some programs
59 SUMMARY 59
60 Summary Both value iteration and policy iteration are standard algorithms for solving MDPs, and there isn't currently universal agreement over which algorithm is better. For small MDPs, value iteration is often very fast and converges with very few iterations. However, for MDPs with large state spaces, solving for V explicitly would involve solving a large system of linear equations, and could be difficult. In these problems, policy iteration may be preferred. In practice value iteration seems to be used more often than policy iteration. Q-learning is model-free, and explore the temporal difference 60
61 Types of Learning Supervised Learning - Training data: (X,Y). (features, label) - Predict Y, minimizing some loss. - Regression, Classification. Unsupervised Learning - Training data: X. (features only) - Find similar points in high-dim X-space. - Clustering. Reinforcement Learning - Training data: (S, A, R). (State-Action-Reward) - Develop an optimal policy (sequence of decision rules) for the learner so as to maximize its long-term reward. - Robotics, Board game playing programs 61
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
New Features & Functionality in Q Release Version 3.2 June 2016
 in Q Release Version 3.2 June 2016 Contents New Features & Functionality 3 Multiple Applications 3 Class, Student and Staff Banner Applications 3 Attendance 4 Class Attendance 4 Mass Attendance 4 Truancy
in Q Release Version 3.2 June 2016 Contents New Features & Functionality 3 Multiple Applications 3 Class, Student and Staff Banner Applications 3 Attendance 4 Class Attendance 4 Mass Attendance 4 Truancy
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus
 Spring 2008 Syllabus") Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
Stochastic Calculus for Finance I (46-944) Spring 2008 Syllabus Introduction. This is a first course in stochastic calculus for finance. It assumes students are familiar with the material in Introduction
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design
 Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
LEGO MINDSTORMS Education EV3 Coding Activities
 LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
Improving Fairness in Memory Scheduling
 Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
Improving Fairness in Memory Scheduling Using a Team of Learning Automata Aditya Kajwe and Madhu Mutyam Department of Computer Science & Engineering, Indian Institute of Tehcnology - Madras June 14, 2014
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
AP Calculus AB. Nevada Academic Standards that are assessable at the local level only.
 Calculus AB Priority Keys Aligned with Nevada Standards MA I MI L S MA represents a Major content area. Any concept labeled MA is something of central importance to the entire class/curriculum; it is a
Calculus AB Priority Keys Aligned with Nevada Standards MA I MI L S MA represents a Major content area. Any concept labeled MA is something of central importance to the entire class/curriculum; it is a
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Functional Skills Mathematics Level 2 assessment
 Functional Skills Mathematics Level 2 assessment www.cityandguilds.com September 2015 Version 1.0 Marking scheme ONLINE V2 Level 2 Sample Paper 4 Mark Represent Analyse Interpret Open Fixed S1Q1 3 3 0
Functional Skills Mathematics Level 2 assessment www.cityandguilds.com September 2015 Version 1.0 Marking scheme ONLINE V2 Level 2 Sample Paper 4 Mark Represent Analyse Interpret Open Fixed S1Q1 3 3 0
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE. Junior Year. Summer (Bridge Quarter) Fall Winter Spring GAME Credits.
 Fall Winter Spring GAME Credits.") DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
Cal s Dinner Card Deals
 Cal s Dinner Card Deals Overview: In this lesson students compare three linear functions in the context of Dinner Card Deals. Students are required to interpret a graph for each Dinner Card Deal to help
Cal s Dinner Card Deals Overview: In this lesson students compare three linear functions in the context of Dinner Card Deals. Students are required to interpret a graph for each Dinner Card Deal to help
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Managerial Decision Making
 Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Executive Guide to Simulation for Health
 Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task
 Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Curriculum Design Project with Virtual Manipulatives. Gwenanne Salkind. George Mason University EDCI 856. Dr. Patricia Moyer-Packenham
 Curriculum Design Project with Virtual Manipulatives Gwenanne Salkind George Mason University EDCI 856 Dr. Patricia Moyer-Packenham Spring 2006 Curriculum Design Project with Virtual Manipulatives Table
Curriculum Design Project with Virtual Manipulatives Gwenanne Salkind George Mason University EDCI 856 Dr. Patricia Moyer-Packenham Spring 2006 Curriculum Design Project with Virtual Manipulatives Table
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Mathematics process categories
 Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
Essentials of Ability Testing. Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology
 Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Version Space. Term 2012/2013 LSI - FIB. Javier Béjar cbea (LSI - FIB) Version Space Term 2012/ / 18
 Version Space Term 2012/ / 18") Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Results In. Planning Questions. Tony Frontier Five Levers to Improve Learning 1
 Key Tables and Concepts: Five Levers to Improve Learning by Frontier & Rickabaugh 2014 Anticipated Results of Three Magnitudes of Change Characteristics of Three Magnitudes of Change Examples Results In.
Key Tables and Concepts: Five Levers to Improve Learning by Frontier & Rickabaugh 2014 Anticipated Results of Three Magnitudes of Change Characteristics of Three Magnitudes of Change Examples Results In.
Lesson plan for Maze Game 1: Using vector representations to move through a maze Time for activity: homework for 20 minutes
 Lesson plan for Maze Game 1: Using vector representations to move through a maze Time for activity: homework for 20 minutes Learning Goals: Students will be able to: Maneuver through the maze controlling
Lesson plan for Maze Game 1: Using vector representations to move through a maze Time for activity: homework for 20 minutes Learning Goals: Students will be able to: Maneuver through the maze controlling
Getting Started with TI-Nspire High School Science
 Getting Started with TI-Nspire High School Science 2012 Texas Instruments Incorporated Materials for Institute Participant * *This material is for the personal use of T3 instructors in delivering a T3
Getting Started with TI-Nspire High School Science 2012 Texas Instruments Incorporated Materials for Institute Participant * *This material is for the personal use of T3 instructors in delivering a T3
INTERMEDIATE ALGEBRA PRODUCT GUIDE
 Welcome Thank you for choosing Intermediate Algebra. This adaptive digital curriculum provides students with instruction and practice in advanced algebraic concepts, including rational, radical, and logarithmic
Welcome Thank you for choosing Intermediate Algebra. This adaptive digital curriculum provides students with instruction and practice in advanced algebraic concepts, including rational, radical, and logarithmic
COMPUTER-AIDED DESIGN TOOLS THAT ADAPT
 COMPUTER-AIDED DESIGN TOOLS THAT ADAPT WEI PENG CSIRO ICT Centre, Australia and JOHN S GERO Krasnow Institute for Advanced Study, USA 1. Introduction Abstract. This paper describes an approach that enables
COMPUTER-AIDED DESIGN TOOLS THAT ADAPT WEI PENG CSIRO ICT Centre, Australia and JOHN S GERO Krasnow Institute for Advanced Study, USA 1. Introduction Abstract. This paper describes an approach that enables
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this